Zhang, Han, et al. "Self-attention generative adversarial networks." International conference on machine learning. PMLR, 2019.
Abstract
- Self-attention GANs (SAGAN) 모델 아키텍처를 제안.
- 기존 Convolutional 레이어를 활용한 GAN 모델들은 long-range dependency를 모델링하기엔 어려움을 가지고 있었다.
- Convolutional 레이어 자체가 이미지를 local하게 바라본다.
- Spectral localization과 Self-attention을 적용해 Inception score를 높이며, FID를 낮추었다.
1. Introduction
- Convolution 계산이 local receptive한 영역에서 진행되기 때문에, long-range dependecy에 대한 학습이 어려웠다.
- Convolution 커널의 사이즈를 늘리면 long-range dependency의 학습에는 도움이 되겠지만 세부적인 디테일을 놓치게 될 것이다.
- 논문에서 self-attention을 통해 long range, multi-level dependency를 모델링하고자 한다.
- 여기에, 이전 연구에서 판별 모델()에만 적용하던 spectral normalization을 생성모델()에도 적용해보았다.
3. Self-Attention Generative Adversarial Networks
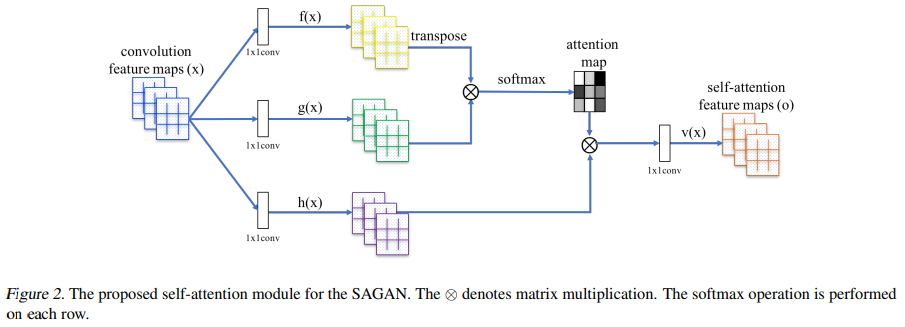
-
이전 레이어에서 전달되어 온 image features 를 두 가지 feature space 로 변환한다.
는 각각 query, key로 변환하는 계산과정으로 생각할 수 있겠다. -
attention score 를 계산한다. 번째 픽셀을 생성할 때, 번째 픽셀을 집중(attend)하는 정도를 나타낸다.
는 feature map의 채널 수, 은 이미지의 전체 픽셀 수() 이다.
-
Attention layer를 거친 결과값은 로 표현된다.
-
위에 나타난 , , 는 의 convolution 레이어로 구현되어 있다.
-
로 조정하며 실험했는데, 채널 수를 줄이면서 성능 하락이 나타나지 않았기 때문에, 가장 적은 채널 수를 채택하여 계산 비용을 줄였다.
즉, 의 feature map이 self-attention 블록을 통과할 때 로 채널 수가 줄어들었다가 다시 의 feature map 로 탄생!
-
마지막으로 learnable parameter 를 통해 self-attention score를 얼마나 반영할지 학습하게 했다. 으로 초기화 했다.
논문에서 주장하는 바로는 가 처음에는 0으로 초기화되기 때문에, 모델이 처음에는 convolution의 영향이 큰 학습으로 지역적(local) 정보를 학습하고 나중에는 가 점점 커지면서 non-local한 정보를 학습하게 될 것이라고 서술하고 있다.
-
이 self-attention 모듈은 생성 모델()와 판별 모델()에 모두 적용되어 adversarial loss를 최소화하는 방향으로 학습했다.
4. Techniques to Stabilize the Training of GANs
논문에서는 GANs의 학습에 안정을 위한 테크닉을 두 가지 사용했다.
1. spectral normalization
2. two timescale update rule (TTUR)
4.1. Spectral normalization for both generator and discriminator
- Miyato 등의 2018년 연구에서 먼저 GANs의 판별 모델()에 Spectral normalization을 사용했었다.
- 다른 normalization 테크닉과 다르게, spectral normalization은 hyper-parameter 튜닝이 필요하지 않다.
- 생성 모델()에 제한을 가하는 것이 GANs의 성능의 중요한 역할을 한다는 최근의 연구들을 기반으로 spectral normalization을 생성 모델()에도 적용했다.
- parameter가 증가하는 것과, 비정상적인 gradient를 방지할 수 있다.
4.2. Imbalanced learning rate for generator and discriminator updates
- Miyato 등의 2018년 연구와 Gulrajani 등의 2017년 연구에서 판별 모델()에 제약을 가하는 것이 GANs의 학습 속도를 늦출 수 있다고 지적했다.
- 실제로, 판별 모델이 학습에 제약을 받으면 생성 모델이 한 번 업데이트될 때마다 여러 번의 업데이트를 거쳐야 했었다.
- Heusel 등의 2017년 연구에서 두 모델에 별도에 학습 속도의 사용(TTUR)을 제안했었다.
- 이번 연구에서도 TTUR을 사용했을 때, 더 나은 결과를 도출할 수 있었다.
5. Experiments
LSVRC2012(ImageNet) 데이터셋에 다양한 실험을 진행했다.
Evaluation metrics. Inception score와 FID를 정량적인 평가 척도로 사용했다.
두 평가 척도 모두 이미지 분류 네트워크인 Inception-V3를 사용한 평가 척도인데, 그 사용법이 약간 다르다.
Inception score (IS)는 Inception-V3가 예측한 클래스 값으로 계산할 수 있다.
- GAN이 생성한 이미지에 대해 conditional class distribution과 marginal class distribution의 KL divergence 값을 계산하는 척도이다.
- conditional class distribution: 주어진 입력 이미지에 대한 label의 분포.
즉, 고양이 사진을 고양이로 분류해낼 확률 분포이다. 생성한 이미지가 고양이에 가까운 이미지를 생성했다면 고양이의 확률 값이 굉장히 높은 peak한 분포를 이룬다. (Entropy가 낮다.) - marginal class distribution: 모든 이미지에 대한 label의 분포.
즉, 고양이, 강아지, 코끼리, ... 등등의 클래스 분포이다. 모든 이미지가 각 label마다 일정한 수의 이미지가 생성되었다면 그 분포는 골고루 퍼진, uniform한 분포를 이룬다. (Entropy가 높다.) - KL-divergence: 위에서 구한 두 분포 사이의 Entropy 차이를 계산하게 된다.
위에서 서술한 예시처럼 두 분포 사이의 entropy 차이를 구하면 큰 값이 나타나게 된다.
- conditional class distribution: 주어진 입력 이미지에 대한 label의 분포.
- 정리하면 inception score는 GANs이 한 이미지를 만들 때 그 클래스의 특징을 잘 만드는지 (Conditional class distribution)와 다양한 클래스의 이미지를 만들었는지 (Marginal class distribution)를 동시에 측정할 수 있는 평가척도이다.
- 클수록 좋은 점수!
Frechet inception distance (FID)는 Inception-V3가 추출한 feature map을 가지고 계산할 수 있다.
- GAN이 생성한 이미지와 실제 이미지에 대해 Inception-V3를 통과시킨다. 이 때, 가장 마지막 단의 classifier 부분을 제거하고 feature map까지 생성하도록 한다.
- 생성된 feature map 사이의 분포간 거리를 구한다. 논문에서는 Wasserstein-2 거리를 계산했다.
- 계산된 분포간 거리가 가까울수록 실제 이미지와 생성된 이미지가 비슷하다는 의미이다.
- FID가 IS보다 좀 더 원칙적이고 포괄적인 지표하고 볼 수 있다.
5.1. Evaluating the proposed stabilization techniques
- 논문에서 제안하고 있는 stabilization techniques (1. spectral normalization; 2. TTUR)의 효과를 입증하는 실험이다.
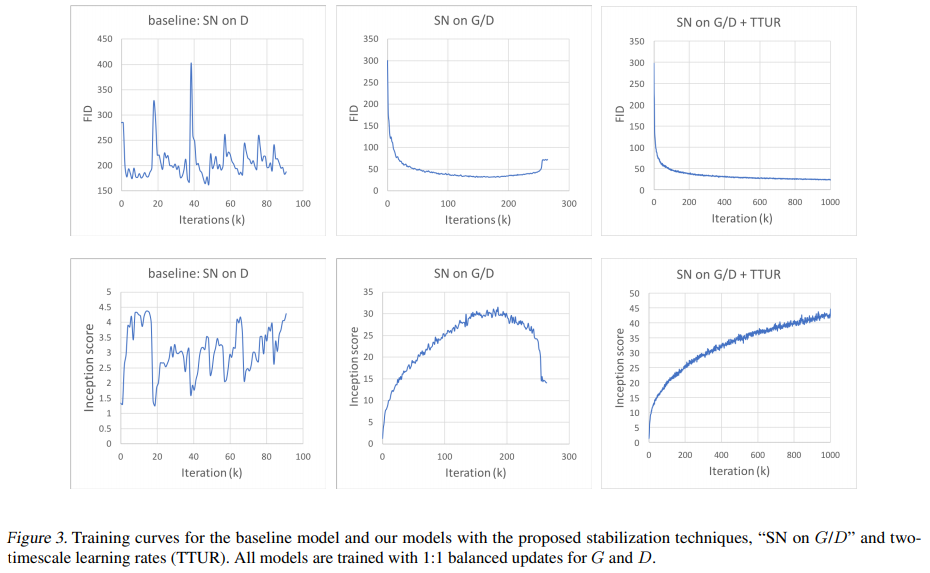
- Spectral normalization을 생성 모델에도 적용했을 때, TTUR을 적용했을 때, 점차 학습의 안정성이 향상되는 모습을 볼 수 있다.
- 테크닉을 모두 사용한 SN on G/D + TTUR모델은 학습 횟수가 점차 늘어남에도 FID와 Inception score 모두 지속적으로 증가하는 모습을 보여준다.

5.2. Self-attention mechanism
- self-attention 모듈이 추가되는 위치에 따른 성능 차이를 비교하고 있다.

- 높은 수준의 feature map에 self-attention 모듈을 부착했을 때, 더 좋은 성능을 보였다.
논문의 저자들은 "SAGAN, "의 self-attention 모듈보다 "SAGAN, "가 더 많은 정보를 받을 수 있기 때문에 더 좋은 성능을 보인다고 추측하고 있다.
- 같은 크기의 feature map을 반환하는 Residual block을 self-attention에 대체했을 때는 성능이 향상되지 못하고 있다. (표 1의 "Residual" columns)

- 그림 5는 각 픽셀의 위치에 따른 attention map을 시각화한 그림이다.
- 각 픽셀에 따라 다른 부분을 "attend"하고 있음을 알 수 있다.
6. Conclusion
- GANs의 프레임워크에 self-attention을 도입해, long-range dependency를 모델링할 수 있도록 했다.
- 여러 이전 연구에서 제안된 학습 안정 테크닉들을 개량하여 학습 안정성을 개선했다.
review...
- 단순한 self-attention 모듈을 도입하여 성능 향상을 이루었다.
- 그림 5의 attention map의 시각화는 충분히 흥미로웠다.
비슷한 위치의 픽셀들도 각자가 각각 "attend"하는 부분이 다름을 관찰하면서 실제로 질감의 표현, 전경과 배경의 구분과 같은 요소들을 학습시킬 수 있다는 인사이트를 얻는 기분이었다.
