1. LeNet
현재 우리가 사용하는 CNN의 기본 구조를 처음으로 도입했으며, 필기 숫자 인식(MNIST) 등에 사용됐다.
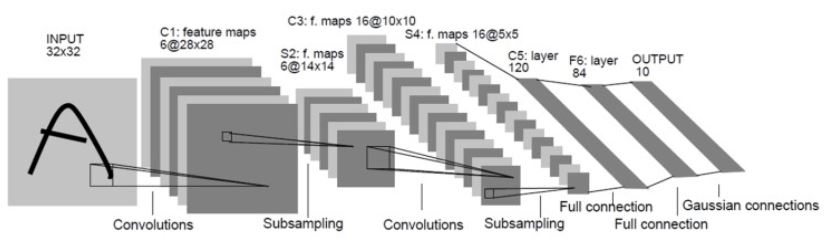
1-1. LeNet-5 구조
- 입력 크기: 32×32 흑백 이미지
- Conv-Pooling 반복 → Fully Connected Layer (FC) → Softmax
1-2. LeNet-5의 특징
- 최초의 CNN 구조 도입 (합성곱 → 풀링 → FC Layer)
- 필기 숫자 인식(MNIST)에서 사용됨
- 필터 수가 적고 연산량이 작아서 비교적 가벼운 모델
1-3. LeNet-5의 한계점
- 단순한 구조로 인해 복잡한 이미지 분류에는 적합하지 않음
- 깊이가 얕아서 복잡한 패턴 학습이 어려움
2. AlexNet
AlexNet은 2012년 ImageNet 대회에서 우승하며 CNN을 대중적으로 널리 알린 모델로 기존의 LeNet 구조를 확장하여 깊이(depth)를 증가시키고, ReLU 활성화 함수와 드롭아웃(Dropout) 기법을 도입하여 강력한 성능을 보여준다.
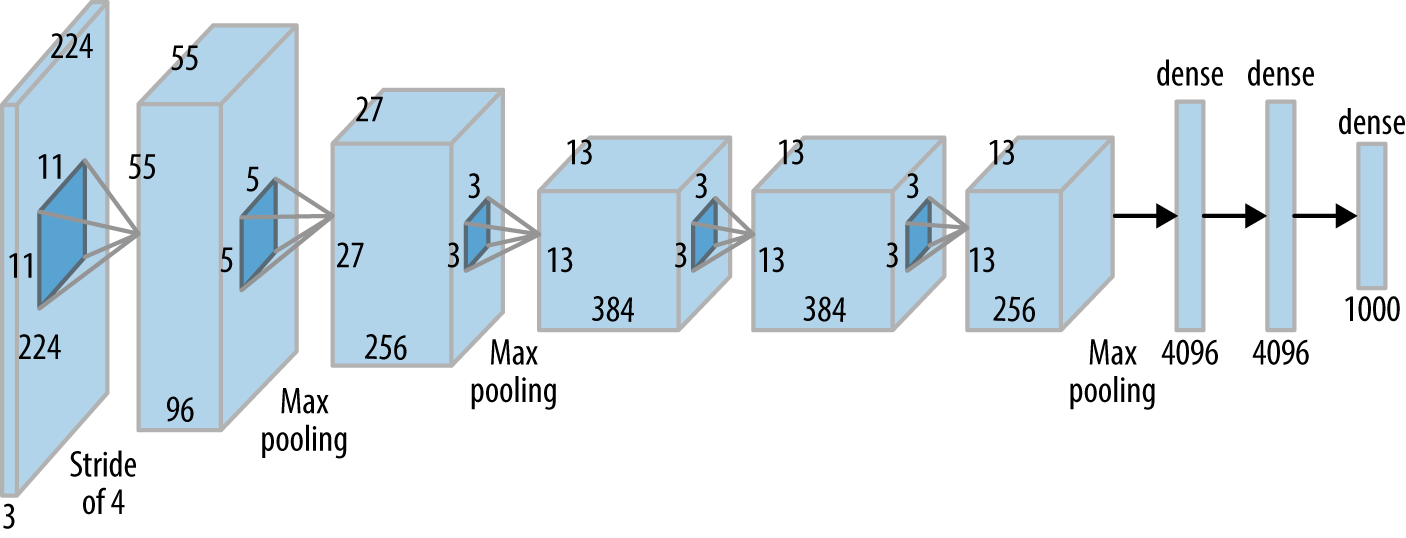
2-1. AlexNet 구조
- 입력 크기: 224×224 RGB 이미지
- 5개의 합성곱 층(Conv Layer) + 3개의 Fully Connected Layer
- ReLU, Dropout, 데이터 증강(Data Augmentation) 기법 사용
2-2. AlexNet의 특징
- CNN을 대중화시킨 모델 (2012 ImageNet 대회에서 1위)
- ReLU 활성화 함수 사용 → 학습 속도 향상
- 드롭아웃(Dropout) 사용 → 과적합 방지
- 데이터 증강(Data Augmentation) 사용 → 일반화 성능 향상
2-3. AlexNet의 한계점
- 연산량이 많아서 고성능 GPU가 필요함
- 필터 크기가 크고, 구조가 비교적 단순하여 복잡한 패턴을 깊게 학습하는 데 한계
3. VGGNet
VGGNet은 AlexNet보다 더 깊은 네트워크를 사용하여 성능을 향상시킨 모델로 특히, 작은 3×3 필터를 여러 개 쌓아서 더 깊은 모델을 만들면서도 계산량을 최적화했다.
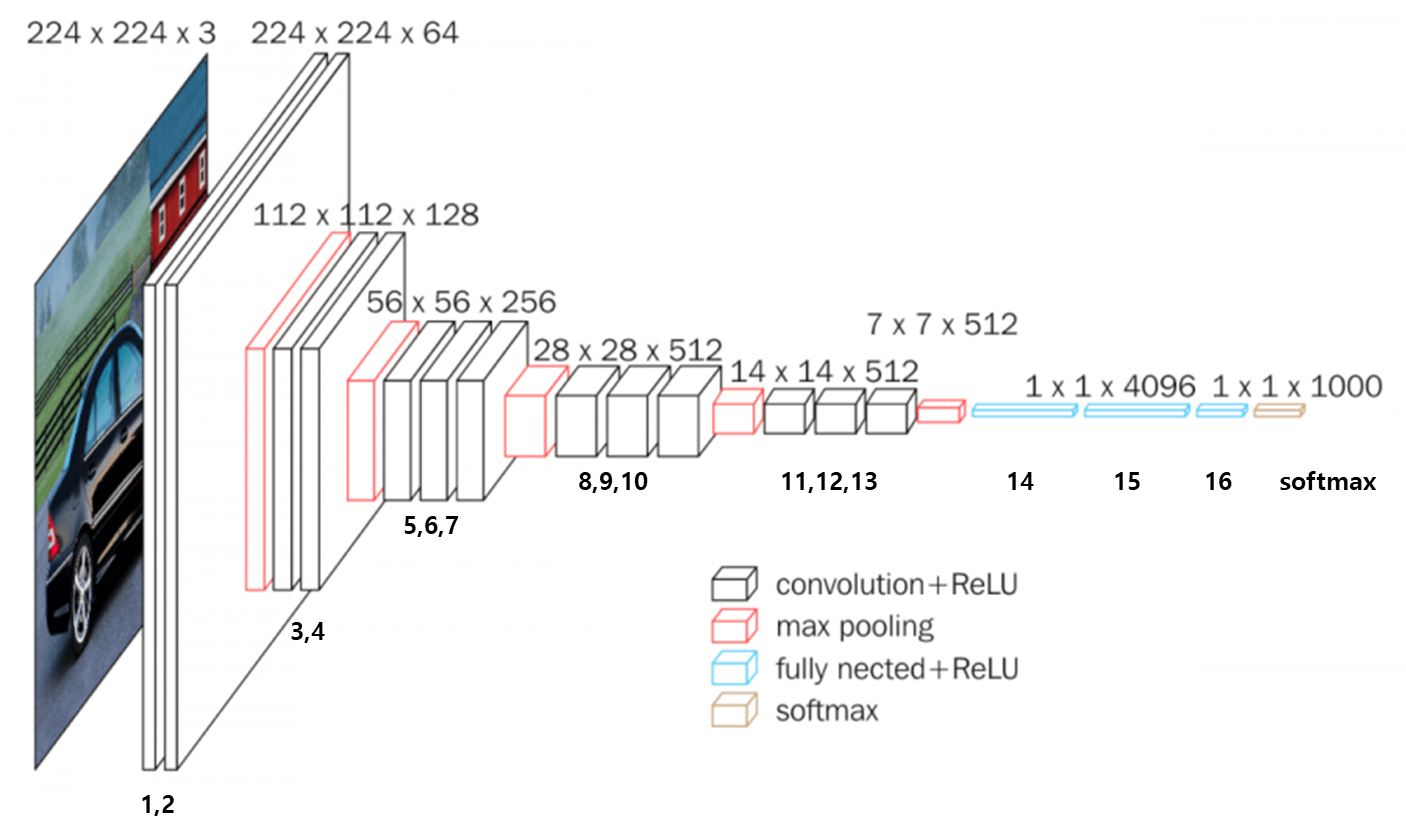
3-1. VGGNet 구조
- 입력 크기: 224×224 RGB 이미지
- 16개의 합성곱 레이어(Conv Layer) + 3개의 Fully Connected Layer
- 모든 필터 크기를 3×3으로 통일하여 일관성 유지
3-2. VGGNet의 특징
- 작은 3×3 필터를 여러 개 사용하여 깊은 네트워크 설계
- 필터 크기를 통일하여 일관성 유지
- 깊은 네트워크 덕분에 뛰어난 성능
3-3. VGGNet의 한계점
- 파라미터 수가 많아서 연산량이 큼
- 깊이가 깊을수록 학습 속도가 느려지고, 메모리 사용량 증가
4. LeNet vs AlexNet vs VGGNet
점점 네트워크가 깊어지면서 에러율이 줄어드는 특징이 있음
| 모델 | 연도 | 깊이 | 필터 크기 | 주요 특징 |
|---|---|---|---|---|
| LeNet-5 | 1998 | 5 | 5×5 | CNN 기본 구조 |
| AlexNet | 2012 | 8 | 11×11, 5×5, 3×3 | ReLU, Dropout 사용 |
| VGGNet | 2014 | 16~19 | 3×3 | 깊은 구조, 작은 필터 |
4-1. ILSVRC
ILSVRC (ImageNet Large Scale Visual Recognition Challenge)은 ImageNet이라는 대용량 데이터셋을 활용하여 가장 높은 이미지 분류 성능을 내는 경진대회로 아래 사진은 연도별 우승 알고리즘의 분류 에러율이다. 2015년 ResNet부터 에러율 5%인 인간을 뛰어넘는 알고리즘이 등장하기 시작했다.

이미지1 출처: https://velog.io/@kjune1236
이미지2 출처: https://bskyvision.com/425
참고자료1: https://itforfun.tistory.com/51

기록은 기억을 지배한다.