2022년 google research 팀에서 발표한 LLM 모델 PaLM. (https://arxiv.org/pdf/2204.02311.pdf)
Med-PaLM 논문을 리뷰해보기 이전에 간단히 어떠한 LLM 모델인지 리뷰해보도록 하기. 다른 LLM 모델들과의 성능 비교를 어떻게 했는지, 실험을 어떻게 했는지 초점보다는 대략적으로 어떤 모델인지만 확인해보도록 하기.
LLM에서 사용되는 모델 구조나, 어떻게 계산 효율성을 높이는지, 또 일반적으로 내가 알고 있는 딥러닝 모델들과는 다르게 어떤 파라미터나 optimizer들을 사용하는지 확인해보기 위한 리뷰.
Abstract
Pathways Language Model (PaLM) 은 5400억 개의 파라미터를 가진 대규모 transformer 언어 모델로, 자연어 처리 작업의 few-shot 학습의 이점을 더욱 확장하기 위해 개발된 모델임. Few-shot 학습은 특정 task에 모델을 적응시키기 위해서 필요한 task별 훈련 데이터의 수를 대폭 줄이는 특성이 있는데, PaLM은 pathways라는 새로운 머신러닝 시스템을 사용해서 6144개의 TPU로 훈련이 되었고, 매우 효율적인 훈련을 가능하게 했다.
PaLM은 LLM 분야에서, 모델 규모를 확대함에 따른 이점을 계속해서 보여줬고, PaLM 540B는 다단계 추론 과제 모음에서 최신 fine-tunning 보다 우수한 성능을 보이고, 평균 인간 성능을 능가하는 성능을 달성했다. 여러 과제에서 모델 규모가 확대됨에 따라서 성능이 급격히 향상되는 것을 보여는고, PaLM 또한 그러한 결과 향상을 보여줬으며 다국어 작업 및 소스 코드 생성에서도 강력한 능력을 보여주고 입증하였다.
PaLM 연구는 대규모 언어 모델의 가능성을 탐구하고, few-shot 학습의 성능을 극대화하는 데 중점을 두면서, 동시에 이러한 모델의 개발과 사용이 수반하는 윤리적 및 사회적 문제에 대한 책임 있는 접근 방식을 강조하였다.
Introduction
LLM 모델, 특히 autoregressvie model들이 어떻게 발전을 이루었는지
최근 BERT, T5 등의 encoder-only, encoder-decoder architectures 들이 NLP tasks에서 좋은 성적을 보여줬다. 하지만 fine tuning을 위해 많은 양의 task-specific training examples들이 필요로 했으며, task에 맞게 fit하도록 하기 위해서 model parameter를 업데이트 하는 과정이 필요하기 때문에 복잡성이 추가되었다.
GPT-3는 매우 큰 autoregressive model로 언어모델이 few-shot 학습에 사용가능함을 보여줬다. 모델은 작업 설명과 몇가지 예시만 제공을 받고, decnoder-only transformer 구조이며, standard left-to-right LM objective이다. 이러한 GPT-3는 대규모 작업별 데이터 수집이나 모델 파라미터 업데이트 없이도 매우 강력한 결과를 달성할 수 있음을 보여주었다.
GPT-3 이후, 다른 대규모 autoregressive model들이 개발되었다. GLaM, Gopher, Chinchilla, Megatron–Turing NLG, 그리고 LaMDA와 같은 최신 모델들은 모두 출시 시점에 다수의 작업에서 few-shot 최신 기술 결과를 달성했다. 이 모델들은 모두 Transformer 아키텍처의 변형이며, 모델 크기 증가, 훈련된 토큰 수 증가, 더 다양한 소스에서 깨끗한 데이터셋에 대한 훈련, 그리고 희소하게 활성화된 모듈을 통한 계산 비용 증가 없이 모델 용량 증가 등 하나 이상의 접근 방식에서 주요 개선이 이루어졌다.
이 논문에서는 5400억 개의 파라미터를 가진 대규모 자동회귀 Transformer 모델인 Pathways Language Model(PaLM)을 고품질 텍스트 7800억 토큰으로 훈련하여 언어 모델링의 확장 라인을 계속 추진하였다. 이 모델은 다양한 자연어, 코드, 수학적 추론 작업에서 최신의 few-shot 결과를 달성하며, 이 중 다수에서 돌파구 성능을 보였고, 수천 개의 가속기 칩을 포함한 여러 TPU v4 Pods에 걸쳐 매우 큰 신경망을 효율적으로 훈련할 수 있는 새로운 ML 시스템인 Pathways를 사용하여 달성되었다.
Key takeaways
- Efficient scaling: Pathways를 사용하여 첫 대규모 적용을 실현, 6144 TPU v4 칩에서 5400억 파라미터 언어 모델을 훈련하여 이전에 달성하지 못한 효율성을 실현함.
- Continued improvements from scaling: PaLM은 수백 개의 자연어, 코드, 수학적 추론 작업에서 최신 기술 결과를 달성, 큰 LMs의 개선이 포화점에 도달하지 않았음을 보여줌.
- Breakthrough Capabilities: PaLM은 다단계 수학적 또는 상식적 추론을 필요로 하는 어려운 작업에서 언어 이해 및 생성에서 혁신적인 성능을 보임.
- Discontinuous Improvements: 특정 작업에서 62B에서 540B로 스케일링할 때 정확도에서 극적인 향상을 보여, 모델 규모가 충분히 클 때 새로운 능력이 나타날 수 있음을 시사함.
- Multilingual Understanding: PaLM은 기계 번역, 요약, 질문 응답을 포함한 다양한 언어에서 다국어 벤치마크에 대해 더 철저한 평가를 수행함.
- Bias and Toxicity: 성별 및 직업 편향에 대한 평가에서 모델 규모에 따른 정확도 향상을 발견하고, 인종/종교/성별 프롬프트 연속성에서 편견이 잘못 확인될 가능성을 보임.
Model Architecture
이미 개발된 다양한 모델들을 기반으로 Model architecture를 만들었음. (Transformer based)
1. SwiGLU Activation: Used (Swish(xW) · xV) for the MLP intermediate activations. ReLU, GeLU보다도 더 좋은 성능을 가지고 있었음. SwiGLU가 더 복잡한 비선형 관계를 학습 가능하다고 함. 하지만 intermediate activation 계산을 위해서 행렬 곱이 3번이 필요해 기존 ReLU 처럼 행렬 곱이 두번만 필요한 활성화 함수보다 계산적인 측면에서는 더 많이 소요가 되었지만, 품질적인 측면에서는 더 좋은 결과를 보여주었다고 함.
2. Parallel Layers: 원래 decoder only setup이라면 토큰 X가 X의 layer norm을 거치고 attention을 거치고, 그 다음에 feedforward network를 거쳐서 이거를 다시 multi layer perceptron에 넣고, 그 다음에 다시 x하고 더하는 구조를 가지고 있음.
Decoder only set up: y = x + MLP(LayerNorm(x + Attention(LayerNorm(x))))
근데 이 논문에서는 이거를 두 개로 쪼개서 동시에 parallel하게 동작할 수 있게 했다.
Parallel set up: y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x))
입력 x에 대한 LayerNorm을 한 번만 적용하고, 그 결과를 MLP와 Attention 메커니즘에 동시에(병렬로) 제공함. 그 후, 이 두 처리의 결과를 입력 x와 함께 더하여 최종 출력 y를 구한다. 이렇게 병렬로 처리함으로서 15%더 빠른 훈련 속도를 제공하고 품질 저하도 크게 없음을 확인하였음.
3. Multi-Query Attention: 기존 Transformer 모델에서는 각 attention head마다 query, key, value의 세 가지 구성 요소가 있고, 각각은 다음과 같은 역할을 함:
- Query: 현재의 항목(또는 단어)가 다른 모든 항목과 얼마나 관련이 있는지를 평가.
- Key: 다른 항목들이 쿼리와 어떻게 비교되는지를 나타냄.
- Value: 실제로 전달되어야 할 정보를 담고 있음.
기존의 multi head attention에서는 각 헤드마다 자체적인 query, key, value 프로젝션을 가지며, 이는 병렬로 처리되는 작업들이다. 하지만 multi-query attention 에서는 key와 value에 대한 프로젝션이 모든 헤드에 대해 공유된다. 즉, key와 value가 하나의 공통된 투영을 사용하지만, 각 헤드의 쿼리는 여전히 자체적인 투영을 가진다. 이는 계산 효율성을 높이는데, 하나의 토큰을 디코딩할 때 여러 헤드가 동일한 key,value 값 정보를 재사용할 수 있기 때문이다.
4. RoPE Embeddings: 긴 시퀀스에서 더 나은 성능을 보인다고 알려진 Rotary Positional Encoding embedding 기법을 적용하였음.
Rotary positional encoding의 기본 아이디어는 벡터 공간에서 rotation을 사용해서 단어나 토큰의 순서를 인코딩하는 것이다. 기존 positional encoding은 단어의 위치에 따라 고유한 값이 부여되고, 이 값들은 문장의 다른 부분과 어떻게 상호작용하는지에 대한 정보는 포함되어 있지 않다. 하지만 ROPE positional encoding은 rotation 개념을 도입하면서, 인코딩된 벡터들이 서로 간의 상대적인 위치를 유지할 수 있도록 함. 단어의 위치가 변할때마다 인코딩 벡터가 rotation되면서, 각 단어의 상대적인 위치가 인코딩에 반영되도록 하는 것이다. 이러한 rotation은 단순한 이동이 아니라, 공간 내에서 벡터의 방향을 결정하는 것이다. 그렇기에 상대적인 위치들이 벡터 공간 내에서 좀더 명확히 표현되기 떄문에, transformer 모델은 문장 내에서 단어들의 상호 작용을 보다 더 정확히 이해 및 예측이 가능하다. 그래서 특히 긴 시퀀스에서 좀더 좋은 성능을 보이는 것으로 알려져 있다.
5. Shared Input-Output Embeddings: Input-output embedding matrices를 공유함.
6. Vocabulary:SentencePiece는 어휘 구축을 위한 도구로, 단어나 문자 레벨이 아닌 subword(단어의 일부) 단위를 기반으로 어휘를 만든다. 사용하는 어휘는 256,000개의 토큰을 포함하고 있고, 어휘들은 훈련 데이터로부터 생성되었고, 이는 훈련 효율성을 향상시킨다는 것을 발견했다. 그리도 단어들은 completely lossless and reversible하다. 특히 공백에 대한 정보가 다 기억된다는 특징인데, 공백같은 경우는 코딩같은 작업을 실시할때 기여한다는 점을 의미.
-> 그래서 정리를 해보면 SwiGLU acitivation은 quality, parllel layer는 속도, multi-query attention은 학습하는데 cost saving, RoPE embedding은 학습 퍼포먼스 증가, bias를 사용하지 않음으로서 학습 안정성을 높일 수 있었고, vocabulary는 학습의 효율성을 높일 수 있었음.
Model Scale Hyperparameters
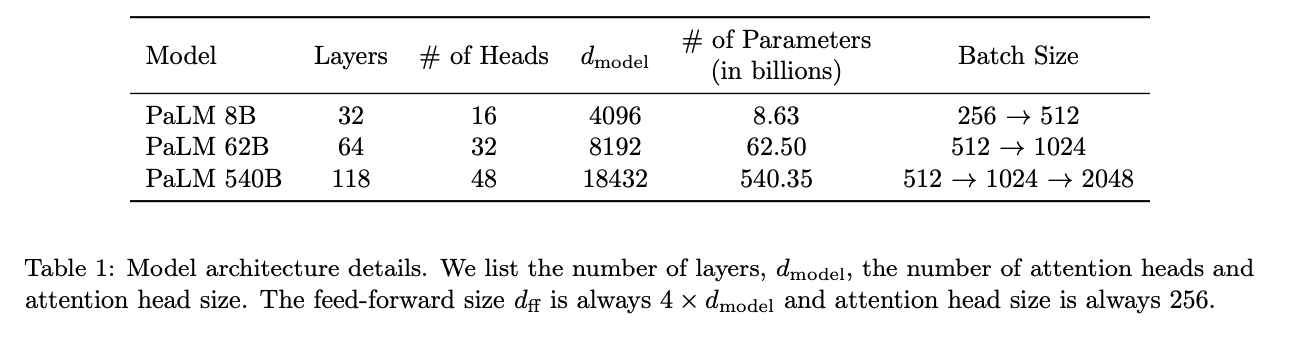
모델들은 3개의 파라미터로 학습이 된 8B, 62B, 540B 모델을 비교하였음.
Training Dataset
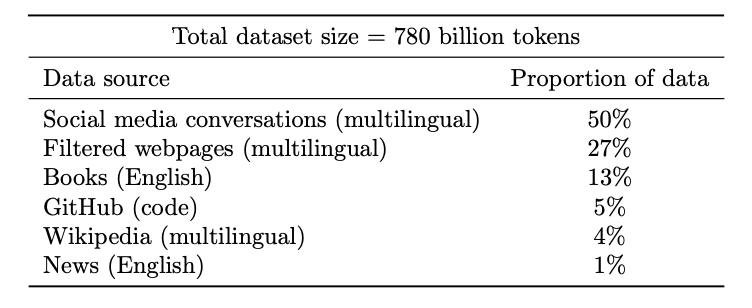
전체 데이터셋은 7800억 토큰으로 구성되며, 여러 자연어 사용 사례를 대표하는 데이터로 구성되어 있음. 데이터는 웹페이지, 책, 위키백과, 뉴스 기사, 소스 코드, 소셜 미디어 대화 등 다양한 출처로부터 모아진 것.
Training Infrastructure
논문에서 이런 대규모 모델 학습을 가능하게 한 pathway에 대한 설명.
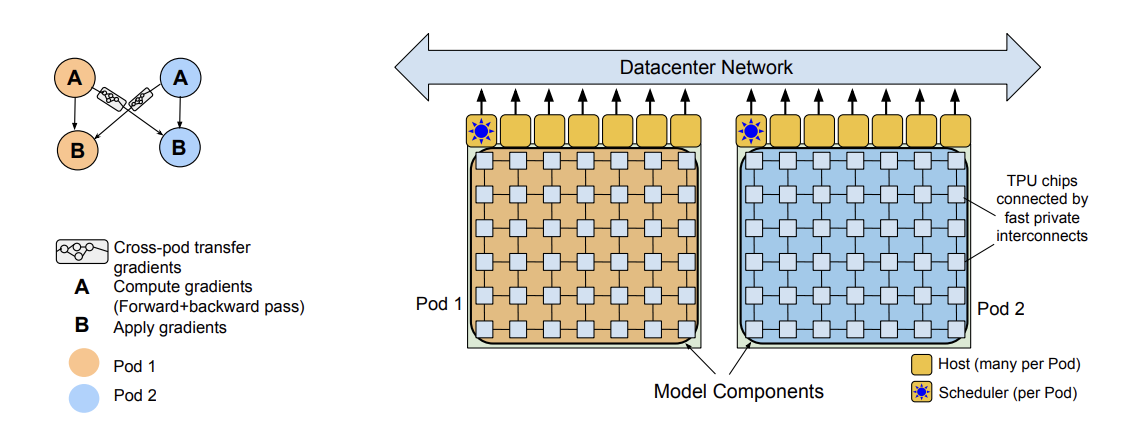
크게 TPU 파트 두 개로 구성되어 있고 (Pod1,2), 학습을 할때 각자 배치를 두개로 쪼개서 두 개의 pod에 나눠가지게 된다. 그런 다음 각 두개의 역할로 나누어져서, 첫번째 A는 forward, backward path를 계산하게 되고, 두번째 스텝에서는 두개의 TPU pod간의 gradient 정보를 공유하고 교환하고 gradient 를 업데이트 하는 스텝으로 이루어져 있음.
이렇게 했을때 굉장히 많은 병렬성을 가질 수 있게 되었지만, gradient를 교환할때 많은 traffic이 발생하는 문제점이 있음. Bursty workload 하고, 각 pair of hosts들은 1.3GB의 gradients를 각 training step마다 교환함. 그래서 이 것을 해결하기 위해서 datacenter network를 사용해서 좀더 효율적으로 빠르게 학습할 수 있도록 달성했다고 함.
Training Efficiency
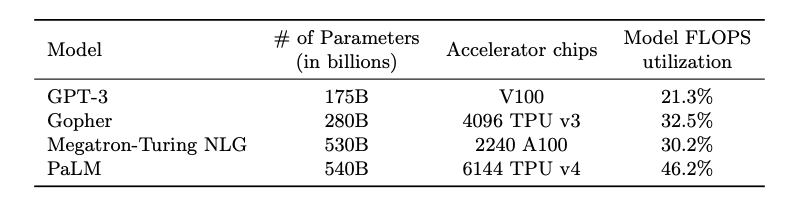
기존 모델들과 학습 효율을 비교하였음. 'Model FLOPS' 수치를 비교하였음.
Training Setup
Weight initialization:
- The kernel weights are initialized with 'fan-in variance scaling'.
- The input embeddings are initalized to E ~ N(0,1)
Optimizer:
- Adafactor optimizer without factorization.
- Effectively equivalent to Adam with 'parameter scaling'.
- 모델 파라미터 사이즈가 바뀌어도 그것에 맞춰 learning rate를 조절해줄 필요가 없다는 특징을 가짐.
Optimizer hyperparameters:
- Momentum 값을 좀더 다이나믹하게 설정해줌으로 shorter windows에서 추론할 때 성능이 안 좋아지는 것을 막았다고 함.
Loss function:
- LLM negative log likelihodd loss 사용 (average log probability of all tokens without label smoothing)
- 분포가 0에 가깝에 설정
Batch size:
- Dynamic batch 사용.
- Use batch size 512 (1M tokens) until step 50k, then double it to 1024 (2M tokens) until step 115k, and finally double again it to 2048 (4M tokens)
- Smaller batch가 학습 초기에 sample efficient 한다는 특징이 있고, 큰 배치가 점점 갈수록 gradient estimate에 좋고 TPU 효율 때문에 배치를 늘린 것.
Sequence length:
- Input examples are concatenated together and then split into sequences of exactly 2048 tokens.
- Few shot learning을 진행했기 때문에 이렇게 나누어서 진행.
Bitwise determinism:
- 데이터 같은 경우도 random access하게 만들어서 학습할 때 다시 재현가능하게 만들었음.
Dropout:
- Dropout이 사용되지 않았음.
Training Instability
학습을 진행하면서 대략적으로 20번정도의 spikes가 관찰이 되었다고 함. 보통 spikes가 잘못된 데이터가 들어가면서 loss값이 튀면서 발생하는데, 그래서 spike가 발생할 때마다 그 부분을 일부 제거해서 완화시킬 수 있었다고 함.
근데 이것을 데이터의 문제가 아니라고 함. 해당 데이터 영역들에 대해서만 따로 학습을 진행해본 결과 spikes는 관찰이 되지 않았지만, 좀더 연구해봐야할게 모델의 파라미터나 데이터의 조합이 spike를 발생하는 것으로 추측한다고 결과를 제시함.
