불법 현수막 탐지 프로젝트(2)
프로젝트

차량 운행 데이터를 통한 불법 현수막 탐지 프로젝트 입니다.
불법 현수막 탐지 프로젝트(1)에 이은 발표 PPT 및 설명입니다.
발표 및 PPT

안녕하세요. 불법현수막 탐지 시스템이라는 주제로 프로젝트를 진행한 3조 "현수막치워조"의 발표를 맡게된 나인채입니다. 반갑습니다.

발표 목차입니다. 목차는 보이시는 순서대로 차례대로 진행하겠습니다.

먼저 팀원 소개와 역할입니다. 팀장인 임정민님을 필두로 김종민님 차민수님 그리고 저 이렇게 셋으로 이루어져 있고, 역할은 보이시는 바와 같습니다.
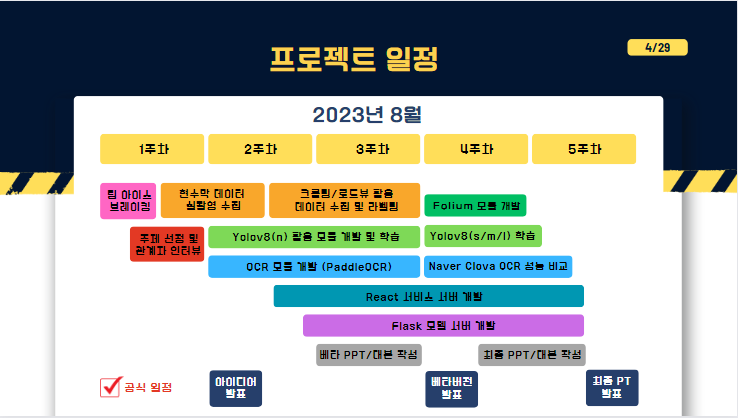
다음으로 일정 그래프입니다. 1주차에 팀 아이스브레이킹 및 주제선정과 공무원관계자 인터뷰를 진행하였고 바로 데이터수집을 시작하였습니다. 2주차부터는 yolov8 과 OCR모듈 개발을 동시에 진행하고 3,4주차에는 서버 및 모델, 코드 통합을 진행하였으며, 마지막 5주차에서는 코드 리팩토링 및 속도/성능 고도화를 진행하였습니다.

주제에 대해서 간략하게 설명드리겠습니다. 저희 주제는 차량 주행 데이터를 통해 합법, 불법현수막 게시현황을 시각화하여 제공함으로써 현수막 단속에 도움을 줄 수 있는 "불법현수막 탐지시스템"을 만드는 것입니다. 불법현수막 탐지시스템의 실효성에 대해서 의문을 품으실 분들이 많으실거라 예상되는데요, 최근 뉴스를 보면 불법현수막에 대하여 많이 보도되며, 뜨거운 감자로 떠오르고 있습니다. 이에 대하여는 주제 선정배경에서 구체적으로 설명드리겠습니다.

이어서 주제선정배경에 대해서 이야기 드리겠습니다. 우선, 지자체 단속 인력의 부족입니다. 영상 하나 시청하시죠.
(동영상 재생)
올해 춘천시 기준으로 불법 현수막 단속 작업을 관할하는 인력은 총9명이고, 이 중 6명은 하루 6시간만 근무하는 희망근로자인 상황입니다. 그러나 직접 이동하여 불법 현수막을 발견하고 철거해야하는 현수막 단속 작업 특성상 많은 시간이 소요되어 보다 많은 인력이 투입되어야하는 상황입니다.
또한 주말에만 몰래 게시하는 게릴라성 불법 현수막 때문에 휴일에도 상시인력이 투입되거나
야간 단속작업 횟수를 2배 이상 확대하는 광진구의 사례도 있기 때문에 단속 작업을 자동화하여 이러한 문제점들을 해결할 필요성이 있습니다.
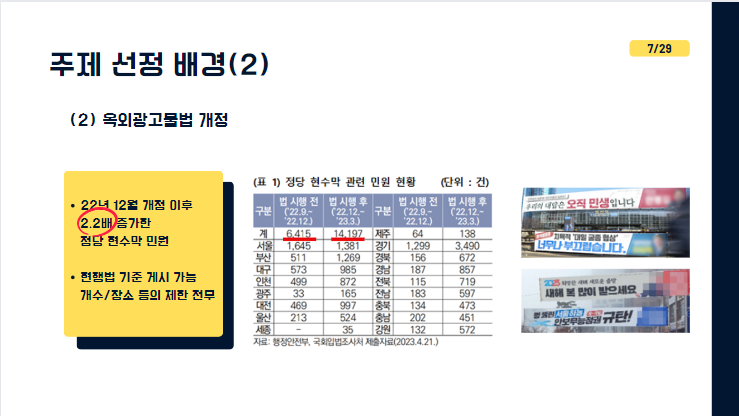
두번째로 옥외광고물법 개정입니다. 22년 12월 옥외광고물법 개정으로 인해 정치적 의미가 담긴 현수막 게시가 합법화 되었습니다. 법 개정 이후, 늘어난 정당 현수막으로 인한 관련민원이 2.2배 증가하였습니다.
현행법상 갯수/장소에 대한 제한이 전무하여 발생한 일인데 이러한 문제점을 최근 국회에서도 인지하여 갯수와 장소를 제한하는 법안이 현재 국회에 계류중이며 해당 법안이 통과되었을때 어떤 정치인이 어디,몇개의 현수막을 게시했는지 파악하는데 기여할 수 있는 프로젝트라고 생각합니다.
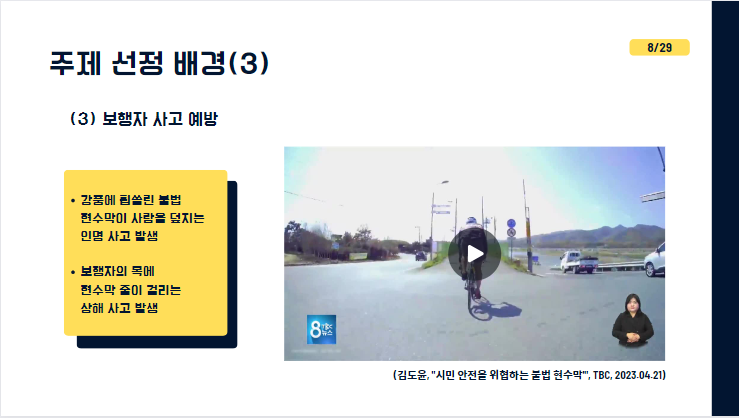
마지막으로 여러분도 이 프로그램의 필요성을 느낄 수 있는 보행자 사고 예방 목적입니다.
(동영상 재생 클릭)
영상에서 보신 것처럼 인도,자전거 도로, 일반도로 근처 제대로 관리되지 않은 현수막으로 인해 인명피해가 발생하는 경우가 있습니다. 사전에 이러한 위협요소를 제거하여 보행자 안전에 기여하고자 합니다. 그리하여 위 3가지 근거에 기반하여 본 프로젝트를 진행하게 되었고

이를 구현하기 위해 활용한 3가지 기술 스택은 다음과 같습니다. 사전에 수집한 차량 주행 이미지 데이터에서 yolov8을 활용하여 현수막을 탐지하고 PaddleOCR 혹은 ClovaOCR 기술을 통해 현수막의 텍스트를 정렬하고 추출합니다. 마지막으로 추출된 텍스트를 chatGPT를 통해서 카테고리별로 분류한 뒤 이후에 보여드릴 부분이지만 지도상에 위치별 현수막을 표시하여 단속에 활용할 수 있는 시각화 정보를 제공하는 방향으로 큰 맥락을 잡았습니다.
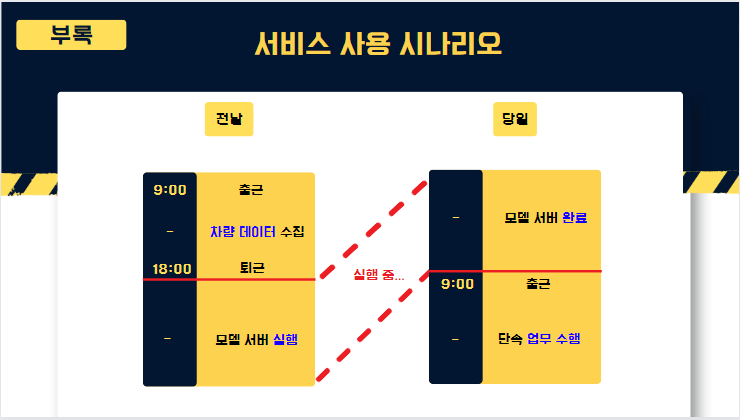
우선 저희 프로그램이 관공서를 고객페르소나로 잡은만큼, 단 한번의 클릭만으로 모든 프로세스가 진행되는 UX면에서 신경을 쓴 점, 그리고 real-time이 아닌 정확도를 위한 프로그램인 점 등에 의해
프로세스 진행이 생각보다 오래걸려, 원활한 시연을 위해 먼저 서버에서 선진행을 하도록 하겠습니다.(데이터 보여주며, 주말에 수집한 데이터 강조)
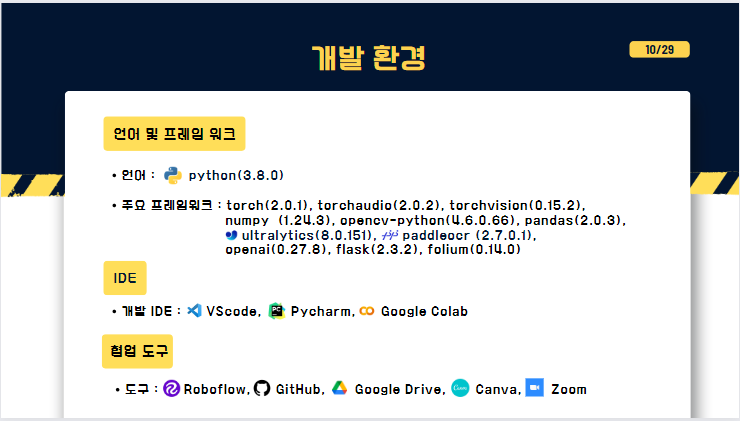
(이제 다시 PPT로 넘어와) 개발 환경에 대해서 이야기 드리겠습니다. 언어는 초기에는 yolov8 호환버전인 3.7 기준으로 실행해보며, 최종적으로 3.8버전으로 일치시킨 뒤 진행하였고
주요프레임워크는 torch, ultralytics, paddleOCR, flask, folium 등이 있습니다. 데이터 전처리 협업도구로써 Roboflow를 활용하여 box annotation을 진행하였습니다.

다음으로 개발과정입니다. 먼저 데이터수집으로는 저희가 각자 살고 있는 집 근처 길가에 있는 현수막을 실촬영하여 수집하였습니다. 실촬영 할 시기가 발표 2~3주전 기간으로 올해 가장 더운 기간대였지만 프로젝트를 위해 직접 발로 뛰면서 수집하였다는점 "꼭" 알아주셨으면 좋겠습니다^^
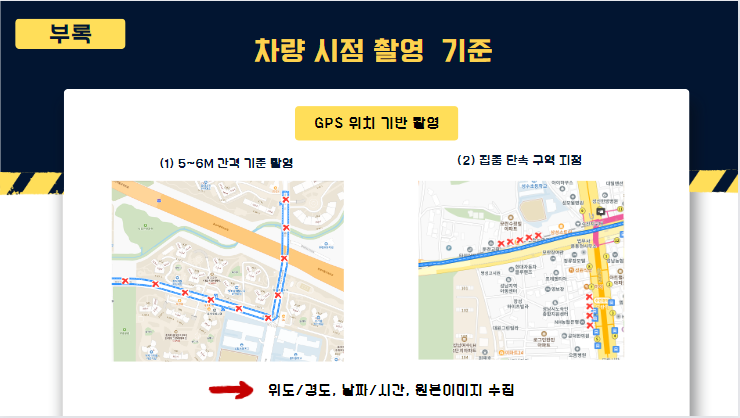
두번째로 수집한 경로는 강사님의 조언으로, 로드뷰 캡처입니다. 간단히 캡처하는 방식이기도하고 차량주행시점의 데이터로 저흐 프로젝트에 가장 유효하다고 생각되어 가장 많은 약 900장 정도 수집하였습니다.
세번째로 이미지크롤링을 진행하여 총 1342장의 현수막데이터를 수집하였습니다.

데이터 전처리에서는 차량주행상황을 고려하여 데이터증강을 진행하였는데
첫번째로, 촬영된 구도에 따라 각도가 기울어질 수 있기 때문에 rotate 변화를 주고 두번째로,
주간/야간에 따라 밝기 다를 수 있기 때문에 명도를 조절해 주거나 마지막으로, 날씨나 카메라 노이즈에 따라 사진이 불분명할 수 있기 때문에 선명도 변화 등을 주었습니다.
최종적으로 총 3226개의 학습 데이터로 증강했습니다. 라벨링 할 때는 2개의클래스로 분류하였는데 찾아야 하는 현수막을 첫번째 클래스로 지정하였고 각 지자체에서 정식으로 현수막을 걸 수 있게 설치해놓은 지정게시대를 2번째 클래스로 지정하여 라벨링 하였습니다.
우측에 보이시는 사진이 지정게시대인데 뒤편에서 좀 더 자세히 설명드리겠습니다.

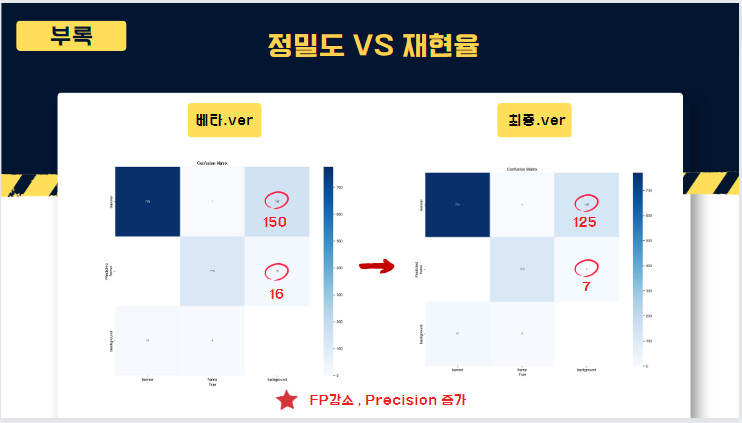
네, 방금 말씀드린 방식대로 전처리한 데이터를 학습한 yolov8 모델의 지표입니다. 좌측에 보이시는게 학습 argument 입니다. 학습할 때 epochs=2000, patience=50, batch 사이즈는 32 로 설정하였고
베타버전때 발생했던 배경을 현수막으로 인식하는 케이스, 즉 FalsePositive(FP)를
줄이기 위해 파라미터를 튜닝하여 150개에서 125개로 줄일 수 있었고 정밀도를 높힐 수 있었습니다. optimizer는 Adam, learing rate는 0.01로 진행하였습니다.
오른쪽에 보이시는게 학습 결과입니다. mAP50은 0.963 , mAP50-95는 0.797로 도출되었습니다.

학습 과정에서 검증한 예시 사진들입니다. 검증 데이터 기준으로는 대부분 confidence 값이 0.8 이상으로 예측한 성공한 케이스들이 많았습니다.

모델 추론과정에서 나온 detect사진들입니다. 왼쪽 사진은 이미지내의 단일현수막들에 대한 detect이고 가운데 사진과 오른쪽 사진은 지정게시대와 함께 detect된 현수막들입니다.
여기까지가 모델링에 관한 부분이고 이제 실제로 어떻게 활용할 지 말씀드리자면

먼저 현수막에 대한 이해가 필요합니다. 다들 현수막이 뭔지 잘 아시나요? 그쵸, 반응을 보아하니 잘 모르실거 같으니 구체적으로 설명드리겠습니다.
구체적으로 현수막의 종류는 크게 3가지로 나뉩니다. 첫번째로 지정게시대입니다. 여기서 지정게시대라 함은 시청에서 주관하여서 개인병원,자영업자분들의 요청을 받고 추첨을 통해 일정기간 기재되는 옥외광고물이고 이러한 형태는 모두 '합법'입니다. 그리고 중간에 있는 두번째 케이스가 길거리에서 자주 볼 수 있는 하나의, 단일한 '불법' 현수막입니다. 여기까지만 보면 지정게시대에 속하지 않은 단일 현수막은 전부 불법이 아니냐? 라고 생각하실 수 있는데, 세번째로, 단일 현수막이되 지자체에서 게시한 공익적인 문구의, 예를 들어, 담배꽁초를 버리면 과태료를 물게됩니다와 같은 합법 단일 현수막 형태도 있습니다.
그래서 이렇게 3종류를 분류하기 위해 진행한 내용에 대하여 말씀드리자면,
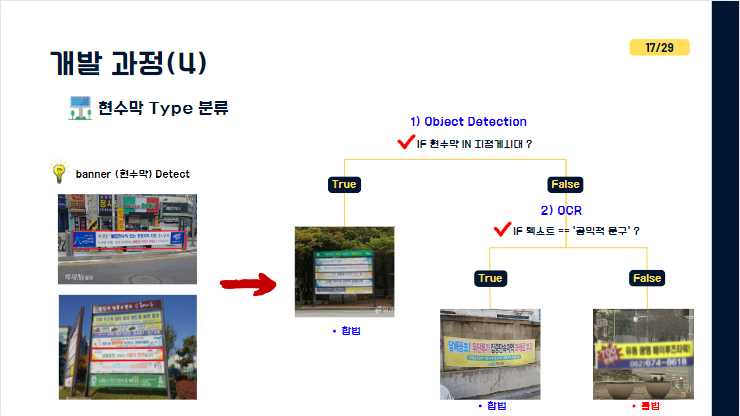
우선 저희가 진행한 알고리즘입니다. 일단 어떤 형태 이미지 데이터가 입력되든 이미지에서 현수막이 Detect 되었을때 이 현수막이 지정게시대 안에 있다면 '합법'으로 결론냅니다.
만약 지정게시대 안에 없는 단일현수막일경우는 두가지 케이스로 OCR을 진행하여 "공익적문구"인지 여부를 판별한 뒤 공익이면 합법, 아니면 불법으로 분류하였습니다.

방금 말씀드린 '지정게시대 현수막'으로 분류하는 방법입니다. 지정게시대안에 현수막이 있을경우 그 현수막을 내용에 상관없이 합법으로 처리해야하기에 현수막과 지정게시대의 겹치는 비율이 일정퍼센트 이상일 때에 합법으로 분류하는 코드로 해결했고 카메라 각도에 따라 혹은 현수막이 축 쳐지는 케이스들도 있기 때문에 현재는 임계값을 70%로 설정해두었고 활용에 따라 조정이 가능하게끔 만들었습니다.
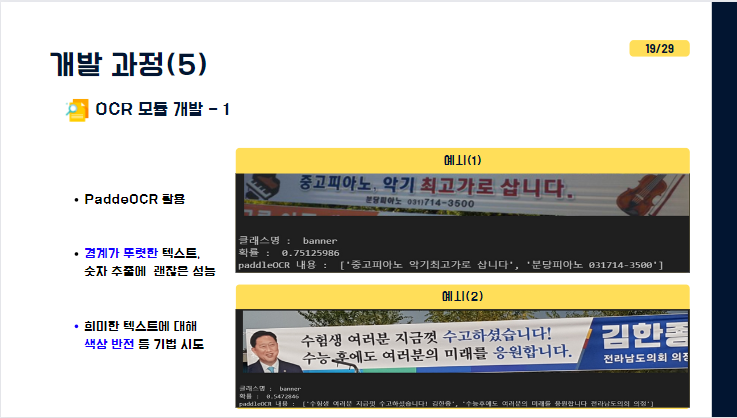
그 다음으로 지정게시대에 속하지 않은 현수막이나 단일 현수막을 OCR 기술을 통해 텍스트를 추출하였습니다.
먼저 시도한 PaddleOCR의 예시입니다. 경계가 뚜렷한 텍스트나 숫자에는 괜찮은 성능을 보였습니다. 하지만 일부 희미한 텍스트들에는 성능이 좋지 않아 grayscale 처리나 색상 반전 등의 기법을 시도해보기도 하였습니다. 우측에 보이시는게 PaddleOCR의 예시입니다.
(3초 대기)
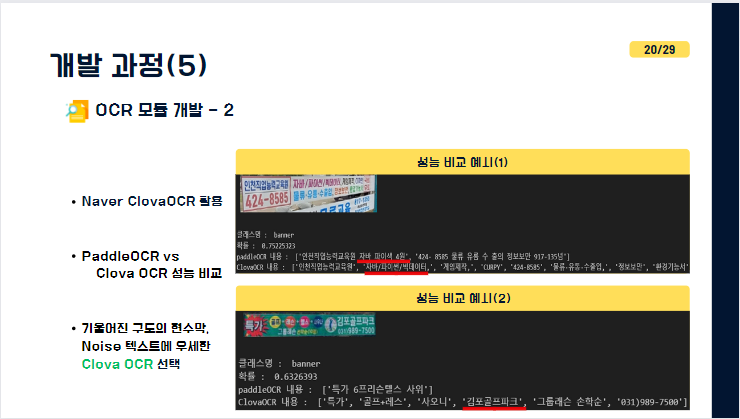
또한 Naver Clova에서 제공하는 OCR도 사용하였는데요. Paddle OCR로 문구를 추출할 때보다 좀 더 흐린 문구를 추출할 수 있고,기울어진 구도의 현수막 문구를 추출하는데 있어 더욱 좋은 성능을 내는 것을 확인할 수 있었습니다.
예를 들어, 성능 비교 예시(1)번에 보시면 위와 같이 기울어진 현수막이 있을 때, '자바/파이썬/빅데이터'라는 텍스트를 paddleOCR은 자바, 파이색, 4원이라고 인식했지만,ClovaOCR은 정확히 인식한 것을 볼 수 있었습니다.
또 이미지에 노이즈가 낀형태의 예시에서 ClovaOCR이 PaddleOCR보다 더욱 정확하게 검출해내는 모습을 볼 수 있습니다. PaddleOCR을 활용하여 다양한 기법으로 텍스트를 추출해보았지만
전반적인 성능은 ClovaOCR이 좋아 프로젝트에 활용하게 되었습니다.
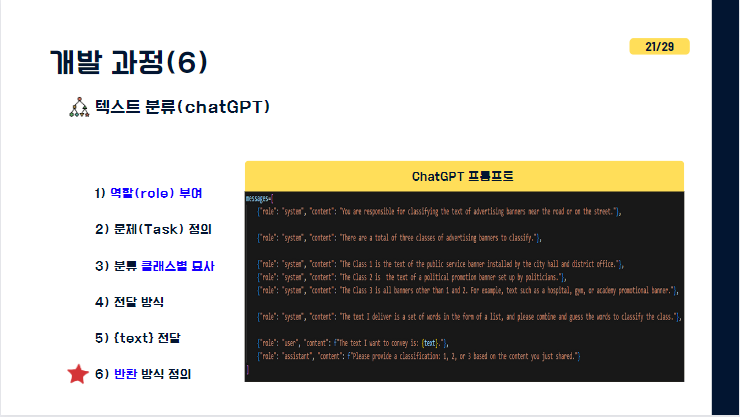
다음으로 보이시는게 chatGPT를 활용한 텍스트 분류입니다. 이러한 생성형 언어모델을 활용하는 요소 중 가장 중요한 것이 프롬프트, 어떻게 gpt를 잘 다루어 output을 뽑아낼 것이냐 인데
우측에 사진을 첨부하였지만 이 과정에 대해 자세히 설명해드리자면 우선, chatGPT에게 "너는 지금 길거리 광고 현수막을 분류하는 역할이야" 라고 역할을 명시해줍니다. 그 다음 어떤 문제, 어떤 텍스트 분류를 해결해야한다고 설명해주고 "Class1은 지자체에서 게시한 공익적인 현수막이야 "라는 식으로 클래스별 묘사까지 정확하게 언급해줍니다. 데이터를 전달한다음 마지막이 가장 중요한 요소인데 반환을 어떻게 받을 것인지 구체적으로 알려줘야 결과값이 나옵니다. 반환 방식을 제대로 정의하지 않으면 몇번을 돌려도 원하는 형식대로 도출되지 않기때문에 이부분이 가장 중요했습니다.

분류 결과 예시를 보여드리면 다음과 같습니다. 카테고리는 프레임, 공익(합법), 정치, 기타로 설정하였고 우측 예시 사진에서 보이시듯 chatGPT가 "생활쓰레기 배출" 과 같은 문구 때문에 공익, 즉 합법으로 하였다는 근거 또한 기록하여 관리자 입장에서 확인할 수 있게 저장하였습니다.
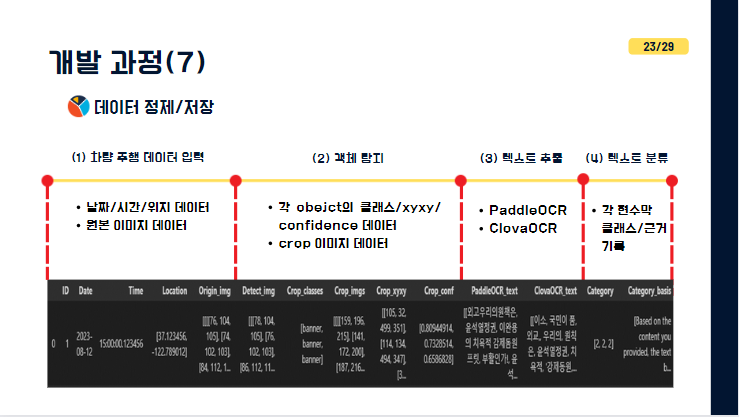
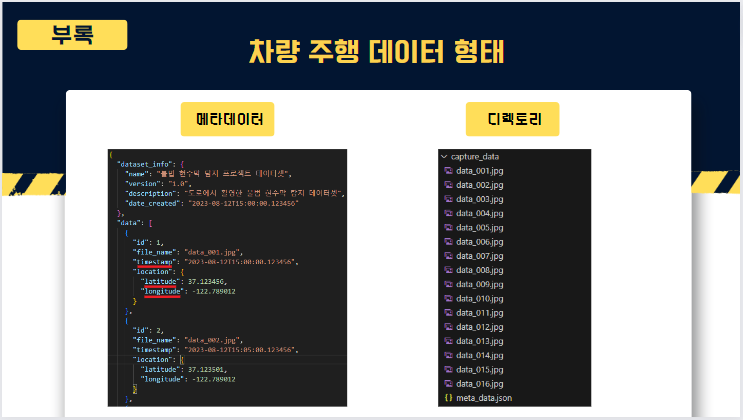
앞선 과정 순서대로 얻은 데이터들, 원본 데이터,객체탐지 데이터, OCR데이터,
텍스트 분류 데이터들 모두 기록하여 하나의 데이터프레임 형태로 저장하게 해놓았습니다.
(3초 대기)
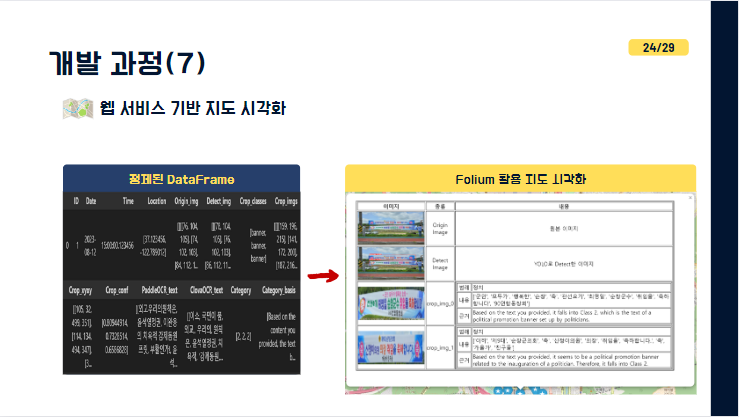
그리고 마지막으로 해당 Dataframe을 folium에 활용하여 촬영된 현수막데이터들의 위치와 현황을 한눈에 알 수 있도록 시각화하였습니다.
우측에 보시면 지도상 어떤 위치에 해당하는 detect된 현수막 이미지, 추출한 텍스트, 카테고리 등을 보실 수 있습니다.
(3초 대기)

시연 영상 (Youtube) : https://www.youtube.com/watch?v=UXZTP0jx1WQ&ab_channel=%EC%9E%84%EC%A0%95%EB%AF%BC
이렇게 하여 현수막 게시현황 시각화 시스템을 구축할 수 있었습니다. 이 서비스를 실제로 보여드리면서 설명드리겠습니다.
(강조)
현재 보이시는 현수막 현황이 저번주 토요일 오전8시~10시 사이 용인시 기흥구의 실제 게시 현황을 적용시킨 모습입니다.
현수막들을 종류별로 마커 색깔을 구분해 놓았기 때문에
1) 실제 순찰을 나가게 된다면 불법 현수막 버튼만 체크해서 불법 현수막을 기준으로 동선을 짜서 더욱 효율적인 업무를 수행할 수도 있고
2) 만약 선거철이라고 한다면 정치 현수막 버튼만 눌러서 정당 현수막들의 현황을 우선적으로 파악하며 단속할 수도 있고
3) 실제 불법 현수막이라고 판단될 시에 저희가 시간/날짜/이미지 모두 저장해 놓았기 때문에 이 자체가 증거물로써 확실한 근거에 의해 단속을 진행할 때 도움이 될 수 있다는 점을 말씀드립니다.
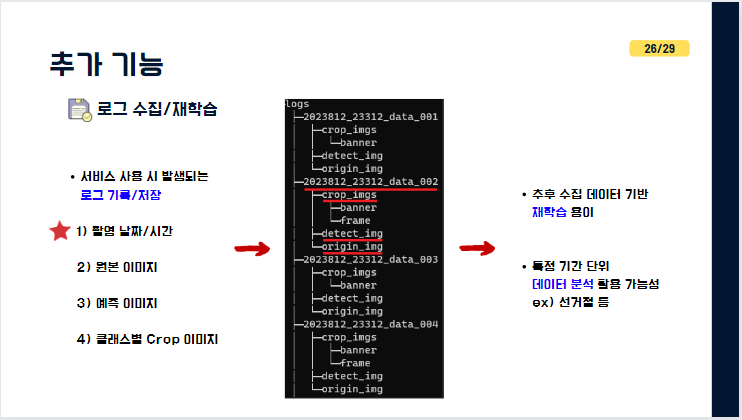
앞에서 보신 서비스 실제로 사용하게 여러번 사용하게 된다면 새로 들어오게 되는 이미지들과 로그들이 발생하게 되는데 이 데이터들을 자동으로 정리하여 어떤데이터가 언제 예측되었는지에 대한 기록과 원본이미지, 예측이미지(Detect이미지), 클래스별 crop이미지를 저장하도록 하였고
추후 재학습에 활용하기 용이하게 하였습니다. 이때도 사진에서 자세히 보시면 날짜/시간을 전부 기록해 놓았기 때문에 먼저 수집을 해놓고 특정한 기간, 예를 들어 선거철 기간에 부적합한 현수막이 있었는지 참고할 수 있는 기능이라고 보시면 되겠습니다.
한계점 및 개선사항입니다.
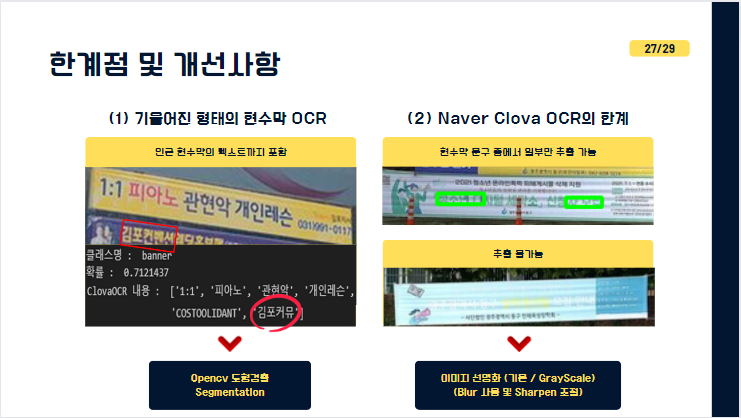
첫번째 한계점으로 하나의 현수막을 탐지할때 인근 현수막의 일부까지 포함되어 불필요한 텍스트가 추출 될 수 있다는 점입니다. 사진에서 보이시는 것처럼 '김포커뮤'가 추가된것을 보실수 잇습니다
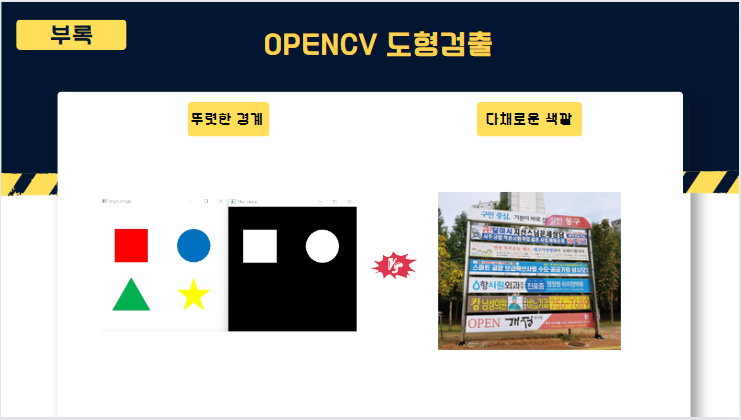
이 때 고안한 첫번째 방법으로 opencv를 통해 이미지의 도형을 검출하여 직사각형을 추출하는 방식이었지만, 이미지 자체에 다채로운 색깔이 모두 포함되어 있어 크게 효과를 보지 못하였습니다.
근본적인 해결방안으로 segmentation으로 현수막의 픽셀값들만 도출하는 방식으로 해결 가능하지만 오히려 box annotation이 더 accurate하다는 결과와 한정적인 시간관계상 1300여개 데이터를 다시 전처리할 수는 없어 이부분은 다음 기회에 시도해보는 것을 목표로 하고있습니다.
두 번째 한계점으로는 Naver OCR로도 추출하지 못하는 현수막 문구들입니다. 보시는 바와 같이 현수막 문구 중에서 일부만 추출 가능하거나 혹은 아예 추출 불가능한 경우가 있었습니다.
이에 대한 개선사항으로는 이미지의 원본이미지와 흑백처리한 이미지를 가지고 Blur를 넣어 선명화 작업을 진행하거나 sharpen을 더 넣어보는 형식으로 해결해볼 생각합니다.

이번 프로젝트 개발과정과 발표 에 활용한 참고문헌들입니다

이상으로 발표 마치겠습니다. 감사합니다.
<부록>




프로젝트 정말 재미잇게 잘 봤습니다!! 혹시 텍스트 분류 단계에서 ChatGPT를 활용한 특별한 이유가 있을까요?