
Object Detection(객체 탐지)
객체 탐지는 컴퓨터 비전과 이미지 처리와 관련된 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지하는 일을 다룬다.
Yolo(CVPR 2016)
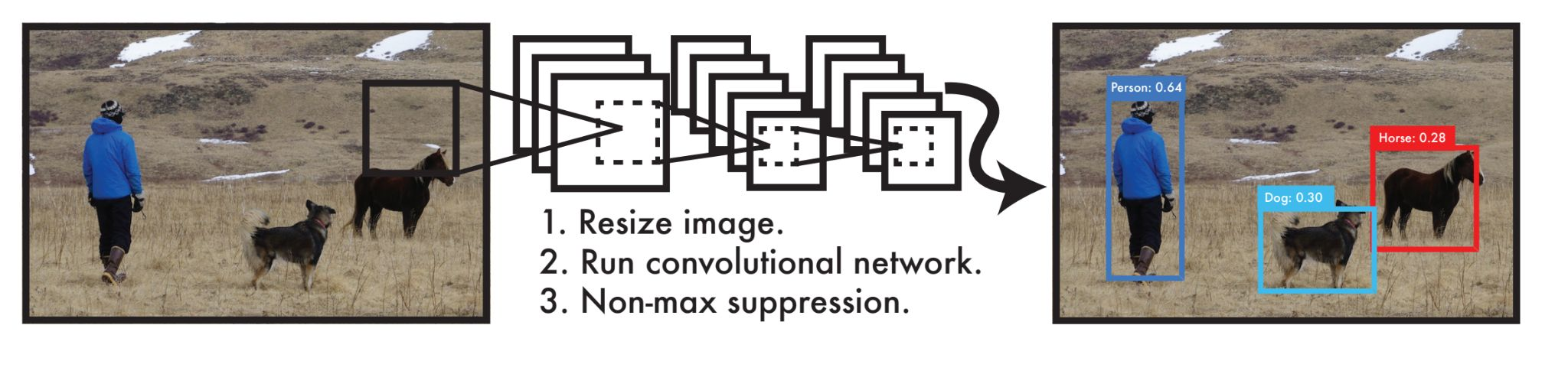
yolo에서는 3단계를 통해 간단하고 실시간으로 객체 탐지를 할 수 있다.
첫 단계는 이미지를 resize하고 두 번째는 convolutional network를 통과하고 마지막으로 Non-maximum supperssion을 수행하는 것이다.
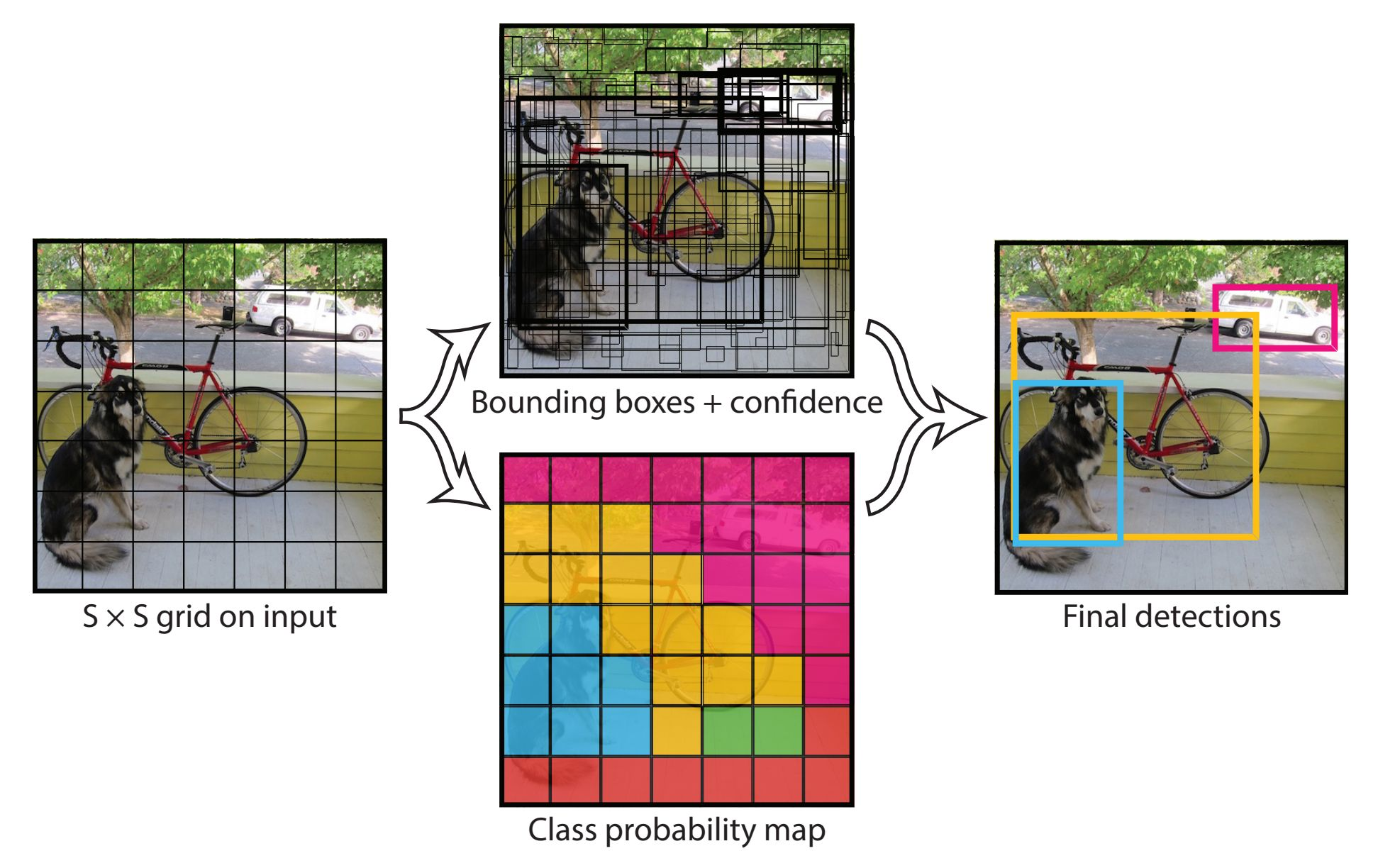
yolo는 S×S로 이미지를 grid로 나누어서 하나의 grid마다 바운딩 박스를 2개씩 추론하고 해당 박스에 객체가 있는지 없는지에 대한 confidence를 같이 학습한다.
그리고 grid마다 클래스가 어떤 클래스에 속하는지 판단한다. 가장 높은 confidence score 박스에 가장 많이 포함되어 있는 class probability로 최종 클래스를 결정하게 된다.
Faster R-CNN, SSD는 백그라운드를 가리키는 바운딩 박스가 매우 많아 조절을 해야 했던 반면, yolo는 어떤 객체도 가리키지 않는 grid를 백그라운드로 인식하기에 접근 방식이 다르다.
feature map은 448×448로 크기로 입력이 들어오고 최종 출력은 7×7 feature resolution을 가지며, 7×7에서의 한 픽셀들이 하나의 grid가 된다.
7×7의 한 픽셀이 30개 dimension을 가지는데, 4개의 바운딩 박스 코디네이트와 해당 바운딩 박스에 대한 confidence score가 2개 존재한다. 그리고 20 classes에 대한 classification이 존재한다. 그래서 총 30개의 dimension을 가진다.

Training Loss Funtions은 기존의 SSD, Faster R-CNN의 백그라운드 영역에 대한 바운딩 박스를 어떻게 핸들링 할 것인지가 이슈였던 반면, yolo는 객체가 있는 grid와 없는 grid로 나눠서 Loss Function을 구성한다.
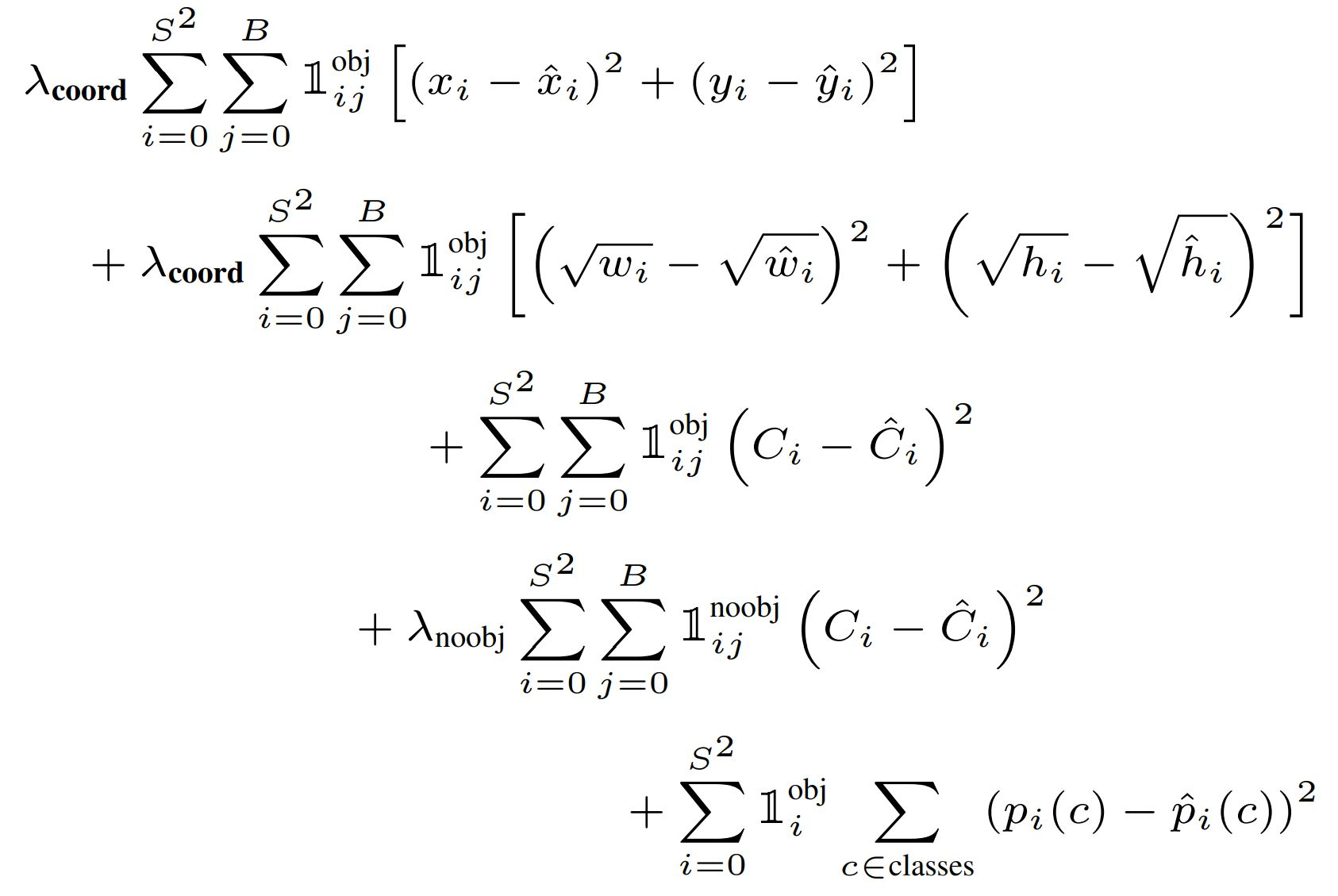
YOLOV1 구현 - bus/truck detection
소스 코드 : GitHub
데이터
kaggle의 Open-Images-Bus-Trucks를 사용한다.
데이터셋
- 이미지 : kaggle
- csv : 이미지 파일 이름, label(class) name, Confidence Score, 바운딩 박스 좌표
dataset 구축
dataset
class MyDataset():
def __init__(self, data_dir, phase, transform=None):
self.data_dir = data_dir
self.phase = phase
self.df = pd.read_csv(os.path.join(self.data_dir, 'df.csv'))
self.image_files = [fn for fn in os.listdir(os.path.join(self.data_dir, phase)) if fn.endswith('jpg')]
self.transform = transform
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
# iamge, class_id, bounding box(xc, yc, w, h) 형식
filename, image = self.get_image(index)
bboxes, class_ids = self.get_label(filename)
if self.transform:
transformed_data = transform(image=image, bboxes=bboxes, class_ids=class_ids)
image = transformed_data['image']
bboxes = np.array(transformed_data['bboxes'])
class_ids = np.array(transformed_data['class_ids'])
target = np.concatenate((bboxes, class_ids[:, np.newaxis]), axis=1)
return image, target, filename
def get_image(self, index):
filename = self.image_files[index]
image_path = os.path.join(self.data_dir, self.phase, filename)
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return filename, image
def get_label(self, filename):
image_id = filename.split('.')[0]
meta_data = self.df[self.df['ImageID'] == image_id]
cate_names = meta_data['LabelName'].values
class_ids = np.array([CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names])
# 'XMin', 'XMax', 'YMin', 'YMax' -> X.center, Y.center, X.w, Y.h
bboxes = meta_data[['XMin', 'XMax', 'YMin', 'YMax']].values
bboxes[:, [1, 2]] = bboxes[:, [2, 1]] # XMax, YMin 자리바꿈
bboxes[:, 2:4] -= bboxes[:, 0:2] # XMax -> w, YMax -> h
bboxes[:, 0:2] += bboxes[:, 2:4] / 2 # XMin -> x좌표 center, YMin -> y좌표 center
return bboxes, class_idsdataloader
IMAGE_SIZE = 448
transform = A.Compose([
A.Resize(height=IMAGE_SIZE, width=IMAGE_SIZE),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2()
],
bbox_params=A.BboxParams(format='yolo', label_fields=['class_ids'])
)
def build_dataloader(data_dir, batch_size, image_size):
transform = A.Compose(
[
A.Resize(height=image_size, width=image_size),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2()
],
bbox_params=A.BboxParams(format='yolo', label_fields=['class_ids'])
)
dataloaders = {}
trainset = MyDataset(data_dir, phase='train', transform=transform)
valset = MyDataset(data_dir, phase='val', transform=transform)
testset = MyDataset(data_dir, phase='test', transform=transform)
dataloaders['train'] = DataLoader(trainset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
dataloaders['val'] = DataLoader(valset, batch_size=1, shuffle=False, collate_fn=collate_fn)
dataloaders['test'] = DataLoader(testset, batch_size=1, shuffle=False, collate_fn=collate_fn)
return dataloadersmodeling
backbone
# resnet18에서 layers 부분만 backbone, (avgpool, fc)는 사용 X
resnet18 = torchvision.models.resnet18(pretrained=False)YOLO model
class YOLO_RESNET(nn.Module):
def __init__(self, num_classes):
super(YOLO_RESNET, self).__init__()
num_classes = num_classes
num_bboxes = 2
grid_size = 7
resnet18 = torchvision.models.resnet18(pretrained=True)
layers = [layer for layer in resnet18.children()]
self.backbone = nn.Sequential(*layers[:-2])
self.neck = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
)
self.head = nn.Sequential(
nn.Conv2d(in_channels=1024, out_channels=(4+1)*num_bboxes+num_classes, kernel_size=1, padding=0, bias=False),# yolo output depth
nn.AdaptiveAvgPool2d(output_size=(grid_size, grid_size))
)
def forward(self, x):
out = self.backbone(x)
out = self.neck(out)
out = self.head(out) # (batch, 3, 448, 448) -> (batch, 12, 7, 7)
return outLoss Function
# IOU
def get_IoU(cbox1, cbox2):
box1 = xywh_to_xyxy(cbox1)
box2 = xywh_to_xyxy(cbox2)
# 교집합 부분
x1 = torch.max(box1[:, 0, ...], box2[:, 0, ...])
y1 = torch.max(box1[:, 1, ...], box2[:, 1, ...])
x2 = torch.min(box1[:, 2, ...], box2[:, 2, ...])
y2 = torch.min(box1[:, 3, ...], box2[:, 3, ...])
intersection = (x2 - x1).clamp(min=0) * (y2 - y1).clamp(min=0)
# 합집합 부분
union = abs(cbox1[:, 2, ...] * cbox1[:, 3, ...]) + abs(cbox2[:, 2, ...] * cbox2[:, 3, ...]) - intersection # (w * h) + (w * h) - intersection = union
# 7*7*7 dimension shape 유지하면서 iou 반환
intersection[intersection.gt(0)] = intersection[intersection.gt(0)] / union[intersection.gt(0)]
return intersection
def xywh_to_xyxy(cbox):
# cbox : (xn, yn, w, h) -> offset box : (xc, yc, w, h) -> box : (xmin, ymin, xmax, ymax)
# 1: cbox : (xn, yn, w, h) -> offset box : (xc, yc, w, h)
num_batch, _, grid_size, grid_size = cbox.shape
xy_normed_grid = generate_xy_normed_size(grid_size=grid_size)
xcyc = cbox[:, 0:2, ...] + xy_normed_grid.tile(num_batch, 1, 1, 1)
# 2 : offset box : (xc, yc, w, h) -> box : (xmin, ymin, xmax, ymax)
wh = cbox[:, 2:4, ...]
x1y1 = xcyc - (wh/2)
x2y2 = xcyc + (wh/2)
return torch.cat([x1y1, x2y2], dim=1)
def generate_xy_normed_size(grid_size):
y_offset, x_offset = torch.meshgrid(torch.arange(grid_size), torch.arange(grid_size))
xy_grid = torch.stack([x_offset, y_offset], dim=0)
xy_normed_grid = xy_grid / grid_size
return xy_normed_grid
# Loss Function
class YOLO_LOSS():
def __init__(self, num_classes, device, lambda_coord=5., lambda_noobj=0.5):
self.num_classes = num_classes
self.device = device
self.grid_size = 7
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.mse_loss = nn.MSELoss(reduction="sum")
def __call__(self, predictions, targets):
self.batch_size, _, _, _ = predictions.shape
groundtruths = self.build_batch_target_grid(targets)
groundtruths = groundtruths.to(self.device)
with torch.no_grad():
iou1 = self.get_IoU(predictions[:, 1:5, ...], groundtruths[:, 1:5, ...])
iou2 = self.get_IoU(predictions[:, 6:10, ...], groundtruths[:, 1:5, ...])
ious = torch.stack([iou1, iou2], dim=1)
max_iou, best_box = ious.max(dim=1, keepdim=True)
max_iou = torch.cat([max_iou, max_iou], dim=1)
best_box = torch.cat([best_box.eq(0), best_box.eq(1)], dim=1)
predictions_ = predictions[:, :5*2, ...].reshape(self.batch_size, 2, 5, self.grid_size, self.grid_size)
obj_pred = predictions_[:, :, 0, ...]
xy_pred = predictions_[:, :, 1:3, ...]
wh_pred = predictions_[:, :, 3:5, ...]
cls_pred = predictions[:, 5*2:, ...]
groundtruths_ = groundtruths[:, :5, ...].reshape(self.batch_size, 1, 5, self.grid_size, self.grid_size)
obj_target = groundtruths_[:, :, 0, ...]
xy_target = groundtruths_[:, :, 1:3, ...]
wh_target= groundtruths_[:, :, 3:5, ...]
cls_target = groundtruths[:, 5:, ...]
positive = obj_target * best_box
obj_loss = self.mse_loss(positive * obj_pred, positive * ious)
noobj_loss = self.mse_loss((1 - positive) * obj_pred, ious*0)
xy_loss = self.mse_loss(positive.unsqueeze(dim=2) * xy_pred, positive.unsqueeze(dim=2) * xy_target)
wh_loss = self.mse_loss(positive.unsqueeze(dim=2) * (wh_pred.sign() * (wh_pred.abs() + 1e-8).sqrt()),
positive.unsqueeze(dim=2) * (wh_target + 1e-8).sqrt())
cls_loss = self.mse_loss(obj_target * cls_pred, cls_target)
obj_loss /= self.batch_size
noobj_loss /= self.batch_size
bbox_loss = (xy_loss+wh_loss) / self.batch_size
cls_loss /= self.batch_size
total_loss = obj_loss + self.lambda_noobj*noobj_loss + self.lambda_coord*bbox_loss + cls_loss
return total_loss, (obj_loss.item(), noobj_loss.item(), bbox_loss.item(), cls_loss.item())
def build_target_grid(self, target):
target_grid = torch.zeros((1+4+self.num_classes, self.grid_size, self.grid_size), device=self.device)
for gt in target:
xc, yc, w, h, cls_id = gt
xn = (xc % (1/self.grid_size))
yn = (yc % (1/self.grid_size))
cls_id = int(cls_id)
i_grid = int(xc * self.grid_size)
j_grid = int(yc * self.grid_size)
target_grid[0, j_grid, i_grid] = 1
target_grid[1:5, j_grid, i_grid] = torch.Tensor([xn,yn,w,h])
target_grid[5+cls_id, j_grid, i_grid] = 1
return target_grid
def build_batch_target_grid(self, targets):
target_grid_batch = torch.stack([self.build_target_grid(target) for target in targets], dim=0)
return target_grid_batch
def get_IoU(self, cbox1, cbox2):
box1 = self.xywh_to_xyxy(cbox1)
box2 = self.xywh_to_xyxy(cbox2)
x1 = torch.max(box1[:, 0, ...], box2[:, 0, ...])
y1 = torch.max(box1[:, 1, ...], box2[:, 1, ...])
x2 = torch.min(box1[:, 2, ...], box2[:, 2, ...])
y2 = torch.min(box1[:, 3, ...], box2[:, 3, ...])
intersection = (x2-x1).clamp(min=0) * (y2-y1).clamp(min=0)
union = abs(cbox1[:, 2, ...]*cbox1[:, 3, ...]) + \
abs(cbox2[:, 2, ...]*cbox2[:, 3, ...]) - intersection
intersection[intersection.gt(0)] = intersection[intersection.gt(0)] / union[intersection.gt(0)]
return intersection
def generate_xy_normed_grid(self):
y_offset, x_offset = torch.meshgrid(torch.arange(self.grid_size), torch.arange(self.grid_size))
xy_grid = torch.stack([x_offset, y_offset], dim=0)
xy_normed_grid = xy_grid / self.grid_size
return xy_normed_grid.to(self.device)
def xywh_to_xyxy(self, bboxes):
xy_normed_grid = self.generate_xy_normed_grid()
xcyc = bboxes[:,0:2,...] + xy_normed_grid.tile(self.batch_size, 1,1,1)
wh = bboxes[:,2:4,...]
x1y1 = xcyc - (wh/2)
x2y2 = xcyc + (wh/2)
return torch.cat([x1y1, x2y2], dim=1)학습 및 평가
학습
def train_one_epoch(dataloaders, model, criterion, optimizer, device):
train_loss = defaultdict(float)
val_loss = defaultdict(float)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = defaultdict(float)
for index, batch in enumerate(dataloaders[phase]):
images = batch[0].to(device)
targets = batch[1]
filenames = batch[2]
with torch.set_grad_enabled(phase == 'train'):
predictions = model(images)
loss, (obj_loss, noobj_loss, bbox_loss, cls_loss) = criterion(predictions, targets)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss['total_loss'] += loss.item()
running_loss['obj_loss'] += obj_loss
running_loss['noobj_loss'] += noobj_loss
running_loss['bbox_loss'] += bbox_loss
running_loss['cls_loss'] += cls_loss
train_loss['total_loss'] += loss.item()
train_loss['obj_loss'] += obj_loss
train_loss['noobj_loss'] += noobj_loss
train_loss['bbox_loss'] += bbox_loss
train_loss['cls_loss'] += cls_loss
if index % VERBOSE_FREQ == 0:
text = f'iteration:[{index}/{len(dataloaders[phase])}] - '
for k, v in running_loss.items():
text += f'{k}: {v/VERBOSE_FREQ:.4f} '
running_loss[k] = 0
print(text)
else:
val_loss['total_loss'] += loss.item()
val_loss['obj_loss'] += obj_loss
val_loss['noobj_loss'] += noobj_loss
val_loss['bbox_loss'] += bbox_loss
val_loss['cls_loss'] += cls_loss
for k in train_loss.keys():
train_loss[k] /= len(dataloaders['train'])
val_loss[k] /= len(dataloaders['val'])
return train_loss, val_lossTest : NMS
@torch.no_grad()
def model_predict(image, model, conf_threshold=0.3, iou_threshold=0.1):
tf_data = transform(image=image)
tensor_image = tf_data['image'].to(DEVICE)
tensor_image = tensor_image.unsqueeze(dim=0)
predictions = model(tensor_image)
prediction = predictions.cpu().detach().squeeze(dim=0)
grid_size = prediction.shape[-1]
y_grid, x_grid = torch.meshgrid(torch.arange(grid_size), torch.arange(grid_size))
stride_size = IMAGE_SIZE / grid_size
conf = prediction[[0, 5], ...].reshape(1, -1)
xc = (prediction[[1, 6], ...] * IMAGE_SIZE + x_grid * stride_size).reshape(1, -1)
yc = (prediction[[2, 7], ...] * IMAGE_SIZE + y_grid * stride_size).reshape(1, -1)
w = (prediction[[3, 8], ...] * IMAGE_SIZE).reshape(1, -1)
h = (prediction[[4, 9], ...] * IMAGE_SIZE).reshape(1, -1)
cls = torch.max(prediction[10:, ...].reshape(NUM_CLASSES, -1), dim=0).indices.tile(1, 2)
x_min = xc - w/2
y_min = yc - h/2
x_max = xc + w/2
y_max = yc + h/2
prediction_res = torch.cat([x_min, y_min, x_max, y_max, conf, cls], dim=0)
prediction_res = prediction_res.transpose(0, 1)
prediction_res[:, 0].clip(min=0)
prediction_res[:, 1].clip(min=0)
prediction_res[:, 2].clip(max=IMAGE_SIZE)
prediction_res[:, 3].clip(max=IMAGE_SIZE)
pred_res = prediction_res[prediction_res[:, 4] > conf_threshold]
nms_index = torchvision.ops.nms(boxes=pred_res[:, 0:4], scores=pred_res[:, 4], iou_threshold=iou_threshold)
pred_res_ = pred_res[nms_index].numpy()
n_obj = pred_res_.shape[0]
bboxes = np.zeros(shape=(n_obj, 4), dtype=np.float32)
bboxes[:, 0:2] = (pred_res_[:, 0:2] + pred_res_[:, 2:4]) / 2
bboxes[:, 2:4] = pred_res_[:, 2:4] - pred_res_[:, 0:2]
scores = pred_res_[:, 4]
class_ids = pred_res_[:, 5]
return bboxes, scores, class_ids