Paper review
1.Show, Attend, and Tell: Neural Image Caption Generation
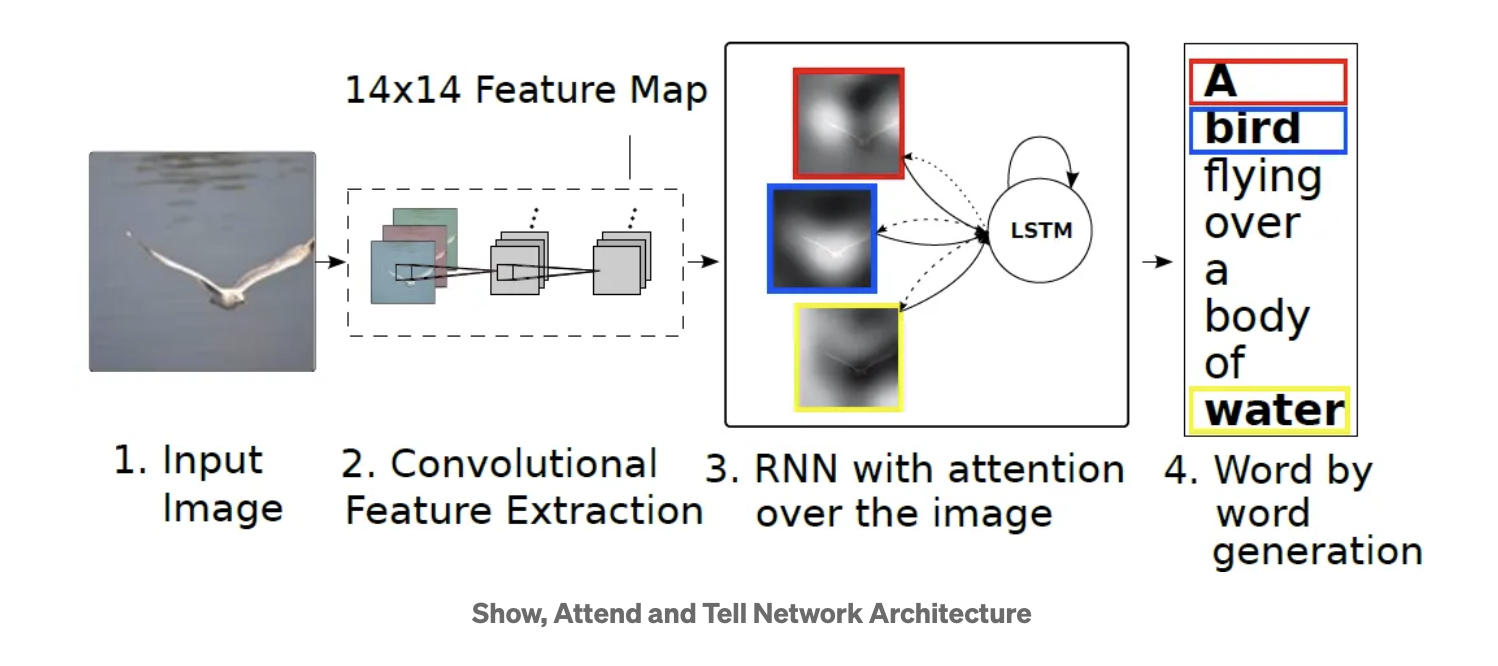
핵심 내용만 요약 Image captioning paper1\. Input Image: 모델에 입력되는 이미지로부터 시작. 이 이미지는 다음 단계에서 feature을 추출을 위해 사용됨.2\. Convolutional Feature Extraction: 입력 이미지는
2.VL-BERT: PRE-TRAINING OF GENERIC VISUALLINGUISTIC REPRESENTATIONS

VIT가 나오기 이전에 나왔던 transformer 구조를 활용하여 image captioning task에 활용한 논문. VIT 이전에는 어떠한 접근 방법으로 task를 수행했는지 초점을 큰 컨셉에 대해서만 간략하게 리뷰! VL-BERT는 BERT 모델을 기반으로
3.VideoBERT: A Joint Model for Video and Language Representation Learning

VideoBERT. 2019년 Google Research 팀에서 출간한 논문. (https://arxiv.org/pdf/1904.01766.pdf) 이미지 모델에서 spatial sampling 대신에 비디오 프레임을 시간적으로 샘플링해서 feature를 추출하고,
4.Learning Transferable Visual Models From Natural Language Supervision
Multimodal metric learninng이 요즘은 대세. 이 CLIP 이라는 모델은 정말 단순하지만 데이터의 파워로 해당 분야를 거의 정복했다고 한다. 2021년에 나온 논문 텍스트, 이미지 pair 데이터로부터 각 텍스트 encoder로부터 feature
5.Multimodal biomedical AI

2022년 Nature medicine에 published 된 review article. (https://www.nature.com/articles/s41591-022-01981-2)전체적인 흐름을 확인하기 위해서 논문 리뷰! AI 발전이 너무 빨라서 지금이
6.PaLM: Scaling Language Modeling with Pathways
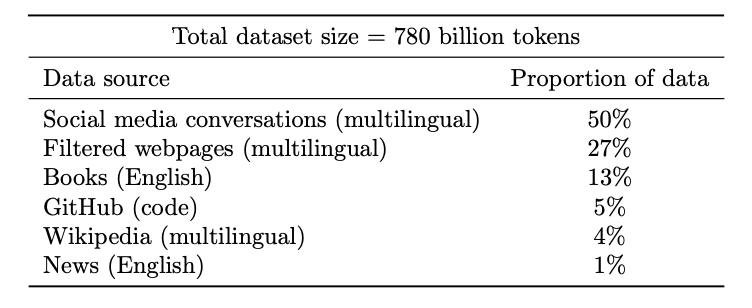
2022년 google research 팀에서 발표한 LLM 모델 PaLM. (https://arxiv.org/pdf/2204.02311.pdf) Med-PaLM 논문을 리뷰해보기 이전에 간단히 어떠한 LLM 모델인지 리뷰해보도록 하기. Abstract Pathway
7.Data-efficient and weakly supervised computational pathology on whole-slide images
Multiple instance learning을 적용한 CLAM 모델 논문. CLAM 모델 구조에 대해서 좀더 자세하게 파악하기 위한 논문 리뷰. (추후 리뷰할 CLAM을 활용한 멀티모달을 이해하기 위해)(https://www.nature.com/articl
8.Data-efficient and weakly supervised computational pathology on whole-slide images (2) - code review
어제 리뷰한 CLAM의 코드 리뷰. 코드는 아래 깃허브 참고. (https://github.com/mahmoodlab/CLAM?tab=readme-ov-file코드를 보면서 전체적인 pipeline을 다시 한번 살펴보고, CLAM 모델 구조에 대해서 리뷰. 전
9.(Review paper) Deep learning in cancer pathology: a new generation of clinical biomarkers
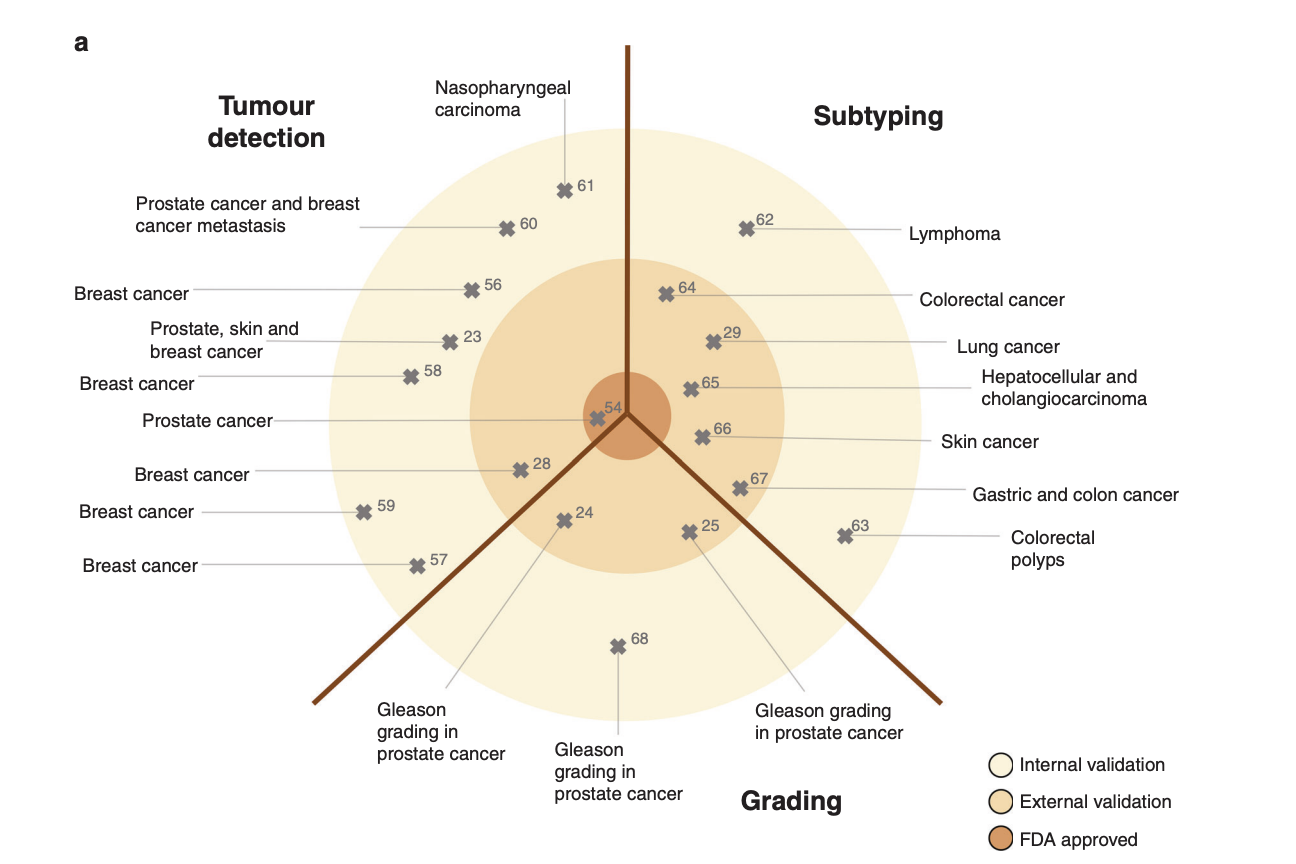
Deep learning in cancer pathology: a new generation of clinical biomarkers (British Journal of Cancer. 2021)(https://www.nature.com/articles/s414