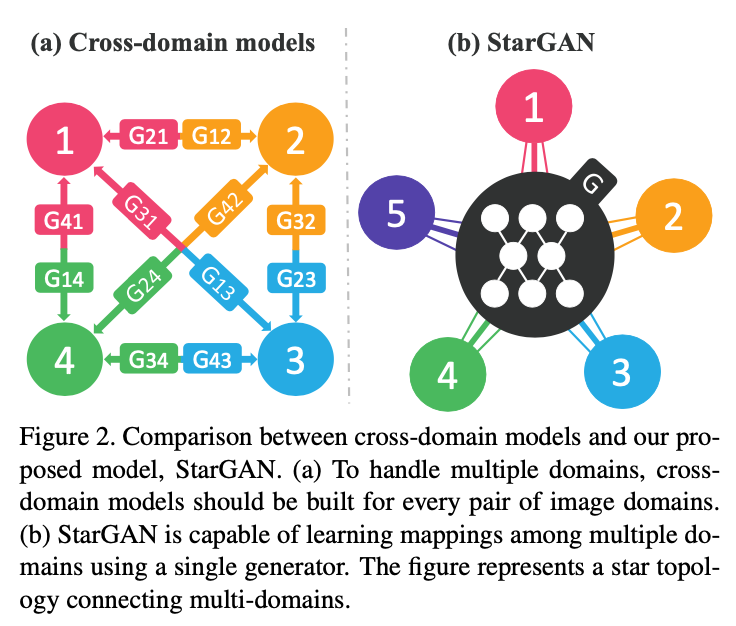
StarGAN
Introduction

보통 컴퓨터 비전 분야에서 이미지 변환(Image Translation)이란, 특정한 특징을 갖는 이미지를 또 다른 특징을 갖는 이미지로 변환하는 태스크를 일컫습니다.
ex)
- 웃는 얼굴에서 우는 얼굴로
- 흑발을 금발로
- 여름이미지를 겨울 이미지로..
- Cycle-GAN
이 때의 특징을 보통 도메인이라 부릅니다.
- attribute : 이미지 내 의미 있는 특징
- 나이, 성별, 머리 색
- attribute value : attribute의 특정 값
- 검은 머리, 노란 머리, 회색 머리 <-- 각각 다른 값
- domain : 같은 attribute value를 공유하는 이미지의 집합
- 남자, 여자
기존의 Translation 관련 GAN 모델들은 여러 가지의 특징을 변형하기 위해서는 여러 네트워크를 학습했어야 했습니다.
기존 모델들의 단점
- 개의 도메인이 존재한다면 모든 변형을 위해 개의 Generator 필요
- 각 데이터 셋들은 라벨이 같지 않기 때문에 모두 결합해 학습할 수는 없다(jointly learning x, 학습시킬 수 있는 이미지 수가 적기 때문에 성능도 안 좋다).
StarGAN은 이러한 문제들을 해결하기 위해 제안됐으며, 하나의 모델만을 이용해 여러 가지 도메인에 image-to-image translation을 적용할 수 있는 모델입니다.
또한, 여러 데이터 셋에 대해 동시에 학습할 수 있습니다.
(심지어 두 데이터 셋의 label이 다르더라도)
이를 위해서 mask vector를 활용해 각기 다른 데이터셋 간 겹치지 않는 라벨은 무시할 수 있게끔 학습합니다.
즉, 단순히 두 개의 도메인을 바꾸는 학습을 하는 것 대신, one-hot-vector로 attribute들을 표현해 이미지를 각기 다른 도메인으로 바꾸는 것을 학습하게 됩니다.
StarGAN은 아래와 같은 contribution이 존재합니다.
- 하나의 생성자 / 판별자만을 이용해 multiple domain 간 mapping 학습
- Multiple Dataset의 multi-domain image traslation을 학습할 수 있음
- 베이스 라인 모델과의 정량 / 정성평가
관련연구
간략히 식과 도표만 정리해놓고 넘어가겠습니다.
GAN
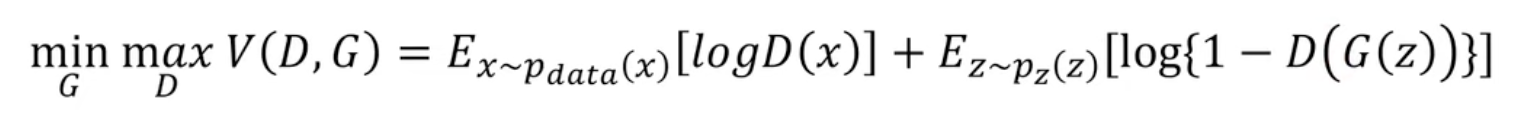
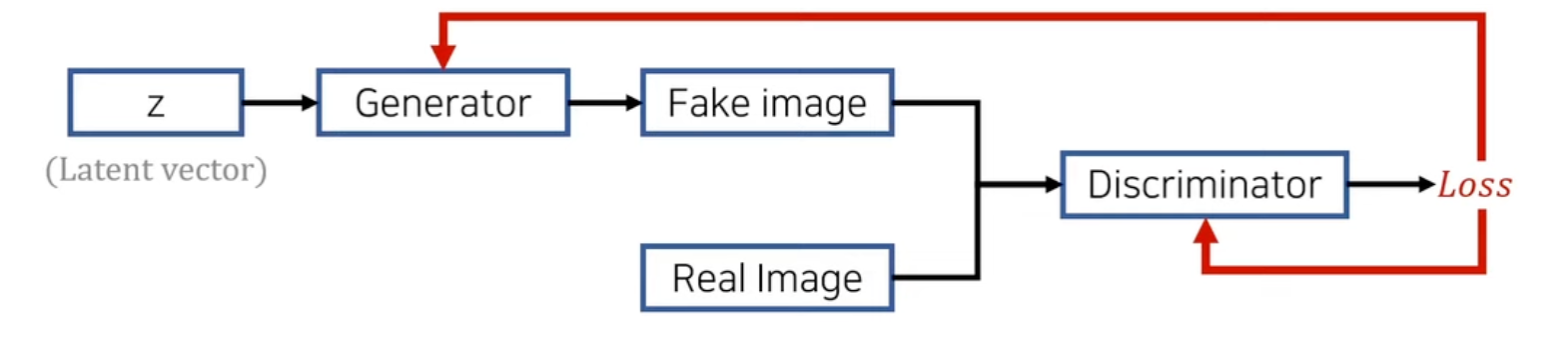
https://velog.io/@sjinu/GAN-DCGAN
CGAN
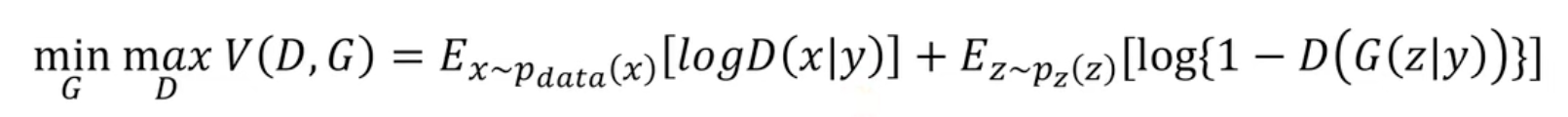
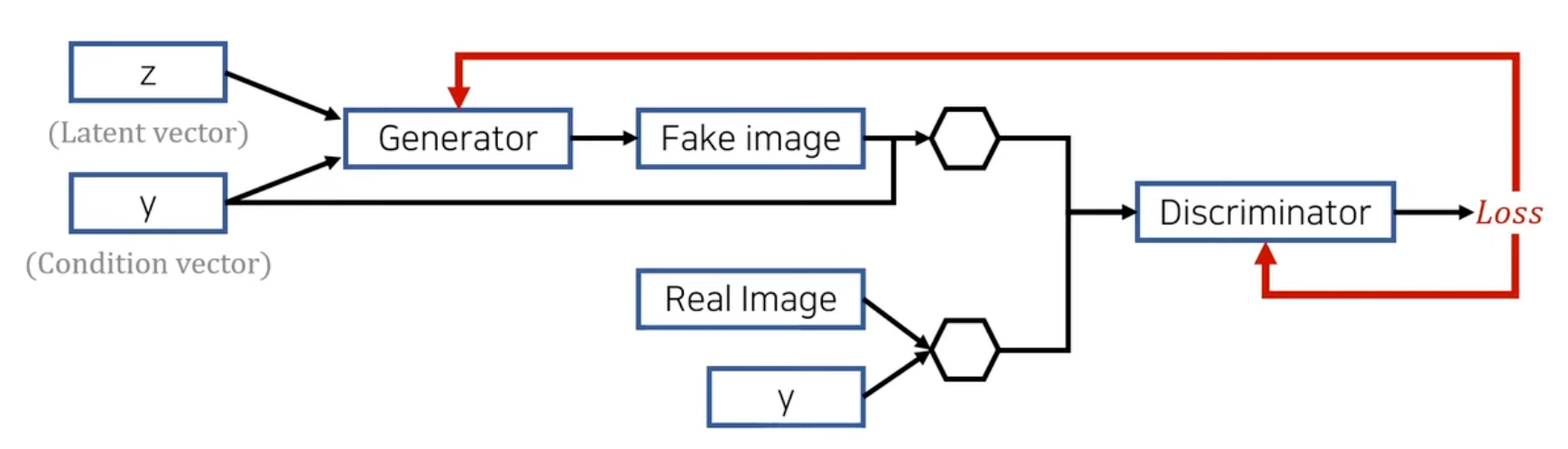
Pix2Pix - image-to-image Translation(1)
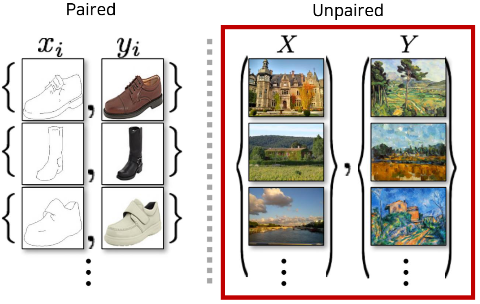
- Pix2Pix는 위 그림에서도 볼 수 있다시피 Paired Dataset이 필요합니다.
- 이런 데이터셋은 구하기 힘들기 때문에 Unpaired dataset으로 학습할 필요가 있고, 이런 방식으로 진행한 모델이 아래의 CycleGAN입니다.
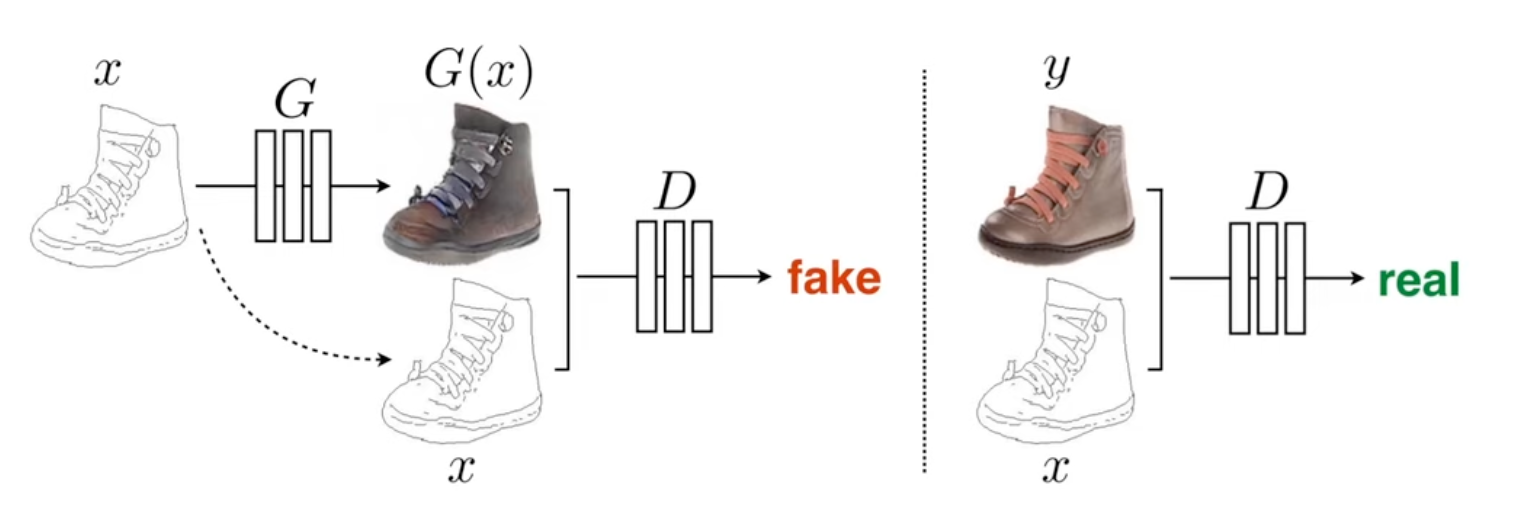
CycleGAN - image-to-image Translation (2)
- Cycle-GAN에서는 Cycle-loss를 사용하는 방식으로 원본 이미지의 content를 유지하고자 하였습니다.
WGAN(WGAN-GP)
https://velog.io/@sjinu/WGAN1
https://velog.io/@sjinu/WGAN-GP
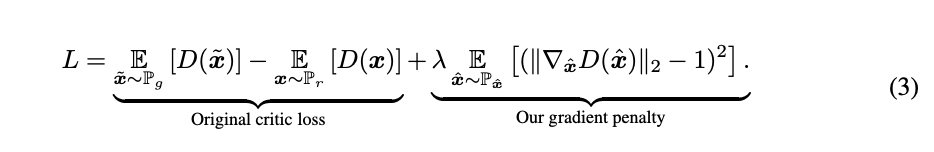
StarGAN
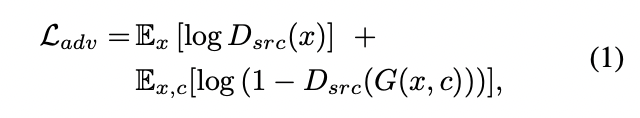StarGAN은 한 마디로 다중 도메인을 위한 하나의 모델이라고 할 수 있습니다.
기본적인 notation은 아래와 같습니다.
- : input image
- : output image
- : domain label(one-hot)
단순 목표는 아래와 같이 생성자 가 여러 도메인 간의 매핑을 학습하는 것입니다.
Vanilla GAN은 input으로 잠재 벡터 를 받지만, 여기서는 input image 와 class label 를 받습니다.
이 때, 이미지의 진위 여부() 뿐만 아니라 해당 이미지가 어디에 속하는 지()에 대한 판별도 진행합니다.
Training Loss
우선 StarGAN의 loss를 먼저 살펴봅시다.
Adversarial loss
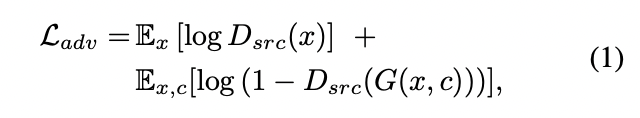
- 이는 Vanilla GAN의 loss와 같습니다.
- 는 위 식을 최소화, 는 최대화하는 방향으로 적대적 학습이 진행됩니다.
Domain Classification loss
새롭게 추가된 loss입니다.
StarGAN의 목표는 이미지 와 target domain label 가 주어졌을 때 로 분류될 수 있는 output image 를 만드는 것이었습니다.
이런 조건을 만족시키기 위해 판별자 에 보조 분류기를 추가해 도메인 분류를 추가적으로 진행하게 되며, 이를 위한 loss term은 아래 2개와 같습니다.
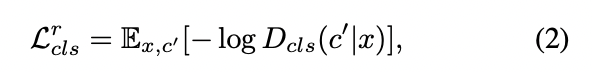
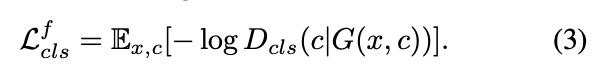
- 식 (2) : 를 최적화하기 위한 진짜 이미지에 대한 도메인 분류
- Loss니까 당연히 낮추어야 하며, 그렇다는 건 를 높히는 방향, 즉 image 를 받아 domain을 로 예측할 확률을 높히는 방향으로 학습하게 됩니다.
- 식 (3) : 를 최적화하기 위한 가짜 이미지에 대한 도메인 분류
- 즉 가짜 이미지 를 받아 분류기 가 이를 target domain 로 예측하게끔 학습됩니다.
Reconstruction loss
CycleGAN과 유사한 loss입니다.
위의 Loss들만 사용한다면 생성자는 그저 분류기를 속이는 방향으로 target domain 에 대한 이미지를 생성하자라는 목표만을 갖기에, 하나의 이미지만을 생성하거나 무의미한 mapping을 학습할 수 있습니다.
즉, 올바른 domain 변화는 야기하되 content를 보존하지 못할 수 있습니다.
그래서 아래와 같이 Cycle consistency loss를 추가해주어야 합니다.
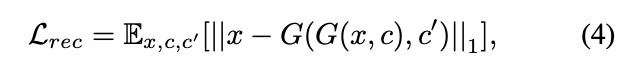
Full Objective
위의 세 종류의 loss를 통합해 최종적인 loss를 구성할 수 있습니다.
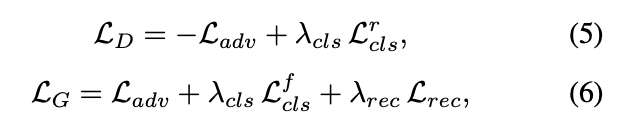
- 본 논문에서는 을 설정해 domain classification <-> reconstruction <-> adversarial loss 간 중요도를 조절했습니다.
즉, 학습 과정을 도식화하면 아래 그림으로 나타낼 수 있습니다
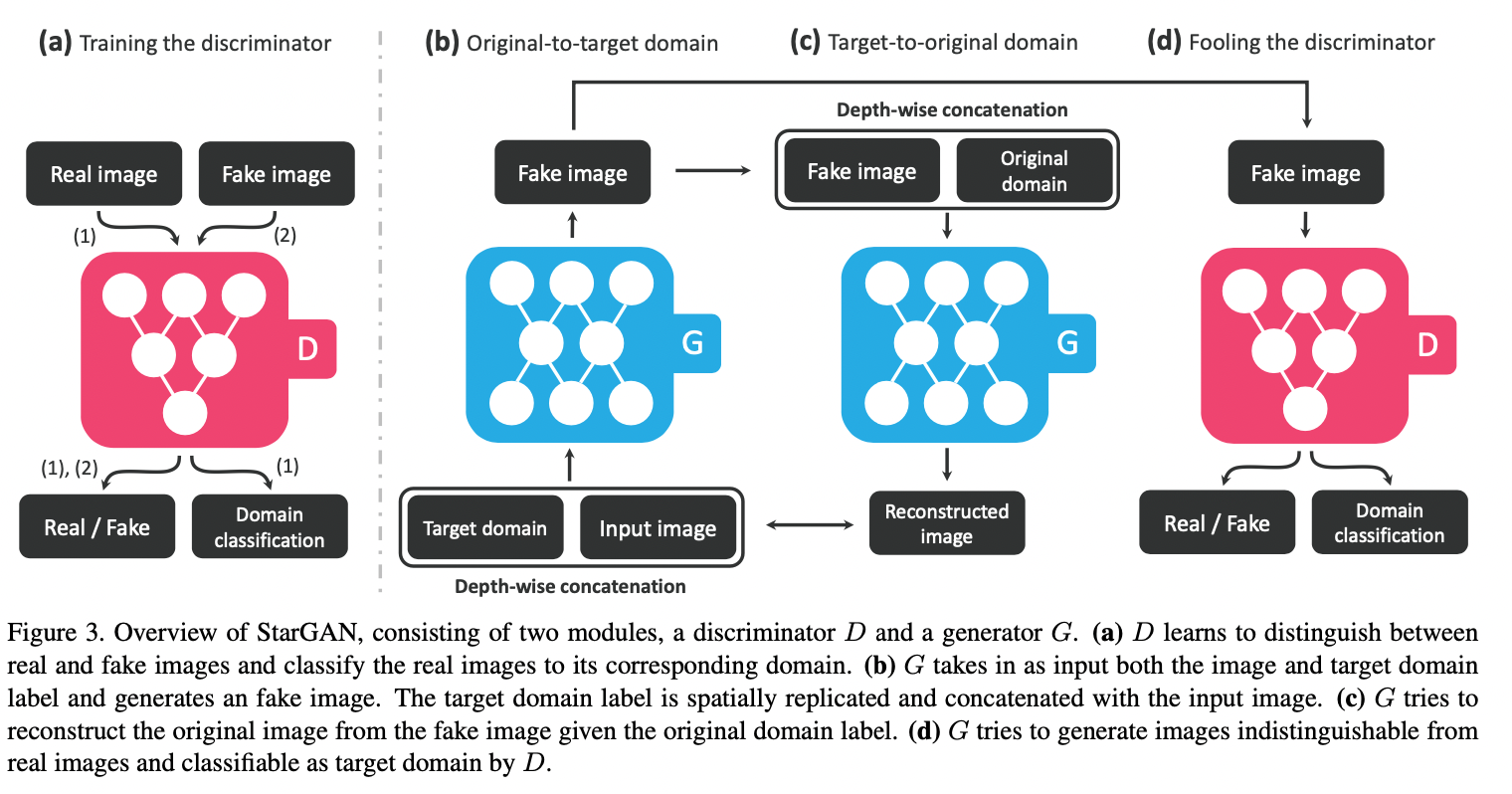
위에서 보다시피 를 학습할 때에는 Fake image에 대한 도메인 예측을 하지 않습니다
정확히 말하면 의 학습에만 안 쓰일 뿐, 의 학습에는 쓰입니다.
Mask vector
- 여러 도메인을 학습하기 위한 전략 중 하나입니다.
예를 들어 데이터 셋이 아래와 같이 구성되어 있다고 해봅시다.
- Dataset A : [hair color, age, gender]
- Dataset B : [face expression, hair length]
위와 같은 데이터 셋을 단순히 합쳐서 사용한다면 둘의 label이 다르기 때문에 학습할 수 없습니다.
이 둘을 통합하기 위한 개념이 mask vector로, label의 형식들을 맞춰 놓고 실제로 A를 학습할 때에는 B의 label들을 보지 못하게, 그리고 B를 학습할 때에는 A의 label들을 보지 못하게 가리는 역할을 합니다.
아래와 같이 notation을 정합시다.
- : 사용할 데이터 셋의 개수
- : mask vector
- 은 차원 원핫 벡터가 되겠죠.
그러면, 데이터 셋이 개이므로 각각 데이터 셋에 대한 라벨인 ~ (binary vector)과 학습할 데이터 셋 외의 데이터를 가리기 위한 마스크 벡터 (onehot vector)을 포함해 아래와 같이 통합된 라벨을 나타낼 수 있습니다.
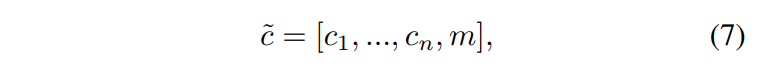
이에 대해서는 아래에서 사용할 예시(CelebA, RaFD)에서 살펴보겠습니다().
Training

CelebA 이미지를 학습한다고 가정해봅시다(우측 상단)
그러면, Mask vector를 으로 할당해주고 RaFD에 대한 label vector는 zeros vector로 만들어줌으로써 CelebA에 대한 라벨만 활성화해줍니다.
이 때, 학습을 진행하면서 얻은 Loss의 Gradient는 RaFd label로는 backword를 해주지 않습니다.
label prediction in
학습 도중에는 입장에서 input real image의 CelebA label(좌측 상단의 노란색 [0,0,1,0,1])을 받아 해당 label로 예측하게끔 Loss로부터 역전파를 진행합니다.
true or false prediction in
이러한 Label 예측과 별개로 input real image와 generated fake image의 진위 여부 또한 잘 구별하게끔 라벨이 주어진 채로 학습이 진행됩니다.
label prediction in
의 입장에서는 가 fake image를 target domain의 라벨인 target label$(우측 상단의 노란색 [1,0,0,1,1])로 판단하게끔 라벨을 부여해 학습을 진행하게 됩니다.
true or false prediction in
생성 이미지에 대한 진위 여부를 가 잘못 판단하게끔 라벨을 주어 학습하게 됩니다.
reconstruction error in
target-domain에서 다시 input domain으로 역변환한 이미지를 input image와 비교해 cycle-consitency error를 계산해 학습하게 됩니다.
- 당연히 를 학습할 때에는 를 업데이트 하지 않습니다(반대도 동일).
Implementation
WGAN-Gp의 Adversarial Loss 차용
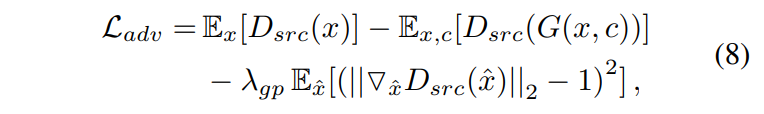
- WGAN Loss를 사용했습니다(WGAN-GP,velog).
Generator
위에서 대략적으로 살펴본 것처럼 Cycle GAN 구조를 약간 차용한 StarGAN을 사용합니다. Generator의 자세한 구조는 아래와 같습니다.
- downsampling을 위한 2-stride convolution layers
- 6 residual blocks
- upsampling을 위한 2-stride transposed convolution

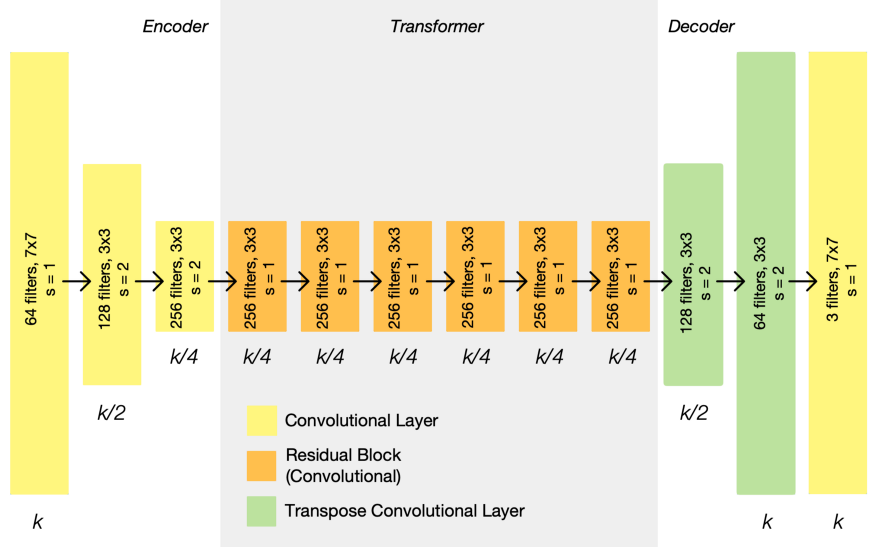
그림 참고(CycleGAN) : https://towardsdatascience.com/cyclegan-learning-to-translate-images-without-paired-training-data-5b4e93862c8d
- 그 외에 instance normalization을 적용했다고 합니다(Generator에만).
- : domain labels의 차원
- 논문 내 CelebA와 RaFD 데이터 셋에 대해서는 라고 합니다. 아마 CelebA의 hair color, gender, age와 RaFD의 facial expression이 아닐련지..
즉, 가 데이터 셋의 개수인 2개일 때, 라고 표현을 하긴 했는데, 그에 대해서는 이유를 잘 모르겠습니다.
- 논문 내 CelebA와 RaFD 데이터 셋에 대해서는 라고 합니다. 아마 CelebA의 hair color, gender, age와 RaFD의 facial expression이 아닐련지..
Code for Generator

Discriminator
-
PatchGAN을 사용했습니다.
-
는 domain의 개수(domain labels)

pix2pix에 쓰인 PatchGAN과 비슷한 듯 합니다.
Code of Discriminator

Experimetns
- Adam()
- Data augmentation(flip)
- 판별자 5번 업데이트 당 생성자 1번 업데이트
- 배치사이즈 16
- e.t.c.
또한 비교를 위한 모델들은 다중 도메인 학습을 지원하지 않기 때문에 도메인마다 각각 학습했다고 합니다.
Experimental Results
- 단일 도메인 간 변환만 학습한 모델들보다 다중 도메인으로 학습한 Star GAN이 단일 도메인 간 변화 성능에 있어서도 좋은 모습을 보였습니다

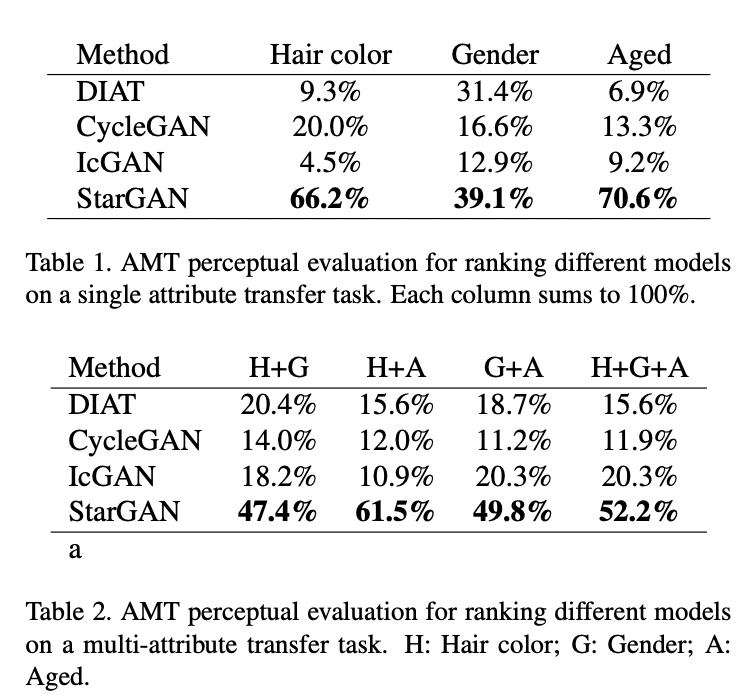
아마 데이터 셋을 동시에 많이 사용할 수 있기 때문에.
생성 이미지 검증(through trained classifier)
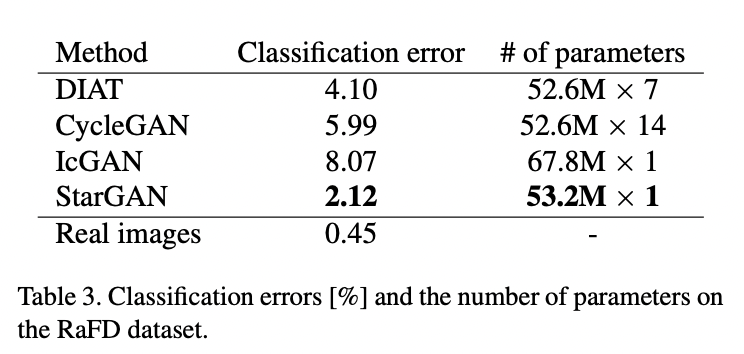
Jointly Training의 효과

mask vector의 효과

표정을 변경시키려면 RaFD에 해당하는 mask vector인 [0,1]을 사용해야 한다.
잘못된 마스크 벡터([1,0])를 사용하면 표정 변환을 제대로 못 하고, 나이를 조작하게 됩니다.
Conclusion
- 여러 도메인 간 변환을 하나의 생성자 학습만으로도 가능한 모델 StarGAN 제안.
- multi-task learning의 일반화 성능 때문에 하나의 도메인만 학습했을 때보다도 더 높은 품질의 이미지를 생성할 수 있었음.
- 여러 데이터셋을 사용할 수 있기 때문에 모든 label을 동시에 처리할 수 있었음.
Ref
본문 내 기재
