<CS224W> Lecture 15. Traditional Generative Models for Graphs
1. Machine Learning for Graph Generation
Graph Generation Tasks
- Graph generation에는 주어진 그래프와 유사하도록 만드는 task와 제약조건 하에서 최적화되는 그래프를 생성하는 task가 있다. 이번 lecture에서는 전자에 대해 다룬다.
- 하지만 다음과 같은 이유로 그래프 생성은 어려움이 있다.
- n개의 노드를 위해 n2개의 값을 만들어야 하므로 output space가 크다.
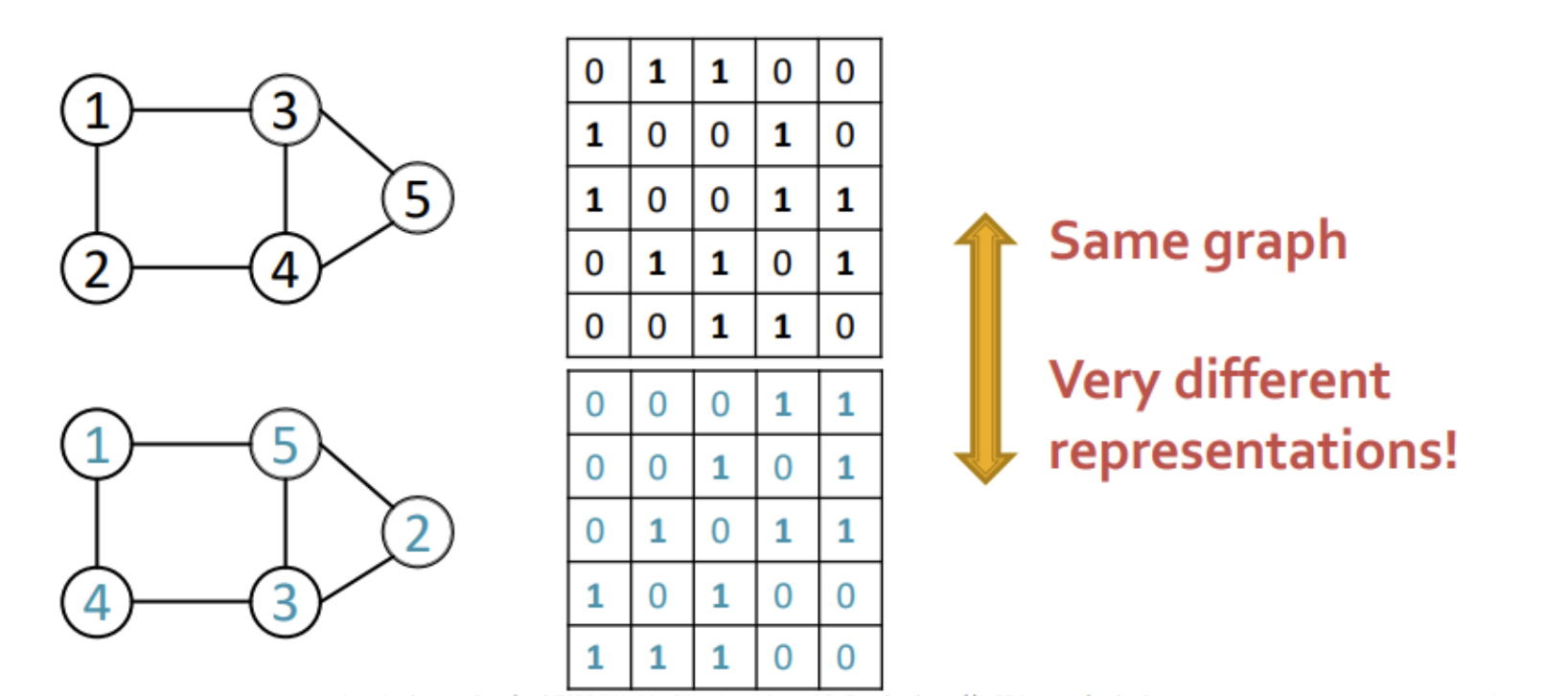
- 그래프를 표현하는 방식이 고정되어 있지 않아 같은 그래프여도 인덱스의 순서에 따라 다르게 표현되고 따라서 objective function으로 최적화하는데 어려움이 있다.
- 노드의 연결과정에서 처리하고 있는 노드의 수를 기억해야 한다는 long-range dependency 문제가 있다.
Graph Generative Models
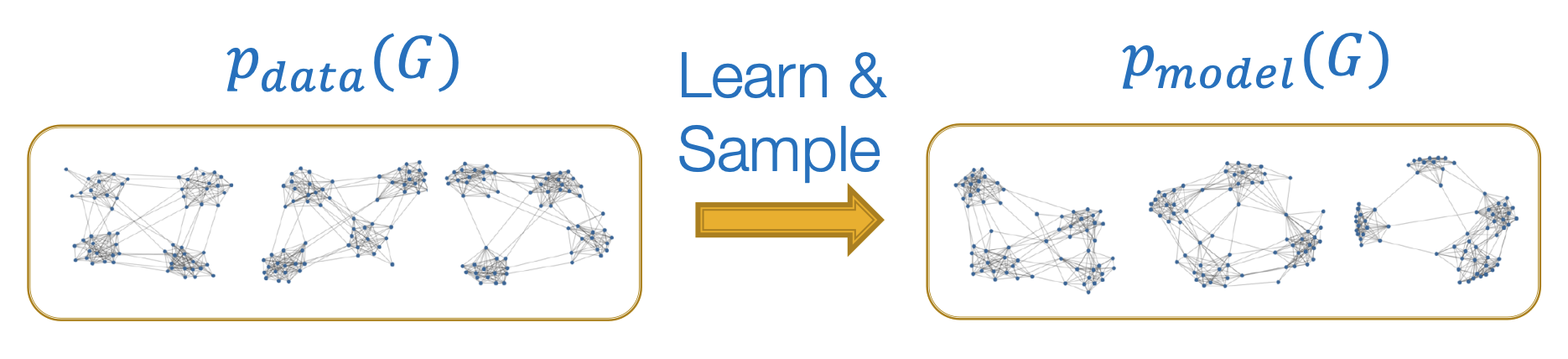
- 우리의 목표는 pmodel(G)의 분포를 학습하여 주어진 pdata(G)와 유사하게 만들고 (density estimation) 이로부터 샘플링(sampling)하는 것이다.
- pmodel(x;θ)이 pdata(x)에 가까워지도록 하기 위해 MLE를 활용한다.
θ∗=θargmaxEx∼pdata logpmodel (x∣θ)
- 일반적으로 정규분포 N(0,1)로부터 노이즈 zi를 샘플링하여 함수 f(zi;θ)를 통해 complex distribution을 만들며 f는 deep neural network를 통해 학습한다.
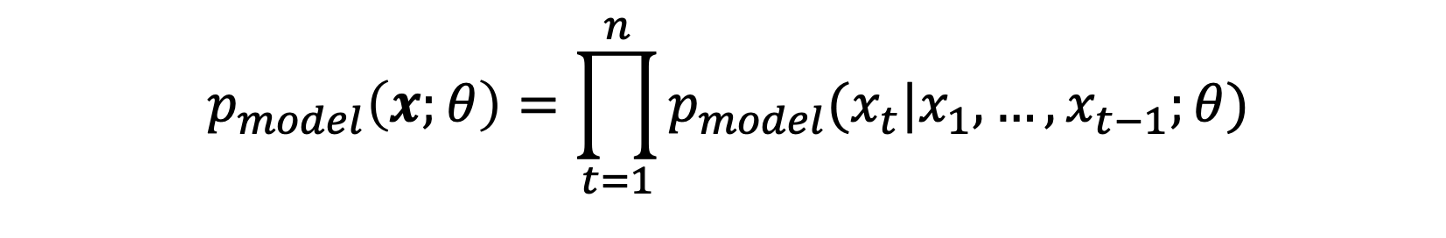
- Auto-regressive model: density estimation과 sampling을 모두 수행하기 위해 노드/엣지를 추가하는 것을 t번째 action xt으로 보고 joint liklihood를 구한다.
2. GraphRNN: Generating Realistic Graphs
GraphRNN Idea
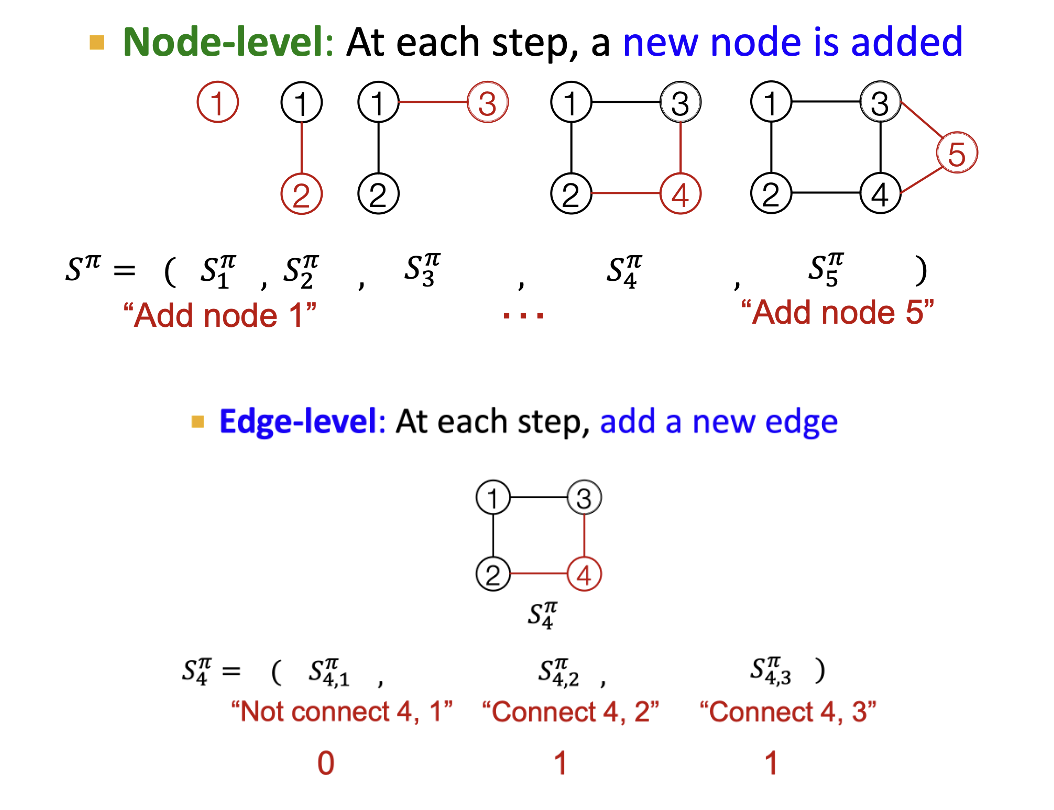
- Graph generation problem을 sequence generation problem으로 바꾼다.
- 노드를 추가하는 step과 엣지를 추가하는 step으로 나뉜다.
- 노드를 추가하는 순서는 랜덤하게 선택한다.
Recurrent NNs
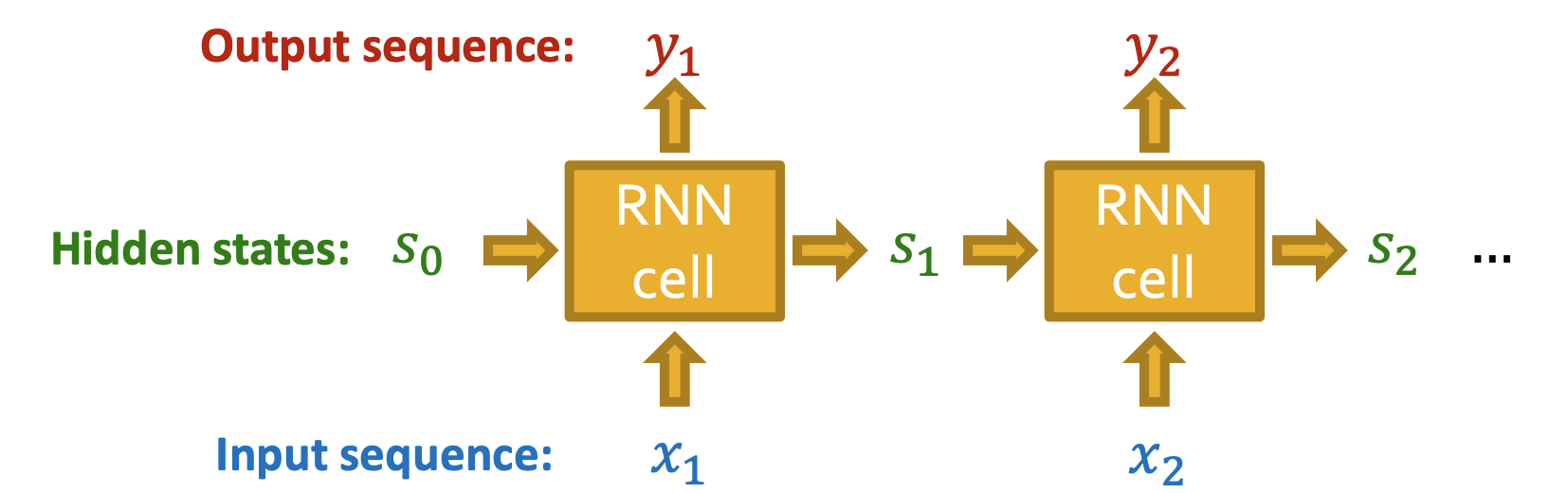
- RNN은 sequential data를 받아 input의 정보를 담고있는 hidden states를 update 한다.
- st,xt,yt는 각각 t step 후에 RNN의 state, t step에서의 input, output을 의미한다.
- W,U,V가 학습되는 parameters라 할 때
st=σ(W⋅xt+U⋅st−1),yt=V⋅st
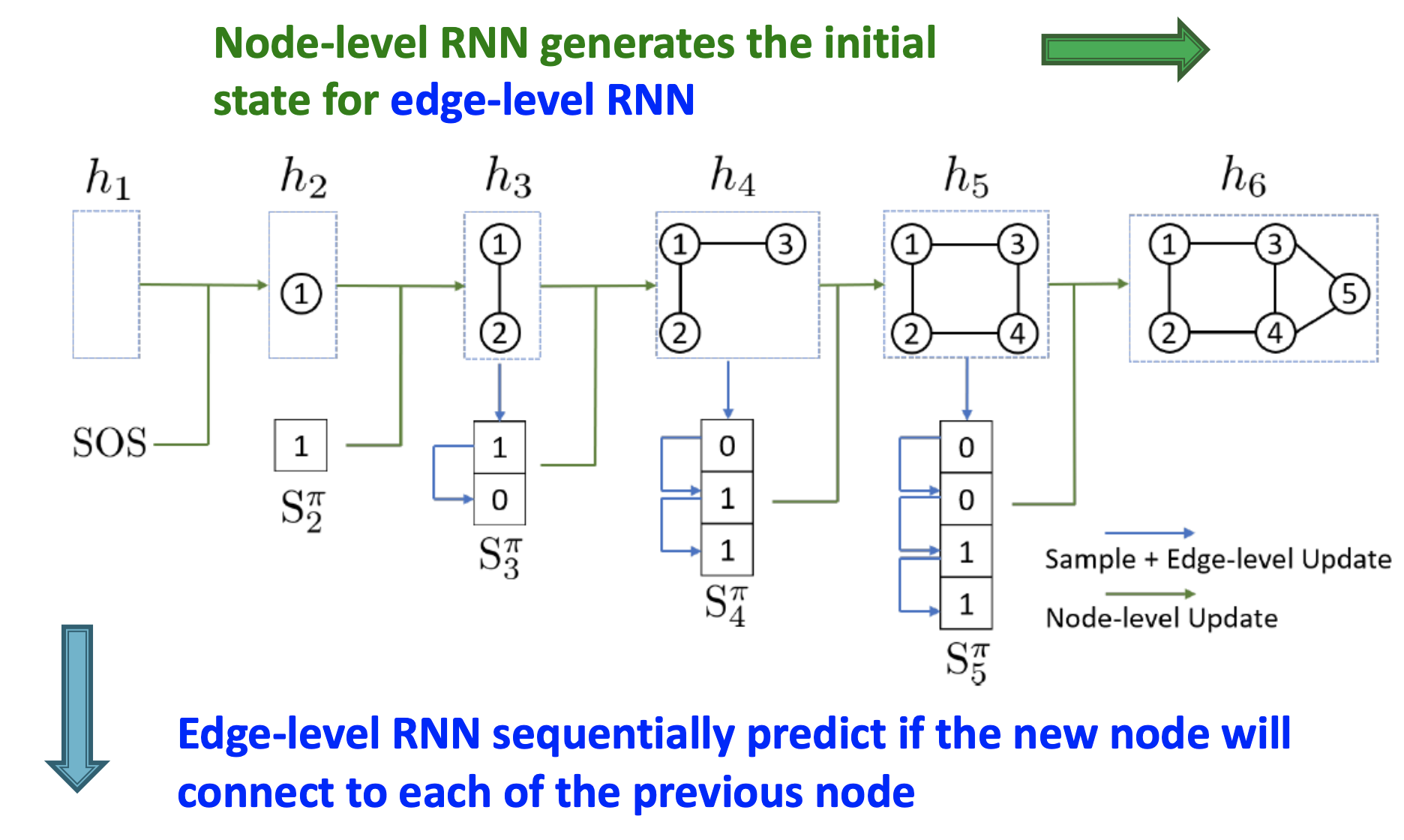
- Node-level RNN은 edge-level RNN을 위한 초기 state를 생성한다.
- Edge-level RNN은 새로운 노드가 이전 노드들에 연결될지 sequential하게 예측한다.
RNN for Sequence Generation
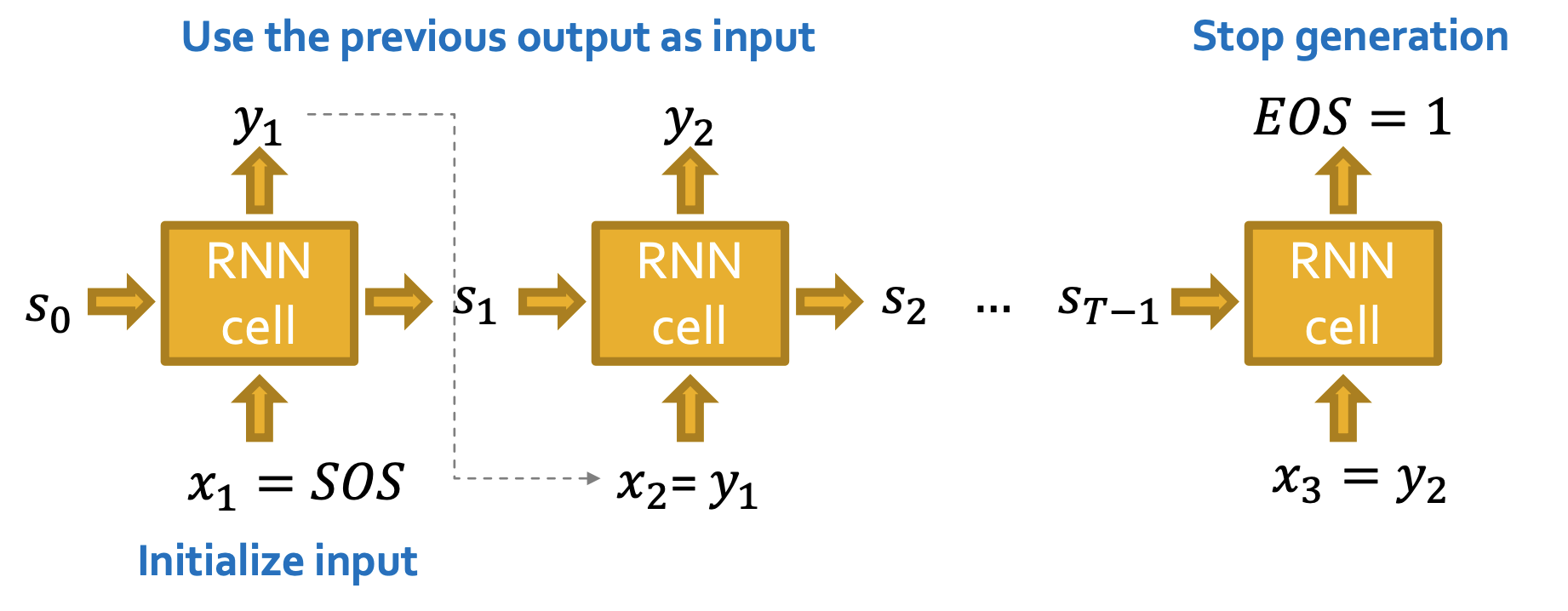
- Auto-regressive model이므로 이전 cell의 output이 다음 cell의 input으로 사용된다.(xt+1=yt)
- 초기 input은 start of sequence token(SOS)으로 일반적으로 영벡터를 사용하며 end of sequence token(EOS)이 1일 될 때 generation을 멈춘다.
- 이러한 방식은 deterministic하여 같은 그래프만 만들게 된다.
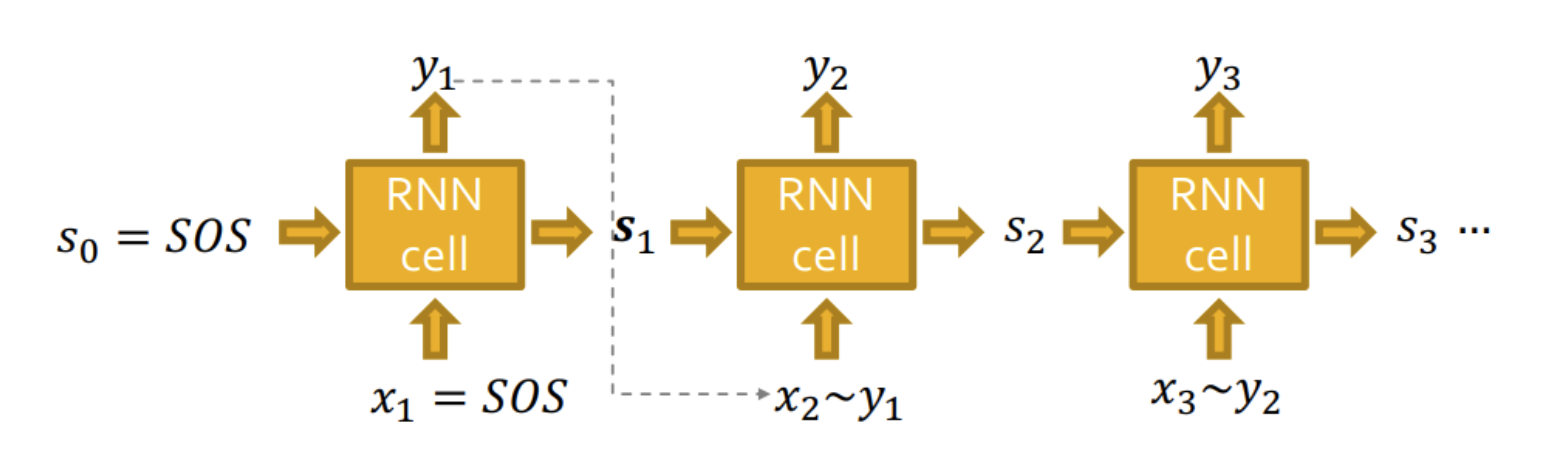
- 따라서R RNN의 output을 single edge에 대한 확률값으로 내주고 이 확률분포yt:xt+1∼yt로부터 샘플링한 xt+1을 다음 cell의 input으로 사용한다.
Put Things Together
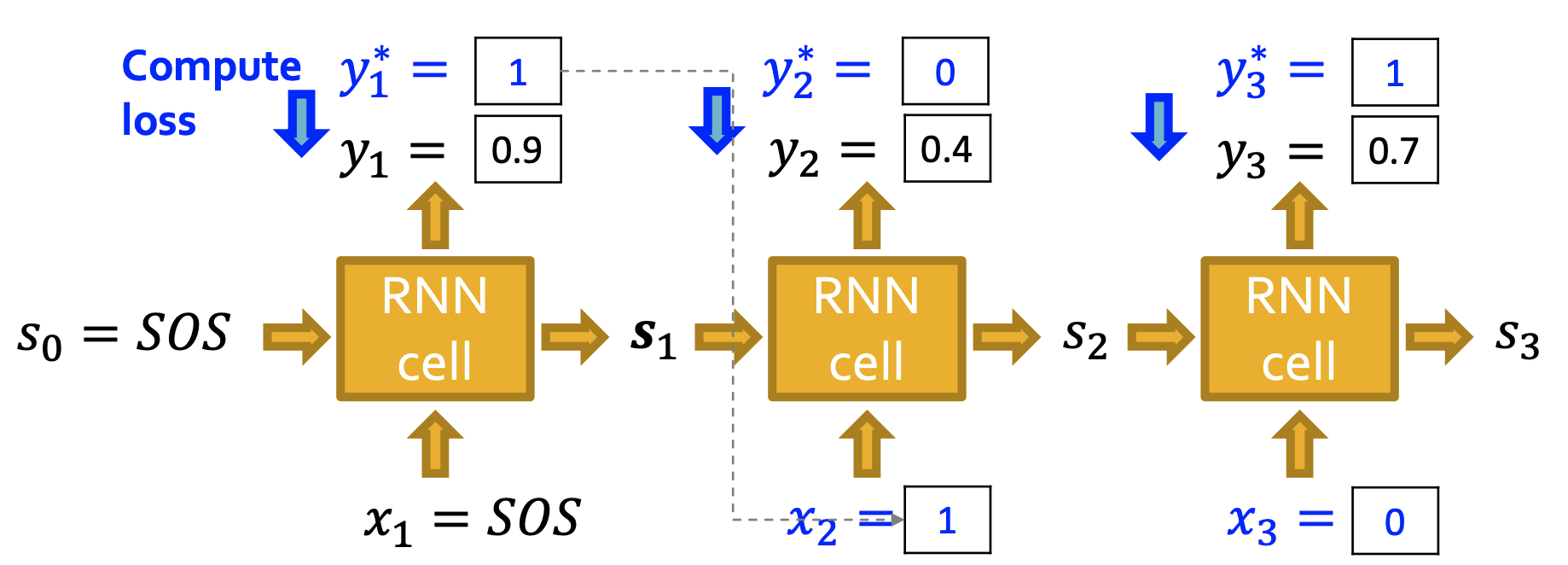
- 정답 라벨 y∗가 있을 때 binary cross entropy를 활용할 수 있다.
- GT를 디코더의 다음 입력으로 넣어주는 teacher forcing 방식을 쓴다.
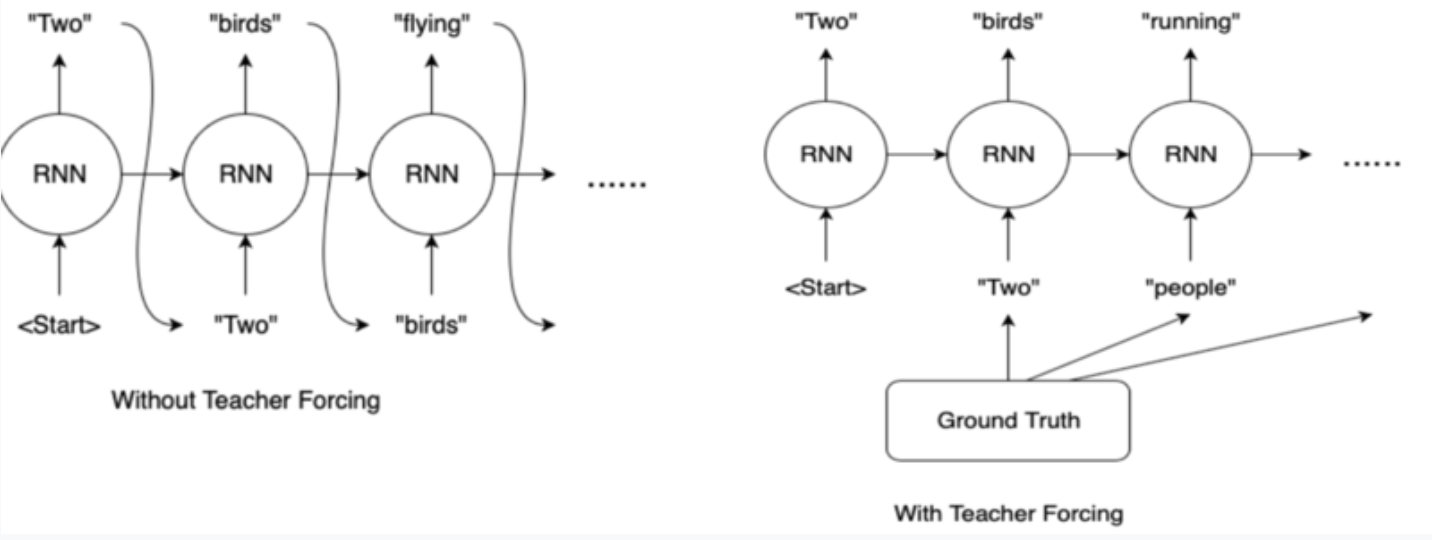
Training process
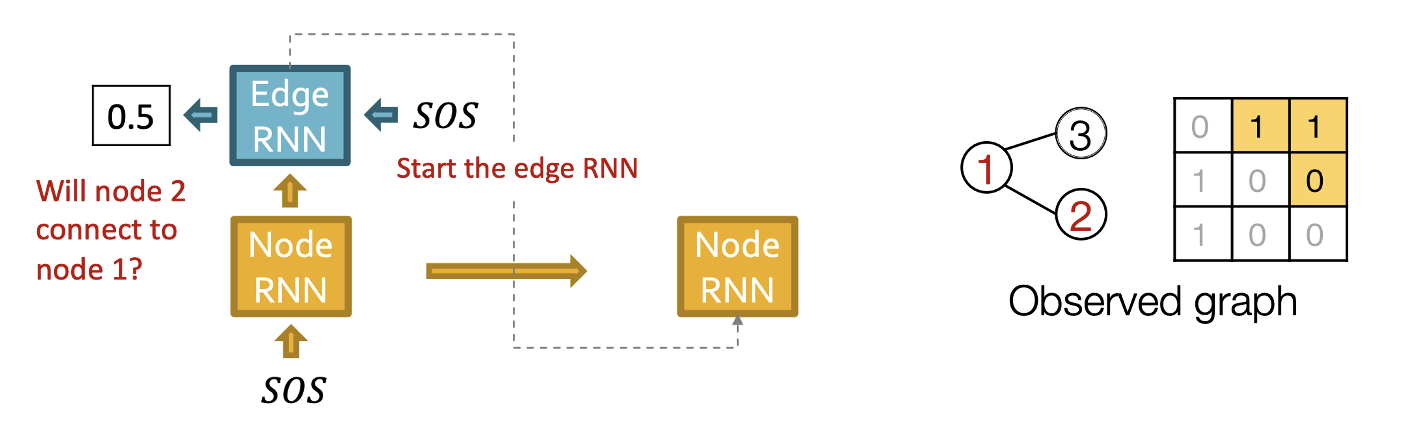
- 먼저 노드1은 있다고 가정하고 노드2를 추가한다.
- 노드와 엣지 모두 SOS 토큰으로 시작하고 출력값으로 0.5가 나왔다.
- Edge RNN의 hidden state를 통해 Node RNN을 update 한다.
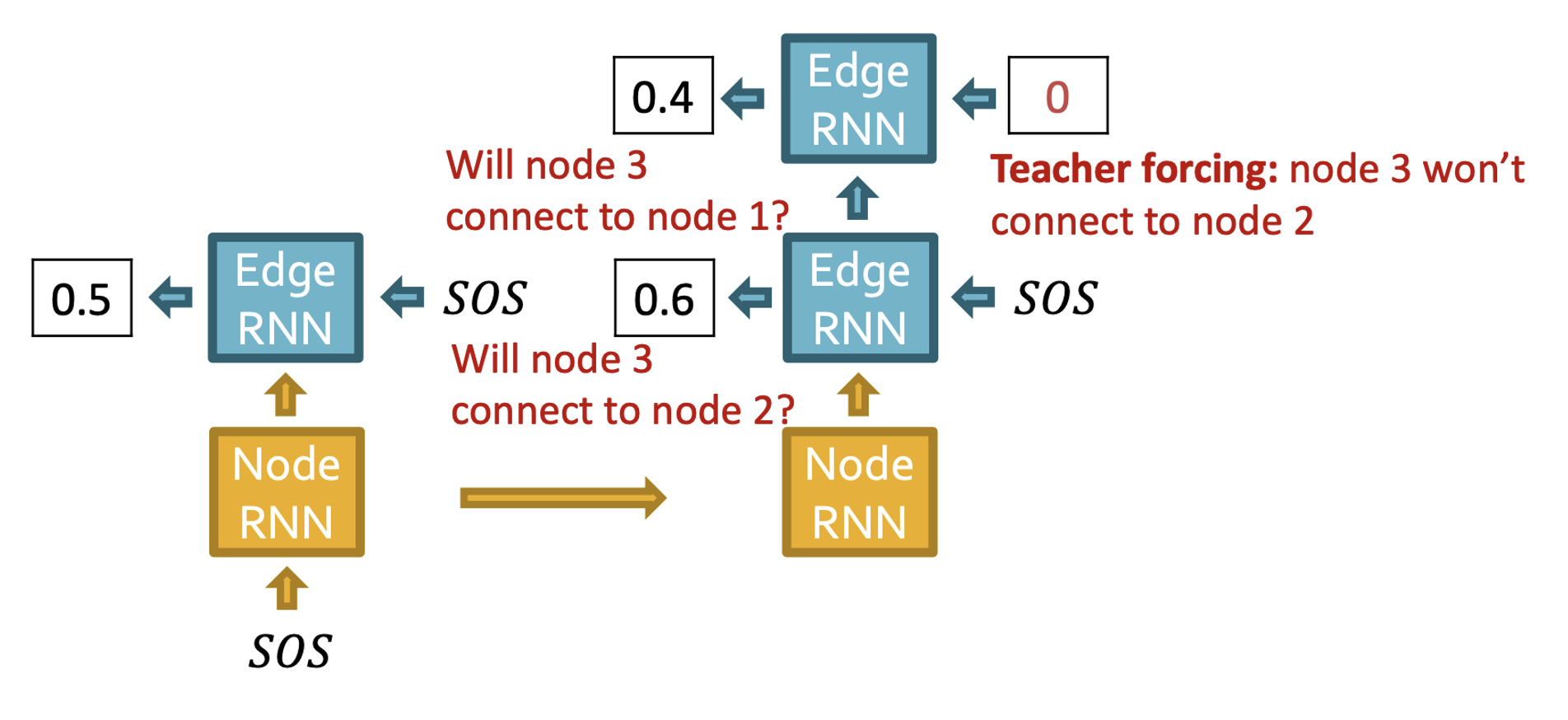
- 노드3이 노드1,2와 연결되어 있는지 예측한다.
- 노드2와의 연결 관계는 0.6으로 예측했지만 teaching forcing에 의해 다음 Edge RNN에는 0이 input으로 들어가 node1과의 연결에 대한 예측은 0.4가 된다.
- 이전 스텝과 마찬가지로 Edge RNN의 hidden state는 Node RNN을 update 한다.
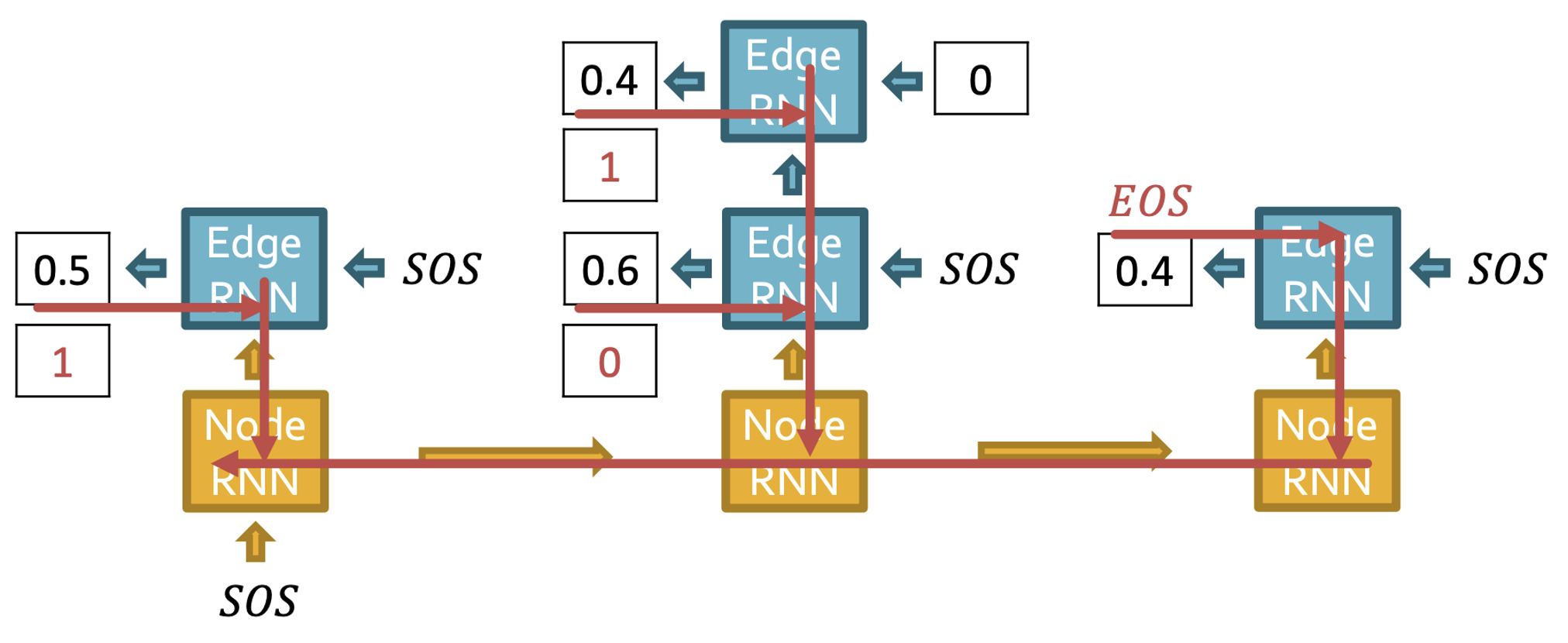
- 노드4는 어떤 노드와도 연결이 없으므로 EOS 토큰과 함께 generation을 멈춘다.
- GT와의 BCE loss로 역전파 하여 파라미터를 업데이트 한다.
Test process
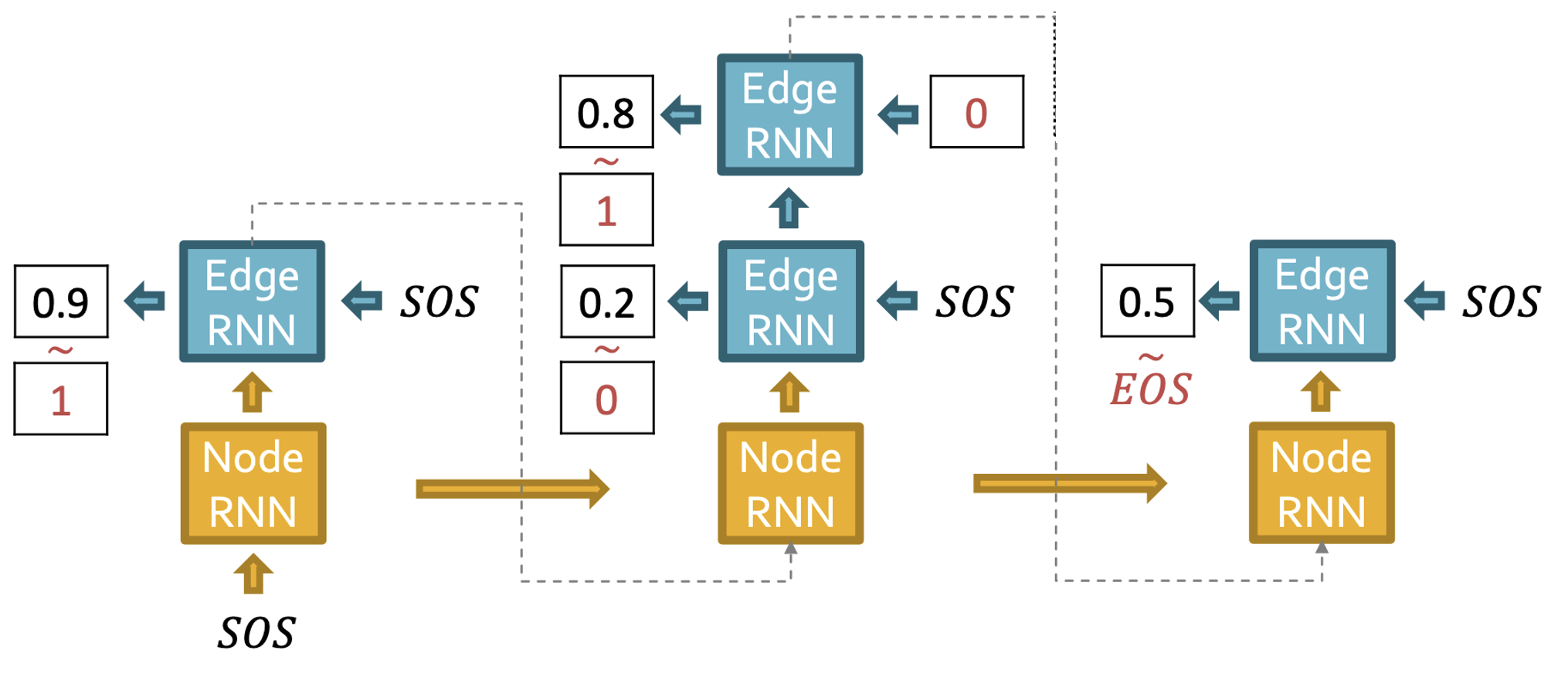
- Output으로 나온 값이 thereshold 이상이면 1, 아니면 0으로 계산한다.
- GT가 없으므로 예측값이 다음 RNN의 input으로 들어간다.
Issue: Tractability

- 모든 노드는 이전 노드들과 연결될 수 있으므로 매우 복잡한 과정을 거쳐야 한다.
- 노드 2가 추가되면 1과의 엣지 확인, 노드3이 추가되면 노드1,2와의 엣지 확인, ...와 같은 형태로 시간복잡도가 O(N!)이 된다.
- BFS를 활용하면 노드1의 이웃노드인 노드2,3을 추가 해주고 그 이후 노드 2,3의 이웃노드인 노드4,5를 추가하게 되는데 이 때 노드4,5는 노드1의 이웃노드가 아님을 이미 확인했으므로 다시 연산할 필요가 없다.
Evaluating Generated Graphs
- Visual similarity: 외관 상 두 그래프가 유사한지 비교한다.
- Statistics similarity: Degree distribution, Clustering coefficient distribution, Orbit count statistics 등을 비교한다.
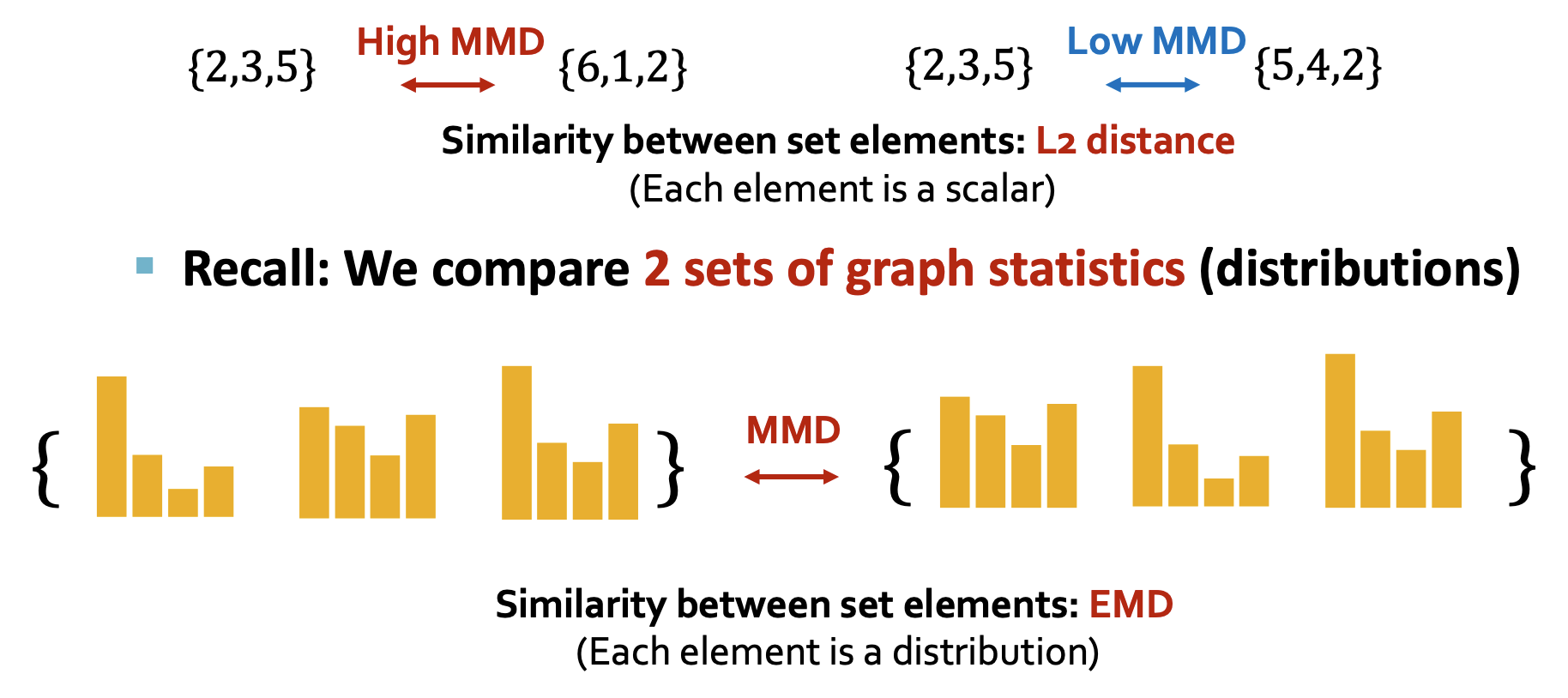
- 분포를 얻으면 두 분포가 같아지기 위한 최소한의 이동을 척도로 삼을 수 있다.
References
