
Object Detection(객체 탐지)
객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.
EfficientDet
여러 아키텍쳐들의 방법들을 사람이 아닌 자동으로 찾는 AI를 개발하는 제안을 하게 된다.
그래서 NAS(Neural Architecture Search)라는 연구 분야가 발생하게 된다.
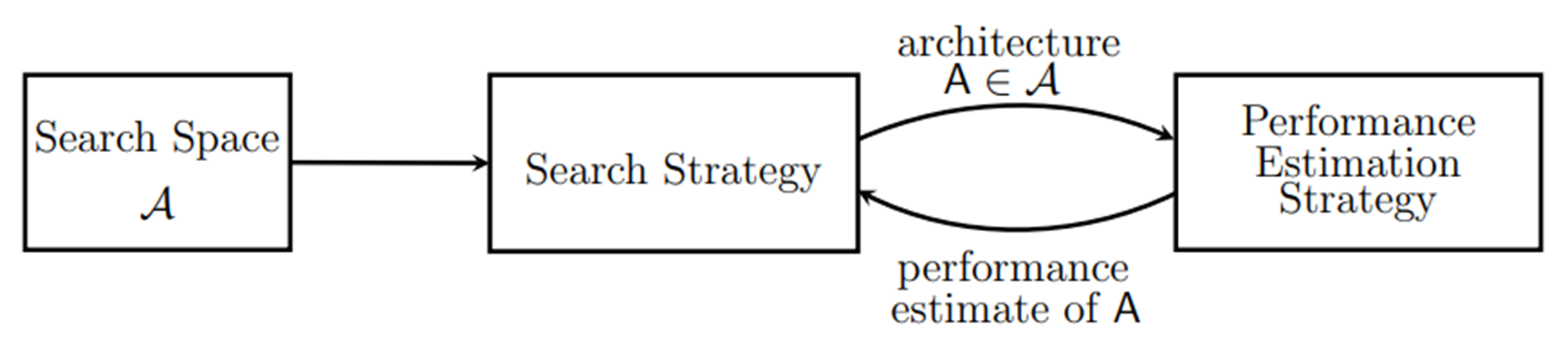
NAS를 간단히 보면, 먼저 사람이 정해놓은 Search Space가 있고 Search Space를 탐색할 Search Strategy를 정한다. 그 후에 Search Strategy 통해서 찾은 아키텍쳐를 찾고 performance를 측정한다. 그리고 performance를 리워드로 사용하거나 이 performance를 기준으로 다른 Search Strategy에서 새로운 아키텍쳐를 찾아내는 방법을 반복한다.
NAS는 노말셀과 리덕션셀 두 가지를 찾는데, 너무 복잡하게 되어 있었다. 커널 사이즈부터 오퍼레이션까지 모두 다르고 복잡하게 연결이 되다보니 성능은 좋지만 실사용에서 적용시키기에 의문점이 많이 있었다.
이 후에는 얼마나 Efficient하게 그리고 아키텍쳐 상에서 채널의 수나 블록의 반복 횟수들에 대한 방향으로 가게 된다. 그래서 NAS의 큰 틀은 비슷하나 새로운 아키텍쳐를 찾는다기 보다는 최적화된 아키텍쳐를 기계가 자동으로 찾아가는 방향 접근하게 된다.
그렇게 나온 논문이 아래 그림의 EfficientNet(CVPR 2019)이다.
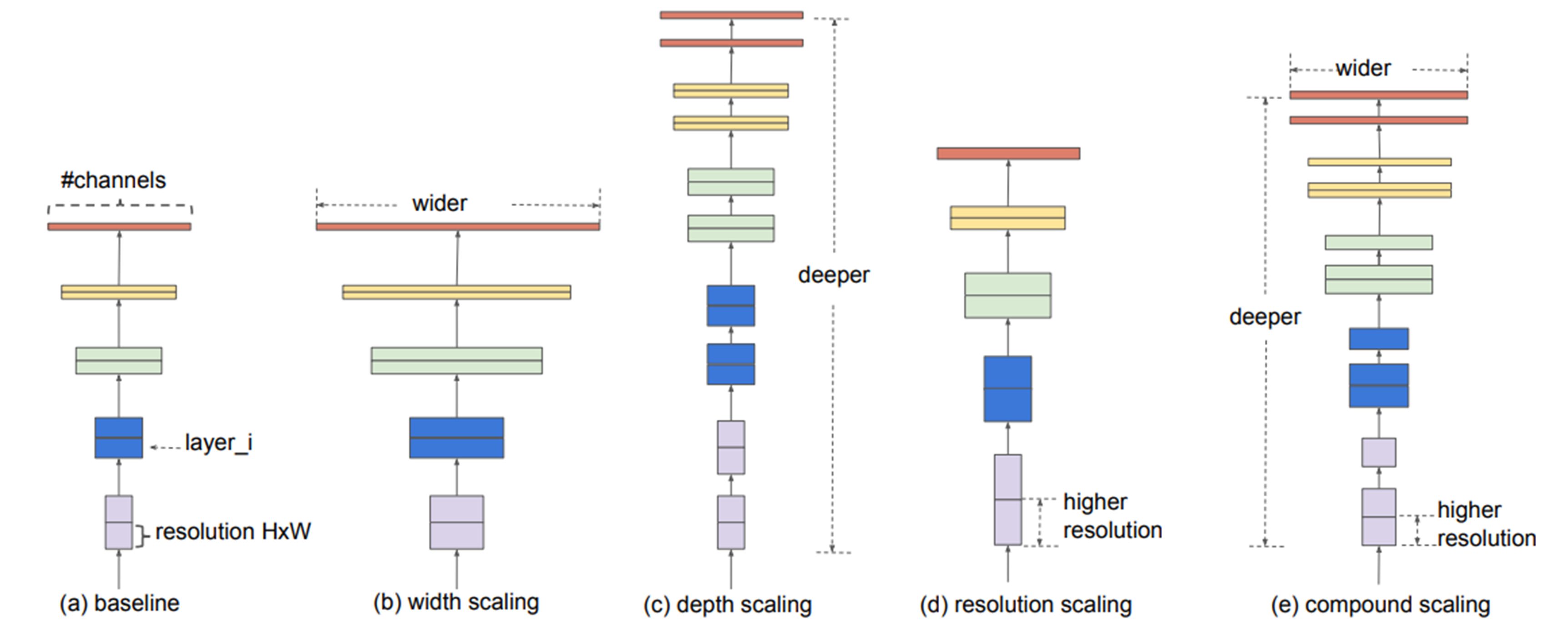
채널 수, 레이어, 입력 영상의 레졸루션 등을 scaling하면서 찾아보겠다는 것이다. 리소스가 굉장이 많이 드는 연구로 일반적으로 접근하기에는 어려움이 있다.
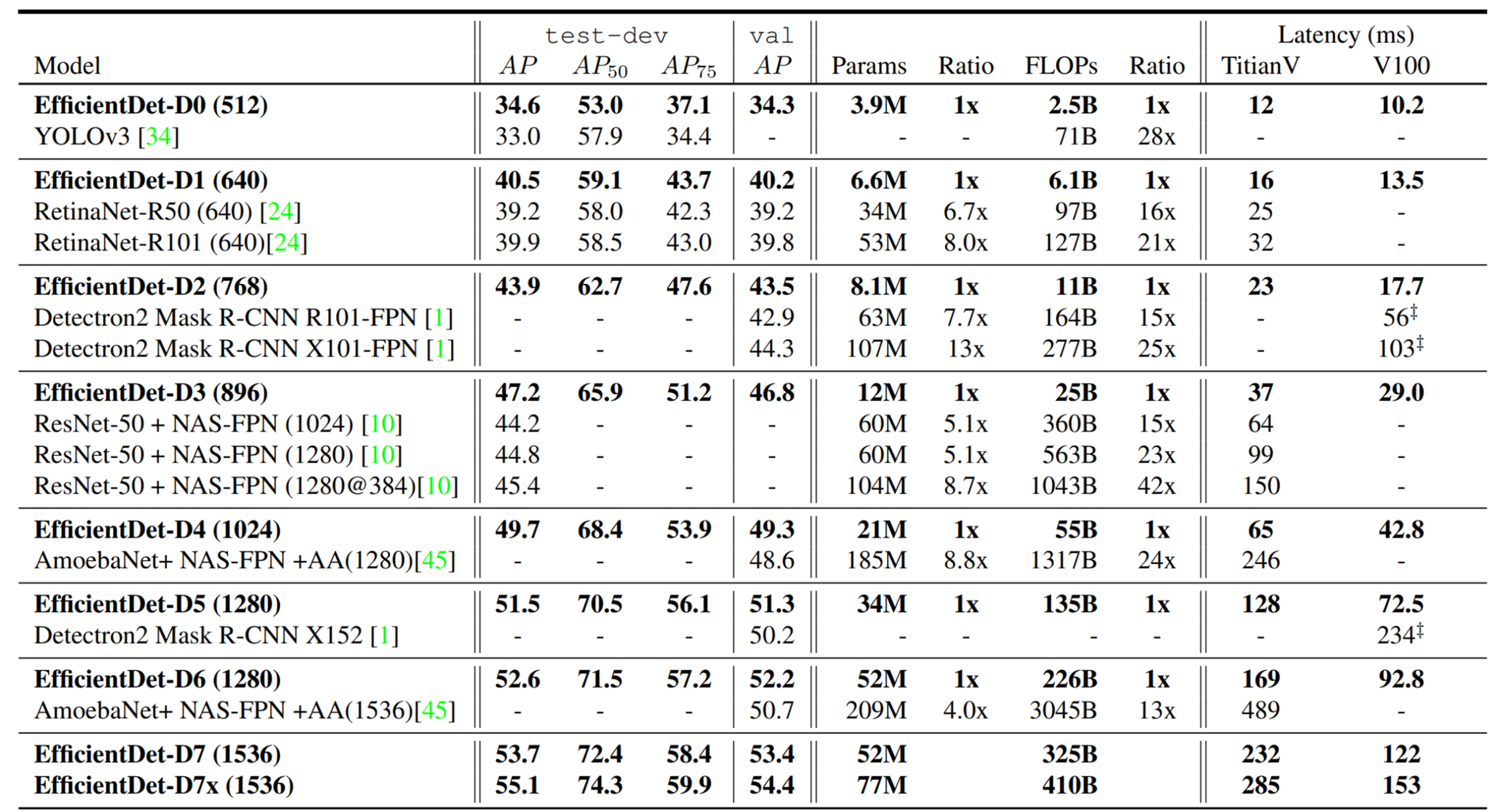
EfficientDet은 EfficientNet을 detection용으로 바꿔서 제안한 방법이다. 기존의 state of the Art Method보다 좋은 성능을 보여준다.
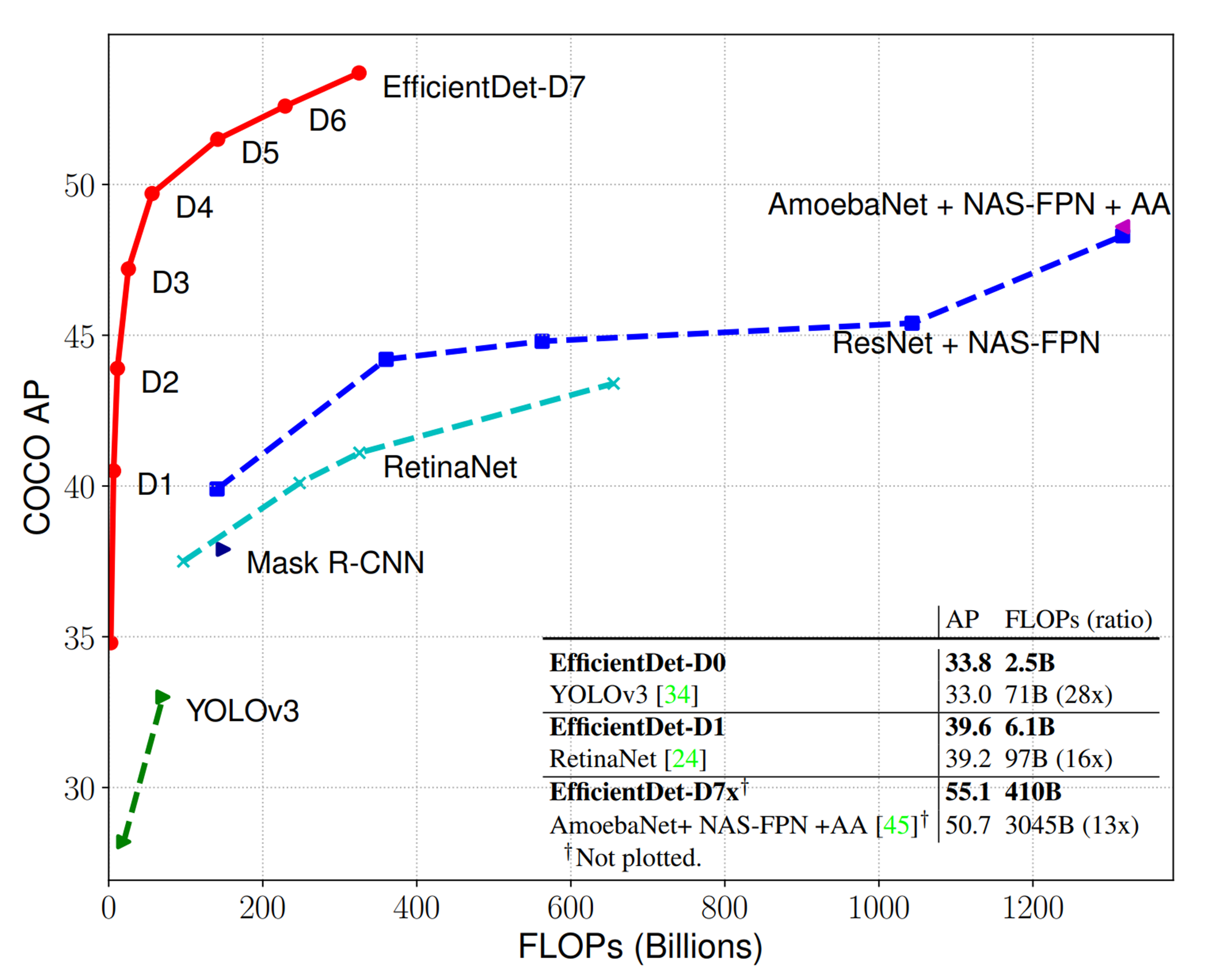
EfficientDet은 크게 3가지를 제안한다.
- Cross-scale connections
- Weighted feature fusion
- Compound scaling
1. Cross-scale connections
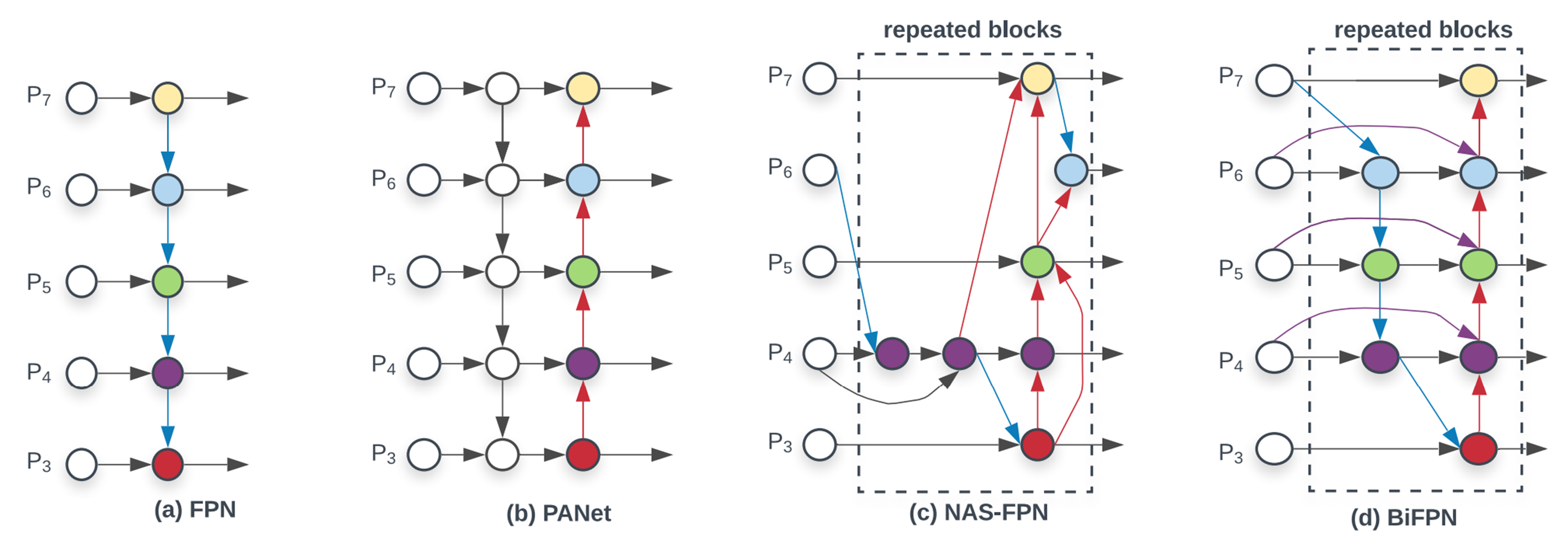
FPN에서 P의 숫자가 클 수록 피쳐 레졸루션이 작은 상태인데, 레졸루션을 줄여나가다가 다시 레졸루션을 키우면서 이전의 피쳐들에 맞게 스케일링 혹은 더하는 방법으로 합친다. 그리고 다시 출력을 통해서 최종 detection 성능을 뽑는 방법으로 사용된다. U-Net과 비슷하지만, U-Net은 다시 P0까지 업스케일링 후에 출력을 한 것에 반해서 FPN은 원하는 결과 출력부에 Head를 연결시켜서 출력을 하게 된다.
PANet은 FPN의 다운과 업을 반복하는 방법을 제안했다.
NAS-FPN은 백본 이후의 네트워크를 NAS 방법을 통해 찾는 방법으로 복잡한 형태의 커넥션을 만든다.
BiFPN은 기존의 FPN과 같이 레졸루션의 연결이 올라갔다가 내려오는 구조는 유지하고 기존의 레졸루션에서 스킵 커넥션을 가져오는 방식을 취한다.
2. Weighted feature fusion
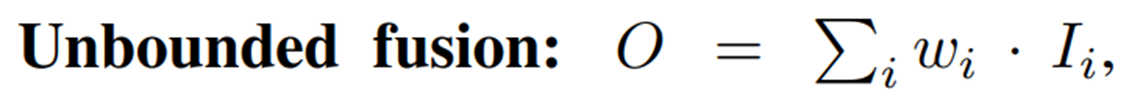
각각의 features에 가중치를 줘서 합한다. unbounded fusion은 각 피쳐 맵마다 어떤 가중치를 정해줘서 최종 출력을 정하게 된다.

EfficientDet 논문에서는 unbounded fusion보다 softmax-based fusion을 하는 것이 좋다고 제안한다. 하지만 softmax-based fusion은 계산량이 많이 들어가게 된다.
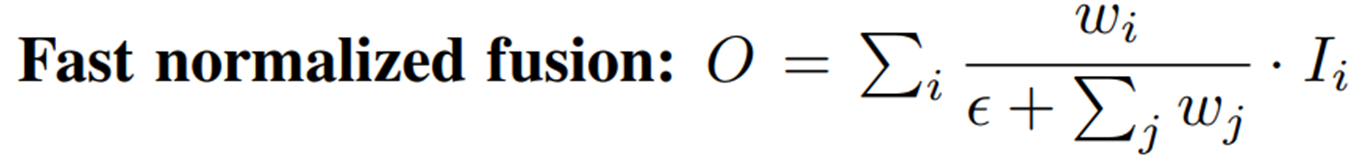
그래서 비슷한 형태를 가지지만 e의 지수승을 계산하기 보다 하나의 변수로 변경을 한 fast normalized fusion을 제안한다.
예로 아래의 P6의 td.
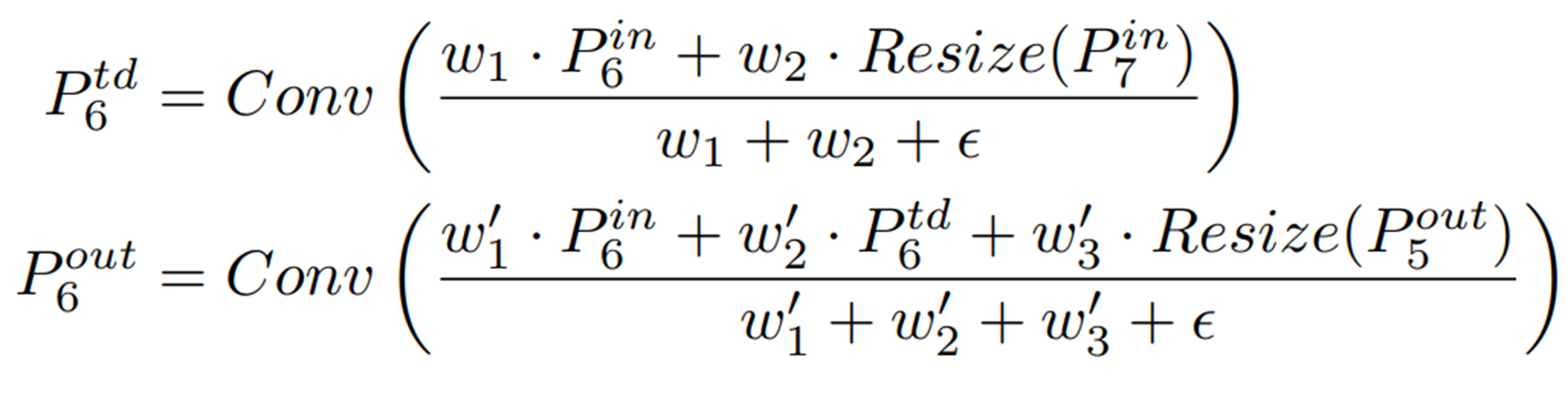
3. Compound scaling
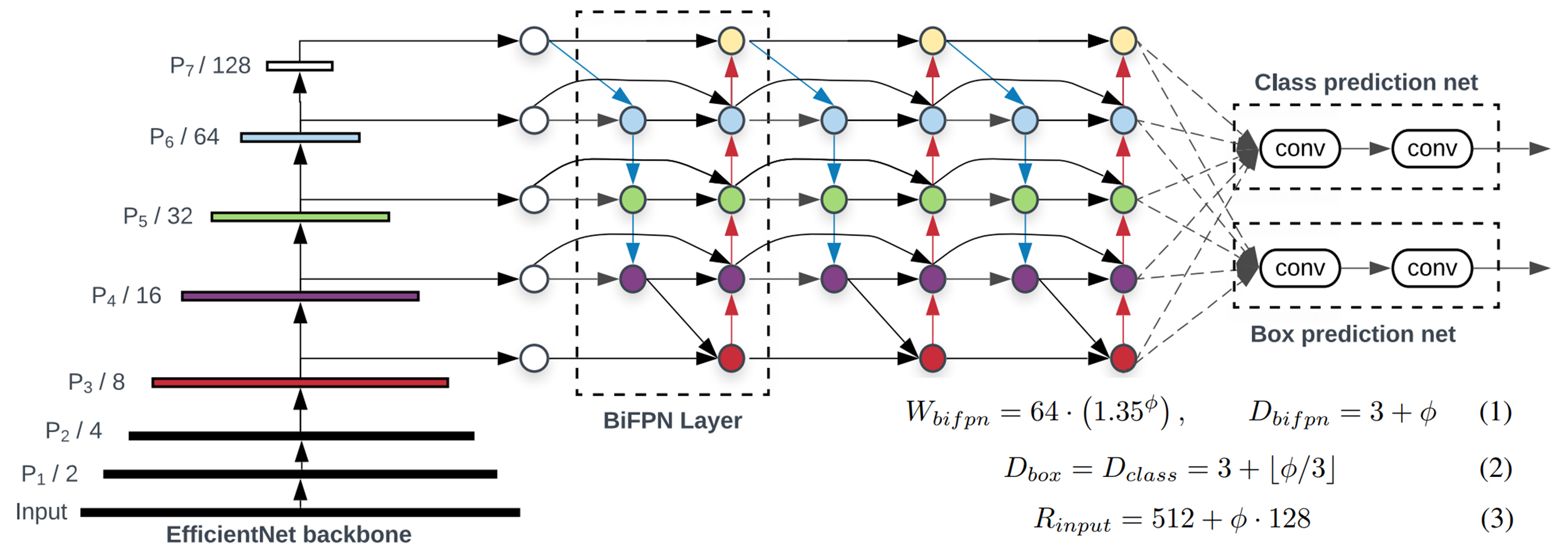
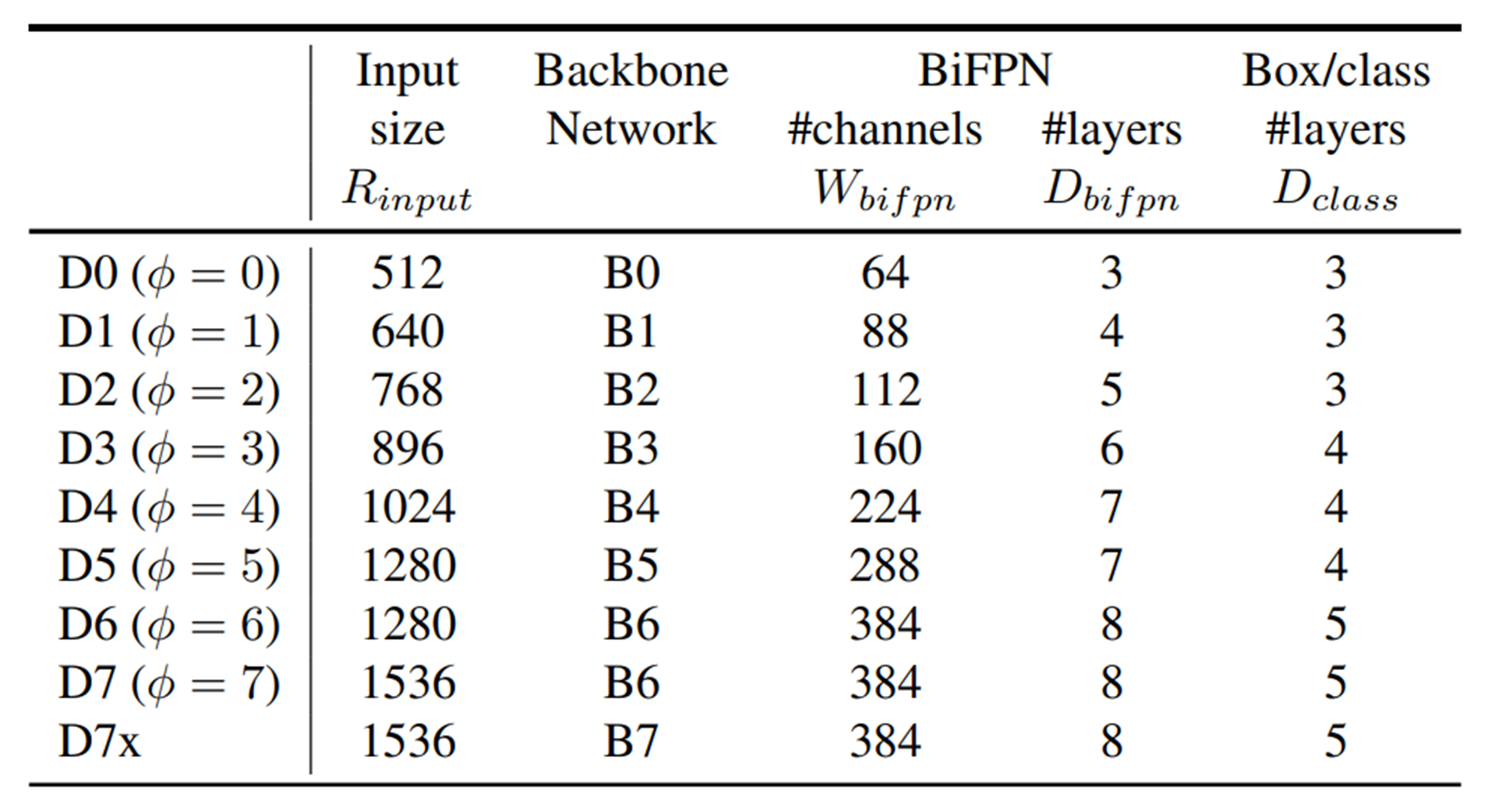
논문에서는 스케일링 팩터 파이를 정한 다음에, 그 파이에 따라서 반복 횟수, 영상 레졸루션 등을 정하게 된다.
W(bifpn)는 채널수, D(bifpn)는 BiFPN 레이어를 몇 번 반복할지 정의, D(box, class)는 네트워크에 있는 conv의 수, R(input)은 입력으로 파이가 증가함에 따라서 선형적으로 증가하도록 정의가 되어 있다.
아래와 같이 표로 정리해 볼 수 있다.
이렇게 미리 정의함으로써 네트워크가 심플해진다.
Loss Function
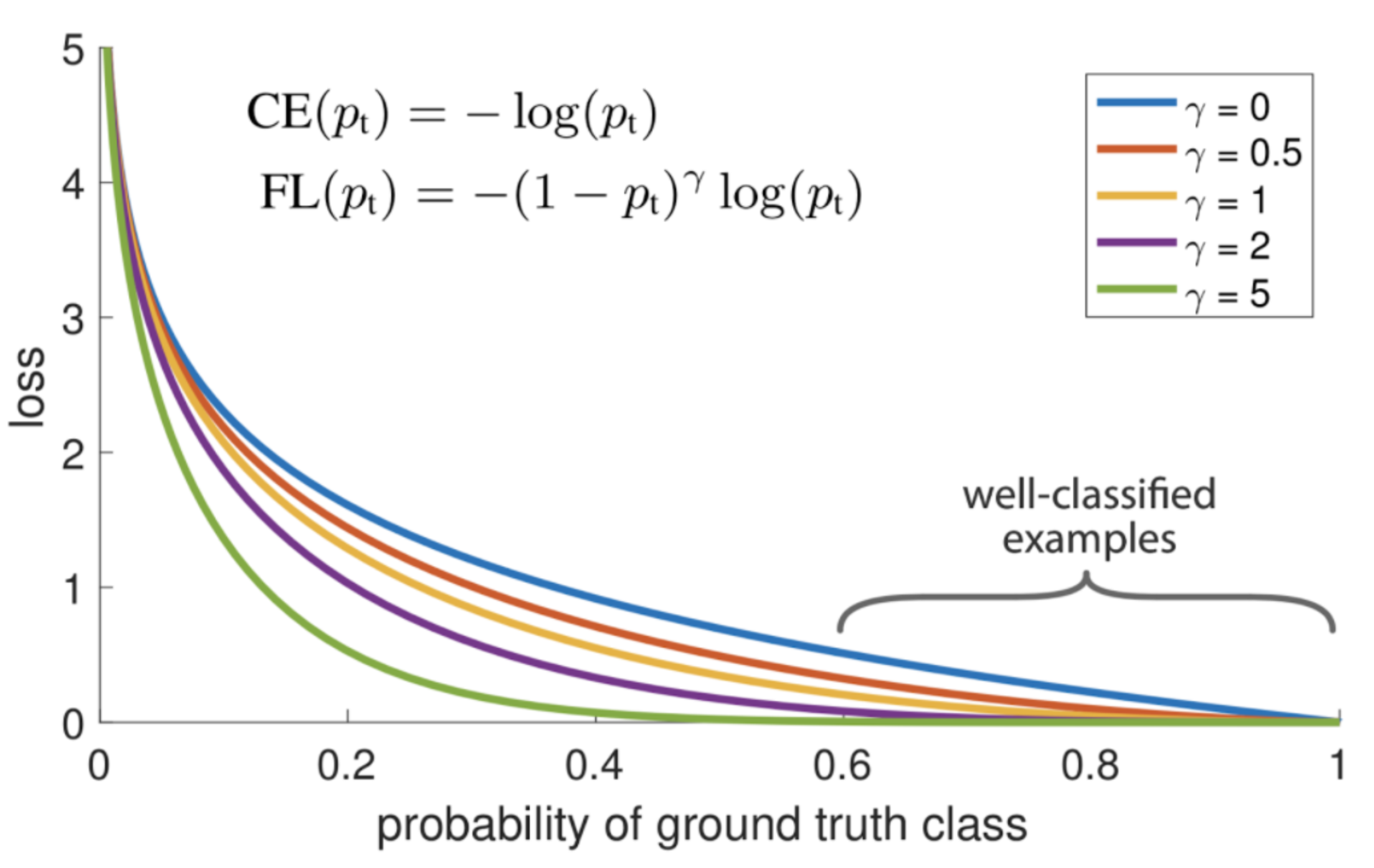
Loss Function은 RetinaNet에서 사용한 Focal Loss를 사용한다.
Pt는 score는 에측하지 못한 0과 잘 예측한 값 1사이의 값을 가지는데, CE(cross entropy loss)가 0이면 inf loss를 1이면 loss를 받지 않는다. CE는 잘못 예측한 경우에 패털티를 부여하는데 초점을 맞춘 것이다. 그래서 샘플 수가 다른 것에 대해서도 모두 같은 loss값을 주기때문에 누적이 되면 샘플 수가 많은(백그라운드) 것에 예측을 잘 하지만 정답에 대해서는 예측을 잘 하지 못하는 경우가 발생한다.
Focal Loss는 예측된 확륙값을 기반으로 Loss를 조절하는 방법이다. 기존의 CE에 '(1 - pt)^gamma'을 곱해준다. 그래서 gamma가 0이면 CE와 같고 커질수록 x축과 가까워지는 형태가 된다.
EfficientDet Model
EfficientDet 모델
EfficientDet 모델은 EfficientNet를 backbone으로 사용한다.
class EfficientDetBackbone(nn.Module):
def __init__(self, num_classes=80, compound_coef=0, load_weights=False, **kwargs):
super(EfficientDetBackbone, self).__init__()
self.compound_coef = compound_coef
self.backbone_compound_coef = [0, 1, 2, 3, 4, 5, 6, 6, 7] # 파이 값
self.fpn_num_filters = [64, 88, 112, 160, 224, 288, 384, 384, 384] # 파이 값에 따른 BiFPN channels
self.fpn_cell_repeats = [3, 4, 5, 6, 7, 7, 8, 8, 8] # 파이 값에 따른 BiFPN layers(반복)
self.input_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536] # 파이 값에 따른 input size(Resize)
self.box_class_repeats = [3, 3, 3, 4, 4, 4, 5, 5, 5] # 파이 값에 따른 box/class layers
self.pyramid_levels = [5, 5, 5, 5, 5, 5, 5, 5, 6]
self.anchor_scale = [4., 4., 4., 4., 4., 4., 4., 5., 4.]
self.aspect_ratios = kwargs.get('ratios', [(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)])
self.num_scales = len(kwargs.get('scales', [2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]))
conv_channel_coef = {
# the channels of P3/P4/P5.
0: [40, 112, 320],
1: [40, 112, 320],
2: [48, 120, 352],
3: [48, 136, 384],
4: [56, 160, 448],
5: [64, 176, 512],
6: [72, 200, 576],
7: [72, 200, 576],
8: [80, 224, 640],
}
num_anchors = len(self.aspect_ratios) * self.num_scales
# BiFPN 정의
self.bifpn = nn.Sequential(
*[BiFPN(self.fpn_num_filters[self.compound_coef],
conv_channel_coef[compound_coef],
True if _ == 0 else False,
attention=True if compound_coef < 6 else False,
use_p8=compound_coef > 7)
for _ in range(self.fpn_cell_repeats[compound_coef])])
self.num_classes = num_classes
self.regressor = Regressor(in_channels=self.fpn_num_filters[self.compound_coef], num_anchors=num_anchors,
num_layers=self.box_class_repeats[self.compound_coef],
pyramid_levels=self.pyramid_levels[self.compound_coef])
self.classifier = Classifier(in_channels=self.fpn_num_filters[self.compound_coef], num_anchors=num_anchors,
num_classes=num_classes,
num_layers=self.box_class_repeats[self.compound_coef],
pyramid_levels=self.pyramid_levels[self.compound_coef])
self.anchors = Anchors(anchor_scale=self.anchor_scale[compound_coef],
pyramid_levels=(torch.arange(self.pyramid_levels[self.compound_coef]) + 3).tolist(),
**kwargs)
# backbone 정의 : EfficientNet
self.backbone_net = EfficientNet(self.backbone_compound_coef[compound_coef], load_weights)
def freeze_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def forward(self, inputs):
max_size = inputs.shape[-1]
_, p3, p4, p5 = self.backbone_net(inputs) # backbone network에서 3, 4, 5만 사용
features = (p3, p4, p5)
features = self.bifpn(features)
regression = self.regressor(features)
classification = self.classifier(features)
anchors = self.anchors(inputs, inputs.dtype)
return features, regression, classification, anchors
def init_backbone(self, path):
state_dict = torch.load(path)
try:
ret = self.load_state_dict(state_dict, strict=False)
print(ret)
except RuntimeError as e:
print('Ignoring ' + str(e) + '"')BiFPN
BiFPN 정의를 아래의 그림과 같이 따라가면서 보자.
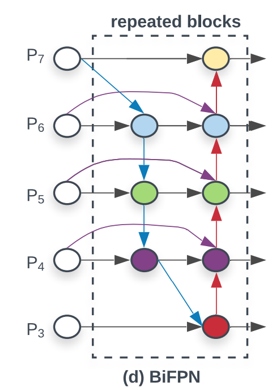
# BiFPN 정의
class BiFPN(nn.Module):
def __init__(self, num_channels, conv_channels, first_time=False, epsilon=1e-4, onnx_export=False, attention=True,
use_p8=False):
super(BiFPN, self).__init__()
self.epsilon = epsilon
self.use_p8 = use_p8
# Conv layers
self.conv6_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv5_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv4_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv3_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv4_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv5_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv6_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv7_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
if use_p8:
self.conv7_up = SeparableConvBlock(num_channels, onnx_export=onnx_export)
self.conv8_down = SeparableConvBlock(num_channels, onnx_export=onnx_export)
# Feature scaling layers
self.p6_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p5_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p4_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p3_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p4_downsample = MaxPool2dStaticSamePadding(3, 2)
self.p5_downsample = MaxPool2dStaticSamePadding(3, 2)
self.p6_downsample = MaxPool2dStaticSamePadding(3, 2)
self.p7_downsample = MaxPool2dStaticSamePadding(3, 2)
if use_p8:
self.p7_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p8_downsample = MaxPool2dStaticSamePadding(3, 2)
# 활성 함수
self.swish = MemoryEfficientSwish() if not onnx_export else Swish()
self.first_time = first_time
if self.first_time:
self.p5_down_channel = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
)
self.p4_down_channel = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[1], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
)
self.p3_down_channel = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[0], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
)
self.p5_to_p6 = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
MaxPool2dStaticSamePadding(3, 2)
)
self.p6_to_p7 = nn.Sequential(
MaxPool2dStaticSamePadding(3, 2)
)
if use_p8:
self.p7_to_p8 = nn.Sequential(
MaxPool2dStaticSamePadding(3, 2)
)
self.p4_down_channel_2 = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[1], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
)
self.p5_down_channel_2 = nn.Sequential(
Conv2dStaticSamePadding(conv_channels[2], num_channels, 1),
nn.BatchNorm2d(num_channels, momentum=0.01, eps=1e-3),
)
# Weight
self.p6_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p6_w1_relu = nn.ReLU()
self.p5_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p5_w1_relu = nn.ReLU()
self.p4_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p4_w1_relu = nn.ReLU()
self.p3_w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p3_w1_relu = nn.ReLU()
self.p4_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p4_w2_relu = nn.ReLU()
self.p5_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p5_w2_relu = nn.ReLU()
self.p6_w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.p6_w2_relu = nn.ReLU()
self.p7_w2 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.p7_w2_relu = nn.ReLU()
self.attention = attention
def forward(self, inputs):
"""
illustration of a minimal bifpn unit
P7_0 -------------------------> P7_2 -------->
|-------------| ↑
↓ |
P6_0 ---------> P6_1 ---------> P6_2 -------->
|-------------|--------------↑ ↑
↓ |
P5_0 ---------> P5_1 ---------> P5_2 -------->
|-------------|--------------↑ ↑
↓ |
P4_0 ---------> P4_1 ---------> P4_2 -------->
|-------------|--------------↑ ↑
|--------------↓ |
P3_0 -------------------------> P3_2 -------->
"""
# downsample channels using same-padding conv2d to target phase's if not the same
# judge: same phase as target,
# if same, pass;
# elif earlier phase, downsample to target phase's by pooling
# elif later phase, upsample to target phase's by nearest interpolation
if self.attention:
outs = self._forward_fast_attention(inputs)
else:
outs = self._forward(inputs)
return outs
def _forward_fast_attention(self, inputs):
if self.first_time:
p3, p4, p5 = inputs
p6_in = self.p5_to_p6(p5)
p7_in = self.p6_to_p7(p6_in)
p3_in = self.p3_down_channel(p3)
p4_in = self.p4_down_channel(p4)
p5_in = self.p5_down_channel(p5)
else:
# P3_0, P4_0, P5_0, P6_0 and P7_0
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
# 블럭 연결 부
# P7_0 to P7_2
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(self.swish(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in)))
# Weights for P5_0 and P6_1 to P5_1
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
# Connections for P5_0 and P6_1 to P5_1 respectively
p5_up = self.conv5_up(self.swish(weight[0] * p5_in + weight[1] * self.p5_upsample(p6_up)))
# Weights for P4_0 and P5_1 to P4_1
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
# Connections for P4_0 and P5_1 to P4_1 respectively
p4_up = self.conv4_up(self.swish(weight[0] * p4_in + weight[1] * self.p4_upsample(p5_up)))
# Weights for P3_0 and P4_1 to P3_2
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(self.swish(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up)))
if self.first_time:
p4_in = self.p4_down_channel_2(p4)
p5_in = self.p5_down_channel_2(p5)
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.swish(weight[0] * p4_in + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out)))
# Weights for P5_0, P5_1 and P4_2 to P5_2
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
self.swish(weight[0] * p5_in + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out)))
# Weights for P6_0, P6_1 and P5_2 to P6_2
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
self.swish(weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out)))
# Weights for P7_0 and P6_2 to P7_2
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(self.swish(weight[0] * p7_in + weight[1] * self.p7_downsample(p6_out)))
return p3_out, p4_out, p5_out, p6_out, p7_out
def _forward(self, inputs):
if self.first_time:
p3, p4, p5 = inputs
p6_in = self.p5_to_p6(p5)
p7_in = self.p6_to_p7(p6_in)
if self.use_p8:
p8_in = self.p7_to_p8(p7_in)
p3_in = self.p3_down_channel(p3)
p4_in = self.p4_down_channel(p4)
p5_in = self.p5_down_channel(p5)
else:
if self.use_p8:
# P3_0, P4_0, P5_0, P6_0, P7_0 and P8_0
p3_in, p4_in, p5_in, p6_in, p7_in, p8_in = inputs
else:
# P3_0, P4_0, P5_0, P6_0 and P7_0
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
if self.use_p8:
# P8_0 to P8_2
# Connections for P7_0 and P8_0 to P7_1 respectively
p7_up = self.conv7_up(self.swish(p7_in + self.p7_upsample(p8_in)))
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(self.swish(p6_in + self.p6_upsample(p7_up)))
else:
# P7_0 to P7_2
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(self.swish(p6_in + self.p6_upsample(p7_in)))
# Connections for P5_0 and P6_1 to P5_1 respectively
p5_up = self.conv5_up(self.swish(p5_in + self.p5_upsample(p6_up)))
# Connections for P4_0 and P5_1 to P4_1 respectively
p4_up = self.conv4_up(self.swish(p4_in + self.p4_upsample(p5_up)))
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(self.swish(p3_in + self.p3_upsample(p4_up)))
if self.first_time:
p4_in = self.p4_down_channel_2(p4)
p5_in = self.p5_down_channel_2(p5)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
self.swish(p4_in + p4_up + self.p4_downsample(p3_out)))
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
self.swish(p5_in + p5_up + self.p5_downsample(p4_out)))
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
self.swish(p6_in + p6_up + self.p6_downsample(p5_out)))
if self.use_p8:
# Connections for P7_0, P7_1 and P6_2 to P7_2 respectively
p7_out = self.conv7_down(
self.swish(p7_in + p7_up + self.p7_downsample(p6_out)))
# Connections for P8_0 and P7_2 to P8_2
p8_out = self.conv8_down(self.swish(p8_in + self.p8_downsample(p7_out)))
return p3_out, p4_out, p5_out, p6_out, p7_out, p8_out
else:
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(self.swish(p7_in + self.p7_downsample(p6_out)))
return p3_out, p4_out, p5_out, p6_out, p7_outFocal Loss
class FocalLoss(nn.Module):
def __init__(self):
super(FocalLoss, self).__init__()
def forward(self, classifications, regressions, anchors, annotations, **kwargs):
alpha = 0.25
gamma = 2.0
batch_size = classifications.shape[0]
classification_losses = []
regression_losses = []
anchor = anchors[0, :, :] # assuming all image sizes are the same, which it is
dtype = anchors.dtype
anchor_widths = anchor[:, 3] - anchor[:, 1]
anchor_heights = anchor[:, 2] - anchor[:, 0]
anchor_ctr_x = anchor[:, 1] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 0] + 0.5 * anchor_heights
for j in range(batch_size):
classification = classifications[j, :, :]
regression = regressions[j, :, :]
bbox_annotation = annotations[j]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
if torch.cuda.is_available():
alpha_factor = torch.ones_like(classification) * alpha
alpha_factor = alpha_factor.cuda()
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
cls_loss = focal_weight * bce
regression_losses.append(torch.tensor(0).to(dtype).cuda())
classification_losses.append(cls_loss.sum())
else:
alpha_factor = torch.ones_like(classification) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
cls_loss = focal_weight * bce
regression_losses.append(torch.tensor(0).to(dtype))
classification_losses.append(cls_loss.sum())
continue
IoU = calc_iou(anchor[:, :], bbox_annotation[:, :4])
IoU_max, IoU_argmax = torch.max(IoU, dim=1)
# compute the loss for classification
targets = torch.ones_like(classification) * -1
if torch.cuda.is_available():
targets = targets.cuda()
targets[torch.lt(IoU_max, 0.4), :] = 0
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
alpha_factor = torch.ones_like(targets) * alpha
if torch.cuda.is_available():
alpha_factor = alpha_factor.cuda()
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
cls_loss = focal_weight * bce
zeros = torch.zeros_like(cls_loss)
if torch.cuda.is_available():
zeros = zeros.cuda()
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, zeros)
classification_losses.append(cls_loss.sum() / torch.clamp(num_positive_anchors.to(dtype), min=1.0))
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# efficientdet style
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dy, targets_dx, targets_dh, targets_dw))
targets = targets.t()
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).to(dtype).cuda())
else:
regression_losses.append(torch.tensor(0).to(dtype))
# debug
imgs = kwargs.get('imgs', None)
if imgs is not None:
regressBoxes = BBoxTransform()
clipBoxes = ClipBoxes()
obj_list = kwargs.get('obj_list', None)
out = postprocess(imgs.detach(),
torch.stack([anchors[0]] * imgs.shape[0], 0).detach(), regressions.detach(), classifications.detach(),
regressBoxes, clipBoxes,
0.5, 0.3)
imgs = imgs.permute(0, 2, 3, 1).cpu().numpy()
imgs = ((imgs * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255).astype(np.uint8)
imgs = [cv2.cvtColor(img, cv2.COLOR_RGB2BGR) for img in imgs]
display(out, imgs, obj_list, imshow=False, imwrite=True)
return torch.stack(classification_losses).mean(dim=0, keepdim=True), \
torch.stack(regression_losses).mean(dim=0, keepdim=True) * 50