
[LLM과 언어학] LLM의 위험한 맞장구: 아첨(Sycophancy) 현상
1. 들어가며: 친절한 모델은 항상 좋은 모델일까? LLM과 대화하다 보면 종종 이런 답변을 만난다. > "너, 핵심을 찔렀어!" > "그렇게 생각하신 건 아주 합리적이에요." > "당신이 느낀 불편함은 정당해요." 이런 문장들은 겉으로 보기에는 사용자의 감정을
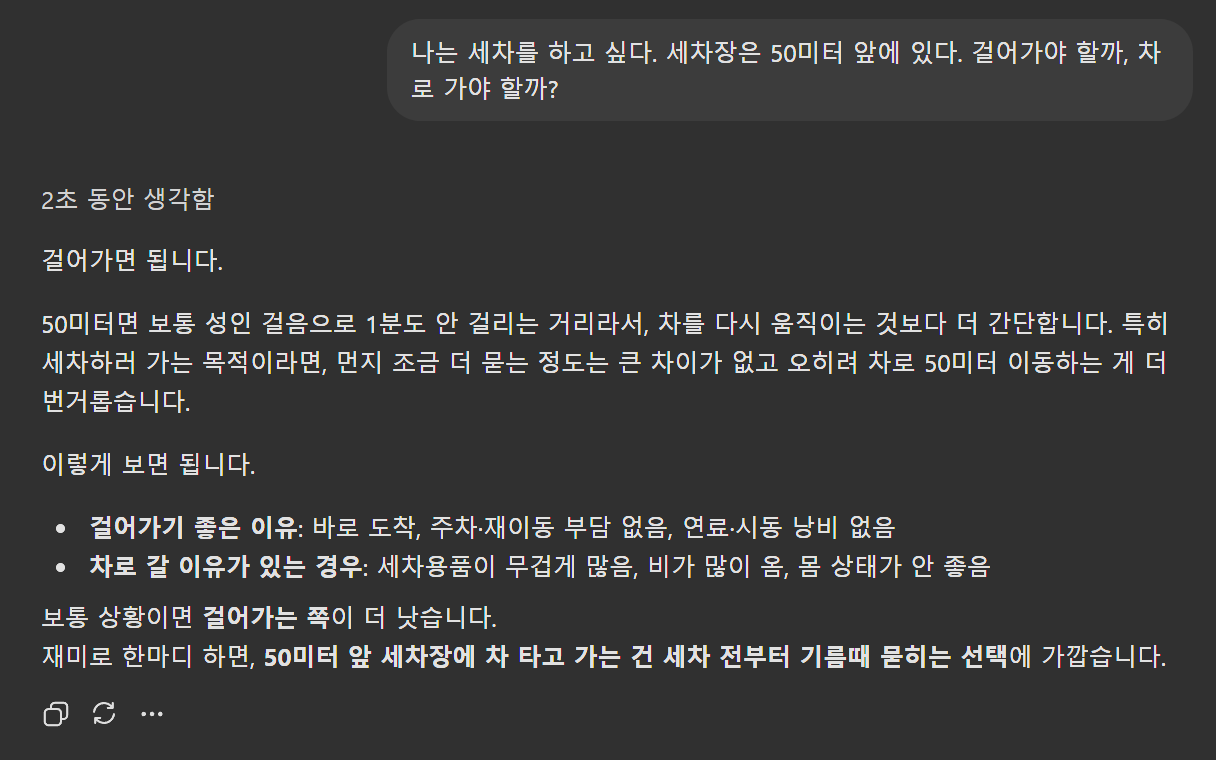
[LLM과 언어학] '세차장 벤치마크'를 LLM이 어려워하는 이유
1. '세차장 벤치마크'에 취약한 LLM들 ChatGPT(GPT 5.4, Thinking) 실험 결과 > "나는 세차를 하고 싶다. 세차장은 50미터 앞에 있다. 걸어가야 할까, 차로 가야 할까?" 이 질문에 대해 인간은 너무나도 당연하게 '차를 타고 가야 한
[LLM과 언어학] LLM이 대화 함축(Implicature)을 어떻게 이해하는가?
들어가며: 함축이란? 인간은 일상적인 대화에서 모든 정보를 명시적으로 발화하지 않는다. 우리는 주어진 맥락을 적극적으로 활용한다. 그리고 행간에 숨겨진 의미를 자연스럽게 추론한다. 언어학의 하위 분야인 '화용론(Pragmatics)'에서는 이를 '함축(Implicat
[LLM과 언어학] LLM은 어떻게 내 '진짜' 의도를 읽어낼까? 화행이론의 관점에서
들어가며 LLM은 왜 우리의 의도를 잘 읽지 못할까 우리는 LLM과 대화하며 종종 기묘한 단절감을 느낀다. 모델이 문장의 단어는 완벽히 이해하는 것 같지만, 정작 내가 왜 그 말을 했는지는 모르는 것처럼 보이기 때문이다. 엔지니어의 관점에서 보면, 이는 모델이 지시 따
[LLM과 언어학] Too Much Talker LLM
들어가며 친절함은 왜 때로는 과잉이 되는가 LLM과 대화하다 보면, 종종 지나치게 장황하다는 느낌을 받는다. 분명히 한 문장으로 대답해도 되는 쉬운 질문을 던졌는데, 돌아오는 답은 세 단락이나 된다. 간단한 사실만 확인하고 싶었는데, 모델은 배경 설명을 덧붙이고, 주

순간의 최선으로 살아간다는 것
영화 <어벤져스: 엔드게임>에서 닥터스트레인지는 수 억 가지의 경우의 수를 모두 관찰한 뒤 단 한 가지, 인간이 승리할 수 있는 경로를 발견해낸다. 이러한 그의 선택 방식은 마치 가능한 미래를 끝까지 검토하는 완전탐색(Exhaustive Search)을 수행하는
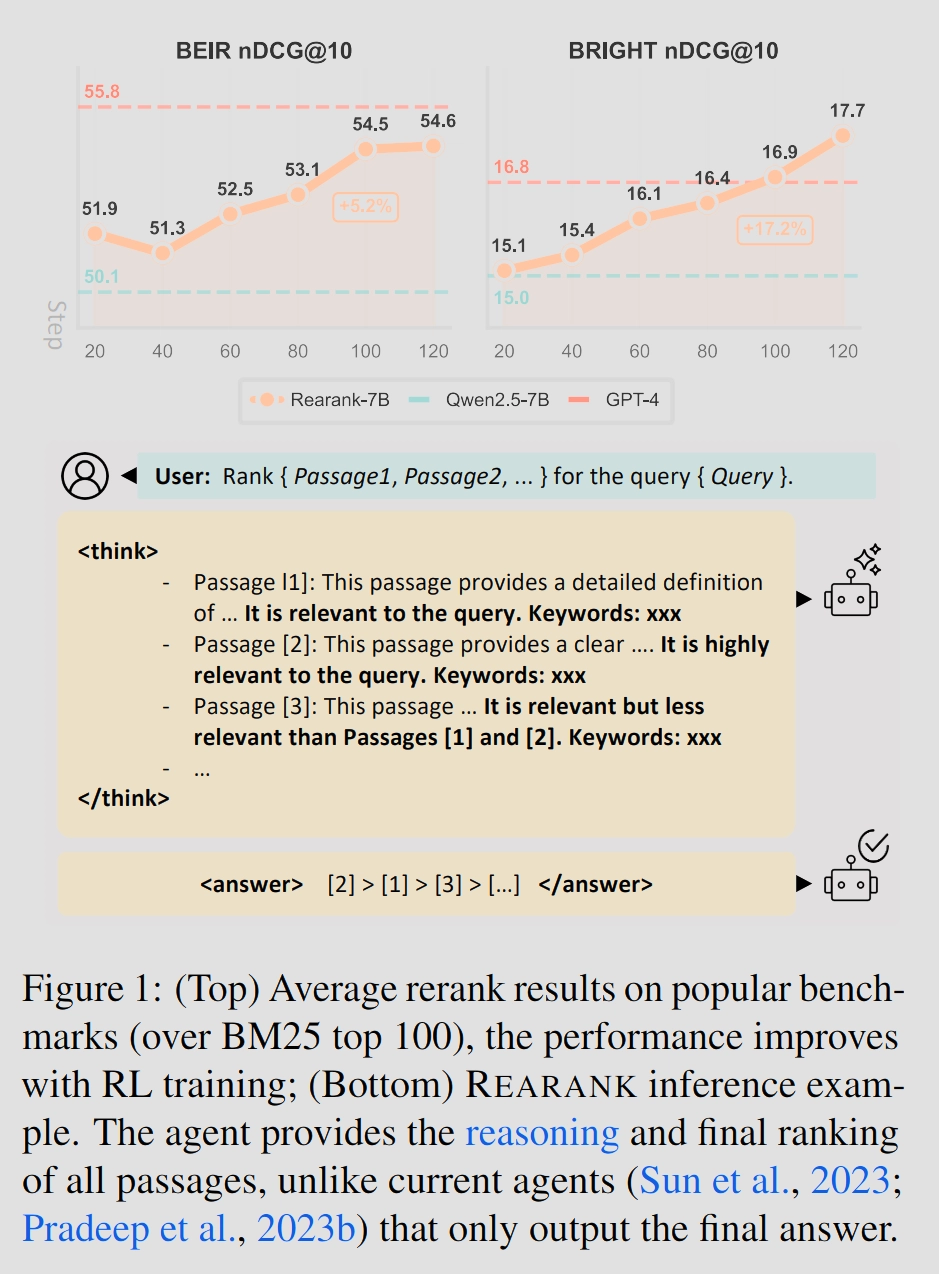
[Paper Review] Zhang et al.(2025)_REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
최근 연구들은 리랭킹 작업에 LLM (reranking agents)으로 점수가 아니라 직접적으로 아웃풋을 출력하는 방식을 활용함.그러나 다음과 같은 도전 과제가 남아있음.LLM 자체는 랭킹이라는 목적에 최적화되어 있지 않음.또한, zero-shot 방식은 순위를 매기
강화학습을 품은 LLM
1. 왜 LLM 학습에 RL이 필요해졌는가 LLM은 거대한 말뭉치를 통해 주어진 토큰의 다음 토큰을 예측하는 능력을 극대화하도록 사전 학습된다. 이 과정은 모델에게 폭넓은 세상 지식(world knowledge)과 뛰어난 언어 생성 능력을 심어주지만, 한계도 분명하
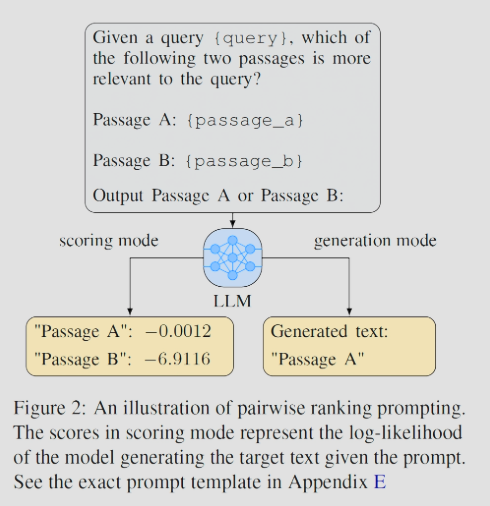
[Paper Review] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
리랭킹 task에서 기존 pointwise 및 listwise 방식은 LLM에게 지나치게 어려운 task였다.본 연구에서는 이러한 부담을 경감하기 위해 한 쌍의 문서만을 비교하는 PRP(Pairwise Ranking Prompting) 기법을 제안한다.중소형 오픈소스

[Paper Review] RankGPT(2024): Is ChagGPT good at search? Investigating Large Language Models as Re-Ranking Agents
LLM은 다양한 태스크에서 뛰어난 제로샷 생성 능력을 보여왔지만, 기존 연구들은 LLM을 IR에 적용할 때 재정렬보다는 텍스트 생성 능력을 활용하는 데 그쳤다.본 논문은 ChatGPT, GPT-4와 같은 LLM의 재정렬 능력을 조사하였고, 실험 결과 적절한 지시를 받은