데이터분석 및 MLOps
1.데이터분석 기초

데이터 분석은 데이터를 통해 통찰을 얻고 의사결정을 지원하는 과정입니다. 데이터 분석은 다양한 방법론과 기술을 통해 데이터를 탐색, 변환, 모델링하여 유용한 정보를 도출합니다.데이터 수집: 데이터를 다양한 소스에서 수집.데이터 전처리: 결측치 처리, 이상치 제거, 스케
2.데이터분석 - 기초통계
확률은 동일한 원인에서 특정한 결과가 나타나는 비율을 의미합니다. 이는 데이터 분석에서 결과를 예측하거나 불확실성을 수치화하는 데 사용됩니다.확률분포는 확률 변수 $$X$$의 함수로, 표본의 크기가 클수록 표본 집단의 평균 $$x$$의 확률 분포가 정규분포에 가까워지는
3.ML 모델 개발 및 최적화 (1)
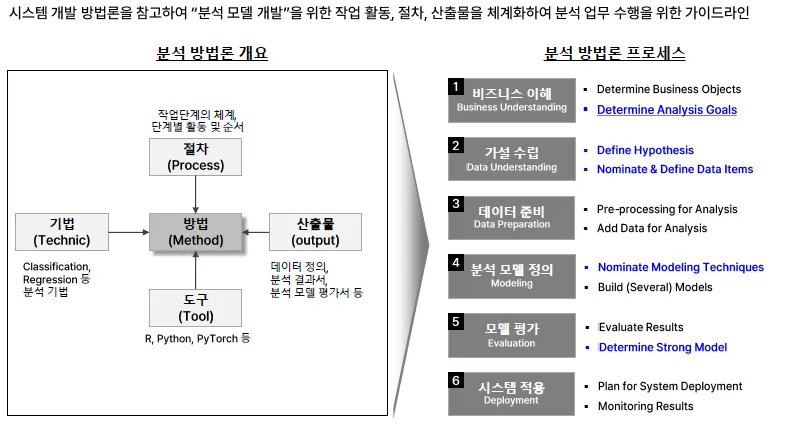
보통 논문은 Regression보다는 Classification을 사용함.⇒ 비교/측정하기 좋음.(직관적)A. EDA, 탐색적 데이터 분석 (기술통계, 시각화)B. 모델 설계 및 학습C. 모델 최적화 및 모델 평가A. 기술 통계 분석평균, 표준편차 등으로 이상치 파악이
4.ML 모델 개발 및 최적화 (2)
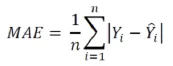
실제값과 예측값의 평균적인 차이를 측정하는 것이 목적(오차의 크기)각 방법론에 장단점이 있기 때문에, 여러 개를 함께 사용하기도 함.데이터와 데이터 평균 간 절대적인 차이의 평균제곱을 하는 이유는 차이값이 상쇄되는 것을 막기 위하여데이터의 크기에 의존적(데이터 자체의
5.XAI, eXplainable AI
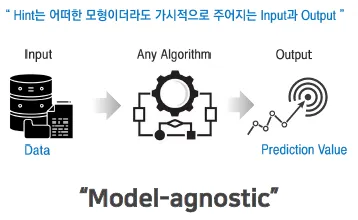
모델을 해석한다는 것의 의미, 모델의 과정을 알기 위해서…모델들의 복잡도가 증가하면서, 블랙박스 모델의 해석이 더 어려워짐다양한 알고리즘을 동일한 기준으로 해석할 필요성 生어떠한 모델을 사용하더라고 Input과 Output이 존재하기 마련특정 피처의 중요도를 평가하기
6.데이터분석 mini project (1) EDA
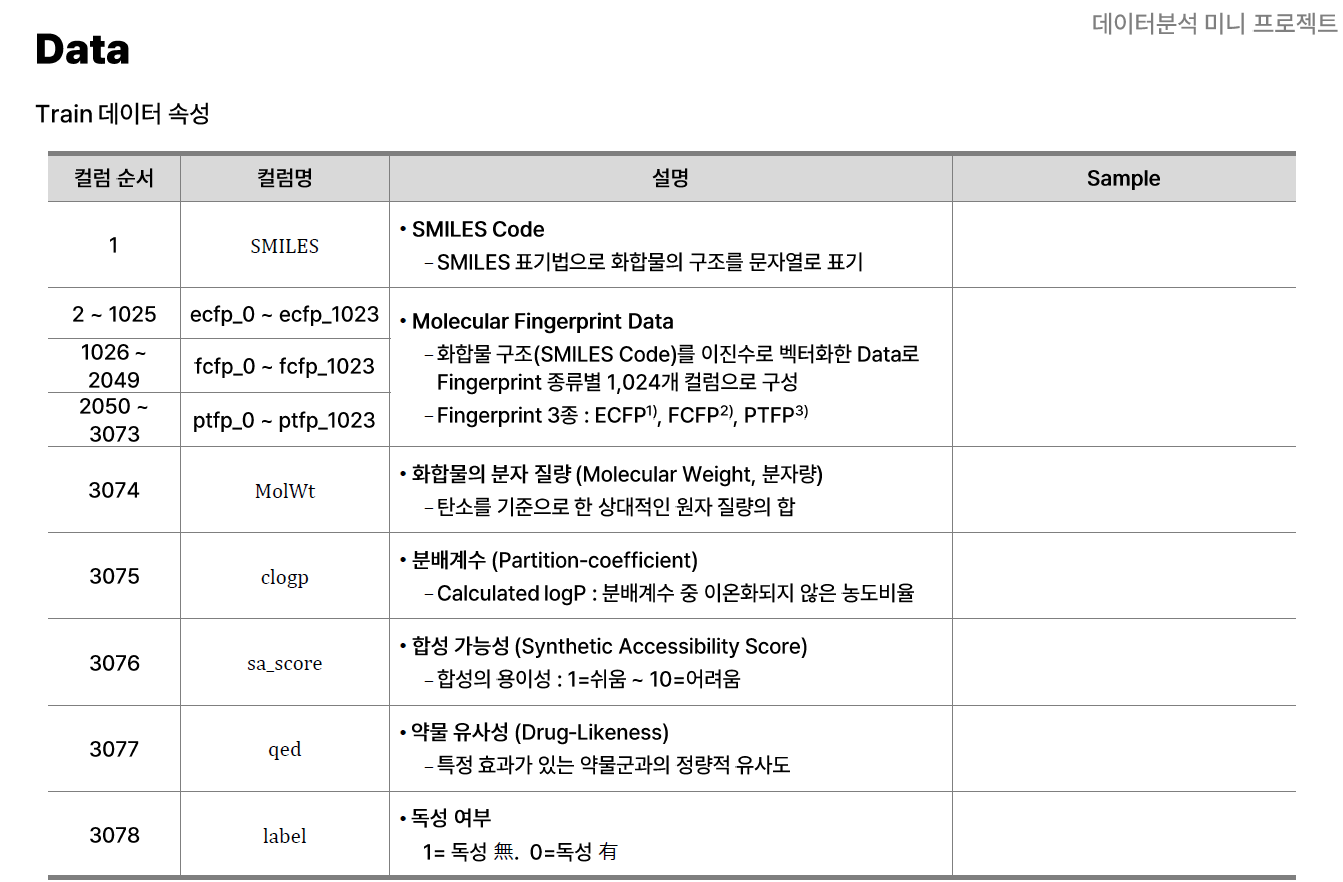
해당 미니 프로젝트는 실제로 sk 내에서 진행했던 경진대회? 느낌의 프로젝트이다.위의 표와 같이 데이터는 총 3078개의 Column으로 이루어져 있었고, 데이터의 총 수는 약 8300개 가량이었다. 데이터의 수가 매우 적으며, 차원의 수가 매우 많은 데이터의 특성을
7.데이터분석 mini project (2) 신약 독성 예측
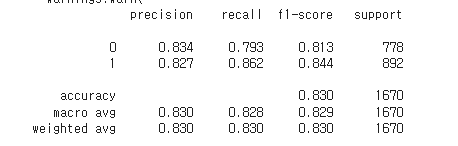
들어가기에 앞서 SMILE 화학식 코드에 대해서 유용한 라이브러리를 알개되었다 RDKit이라는 라이브러리로, SMILES ↔ 분자 객체(Mol) 변환이 가능하며, 다양한 분자 지문(fingerprint), 분자 지표(descriptor) 계산을 할 수 있다.smiles