본 페이지에서는 HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation 논문에 대해서 말하고자 합니다.
DACS, DAFormer와 직접적인 연관성이 있고 해당 페이지에만 있는 내용도 있으니 아래의 링크를 통해 같이 보시는 걸 추천드립니다.
1. Intro
기존의 UDA 방법론들은 좋은 성능을 내고 있었습니다.
그러나 기존의 UDA 방법들은 Source Domain과 Target Domain을 동시에 학습시키며 Student, Teacher Model 두 모델 사용과 많은 Loss 함수 때문에 GPU Memory 사용량이 매우 큽니다.
이러한 제한으로 GPU Memory 사용량을 줄이기 위해 기존 UDA 방법론들은 이미지의 크기를 줄여서 학습하는 방식을 선택했습니다.
예를 들면 CityScapes 데이터셋에서 일반적인 지도 학습을 하는 경우 높은 해상도(High-Resolution[HR])를 가진 원본 이미지 크기인 를 입력으로 하지만 기존 UDA 방법론들은 절반의 크기인 를 입력으로 합니다.

1.1 Low-Resolution(LR) Problem
이 과정에서 다음과 같은 문제가 발생합니다.
-
적어진 해상도(Low-Resolution[LR])로 인해서 세부 특징(Fine-Detail)들을 학습하지 못함
-
위의 이유로 신호등이나 사람 같은 작은 물체에 대해서 잘 감지하지 못하는 경우가 발생함
1.2 High-Resolution(HR) Crop and Problem
위의 문제를 해결하기 위해서 그동안 해상도를 줄이지 않고 Crop 하는 방식(HR Crop)으로 세부 특징이 사라지는 문제와 메모리 연산의 문제를 해결했습니다(Fig. 1 a).
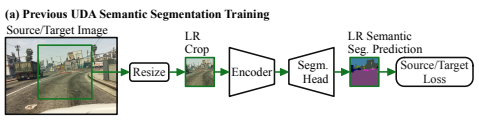
※ HR Crop이라고 하는 이유는 Crop을 했다고 하지만 해상도를 줄이지 않고 Crop을 했기 때문에 HR Crop이라고 합니다.
하지만 이 방법에도 다음과 같은 문제가 발생합니다.
-
전체 이미지 중 일부만을 보기 때문에 Global Context(Long-Range Context)에 대한 정보에 대해서 학습하지 못함
-
강건한 특징을 학습해야 하는 UDA의 특성상 Context 정보를 잃게되면 UDA의 성능이 제한됨
1.3 High-Resolution(HR) Problem
위의 문제들을 제외하더라도 고해상도를 사용하는 것에 대한 문제가 있습니다.
물론 고해상도 입력(HR Inputs)를 사용하는 것은 작은 물체를 더 잘 적응(Adaptation)하도록 해줍니다. 그러나 보도블럭과 같이 매우 큰 물체(Large Stuff-Regions)에 대해서는 오히려 잘 적응(Adaptation)하지 못합니다.
이 이유를 다음과 같이 설명합니다.
-
고해상도인 이미지는 매우 큰 물체(Large Stuff-Regions)에 대해서 너무 많은 세부 특징을 가지고 있다. 이렇게 특정 도메인의 세부적인 특징(Domain-Specific HR Textures)을 학습하게 되면 UDA에서는 오히려 악 효과가 날 수 있음
-
반면에 저해상도 이미지의 경우는 적당히 특징을 학습하기 때문에 다른 도메인에 대해서도 적절한 성능을 낼 수 있음
너무 많은 세부적인 특징을 학습해 다른 도메인에서는 오히려 악영향을 끼칠 수 있다는 점 때문에 위의 이유를 과적합과 비슷한 이유라고 생각합니다.
1.4 Solution
그래서 본 논문은 위의 문제들을 해결하기 위해 LR과 HR을 적절히 사용하는 방법을 제안합니다.(Fig. 1 b)
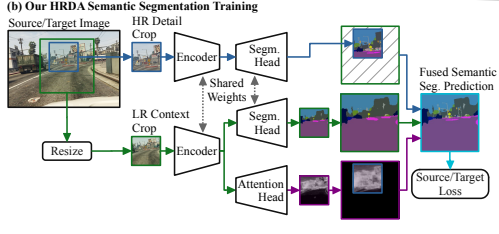
-
LR Context Crop : 원본 이미지의 일부를 Crop하여 Resize 하여 LR 이미지를 얻습니다.
LR Context Crop은 HR과 관련된 문제점들을 해결하기 위한 방법으로 Context정보와 큰 물체에 대해서 적절하게 학습하도록 하여 특정 도메인의 세부적인 특징에 과적합되지 않도록 합니다.
-
HR Detail Crop : LR Context Crop에서 Resize전 이미지 내에서 일부를 Crop하여 HR 이미지를 얻습니다.
HR Detail Crop은 LR과 관련된 문제점들을 해결하기 위한 방법으로 세부적인 특징들을 얻어낼 수 있고 이에 따라 작은 물체를 더 잘 탐지합니다.
-
Input-Dependent Scale Attention : 특정 범위 내에 HR Crop의 결과에 대한 신뢰도를 나타냅니다.
LR Context Crop을 만들기 위해서 처음 Crop한 범위 내에서 특정 Pixel의 클래스 값을 HR Detail Crop과 LR Context Crop을 이용한 출력을 어느정도의 비율로 선택할지 정합니다.
자세한 내용은 이후에 다루겠습니다.
2. Term
본 논문을 이해하시기 전에 용어들이 어떤 것을 의미하는지 확인하시면 편하실 겁니다.
-
: Source 데이터들의 개수 입니다.
-
: Target 데이터들의 개수 입니다.
-
: Source 이미지들을 의미하며 는 번째 Source 이미지 입니다.()
-
: Source 라벨들을 의미하며 는 번째 Source 라벨 입니다.()
-
: Target 이미지들을 의미하며 는 번째 Target 이미지 입니다.
-
: 의 결과를 의미합니다.
-
: Student Model의 가중치를 의미합니다.
-
: Teacher Model의 가중치를 의미합니다.
-
: Student Model을 의미합니다.
-
: Teacher Model을 의미합니다.
-
: 입력 을 Scale 만큼 Upsample(>1)을 적용하거나 Downsample(<1) 적용합니다.
-
: X의 해상도에서 Height(H),Width(W)를 의미합니다.
3. Unsupervised Domain Adaptation (UDA)
3.1 Student Model ()
Segmentation에서 모델을 학습시키는 경우 주로 Cross Entropy Loss 를 사용합니다.
위에서 가 존재하는 이유는 Segmentation에서 일반적으로 출력 Map의 해상도는 원래 라벨의 해상도보다 작은 경우가 많기 때문에 해상도를 맞춰주기 위함입니다.
기존의 UDA 방식들과 동일하게 Source Domain은 Label이 존재하므로 Source Domain에 대한 학습은 Cross Entropy Loss를 사용하며 다음과 같습니다.
Target Domain의 경우 라벨이 없기 때문에 다음과 같이 Teacher Model을 활용하여 만든 Pseudo Label을 통해 와 를 만들어 학습을 진행합니다.
는 Pseudo Label을 Class 축을 기준으로 Argmax를 적용한 것이며 일반적인 Segmentation Mask와 동일합니다.
는 Pseudo Label에서 각 픽셀값의 최대값이 임계값 이상인 픽셀의 비율이며 이를 통해 Loss의 크기를 조절합니다.
이를 통해 Target Loss는 다음과 같습니다.
일반적인 UDA 방법론들에서 사용하던 Loss는 다음과 같습니다.
이 Loss를 통해 Student Model을 학습시킵니다.
3.2 Teacher Model ()
본 논문에서는 주로 DAFormer 방법을 따르며 HRDA에 대해서 실험합니다.
DAFormer의 학습 방법과 동일하게 Teacher Model()의 가중치 를 지수이동평균(Exponetial Moving Average)를 이용해 업데이트합니다.
그 식은 다음과 같습니다.
시점의 는 다음과 같이 정해집니다.
EMA를 사용함으로써 이전 시점의 Student Model()을 Temporal Ensemble하는 것과 같은 효과를 낼 수 있습니다.
이로 인해서 안정성을 가진 Pseudo 라벨을 만들어낼 수 있습니다.
4. Method
앞에서 말했듯 고해상도(HR)에서는 작은 물체들을 적응(Adaptation)하기 쉽습니다.
반대로 저해상도(LR)에서는 큰 물체(Large Stuff Regions)에 대해서 적응(Adaptation)하기 쉽습니다.
또한 UDA 방법의 특성상 지도학습을 하는 것보다 더 많은 GPU Memory를 사용한다는 점이 있습니다.
본 절에서는 위 문제에 대한 해결 방법을 다음과 같은 순서로 설명할 예정입니다.
-
LR Context Crop, HR Detail Crop
저해상도 특징과 고해상도의 특징을 어떻게 뽑아낼 것인가?
-
Multi-Resolution Fusion with Scale Attention
그 특징들을 어떻게 활용할 것인가?
-
Pseudo-Label Generation With Overlapping Sliding Window
전체 이미지(Test 단계)를 추론하거나 일부분(Pseudo Label 생성 단계)을 추론하는 경우에는 어떻게 할 것인가?
위의 1번과 2번에 대한 내용은 아래 그림에서 a에 해당하는 내용이며 3번은 b에 해당하는 내용입니다.
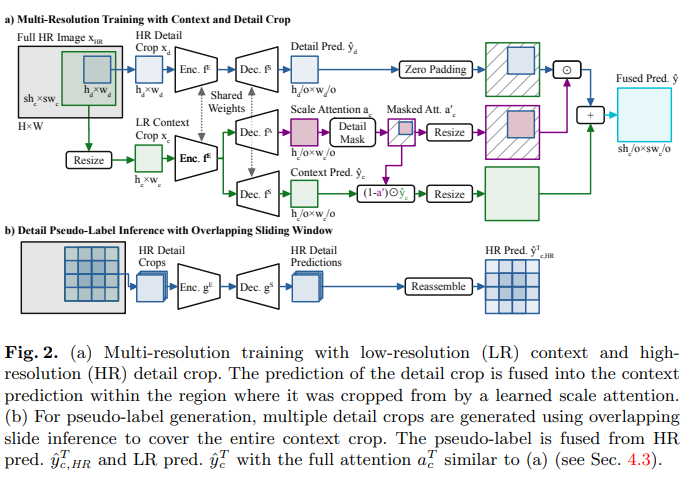
4.1 LR Context Crop, HR Detail Crop
GPU 메모리 사용량의 증가는 다음과 같은 이유로 발생합니다.
-
학습하고자 하는 여러 도메인
-
추가적인 모델( Student, Teacher )
-
여러개의 Loss 함수
이러한 GPU 사용량 때문에 Resize 방법(LR, Context) 또는 Random Crop(HR, Detail) 방식을 사용하여 GPU 사용량을 줄였습니다.
그러나 1절에서 말한 LR과 HR의 각각의 단점들로 인해 각 방법은 UDA 성능을 제한하게 됩니다.
두 방법은 서로 보완이 가능하기 때문에 본 논문의 저자들은 두 방법을 활용하려고 합니다.
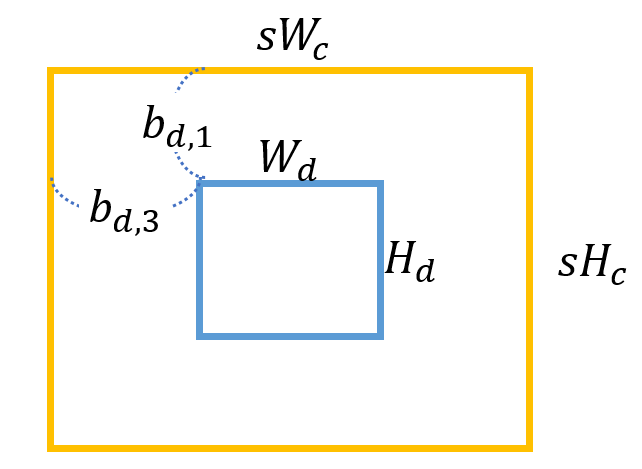
그렇다면 LR과 HR의 특징을 추출하는지 살펴보면 다음과 같습니다.
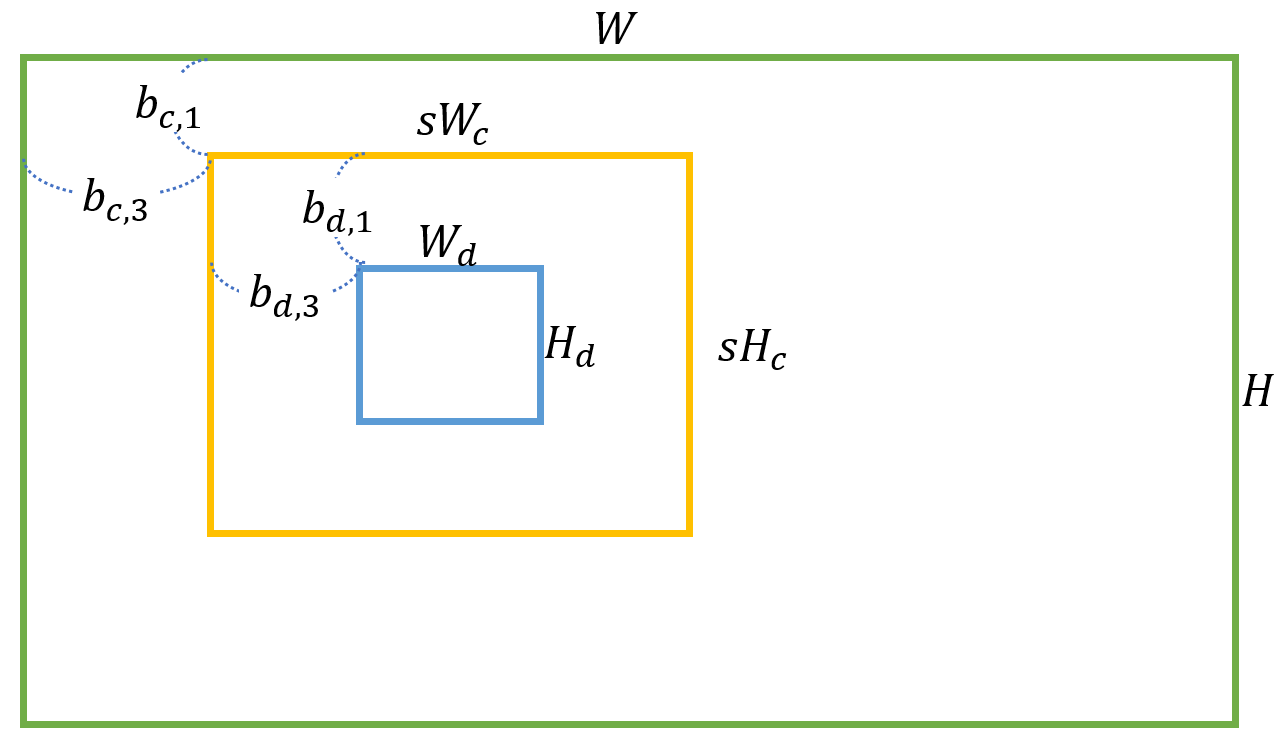
-
초록색 사각형 : 원본 이미지 ( )입니다.
-
주황색 사각형 : 원본 이미지에서 ( ) 의 크기로 Random하게 Crop 합니다. 이후 Resize하여 LR Context Crop ( )를 만듭니다.
-
파란색 사각형 : 주황색 사각형 내에서 ( )의 크기로 Random 합니다. HR Detail Crop 부분에 해당됩니다.
HR Context Crop ()
논문에서는 그냥 Context Crop이라고 하였지만 저는 헷갈리지 않게 HR Context Crop이라고 하였습니다.
주황색 사각형에 해당되며 이 부분을 만드는 수식은 다음과 같습니다.
이때 과 은 균등 분포를 따라 다음과 같이 무작위로 수가 정해집니다.
이때 이며 는 Downsample Scale을 의미하고 는 Segmentation Model의 Output Stride를 의미합니다.
LR Context Crop ()
주황색 사각형()을 Downsample Scale 만큼 Resize 하여 LR Context Crop을 만들어 줍니다.

수식은 다음과 같습니다.
본 논문에서 는 2로 정해집니다.
HR Detail Crop ()
파란색 사각형에 해당되는 부분입니다.
수식은 다음과 같습니다.
이때 과 은 균등 분포를 따라 다음과 같이 무작위로 수가 정해집니다.
Prediction
본 논문에서는 로 사용하며 를 사용합니다.
특히 를 사용하게 되므로 LR Context Crop은 HR Detail Crop에 비해 4배 더 많은 지역의 Context를 다루게 됩니다.
이렇게 동일한 크기의 LR Context Crop과 HR Detail Crop을 동일한 Feature Encoder ()와 Semantic Decoder()에 입력으로 넣어 Segmentation Map()을 얻습니다.
4.2 Multi-Resolution Fusion with Scale Attention
LR Context Crop과 HR Detail Crop을 입력으로 한 출력을 따로 학습을 시킨다면 결국에 여러 해상도를 모델에게 학습시키는 것으로 끝날 것입니다.
모델에게 Context 정보와 Detail 정보를 학습 시키기 위해서는 두 출력을 적절히 활용해야합니다.
그래서 Scale Attention 개념과 이를 활용해 가중합을 통하여 최종 결과를 얻어내 Loss를 구합니다.
이를 위해 Scale Network()를 통해 Scale Attention 를 예측하며 수식은 다음과 같습니다.
는 Sigmoid 함수를 의미합니다.
저자들은 가 0인 경우에는 LR Context를 선택하고 1인 경우에는 HR Detail의 출력을 선택하도록 합니다.
이 Scale Attention을 어떻게 활용하는지에 대해서 그림과 함께 보시면 이해가 쉬우실 겁니다.
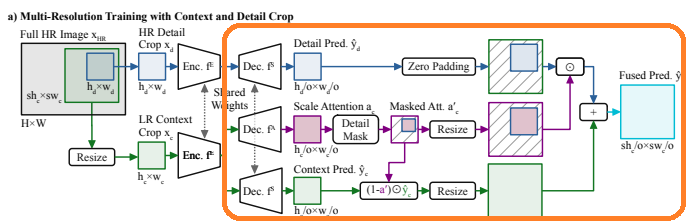
Output Of HR Detail Crop ()
LR Context Crop의 출력 에서 Scale 만큼 Upsample 한 영역을 0으로 초기화 한 합니다. (Zero Padding을 하는 과정입니다.)
이후에 원래 LR Detail Crop 에서 실제 가 존재하는 위치와 비슷하게 새로 만든 영역에 를 붙여넣습니다.
이를 수식으로 나타내면 다음과 같습니다.
결과물 를 얻습니다.
이 결과는 Scale Attention을 이용해 LR Context Crop의 결과와 혼합되어 최종 예측 결과를 얻습니다.
Scale Attention()
LR Context Crop의 출력내에서 HR Detail Crop 출력 부분에는 값을 그대로 입력하고 나머지 부분에는 0으로 채웁니다.
최종 출력에서 HR Detail Crop 부분을 제외한 나머지 부분에는 LR Context Crop의 값만 존재하므로 무조건 LR Context Crop의 값이 선택되도록 0이 되어야 합니다.
이 과정을 수식으로 표현하면 다음과 같습니다.
결과물 를 얻습니다.
Fuse for Prediction And Train
고해상도와 저해상도의 장점을 모두 활용하기 위해서는 지금까지의 출력결과인 , , 를 모두 사용하여야 합니다.
그 과정을 수식으로 나타내면 다음과 같습니다.
최종 출력물인 를 통해 Loss를 계산하여 Student Model을 학습시킵니다.
이 과정에서 LR, HR을 혼합해 사용하여 최적의 가중치로 업데이트 되기 때문에 LR Context 정보와 HR Detail 정보를 적절히 사용해 학습할 수 있습니다.
Loss 함수는 다음과 같습니다.
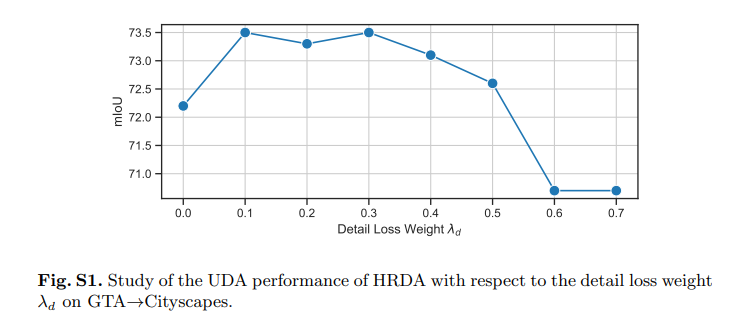
는 하이퍼 파라미터로 값이 높을 경우 HR Detail Crop에 더 집중하여 학습하고 낮을 수록 HR Detail과 LR Context를 혼합한 결과에 더 집중하여 학습합니다.
본 논문에서는 0.1을 선택하여 학습을 진행합니다.
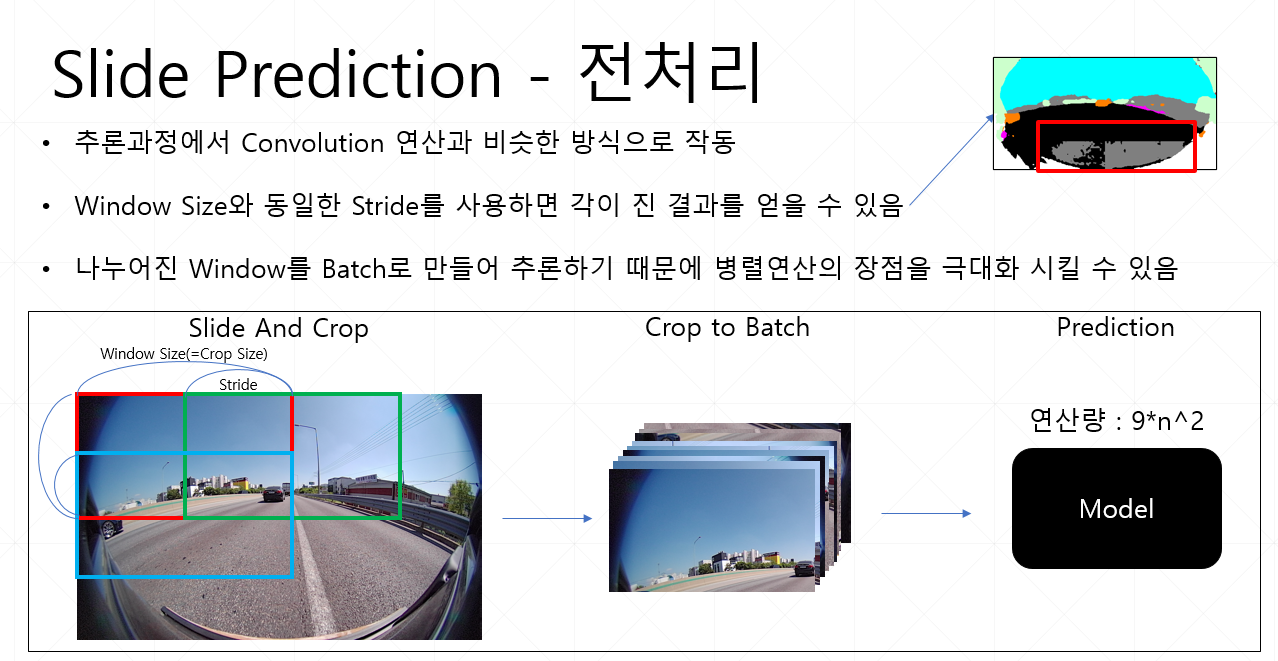
4.3 Pseudo-Label Generation With Overlapping Sliding Window
그렇다면 UDA과정에서 제일 중요한 방법인 Pseudo Label은 어떻게 만들고 추론과정에서 전체 이미지는 추론할까?
Pseudo Label
HR Context Crop (LR Context로 만들기 전의 Crop 범위)을 위해서는 위해서는 Pseudo Label 가 필요합니다.
※ 는 를 Class 방향으로 Argmax를 적용한 것입니다.
를 만드는 과정은 Source Domain과 비슷하며 다음과 같습니다.
여기서 Scale Attention 와 을 중요하게 보셔야합니다.
이 부분에서는 를 만들기 위해서 HR Detail Crop()가 아닌 HR Context Crop 이 필요합니다.
매우 큰 고해상도의 입력은 학습 과정에서는 메모리 제한으로 인해서 문제가 되지만 추론 과정에서는 문제가 되지 않습니다.
그러나 ViT 기반의 DAFormer을 사용하기 때문에 패치의 Position에 대한 영향이 내재적으로 존재하게 됩니다.
이 때문에 동일한 해상도를 입력으로 넣는 것이 성능이 좋게 나옵니다.
그래서 고해상도의 를 얻기 위해서 Overlapping Sliding Window 방식을 통해 추론을 합니다.
그 방법은 다음과 같습니다.
Context Crop 내에서 크기의 Window 를 의 Stride로 옮겨가며 예측하는 방법입니다.
이후의 결과에서 겹치는 부분들은 평균을 내며 이는 강건함을 증가시킨다고 합니다.
또한 병렬로 처리를 하기에 GPU 연산에 최적화 되었다고 할 수 있습니다.
아래는 제가 Samsung AI Challenge(Domain Adaptation)에서 사용한 방법과 비슷하다고 생각하여 추가해봅니다.
추가적으로 이 과정에서 뿐만이 아니라 또한 동일한 방법으로 전체 부분에 대한 Scale Attention을 얻으셔야 합니다.
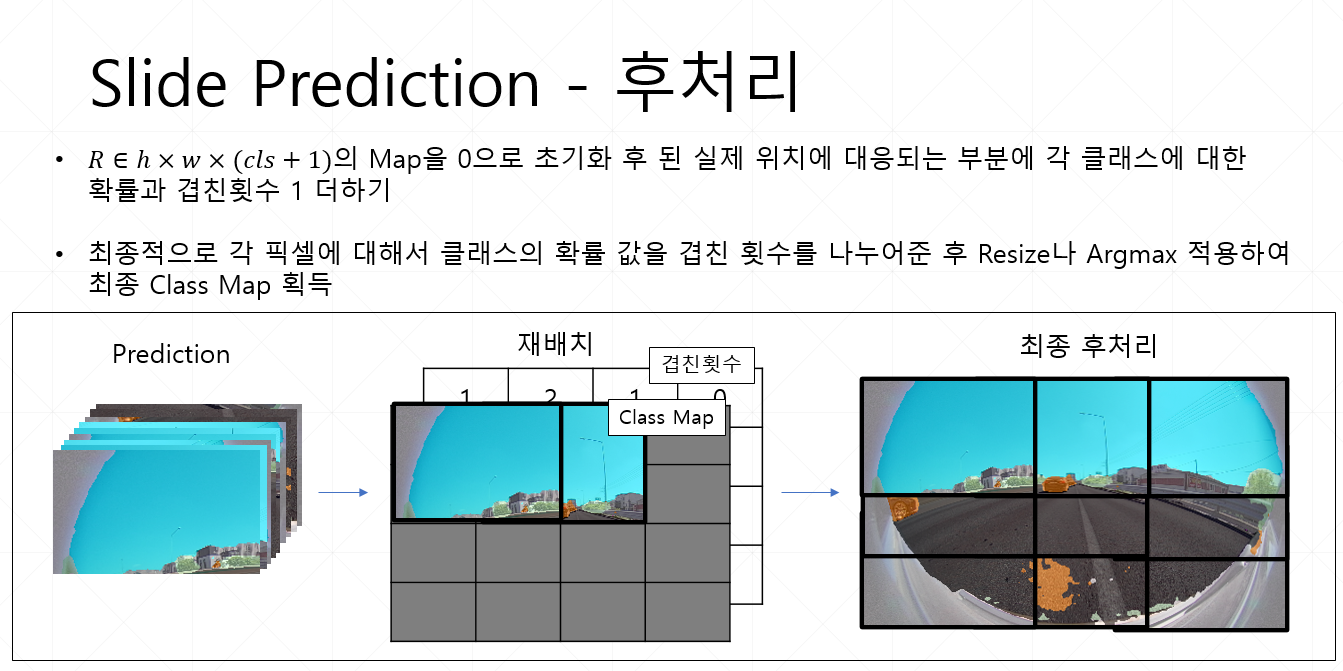
Inference Entire Image
위의 방법은 Pseudo Label을 생성하는 과정입니다.
반대로 전체 이미지를 추론하는 과정은 다음과 같습니다.
전체 이미지 을 예측함으로써 전체이미지에 대한 출력 가 결과로 나와야 합니다.
그러나 위에서와 같은 이유로 를 만들기 위해서 Overlapping Sliding Window 방식을 사용해야 합니다.
여기서는 Window Size를 를 사용하며 Stride는 로 설정합니다.
그리고 각 Window에 대해서는 Pseudo Label을 생성하는 과정과 같은 방식으로 추론을 시작합니다.
5. Experiments
우선 본 논문에서 사용한 주요 실험 설정은 다음과 같습니다.
데이터셋 해상도
-
CityScapes : -> ( 기존 UDA 방법론 = )
-
GTA : -> ( 기존 UDA 방법론 = )
-
Synthia : ->
UDA 하이퍼 파라미터
-
Learning Rate : Encoder(6e-5), Decoder(6e-4)
-
Batch Size : 2
-
Warmup
-
: 1
-
: 0.999
-
DACS 데이터 증강 사용
HRDA 하이퍼 파라미터
-
: 512
-
: 2
-
: 0.1
5.1 Result
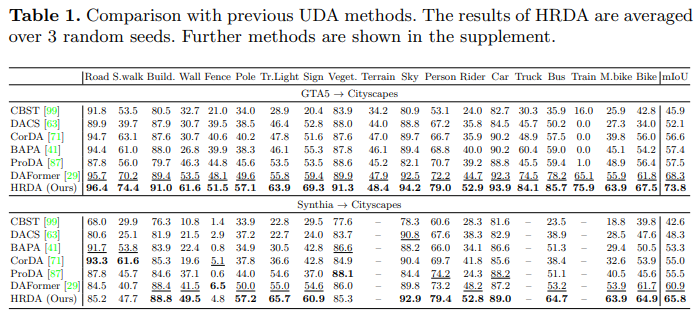
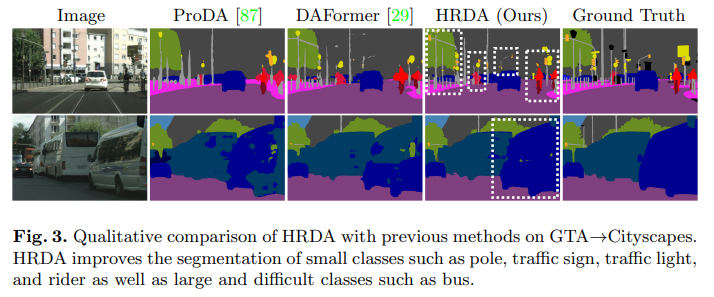
기존의 UDA와는 달리 큰 물체들에서도 좋은 성능을 보이며 작은 물체에 대해서는 빠짐없이 모두 좋은 성능을 내는 것을 확인할 수 있습니다.
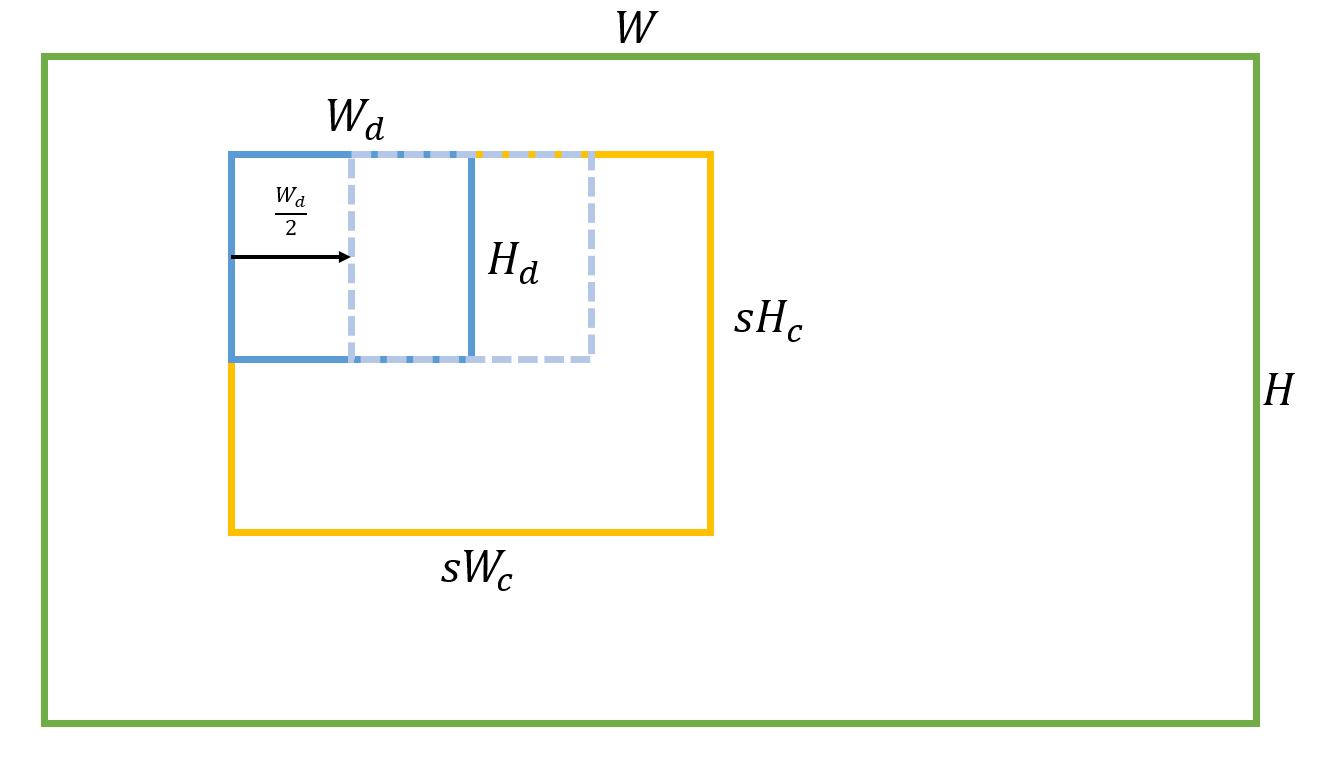
5.2 Relative Crop Size ()
제가 생각하기에 이 부분이 이해하기 힘들었던 거 같았습니다. 원래는 성능 부분은 따로 리뷰에 안넣었는데 이거 때문에 이번 논문 리뷰에 성능 부분에 대한 설명도 넣어봤습니다.
수식을 다음과 같이 변경해서 보면 직관적으로 이해하기 쉽습니다.
는 Target 이미지의 높이라고 보시면 될 거 같습니다.
는 Crop한 높이라고 보시면 됩니다.
는 입력으로 사용한 Target의 높이 입니다.
아래 Fig. 4.와 5.를 보면 에 관한 내용이 있습니다.
의 경우 이므로 Crop 한 높이는 입니다.
즉, 입력으로 사용한 Target의 높이는 Crop한 높이의 절반이 되며 이는 LR Context Crop을 의미합니다.
반대로 의 경우 이므로 Crop한 높이는 입니다.
즉, Crop한 높이와 입력으로 사용한 Target의 높이가 동일하므로 HR Detail Crop을 의미합니다.
※ 실제로 GTA 5 -> Cityscapes에서 HRDA의 성능은 73.8이며 이는 반올림 하면 74입니다. Fig. 5.에서 마지막 행을 보면 mIoU가 동일하며 이 때 를 통해 비율을 계산하면
근거는 다음과 같습니다.
-
Table 1. 마지막 행과 Fig.5. 4행을 보면 GTA 5 -> Cityscapes에서 클래스별 IoU가 동일함
-
CityScapes의 원본 이미지의 높이()는 1024 인데 입력으로 들어가는 는 모두 512임
-
을 계산해보면 각각의 H는 모두 512가 나옴
제가 Relative Crop Size에 대한 내용에서 놓쳐서 쉽게 이해를 못한 것인지 아무리 세세한 설명을 찾아봐도 안나오더라구요... 일단 저렇게 억지 유도를 했습니다... 아시는 분 계시면 댓글 부탁드립니다...
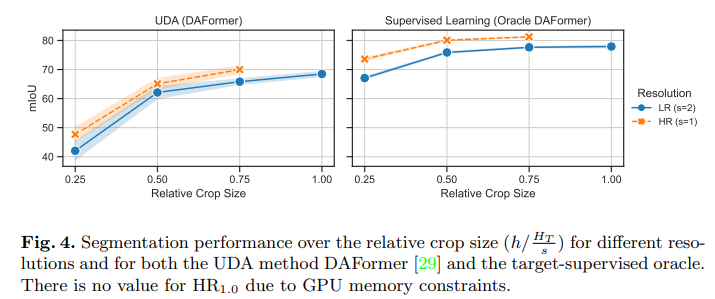
위의 내용을 토대로 그래프를 이해하면 다음과 같습니다.
-
Crop Size가 증가하면 증가할 수록 성능은 향상됨.
-
Crop 비율이 동일하면 HR Detail Crop의 성능이 더 높음.
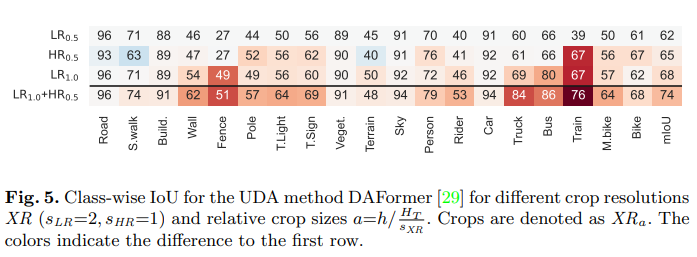
위의 표는 클래스 별로 IoU를 계산한 표 입니다.
-
행 1과 2 : LR Context Crop을 사용하는 것이 HR Detail Crop보다 도로나 보도블럭 같이 큰 부분에서는 더 좋은 성능을 냄.
-
행 1과 3 : LR Context Crop의 크기가 커질 수록 더 많은 Context로 인해 성능이 향상됨.
※시간이 되신다면 논문의 5.5절 한번 보시면서 이해하시면 더 좋을 거 같습니다.
6. 마무리
고해상도 이미지와 저해상도 이미지를 적절히 혼합하여 학습을 했다는 점이 신기했습니다.
특히, 실제로 고해상도 이미지와 저해상도 이미지에서 본 논문에서 말한 장단점이 있다는 것을 처음 알았습니다.
하나 아쉬운 점은 Scale Attention을 진행하지 않고 Context 따로 Detail 따로 Loss를 줘서 학습하는 방법에 대한 실험이 있었다면 더 좋았을 거 같습니다.
이 논문은 Samsung AI Challenge 할 때 알았으면 더 좋았을 거 같습니다.
