알고리즘
1.[알고리즘] 빅오 표기법(big-O notation)이란?
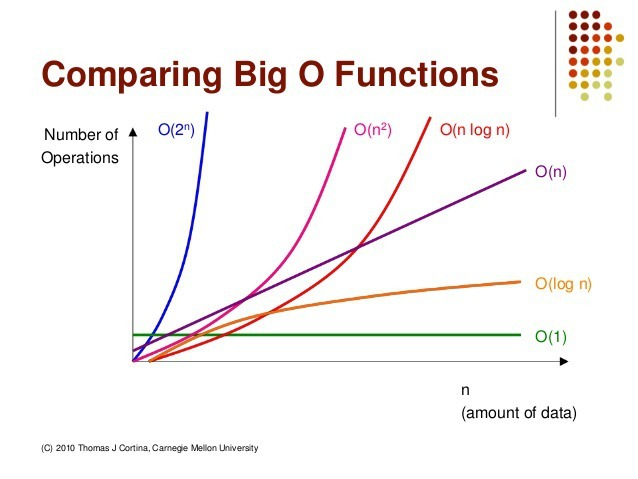
알고리즘의 복잡도를 판단하는 척도는 시간 복잡도와 공간 복잡도가 있다. 그 중 시간 복잡도는 알고리즘 내 연산의 횟수와 밀접한 관계가 있다. Big-O(빅 오) 표기법 알고리즘 최악의 실행 시간을 표기한다. 가장 많이 사용하는 표기법이다. 최소한 보장되는 성능을 표기
2.[알고리즘] 선택, 버블, 삽입, 계수 정렬

맨 앞 인덱스부터 기준이 된다 기준 보다 뒤에 있는 값들을 기준과 비교하면서 기준보다 작을 경우 기준과 해당 값을 swap해준다. swap 후에는 기준이 그 다음 인덱스로 바뀐다. 장점구현이 간단하고, 정밀 비교 가능하다.교환 횟수가 적어 내림차순 데이터 → 오름차순
3.[알고리즘] direct, pattern, bucket 활용
direct 배열을 이용해 2차원 배열에서 한 좌표를 기준으로 특정 위치에 있는 좌표를 확인할 수 있다. direct를 활용한 문제💡SWEA 달팽이 숫자SWEA Ladder1for문을 이용해 한 배열 내에서 특정 패턴이 있는지 없는지 찾을 수 있다. 함수로 분리하면
4.[알고리즘] 이진 탐색(Binary search)
이진 탐색 알고리즘이란 정렬된 데이터 내에서 특정 값을 검색할 때 탐색 범위를 절반씩 좁혀가며 탐색하는 알고리즘이다. 탐색 범위가 반씩 줄어들기 때문에 O(logN)의 시간복잡도를 가진다. 단, 정렬된 데이터에서만 쓸 수 있다는 단점이 있다. 필요한 변수start: 탐
5.[알고리즘] 파라메트릭 서치(Parametric search)
Parametric search는 이분(이진) 탐색과 매우 유사하다. Parametric search란 쉽게 말해서, 최적화 문제를 결정 문제로 변형하여 이분(이진) 탐색을 통해 해결하는 것을 말한다.Parametric search 적용 조건최적화된 값을 요구하는 문제
6.[알고리즘] 슬라이딩 윈도우(Sliding window), 투 포인터(Two pointer)
슬라이딩 윈도우는 일정한 길이의 범위를 이동하여 조건에 맞는 값을 찾는 알고리즘이다. 한 칸씩 이동 하기 때문에 공통된 부분은 유지하고 처음과 끝 원소만 갱신하여 유용하게 사용할 수 있다.일정 길이 최댓값을 구하는 함수일정 길이 최솟값을 구하는 함수투 포인터는 데이터에
7.[알고리즘] 재귀함수-기본, 누적합
재귀함수는 정의 단계에서 자신을 재참조하는 함수를 뜻한다. 재귀함수는 재귀가 모두 실행되어 끝나거나, 특정 브레이크 포인트를 만날 때까지 계속해서 실행되는데, 만약 브레이크 포인트를 제대로 설정하지 않으면 무한루프의 늪에 빠질 수도 있다. 함수가 무한대로 실행되면 스택
8.[알고리즘] 재귀-순열(Permutation), 백트래킹(Backtracking)
순열이란 서로 다른 n개 중 r개를 골라 순서를 고려해 나열하는 가짓수를 말한다. nPr로 표시한다. 사실 순열은 itertools를 이용하면 쉽게 구현할 수 있다. 하지만 재귀로 직접 구현하는 방법을 알아보고자 한다. (itertools를 사용하여 구현하는 방법은 포
9.[알고리즘] 재귀-조합(Combination)
순열이란 서로 다른 n개 중 r개를 뽑아 그룹을 만드는 가짓수를 말한다. nCr로 표시한다. 사실 순열은 itertools를 이용하면 쉽게 구현할 수 있다. (아래 링크 참고)\[알고리즘] 재귀-순열(Permutation), 백트래킹(Backtracking)일반 조합중
10.[알고리즘] DFS(깊이 우선 탐색)-재귀, 스택(Stack)
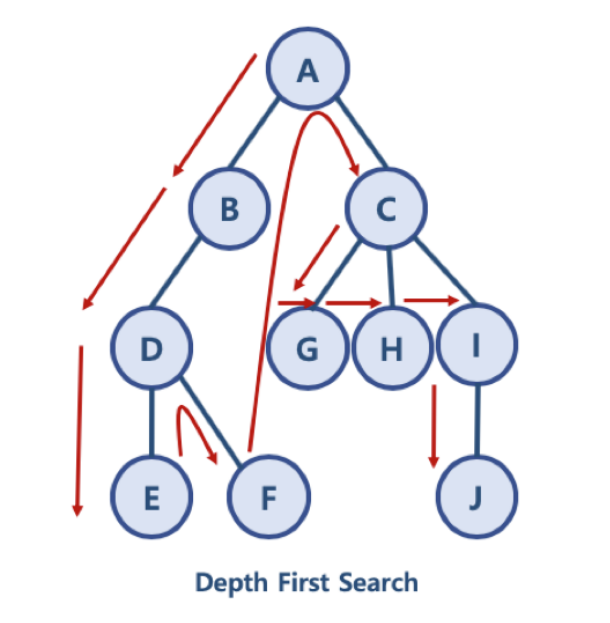
대표적인 그래프 탐색 알고리즘이다. 깊이 우선 탐색(Depth First Search)는 정점의 자식을 먼저 탐색하는 방식이다. 위의 그래프를 DFS 방식으로 순회하면 A - B -D - E - F - C - G - H - I - J 순으로 돌게 된다.그래프(Graph
11.[알고리즘] BFS(넓이 우선 탐색)-큐(Queue)
DFS와 함께 대표적인 그래프 탐색 알고리즘이다. BFS는 넓이 우선 탐색(Breadth First Search)이라는 알고리즘이며, 정점에서 가까운 노드부터 우선적으로 탐색한다. BFS는 Queue라는 자료구조를 이용하여 구현할 수 있다.탐색 시작 노드를 Queue에
12.[알고리즘] 이진 탐색 트리(Binary Search Tree)
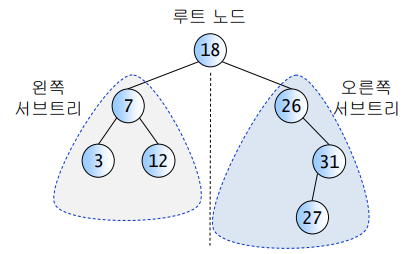
이진 탐색 트리란 다음과 같은 속성을 만족하는 이진 트리 자료구조이다. 각 노드에 중복되지 않는 값이 있다.한 노드의 왼쪽 서브 트리는 해당 노드의 값보다 작은 값들을 가진 노드들로 이루어져 있다.한 노드의 오른쪽 서브 트리는 해당 노드의 값보다 큰 값들을 가진 노드들
13.[알고리즘] Union-Find(합집합 찾기)
각각의 독립된 데이터들을 그룹화 시켜 관리할 때 사용하는 자료구조이다. 두 그룹울 그룹화 시킬 때 각 그룹의 보스 데이터를 하나로 합친다. 그래서 임의의 두 데이터가 같은 그룹인지 아닌지를 확인할 때 각 데이터가 속한 그룹의 보스가 같은지 여부를 판단한다.민코딩Minc
14.[알고리즘] 크루스칼 알고리즘(Kruskal Algorithm)
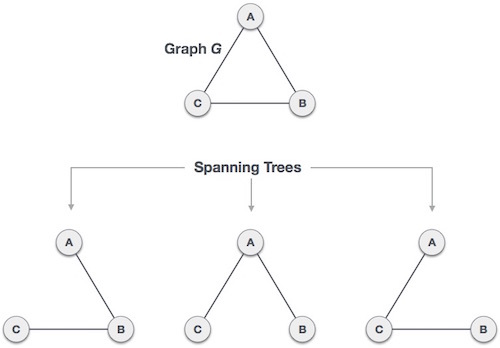
최소 신장 트리를 찾는 데 사용되는 알고리즘 중 하나이다.하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다. 예를 들어 아래와 같은 그래프 G가 있을 때, 이 그래프에서 가능한 신장 트리는 하단의 3가지 그래프이다.모든 노드
15.[알고리즘] Flood Fill(Seed Fill)-BFS

다차원 배열의 어떤 칸과 연결된 영역을 찾는 알고리즘이다. 해당 알고리즘은 그림판의 채우기 기능과 지뢰 찾기 프로그램에 이용된다. 주변에 같은 성질을 가지는 셀을 모두 찾아준다는 공통점이 있다. 플러드 필은 보통 DFS(재귀)와 BFS(Queue)를 이용하여 구현한다.
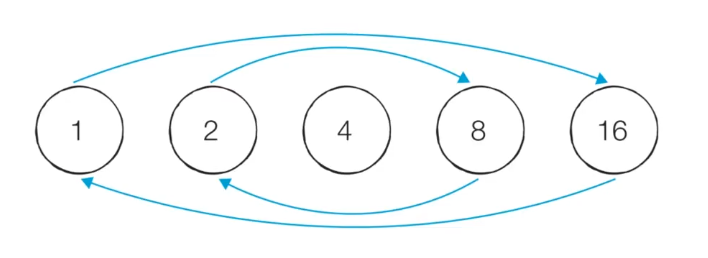
16.[알고리즘] 바이너리 카운팅(Binary Counting)-부분 집합
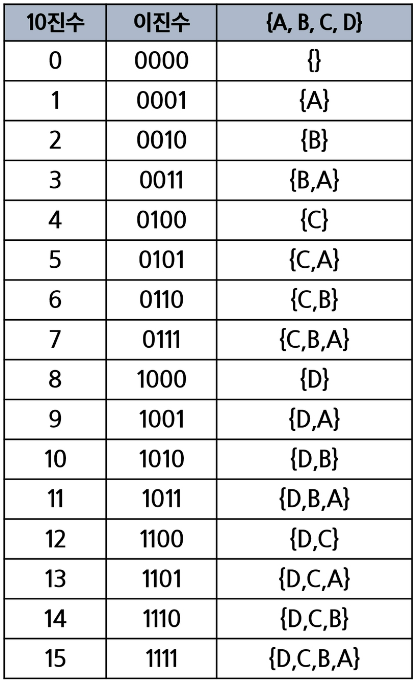
원소 수에 해당하는 N개의 비트열을 이용한다. n번째 비트값이 1이면 n번째 원소카 포함 되었음을 의미한다. 이는 부분 집합(개수가 정해져 있지 않은 조합)을 구하는 문제에서 활용된다. 바이너리 카운팅처럼 각 원소가 포함되는지 아닌지 여부를 배열에 표시하여 부분 집합을
17.[알고리즘] 위상 정렬(Topological Sort)
사이클이 없는 방향 그래프의 모든 노드를 방향성에 거스르지 않도록 순서대로 나열하는 것을 의미한다. 특정 공정을 수행하기 위해선 선행 되어야 하는 공정이 다 수행되어야 할 때 많이 쓰인다. 진입차수(Indegree): 특정한 노드로 들어오는 간선의 개수진출차수(Outd
18.[알고리즘] 유클리드 호제법(Euclidean algorithm)
두 수의 최대공약수(GCD)를 구하는 알고리즘으로, 유클리드에 의해 기원전 300년경에 발견된 가장 오래된 알고리즘이다. 호제법(互除法)이라는 말은 서로(互) 나누기(除) 때문에 붙여진 이름이다.유클리드 호제법에는 모듈러 연산(나머지 연산)이 사용된다. 큰 수를 작은
19.[알고리즘] 에라토스테네스의 체 - 소수(Prime Number)
소수란 1보다 큰 자연수 중에서 1과 자기 자신을 제외한 자연수로는 나누어 떨어지지 않는 자연수이다. 보통은 2부터 N-1(자신-1)까지 돌며 나누어 떨어지는 수가 있는지 확인한다.어떤 수의 약수는 그 수의 제곱근을 기준으로 곱셈 연산에 대해 대칭을 이룬다. 이런 성질
20.[알고리즘] 그리디(Greedy) 알고리즘
그리디 알고리즘은 탐욕 알고리즘이라고도 불린다. 여러 경우 중 하나를 결정해야 할 때마다, 현재 상황에서 최적이라고 생각되는 경우를 선택하여 정답를 구하는 알고리즘이다. 그리디 알고리즘은 현재의 선택이 나중에 미칠 영향을 고려하지 않기 때문에, 항상 최적해를 보장하는
21.[알고리즘] 동적 계획법(Dynamic Programming)
메모리 공간을 약간 더 사용해서 연산 속도를 비약적으로 증가시키는 방법이다. 또한 큰 문제를 작은 문제로 나눠서 푸는 알고리즘이기도 하다.DP의 핵심은 ‘메모제이션’(캐싱) 기법이다. 이미 계산된 결과(작은 문제)를 별도의 메모리에 저장해 다시 계산하지 않고 필요한 경
22.[알고리즘] 우선순위 큐(Priority Queue)와 힙(Heap)
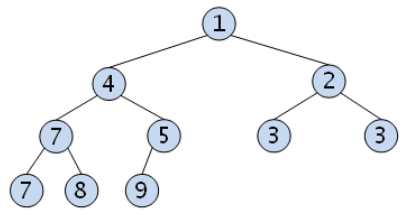
우선순위 큐(Priority Queue)는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 것을 말한다. 데이터 추가는 어떤 순서로 해도 상관 없지만, 제거될 때는 가장 작은 값을 제거하는 특징을 가진 자료구조이다. Python에서는 이런 로직이 내부적으로
23.[알고리즘] 다익스트라(Dijkstra) 알고리즘
다익스트라 알고리즘은 플로이드 워셜(Floyd-Warshall)과 함께 최단 경로를 찾는 대표적인 알고리즘이다. 다익스트라는 구현이 간단하지만 오래 걸리는 방법과 구현은 복잡하지만 성능이 개선된 방법 두 가지가 존재한다. 시작점에서 도착점(특정 노드 또는 모든 노드)까