더욱 투명한 신경망 네트워크를 구축하고, 설명 가능한 AI 모델을 만듬으로써 무엇을 얻을 수 있을까? 여러가지 있겠지만, 본 글에서는 어떻게 구축할 지에 대해서 생각해보자.
deep explanation이란?
deep explanation은 신경망 네트워크 안에서 무엇이 일어나는지를 떼어서 생각할 수 있게끔 하는 설명가능 AI를 구축하는 방법이라 할 수 있다. 크게 세가지 테크닉으로 나눌 수 있다.
- Learning Semantic Associations(의미 있는 관계 학습)
- Generating Visual Explanations(시각적인 설명 생성)
- Rationalizing Neural Predictions(AI의 예측 정당화)
Learning Semantic Associations
이 기법은 SRI가 비디오 내에서 의미 있는 관계를 학습하는 기법이다. 목표는, 비디오 내 프레임들 중 관심 있는 항목이 발생할 경우 이를 카운팅하고, 이벤트에 대한 캡션을 생성하는 것이다.
예를 들어, 스케이트 보드를 타는 영상을 input으로 받을 경우, 특정 프레임에서 특정 동작에 대해 식별한 후, 하나로 합쳐질 때 모델은 "이 동영상은 보드 트릭을 시도하는 동영상이다"라고 말하게 하고 싶은 것이다.

visual recognition, audio recognition, OCR technique 등을 이용해 최대한 많은 정보를 얻는다. 이 정보는 convolutional layers들에 투입되고, 여러 번 학습된다.
웨딩을 예로 들어보자. 이 때, 모델은 이 동영상이 웨딩 동영상이라는 것에 대한 증거를 반환해야 한다(부캐, 결혼반지, 신부 등). 이 기법은 학습된 subject 전문지식과 학습된 시스템을 혼합한다. picture를 손가락 위에 있는 ring이다 라고 분류하는 것으론 충분하지 않고, 이 이벤트가 구체적인 무언가를 암시한다는 subject matter expert로서의 온톨로지(방법론 정도)를 제공해야 한다. 예를 들면, '두 사람이 결혼을 하고 있다'처럼 말이다. 위 과정은 모델 자체의 구축의 일환으로 행해져야 한다.
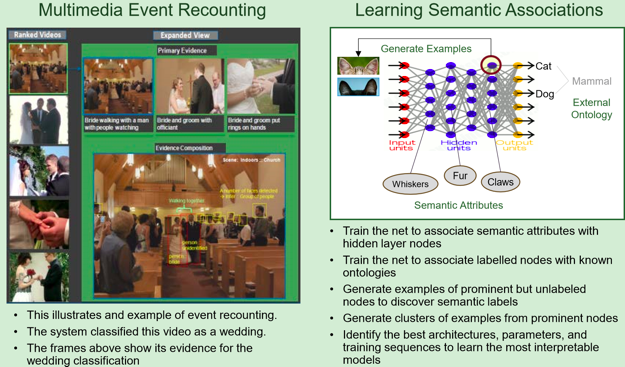
SRI는 이 과정을 성공적으로 수행했다. 특정 순간의 비디오를 찾는 시스템을 구축하기 위해 풍경들로부터 meta data를 사용하기도 하였다.
http://www-nlpir.nist.gov/projects/tvpubs/tv14.papers/sri_aurora.pdf
이미지 캡셔닝이 Object detection과 멀리 떨어져 있을까? 기존에 조사했던 VQA 관련 논문을 다시 보는 것도 좋을 것 같다.
