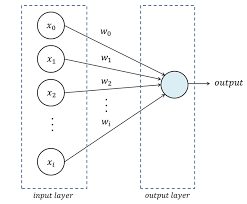
신경망의 사용처
- 모든 머신러닝에 사용될 수 있다.
💡 분류와 회귀를 알아보자- 출력층의 활성화 함수에 따라서 목적( 사용처 )이 달라진다. ( 분류를 할지, 회귀를 할지 )
- 일반적으로 항등 함수( identity function )을 활용하면 회귀
- 또는 시그모이드()를 활용하면 분류
- 시그모이드(): 이진 분류
- 소프트맥스 : 이진, 다중 분류
소프트맥스 함수 구현하기
- : 번째 출력 ( 클래스 번호 ) 0, 1, 2 ,,,
- : 출력층에 있는 뉴런의 연산
- : 전체 클래스의 개수
import numpy as np
z = np.array([0.3, 2.9, 4.0]) # 입력 신호
# 분자 부분 계산
exp_z = np.exp(z)
# 분모 계산
sum_exp_z = np.sum(exp_z) # 모든 입력 신호에 대한 지수 함수의 합
# 소프트 맥스를 적용한 최종 예측 값
y = exp_z / sum_exp_z
print('sotfmax 결과 : {}' .format(y))
~~>
sorfmax 결과 : [0.01821127 0.24519181 0.73659691]
print('softmax 결과의 원소의 총 합 : {}' .format(np.sum(y)))
~~>
softmax 결과의 원소의 총 합 : 1.0👉 전체 합이 1 이기 때문에 각각의 원소를 확률로 생각 할 수 있다.
softmax의 특징
- 어떠한 실수 배열이 softmax를 지나게 되면 그 배열의 총합이 언제나 1.0 이 된다.
- 총 합이 1.0이라는 것의 특징 : 확률로써 설명이 가능하다.
softmax 구현하기
def softmax(a):
# 분자
exp_a = np.exp(a)
# 분모
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
softmax(z)
~~>
array([0.01821127, 0.24519181, 0.73659691])
a = np.array([1010, 1000, 990])
np.exp(a)
~~>
array([inf, inf, inf])👉 지수승 계산이기 때문에 숫자가 조금만 커져도 계산이 불가능해 진다.
소프트맥스 함수 튜닝
- 소프트맥스 함수는 지수 함수를 사용
- 따라서 입력값이 약간만 커져도 굉장히 큰 값을 연산해야 한다.
- 예시
만 되어도 20000 정도임
0이 40개가 넘는 큰 숫자
무한대를 의미하는inf
수학적 기교로 튜닝하기
- 분자 분모에 라는 임의의 정수를 곱한다.
- 를 지수 함수
exp안으로 옮겨서 로 만들어 준다. - 를 이라는 새로운 기호로 만들어 준다.
튜닝된 소프트 맥스
# C 값 구하기 -> C는 어떤 값이 와도 상관은 없으나, 일반적으로는 배열에서 가장 큰 값이 온다.
a = np.array([1010, 1000, 990])
c = np.max(a)
z = a - c
print(z)
print(np.exp(z) / np.sum(np.exp(z)))
~~>
[ 0 -10 -20]
[9.99954600e-01 4.53978686e-05 2.06106005e-09]
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
np.sum(softmax(a))
~~>
1.0출력층의 뉴런 수 정하기
- 출력층의 뉴런 개수는 적절하게 정해줘야 한다.
- 분류 문제에서는 분류하고 싶은 클래스의 개수대로 설정하는 것이 가장 일반적
- 예시
💡 강아지 고양이를 분류하는 모델을 만들고 싶다.
- 클래스의 개수 : 2개
- sigmoid를 쓰려면 뉴련의 개수가 1개
- softmax를 쓰려면 뉴런의 개수가 2개
💡 손글씨 데이터( MNIST )를 분류하는 모델을 만들고 싶다.
- 클래수의 개수 : 10개( 0 ~ 9 까지의 숫자 )
- 출력층의 뉴런을 10개로 설정해야 한다.
- 활성화 함수는 softmax만 사용이 가능하다.
- 시그모이드 함수는 2진 분류에서만 사용이 가능
- 소프트맥스 함수는 2진 분류, 다중 분류에서도 사용이 가능하다. ( 가장 범용적으로 사용이 된다. )
MNIST 손글씨 데이터셋 분류 추론 모델 만들기
- 학습은 하지 않고, 추론( predict )만 하는 모델을 만들어 보기
- ✨
sample_weight.pkl파일에 학습이 완료된 가중치와 편향이 들어 있음
Tensorflow MNIST 데이터 불러오고 형상 다루기
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
# mnist 데이터셋 로딩
from tensorflow.keras import datasets
mnist = datasets.mnist
(x_train, Y_train), (x_test, y_test) = mnist.load_data()
~~>
데이터가 다운로드 된다.
# 데이터의 형상 확인하기
x_train.shape
~~>
(60000, 28, 28)(N, H, W, C)
- 60000 : 이미지의 개수(N)
- 28 : H 값, W 값
- C 값이 없기 때문에 흑백 이미지인것을 유추할 수 있다.
y_train.shape
~~>
(60000, )💡 One Hot Encoding 이 되어있었다면 y_train의 shape은??
y_train[:3] # one hot encoding이 안되어 있는 상태
~~>
array([5, 0, 4], dtype=uint8)
y_train_one_hot = tf.one_hot(y_train, 10) # 10 : 숫자가 10개이기 때문에
print(y_train_one_hot.shape)
print(y_train_one_hot[:3])
~~>
(60000, 10)
tf.Tensor(
[[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]], shape=(3, 10), dtype=float32)👉 (60000, 10) 이 된다.
데이터 확인하기
- 이미지 데이터는 이미지를 표시하는 것
# 첫 번째 이미지 데이터 가져와서 시각화로 확인하기
image = x_train[0]
image.shape
~~>
(28, 28)C( Channel ) 데이터가 없기 때문에 grayscale( 흑백채널 ) 이미지라는 것을 알 수 있다.
# matplotlib을 이용한 이미지 시각화
plt.imshow(image, 'gray')
plt.title(y_train[0])
plt.show()
~~>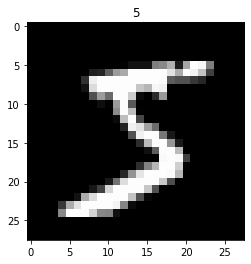
✨ 데이터를 신경망에 집어 넣을 준비
- 훈련과 학습, 테스트 모두 동일한 데이터의 shape을 가져야 한다.
- 각 데이터를 모두 1차원 형식으로 집어넣어야 한다.
- 하나의 데이터를 1차원 배열( 벡터 )로 받는 신경망
- 신경망 : Dense Layer( 신경망 기술적인 표현으로 이야기 할 때 )
- 기하학 : Affine Transformation( Affine Layer )
- 종합적 : Fully Connected Layer - 완전 연결 계층이란 표현으로 많이 사용
✨ 신경망에 1장의 이미지 데이터를 입력할 수 있는 경우 확인하기 - shape을 확인하기
- 몇 장인지에 대한 정보 없이 가로 픽셀, 세로 픽셀만 있는 상황 :
(28, 28)-> 2차원이기 때문에 데이터를 집어넣을 수 없다. - 몇 장인지에 대한 정보 없이 이미지 정보를 평탄화 한 상황 :
(784, )-> 평탄화를 통해 1차원이 되었기 때문에 데이터를 집어넣을 수 있다.
✨ 신경망에 N장의 이미지 데이터를 입력할 수 있느 경우 확인하기
- 몇 장인지에 대한 정보가 존재하는 형태로 가로 픽셀, 세로 픽셀의 정보가 있는 상황 :
(N, 28, 28)-> 3차원이기 때문에 데이터를 넣을 수 없다. - 몇 장인지에 대한 정보가 존재하는 형태로 이미지 정보를 이미지 정보를 평탄화 한 상황 :
(784, )-> 평탄화를 통해 1차원이 되었기 때문에 넣을 수 있다.
✨ 결론적으로 입력되는 데이터의 차원이 ( N, M )이면 ( F.C 레이어 )에 집어 넣을 수 있다.
N: 데이터의 개수 ( N장의 이미지 )M: 데이터 스칼라의 개수
✨ 참고로 CNN은 Fully Connected Layer가 아니고, 특징 추출( Feature Extraction )이라는 과정으로써, 단순한 2차원 데이터가 아닌 ( N, H, W, C )가 입력 데이터의 모양이 된다.
신경망에 들어가는 형태로 이미지 배열 편집하기
1. Flatten()을 활용한 평탄화
image = x_train[0].flatten()
image.shape
~~>
(784, )2. ravel()을 이용한 평탄화
image = np.ravel(x_train[0])
image.shape
~~>
(784, )ravel()을 활용한 평탄화는 잘 사용되지 않는다.
👉 원본 이미지 데이터에 훼손이 우려되기 때문에
3.reshape()을 활용한 평탄화
- 원하는 방식으로 자유롭게 바꾸고자 할 때 사용할 수 있다.
- reshape을 활용하면 데이터의 개수까지 한꺼번에 고려하면서 평탄화를 시킬 수가 있다.
- ( N, M ) 형식을 만들기가 편하다.
- 제일 많이 사용되는 방법
- Tensorflow에서 flattn() 레이어가 reshape 평탄화와 비슷한 역할을 해준다.
image = x_train[0].reshape(-1)
image.shape
~~>
(784, )평탄화된 이미지를 원래대로 복구
image_bokgu = image.reshape(28, 28)
plt.imshow(image_bokgu, 'gray')
plt.show()
~~>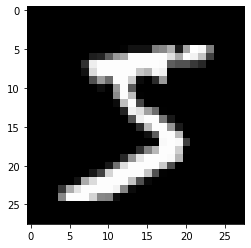
여러 장의 이미지를 reshape을 활용해서 한꺼번에 평탄화 하기
x_train.shape
~~>
(60000, 28, 28)
x_train_reshaped = x_train.reshape(60000, -1)
x_train_reshaped.shape
~~>
(60000, 784)💡 개발자 적인 방법을 이용한다면 ... 상수값을 그대로 쓰는 것을 지양
image_count = x_train.shape[0] # 이미지 개수를 가져오기
x_train_reshaped = x_train.reshape(image_count, -1)
x_train_reshaped.shape
~~>
(60000, 784)MNIST 신경망 만들기 - F.C.L
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def get_test_data():
# 테스트 데이터만 가져오기
-, (x_test, y_test) = mnist.load_data()
image_count = x_test.shape[0] # 이미지 개수 ( x_test.shape -> (10000, 28, 28)
x_test_reshape = x_test.reshape(image_count, -1)
return x_test_reshaped, y_test
# 이미 학습이 완료된 신경망 매개변수( W, b ) 가져오기 sample_weight.pkl
def init_network():
import pickle
with open('./sample_weight.pkl', 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
# network는 dict
# network에 각 매개변수가 들어 있다.
# W1, W2, W3 => 가중치
# b1, b2, b3 => 편향
Z1 = np.dot(x, network['W1']) + network['b1']
A1 = sigmoid(Z1)
Z2 = np.dot(A1, network['W2']) + network['b2']
A2 = sigmoid(Z2)
Z3 = np.dot(A2, network['W3']) + network['b3']
y = softmax(Z3)
return y
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1. b2, b3 = network['b1'], network['b2'], network['b3']
W1.shape, W2.shape, W3.shape
~~>
((784, 50), (50, 100), (100, 10))
network = init_network()
x, y = get_test_data()
pred_result = predict(network, x[0])
np.argmax(pred_result)
~~>
7
plt.imshow(x[0].reshape(28, 28), 'gray')
plt.show()
~~>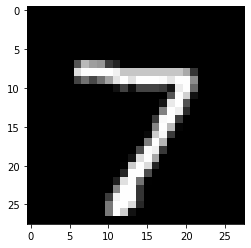
y_test[0]
~~>
7x_test[0]은 7의 모양을 하고 있는 이미지
test_image = x_test[0]
test_image.shape
~~>
(28, 28)
plt.title(y_test[0])
plt.imshow(test_image, 'gray')
plt.show()
~~>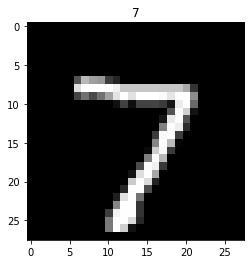
위의 코드는 정답 확인용 코드
예측하기
pred_image = x_test[0]
# predict를 할 수 있는 모양으로 만들어 주기
pred_image_reshaped = pred_image.reshape(-1)
pred_image_reshaped.shape
~~>
(784, )
pred_result = predict(network, pred_image_reshaped)
pred_result
~~>
array([4.2879005e-06, 4.5729317e-07, 1.8486280e-04, 8.3605024e-05,
1.5084674e-07, 6.3182205e-07, 4.5782045e-10, 9.9919468e-01,
3.8066935e-07, 5.3083024e-04], dtype=float32)✨ softmax 결과물에서 제일 높은 값의 인덱스가 이 신경망이 예측한 클래스가 된다.
# np.argmax 함수를 이용하면 배열에서 가장 큰 값을 가지고 있는 인덱스를 리턴
np.argmax(pred_result)
~~>
7pred_image는 7의 모양을 한 이미지y_test[0]은pred_image의 정답.7pred_result는pred_image의 softmax 결과물np.argmax( pred_result )를 이용하여 가장 확률이 높은 인덱스를 확인해 보니 : 7- 즉 예측이 잘 되었다고 할 수 있다.
배치( BATCH )
- 배치란 데이터의 묶음
- 일반 배치
- 데이터를 순서대로 묶은 것
- 데이터가 모자라거나 적당하게 모아낸 경우
- 미니 배치
- 데이터를 랜덤하게 뽑아서 묶은 것
- 빅데이터 같은 데이터의 양( Data Volume )이 엄청나게 큰 경우
- 엄청나게 많은 데이터를 모두 사용해서 훈련을 한다면 시간이 매우 많이 걸림
- 랜덤하게 몇 개의 데이터를 선정해서 훈련
배치를 사용하지 않고, 전체 테스트 데이터에 대한 정확도를 확인
x, y = get_test_data()
network = init_network()
accuracy_count = 0 # 정답을 맞춘 개수를 저장
total_count = x.shape[0] # 전체 데이터의 개수
for i in range(len(x)):
pred = predict(network, x[i]) # pred의 shape : 1개씩 10개로의 예측을 했으니까 (10, )
pred = np.argmax(pred) # 확률이 가장 높은 원소의 인덱스
# 예측한 것과 정답이 같으면
accuracy_count += (pred == y[i]) # True면 1이 accuracy_count에 더해지고, False면 0이 더해진다.
print(float(accuracy_count / len(x)))
~~>
0.9207👉 위 코드의 단점
- 10,000장의 이미지를 한장씩 예측하고 있다.
- 시간이 오래걸릴 수 밖에 없다.
💡 해결 방법
- 배치( BATCH )를 사용해서 한장씩이 아닌, 데이터의 묶음으로 예측을 하게 하겠다.
x, y = get_test_data()
network = init_network()
batch_size = 100 # batch_size : 1 배치당 들어있어야 하는 데이터의 개수
# ㄴ ex) 60,000개의 데이터를 batch_size 100으로 묶으면 몇 개의 배치가 만들어 질까? -> 600개의 배치가 만들어 진다.
accuracy_count = 0
# batch를 활용한 예측 구현
for i in range(0, len(x), batch_size):
x_batch = x[i : i+batch_size]
pred_batch = np.argmax(pred_batch, axis=1)
accuracy_count += np.sum(pred_batch == y[i : i+batch_size])
# pred_batch의 shape : (100, 10) 100장의 이미지에 대한 각각의 10개씩 예측 결과
# argmax를 사용해서 100장의 이미지에서 각각 가장 높은 확률이 들어있는 인덱스를 추출
print(float(accuracy_count / len(x)))
~~>
0.9207✨ np.argmax의 axis가 1인 이유
- softmax의 결과는 10개의 원소( 결과물 )를 가진 1차원 배열
- 그런데, 이 결과물이 100개씩 묶음 지어져 있다. (왜? 배치로 100장씩 묶어놓았으니깐 100개씩 10개의 결과물이 있는 것)
- 따라서
np.argmax의axis를 스칼라가 추가되는 방향인 1로 줘야지만 각 이미지별 최댓값의 인덱스를 구할 수 있다. axis=0은 1차원 배열이 추가되는 이미지 장수에 대한 방향이기 때문에
