Multimodal metric learninng이 요즘은 대세.
이 CLIP 이라는 모델은 정말 단순하지만 데이터의 파워로 해당 분야를 거의 정복했다고 한다. 2021년에 나온 논문
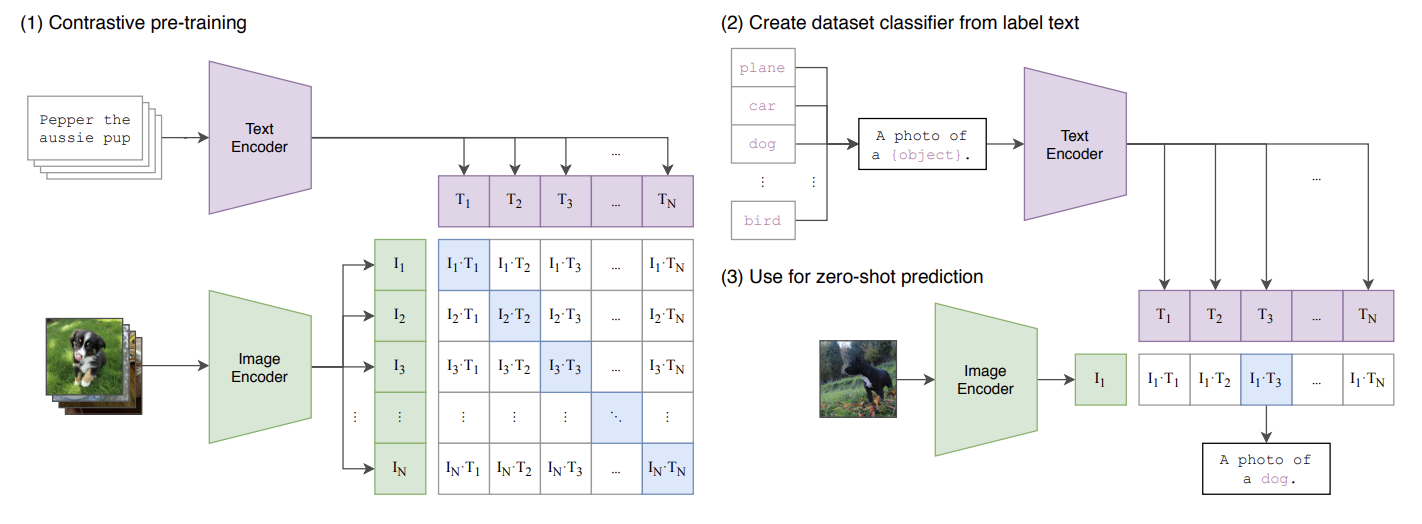
텍스트, 이미지 pair 데이터로부터 각 텍스트 encoder로부터 feature를 추출하고, image encoder로부터 feature를 추출하여 두 개를 이렇게 외적을 시켜주면 대각선에 있는 거는 자기 같은 페어가 원래 있었던 것들이기에 1에 가깝게 만들어주고, 나머지는 이제 pair가 아니기 때문에 0으로 가게 만들어주는 것이다.
Contrastive learning을 한 것이다. 같은 pair에서 나온 것들은 가깝게 만들어주고, 다른 pair에서 나온 것은 멀어지게 만드는 것을 (1) Contrastive pre-training 이라고 표현을 한 것이다. 이렇게 단순한 알려진 아이디어를 가지고 엄청나게 큰 데이터셋을 학습을 시켰더니 잘 되더라라는 이야기이다.
그래서 이렇게 학습이 끝나고 나면 텍스트 임베딩이랑 비쥬얼 임베딩이 각각 굉장히 디테일한 정보를 잘 담고 있게 되어서 새로운 이미지가 들어와도 잘 적용이 된다는 것이다.
Training

-
모델을 살펴보면 사실은 위에 내용이 전부이고, 배치 사이즈만큼의 이미지랑 텍스트 페어가 들어오게 되고 그것에 대해서 true pairs간에의 similarity값은 최대값이 되도록 하고, other pairs간에는 최소화되도록 하는 것이다.
-
그래서 이것을 수학적으로 보면 이러한 내적 계산이 identiity matrix (단위 행렬)가 되게 만들어주는 거랑 같다.
-
그리고 이게 본질적으로 contrastive learning에서 InfoNCE loss를 사용하는 것이랑 같은 원리라고 함.
Inference
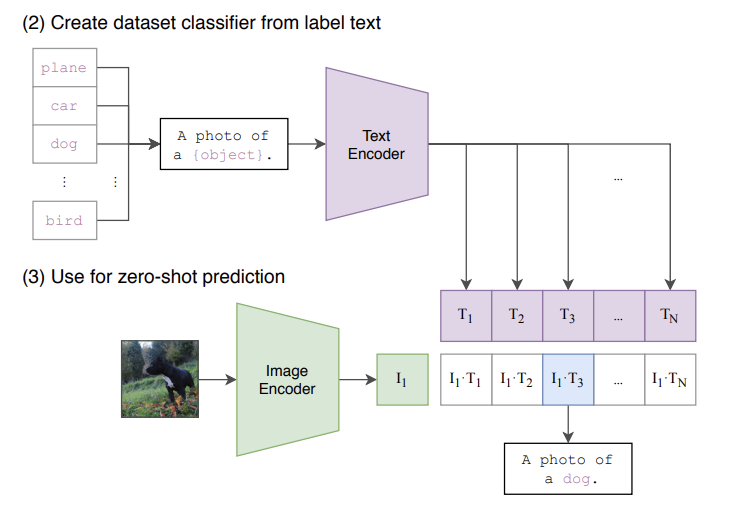
이렇게 진행을 하면 임베딩이 굉장히 강함. 이건 비쥬얼, 텍스트를 같이 본 것이기 때문에 훨씬 성능이 좋고 이를 활용한 후속연구들이 많이 진행되고 있음.
