
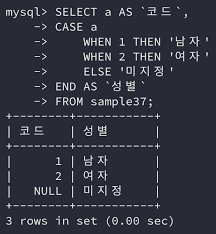
SQL 첫걸음 #1
DBMS는 데이터베이스를 관리하는 소프트웨어로, 사용 목적은 생산성 향상과 기능성, 신뢰성 확보에 있음생산성: DBMS가 데이터 검색, 추가, 삭제, 갱신과 같은 기본 기능을 제공기능성: 복수 유저의 요청에 대응하거나 대용량의 데이터를 저장하고, 고속으로 검색하는 기능
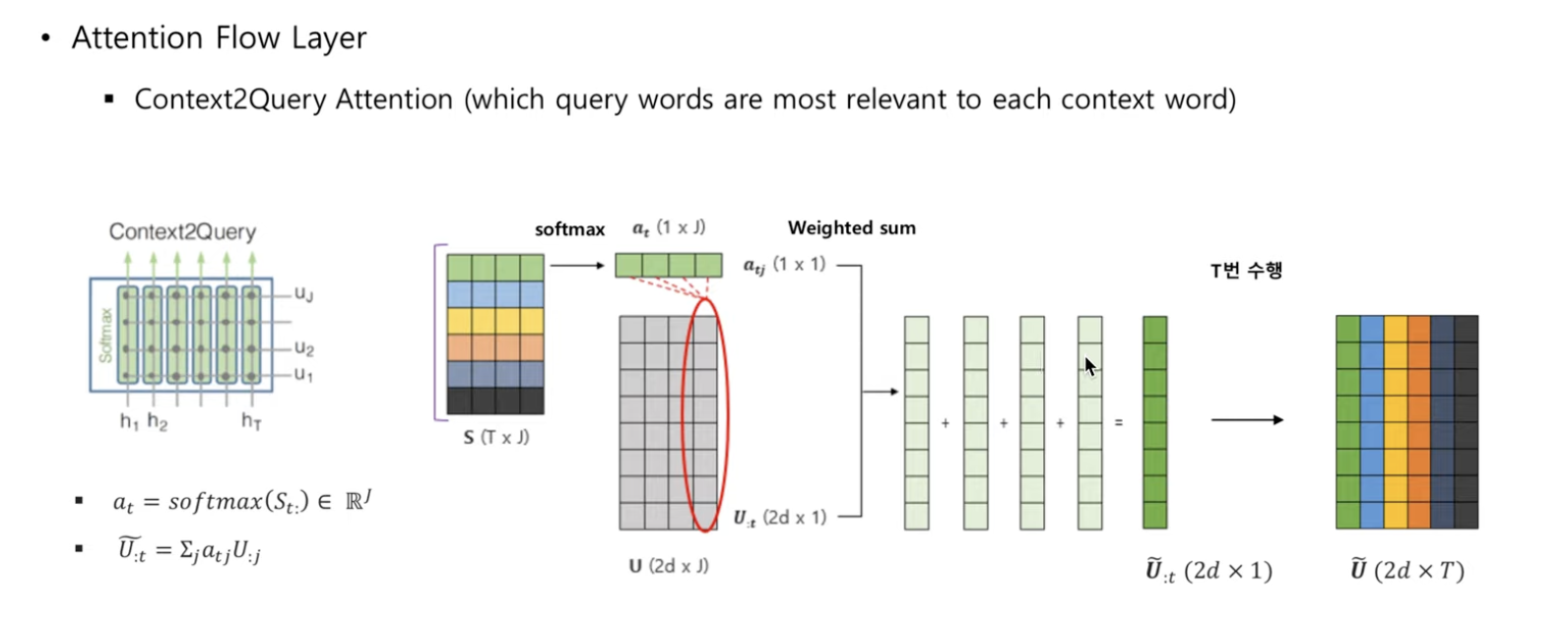
Question Answering
goal of QA: 질문에 natural language로 자동으로 답하는 시스템 구축 문제에는 굉장히 다양한 유형이 있으며, QA를 통해 우리는 실생활에서 굉장히 유용한 어플리케이션을 사용할 수 있습니다. 예를 들어, 구글에 세계에서 가장 깊은 호수가 무엇인가
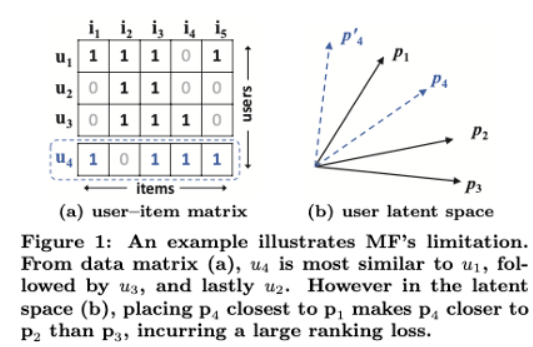
Neural Collaborative Filtering
collaborative filtering을 모델링하기 위해서 user와 item의 상호작용이 필요하며, user-item 공간의 latent feature들의 내적곱을 통해 두 관계를 표현하고 추천시스템에서 널리 사용되는 MF에 의존한다. 그러나 MF는 linear
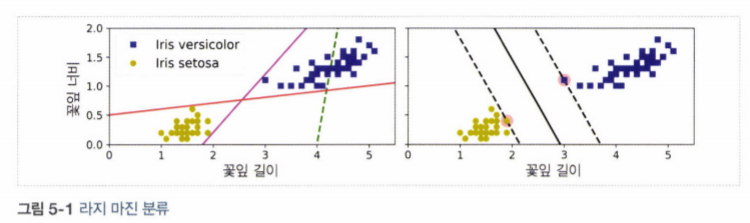
SVM
SVM: 매우 강력하고 비선형 분류, 회귀, 이상치 탐색에도 사용할 수 있는 다목적 머신러닝 모델SVM Classification는 클래스 사이에서 가장 폭이 넓은 도로를 찾는 것으로 생각 할 수 있음.라지 마진 분류(large margin classification)

Wa
텍스트items = document.querySelectorAll('div.pf5lIe')댓글내용 Array.prototype.map.call(items, function(x) {return x.parentNode.parentNode.parentNode.parentNo
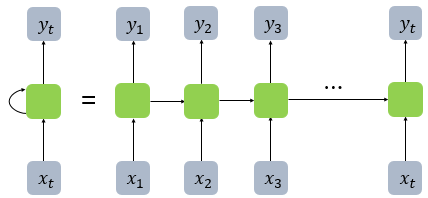
R-Transformer
RNN은 그림처럼 순환하며 출력을 다시 입력으로 받는 모델입니다. RNN은 이런 순환성 때문에 기억을 가지는 모델이라고도 부르는데요, 문장을 이해하기 위해서는 맥락을 이해해야 하고 맥락을 이해하기 위해서는 이전의 결과가 다음의 결과에 영향을 미쳐야 합니다. RNN은

[논문 발표]Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in Vector Space 논문에 나오는 내용 모두 정리하기
[논문 해석]Efficient Estimation of Word Representations in Vector Space
💡 Abstract 본고는 대량의 데이터로 부터 단어의 연속적인 벡터표현을 계산하기 위한 두 개의 새로운 모델 구조를 제안한다. 이 표현들의 성능은 단어 유사도로 측정되며, 이 결과는 이전에 가장 좋은 성능을 냈던 다른 유형의 신경망구조를 기반으로한 기술과 비교한다.