VIT가 나오기 이전에 나왔던 transformer 구조를 활용하여 image captioning task에 활용한 논문. VIT 이전에는 어떠한 접근 방법으로 task를 수행했는지 초점을 큰 컨셉에 대해서만 간략하게 리뷰!
Summary
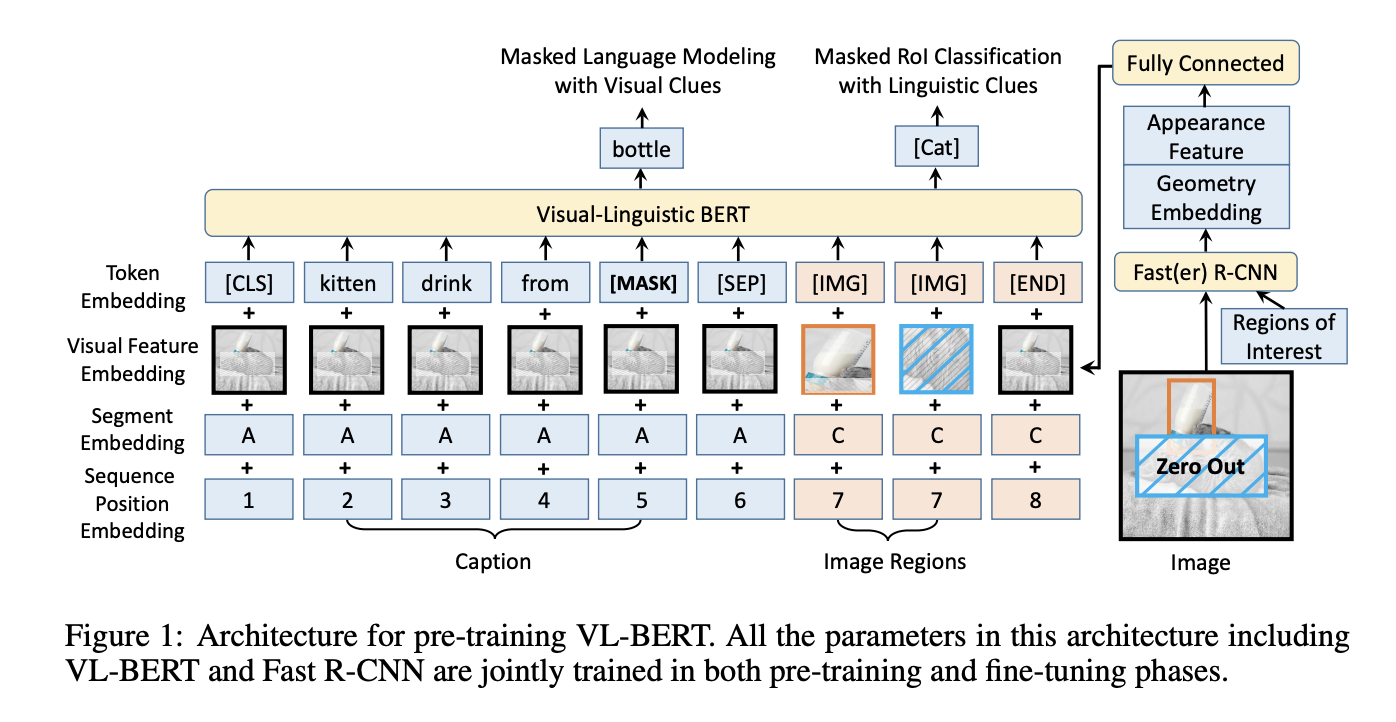
VL-BERT는 BERT 모델을 기반으로 하여 시각적 특징을 언어 모델링과 결합하는 방법을 제시하고, 기존 BERT의 tokenize와 유사한 사항들이 많지만 이미지 데이터가 들어오게 되면서 좀 변경된 부분들이 있음을 확인 가능하다.
*우선 구조에 대해서 먼저 파악을 해보면 아래와 같은 토큰으로 구성:
-
Token embedding: 텍스트 영역에 해당되는 파란 부분은 그대로 텍스트에 대한 정보가 tokenize가 되는 것이고, 이미지 영역에는 [IMG] 라는 정보만 제공해주는 speical token이 들어가게 되는 구조이다.
-
Visual fetaure embedding: 텍스트 영역에 속하는 부분은 전체 이미지에 대한 정보를 제공해준다. 단순 텍스트 단어 하나하나 만으로는 해당되는 단어가 이미지의 어느 영역에 속하는지를 알 수 없기 때문이다. 반면에 이미지에 속하는 영역의 경우는 Fast R-CNN을 통해서 object detection을 실시하고 그 결과로 나온 bounding box를 이제 토큰으로 들어가게 되는 것이다.
(VIT의 개념이 있었다면 패치 단위로 나누어서 학습을 적용했겠지만, 해당 논문은 2019년에 나온 논문! VIT는 2020년에 나온 논문) -
Segment embedding: 입력 데이터가 텍스트인지 이미지인지를 구분하는 임베딩이다. 텍스트 영역에는 A, 이미지 영역에는 C가 들어가게 된다. 'B'가 없는 부분이 좀 의문이였는데, 해당 모델 구조를 통해서 VQA task에도 활용이 가능하고, VQA task 의 경우는 input sequence가 2개가 들어가야 되기 때문에 그림에는 표현이 되지 않았지만 'B'를 건너뛰고 C로 표현이 되어 있는 것을 확인 가능하다.
-
Sequence position embedding: 입력 시퀀스 내에서 토큰의 위치를 나타내는 임베딩다. 텍스트 영역은 positional encoding을 진행하는 것 처럼 순서대로 정보가 들어가게 되는 것이고, 이미지의 경우 마지막 [END] 영역에 속하는 부분을 제외하고 그저 이미지임을 판단하기 위한 토큰 값이 추가가 되는 것이다.
Train
Maskesd language modeling with bisual clues: 텍스트 중 일부를 마스킹하여 모델이 그 부분을 예측하도록 함. 예를 들어, "drink" 단어가 [MASK]로 대체되었을 때, 이미지의 시각적 단서를 사용하여 이를 예측하는 것처럼 기존 BERT와 유사하게 MLM loss를 통해서 학습을 진행함.
Masekd RoI classification with linguistic clues: 이미지의 특정 영역을 'Zero Out' 처리하여 모델이 텍스트의 언어적 단서를 사용하여 이 영역이 무엇인지 분류하도록 한다. Fast R-CNN을 통해서 나온 결과값, 즉 object detection을 통해서 선별된 레이블의 값을 이제 classification task에 활용을 함으로서 학습을 진행하는 것이다.
VL-BERT랑 유사하지만 조금 다른 컨셉으로 진행한 논문!

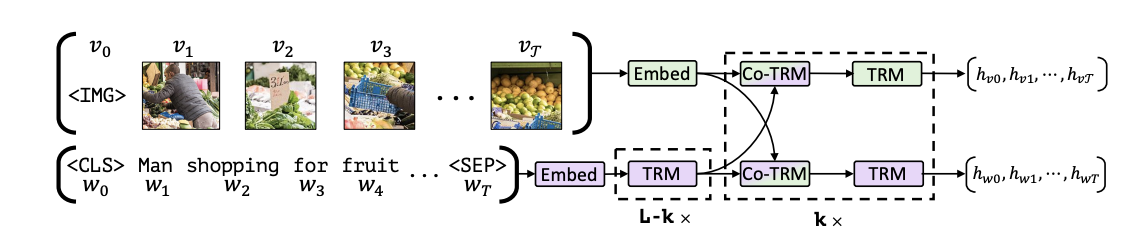
[TRM]이 transformer를 의미함. 녹색은 비쥬얼 시그널을 가지고 다루고, 보라색은 텍스트 영역들에 대해서 처리하는 것. 여기는 이미지는 이미지끼리, 텍스트는 텍스트끼리 따로 처리를 하는 컨셉이다.
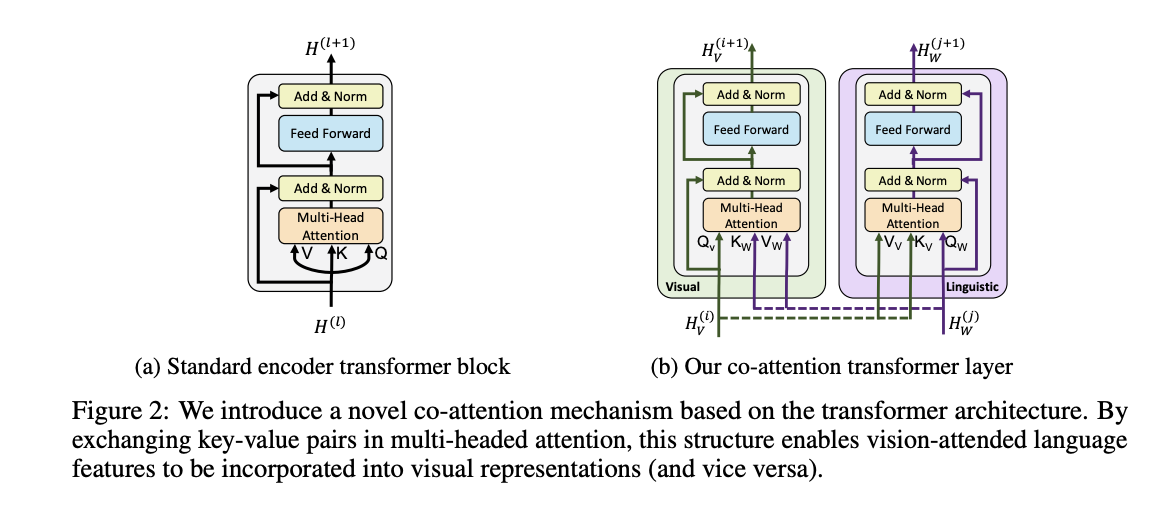
근데 그 앞에 Co-TRM이라는 것이 있는데 Co-attention transformer layer라는 것이다. 색깔을 보면 알 수 있듯이 지금 두개가 섞여 있는 구조이다. 아까 VL-BERT는 토큰을 한번에 넣어주는 구조라면, 얘는 여전히 이미지, 텍스트 각각 처리하는 transformer를 가지고 있다. 근데 transformer는 따로 있는데, query, key, value가 들어가는게 바뀐다. 쿼리는 자기의 값이 들어가지만, 대상이 되는 key, value는 상대방의 transformer의 값에서 가져오게 되는 구조이다.
근데 이것만 하면 자기를 잊어버리게 되니깐, Co-TRM -> TRM 으로 번갈아가면서 반복하면서 학습을 이제 진행하게 되는 구조로 구성되어 있다.