
Pima Indians Diabetes Database
라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt데이터셋 로드
df = pd.read_csv("http://bit.ly/data-diabetes-csv")
df.shape
=> (768, 9)EDA
df.describe()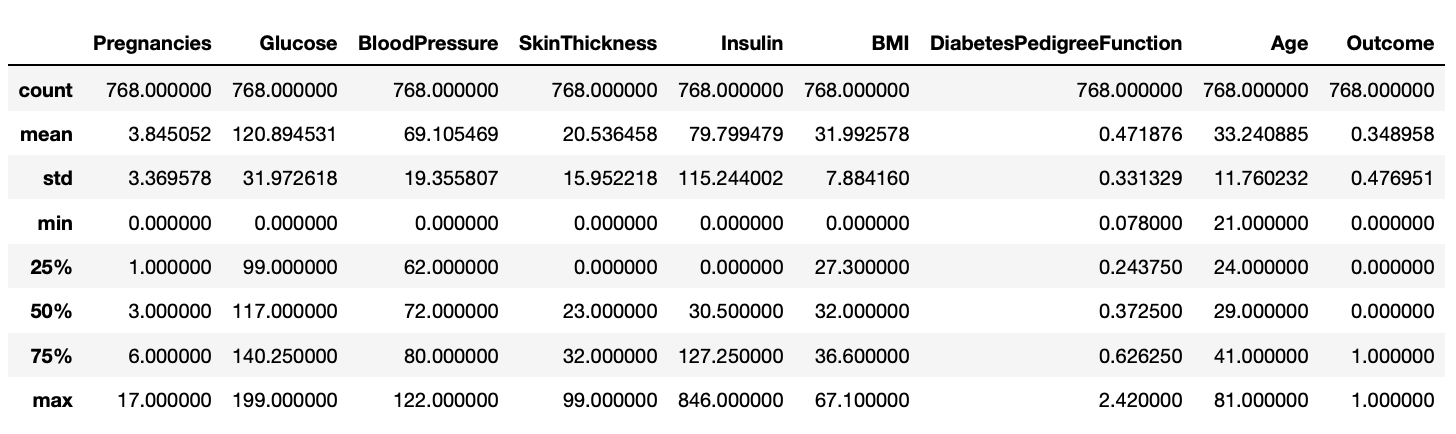
df.hist(figsize=(10, 8), bins=50);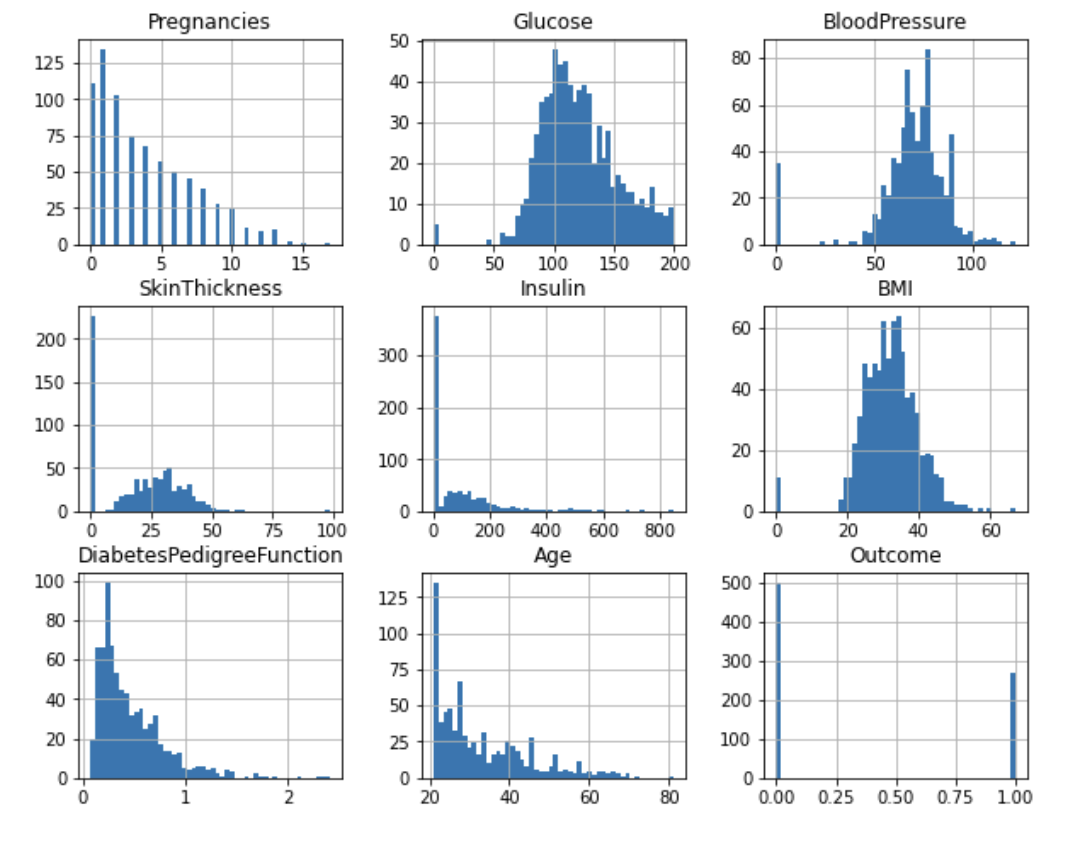
# 임신횟수별 당뇨병 발병 빈도
sns.countplot(data=df, x='Pregnancies', hue='Outcome')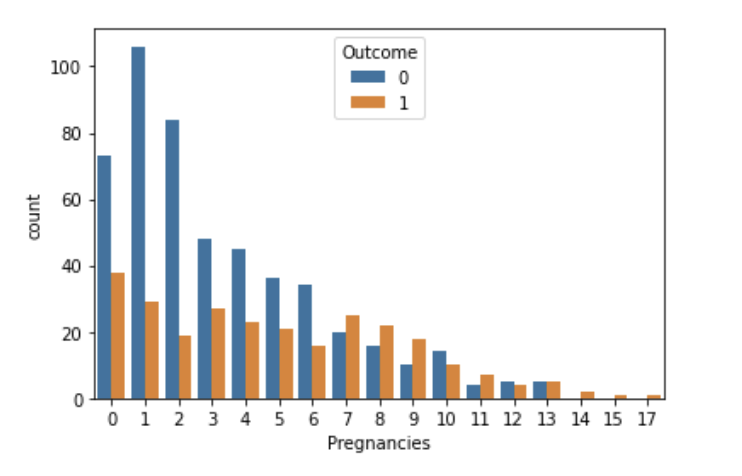
# 나이별 당뇨병 발병 빈도
plt.figure(figsize=(15, 4))
sns.countplot(data=df, x="Age", hue="Outcome")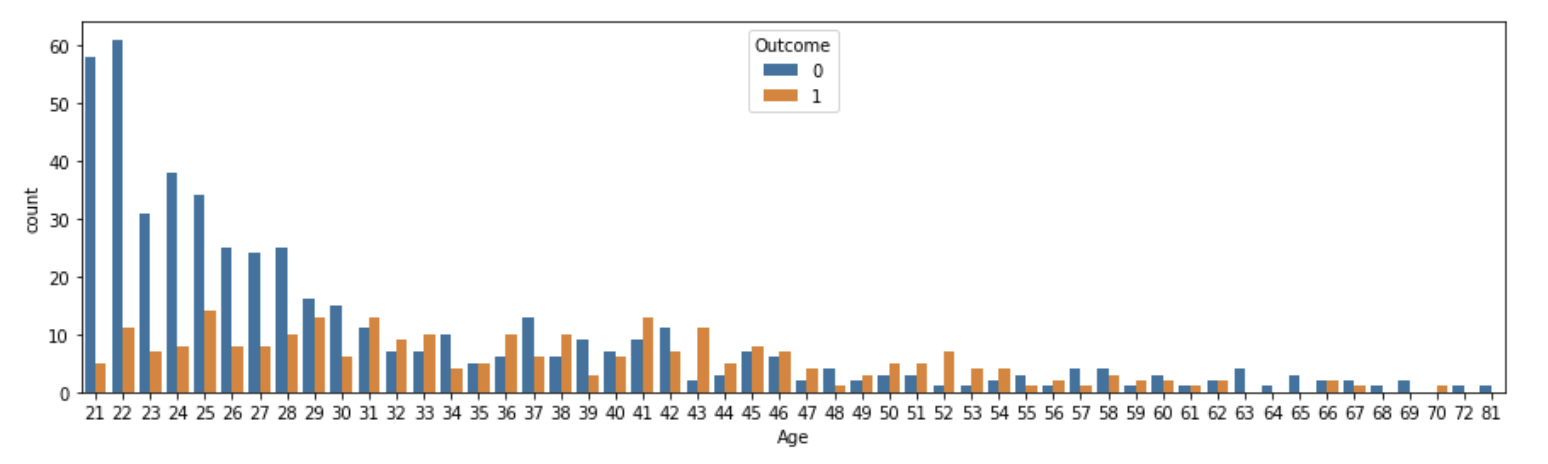
# Outcome 값 비교
sns.countplot(data=df, x="Outcome")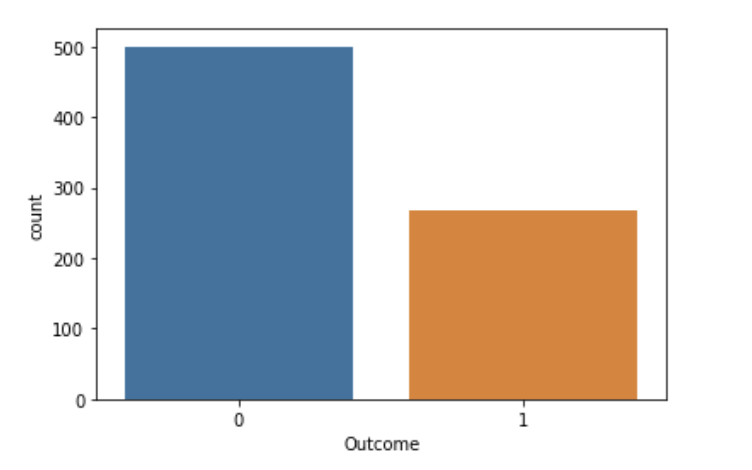
Feature Engineering
수치형 변수 -> 범주형 범주 만들기
# Pregnancies_high 파생변수 만들기
# 임신횟수가 6보다 큰 값의 True, False 값을 파생변수로 만들기
df['Pregnancies_high'] = df['Pregnancies'] > 6
sns.countplot(data=df, x="Pregnancies_high", hue="Outcome")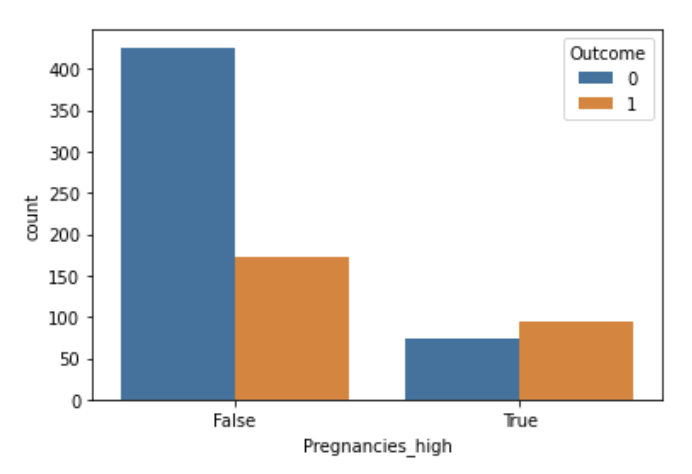
결측치 다루기
# Insulin 의 0 값을 결측치로 처리하여 Insulin_nan 새로운 컬럼 만들기
df['Insulin_nan'] = df['Insulin].replace(0, np.nan)
# 결측치 수
df["Insulin_nan"].isnull().sum()
=> 374
# 결측치 비율
df["Insulin_nan"].isnull().mean() * 100
=> 48.69791666666667
# groupby 사용하여 당뇨병 여부에 따른 평균, 중앙값
df.groupby("Outcome")[["Insulin", "Insulin_nan"]].describe()
# 결측치 채우기 1
df_1 = df.loc[df["Outcome"] == 0, "Insulin_nan"].fillna(Insulin_mean[0])
df_1 = df.loc[df["Outcome"] == 1, "Insulin_nan"].fillna(Insulin_mean[1])
df_3 = pd.concat([df_1, df_2])
df["Insulin_fill"] = df_3
df[["Insulin_fill"]].sample(3)
=>
Insulin_fill
533 130.287879
219 206.846154
53 300.000000# 결측치 채우기 2
df["Insulin_fill"] = df["Insulin_nan"]
df.loc[(df["Outcome"] == 0) & df["Insulin_nan"].isnull(), "Insulin_fill"] == Insulin_mean[0]
df.loc[(df["Outcome"] == 1) & df["Insulin_nan"].isnull(), "Insulin_fill"] == Insulin_mean[1]
df[['Insulin', 'Outcome', 'Insulin_nan', 'Insulin_fill']].sample(5)
=>
Insulin Outcome Insulin_nan Insulin_fill
176 0 0 NaN 130.287879
560 0 1 NaN 206.846154
296 360 1 360.0 360.000000
689 180 1 180.0 180.000000
673 240 0 240.0 240.000000df[["Insulin", "Insulin_nan", "Insulin_fill"]].describe()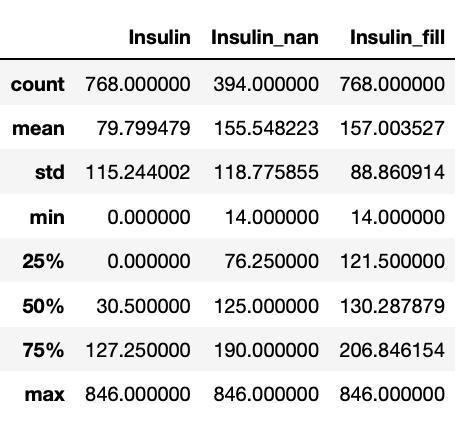
이상치(Outlier)
# boxplot 으로 이상치 확인
plt.figure(figsize=(15, 2))
sns.boxplot(df["Insulin_nan"])# 이상치 제거 전
df.shape
=> (768, 12)
IQR = df["Insulin_nan"].quantile(0.75) - df["Insulin_nan"].quantile(0.25)
outliers = df[df["Insulin_nan"] > df["Insulin_nan"].quantile(0.75) + 1.5 * IQR]
df = df.drop(outliers.index)# 이상치 제거 후
df.shape
=> (744, 12)학습, 예측 데이터셋 나누기
split_count = int(df.shape[0] * 0.8)
split_count
=> 595
train = df[:split_count].copy()
train.shape
=> (595, 12)
test = df[split_count:].copy()
test.shape
=> (149, 12)학습, 예측에 사용할 컬럼
# 학습과 예측에 사용할 컬럼 정리
feature_names = df.columns.tolist()
feature_names.remove(label_name)
feature_names.remove("Insulin")
feature_names.remove('Insulin_nan')
feature_names.remove('Pregnancies')학습, 예측 데이터셋 만들기
X_train = train[feature_names]
X_train.shape
=> (595, 8)
y_train = train[label_name]
y_train.shape
=> (595,)
X_test = test[feature_names]
X_test.shape
=> (149, 8)
y_test = test[label_name]
y_test.shape
=> (149,)머신러닝 알고리즘 RandomForest
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators = 100, max_features=0.95, max_depth=6, min_samples_leaf=3, n_jobs=-1, random_state=42)학습(훈련)
model.fit(X_train, y_train)예측
y_predict = model.predict(X_test)트리 알고리즘 분석하기
# 피처의 중요도를 추출하기
fi = pd.Series(model.feature_importances_)
fi.index = model.feature_names_in_
fi = fi.sort_values()
sns.barplot(x=fi, y=fi.index);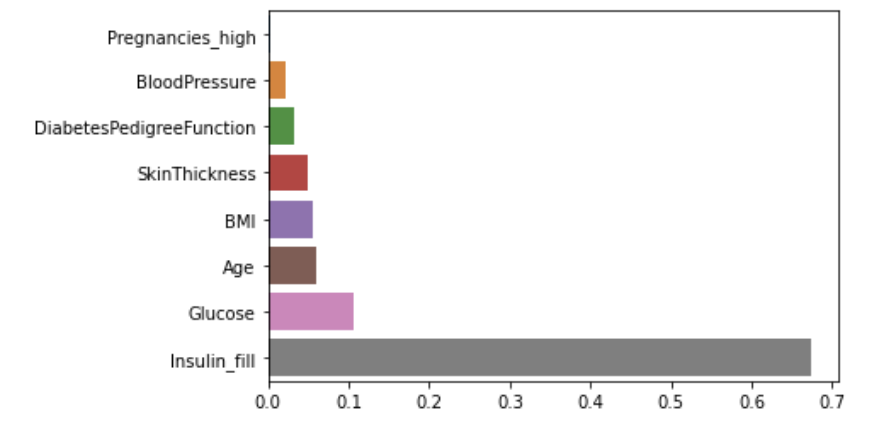
정확도(Accuracy) 출력
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
=> 0.9060402684563759
Ⓓ🅰️🅣🄰 ♡♥︎