알고리즘 기법
1.재귀함수
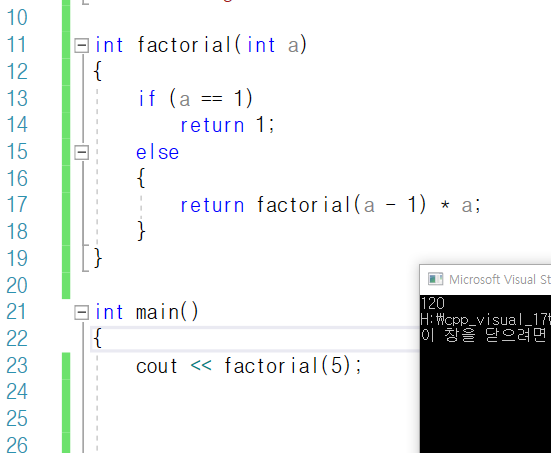
언제 사용할까? : 큰 문제를 작은 문제로 나뉠 경우,
2.알고리즘 종류 정리

dfs :
3.dfs를 활용법
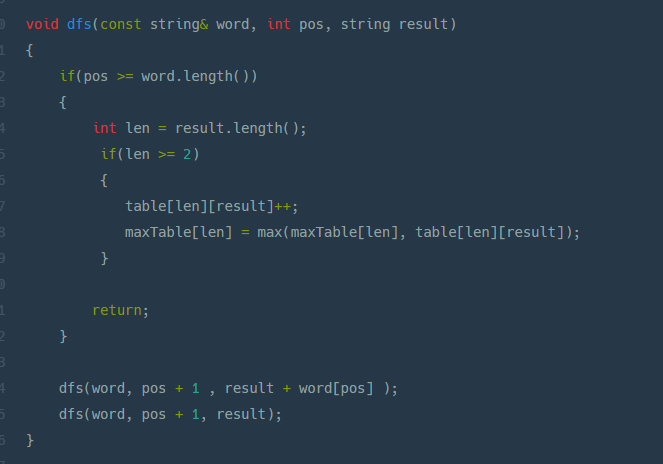
컨테이너의 값이 (1,2,3,4)값을 (사용, 사용 , 사용, 사용 안함.)이럴 경우에 dfs를 사용할 수 있다.dfs(vectorv, int index, int sum + vindex)관련 문제1-1) 프로그래머스의 타겟 넘버https://programmer
4.bfs에서 visited 변수에 대해
bfs로 접근할때 불변수를 이용해 사용유무를 확인하는데, 그렇지 않은 경우도 있다. 예시 : 이코테의 미로탈출, 프로그래머스의 게임 맵 최단 거리가 이에 해당한다. 어떻게 구별할 수 있냐면 컨테이너의 값이 접근할 수 있는 수와 접근할 수 없는 수로 제한되어 있을 경우에
5.알고리즘 필수 기법들
dfsbfsdpTriesortpriority Queue 정렬LIS다익스트라에이스타 이진검색string 잘 사용하기 플로이드워셜비트마스킹오름차순으로 정렬 후에 동일한 갯수 새기 lower_bound , upper_bound투포인터 : 2개의 지점을 이용해 특정 범위에서
6.mapping을 배열이나 벡터 형식으로 사용하는 문제의 경우
프로그래머스 n으로 표현카카오 메뉴 리뉴얼 프로그래머스 여행경로=> 왜 배열로 사용하냐면 자릿수나, 갯수에 따라 저장을 한 상태에서 그 인덱스에 저장된 key-value값을 활용하고자 할때 사용한다.
7.분수 만들때 주의할 점에 대해서 -> 카카오 실패율
분모는 반드시 0이 되면 안된다는 것을 인지해두고 분수를 만들어야 한다.
8.🤔비트마스킹!!_ 핵심 개념.
ezsw님의 c++ 비트와 부분집합을 공부하고 정리한 내용입니다. : {공집합}, {a} , {b} {c} {d} {a,b} {a,c} {a,d} {b, c} {b, d} {c, d} {a,b,c} {a,b,d} {a, c,d} {b, c, d} {a,b,c,d}=>
9.이진 탐색

1) 탐색범위가 엄청나게 많을 경우 / 1000만 단위 이상의 데이터일 때2) 정렬시킬수 있거나, 정렬되어 있을때이진탐색은 코딩테스트에서 빈번하게 나오므로, 외우도록 하자.
10.오름차순으로 정렬된 상태에서 원소의 갯수를 알고 싶을때
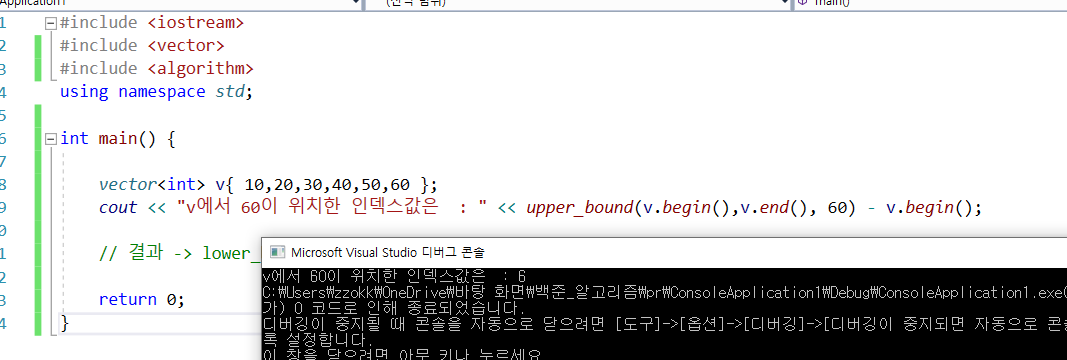
참고 자료 : https://chanhuiseok.github.io/posts/algo-55/오름차순이 되어 있는 상태에서 가능하다. 시간복잡도는 Log(n): 타겟으로 잡은 값을 컨테이너 중 시작원소의 반복자를 반환 받는다.: 타겟으로 잡은 값을 컨테이너 중
11.string- 소문자, 대문자 변환
https://blog.naver.com/kimwontae466/222424918646
12.다이나믹 프로그래밍

: 언제 사용할까??한번 해결한 문제를 다시 해결하고 싶지 않을때 사용한다. 1\. 큰 문제를 해결하기 위해 작은 문제로 나뉠때2\. 동일한 작은 문제를 반복적으로 해결해야 할때메모이제이션을 이용하자. : 한번 계산된 결과를 메모리 공간에 메모하는 기법이다.같은 문제가
13.🎅 중요! find : 알고리즘 vs string 다름...
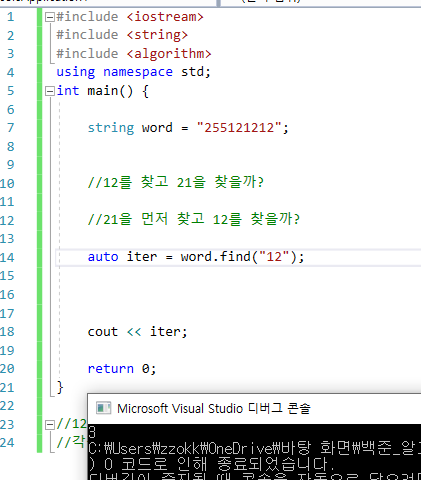
변수에 find를 통해 end() 값 비교를 통해 검색이 가능하다. 변수에 find함수 사용 못하므로 iter를 통해 진행하자. auto iter = find(v.begin(), v.end(), target);iter != end() 이렇게 관련문제 : 카카오 2018
14.LIS : 가장 긴 증가하는 부분 수열

ㅇㅇㅇ
15.이분탐색으로 특정 조건의 개수 구하기.
lower_bound
16.다익스트라_우선순위 큐 비교 연산자
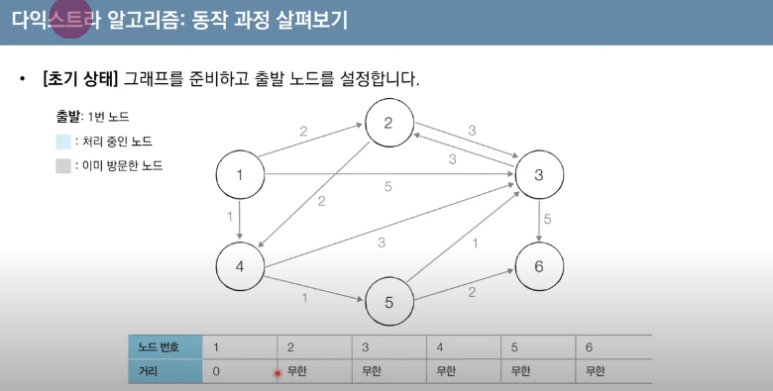
인프런의 김태원 강사님의 강의를 공부하고 정리한 내용입니다. 이것이 코딩테스트다를 공부하고 정리한 내용입니다. 1) 시작점을 0으로 놓고, 나머지 정점들을 모두 무한대 값으로 설정한다.2) 정점 중 체크 안된 정점 중에서 값이 가장 작은 놈을 체크 후, 해당 정점으로부
17.정렬, 쌍으로 가져가는 pair
https://m.blog.naver.com/oyh951416/222001614292
18.제곱근과 제곱구하기
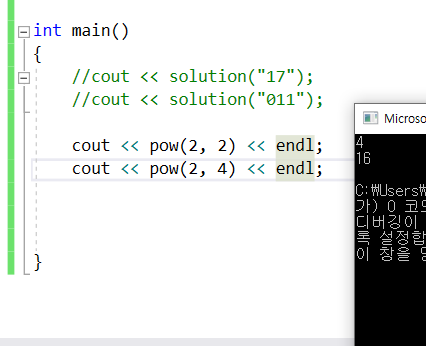
제곱과 제곱근 구하기에 앞서서 cmath 헤더 파일이 필요하다.
19.언제 bfs vs dfs쓸까?
최단 거리를 구해야 할 때는 bfs로 풀자모든 정점을 확인해야 할때는 dfs로 풀자.
20.🔥to_string stoi, stoll, atoi 숫자인지 문자인지
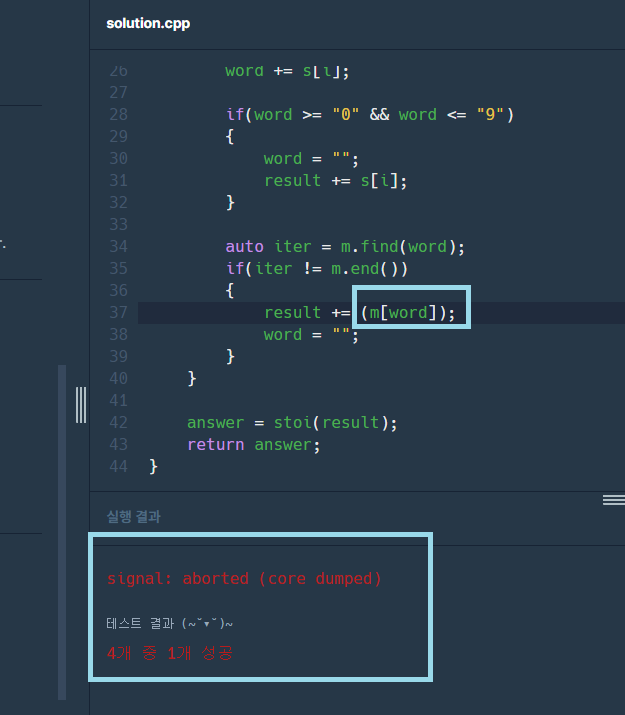
string word = to_string(int i)int a = stoi(string word);
21.투포인터

푸는 방법 2가지 모두 알아야 함...
22.Trie 기법 - 카카오 가사 검색
카카오 2020 가사 검색 문제\-> string으로 접근하면 부분 점수 나온다.프로그래머스 : 전화번호 목록
23.😘플로이드 와샬
: 모든 정점에서 모든 정점까지의 최소 거리를 알아야 할 경우에 사용된다. 다익스트라는 하나의 정점을 기준으로 다른 모든 정점까지의 최소거리를 구하는 것이다. 이차원 배열을 사용하자. 초기값은 어마어마 하게 큰값으로 , 팁으로는 비용 \* 모든 간선의 값이다.자기 자신
24.count 함수
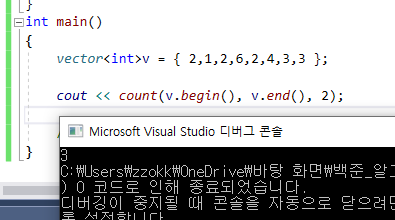
: 특정 범위 중에서 일치하는 값의 개수를 추출하는 함수이다.
25.ranged_base for문으로 컨테이너의 내부값 변경하려고 할때
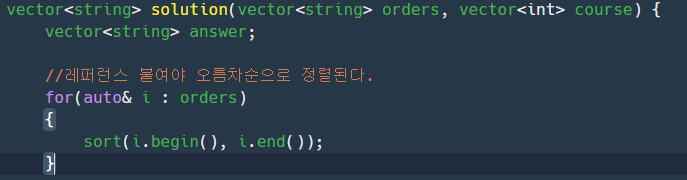
: 레퍼런스 안붙이면 정렬 적용이 되지 않는다.
26.묶음으로 컨테이너에 저장하려고 할때
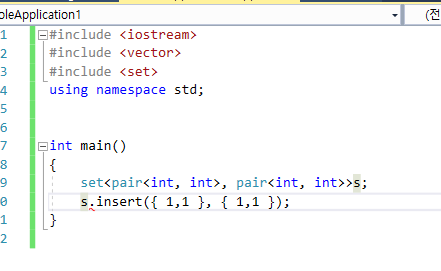
pair나 tuple을 사용하자. 근데 잘 사용해야 한다. pair로 사용할 경우 tuple로 사용할 경우
27.tuple 사용할때
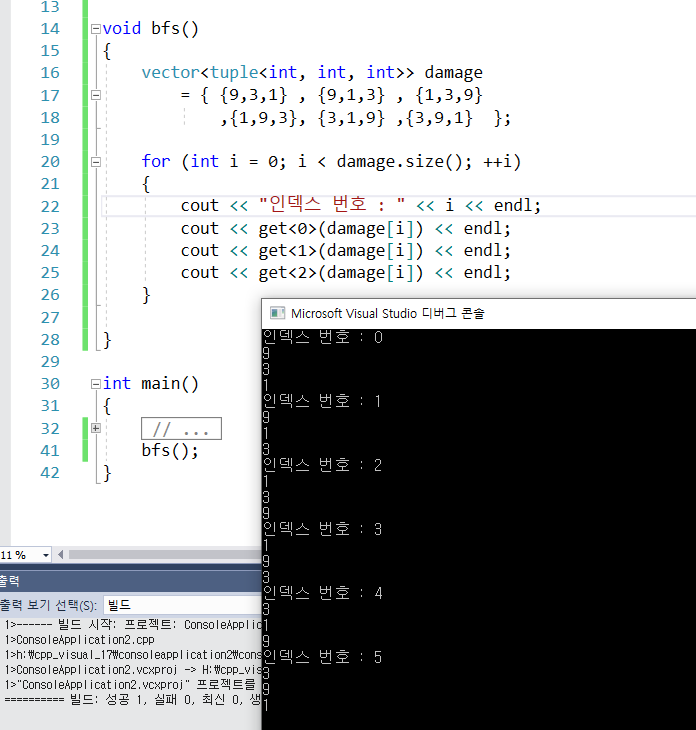
tuple 헤더 필요하다!관련문제 : 프로그래머스 방문길이
28.sort 함수 vs 우선순위 큐 일반 타입, pair 타입 처리하기
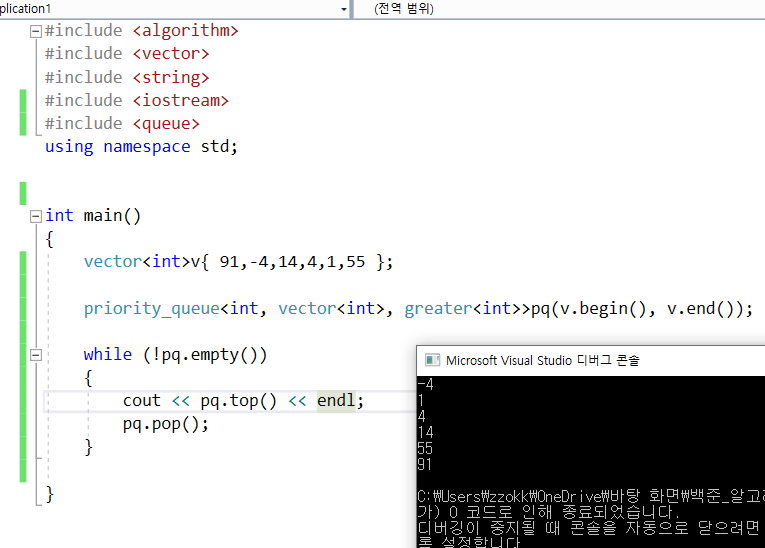
참고 자료: 뇌를 자극하는 stl 페이지 82less는 < 연산자의 함수 객체이다.greater는 > 연산자의 함수 객체이다. 따라서 less는 뒤로 갈수록 요소의 값이 커지게되고,greater는 앞으로 갈수록 요소의 값이 커지는 것이다.: 위의 함수객체를 그대로
29.string을 저장하는 방법
https://blog.naver.com/kimwontae466/222437302048
30.구간합 구하기

https://www.acmicpc.net/problem/11659그냥 합을 구해버리면 작은 범위값은 문제가 없으나,,제한 사항에서 이므로 시간복잡도는 10만 \* 10만이다. 1 ≤ N ≤ 100,0001 ≤ M ≤ 100,0001 ≤ i ≤ j ≤ N\->
31.누적합

: 2022 카카오 6번 문제\-> 효율성 틀렸다...: 백준 2167번 2차원 배열의 합
32.260523_백트래킹
네이버 블로그로
33.최대값과 최소값 함수
https://blog.naver.com/kimwontae466/222406129420
34.입출력양이 많을 때는
ios::sync_with_stdio(false); cin.tie(0);를 main실행 후에 작성하자!
35.벡터의 외적
: 방향벡터를 이용해 왼쪽에 있는지 오른쪽에 있는지 알 수 있다. u = (uX, uY, uZ) / v = (vX, vY, vZ)일 때 : x좌표에서는 x값을 뺀상태에서 곱하고 빼기 , 한 칸 밀고y좌표에서는 y값 뺀 상태에서 곱하고 빼기w = u x v = (uYvZ
36.벡터의 뺄셈
: 방향벡터를 구할 수 있다. 시작점 a, 타겟지점이 b 일 때 b- a를 하게 되면 a가 b로 향하는 방향벡터를 구할 수 잇다.
37.공백 없이 입력되는 데이터 딱 하나만 받기
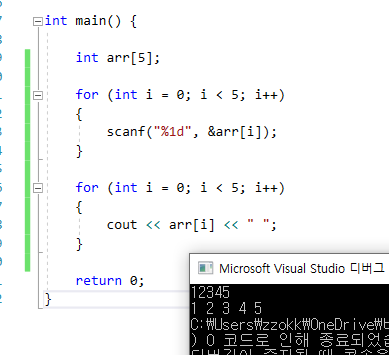
scanf를 사용하자!
38.시간 복잡도
시간복잡도 : 알고리즘을 위해 필요한 연산의 횟수 공간복잡도 : 알고리즘을 위해 필요한 메모리의 양
39.erase : vector, map 에서 사용할 때
\-> begin과 인덱스로 접근해 지우자
40.문자열의 시작주소값을 반환하는 c_str()
사용
41.2차원 벡터 , resize
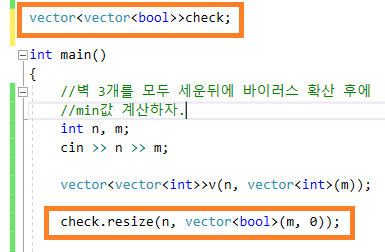
전역변수로 사용하는 2차원 벡터의 크기를 할당할 경우 \-> resize를 이용하자.
42.순차열 뒤집기 : reverse
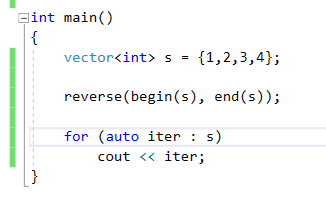
순차열 뒤집기 : reverse 알고리즘을 사용하자. 업로드중..
43.vector의 reserve와 push_back 관계
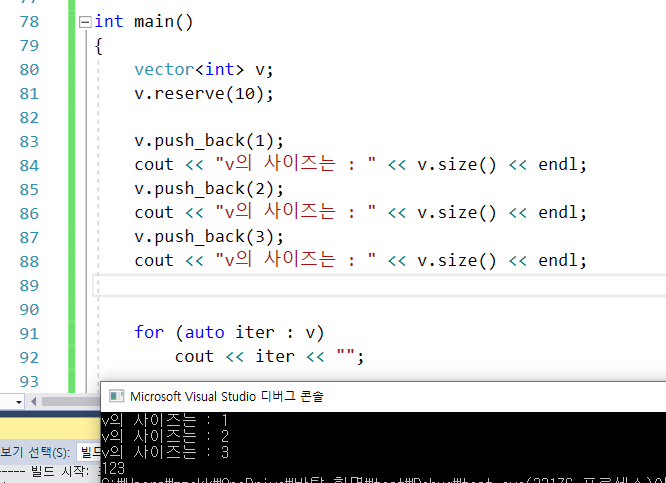
: reserve를 한 것은 용량 : capacity를 확보만 한것임. // 원소를 추가한게 아님push_back을 하면 원소를 추가하면서 size를 증대함. \-> 실제 원소 삽입. but capacity이하일 경우 용량 증대는 없음
44.map 동일한 키값으로, value 연속저장, vector 컨테이너 따로 저장
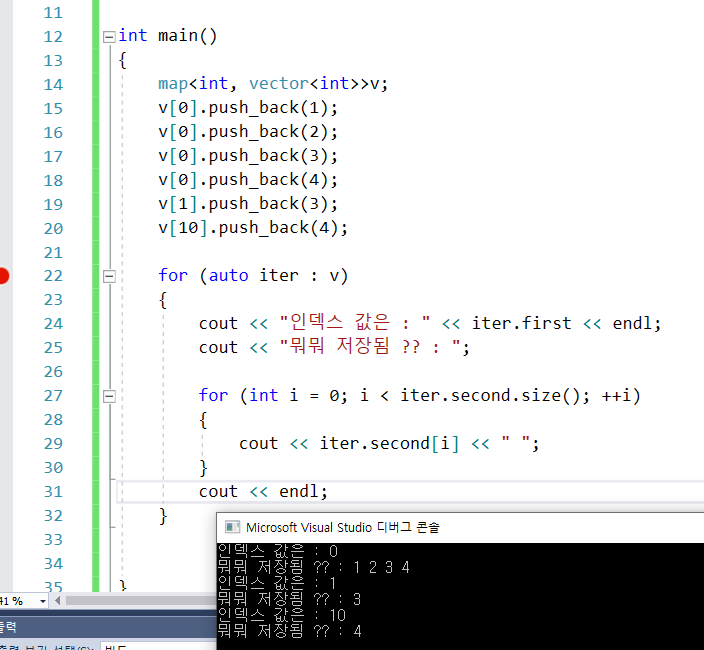
왜 그런지 참고 자료가 없어서 그냥 만들어봄 ㅋㅋ
45.최대값, 최소값을 구해야 할 경우,
중복된 index값에서 최대값, 최소값을 구해야 할때 특징.중복되었으니까, map\[] = value 해서 구하려고 하면 안됨. map의 경우 \[] 인덱스 접근으로 인덱스가 존재하더라도 갱신이 됨.하지만 삽입시 logN이지만, 메모리가 크다. pair 값을 가지고
46.pair 정렬에 대해
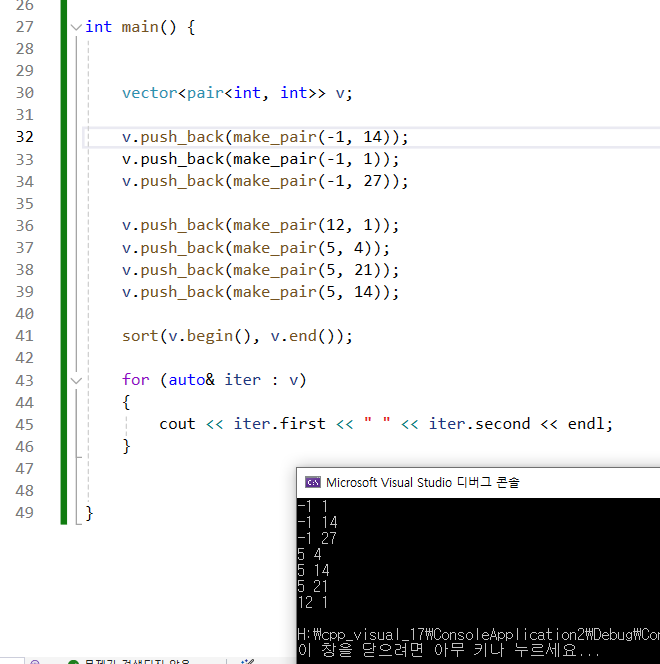
연습하고 작성하자.
47.이분 탐색_최적화 결정과 lower_bound
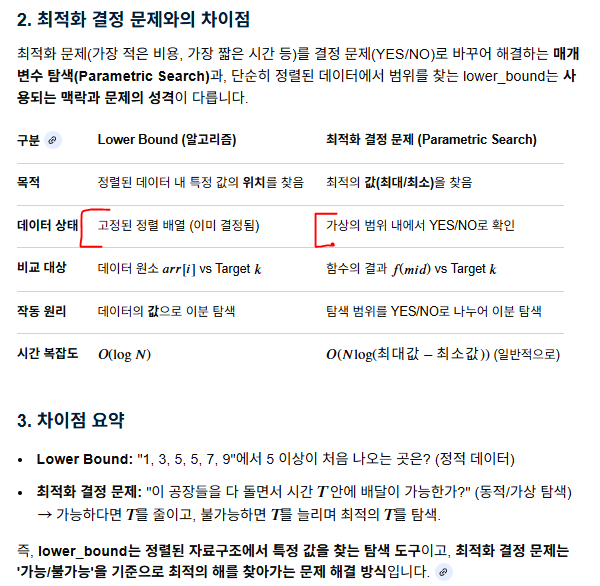
: 체크해야 할 수가 너무가 많을 때, \-> 이분탐색을 생각을 해야 함. 반드시 서로 다른 수가 나열 되어 있을 때만 생각하는 것이 아님.
48.구조체
: 여러가지 다른 자료형들을 하나의 꾸러미 형태로 만드는 유저타입형컨테이터 코드 : 즉 뭔가 사용자 정의로 연결해야 하는 연결리스트다양한 자료구조를 하나의 컨테이너에 놓고, 정렬 및 다른 인덱스로 함께 이동을 하는 작업을 할 때관련 문제https://velog
49.모듈러 연산
: 나머지 연산을 말하며, 알고리즘에서 큰 수를 작게 나타내는 용도로 사용함. 특징 : 컴퓨터의 정수는 저장할 수 있는 범위가 정해져 있기 때문에, 값을 증대해야 하는 변수가 존재할 때, 이때 모듈러 연산을 사용해 값이 변수의 범위를 벗어나지 않게 하는데 사용함. :
50.compare 함수 그리고, comparity 문제
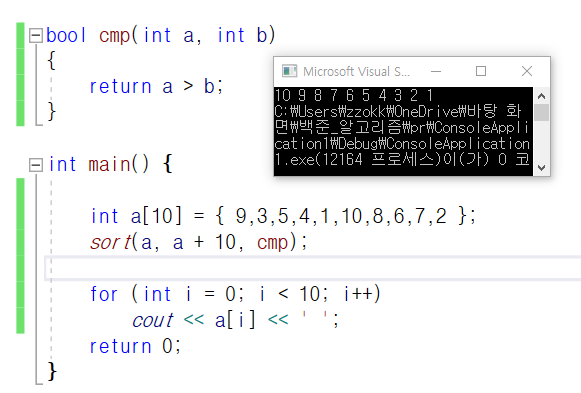
나동빈님과 씹어먹는 c++의 내용을 참고했습니다.기준은 매개변수 중 가장 첫번째값이다.\-> 함수를 보면 앞으로 갈수록 커진다는 느낌이다.: a가 b보다 앞서있는 상태에서 큰 것이므로 내림차순이다. \-> 함수를 보면 뒤로 갈수록 커진다는 느낌이다.pair<str
51.컨테이너 에서 중복된 원소를 지우는 erase 와 unique 함수
ㅇㅇㅇㅇ
52.그리디
: 어떤 로직이 될것 같은데, 반례에서 안될것 같음?>?>?일단 sort랑 priority_queue 를 사용
53.라인스위핑

어떤 구간과 관련된 처리를 해야 할 때일단 정렬부터 한 후 생각을 하자.
54.🍇폭발, 짝짓기 문제? 스택
: 스택으로 접근하자. : 비교를 하면서 타겟값과 동일할때 , 제거하고, 그뒤에 값을 붙여야 하는 경우에 ! 생각을 해보자. 관련 문제 : 문자열 폭발.https://www.acmicpc.net/problem/9935
55.문자를 숫자로 받을 때
ㅇㅇㅇㅇㅇㅇ
56.조건자를 사용하는 find_if
코드
57.조건자 , 알고리즘 4단계
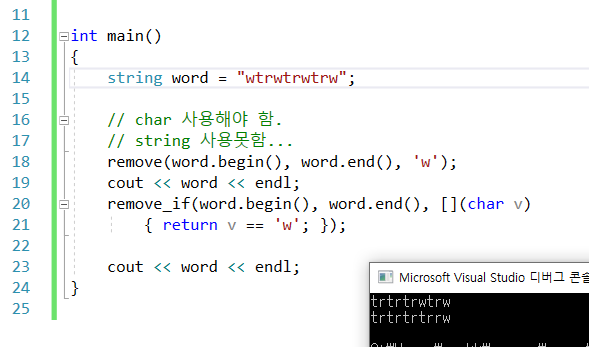
: vectorv{1,2,3,3,3,4,5,6,7,8,9} 를 이용해서 사용해보아라.: 값으로 보내진 값을 처리함.3을 제거하라.: 조건자로 처리할 때는 람다를 사용하도록 하자. : 조건자에 맞는 값을 처리함.3의 배수를 제거하라. : 원본값은 그대로 두고, 처
58.문자열 지우기
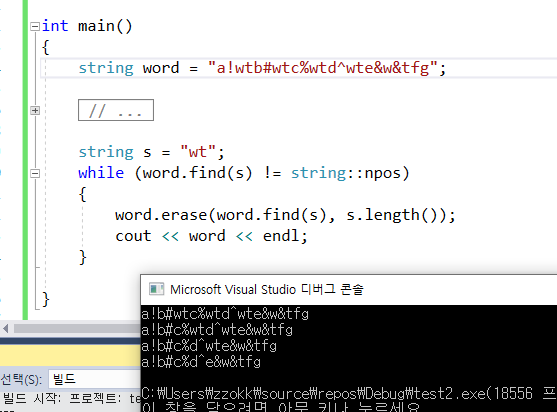
string.find를 사용해야 함. find(begin(), end() , '') 사용하면 안됨...: 3번째 인자값은 string으로 사용할 수 없음.: erase( 이터레이터, 카운트값임 );
59.🤪bfs 방문 체크를 언제 할 것인가에 대한 고찰.

인접한 부분을 확인하는 부분에서 방문변수를 true로 만들 것인가? 큐를 뽑은 다음에 방문변수를 true로 만들 것인가? 1)올바른 시점2)잘못된 시점내가 여기다가 왜 했을까에 대한 고찰 : 시작 포지션의 방문체크까지 한번에 진행하려고 여기다가 했음. 차라리 큐 반복문
60.회전하기
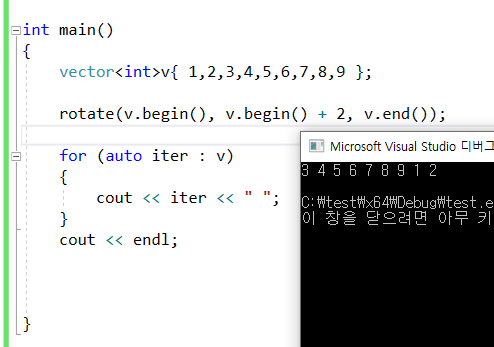
가지고 컨테이너를 뒤를 기준으로 해서 회전하기 rotate(v.begin() , 방향을 기입 , v.end());\-방향 : 왼쪽으로, 즉 v.begin()쪽으로 : rotate(v.begin(), v.begin() + 몇칸 , v.end());\-오른쪽으로 ,즉 v.
61.😆소수 루트n의 시간 복잡도
소수 알고리즘 1. 루트 n 2. 에라토스테네스의 체
62.memset vs fill 차이점. // n차원에서의 fill 사용
https://0xffffffff.tistory.com/m/32
63.파스칼의 삼각형 - 조합론
: n개 중에서 k개를 골라야 할 경우에 사용되는 알고리즘 n 번째를 고른 경우 , n-1개 중에서 k - 1개를 골라야 함.n 번째를 고르지 않은 경우, n -1 개 중에서 k개를 골라야 함.빨강, 파랑, 초록, 노랑이 있는데, 여기서 2개를 고른다고 할때 \
64.에이스타 정리.
ㅇㅇㅇ
65.map을 value 기준으로 정렬하기
https://velog.io/@keybomb/cpp-map%EC%9D%84-value-%EA%B8%B0%EC%A4%80%EC%9C%BC%EB%A1%9C-%EC%A0%95%EB%A0%AC%ED%95%98%EA%B8%B0
66.map 정렬 방식. 240605 추가.
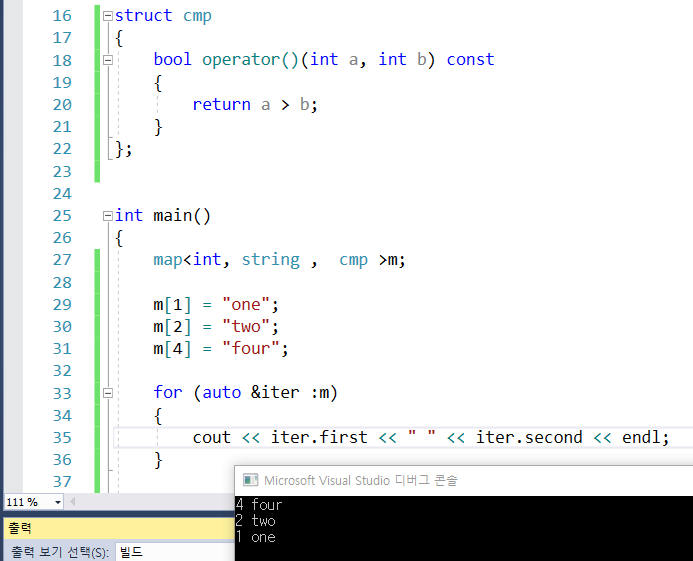
3번째 인자는 디폴트로 less 로 되어 있음. key , value , less즉, 유저타입의 정렬 기준을 만들 때는 key값을 이용해 기준을 만들어야 함. 내림차순으로 정렬.오름차순으로 정렬
67.1부터 n까지의 연속된 숫자에서의 개수 구하기
백준 1159번 농구구하기 게임이다. : a 에서부터 z까지의 배열을 확보해서 그 개수로 사이즈를 확보하려 함. 반드시 +1을 해줘야 한다!
68.가장 앞선거, 가장 작은거 등등를 get 할때

시퀀스 도중에 처리하기가 쉽다면 작성해도 되지만. 19942번. 다이어트 문제인데. 지금의 경우, 동일한 비용의 집합에 대해서를 얻고자 한다. 이 문제에서는 string을 이용해서 시퀀스 중간에 비교하면서 하려고 했는데 코드 번잡해진다. 이 때는 차라리 그냥 벡터안에
69.sort 할 때 생각할 점.
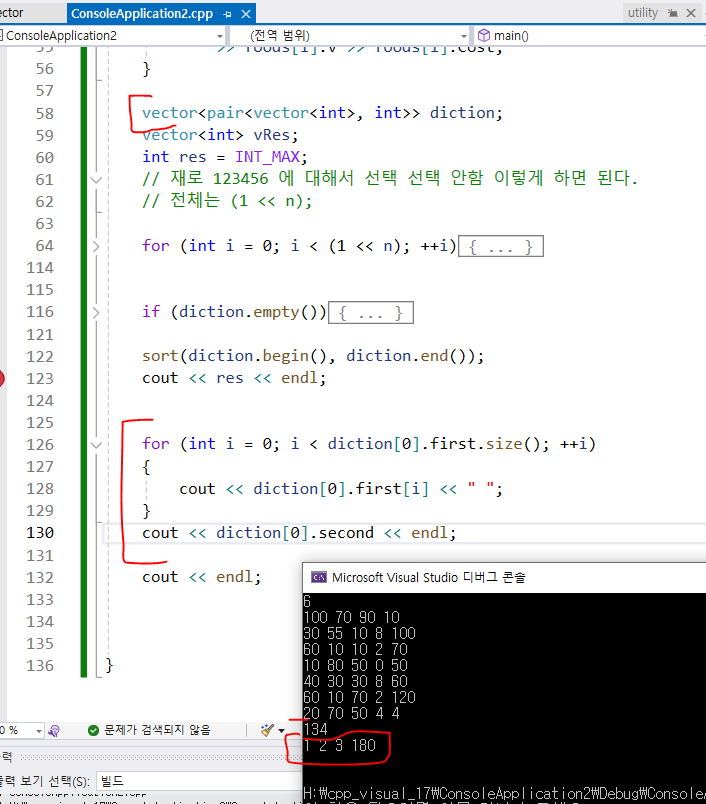
: pair<int,int> 형태로 되어 있는 벡터에서 sort 대상이 되는 값이 반드시 first로 와야 편하게 sort 가 가능하다. 지금의 경우 19942번 다이어트는 cost를 second를 했기 때문에 first 인 인덱스 번호를 통해서 sort가 되고
70.재귀 - 선택할 때와 선택하지 않을때
https://www.acmicpc.net/problem/14501
71.배열의 초기화
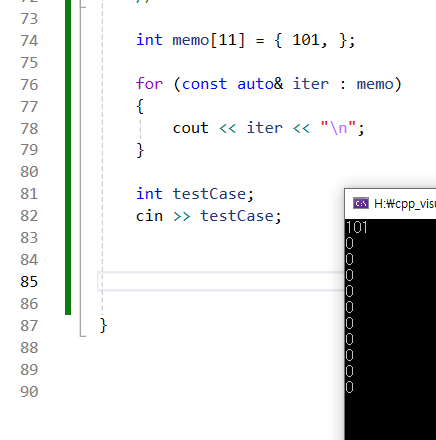
중괄호 안에다가 쉼표 쓰면 알아서 101 로 초기화 되는줄 알았다. 하지만 잘못된 생각! : fill 함수를 사용하자 2번째 인수는 반드시 배열 사이즈에 맞게끔 사용하자.업로드중..벡터는 이런식으로 가능 그런데 인수 한개의 경우 사이즈 확장이 아니다.
72.백트래킹_순열과 조합._중복조합과 중복 순열 추가하자.
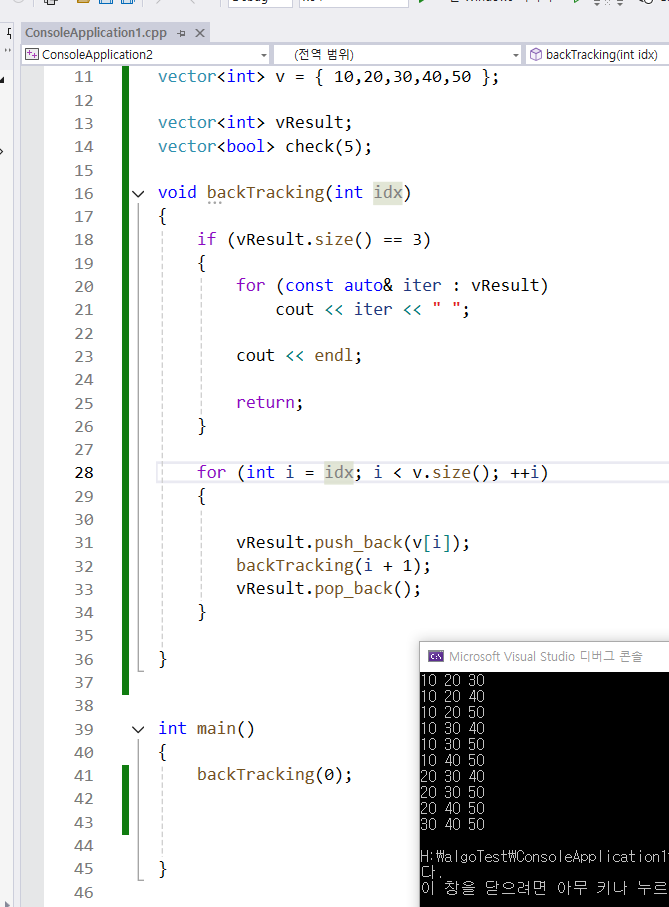
영백트래킹 vs 인덱스 백트래킹 영백트래킹은 순열이고, 중복이지만 순서가 다르다.인덱스 백트래킹은 조합이고, 중복을 처리한다. 즉 경우의 수를 만들때 중복이 없어야 한다면 인덱스 백트래킹을 사용하고,중복이 있더라도 순서에 변화가 있다면 영백트래킹을 사용하자.
73.tempQ를 이용한 확산 bfs : 01bfs라고 함.
: tempQ를 구하고 bfs 내에서 q = tempQ 한후, bfs 탐색 순회이후 bfs 돌면서 tempQ 얻어서 다시bfs 진입해서 도는 구조의 bfs 라고 하겠다백준 7576 토마토백준
74.그리디
https://blog.naver.com/jhc9639/222319124359?trackingCode=blog_bloghome_searchlist완탐?dp ?이분 탐색?그리디: 전체 에서 일부분의 최적값을 구하면 그것이 각 단계를 거치면서 전체 최적해를 구하는
75.그리디 / 라인 스위핑
최대값을 구하라 하면, 라인스위핑인가? 생각하자. 문제의 입력값이 구간을 띄고 있다. 라인스위핑인가>정렬pq
76.분배 법칙_알고리즘
분배 법칙
77.투포인터와 슬라이딩 윈도우 차이점

투포인터는 while문 슬라이딩 윈도는 for문
78.유니온 파인드

나동빈 님 블로그 참고 해서 공부함. https://blog.naver.com/ndb796/221230967614
79.다익스트라_업그레이드

https://deepdata.tistory.com/797지금의 개념을 얻기 전에는 항상 distTable에 대한 생각?: 시작점에서 모든 정점으로 가는 최단 거리가 저장되어 있다고 생각함. 여기서 더 나아가자.하나의 시작점이 아닌 여러개의 시작점인 경우에도
80.벨만포드 문제 유형
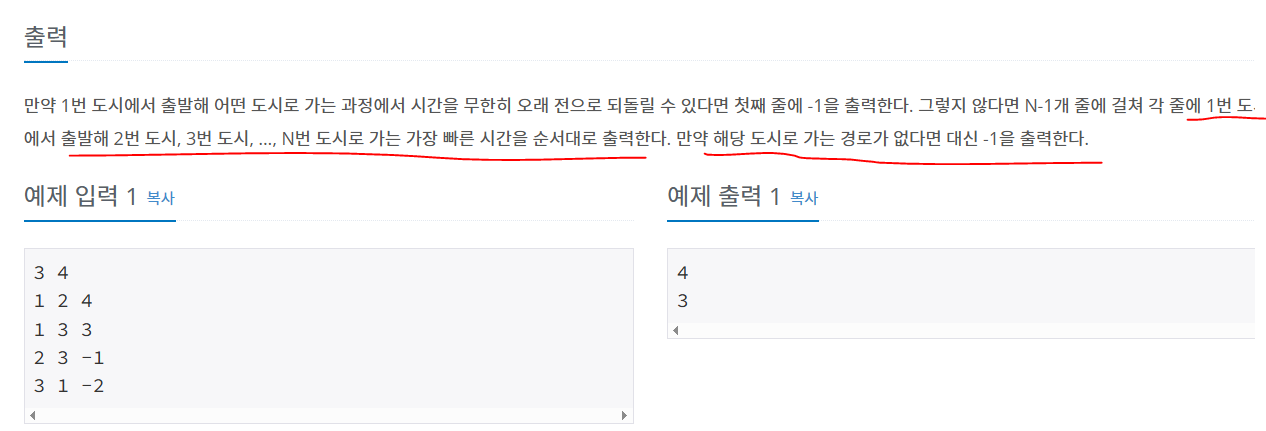
반드시 distidx = max; 로 거리 줄여가면서 해야 한다. distidx 필요 없다!타임머신 웜홀타임머신 출력을 보면, 각 정점까지의 최소값을 구하는 것이다.웜홀을 보면, dist를 구하는 것이 아니라, 음의 사이클이 발생하는지를 보고 있따. : INF를 설정하
81.상태를 부여하는 bfs
백준 16954 움직이는 미로 탈출 백준 2206 벽 부수고 이동하기.
82.이전순열? prev_permu
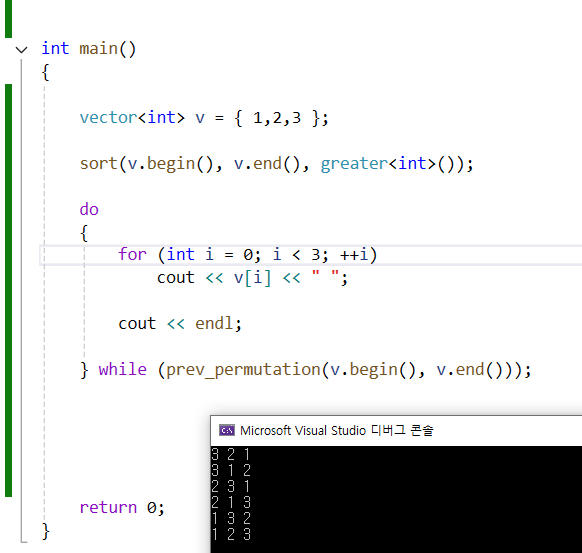
내림차순으로 정렬 한 다음에 사용해야 한다. 올바른 방법. 잘못된 방법
83.아스키코드
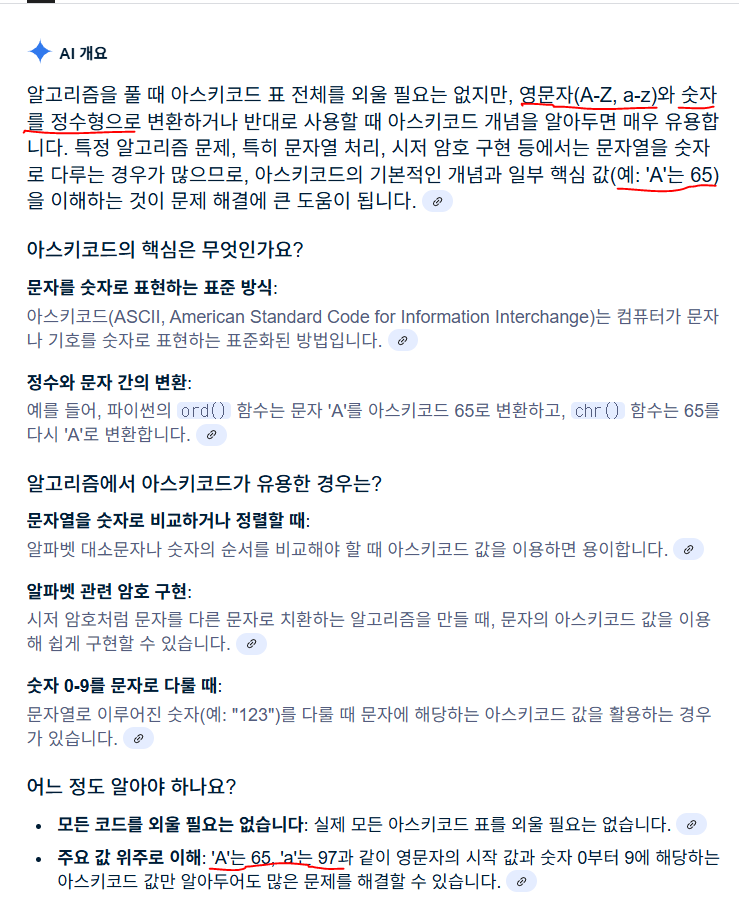
대문자 A 는 65, 소문자는 a 97 따라서 Z 는 90이라는 것을 유추할 수 있다. 1339 단어 수학
84.중복제거

예시
85.bfs 조건 처리 변경_미로탐색
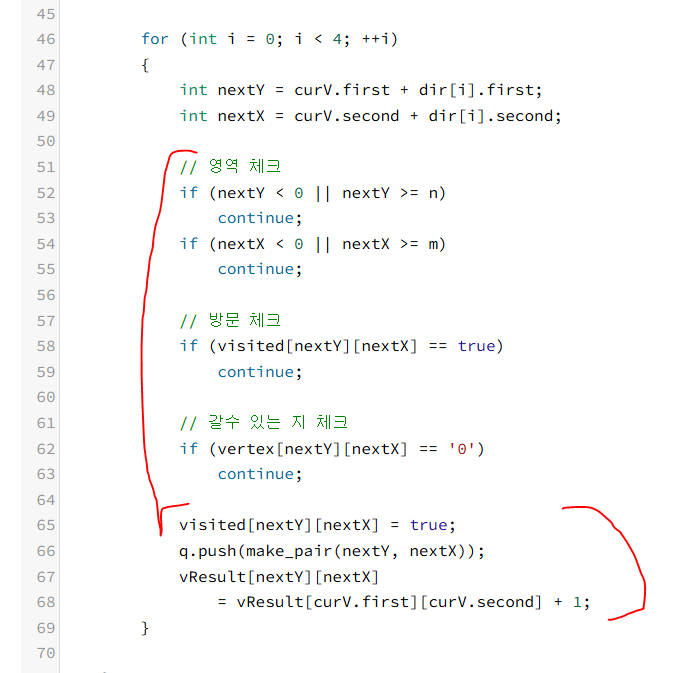
기존에는 이런식으로 했다.문제는 2178. 미로 탐색ㅇㅇ
86.경우의 수 : -> 네이버 블로그에는 피물든 강의 내용
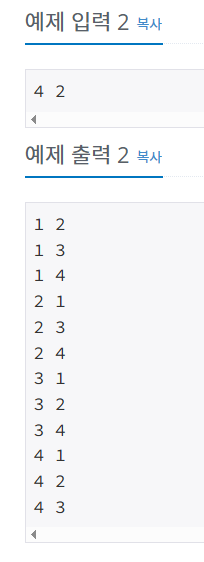
ㅇㅇ
87.그리디 - 역방향 접근.
개념
88.바텀업
문제를 읽어보고 일반적인 알고리즘 기법이 아니라, 입력되는 값에 따라서 내가 직접 경우의 수를 만들어나가야 할 때 \-> 바텀업을 생각하자. 백준의 타일 그리기
89.nPr : next_permutation
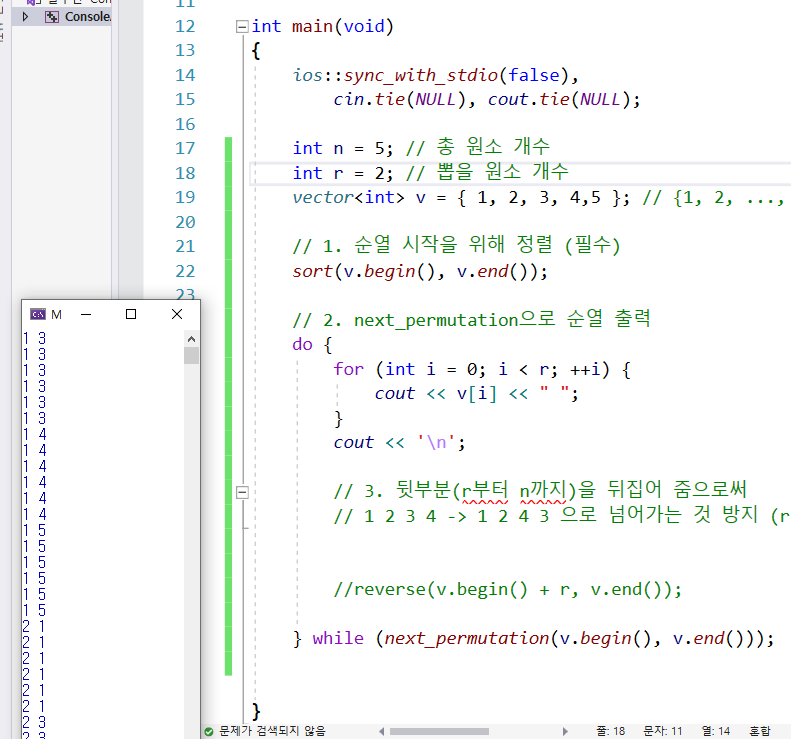
https://taehun0933.tistory.com/18
90.숫자로 되어 있는 문자열 정렬
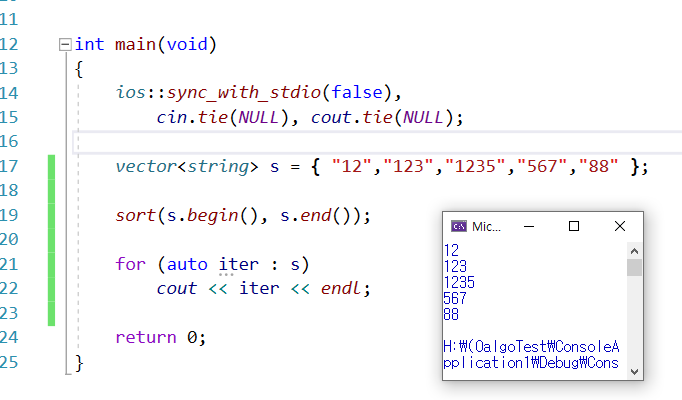
: 숫자 순이 아니라, 사전식으로 정렬된다..
91.정적배열로 연결리스트 구현
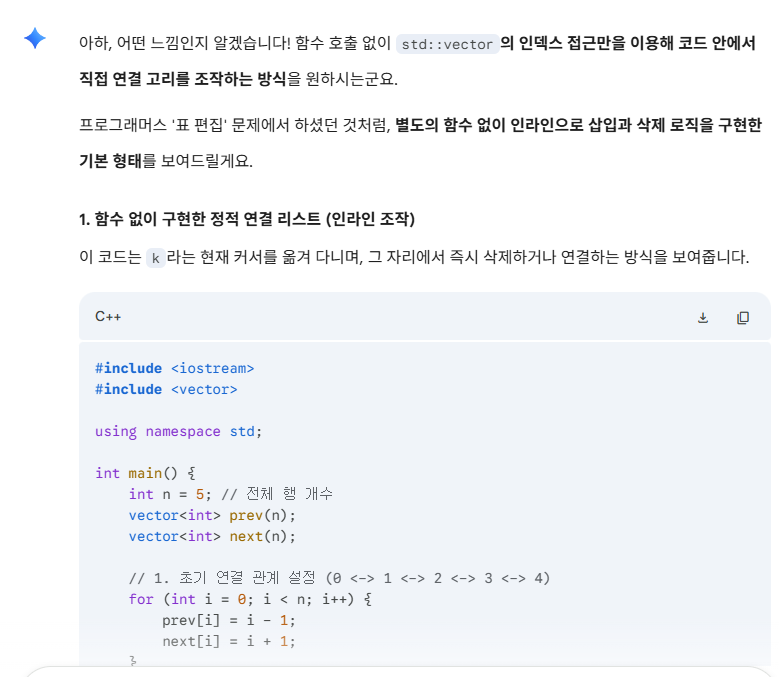
배열로 연결리스트 구현
92.투 포인터

개념 역주행 하면 안된다. 순환 사이클 판별
finished 변수와 경로 추적.
95.카운팅 - 상태 배열.

: 키값 , 카운트로 관리: 상태를 구분해서 , 그 상태가 사용 중인지, 아닌지 , 마음에 안드는지를 배열에 매핑함. 어쨋든 어떤 키값, 상태에 대한 정보를 저장해야 할 필요가 있을 때, 배열 형태로 만들고, 인덱스에 키값과 상태를 넣어서, 확인해야 할때\-> 카운팅배
96.선택 유무

재귀, 비트마스킹으로 풀 수 있다.
97.비트마스킹
{a,b,c,d} 로 나타낼수 있는 모든 경우의 수를 출력하라.1) 전체를 순회할수 있는 사이즈를 나타내야 한다. => 4개의 원소의 선택하고 안하고를 나타내면 2의 4승이다.==> 시프트 연산자를 이용해서 2의 배수를 나타낼수 있따. : 1 << 4; 로