Learning Transferable Visual Models From Natural Language Supervision
Introduction
Huge success in nlp
Auto-Regressive, Masked Language model을 통해 모델이 대규모 데이터 학습이 가능해짐.
"text to text" 발전은 task의 구애받지 않는 zero-shot transfer가 가능해짐. 이러한 발전은 고품질 라벨링 데이터 셋이 아닌 대규모 텍스트 데이터에서 이루어졌다.
그러 나 Computer Vision에서는 Crowd-labeled dataset을 이용해 학습을 진행하고 있다. 웹에서의 텍스트로부터 직접 학습하는 pretraining method가 Computer Vision에서도 효과적인지 확인이 필요함.
- 이전부터 text -> image 방법론은 이전부터 존재했었으나 성능이 좋지 않음.
예를 들어, 2017 visual n-grams의 방식은 ImageNet에서 11.5%의 정확도를 보임.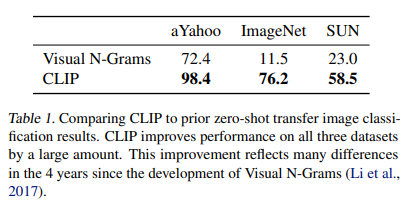
Clip (Contrastive Language-Image Pre-training)
이미지와 텍스트의 학습 규모 격차를 줄이고 natural supervision을 사용하여 대규모로 훈련된 이미지 classifier를 제안함.
인터넷에서 수집한 4억개의 (image-text)쌍의 새로운 데이터 셋을 학습함.
Natural Language Supervision
image-text 쌍의 데이터를 이용해 visual representation을 표현하고자함. => Natural Language Supervision으로 정의
- Crowd-sourced labeling(데이터 라벨링)에 비해 규모를 키우기 쉬움
- vision representation과 language representation을 통해 'zero-shot transfer'가능
Approach
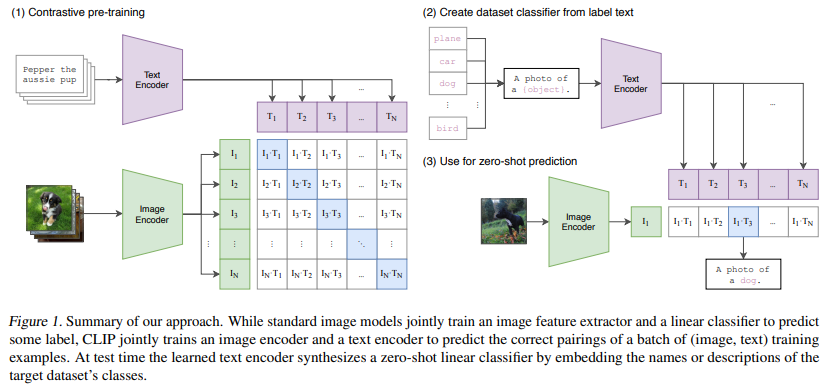
CLIP은 Image Encoder와 Text Encoder를 함께 훈련하여 주어진 (이미지, 텍스트) 쌍이 올바른 매칭인지 예측하도록 학습함. 테스트 시에는 학습된 Text Encoder를 활용하여 대상 데이터의 클래스 이름이나 설명을 임베딩하고, 이를 기반으로 zero-shot 분류기를 생성하여 새로운 태스크에 적용할 수 있음.
CLIP의 핵심 아이디어는 텍스트를 감독 신호로 활용하여 이미지의 인식 능력을 학습하도록 하는 것이다.
이러한 학습 방식 자체는 새로운 개념이 아니며, 연구마다 다른 용어로 불려왔다.
텍스트-이미지 쌍을 활용해 이미지의 시각적 표현을 학습하는 접근 방식은 연구에 따라 비지도 학습(unsupervised), 자기 지도 학습(self-supervised), 약지도 학습(weakly supervised), 지도 학습(supervised) 등으로 다양하게 명명되어 왔다.
CLIP에서는 이러한 방식이 결국 자연어를 학습 신호로 활용하는 것이 핵심이므로, 이를 natural language supervision이라고 부르게 되었다.
natural language supervision의 장점
1️⃣ 확장성이 뛰어남
일반적인 이미지 분류를 위한 crowd-sourced 라벨링보다 자연어 기반 학습을 확장하는 것이 훨씬 용이함
기존 머신러닝에서 요구하는 특정한 주석 없이도 학습 가능
인터넷에 존재하는 방대한 양의 텍스트에서 자연스럽게 학습할 수 있음
2️⃣ Zero-shot 전이 학습이 가능함
자연어 학습을 통해 Representation을 단순히 학습하는 것이 아니라, 다른 언어와 연결할 수 있는 능력까지 갖추게 됨 (word2vec과 유사한 개념)
대부분의 unsupervised이나 semi-supervised 방식보다 Zero-shot Transfer에 훨씬 유리한 장점을 가짐

N개의 (이미지, 텍스트) 쌍이 주어졌을 때, CLIP은 이들 중 실제로 짝을 이루는 쌍을 정확히 예측하도록 사전 학습됨.
쉽게 말하면, 이미지 인코더와 텍스트 인코더를 함께 학습시켜 모든 가능한 N² 개의 조합 중에서 올바른 N개의 쌍을 구별하도록 하는 것임.
이 과정에서:
잘못된 이미지-텍스트 조합(N² - N개)의 코사인 유사도를 낮추고,
정확한 조합(N개)의 코사인 유사도를 높이는 방식으로 멀티모달 임베딩 공간을 학습함.
이렇게 계산된 코사인 유사도는 대칭적 교차 엔트로피 손실(Symmetric Cross Entropy Loss) 을 최적화하는 데 활용됨.
또한, CLIP은 ImageNet의 사전 학습 가중치나 기존의 사전 학습된 모델을 사용하지 않고 처음부터(scratch) 학습함.
CLIP의 학습 과정에서 유일하게 적용된 데이터 증강 기법은 이미지를 크기 조정한 후, 랜덤으로 정사각형 크기로 잘라(cropping) 사용하는 것이 전부임.
모델 선택 및 스케일링 (Choosing and Scaling a Model)
CLIP의 이미지 인코더(Image Encoder) 로는 ResNet-50과 ViT(Vision Transformer) 를 사용함.
기존 모델에서 일부만 약간 수정했을 뿐, 대부분 원형 그대로 유지함.
텍스트 인코더(Text Encoder) 로는 Transformer 를 사용했으며,
8개의 어텐션 헤드(Heads)
12개의 레이어(Layers)
최대 시퀀스 길이(Max Sequence Length) 76 으로 설정함.
CLIP은 텍스트 인코더의 크기 변화에는 비교적 덜 민감하기 때문에,
ResNet의 너비가 확장되는 비율에 맞춰 모델의 너비만 조정하고, 깊이(depth)는 변경하지 않음.
학습 과정 (Training)
CLIP에서는 5가지 ResNet 모델과 3가지 ViT 모델을 훈련함.
각 모델은 총 32 epoch 동안 학습되며, Adam Optimizer(with decoupled weight decay regularization) 를 사용함.
Cosine Schedule 을 적용하여 학습률을 점진적으로 감소시킴.
초기 하이퍼파라미터는 Grid Search + Random Search 조합을 통해 1 epoch마다 탐색하도록 설정됨.
Mini-batch 크기: 32,768
최적화 기법 (Optimization Techniques)
Mixed-precision 학습을 활용하여 학습 속도를 높이고 메모리 사용량을 줄임.
추가적인 메모리 절약을 위해 Gradient Checkpointing, Half-precision Adam Statistics 등을 사용함.
Fully Supervised 방법
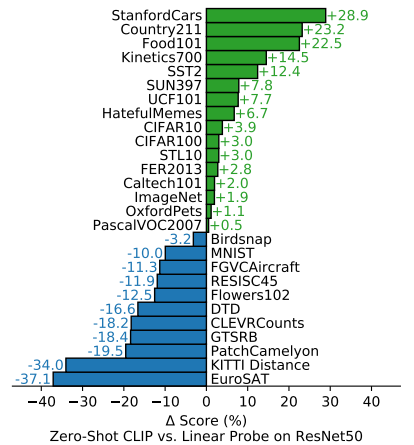
일부 데이터셋에서는 여전히 Fully Supervised 방법이 우세하지만,
EuroSAT과 같이 미세한 디테일(Fine-grained Detail)을 정확하게 구별해야 하는 데이터셋에서는 Zero-shot CLIP의 성능이 부족해 보임.
Few-shot Methods와 Zero-shot CLIP
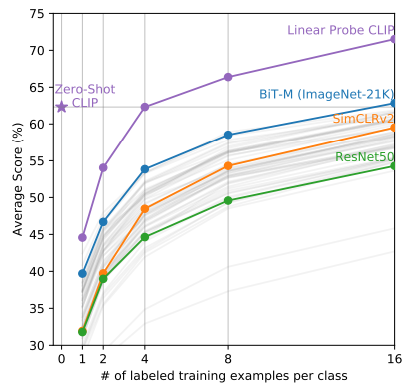
Fully Supervised 방법과 Zero-shot CLIP의 성능이 유사한 점은 상당히 인상적
로지스틱 회귀(Logistic Regression) 분류기가 몇 개의 예제를 학습해야 Zero-shot CLIP의 성능을 따라잡을 수 있는지
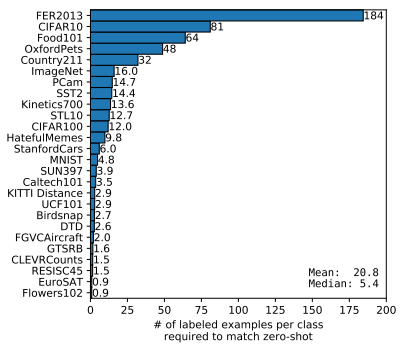
데이터셋마다 차이가 있지만, 일반적으로 수백 개에서 수천 개 정도의 학습 예제(few-shot examples) 가 필요함.
이는 Zero-shot CLIP이 사전 학습된 거대한 자연어-이미지 데이터셋 덕분에 매우 강력한 사전 지식을 갖추고 있음을 보여줌.
즉, CLIP은 추가적인 레이블링 없이도 상당한 성능을 발휘할 수 있으며, 기존의 지도 학습 모델이 이를 따라잡으려면 상당한 수의 예제가 필요함.
ImageNet에 약간의 변형을 준 데이터셋에 대한 성능 비교 자료
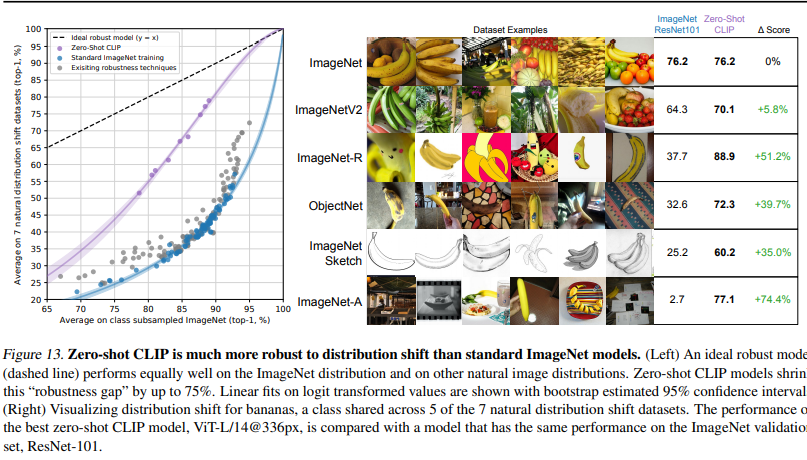
기존 ImageNet과 달리, 스케치 형태의 데이터나 Adversarial Attack이 추가된 형태의 데이터셋들이 포함됨. 이러한 데이터셋에 대해 기존의 ResNet 모델과 CLIP 모델의 Zero-shot 성능을 비교하고 있음.
가장 놀라운 점은 모든 데이터셋에서 CLIP의 Zero-shot 성능이 기존 ResNet보다 우수하다는 것임. 특히 기존 ImageNet의 특성에서 벗어나는 데이터일수록 CLIP이 더 큰 성능 차이를 보인다는 점임. 예를 들어, ImageNet으로 학습한 CNN은 모양을 잘 구별하지 못하고 텍스처에 더 편향되는 경향이 있다는 연구가 있음. 이러한 특성 때문에, ImageNet Sketch 데이터셋에서는 기존 ResNet 모델의 성능이 크게 저하되는 반면, CLIP 모델은 ImageNet에서의 성능과 크게 다르지 않은 성능을 보임.
마찬가지로, Adversarial Attack이 추가된 ImageNet-A 데이터셋에서도 기존 ResNet의 성능은 급격히 떨어지지만, CLIP 모델은 다른 데이터셋과 비슷한 수준의 성능을 유지함.
Robustness-Accuracy trade-off
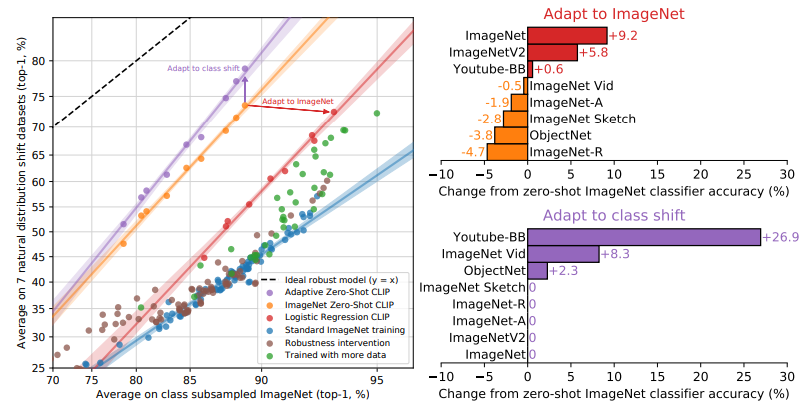
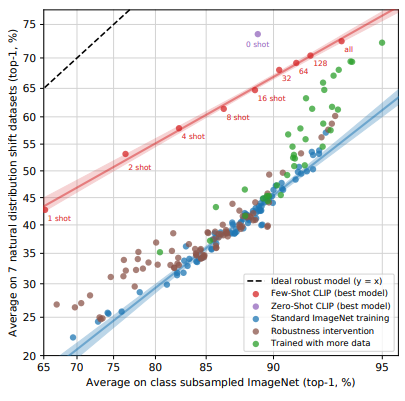
ImageNet 데이터를 사용하여 'adapt'할수록 정확도는 높아지지만, robustness는 떨어지는 경향이 있음을 확인할 수 있음. 이는 모델이 특정 데이터셋에 더 잘 맞춰지면서 그 외의 다양한 상황에 대한 강건성은 떨어질 수 있다는 점을 시사함. 즉, 모델이 특정 태스크에 과적합(overfitting)되면서 더 일반화된 상황에서는 성능이 저하될 수 있음.
마찬가지로, shot 수가 늘어날수록 해당 태스크에 대한 성능은 높아지지만 모델의 generality가 감소하는 경향을 보임. 즉, 더 많은 예제를 학습시키면 특정 문제에 대해 성능이 좋아지지만, 새로운 데이터나 다른 상황에서의 성능은 떨어질 수 있음. 이는 few-shot 학습에서는 모델이 특정 문제에 더 잘 적응하지만, zero-shot과 같은 일반화 능력은 저하될 수 있다는 점을 나타냄.
고민해볼만한 점.
- 대규모 데이터 셋을 학습할 때, 좀 더 정제하여 데이터를 선택했다면? pair가 옳지 못한 경우를 제외..?
- 전이 학습을 진행한다면 general을 유지하면서 specific 능력을 키우기 위한 방법
- fine-grained의 성능을 키우기 위한 방법
출처 : https://arxiv.org/abs/2103.00020
참고 : https://ffighting.net/deep-learning-paper-review/multimodal-model/clip/
참고 : https://seandoprep.tistory.com/3
참고 : https://hyunsooworld.tistory.com/entry/%EC%B5%9C%EB%8C%80%ED%95%9C-%EC%9E%90%EC%84%B8%ED%95%98%EA%B2%8C-%EC%84%A4%EB%AA%85%ED%95%9C-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Learning-Transferable-Visual-Models-From-Natural-Language-Supervision-CLIP-%EB%85%BC%EB%AC%B8-1
🔗 관련 글
