0. Introduction
CNN 모델에 적용할 수 있는 XAI기법 중 하나인 시각화 기법에 대해 알아보자. 해석이 힘든 딥러닝 (블랙박스) 모델을 이해하기 위해 CNN 필터들이 어떻게 생겼는지, 인풋 이미지에서 모델의 성능에 미치는 부분이 어떻게 나타나는지, 그리고 특정 클래스의 Activation을 최대화 하는 이미지 생성은 어떤 것인지 알아보도록 하자.
1. Vision
먼저, 시각에 대해 짚고 넘어가보자. 사람의 두뇌 겉부분을 가리키는 대뇌 피질은 모든 인지와 판단을 담당한다. 또한, 대뇌피질의 30%가 넘는 부분이 모두 시각을 처리한다는 사실이 존재한다(촉각 8%, 청각 2%). 시각은 진화의 키포인트라고 불리기도 하는데, 빛에 반응하는 시신경 세포의 등장이 진화의 폭발적 시각이라는 점 등이 그러한 이유이다. 즉, 시각은 생물의 진화, 포식과 피식 등에도 큰 역할을 해왔으며, 이는 시각이 생존에도 직결되는 요소라는 것을 반증한다.
1.1. Topographical Mapping & Hierarchical Organization
Hubel 과 Wiesel이라는 과학자는 시각과 두뇌의 관계를 알기 위해 고양이의 뇌에 전극을 꼽은 후 다양한 자극을 주어 실험을 진행하였다.
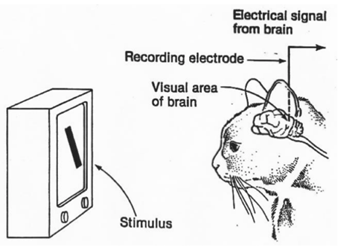
그 결과, 두뇌 피질에서 가까운 영역은 가까운 물체를 인식한다는 사실을 알았고, 이를 Topographical Mapping이라고 한다. 예를 들어, 눈과 코가 가까이 있다면 눈을 인식하는 뉴런과 코를 인식하는 뉴런이 대뇌 피질 위에 공간적으로 비슷한 위치에 존재한다는 것이다.
더 나아가, Abstraction 기능을 밝혀냈는데, 이는 예를 들어 어떤 물체가 얼굴임을 인식하기 위해서는 얼굴의 구성요소인 눈, 코, 입 등을 인식하는 뉴런이 있고, 인식한 눈코입이 정해진 위치에 있는 것을 인식하는 뉴런이있다는 것이다.
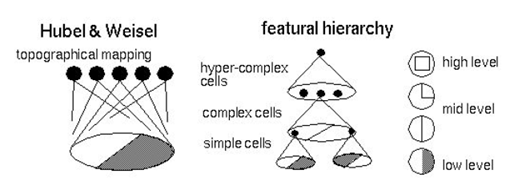
즉, 1. 대뇌피질에서 가까운 세포들은 가까운 물체를 처리함으로서 Spatial Information을 유지하고 2. Feature들은 Abstract하여 계층적으로 처리한다.
유명하게도, 이러한 특징을 반영한 것이 CNN이다.
1.2 Neurocognition
이는 1980년에 일본의 딥러닝 연구자인 Fukushima가 제안한 것으로, CNN의 기원이 되었다.
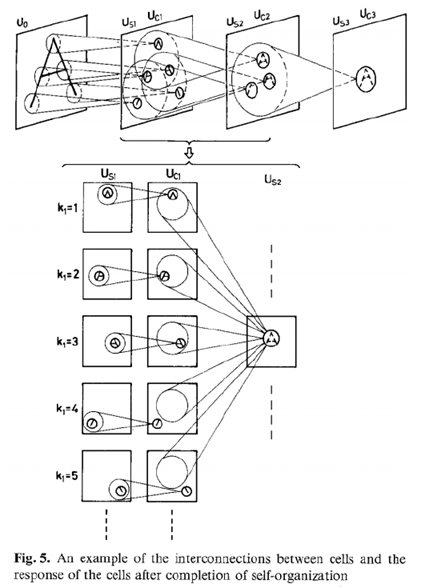
. 자체적인 조직이 완성된 후, 세포와 세포의 반응 사이의 상호연결을 제공.
2. Filter
CNN에서 Filter의 역할에 대해 알아보자.
2.1. Edge Detection

필터(filter or kenrel)은 원본 데이터를 해석하기 위해 사용하는 일정한 행렬 값이다. 필터는 원본 이미지에서 특정 요소를 추출하기 위해 사용한다. 즉, 주파수 필터의 역할을 하는 것이다. 다섯번 째 그림은 저주파만 통과하기 때문에 블러리한 이미지를 결과로 얻으며, 세번째 그림인 Laplace Filter는 Edge를 찾는 역할을 한다. 네번째 그림인 high-pass filter는 이미지가 선명해지는 결과를 얻을 수 있다.
즉, 학습된 CNN 필터들은 이런식으로 경계선을 찾거나 블러리한 면을 찾는 등 다양한 주파수 필터의 기능을 한다.
2.2. Gabor-like Learned Filters
영상처리에 사용되는 전통적인 기법으로는 Gabor Filter가 있다. 수학자 Dennis Gabor가 만든 것으로 Edge를 검출하는 필터로 사용되어 왔다.
Gabor Functions
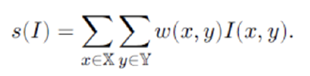
위의 식에는 8개의 매개변수가 존재한다.
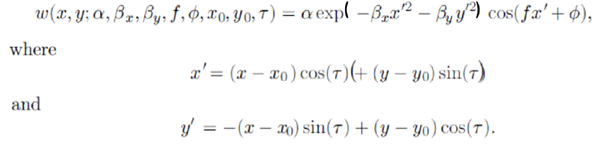
위와 같은 필터를 통과시킨다면 아래와 같은 Gabor Filter들을 얻을 수 있다. 이 Filter 역시 사람의 시각체계가 반응하는 것과 비슷하다고 한다. 각 매개변수에 대한 의미는 여기선 간단히 나타내도록 하자.
: width of kernel, : direction of kernel, : detection of edge …

(일부 매개변수 변화에 따른 Gabor filtering 결과)
아래는 (학습 완료된) CNN의 필터들이며, Gabor Filter와 매우 유사한 모습을 확인할 수 있다.

CNN은 Gabor filter와 무관하게 학습된다. 아래와 같은 필터는 45도로 기울어진 high-pass filter로 45도 방향의 경계선(edge)이 있는지 체크한다. CNN또한 Gabor filter의 목적과 유사하게 경계선을 검출하는 것을 중요하게 생각하기 때문에 유사한 필터를 가지게 된다고 해석할 수 있다.

2-3. Activation
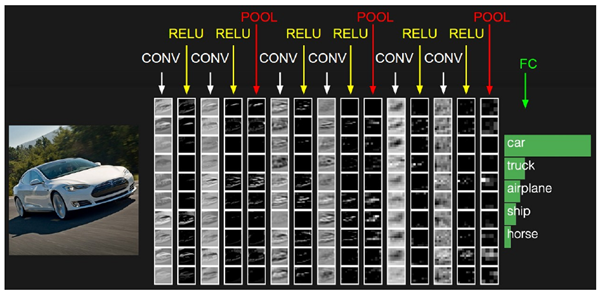
위 그림은 왼쪽의 자동차 이미지가 CNN 모델의 각 레이어를 거쳐서 나온 결과를 시각화한 것이다. Input에 가까울수록(왼쪽) 원본과 비슷한 이미지를 가지지만, Filter에 따라서 관심을 두는 부분이 조금씩 다르다는 것을 확인할 수있다. 또한 output에 가까울수록(오른쪽) 원본의 이미지와는 크게 변형되고, 추상화 수준이 높아 해석이 어렵다. 이러한 레이어별로 추상화 정도가 차이난다는 점을 활용한 연구가 Neural Style이다.
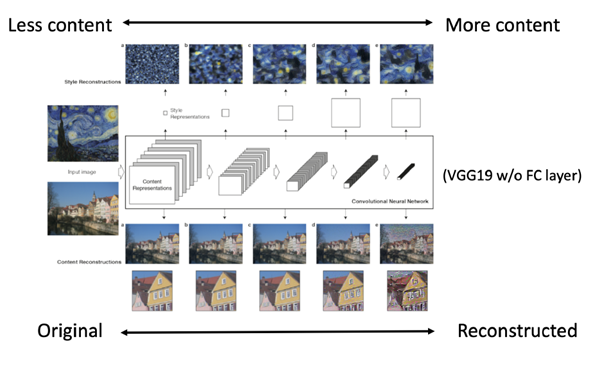
Content의 역할을 하는 마을 사진을 보면, input layer와 가까울수록 원본 이미지와 유사하고, output layer와 가까울수록 추상화 수준이 높아짐을 확인할 수 있다. Neural style에서는 content로 사용할 원본 이미지의 세세한 부분이 아니라 큼직한 추상화된 feature가 필요하므로 깊은 레이어의 activation 결과를 사용한다.
3. Visualization at the image
Input Image를 모델이 어떻게 분류했는지 알기 위한 시각화 방법은 크게 4가지가 존재한다.
3.1. Occlusion Experiment [Zeiler & Fergus 2013]
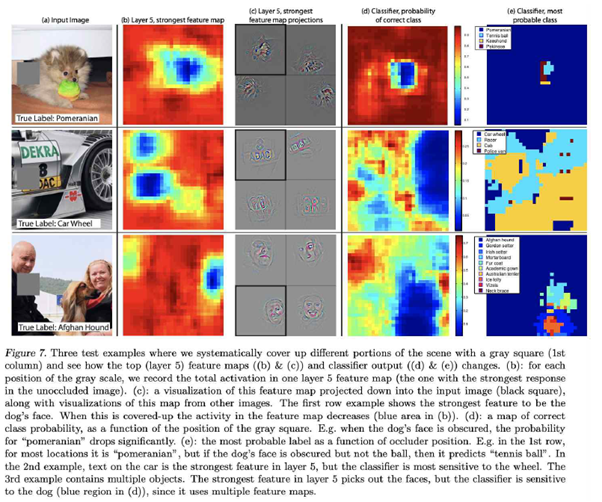
CNN이 물체를 인식하는 과정이 사람이 물체를 인식하는 과정과 유사하다는 것을 보여주는 그림. INPUT에 특정한 노이즈(여기서는 회색박스)를 이동시킴으로써 나온 결과의 변화를 히트맵으로 나타내어다.
3.2. Deconvnet[Zeiler & Fergus 2013] & Guided-Backpropagation[Dosovitsky et al., 2015]


위 사진은 Deconvent의 결과물로, image를 모델에 투입했을 때 각각의 layer에서 activation을 크게 만드는 feature map을 시각화한 것이다. 즉, Input image의 어떤 부분이 레이어를 Activate 시켰는지 알아보기 위해 activation 값을 input에 mapping 시키는 것이다. 이를 위해서는 CNN을 거꾸로 거슬러 올라가야 한다.
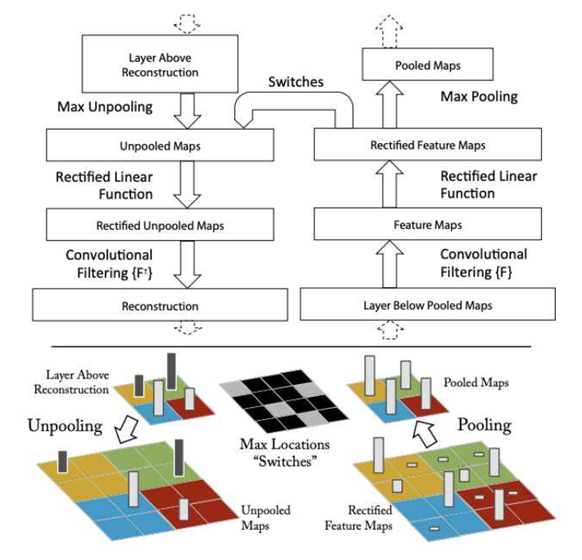

단순히 말하면, Deconvolution은 convolution 연산을 정확히 반대로 진행하는 것이다.
CNN은 Convolution -> Activation Function -> Pooling 으로 이루어져 있는데, Deconv는 이를 반대로 진행한다.
- Unpooling: Forward pass에서 Max Pooling을 할 때 max 값의 위치를 저장한다음, 다시 그대로 돌려 준다.
- Rectification: CNN은 feature map이 항상 양수가 되도록 ReLU를 사용하는데, backward pass에서도 그대로 non-liner ReLU를 사용한다.
- Filtering: Convolution 연산을 할 때 사용했던 Filter의 정보를 사용해, 역 연산을 진행한다.
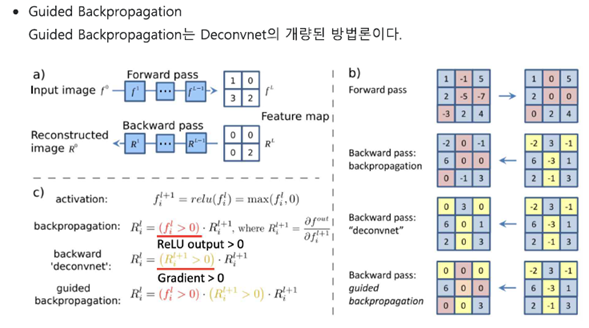
a) Forward pass는 일반적인 CNN과 같고, Backward pass에서는 Activation을 만드는 input 값을 찾는다.
b) Forward pass에서 음수인 값(핑크색)은 다음 레이어로 전달되지 않는다(ReLu). 하지만 기존의 Deconvnet은 Forward pass에서 ReLU를 통과했는지 아닌지와 무관하게 Backward pass에서 계산된 값(노란색)만을 가지고 Rectification을 한다. 이를 보완하기 위해 Guided Backpropagation에서는 Forward pass에서 음수이거나 Backward pass에서 음수인 부분들(분홍색, 노란색)인 부분들을 모두 0으로 반환한다.
c) 그 과정을 위한 수식
3.3 Saliency Map[Simonyan, Vedaldi, Zisserman 2014]


Saliency map은 Input image의 각각의 픽셀이 top-1 predicted 클래스에 미치는 영향을 시각화한 것이다. 즉, 첫번째 사진을 모델이 요트로 분류했다면, output vector(클래스를 분류하는)에서 요트를 나타내는 element가 가장 크다는 것을 의미한다.
그를 이용해
: 요트의 Loss,
: 픽셀 이라 할 때
를 (역전파를 통해) 구하고, RGB 채널 중 가장 큰 값을 시각화에 사용한다고 한다. 위와 같은 직관성 때문에 Segmentation에도 사용된다고 한다.
4.Visualization at the network
이미지를 대상으로 한 CNN 관련 시각화 기법들은 대부분 Input image와 연결된다. Optimization method는 Input image를 사용하지 않고 특정 ‘클래스’를 최대화 하는, 즉 개별 데이터가 아닌 네트워크 전체에 대해 조망하는 기법이다.
4.1. Optimization Method[Simonyan, Vedaldi, Zisserman., 2014]
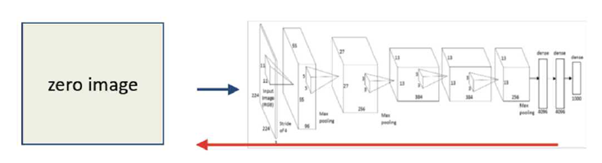
- Zero Image를 모델에 넣고 Forward pass 진행
- Output vector에서 ‘원하는’ 클래스의 값을 1로, 나머지 클래스의 값은 0으로 조정
- 이 vector를 이용해 Gradient Ascent를 진행한다.
- Backward pass를 통해 도착한 값을 Input Image에 더한다.
- 1로 돌아가 반복.
이러한 과정을 통해 특정 클래스를 Activation하는 이미지를 만들 수 있다.
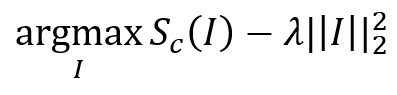
성능 향상을 위해 위와 같은 Regularization term을 추가하고, 노이즈를 제거하기 위해 Low-pass filter(가우시안 블러)를 통과시킨 후, 일정 역치 이하의 값은 0으로 만든다.

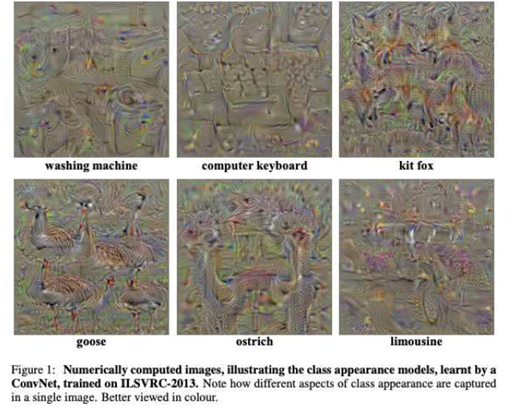
위와 같이 특정 ‘클래스’에 관한 전체적인 이미지를 조망하는 것을 볼 수 있다. 이를 통해 확인할 수 있는 점은 아래와 같다.
- Overfitting : 모델이 training data에 overfitting된 것을 볼 수 있다(거위의 흔적이 특정 구역에, 특정 모양으로만 남아있다). 데이터 보강을 했다면 다양한 장소에, 다양한 방향으로 퍼져있을 것이다.
- Security issue : 네트워크 내 가중치들만 알 수 있다면 특정 class의 판단에 쓰인 Input image들을 역으로 알 수 있게 된다. 보안이 중요한 국방, 신용 등에서는 주의 할 필요가 있다.
5. Reference
https://velog.io/@tobigs_xai/2-CNN-Filter-Visualization
https://arxiv.org/pdf/1312.6034.pdf
https://arxiv.org/pdf/1311.2901.pdf
안재현. (2020). XAI 설명 가능한 인공지능, 인공지능을 해부하다
https://www.youtube.com/playlist?list=PLKs7xpqpX1bd-UDMAe_vl2vZFQ05bzizQ
