안녕하세요, 밍기뉴와제제입니다.
드디어 논문 리뷰를 시도해봅니다. MLP-Mixer 리뷰 이후로 처음 리뷰하네요. 대충 계산해보니 반 년의 시간이 흘렀습니다. 그동안 많은 일이 있었죠.
반 년의 시간동안 제가 접한 논문의 개수는 꽤 많았습니다. 특히 논문을 써야하니까 관련 주제로 많이 읽을 수 밖에 없더라구요. 그런데 이걸 정리해서 리뷰를 할 시간이 없어서 포스팅을 할 수 없었습니다. 아쉽네요.
그래도 입시랑 논문 저술을 해결하면 다시 리뷰를 열심히 할거라 믿었습니다. 근데 그게 어렵더군요. 해야지...해야지...하다보니 합격 소식을 듣고 한 달의 시간이 흘렀으나 리뷰 목적으로 올린 글은 하나도 없었습니다.
아, 어떻게든 논문을 읽고 리뷰 해야겠구나 생각했습니다. 그래서 큰 마음 먹고 '월간 리뷰'라는 것을 해보기로 결심했습니다.
앞으로 매 달마다 논문을 한 편 골라서 리뷰를 할 예정입니다. 물론 읽는 건 여러 논문을 읽을겁니다. 그...러겠죠?
아무튼, 리뷰를 열심히 해보겠습니다. 아자아자!
이번에 리뷰할 논문은 'DiffusionDet: Diffusion Model for Object Detection'입니다. 이름 그대로 Object Detection, 다시 말해 객체 탐지을 위한 Diffusion model을 제안한 논문입니다.
Diffusion model은 주로 이미지 생성 등의 task에 많이 이용됩니다. 객체 탐지에 사용된 적은 한 번도 없었죠. 저자들은 객체 탐지에 Diffusion model을 최초로 제안하였고, 괜찮은 결과를 보여줌을 증명했습니다.
논문이 꽤 쉽게 쓰여있어서 Diffusion model에 대해 제대로 공부하지 않은 저도 논문을 이해하는데 큰 어려움이 없었습니다. 이 글을 보시는 독자 여러분 역시 DiffusionDet을 쉽게 이해하실 수 있을 것으로 생각됩니다.
그럼 지금부터 본격적인 리뷰를 시작해보겠습니다.
1. Introduction
객체탐지는 입력 받은 이미지에 존재하는 객체의 위치와 종류를 알아내는 task입니다. 딥러닝을 이용한 컴퓨터비전의 연구가 시작되고 얼마 안된 시점부터 연구가 진행되었습니다. 꽤 오래 전부터 연구되어온 것이죠.
(객체 탐지를 제안한 주요 논문들입니다. 2018년까지 나온 방식만 정리했는데도 불구하고 아주 많습니다. 출처)
사람들은 객체 탐지를 수행하기 위해 다양한 방식을 제안했습니다. 그 중 유명한 것을 꼽자면 anchor box를 제안한 Faster R-CNN, 하나의 파이프라인으로 연산을 끝내는 YOLO, Attention mechanism을 기반으로 제작된 DETR 등이 있겠습니다.
still have a dependency on a fixed set of learnable queries.
아무튼, 딥러닝 알고리즘을 이용한 객체 탐지는 다양한 해결방식들이 제안되었습니다. 그러나 제안된 방식들은 모두 하나의 공통점을 가지고 있는데요, 바로 '최대 N개의 객체를 탐지하도록 설계된 모델은 실제 추론할 때도 최대 N개의 객체만 탐지할 수 있다'입니다.
앞서 제안된 방식들은 고정된 개수의 '무언가'를 이용해 객체 탐지를 수행합니다. 이 '무언가'를 학습 가능한 parameter로 조정하는 방식으로 객체의 bounding box(이하 bbox)를 찾는 것이죠.
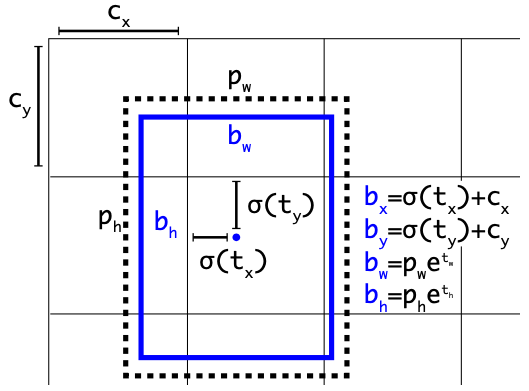
위 그림은 YOLOv3가 객체의 bbox를 예측하는 과정을 나타낸 그림입니다. 특정 위치에 있는 고정된 크기의 anchor가 있으면 이를 조정하는 bx, by...bh, bw를 예측하여 최종 bbox를 정의하죠.
여기서 예측에 쓰이는 anchor의 개수는 사람들이 정의합니다. 고정된 개수를 가지고 있는 것이죠. 그렇기에 예측할 수 있는 객체의 최대 개수는 상한선이 존재했습니다.
예를 들어, 학습시킬 때 최대 400개의 객체를 탐지하게끔 설계된 방식은 500개의 객체가 있는 이미지를 보여줘도 최대 400개만 탐지할 수 있는 것이죠.
엄청나게 많은 객체가 포함된 이미지로 구성된 데이터셋(예를 들면 1만명의 사람이 있는 사진으로 구성된 데이터셋)이 없기 때문에 성능을 측정할 때는 이러한 제약이 크게 우려가 없으나 실제로 학습된 모델을 이용하는 상황에서는 상황에 따라 큰 아쉬움을 가질 수 있겠다는 생각이 들었습니다.
random boxes를 이용해 객체를 탐지하자
그래서 저자는 '랜덤 박스'를 이용해 객체를 탐지하는 모델을 설계했습니다.
저자들은 랜덤으로 생성한 bbox들을 가지고 하나둘씩 제거하거나 위치와 크기를 수정하는 과정을 거치며 최종적으로 실제 객체를 둘러싼 bbox만 남김으로써 객체 탐지를 수행하는 방식을 제안했습니다.
이러한 방식은 기존의 방식과 달리 탐지가 가능한 객체의 수에 제한이 없다는 장점을 가지고 있습니다. 왜냐하면 맨 처음에 랜덤하게 생성한 뒤 실제 존재하는 객체의 개수만큼 bbox를 줄여나가는 방식으로 연산을 수행하기 때문이죠.
논문에서는 이를 'noise-to-box'라고 정의했으며 does not require heuristic object priors nor learnable queries, further simplifying the object candidates and pushing the development of the detection pipeline forward.라는 장점을 가지고 있다고 말하고 있습니다.
Denoising diffusion method
저자가 제안하는 방식을 그림으로 나타내면 다음과 같습니다.
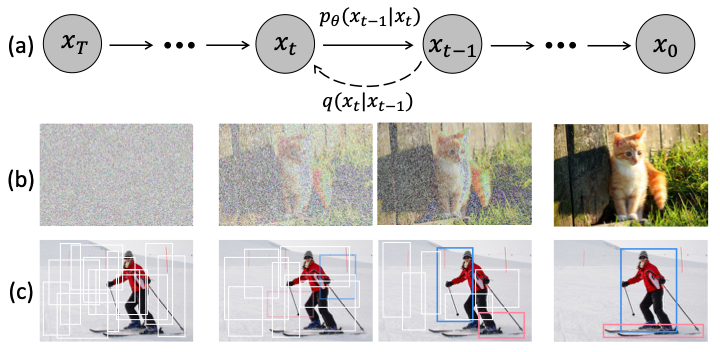
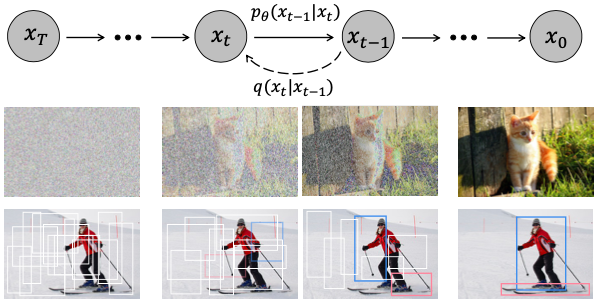
(c)와 같이 점차적으로 bbox를 줄여나가는 것이 저자가 제안한 방식입니다. 이는 마치 noise를 점차적으로 이미지로 만드는 (b)와 많이 유사한 과정을 가지고 있죠.
저자는 자신들이 생각한 noise-to-box는 denoising diffusion model에 있는 noise-to-image과 유사하다고 말했습니다.
최근들어 관심을 받고 있는 diffusion model은 generation task에서 큰 성공을 거두었고 image segmentation과 같은 perception task에서 이를 이용한 연구를 시작했으나 아직까지 object detection에선 diffusion model을 사용한 연구가 없다고 말했습니다.
그래서 저자는 diffusion model을 이용해 object detection을 해결하는 방식을 연구하였고, 그 결과 DiffusionDet을 설계하는데 성공, 이렇게 논문을 통해 사람들에게 해당 방식을 제안할 수 있었습니다.
Contribution
저자는 Introduction의 마지막에 자신들의 Contribution을 정리했습니다. 실은 contribution을 설명하기 전에 DiffusionDet에 관한 간단한 설명이 있었으나 이는 Approach에서 자세히 다룰 것이기에 스킵하겠습니다.
아무튼, 저자들이 말하는 Contribution은 다음과 같습니다.
- Object Detection을 generative denoising process로 해결하고자 시도하였고 이를 위해 diffusion model을 사용했음. 이런 시도는 우리가 처음임.
- 우리가 제시한 noise-to-box 방식(논문에서는 paradigm이라 하는데 적절한 해석을 찾지 못했습니다)은 decoupling training and evaluation stage for dynamic boxes and progressive refinement과 같은 장점을 가지고 있음.
- DiffusionDet을 MS-COCO랑 LVIS 1.0에서 성능 측정을 해봤는데 기존 방식들과 비교했을 때 꽤 괜찮은 성능이 나왔음.
여기까지 Introduction이었습니다.
2. Approach
다음으로 DiffusionDet의 구조, 학습 방식 등 저자들이 제안한 방식에 대한 모든 것을 설명하는 Approach 파트를 설명드리도록 하겠습니다.
2.1 Preliminaries
DiffusionDet을 살펴보기 전에 알면 좋을 것들을 몇가지 살펴보겠습니다.
Object Detection
먼저 DiffusionDet이 수행하는 task인 Object Detection이 뭔지 알아야 합니다.
객체탐치라는 task는 이미지 x를 입력받으면 해당 이미지 속 객체의 bounding boxes b와 각 box의 class를 나타내는 category labels c를 예측하는 것을 의미합니다.
이 때 bounding box를 정의하는 방법은 여러가지가 있으나 DiffusionDet은 예측하는 bounding box를 b_i = (center_x, center_y, width, height)로 정의했다고 합니다.
여기서 [center_x, center_y]는 bounding box의 중심 좌표, width와 height는 box의 높이, 너비를 의미합니다.
Diffusion model
DiffusionDet의 핵심 요소인 Diffusion model에 대해서도 알아야 합니다.
Diffusion model은 non-equilibrium thermodynamics에서 영감을 받은 확률 기반 모델의 한 종류입니다.
sample data z_0에 점차적으로 noise를 더해 z_t를 만든 뒤 z_t로 z_0을 예측하게끔 모델을 학습시키며 추론 단계에서는 iterative way, 다시 말해 연산을 계속 반복해서 z_0을 예측한다고 합니다.
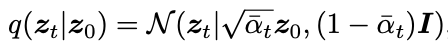
저자는 z_0으로 노이즈 z_t를 생성하는걸 이렇게 식으로 표현했습니다.
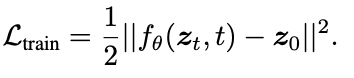
이건 학습시킬 때 사용하는 loss function입니다.
저자들은 앞서 말했듯 diffusion model로 object detection을 수행하고자 DiffusionDet을 제안했습니다. 이 때 z0은 bounding box를, z_t는 무작위로 생성된 random box를 의미합니다.
실은 저도 Diffusion model을 들어만 봤지 자세히 알지 못합니다...공부가 필요합니다.
구글링을 해보니 여기에서 diffusion model을 잘 설명하고 있는거 같습니다. 열심히 공부해야겠네요.
2.2 Architecture
DiffusionDet의 대략적인 구조는 다음과 같습니다.
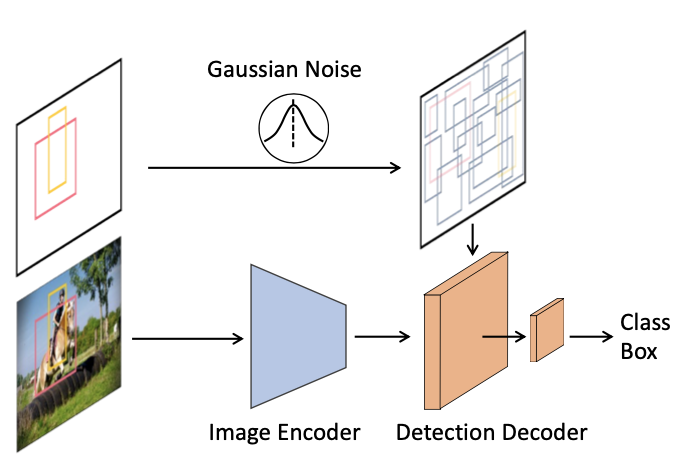
encoder-decoder 구조를 기반으로 하고 있습니다.
encoder에 뽑힌 feature와 랜덤으로 생성된 random box를 이용해 decoder를 반복 연산하여 최종 bounding box를 생성하는 연산 구조를 있죠.
저자는 raw image에서 바로 반복 연산을 통한 bounding box 탐지를 하는건 계산량이 많기 때문에 feature map에서 객체 탐지를 수행하고자 위와 같은 구조를 제안했습니다.
encoder에서 한 번 뽑힌 feature로 반복 연산을 수행해 정제된(?) bounding box를 얻겠다는 전략을 취한 것이죠.
Image encoder
먼저 이미지의 feature를 추출하는 encoder부터 알아보겠습니다. 이미지의 특성을 추출하고자 설계된 model은 매우 많습니다. 저자들은 그 중 ResNet과 Swin을, 정확히 말하면 두 model에서 이미지의 feature map 추출을 담당하는 부분을 encoder로 사용했습니다.
Detection decoder
Detection decoder는 랜덤으로 생성한 bounding box로 인해 crop된 feature map들을 입력으로 받습니다. 그러니까...
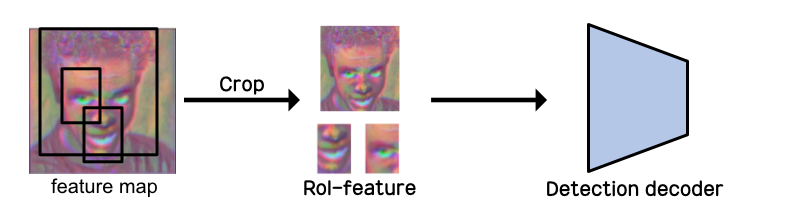
이런식으로 연산이 진행된다는 것이죠. 그림과 같이 RoI feature를 입력받은 decoder는 이미지에 존재하는 객체의 bounding box와 class종류를 예측합니다.
저자는 Sparse R-CNN 등의 방식에 영감을 받아 6개의 cascading stage로 구성된 decoder를 설계했습니다. 그러면서 Sparse R-CNN과 비교했을 때 자신들의 detection deocoder가 좋은 점 3가지를 제시했는데요, 다음과 같습니다.
- DiffusionDet은 사용할 수 있는 bounding box의 개수에 제한이 없다. 허나 Sparse R-CNN은 추론 과정에서 고정된 개수의 box만 사용할 수 있다.
- DiffusionDet은 bounding box(proposal box)의 정보만 있어도 연산이 가능하지만 Sparse R-CNN은 bounding box에 해당하는 proposal feature도 필요하다
- DiffusionDet은 연산 중 객체 탐지에 사용하는 head, 다시 말해 decoder를 여러번 사용할 수 있으며 이전 단계에서 연산한 결과를 다음 연산에 반영할 수 있으나 Sparse R-CNN은 head를 한 번만 사용한다.
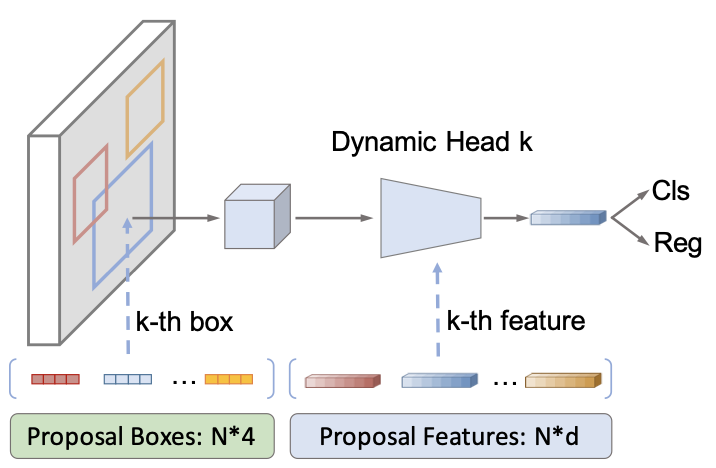
이해를 돕기 위해 Sparse R-CNN의 overview를 첨부하였습니다.
2.3 Training
다음으로 학습 과정을 말씀드리도록 하겠습니다.
DiffusionDet은 [랜덤으로 생성된 bounding box -> ground-truth bounding box]을 원하고 있습니다.
그렇기에 ground-truth bounding box를 '랜덤으로 생성된 bounding box'로 만들어주는 연산이 필요합니다. diffusion을 해야하는 것이죠.
저자는 앞서 말한 noise box 생성을 포함한 전체적인 학습 과정을 다음의 pseudo code로 정리하였습니다.
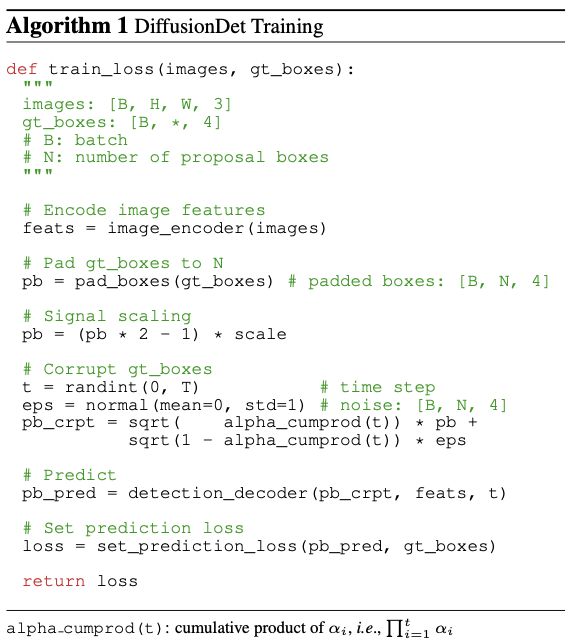
저도 제가 잘 이해했는지 잘 모르겠지만, 한 줄씩 설명을 해보겠습니다.
-
feats = image_encoder(images) : encoder에서 images의 feature map들을 뽑아냅니다
-
pb = pad_boxes(gt_boxes) : ground-truth bounding box, 다시 말해 정답에 해당하는 bounding box와 같이 사용할 bounding box를 랜덤으로 생성합니다. [원래 있던 정답 bounding box + 새로 만드는 bounding box]의 개수가 N_train이 되게끔 생성합니다. 저자는 다양한 padding 전략을 사용했으며 그 중 'concatenating random boxes'이 제일 효과적이었다고 말했습니다.
-
pb = (pb 2 - 1) scale : ground-truth bounding box를 scaling해줍니다. Object detection은 image generation task를 수행할 때보다 상대적으로 큰 scale을 사용하는걸 선호한다고 하는데...자세히는 잘 모르겠네요.
-
t = randint(0, T) ~ pb_crpt = ... : Box corruption을 위한 과정입니다. N_train개의 박스에 Gaussian noises를 추가합니다. 이 때 noise의 scale은 앞서 보여드린
이 식의 a_t로 제어된다고 합니다. -
pb_pred = detection_decoder(pb_crpt, feats, t) : bounding box를 예측합니다.
-
loss = set_prediction_loss(pb_pred, gt_boxes) : Loss를 계산합니다. DiffusionDet은 학습 과정에서 each ground-truth bouding box에 대해 N_train개의 bounding box를 예측합니다. 만약 grund-truth bounding box가 2개면 총 2*N_train개의 bounding box를 예측하는 것이죠. 각 객체별로 예측한 bounding box중 가장 loss가 적은 k개의 box를 골라 'pred_bbox'로 정의한 뒤 가중치 업데이트에 사용합니다.
2.4 Inference
다음으로 inference 단계입니다. DiffusionDet의 infetrence는 noise box를 객체의 bounding box로 denoising하는 과정이라 볼 수 있습니다. 저자는 inference의 pseudo code도 제작하였습니다. 다음과 같습니다.

한 줄씩 설명해보겠습니다.
- feats = image_encoder(images) : images를 encoder에 넣어 feature map들을 얻습니다.
- pb_t = normal(mean=0, std=1) : 표준 정규분포(Standard Gaussian Distribution)에서 random bounding box들을 뽑아냅니다. 이 때 뽑아내는 box의 개수는 임의로 설정할 수 있습니다. 앞서 학습 과정에서 구한 N_train개만큼 random하게 생성할 의무가 없는 것이죠.
- times = ... ~ time_pairs = ... : decoder로 얼마나 반복해서 연산할 것인지 그 횟수를 구합니다.
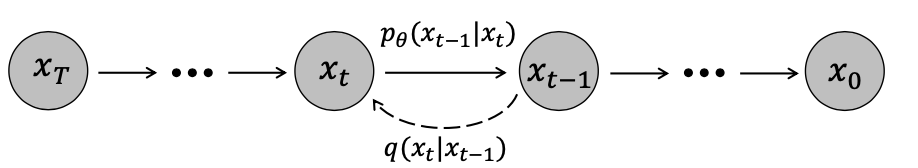
이 그림을 보면 이해에 도움이 되실듯 합니다. 여기서 중요한 것은, 연산 횟수를 임의로 설정할 수 있다는 겁니다. 정확도를 원한다면 연산 횟수를 늘리고 속도를 원한다면 연산 횟수를 낮추면 되는 것이죠. - pb_pred = detection_decoder(pb_t, feats, t_now) : 매 step마다 decoder를 이용합니다. 맨 처음 step에서는 표준 정규분포에서 뽑아낸 random box를 pb_t로 이용하지만 다음 step부터는 이전 step에서 얻은 pb_t를 입력값으로 넣어줍니다.
- pb_t = ddim_step(pb_t, pb_pred, t_now, t_next) : 현재 step에서 예측했다고 할 수 있는 bounding box입니다. decoder에서 얻은 pb_pred를 DDIM에 넣어서 pb_t를 휙득합니다.
- pb_t = box_renewal(pb_t) : 매 step마다 생성된 pb_t는 크게 'desired'와 'undesired' bounding box로 분류할 수 있습니다. 이 중 desired는 적절히 객체의 위치와 종류를 예측한 bounding box를 의미하고 undesired는 그렇지 않은 box를 의미하죠(논문에서는 distributed arbitrarily라고 표현했습니다). 저자는 desired와 undesired bounding box를 그대로 다음 step에 사용하는 것은 benefit을 가져오지 못할 것이라 말했습니다. 그 이유는 학습 과정의 corruption과는 달리 우리가 의도하지 않은 방향으로 만들어진 애들이 아니기 때문이라고 하는데요...어떤 의미인지는 알겠는데 확 와닿지는 않습니다. 아무튼, 저자는 pb_t를 그대로 다음 step에서 쓰는 대신 'box renewal' 과정을 거친 pb_t를 다음 step에서 사용하기로 했습니다. box renewal는 undesired bounding box를 normal(mean=0, std=1)과 같은 gaussian distribution에서 뽑아낸 random box로 대체하는 과정입니다. 참고로 desired와 undesired를 구분하는 기준은 특정 threshold라고 하네요.
step을 거치며 얻은 pb_t는 맨 처음 random하게 생성한 bounding box와 개수가 같습니다. 나중에 Experiments에서 설명드리겠지만, pb_t에 있는 bounding box 중 실제 객체를 정확히 탐지한 bounding box만 살리는 작업은 nms를 이용합니다.
저자는 inference의 마지막 부분에서 DiffusionDet이 생성하는 random box와 연산 횟수를 임의로 조정할 수 있다는 점을 강조했습니다.
이러한 값들을 학습 당시 설정한 값으로 고정해야만 하는 기존 방식들과 비교했을 때 큰 차별점이기 때문에 계속해서 강조하는게 아닌가 생각됩니다.
생각해보면 정말 큰 장점인거 같습니다. 학습을 한 번만 시켜도 여러 조건에서 성능을 측정할 수 있다는게 제일 먼저 생각나네요. 그리고 모델을 inference하는 기기의 성능에 따라서 유동적으로 연산 횟수를 수정할 수 있으니 deploy에서도 유리하다는 장점을 가질 수 있지 않나 생각됩니다.
3. Experiments
다음으로 DiffusionDet의 성능을 측정한 실험들의 결과에 대해 설명드리도록 하겠습니다.
저자들은 제안한 방식인 DiffusionDet을 DETR 등 object detection을 수행하는 모델 중 유명한 것들과 성능을 비교하였으며 Ablation Study도 수행하였습니다. 어우...정말 힘들었을 것으로 생각됩니다.
저자들은 앞서 Introduction에서 말씀드린 것과 같이 MS-COCO와 LVIS 1.0 데이터셋을 이용해 성능을 측정했습니다. 그리고 경쟁력 있는 metric을 얻을 수 있었죠.
그럼 지금부터 하나씩 설명을 해보도록 하겠습니다.
3.1 Implementation Details.
어떤 세팅으로 DiffusionDet을 설계하고 Training하고 inference 하는지 설명해주는 부분입니다.
Training schedules
학습 부분에 대한 설명이 먼저 나옵니다. 다음과 같이 정리할 수 있습니다.
- Image encoder : ImageNet-1k로 학습시킨 ResNet, ImageNet-21k로 학습시킨 Swin을 encoder의 초기 parameter로 설정했습니다.
- Detection decoder : Xavier initialization 방식으로 초기화했습니다.
- Optimizer : 초기 학습률 2.5 x 10^(-5)인 AdamW를 사용했습니다.
- Weight Decay : 10^(-4)
- Batch size : 16(8대의 GPU 사용)
- 학습 전략 : MS COCO의 경우, parameter를 총 450K회 업데이트 하며 350K, 420K번 째 업데이트를 할 때 학습률을 10으로 나눕니다. 그리고 LVIS 1.0의 경우, parameter를 총 210K, 250K, 270K회 업데이트를 수행하게끔 하였으며 학습률 조정은 하지 않습니다.
- Data augmentation : random horizontal flip, random crop augmentations, scale jitter of resizing이 있습니다.
Inference details
MS COCO를 사용할 경우 100개의 bounding box를, LVIS 1.0를 사용할 경우 300개의 bounding box를 생성하며 모든 step이 끝난 이후 휙득한 예측 bounding box는 nms를 이용해 괜찮은 것만 걸러내는 작업을 수행합니다.
3.2 Main Properties
앞서 DiffusionDet은 Detection decoder의 연산 횟수와 생성하는 random bounding box의 개수를 조정할 수 있음을 알아냈습니다. 3.2 항은 연산 횟수와 생성하는 random box의 개수에 따른 성능 변화에 관해 설명하는 내용이 담겨 있습니다.
Dynamic boxes.
먼저 생성하는 bounding box 개수에 따른 성능 변화입니다. 저자들은 학습 중에 300개의 bounding box를 생성했던 DiffusionDet과 DETR을 이용해 bounding box를 [50, 100, 300, 500, 1000, 2000, 4000]개 생성하며 성능을 비교하였습니다.
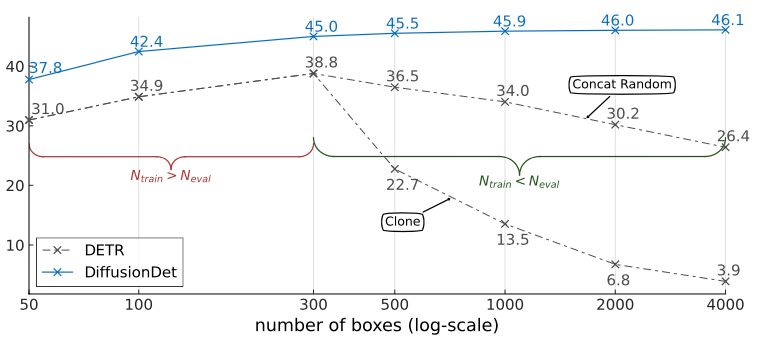
측정 결과는 위 그림과 같습니다.
DiffusionDet은 생성하는 box의 개수가 늘어날 수록 성능이 점차적으로 증가하지만 DETR은 학습에 사용했던 bounding box의 개수인 300개가 넘어가는 순간부터 성능이 떨어지는 것이 보입니다.
왜 이런 이유가 발생하냐면, 저자들은 생성해야하는 bounding box의 개수가 DETR이 생성할 수 있는 개수(300)을 초과할 경우, [N_eval(성능 평가를 위해 생성해야 하는 box의 개수) - N_train(학습 중에 생성한 box의 개수)]개의 bounding box는 랜덤으로 생성(Concat Random)하거나 생성했던 box에서 복사(Clone)하였기 때문입니다.
그럼 왜 성능이 떨어지는 것일까요? 필요한 bounding box를 모두 생성하지 못하는 상황에서 추가로 생성해야하는 bounding box를 만들 때 의미 있는 연산을 하지 않았기 때문입니다.
Clone은 이미 만들었던 box를 복제했기 때문에 추가로 필요한 bounding box에 대해 의미 있는 연산이라 할 수 없습니다. Diversity는 그나마 기존에 있던 box와는 다른 bounding box를 만들 수 있기 때문에 성능 하락이 비교적 덜했던 것이죠.
저자는 이를 'Random으로 생성하여 예측값의 Diversity가 Clone을 할 때보다 더 늘어나기 때문'이라고 말했습니다.
저는 Concat Random 방식은 괜찮은 대처법(?)이라 생각하나 Clone은 아쉬운 방식인 것 같습니다. '이런 방식으로도 추가적으로 필요한 bounding box를 땜빵할 수 있다'는 걸 보여주기 위함인건가 싶기도 하네요.
아무튼, 중요한 것은 생성할 수 있는 bounding box가 제한된 DETR은 그 제한선을 넘기는 순간 성능이 하락하지만 DiffusionDet은 생성할 수 있는 bounding box에 제한이 없으며 그 개수가 늘어날 수록 성능이 우상향 한다는 것입니다.
그런데 생성하는 box의 단위가 늘어날 수록 성능 향상이 폭이 좁아집니다. 그리고 DETR도 box의 단위가 늘어날 수록 성능 하락의 폭이 좁아집니다.
y축이 log-scale이라 그런걸까요? 라기에는 y축이 AP네요. 그러면 어떤게 log-scale인 것일까요...
Progressive refinement.
다음으로 Decoder의 연산 횟수에 따른 성능 변화를 알아보도록 합시다.
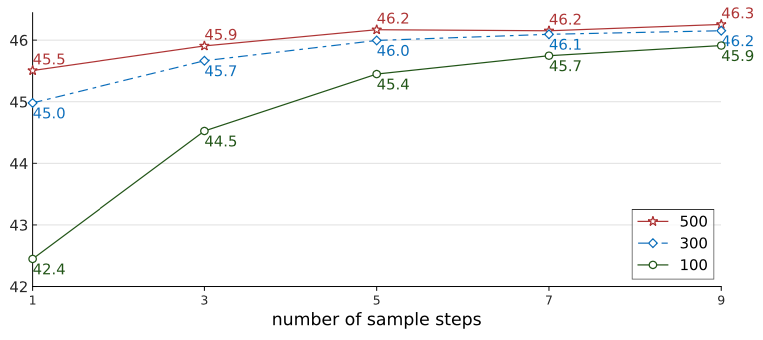
학습 과정에서 300개의 bounding box를 생성한 DiffusionDet으로 평가 과정에서 생성한 bounding box를 [100, 300, 500]개로 설정할 때 decoder의 연산 횟수 별 성능을 정리한 표입니다. 말로 설명하니 엄청 복잡하네요.
decoder의 연산 횟수가 늘어날 수록 성능이 향상하는게 보입니다.
연산 횟수에 따른 성능 향상의 폭은 생성하는 bounding box의 개수가 100일 때 제일 높은데 최대 성능은 bounding box를 500개 생성했을 경우에 제일 높은 것을 알 수 있습니다.
그러니 이 실험에서는 DiffusionDet은 decoder의 연산 횟수를 늘릴 수록 성능이 상승한다는 것을 확인할 수 있으며, Dynamic boxes항목에서 살펴본 실험에서 얻은 결론과 종합해서 써보면 다음과 같다는 사실을 알 수 있습니다.
DiffusionDet은 생성하는 bounding box의 개수를 늘리거나 decoder의 연산 횟수를 늘리면 성능이 상승한다.
3.3 Benchmarking on Detection Datasets
다음으로 MS-COCO와 LVIS 1.0에서 다른 모델들과 성능을 비교한 결과를 간단히 살펴보도록 하겠습니다.
MS-COCO
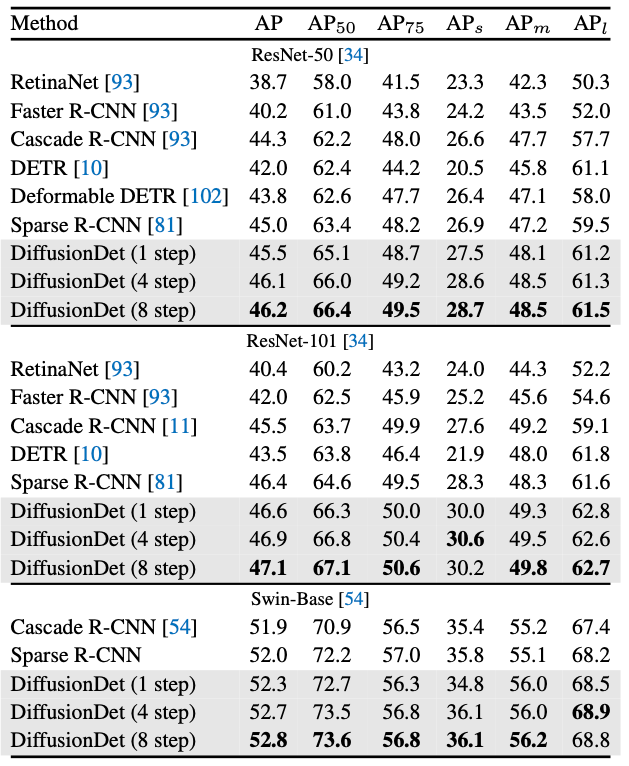
MS-COCO의 val set으로 측정하였습니다. encoder의 종류를 바꿔가며 측정하였으며 어떠한 경우에도 항상 경쟁력 있는 수치를 보여주는 것을 확인할 수 있습니다.
LVIS 1.0
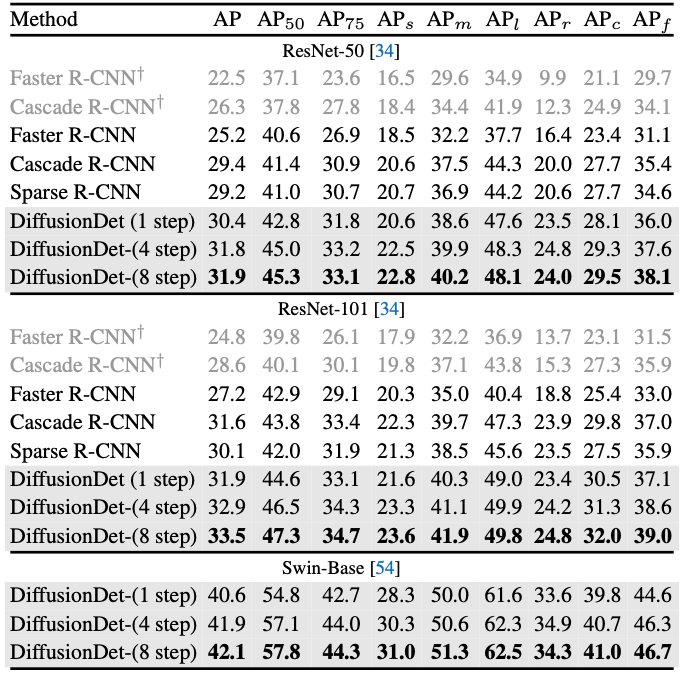
LVIS 1.0의 val set으로 측정했습니다. 여기서도 encoder를 바꿔가며 측정하였고 모든 경우에서 항상 좋은 수치를 보여줬습니다.
표에 보이는 step은 Detection decoder의 연산 횟수입니다.
3.4 Ablation Study
저자들은 Ablation Study에 많은 공을 들였습니다.
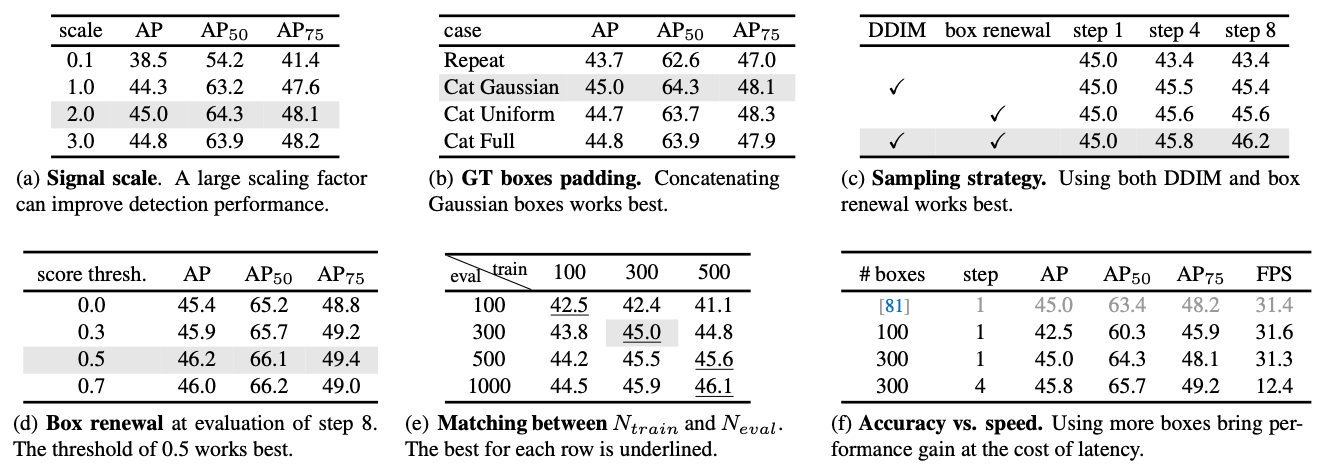
총 6종류의 실험을 하였습니다. 학습에 사용한 DiffusionDet은 ResNet-50 with FPN을 encoder로 사용하고 학습 중에 300개의 bounding box를 생성하였습니다.
하나씩 설명해드리려고 했는데 어...첨부한 표들의 각 항목을 글로 나열하고 있어서 굳이 안써도 되겠구나 싶은 생각이 들었습니다.
그런데 이 항목은 첨부한 그림에 없어서 따로 설명을 하도록 하겠습니다. 뭐냐면
Random seed.
저자들은 Random Seed만 다르게 하며 DiffusionDet의 학습을 수행하였습니다. Random Seed에 대해 언급한 논문을 처음 본거 같습니다. 이거 측정하면서 학습을 꽤 많이 돌렸을텐데...대단합니다 진짜.
아무튼, 결과는 다음과 같습니다.
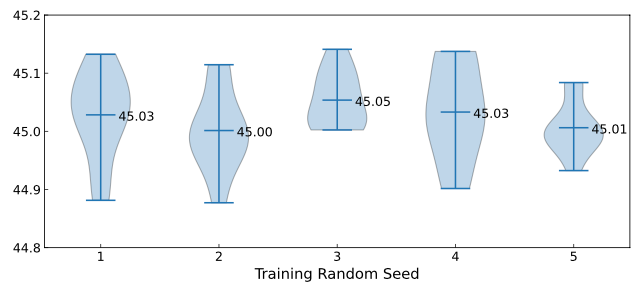
Seed 별로 10번씩 학습한 뒤 각 Seed별로 성능의 평균을 나타냈습니다. 모든 Seed들이 45.0 언저리에 머물러 있는 것을 알 수 있습니다.
이말은 즉, DiffusionDet이 RandomSeed의 변화에 Robust하다는 뜻입니다. 이러기 쉽지 않습니다. 논문에 써서 어필할만 했네요.
4. Conclusion and Future Work
논문의 마무리 단계입니다.
저자들은 자신들이 제안한 DiffusionDet의 내용을 간단히 정리한 뒤 향후 진행 방향으로 좋을 것들을 제시했습니다.
DiffusionDet은 객체 탐지와 같은 object-level recognition task에 Diffusion model을 처음 사용한 사례이며 그 가능성을 충분히 보여줬습니다.
그렇기에 Diffusion model을 object tracking, action recognition과 같은 video-level tasks에 사용해보면 이득이 있을 것이라 말했습니다.
그리고 또다른 발전 방향으로는 DiffusionDet을 close-world에서 open-world 혹은 open-vocabulary object detection으로 확장하는 것도 제시했는데요, 이건 음...뭔 뜻일까요.
그래서 찾아봤습니다. 찾아보니 open-world object detection은 '특정 데이터셋으로 학습된 모델에게 새로운 클래스를 가르쳐주어 탐지할 수 있는 클래스의 종류를 늘리는 모델을 만드는 것'을 뜻하네요. 사람과 같다는 생각이 듭니다.
그리고 open-vocabulary object detection은 '특정 데이터셋으로 학습된 모델이 추론 과정에서 unbounded (open) vocabulary로 정의된 클래스들을 탐지하는 것'을 의미하네요.
두개 다 어려워 보이지만, 지금 딥러닝 알고리즘을 기반으로 하는 방식들이 발전하는 속도라면 금방 수행할 수 있지 않을까 기대해봅니다.
후기
오랜만에 논문 리뷰를 해봤습니다. 힘듭니다.
그래도 하고 나니까 뿌듯하네요. 이렇게 11월의 논문 리뷰를 수행했습니다. 하루만 늦었다면 12월의 리뷰가 되어 1월에 다음 리뷰를 쓰면 되는데 11월 마지막 날에 리뷰를 하게 되어 12월의 논문 리뷰도 써야 하는 상황이 되었네요.
그래도 후회는 없습니다. 12월 내에 꼭! 논문 리뷰를 해보도록 하겠습니다.
그럼 다음 리뷰에서 뵙겠습니다.
