[Object Detection] Architecture - 1 or 2 stage detector 차이
Computer Vision
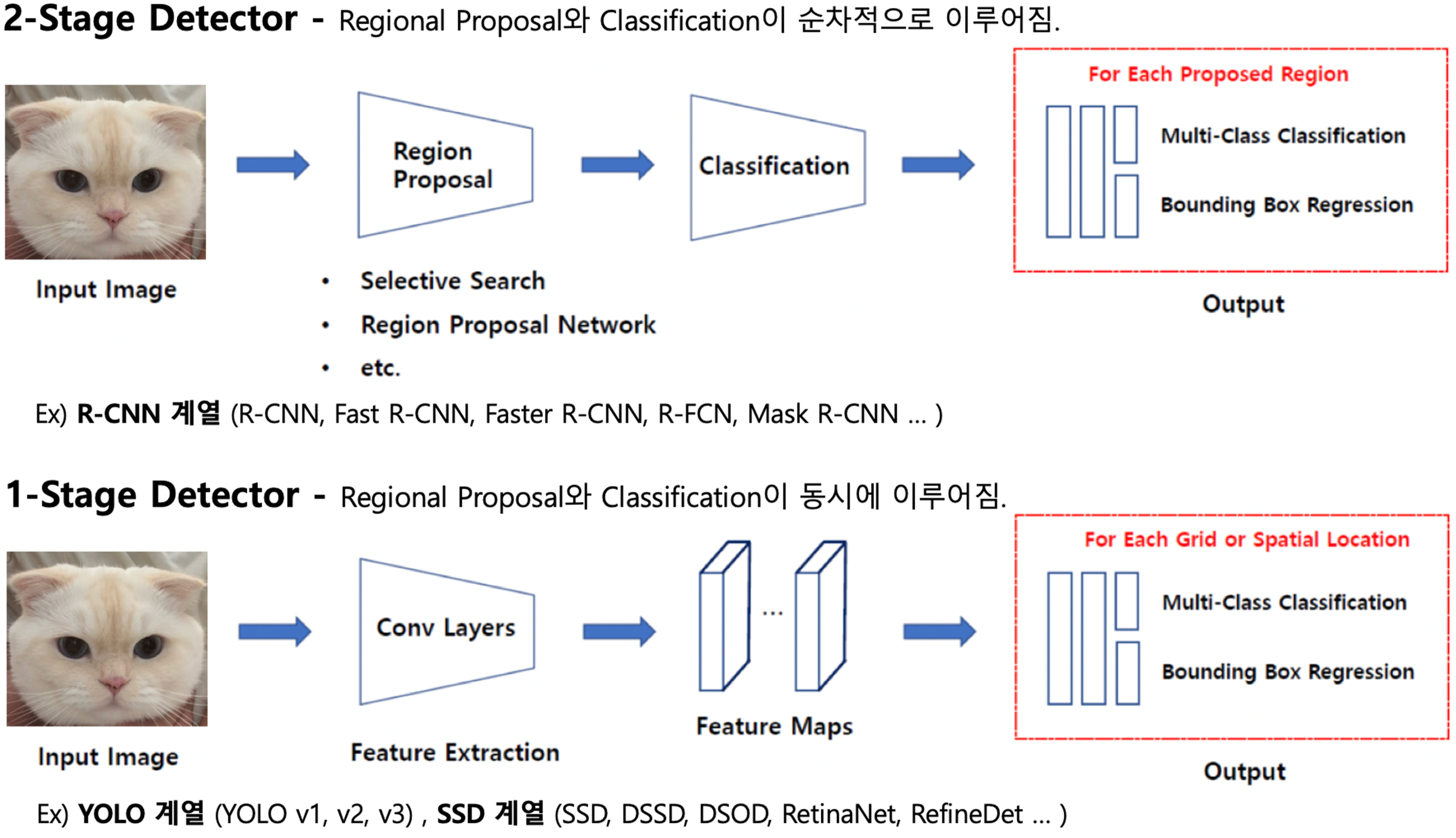
Object detection 아키텍처에는 1-stage detector과 2-stage detector가 있습니다.
본 글에서는 두 아키텍처 모델의 차이점에 대해 알아보려고 합니다.
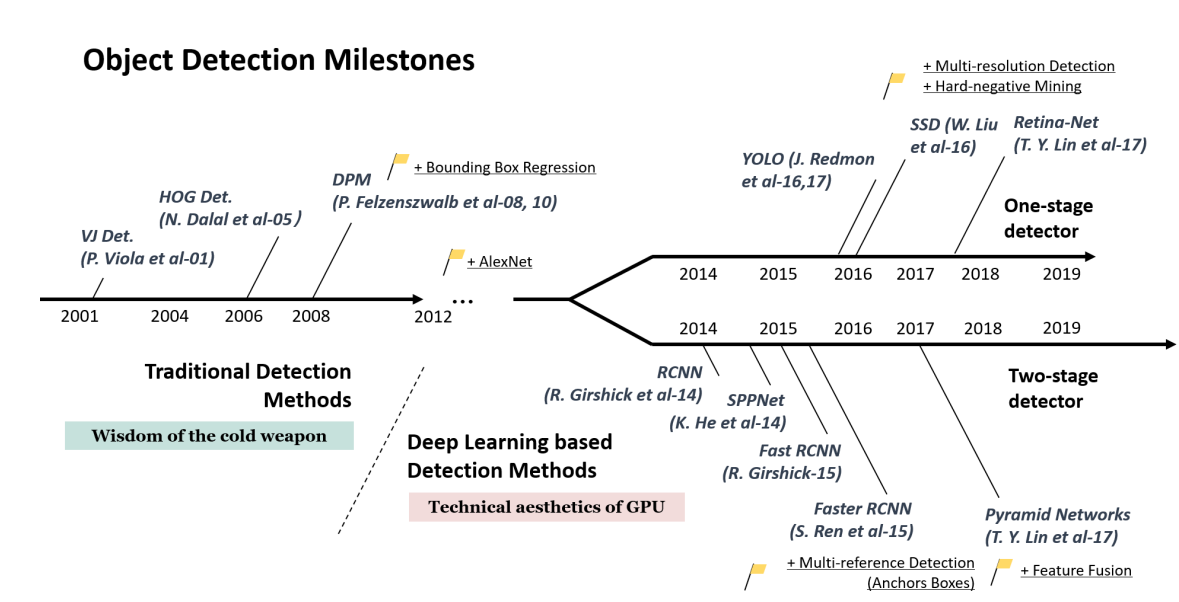
[출처: Zou et al. 2019. Object Detection in 20 Years: A Survey]
1-stage 방식에는 대표적으로 YOLO 시리즈와 Retina-Net, SSD, EfficientDet 등이 있으며, 2-stage 방식에는 RCNN 시리즈와 SPPNet 등이 있습니다.
2-Stage Detector
먼저 2-stage detector 입니다.
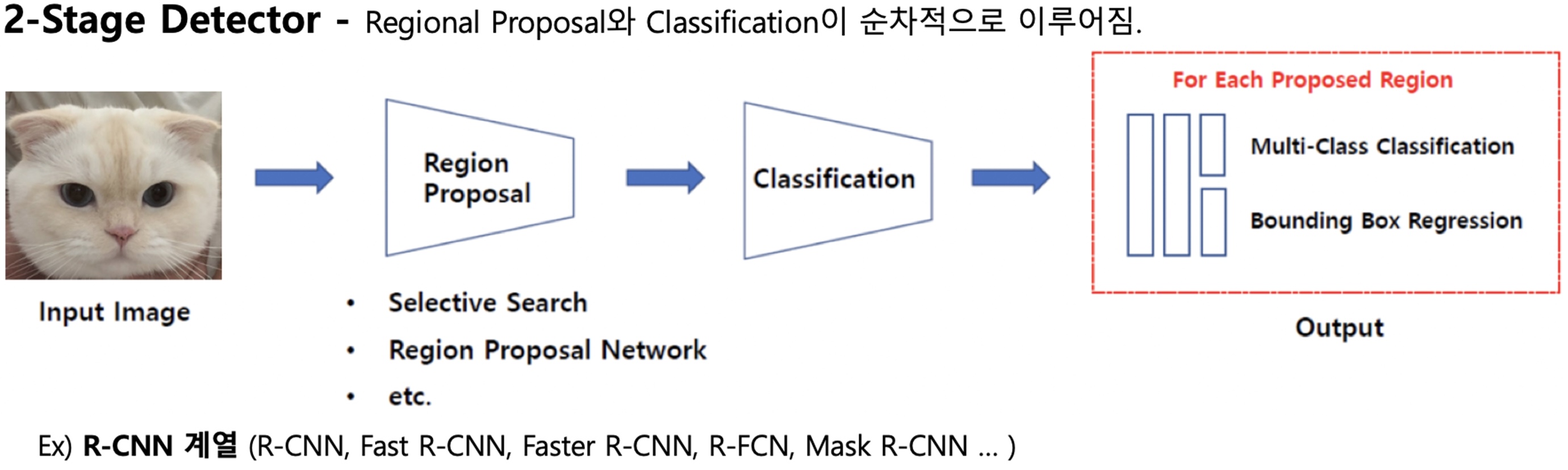
[출처:https://ganghee-lee.tistory.com/34]
이미지 안에서 객체가 있을 법한 같은 영역(ROI)을 Bounding Box로 대략적으로 찾습니다. 이것을 영역 제안(Region Proposal)이라고 합니다. 이후에 후보 영역을 바탕으로 Classification을 진행하여 객체를 검출합니다.
따라서 이러한 과정을 통해 1-stage detector 방식에 비해 시간은 소요되지만, 보다 좋은 성능의 결과를 도출하고 있습니다.
대표적인 영역 제안(Region Proposal) 기법으로는 Selective Search 기법과 Sliding window 방식이 있습니다.
(1) Selective Search
영역의 질감, 색, 강도 등을 갖는 인접 픽셀를 찾아서 물체가 있을 법한 box나 영역을 찾아냅니다.
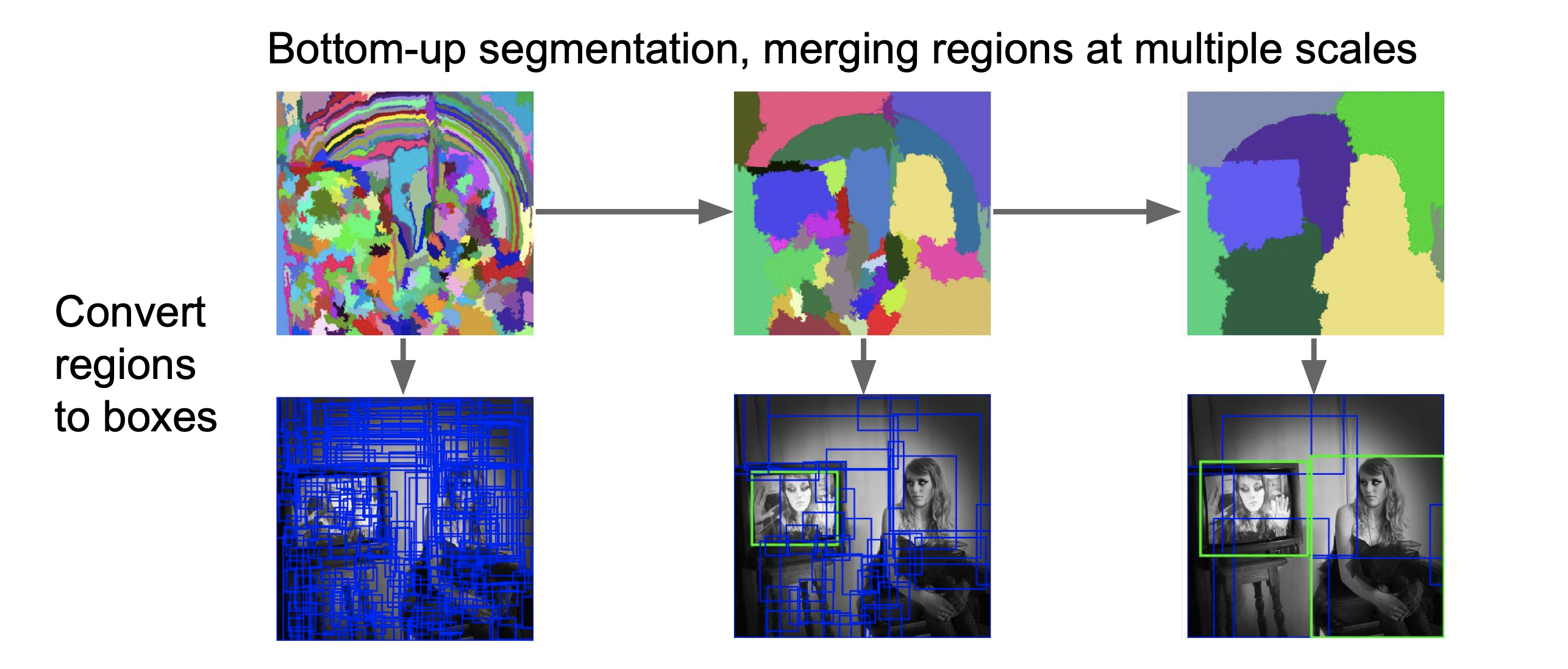
[출처:https://hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-what-is-object-detection/]
즉, 이미지 전체를 convolution 하지 않고 위의 사진에서 초록색 영역만 가지고 검사하도록 하여 훨씬 효율적으로 처리하도록 합니다.
(2) Sliding window
검출하고자 하는 입력 이미지에 정해진 크기의 Bounding Box를 만들어 방향을 이동하면서 물체가 있을 법한 box나 영역을 추출하는 것입니다. 모든 영역을 탐색해야 하기 때문에 시간이 많이 소요되어 비효율적이라는 특성이 있습니다.
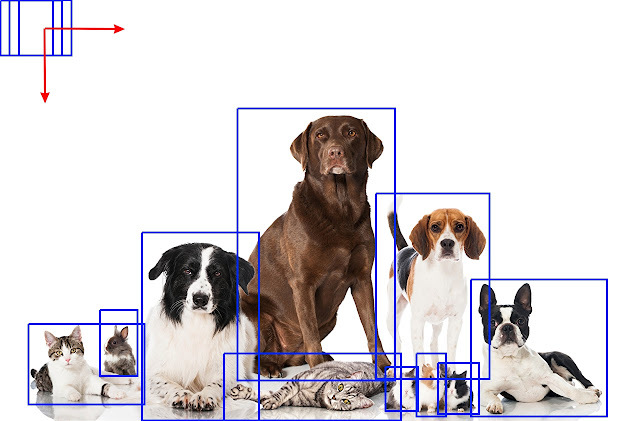
[출처:https://www.bojankomazec.com/2020/01/object-detection-with-sliding-window.html]
1-Stage Detector
반면 1-stage detector는 Regional Proposal과 Classification이 CNN을 통해 동시에 이루어져 2-Stage보다 속도가 빠릅니다.
Feature extraction에 해당하는 Conv layers에서 두 가지가 동시에 이루어집니다.
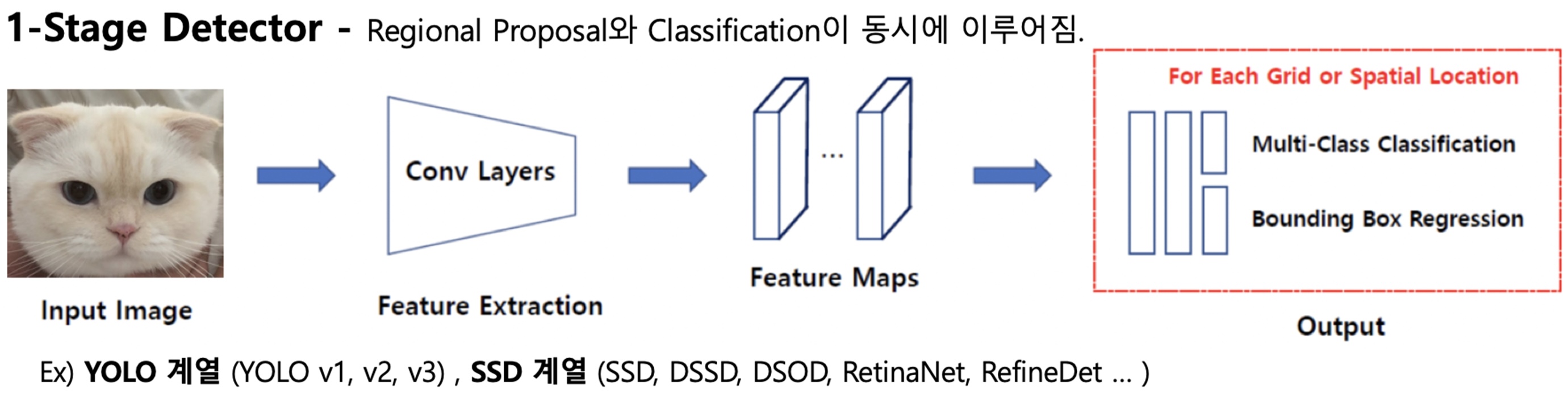
[출처:https://ganghee-lee.tistory.com/34]
여기는 ROI 영역을 추출하는 것이 아니라 Anchor box라는 개념을 사용합니다.
What is Anchor Box?
미리 정의된 형태를 가진 Bounding box 수를 ‘앵커 박스(Anchor Boxes)’라고 말합니다. 앵커 박스는 K-means 알고리즘에 의한 데이터로부터 생성됩니다. 사전에 크기와 비율이 모두 결정되어 있는 박스를 전제로, 학습을 통해서 이 박스의 위치나 크기를 세부 조정하여 객체를 탐지합니다.
앵커 박스를 사용하면 모든 잠재적 위치에서 별도의 예측을 계산하는 슬라이딩 윈도우로 이미지를 스캔할 필요가 없습니다.

[출처:https://blogs.sas.com/content/saskorea/2018/12/21/딥러닝을-활용한-객체-탐지-알고리즘-이해하기/]
각각의 앵커는 각기 다른 크기와 형태의 객체를 탐지하도록 설계되어 있습니다. 그림을 보면 한 장소에 3개의 앵커가 있는데요. 앵커 박스와 유사한 크기의 개체를 탐지하여 이미지의 피쳐(Feature) 맵에서 오프셋을 최적화합니다.
- offset : 예측된 bounding box의 위치 좌표 (g_c_x, g_c_y, g_w, g_h))
마지막으로 두 구조의 차이점을 표로 정리하면 아래와 같습니다.
| 2-Stage Object Detector | 1-stage Object Detector |
|---|---|
| Regional Proposal과 Classification 을 순차적으로 진행하여 객체 검출 | 영역 추출에 대한 좌표와 이미지 피처를 CNN을 통해 한번에 학습하여 결과를 도출 |
| - 1-stage에 비해 높은 검출 성능 | - 2-stage에 비해 낮은 검출 성능 |
| - 1-stage에 비해 속도가 느림 | - 2-stage에 비해 속도가 빠름 |
| → 정확성은 높으나 속도로 인해 실시간 객체탐지가 어려움 | → 실시간 객체 탐지 가능 |
| 대표 모델 : R-CNN / Fast R-CNN / Faster R-CNN | 대표 모델 : RetinaNet, SSD, EfficientDet, YOLO |
