※ 본 글은 Video object segmentation에 선행하는 모델로서 작동하는 VQA 모델을 찾기 위해 사용가능한 github code와 paper를 대략적으로 정리한 글입니다.
작성일 : 2021-05-30
VQA(Visual Question Answering)는 INPUT이 질문형 문장(ex; ~~에는 ~~가 몇 개 있니?)인 반면 VOS에 적용하려면 (1) INPUT이 명령형 문장(ex; 비디오에 붐 마이크에 해당하는 object를 지워줘; 사람 제외 동물에 해당하는 object를 지워줘)으로 적용해야 한다.
물론, 이는 질문 자체를 ‘지우고 싶은 object를 말해주세요.’ 라는 식으로 설정해 지울 object에 대한 단답형 답변을 받아도 되지만 VQA에 대한 개념을 도입한 순간 단순히 video object removal 만이 아닌 video object selecting(masking), video object replacement, video object coloring 등으로 모델의 역할이 확장될 수 있는 용이성을 부여하기 위해, 또는 인터랙티브한 인간 중심 AI 구현을 위해 고려해볼만 한 사항이라고 생각됨.
또한, VQA에 대한 대답으로 나오게 될 object words 외에도 추가로 SIAM MASK(바운딩박스를 이용하여 비디오 내 물체의 segmentation mask를 tracking하는 모델)에 연결시키기 위해 (2) Bounding box(또는 Segmentation mask)의 요소가 존재해야 할 듯.
Paper & Code
1. VQA: Visual Question Answering
Paper(링크, Official(?), Oct 2016, Cited by 2686)

- VQA의 오리지널 격 논문인 듯.
Code 1(링크, Not official, Maybe)
- Pytorch VQA : Visual Question Answering

Code 2(링크, Not official, 위 paper 기반 + 2개의 추가 모델
- CNN+LSTM, Attention based, and MUTAN-based models for Visual Question Answering

특징 : 위의 기본 VQA paper(2016)외에 추가적으로 아래 두 개의 연구를 기반으로 함
- Stacked Attention Networks for Image Question Answering
- MUTAN: Multimodal Tucker Fusion for Visual Question Answering
2. Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Paper(링크, Nov 2018; Cited by 123)
Code(링크, official)
- Code for our paper: Learning Conditioned Graph Structures for Interpretable Visual Question Answering

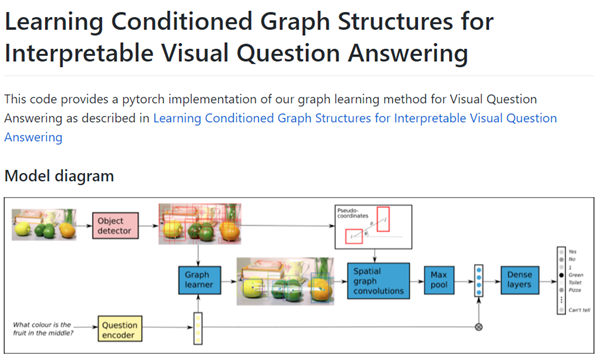

특징
- Graph Structure를 중심으로 하는 연구, 그와 동시에 Bounding box 형태의 요소가 나와 SIAM MASK(code 상)랑 연결시키기 용이할 수 있음
- 자세히 안 읽어봐서 정확히는 모른다. 그리고 아마 다른 VQA 연구들도 Bounding-box와 관련된 요소가 있을 것
3. Exploring Models and Data for Image Question Answering
Paper(링크, Nov 2015, Cited by 579)
Code(링크)


특징
- 평범함.
4. MUTAN: Multimodal Tucker Fusion for Visual Question Answering
Paper(링크, May 2017, Cited by 341)
Code(링크)

특징
- 본 글에서 첫번째로 소개한 연구의 두번째 코드도 해당 모델인 MUTAN을 기반으로 사용했음.
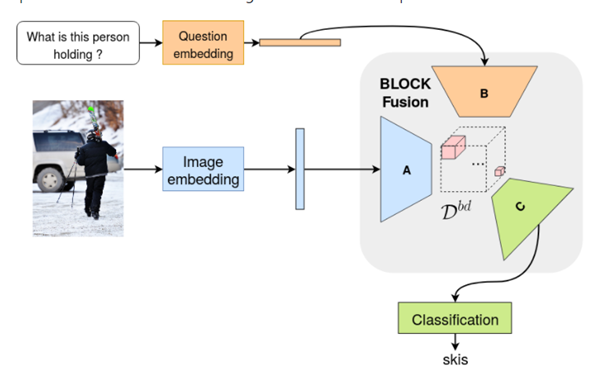
5. BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection
Paper(링크, 2019, Cited by 68)
Code(링크, Official)

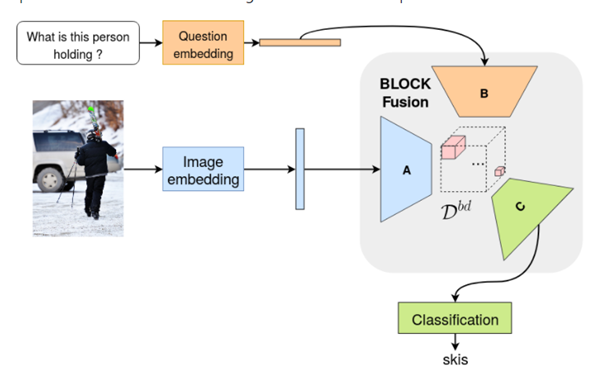
특징
- MUTAN 연구와 동일 저자, 최신버전, 논문 또한 가장 최신)
- fusion of the state-of-the-art (MLB, MUTAN, MCB, MFB, MFH, etc.)
결론
- 마지막 4,5 모델의 경우 논문과 코드가 굉장히 깔끔한 듯 하다.
- VQA 모델 중 Object detection과 관련된 부분을 어떻게 처리하는 지에 대한 아이디어와 코드를 얻으면 좋을 듯 하다.
