1. GAN 평가
1.1. Inception score
GAN은 일반적으로 생성된 이미지에 대한 평가 또한 포함되어야 합니다.
다만, 인간이 직접 눈으로 평가하는 게 아닌, 정량화를 통해서 평가를 할 필요가 있습니다.
이러한 방법들 중에는 대표적으로 인셉션 스코어가 존재합니다.
생성 모델의 학습에서 제일 중요한 것은 아래와 같습니다.
- 생성된 이미지의 quality
- 생성되는 이미지의 다양성.
이를 측정하기 위해서 인셉션스코어는 사전학습된 Inception-v3 모델을 분류기로 사용합니다.

만약, 이상적인 이미지들(데이터들)이라면, Label을 예측할 때 class-distribution은 좌측 그림과 같이 불확실성이 낮을 것입니다.
또한, 생성된 이미지가 다양하다면, 그 class-distribution을 모두 합한다면 균등한 분포가 나타날 것입니다
당연히 아래와 같은 요소가 가정되어야 합니다.
- 테스트 데이터 또한 class별로 균등하다는 가정.
- Label을 잘 예측했다는 가정.
만약, 학습이 잘 안돼서 Label 분포가 균등하다면, 두 분포 간의 차이가 별로 없을 것입니다(Marginal 분포 또한 균등해질 수밖에 없으므로).
즉, 두 분포 간의 차이가 큰 방향으로 Inception score를 결정합니다.
여기서 두 분포 간의 차이는 KL발산을 이용해 계산합니다.
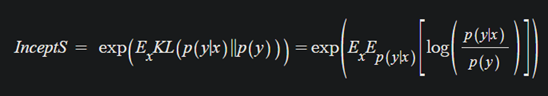
구체적으로는, 이와 같이 계산됩니다.
marginal 분포인 는 그냥 샘플 별, 클래스 예측 확률분포를 평균낸 것으로 사용합니다.
는 이미지가 생성됐을 때, 각 클래스 별 확률이므로 output distribution을 그대로 사용하면 됩니다.
marginal 확률 분포는 1이 조금 넘는데, 샘플링해서 사용하기 때문에 이는 어쩔 수 없는 부분이라 할 수 있습니다.
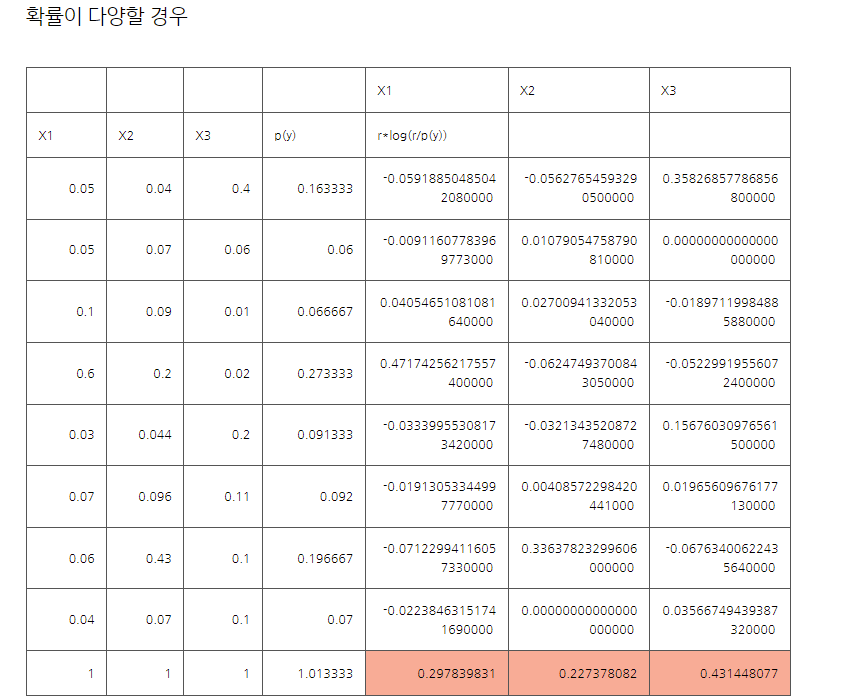
만약 marginal 분포와 class 예측 분포가 같다면 Inception 스코어가 낮을 것입니다.
단점
-
GAN과 인셉션 분류기가 데이터셋이 다를 경우
-
GAN과 인셉션 분류기의 라벨이 다를 경우
-
생성자가 클래스 당 하나의 품질 좋은 이미지만 생성한다면, 인셉션 스코어가 잘 나올 수 있다(Mode Collapse).
- 즉, (class 내) inner diversity 고려 x
-
만일 생성된 이미지가 개의 윤곽만 있는 이미지라면? 이 또한 인셉션 분류기는 잘 분류해냅니다. 그렇기 때문에 생성 이미지의 디테일은 고려하지 못할 수도 있습니다.
1.2. FID(Frechet Inception Distance)
FID(Frechet Inception Distance)는 IS를 개선하기 위해 개발되었습니다.
FID는 IS와 다르게 실제 이미지 모음의 통계량과, 생성된 이미지 모음의 통계량을 비교해 도출합니다.
여기서도 마찬가지로 Inception v3 모듈을 사용하긴 하지만, 단지 특징을 임베딩하기 위한 수단으로만 이용합니다.
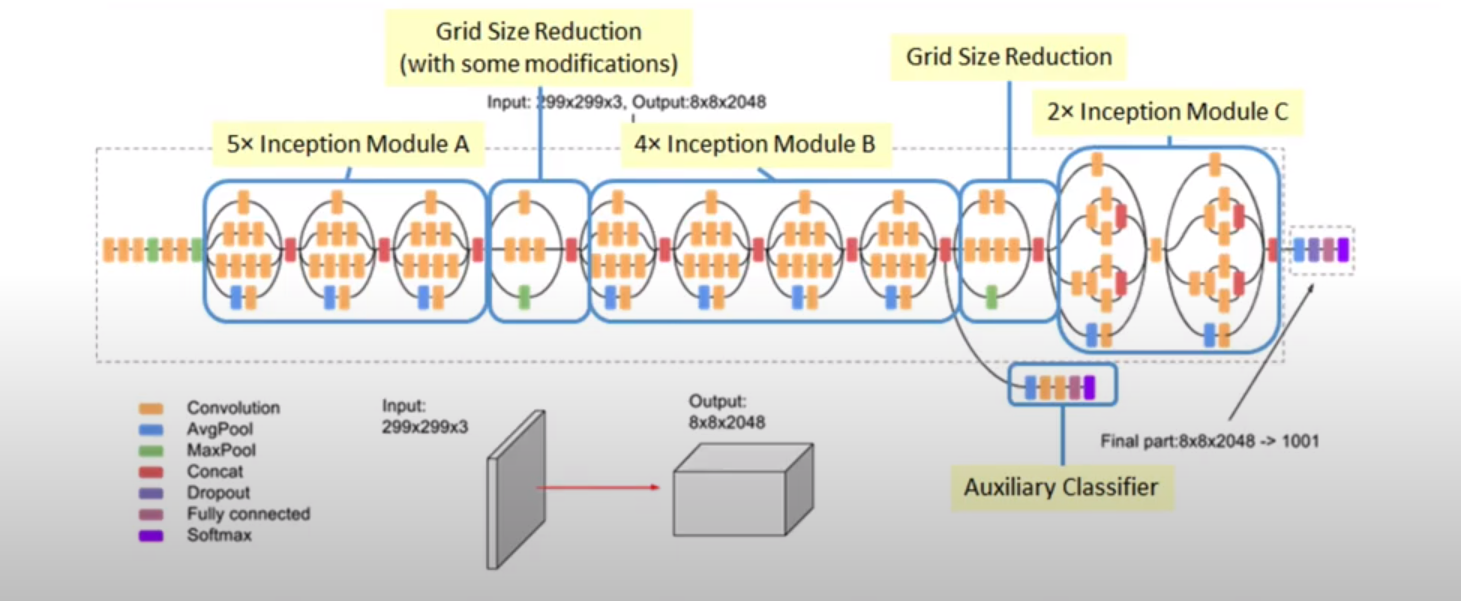
class PartialInceptionNetwork(nn.Module):
def __init__(self, transform_input=True):
super().__init__()
self.inception_network = inception_v3(pretrained=True)
self.inception_network.Mixed_7c.register_forward_hook(self.output_hook)
self.transform_input = transform_input
def output_hook(self, module, input, output):
# N x 2048 x 8 x 8
self.mixed_7c_output = output
def forward(self, x):
"""
Args:
x: shape (N, 3, 299, 299) dtype: torch.float32 in range 0-1
Returns:
inception activations: torch.tensor, shape: (N, 2048), dtype: torch.float32
"""
assert x.shape[1:] == (3, 299, 299), "Expected input shape to be: (N,3,299,299)" +\
", but got {}".format(x.shape)
x = x * 2 -1 # Normalize to [-1, 1]
# Trigger output hook
self.inception_network(x)
# Output: N x 2048 x 1 x 1
activations = self.mixed_7c_output
activations = torch.nn.functional.adaptive_avg_pool2d(activations, (1,1))
activations = activations.view(x.shape[0], 2048) #2048 x num_images로 변환
return activations당연히, Inception v3가 Feature를 잘 추출한다는 가정 하에 진행합니다.
또한, Feature 추출만을 위한 것이기 때문에 다른 모델을 써도 상관 없습니다.
이 때, Inception v3에서 얻은 임베딩을 Output이 8x8x2048이라 가정합시다.
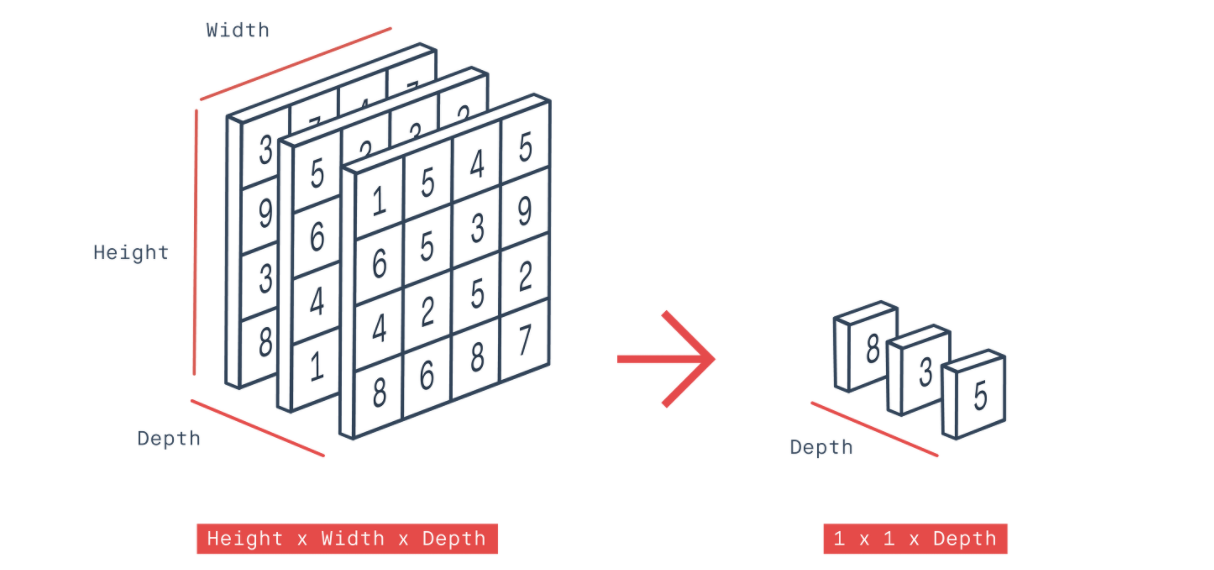
그래서, 그 임베딩을 이용해 Height, Width, Depth로 이루어진 tensor를 (Adaptive average pooling2d)를 통해 Depth vector만 남긴 뒤, 가우시안 다변량 분포를 가정하고 나서, 이 두 분포 사이의 거리를 Wasserstein-2 Distance라 불리는 Frechet distance Distance를 사용해 스코어를 냅니다.
가우시안을 가정한 이유는, 가우시안이 최대 엔트로피 모델이 되기 때문이라고 합니다.
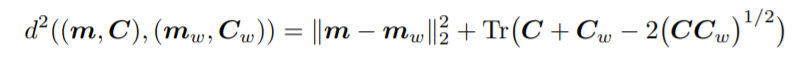
1.3. FID vs IS
-
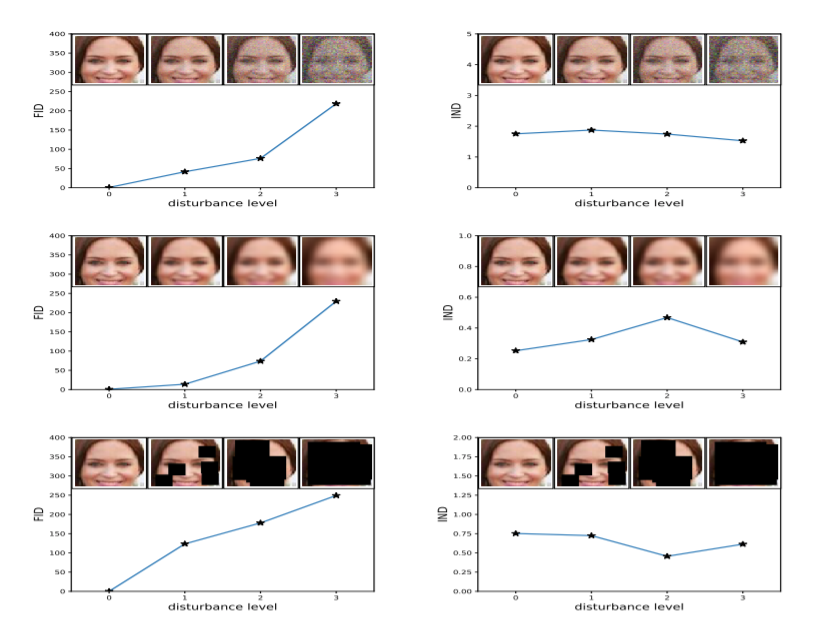
FID는 노이즈를 잘 담아 냅니다.
-
예를 들어, (블러리, 네모, 등)에 민감하게 작동합니다.
-
또한, 실제 이미지 데이터 셋과 생성 이미지 데이터 셋 전체를 직접적으로 비교하기 때문에 IS의 단점(inner diversity of class)을 해결할 수 있습니다.
특히, 실제 데이터의 통계량들은 웬만하면 따로 저장해서 사용한다고 합니다 !
FID의 단점
-
Inception v3 모델을 이용하기 때문에 pre-trained model의 학습 데이터와 특징이 많이 다른 데이터를 다룰 경우 원하는 특징이 잘 추출되지 않을 수 있습니다.
-
임베딩 분포를 다변량 가우시안으로 전제했기 때문에, 평균, 분산만으로 분포의 차이를 잘 설명하지 못할 수도 있습니다.
