
- 핵심 내용만 요약
- Image captioning paper
Summary:
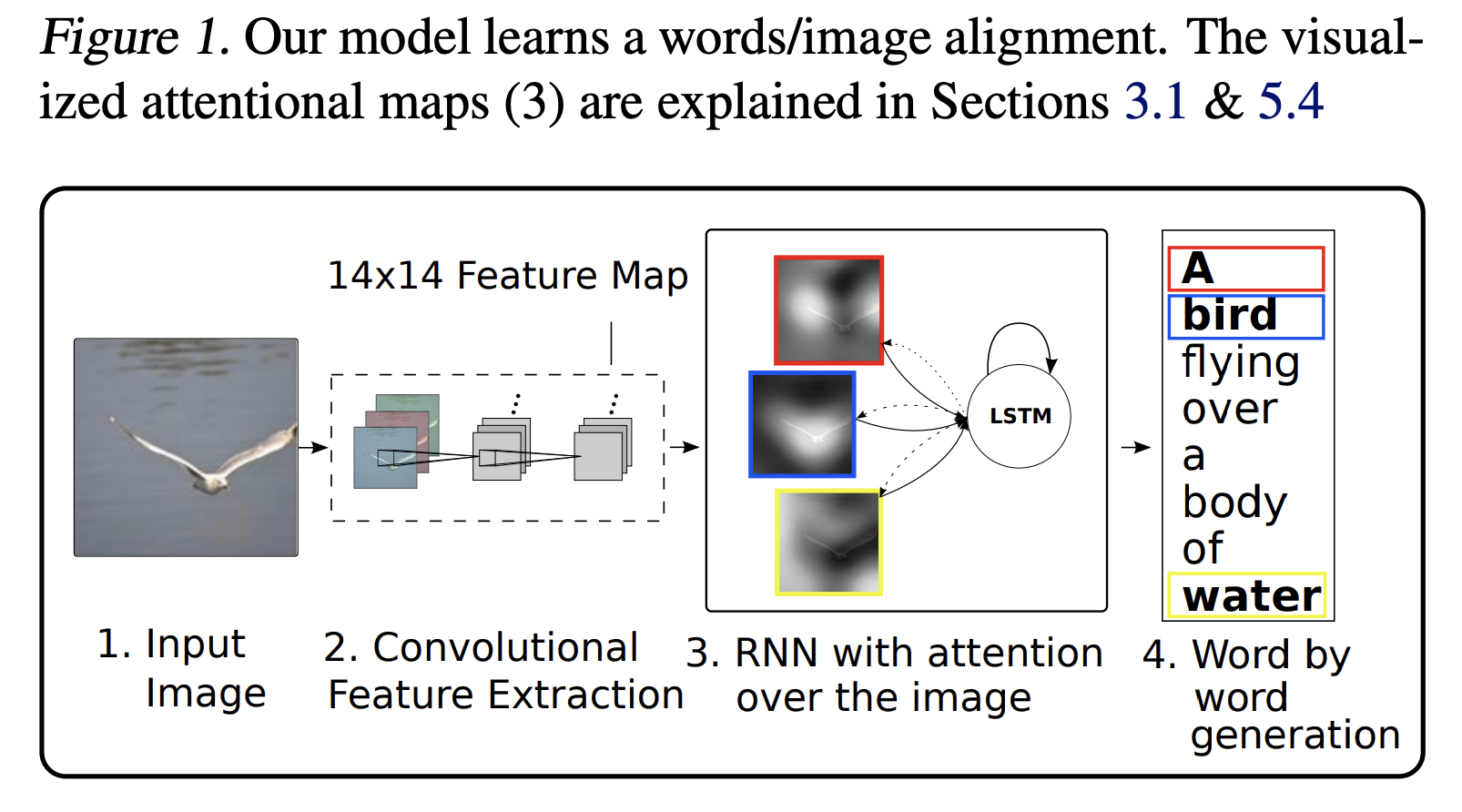
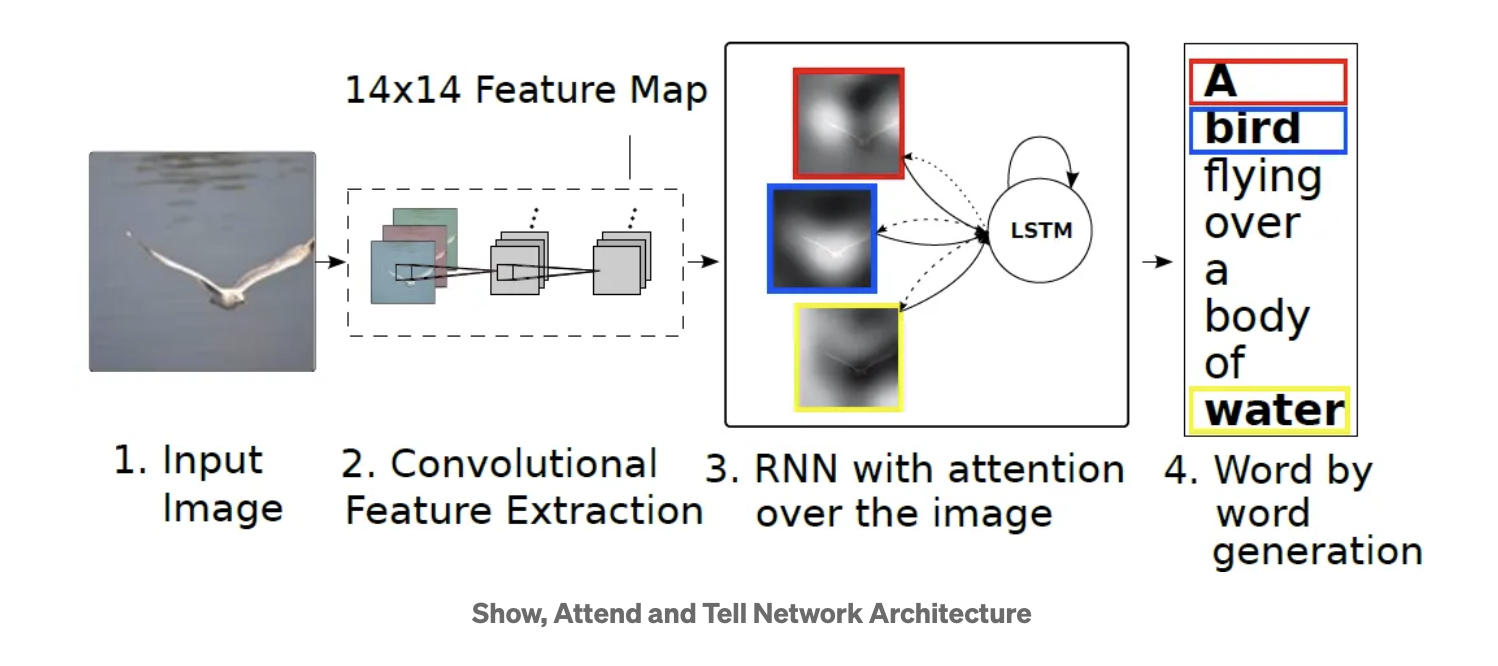
1. Input Image: 모델에 입력되는 이미지로부터 시작. 이 이미지는 다음 단계에서 feature을 추출을 위해 사용됨.
2. Convolutional Feature Extraction: 입력 이미지는 CNN을 통과하여 14x14 크기의 feature map을 생성함. 이 feature map은 이미지의 공간적 정보(spatial information)를 포함하고 있으며, 각 픽셀은 이미지의 일부 영역에 대한 정보를 나타냄.
3. RNN with attention over the image: LSTM은 이미지의 feature map과 이전 단계의 hidden state를 입력으로 받는다. 그러나 본 모델에서는 단순히 이전 상태와 현재 입력만을 고려하는 것이 아니라, 이미지의 feature map 전체에 대해 attention 메커니즘을 적용하여 모델이 이미지의 어떤 부분에 주의를 기울여야 할지 결정하게 함. 이를 통해 LSTM은 이미지를 묘사하는 단어들을 순차적으로 생성하게 된다.
4. Word by word generation: 모델은 LSTM의 출력을 통해 하나씩 단어를 생성하며, 생성된 단어는 최종적으로 이미지를 묘사하는 문장을 형성함. Attnetion 메커니즘은 각 단어가 생성될 때 마다 모델이 이미지의 어느 부분을 attnetion 해야 하는지 결정하는 데 도움을 준다. 예를 들어, "A bird"가 생성된 후, 모델은 이미지 상의 새와 관련된 부분에 주의를 기울여야 할 것. (나중에 example figure 확인)
RNN에 attention 적용한 것을 그대로 써서 input을 이미지로 받고, output을 text로 나온다는 점만 다른 것임. 그래서 멀티모달이라는 점만 다른것. 그럼 학습을 진행할 때도 마찬가지고, 처음에는 output으로 아무 단어를 내뱉곘지만 정답을 찾기 위해 backpropagation을 하면서 이 이미지에 대해서 해당되는 문장이 나오도록 강제를 해서 학습이 진행됨. 그래서 여러 학습 데이터를 통해서 학습을 시키면 처음보는 이미지를 봐도 잘 적용이 된다는 컨셉임.
How model works:
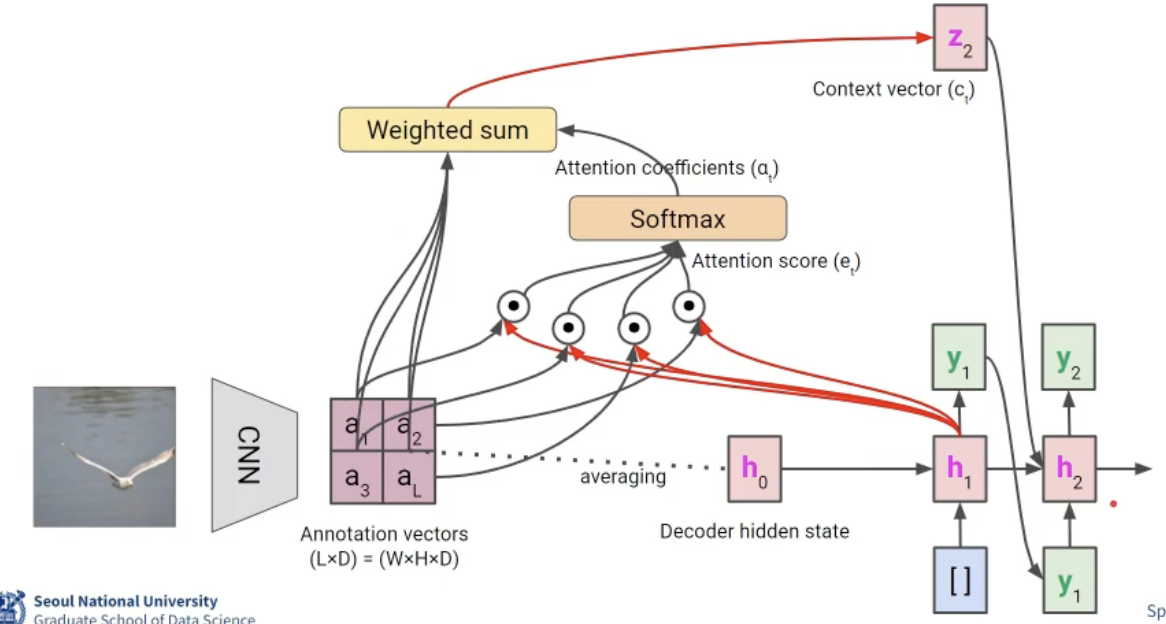
-
Image input & Feature extraction: 입력 이미지가 CNN을 통과하면 feature map 추출됨. 그림에서 보는 것처럼, ( a_1 )부터 ( a_L )까지 각각 이미지의 다른 부분에 해당하는 벡터. (예시는 2x2 feature map)
-
Initial hidden state: 디코더의 초기 hidden state ( h_0 )는 추출된 feature map들의 평균값으로 계산됨. 이 상태는 디코더의 생성 과정을 시작하는 지점으로 사용 .
-
Attention mechanism:
- 디코더의 초기 hidden state를 query로 사용하여, feature map vector들을 key로 하여 내적을 통해 attention score를 계산한다. 이 점수들은 소프트맥스 함수를 통해 정규화되어 합이 1이 되도록 변환해준다.
- Attention coefficients 값과 feature map vector와의 가중합을 계산하고, 이를 통해 context vector 생성. 이 벡터는 시퀀스 생성의 현재 단계와 관련된 이미지의 spatial information을 담고 있는 것.
- Context vector는 현재의 hidden state와 결합되어 출력(예를 들어, 이미지 캡션의 경우 단어)을 생성하고, 다음 단계의 시퀀스를 위해 hidden state를 업데이트함.
- 이 과정은 순차적으로 계속되며, 업데이트된 숨겨진 상태 ( h_1 ), ( h_2 ) 등이 새로운 쿼리로서 주의 집중 메커니즘에 사용됨. RNN 디코더는 주의 집중 메커니즘을 반복 적용하고 그 상태를 업데이트하면서 시퀀스의 다음 요소들(예를 들어 단어들)을 생성합니다.
(hidden state 2개가 사용되는 점 ! 아래 식에서 확인 가능)
그래서 해당 논문에서 사용한 Spatial attention을 정리하면:
- Query - Decoder LSTM hidden state hi
- Key, value: annotation vectors {a1, a2, ...ai}(local conv features)
- Attention values: weighted average of annotation vectors
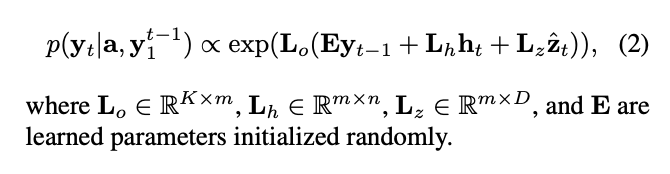
식을 보면 Eyt-1이 input이고, ht, zt가 전단계의 hidden state이다. Hidden state가 2개가 있는 셈이다. attention을 하지 않은 상태의 ht 와 한 상태의 zt가 있다. 그래서 이 것을 모델 파라미터와 곱해주고, Eyt-1의 경우는 word embedding이니깐 embedding layer를 통과시켜준 것. 이후 이 전체 값들에 대해서 모델 파라미터와 곱해줘서 모델링을 하게 되는 구조이다.
Model results example

이 모델의 장점이라고 하면 attention을 사용하기 때문에 interpretability가 있음. 단어 하나를 아웃풋을 낼 때마다 모델이 어느 부분에 attention을 주고 단어를 생성했는지를 알 수 있음.
Figure에 보이는 soft attention, hard attention이 있는데 우선은 soft attention 같은 경우는 모든 픽셀들이 어떤 일정한 스코어를 0부터 1 사이에 스코어를 받을 수 있어서 확률 분포처럼 결과값을 받을 수 있는 것임.
반면에 hard attention은 분포를 보는 것이 아니라 딱 한점만 찍도록 강제하는 것.


Fig5. 틀린 부분에 대한 예시. 근데 언듯 보면 첫번째 기린의 그림 같은 경우를 새처럼 보기도 하고, 여자의 후드티에 있는 표시를 시계처럼 보기도 하는 오류들을 보여주는 예시이다. 근데 왜 틀렸는지, 어떤 것을 오해했는지를 확인 가능하고 이런식의 interpretability를 보여주는 것.
(논문을 작성할 때 limitation example들을 보여줌으로 우리는 이런 것들은 잘 안 됐다 하지만~ 은근히 자랑을 할 수도 있고 ~ 논문 쓸 때 좋은 기술!)
추가적으로 video 데이터는 어떻게 처리하는지에 대해서 확인!
Describing Videos by Exploiting Temporal Structure
비디오가 input으로 들어오면 attention을 어느 frame에 둬 가지고 어떤 텍스트가 나와야 될지를 탐색하는 논문. "Show, Attend, and Tell: Neural Image Caption Generation" 논문의 spatial attention과 굉장히 유사함.
Medical image 같은 경우도 3D 형태의 데이터이기 때문에 해당 논문도 간만하게 어떤 원리인지만 리뷰해보도록 하기!
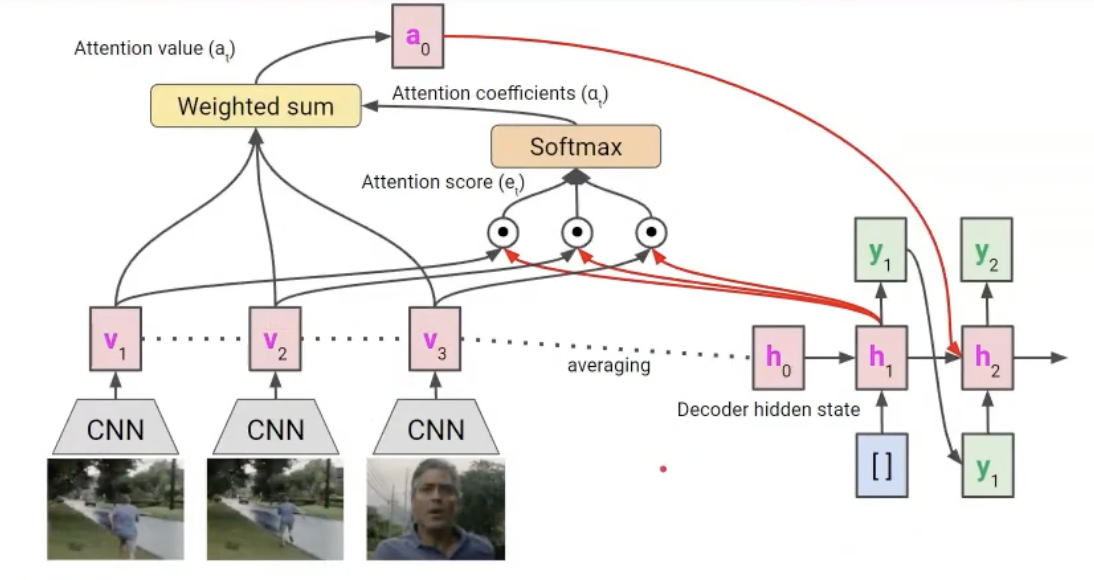
- 비디오가 시퀀스로 들어오게 되면 얘내들을 CNN을 돌려주게 되면 v1, v2, v3의 feature들이 추출됨. 해당 feature들을 이제 평균을 내어서 decoder hidden state가 됨.
- 그래서 decoder hidden state가 query, 각 v1, v2, v3 feature들이 key가 되어서 attention mechanism을 통해서 context vecotr a0 이 만들어지고, 이 값을 다음 hidden state 업데이트에 사용되고~ 이러한 구조로 연속적으로 학습이 되는 구조임.
