VideoBERT. 2019년 Google Research 팀에서 출간한 논문.
(https://arxiv.org/pdf/1904.01766.pdf)
이미지 모델에서 spatial sampling 대신에 비디오 프레임을 시간적으로 샘플링해서 feature를 추출하고, visual frame 과 ASR을 통해 얻은 텍스트 데이터를 결합하여 비디오 내 시간적 연관성을 학습하는 모델임.
본 논문에서는 주로 요리 & 레시피 비디오를 대상으로 연구를 진행.
Abstract:
Self-supervised learning has become increasingly important to leverage the abundance of unlabeled data available on platforms like YouTube. Whereas most existing approaches learn low-level representations, we propose a joint visual-linguistic model to learn high-level features without any explicit supervision. In particular, inspired by its recent success in language modeling, we build upon the BERT model to learn bidirectional joint distributions over sequences of visual and linguistic tokens, derived from vector quantization of video data and off-the-shelf speech recognition outputs, respectively. We use VideoBERT in numerous tasks, including action classification and video captioning. We show that it can be applied directly to openvocabulary classification, and confirm that large amounts of training data and cross-modal information are critical to performance. Furthermore, we outperform the state-of-theart on video captioning, and quantitative results verify that the model learns high-level semantic features.
Summary
이전 VL-BERT 처럼 비디오를 프레임 단위로 object detection을 해서 모델 input으로 넣을수가 없음. 그렇기 때문에 본 논문에서는 제안한 방법은 video tokenization을 해보자라는 것이다. 비디오 프레임들을 내용에 따라서 클러스터링을 해서, 그 클러스터 아이디를 마치 레이블처럼 사용을 하자는 접근 방법을 통해 해결하고자 함.

Viode tokenization: 클러스터를 형성한 이후, 해당 프레임 이미지가 클러스트들에서 가장 가까운 점들을 찾아 가지고, 그 점에 해당하는 이미지를 클러스터에 대표가 되는 이미지로 사용하는 것이다. 이게 무슨 말이냐면, 실제 영상 (케이크 만들기)가 들어오게 되면, 이거랑 비슷한 장면으로 우리가 데이터셋에서 있던 수많은 프레임들을 클러스터링을 잘 해놓으면 얘랑 의미가 되게 비슷한 장면들끼리 하나의 클러스터를 구성하게 되어 있을 ㄷ것이다. 그러면 거기에 centroid에 가장 가까운 이미지를 representative로 설정을 하고 바꿔치기 하는 것이다. 이걸 왜 바꿔치기하나면, 실제로 original video frame을 feature로 사용을 하는데 얘를 만약에 가려둔다고 치면, 이 자리가 무엇으로 예측을 해야하냐면 얘가 대표하는 어떤 클러스터로 예측을 해야 되는 것임. 그럼 내용을 보면 대표 이미지랑 어느정도 일치하는 것을 알 수 있고, 그러니깐 이 클러스터가 충분히 대표성이 있다라는 것을 알고 있으면 됨.
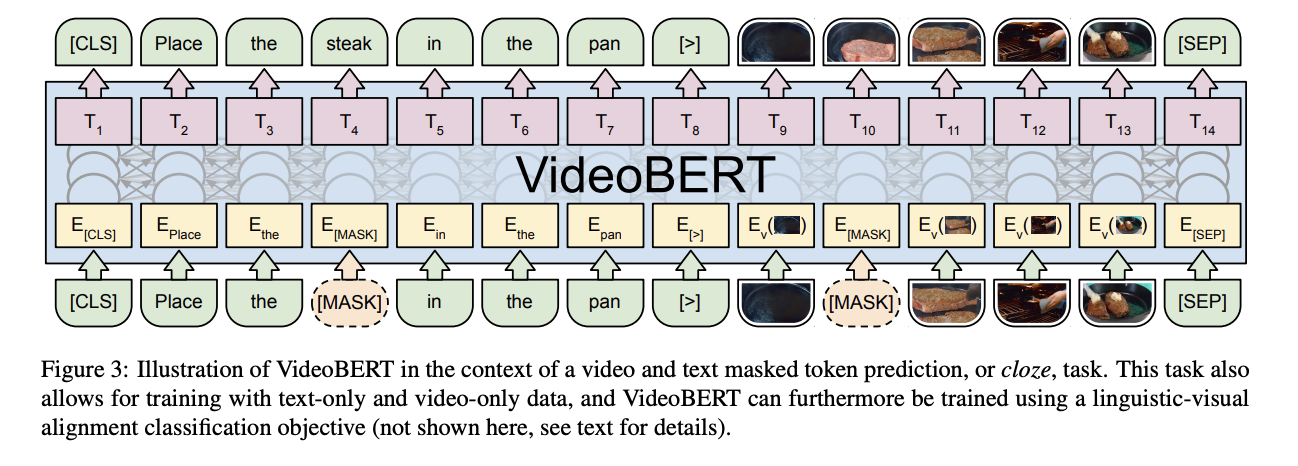
그래서 여기 보면 생고기 부분에 있는 [MASK] 부분에 속하는 것을 어떻게 예측을 할 것인가? 라고 생각을 해보면, 이 날고기가 후라이팬에 있는 장면들이 모여있는 클러스터들이 있을 것이고 그 클러스터라는 사실만 맞춰주면 되는 것이다. 근데 그걸 그 클러스터는 우리는 번호밖에 모르고 레이블이 안달려 있으니깐 그거를 대표할수 있는 이미지로 사람들이 알아볼 수 있도록 visualization 해준 것이다.
Fast R-CNN으로 모든 프레임당 object detection을 진행하는 것과 다르게 이제 클러스터링 기법을 통해서 비교적 간단하게 이제 문제를 해결하자는 접근법을 가지고 있는 것이다!
Training
-
Linguistic-visual alignment task: 이미지랑 텍스트랑 얼만큼 일치하는지를 학습하는 것.
-> aligned/not 이것이 일치하는지 아닌지에 대한 데이터를 어떻게 수집하는지 -> ASR을 뽑아서 사용하고, ASR은 몇분 몇초에 진행했는지 알 수 있고 그 시간에 해당되는 비디오 프레임을 이제 positive pair로서 사용하는 것. 따로 레이블링을 안해도 되고 데이터에서 잘라서 사용하면 되는 것. 그래서 같은 부분에 해당되는 것을 잘라서 쓰는 것은 positive, 반면에 negative는 아무곳에서 뽑은 비주얼이나 텍스트를 엮어놓으면 되는 것. 그래서 이런식으로 데이터를 만들어버릴 수 있음. 그래서 텍스트가 그 비디오에 맞는 내용이냐 아니냐를 맞는 테스크가 첫번째 테스크이다. -
MLM (masked language modeling): 기존 버트랑 동일
-
MFM (masked frame modeling): 프레임이 하나 비워서 들어오면 얘가 속해있을 가장 그럴듯한 클러스터를 맞추는 classification 문제를 푸는 것이다.
그래서 이 3가지 테스크를 풀어서 이제 전체가 contextualize 가 되는 것이다.
Downstream tasks
- Recipe illustration: Conditioned on an input sentence, generate a video token for visualization
- Future frame prediction: Providing one (or a few more) inoput video token(s) and add some more masked future tokens.
- Zero-shot action classification: Force VideoBERT to 'speack' by probiding a template sentence but mask out verbs and nouns: "Now let me show you how to [MASK] the [MASK]."
- Video captioning: Mask all the words in the text part. The model will generate a sentence based on the visual signal.
