
Paper: https://arxiv.org/abs/1806.02071
Code: https://github.com/byungsook/deep-fluids
Video: https://www.youtube.com/watch?v=hSDzOZ9IO8U
본 연구의 핵심은 "CNN+ 유체 방정식을 고려한 손실함수"라 할 수 있습니다. 물리 분야의 연구가 아닌 만큼 유체방정식에 대해서는 깊게 다루고 있지 않지만, 물리 관련 용어와 간단한 수식이 꽤나 많이 나옵니다.
이에 대한 원활한 이해를 위해 유체 방정식의 수치적 모델을 다루는 데 있어서 필요한 배경지식을 정리한 글인 What Are the Navier-Stokes Equations?을 먼저 보는 것을 추천드립니다.
0. Abstract
본 연구는 일련의 파라미터를 사용해 유체 시뮬레이션(fluid simulation)을 합성하는 생성모델을 제안합니다. CNN을 사용해 유체 시뮬레이션의 velocity fields를 학습하며, 이로부터 데이터의 표상(representation)을 학습하게 됩니다. 저자들이 제안한 새로운 방법론은 아래와 같습니다.
- divergence-free velocity filed를 보장하는 새로운 손실 함수 제안
- reduced spaces 내 복잡한 매개변수 제어 + latent space를 통합함으로써 다양한 시뮬레이션 수행
이러한 방법을 통해 유체의 행동을 모델링함으로써 fast construction, inerpolation of fluids, time re-sampling, latent space simulations, compression of fluid simulation data 등 다양한 기능을 수행할 수 있습니다. 특히, 데이터를 re-simulate하는 데 있어서 기존의 CPU 기반 방법에 비해 700배가량 빨랐으며, 시뮬레이션 데이터를 1300배 가량 압축할 수 있었습니다.
1. Introduction
최근 머신러닝(딥러닝) 기반 방법들이 발달함에 따라 그래픽스(graphics) 분야에서도 널리 적용이 되고 있습니다.
- 지형 생성(Guerin et al., 2017): Interactive Example-Based Terrain Authoring with Conditional Generative Adversarial Networks
- 고해상도 얼굴 합성(Karras et al., 2017): Progressive Growing of GANs for Improved Quality, Stability, and Variation.
- PGGAN으로도 불립니다.
- 구름 렌더링(KALLWEIT et al., 2017): Rendering atmospheric clouds with radiance-predicting neural networks.
뿐만 아니라, 본 연구가 다룰 예정인 유체 시뮬레이션 분야에서도 TempoGAN(XIE et al, 2018) 등 최근까지 머신러닝 기반 방법론들이 연구되고 있습니다.
특히, (유체 시뮬레이션)데이터 기반 머신러닝 방법론들이 매력적이었기 때문에 널리 연구되고 있는데, 2016년까지는 일반적으로 linear basis function을 활용해 유체를 표현했기 때문에 (비선형 방법보다) 비효율적인 모습을 보여왔습니다.
위에서 말하는 linear basis function의 예시는 특이값 분해(SVD; Singular Value Decomposition)를 들 수 있습니다. 즉, PCA(주성분 분석), LDA(선형판별분석) 등에 쓰이는 방식
당연히 현실 세계의 현상들은 (일반적으로) 비선형적이기 때문에 비선형 모델링을 이용하는 딥러닝 기반 생성 모델이 유체 시뮬레이션 데이터를 표현하는데 강점을 보인다고 할 수 있겠죠.
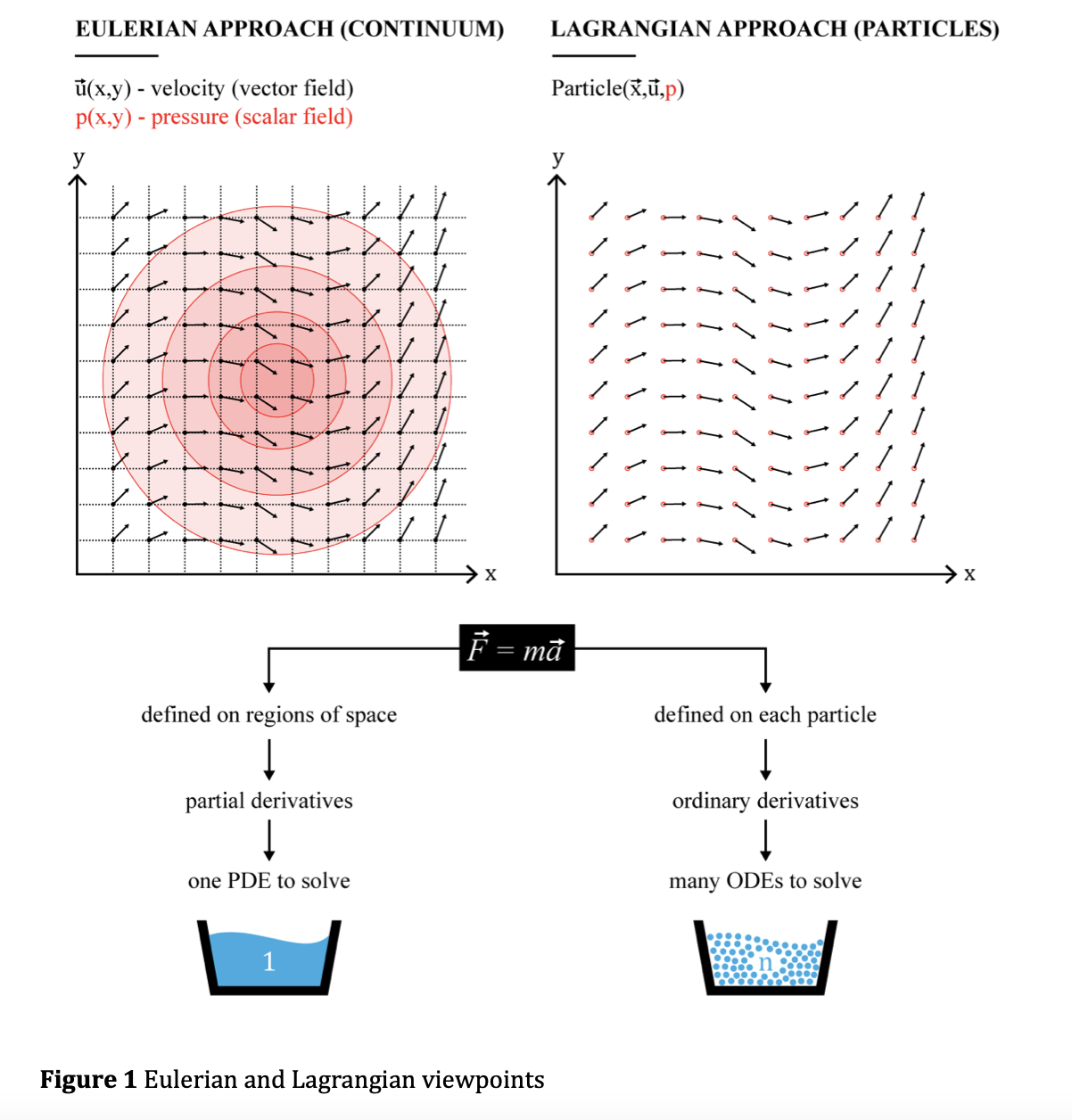
논문의 이름에서부터 알 수 있다시피 본 논문의 저자들도 딥러닝 기반 방법을 제안하며, 특히 (reduced) parameter로부터 동적인 Eulerian fluid simulation velocities*를 구축하는 최초의 생성모델이라고 합니다.
즉, 몇 개의 discrete-parameterizable simulation example이 주어지면, 이로부터 연속적인 velocity field(속도장)을 생성할 수 있게 됩니다. 이를 이용하면 (최상단의 Fig. 1와 같이) 연기에서부터 일반적인 액체에 이르기까지 다양한 유체의 행동을 기술할 수 있습니다.
* Eulerian fluid simulation velocities?(versus Lagrangian)
Image Source: Liviu-George et al., 2016
즉, 시간에 continuous한 velocity field를 모두 생성할 수 있고, 이로 인해 sparse한 reconstruction을 다루는 이전 방법론들에 비해 훨씬 효율적인 시뮬레이션을 수행할 수 있었다고 합니다.
이외에도 실행 시간(700배), 데이터 압축, 비선형 표현(현실적인), latent space 시뮬레이션 등에서 기존의 SoTA 방법들보다 훨씬 나은 결과를 보였으며, 이런 이점으로 인해 game, VR, simulator 등 real-time application 내 물리 현상을 구현하는데 널리 쓰일 수 있습니다.
해당 모델의 technical contribution을 요약하면 아래와 같습니다.

2. Related Work
Reduced-order Methods
Subspace solver는 일반적으로 simplified representation을 찾음으로써 시뮬레이션을 가속화(acceleration*)하는 방법입니다.
* 일반적으로 해당 분야에서는 크거나 긴 시뮬레이션을 돌릴 때 연산량이 많이 요구되는 편입니다. 그렇기 때문에 현실적인 상황에서 시뮬레이션을 수행하기 위해(벡터 필드를 연산하기 위해) 연산량(혹은 연산속도)를 낮출 필요가 있으며, subspace solver는 이를 subspace를 통해 해결한다고 보면 될 것 같습니다.
엔지니어링 분야에서는 이런 기법들이 1967년 즈음에 소개됐지만, 컴퓨터 그래픽스분야에서는 2006~2007년 정도에 도입됐으며(Treuille et al., 2006; Gupta et al., 2007), 이후에도 다양한 방식으로 계속해 발전했습니다(Wicke et al., 2009, Kim et al., 2013 등).
마찬가지로 Subspace solver와 비슷한 Laplacian Eigenfunctions 방법도 제안됐으며, (학습할 때가 아닌) linear subspace를 연산할 때 필요한 training data의 필요성을 없앰으로써 개선된 연구가 발표됐습니다(Gerszewsi et al., 2015).
이런 방법들이 사용하는 basis function은 일반적으로 모두 선형적으로 작동하며, 유체를 시뮬레이션하기 위해서는 별도의 방법을 통해 비선형 매니폴드(non-linear manifold)에 시스템을 강제로 올려놓을 필요가 있습니다. 하지만 이런 reduced-order 방식을 사용할 경우 발생하는 한계는 유체의 비선형성을 표현하는 과정에서 종종 explosion of subspace dimensionality 현상이 일어날 수 있다는 것입니다. 그래서 [유체-고체] 간 결합을 시뮬레이션하기 위해서 유체는 direct한 차원에서 연산하고, 고체는 reduced model을 이용해 다루는 연구나(Lu et al., 2016), (관측 시점이 고정되어야 한다는 치명적인 제약이 있긴 하지만) 유체의 행동을 미리 연산함으로써 문제를 해결하려는 연구도 존재합니다(Stanton et al., 2014).
본 연구의 저자들은 이런 방법들의 한계를 비선형성을 탑재한 CNN기반 방법을 통해 해결할 수 있음을 보여줬습니다.
Machine Learning & Fluids
fluid solver를 머신러닝 기반 방법과 결합한 최초의 연구는Ladicky et al., 2015의 연구입니다. 해당 연구는 Random Forest(for Regression)을 이용해 Lagrangian system 내 나비에 스토크스 방정식을 근사함으로써 다음 time step의 유체의 부분적인 위치와 속도를 예측했습니다. 이런 방식은 효율적이지만 정교한 handcrafted feature를 필요로 하기 때문에 (저자들이 제안하는 CNN 기반 방법에 비해) 일반성이 떨어진다고 할 수 있습니다.
그 외에 하나의 time step에 대한 pressure field를 예측하는데 CNN기반 방법을 사용하거나(Tompson et al., 2017), 여러 time step에 대한 pressure field를 예측하는데 LSTM 기반 방법을 사용한 연구들도 있었습니다(Wiewel et al., 2018). 하지만 이런 연구들은 fluid solver의 pressure projection 단계에서만 작동하기 때문에 divergence-freeness(후술)를 보장하기 위해 별도의 시스템을 구축해야 한다는 한계가 있습니다.
그 외에도 고해상도로 smoke flow를 구현하는데 CNN-based descriptor을 사용하거나(Chu et al., 2017), GAN을 사용하거나(Xie et al, 2018), FLIP simulation-유체의 운동을 기술하는 일종의 시뮬레이션-을 위해 learned splash model을 사용하거나(Um et al., 2018), fluid simulation을 위해 deformation learning을 사용하는 연구들도 있었으나(Prentl et al., 2017), 이는 단지 signed distance function에 집중해 CNN을 사용했을뿐, 다양한 유체 시뮬레이션의 velocity space에 초점을 맞추지는 않았습니다.
signed distance function을 input boundary condition으로 사용한 CNN을 이용해 Lattice-Boltzmann steady-state flow solution을 해결하거나(Guo et al., 2016), heat conduction과 in-compressible flow solver의 평형상태를 학습하기 위해 GAN을 사용한 연구들도 있었으나(Farimani et al., 2017), 해당 방법들은 정의된 공간 내의 일련의 initial condition에 대한 parameter를 받아 단지 하나의 steady state solution을 예측할뿐 연속된 시뮬레이션을 다루는 interpolation을 수행할 수 있는지는 따져보지 않았으며, 2D 환경에서만 연구를 진행했다는 한계가 있습니다.
Machine Learning & Physics
물리학 커뮤니티에서도 여러가지 복잡한 물리 문제를 모델링하고 근사하는데 딥러닝 기반 아키텍처를 사용하는 방법들이 관심을 받아왔습니다. 위와 마찬가지로 강화학습을 사용해 복잡성을 줄이거나, GAN을 사용해 은하 이미지를 합성하거나 3D의 porous media를 구축하는 등의 연구가 있었습니다.
저자들의 모델은 생성모델이긴 하지만 known parameterization을 사용하기 때문에 Adversarial loss는 사용하지 않았으며, 대신 direct loss function을 구축함으로써 고성능의 representation이 학습될 수 있음을 보여주었습니다.
3. A Generative Model For Fluids
우선, 아래와 같이 notation을 정의합시다.
- : fluid velocity
- : fluid pressure
- : externel force
이 때, 전통적으로 유체의 운동은 아래와 같이 두 개의 식으로 기술할 수 있습니다.
- inviscid(비점성) momentum* :
- mass conservation** :
점성이 있는 경우 식 를 포함할 수 있으나, 일반적으로 시뮬레이션 쪽에선 수치적으로 해결한다고 합니다(rely on numerical dissipation).
** 위의 mass conservation은 수식적으로 "vector 의 발산(divergence)이 0"이라고 볼 수 있기 때문에 divergence-free라고 칭할 수도 있습니다(발산 (벡터) - 위키백과).
식이 왜 위와 같이 도출되는지는 아래 참고
- * inviscid momentum : meteo.physik.uni-muenchen.de
- ** mass conservation(continuity equation) : doc file download
위 식을 기반으로, 일련의 학습 데이터를 이용해 original velocity field를 예측할 수 있는 CNN을 학습하는 것이 해당 연구의 목표입니다.
즉, input parameter***에 여러 층의 convolution을 적용해 얻은 (예측)velocity field와 기존의 (정답)velocity field 간의 loss를 줄이는 방향으로 학습하게 되겠죠.
*** : 위에서 말하는 input parameter는 유체 source의 위치, 각도, 크기 등이 될 수 있습니다(유체가 어디서 어떻게 발생하는지 등).
요약하자면 본 연구에서 사용하는 input은 [parameter(condition) + target velocity field], 즉 parameterizable datasets이 됩니다.
Loss Funcction for Velocity Reconstruction
손실함수를 다루기에 앞서, 아래와 같이 notation을 정의합시다.
- : parameters of solver
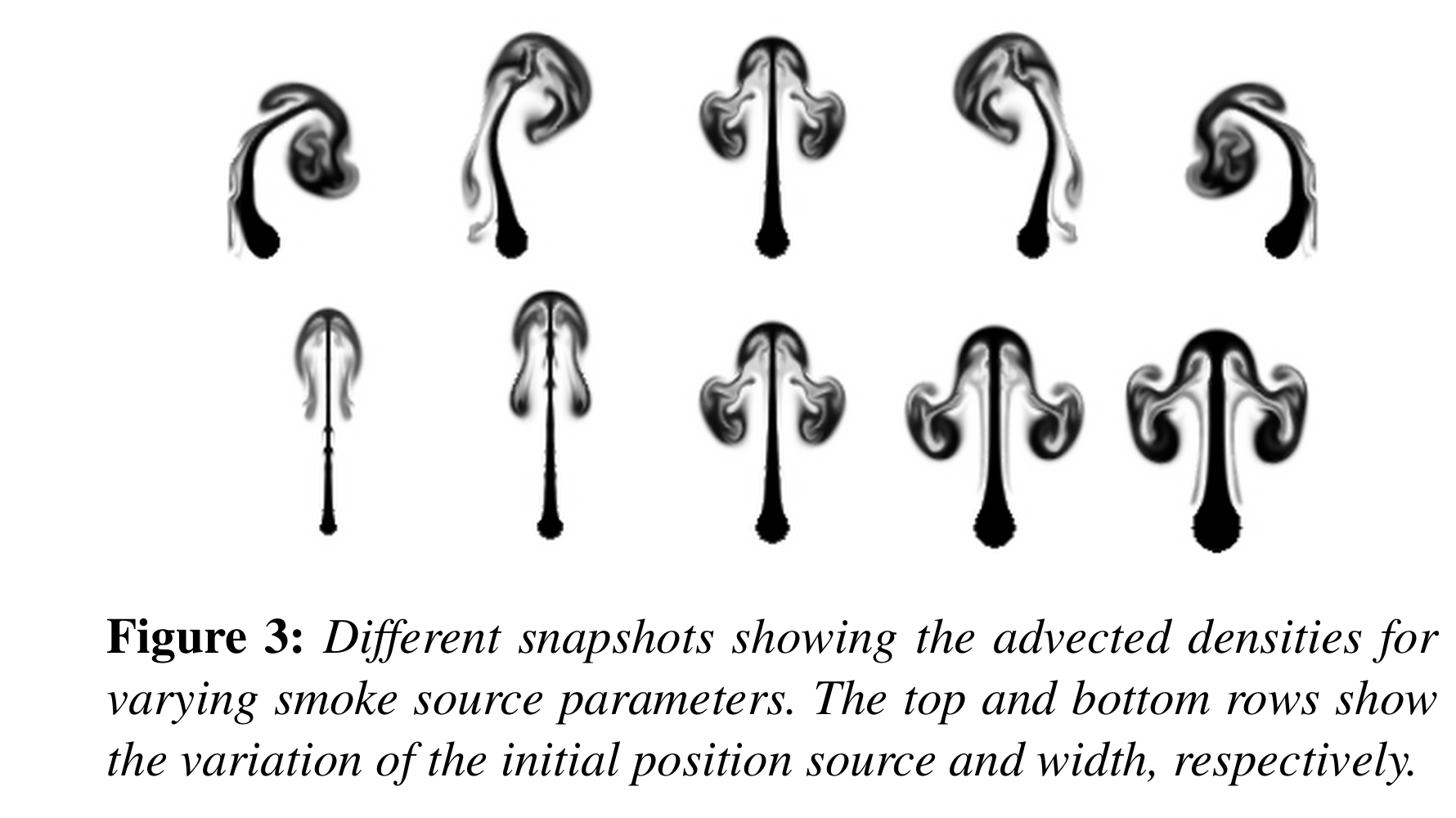
- source의 위치, 너비, timestep 등(Fig. 3 참고)
- : single velocity vector field.
- : (관측하려는 속도장의)height
- : weight
- : depth
- 2D를 다룰 때에는
- 벡터장의 차원
- 2D: , 3D:
그러면, 위에서 살짝 언급했다시피 네트워크의 input은 pair 로 설정할 수 있습니다.
에 time step이 포함되기 때문에 는 single frame에 대한 속도장입니다.
애초에 나비에-스토크스 방정식은 비선형 편미분 방정식이기 때문에, 위에서 input condition 가 동일하더라도, 매우 다양한 output들을 반환하게 됩니다(exact solution을 구할 수가 없음).
위와 같이 velocity-parameter input을 설정하고 나면 이후에는 일반적인 딥러닝 연구들과 마찬가지로 loss함수를 설정하고, 미니배치 학습을 통해 loss를 낮추는 방향으로 CNN 아키텍처 내 internal weights를 업데이트하게 됩니다.
단, 여기서 중요하게 따져봐야할 사실은 아래와 같습니다.
"loss 함수를 어떤 것으로 설정할까?"
먼저 이전 연구들에서 쓰인 loss함수를 생각해봅시다.
- Image 간 비교에 가장 기본적으로 쓰이는 norm
- mae(), mse() 등
- 이미지의 구조적인 정보를 고려한 유사도인 SSIM을 다양한 스케일에서 적용하는 MS-SSIM(Multi Scale Structual Similarity)(Zhao et al.(2017), Loss Functions for Image Restoration with Neural Networks)
- 픽셀 간 비교가 아닌 high-level feature를 활용해 이미지를 비교하는 perceptual losses(Johnson et al.(2016), Perceptual Losses for Real-Time Style Transfer and Super-Resolution)
위처럼 컴퓨터 비전 분야에서는 정답 이미지와 예측 이미지를 비교하는 방법은 굉장히 다양합니다. 본 연구에서 다루는 velocity vector field도 일종의 이미지로 바라볼 수 있기 때문에 위와 같은 loss함수를 사용할 수 있고, 실제로도 선행 연구들도 위와 같은 loss를 사용했다고 합니다.
다만, 엄밀히 따지면 유체의 역학에 대해서 다루는 만큼 (위에서 언급했던)conservation of mass(질량보존)를 만족할 필요가 있습니다.
즉, incompressible flows(혹은 divergence-free motion)을 보장해야 합니다.
이를 위해서 저자들은 아래의 loss함수를 기반으로 하는 새로운 stream function을 제안합니다.
- 는 (CNN) network의 output으로, Stream function*의 역할
- 식 을 통해 (예측하는) velocity field의 divergence-free이 보장됨
- 2차원일 때 , 3차원일 때는
- 결과적으로, 네트워크의 output인 는 학습 데이터 샘플인 와 대응되는 stream function을 근사할 수 있게끔 학습
* Stream function은 Incompressible flows 환경에서 velocity field 를 간접적으로 기술하기 위해 정의된 함수입니다. Stream function이 무엇을 뜻하는지, 그리고 divergence-free를 보장하기 위해서 왜 "stream function의 curl()의 발산()이 0"이라는 명제가 만족되어야 하는지 등에 대한 내용은 아래의 위키를 참고하시길 바랍니다.
Stream function - Wikipedia
위와 같이 divergence-free 조건을 만족해야 한다는 것은, 물리학적으로 타당하다고 말할 수는 있어도, 실질적으로 (모델로 하여금) 더 좋은 결과를 뽑아낼 수 있는 지의 여부는 여러 검증을 거쳐 따질 필요가 있다고 생각합니다.
단, incompressible flows 외에 partially divergent motion이 존재하는 영역*을 다룰 때는 stream function을 이용해 velocity field를 구축하는 것보다 direct하게 velocity inference를 추론하는 것이 더 잘 작동합니다.
이 때는 위의 Loss함수 를 아래와 같이 변경할 수 있습니다.
이 때는 가 vector field를 그대로 근사하기 때문에 함수 의 output은 차원이 됩니다().
* partially divergent motion?
압력 등의 이유로 mass conservation(divergence free)가 만족하지 않는, 즉 유체 총량이 유지되지 않는 상황 정도로 생각하면 될 것 같습니다(Compressible flow).
단, 위의 속도장의 value에 대한 L1 distance만을 사용할 경우 노이즈가 발생하거나, vorticity, shearing, divergence 등의 second-order의 정보를 제대로 인코딩하지 못하는 문제가 발생합니다*. 그래서 속도장의 value 뿐만 아니라 gradient 또한 target vector field와 유사하게 만들어주기 위해** 추가적인 gradient loss도 추가해줍니다.
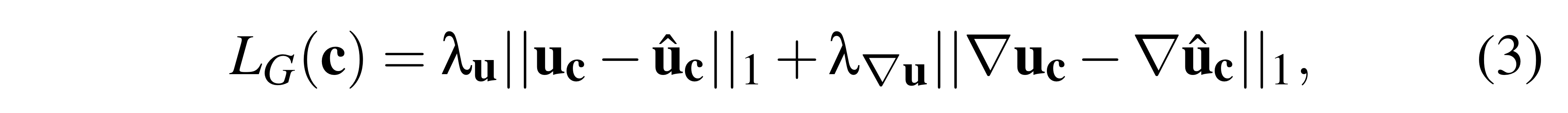
위의 는 위에서 기술한 것처럼 혹은 이며, velocity에 대한 가중치 와 velocity derivatives에 대한 가중치 는 모두 로 설정했다고 합니다.
*: 아래는 vorticity에 대한 식(second order)
자세한 정보는 논문 내 Supplements.
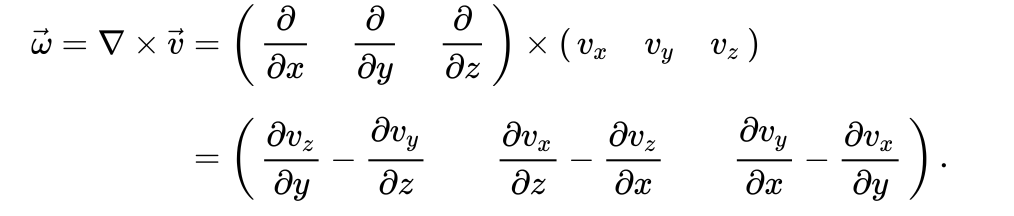
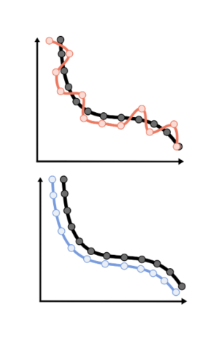
** :
(위 그림과 아래 그림의 L1 loss 값은 같지만, 기울기(gradient)도 맞춰진 아래가 조금 더 이상적인 형태)
Implementation
Deep Fluids의 구조에 대해서 살펴봅시다.
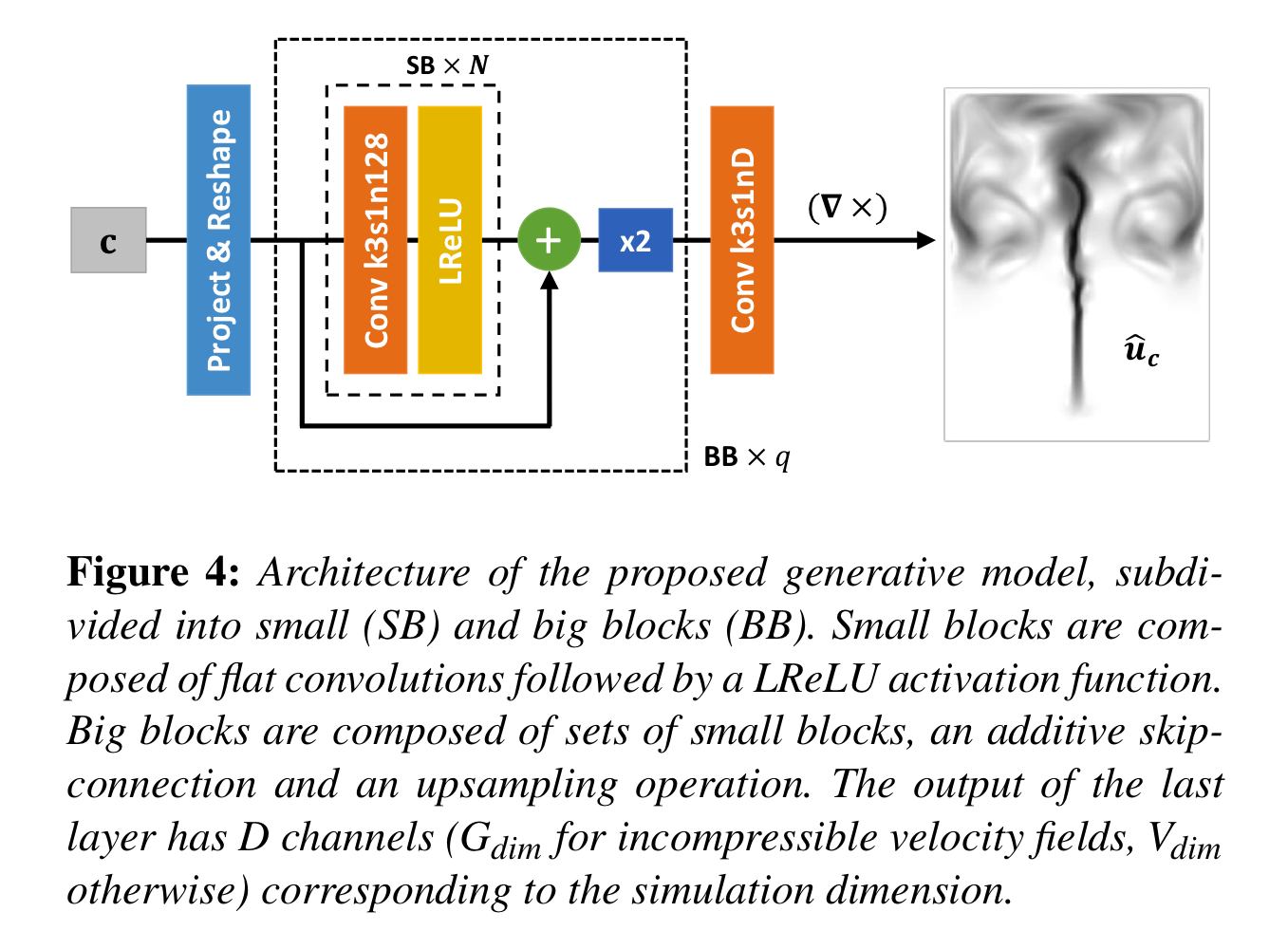
-
initial parameter 는 으로 (linear) projection
- 이 때 는 으로 정의되며, 한 차원에서는 최소한 길이가 8이 되어야 함을 뜻함.
- 을 만족해야 하므로 최소한 가 8이상.
- 후에 번의 upsampling()을 진행하기 때문에 각 차원이 배 증가해 의 결과물(velocity field)을 얻을 수 있음.
-
차원의 vector를 차원의 4차원 tensor로 reshape.
- 128은 feature map의 개수로, fixed parameter임
-
번의 [convolution + LReLU]를 진행해 (small block)을 구성.
-
에 대해 (128 feature map 차원을 따라) [skip connection --> upsampling]을 진행해 (big block)을 구성
-
3,4번 과정을 번 반복해 차원의 4차원 Tensor 생성
-
마지막으로 (incompressible flows의 경우) , (그 밖의 경우-direct velocity inference-) 의 차원으로 맞춰주는 Convolution을 진행
참고 : https://github.com/byungsook/deep-fluids/blob/master/model.py
1 : line 19
2 : line 21
3 : lines 25-27
4 : lines 35-37
5 : lines 24-40
6 : line 42
4. Extended Parameterizations
단순한 시뮬레이션에 대해서는 위에서 기술한 아키텍처()만으로도 충분할 수 있겠지만, 만일 (예를 들어)역동적으로 움직이는 smoke source를 시뮬레이션하는 경우 고정된 parameter 개수를 갖는 게 아닌, 로 표현되는 파라미터 형태를 지닙니다( : 시간에 따른 smoke source의 위치, : 구하고자 하는 속도장).

즉, 프레임 개수에 따라 선형적으로 파라미터 개수가 증가합니다.
이는 학습에 있어서 사실상 실행할 수 없을 정도의 과도한 cost를 요구하기 때문에 별도로 다루어질 필요가 있습니다.
위와 같이 형태, 즉 historical parameter로 표현하는 것 외에도 적당히 참고할 timestep의 개수를 제한하거나(), 아예 마코프 체인 형태로 구현함으로써 parameter space를 줄일 수 있지 않을까? 라는 생각은 들었지만, 시뮬레이션에 있어서 치명적인 문제가 생기니 이런 방식을 활용하지 못하는 거겠죠?
아무튼, 본 연구에서는 생성모델 외에도 인코더 아키텍처인 를 추가하고, 이를 time integration network와 결합함으로써 해결합니다.
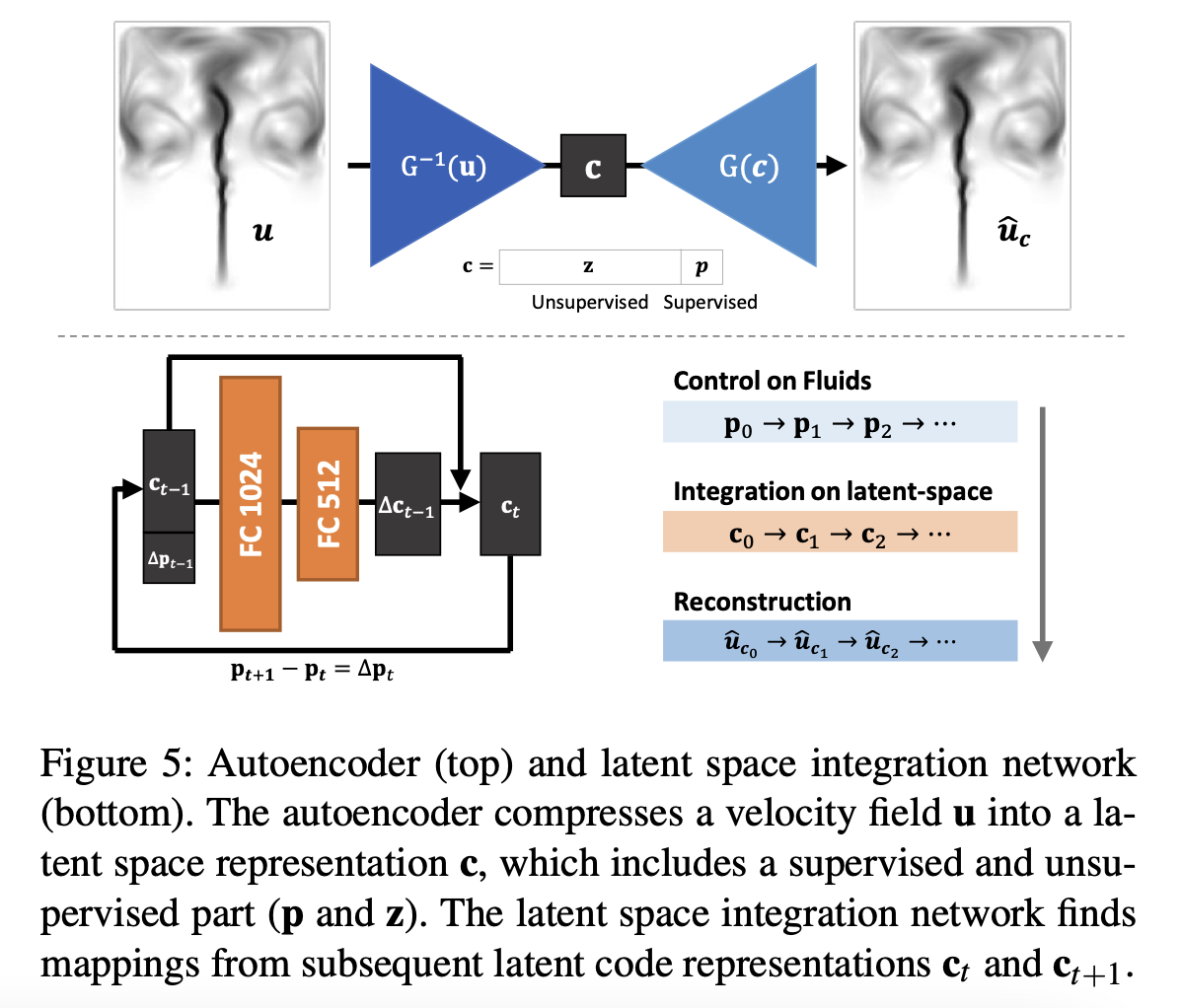
즉, 생성 아키텍처 와 반대로 기존의 속도장 를 parameterization 으로 압축하며, 이 때 는 모델이 비지도 방식으로 flow feature를 모델링하는 reduced latent space이며, 는 특정 attributes를 컨트롤하기 위한 지도 방식의 parameterization입니다.
이렇게 파라미터 를 와 로 분리함으로써, latent space를 줄일 수 있고(sparser), 속도장의 reconstruction의 성능에도 좋은 영향을 끼칠 수 있게 됩니다.
가령, 아래의 시뮬레이션의 경우 ,
위의 Encoder 는 Decoder 역할을 하는 생성모델 와 유사하지만, 마지막에 을 계산하는 부분과 Last convolution layer는 존재하지 않음.
위와 같이 추가적인 parameterization을 위해서 autoencoder 형태의 아키텍처를 구축한 다음, Encoder와 Decoder를 모두 학습하게 됩니다.

마지막 term인 는 supervised parameterization을 처리하기 위함이며, 나머지 는 (모델의 reconstruction 성능이 높아지는 방향으로) 학습이 됨에따라, 우리가 원하는 속도장(velocity field)의 정보를 잘 가지고 있는 latent space 를 파라미터로 활용할 수 있게 되고, time dimension을 직접적으로 인코딩하지 않기 때문에 frame에 따른 파라미터 증가 문제도 다룰 수 있게 됩니다.
time dimension을 직접적으로 인코딩하는 것 대신에 Figure 5의 아래에 나타난 latent space intergration network를 활용해 latent codes의 시퀀스를 적절히 생성해 사용하게 됩니다.
Latent space intergration network
Latent space intergration network는 시간에 따른 확산을 velocity field states 를 통해 학습하게 됩니다.
에서 는 user input parameter이므로.
그러면, time step 에서의 를 다음 step의 로 전파하기 위해 어떤 방법을 활용해야 할까요?
저자들은 (우리가 이미 알고 있는) 를 활용함으로써 을 얻고, 를 활용해 우리의 최종 목표인 를 reconstruct하게 됩니다.
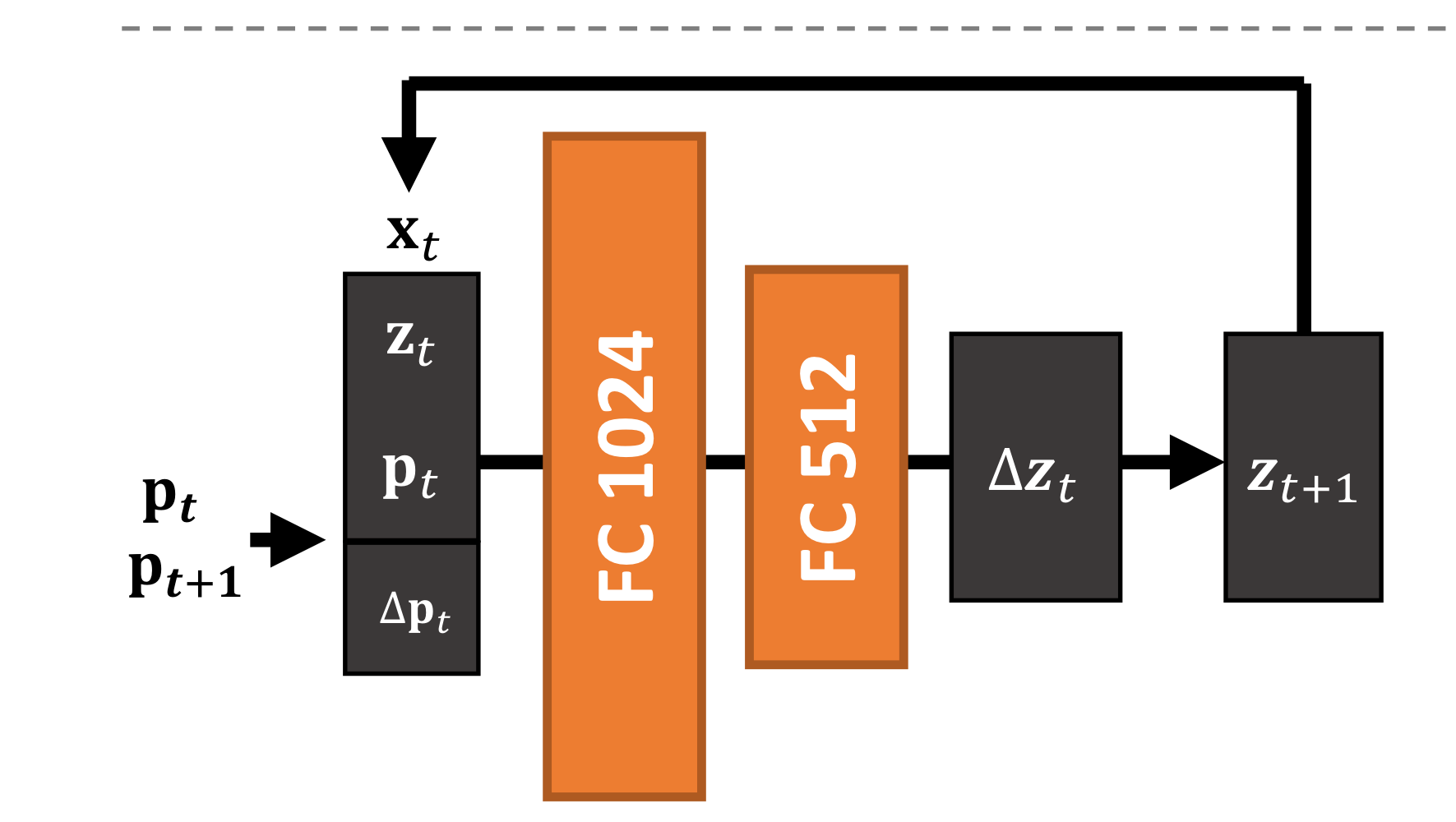
더 구체적으로 기술하기 위해 아래와 같이 notation을 정의합시다.
이 때, 를 input으로 하고 를 output으로 하는 아키텍처 를 학습하게 됩니다.
이로부터 를 얻은 후, 최종적으로 다음 타임스텝의 파라미터인 를 얻게 됩니다.
이렇게 얻은 는 생성 모델 를 활용해 최종적으로 우리의 목표인 속도장 를 생성하는 데 쓰이게 됩니다.
해당 흐름을 정리하면 아래 그림과 같으며,

알고리즘으로 나타내면 아래와 같습니다.

최초의 parameter 은 위에서 기술한 encoder 아키텍처인 를 활용해 얻습니다.
추가적으로 정확도를 향상시키기 위해 위의 통합 아키텍처 는 미래의 timestep을 보게끔해, size의 sequential latent codes를 통해 모델을 학습하게 됩니다(best : ).
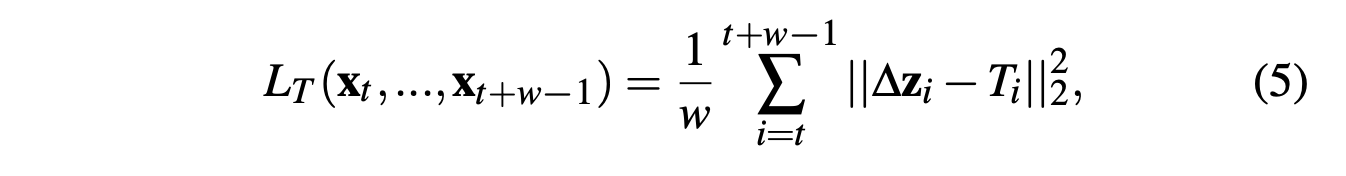
우변이 개의 항을 가지며, 는 timestep 에서 까지 recursive하게 계산한 항.
위의 과정을 통해 당장 다음 step의 정확도 뿐만 아니라 sequential하게 latent space update를 진행함에 따라 생기는 누적 에러를 줄이는 데 도움이 됩니다.
사실 위 식 (5)은 정확히 와닿지 않습니다.
논문 내에 라고 적혀있는데 를 최소화한다는 게 어떻게 가능한지, 는 라벨이 없기 때문에 비지도방식으로 학습하는데 어떻게 위의 식(5)처럼 미래의 latent space 를 얻는지 등의 의문때문에요.
다만, 해당 단락의 integration network 외에도 encoder network를 동시에 학습한다는 점, 그리고 이 encoder network는 (비록 가 아닌 input parameter 만을 사용해 지도학습을 하지만) 결국 output으로 가 포함된 를 반환한다는 점 등을 통해 식 (5)의 는 encoder network 를 통해 얻은 latent vector로 보여집니다.
(는 미래, 과거 상관 없이 우리가 가지고 있는 라벨이기 때문에 미래의 를 얻을 수 있습니다.)
결론적으로, parameter 를 통해 지도학습하는 encoder 네트워크를 통해 얻은 미래의 sequential한 를 마치 pseudo target처럼 활용하는 것으로 보입니다만, 정확하지는 않습니다.
위 문제에 대해 약간의 통찰을 얻을 수 있는 부분이 Supplementary Material 내에 있습니다.
(latent space 의 차원 증감에 따라 auto encoder network와 intergration network의 성능이 반비례하는 모습)
5. Results
비디오부터 보고 갑시다.
위에서 볼 수 있다시피, Deep Fluids CNN은 연기(smoke)와 액체(liquids)에 대한 dynamic flow fields를 생성할 수 있는 모델입니다. 즉, 연기 시뮬레이션이나 액체(표면)의 시뮬레이션을 위해서 속도장을 생성하거나, advect(이류) densities를 진행하게 됩니다. CNN 네트워크로 reconstructiond를 진행한 후에 와도(vorticity)나 난류(turbulence)를 적용할 수는 있지만 해당 논문에서는 하지 않았다고 합니다.
실행 디테일은 아래와 같습니다.
- Data : 5 samples with varying width, 21 samples with varying positions
- iteration : 300k
- time network 의 경우 30k
- batch size : 8 for 2-D, 1 for 3-D
- learning-rate scheduler : cosigne annealing decay
- Fluid scenes : Mantaflow를 활용해 연산
- GPU : 12GB Titan X 등
2-D Smoke Plumes
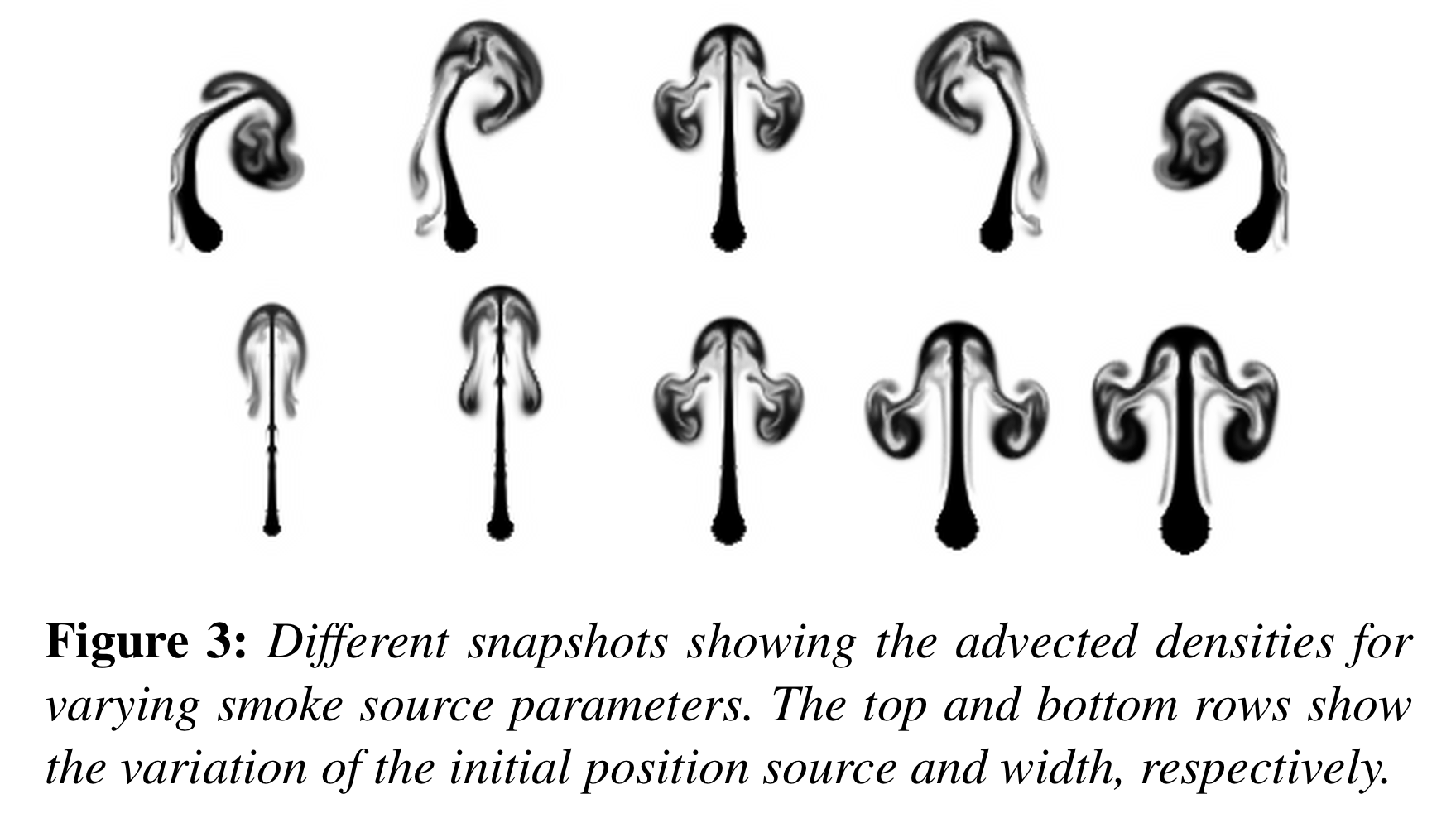
위의 그림은 최초 위치와 너비를 달리함으로써 솟아오르는 연기 기둥의 그림을 보여줍니다(advecting densities). 단, advect smoke를 직접적으로 시각화하게 된다면 연기의 flow structure를 제대로 파악하지 못할 수 있기 때문에 대신 vorticities를 시각화 했으며, 이는 저자들의 CNN 아키텍처가 어떻게 데이터셋의 샘플을 reconstruct하는지, 그리고 어떻게 샘플간 interpolation을 진행하는지 이해하기 쉽게 만들어줍니다.
Reconstruction with Direct Correspondences to the Data Set
본 단락에서는 해당 모델이 현존하는 데이터 샘플(즉, ground truth)을 얼마나 잘 reconstruct하는지를 보여줍니다. 아래의 Fig. 6은 (original dataset과 direct correspondence를 보이는*) 특정 parameter를 사용하여 속도장을 생성한 결과를 보여줍니다(for 2 frame).
즉, 모델은 smoke source의 위치가 인 데이터 샘플을 학습한적 있습니다.

역시 더 나은 이해(직관)를 위해 vorticity plot
을 사용했으며, 색(파랑, 빨강)으로 기류의 회전 방향*을, 그리고 색의 진한 정도가 그 강도**를 나타내겠죠.
위의 그림에서 볼 수 있다시피 실제 데이터인 G.t.와 생성한 데이터인 CNN이 거의 유사한 것을 볼 수 있습니다.
Sampling at Interpolated Parameters
위의 그림 Fig. 6은 분명 모델이 training dataset을 잘 학습했음을 보여주긴 합니다. 하지만 학습 데이터에 존재했던 parameter를 사용해서 결과를 재구성하는 것이 절대적인 모델 성능의 척도가 될 수는 없겠죠.
아래의 그림 Fig. 7은 저자 모델의 Interpolation 능력을 보여주는데요, 이를 통해 training data와 직접적으로 일치하지 않는 parameter임에도 불구하고 꽤나 준수한 생성 능력을 가지는 것을 볼 수 있습니다.
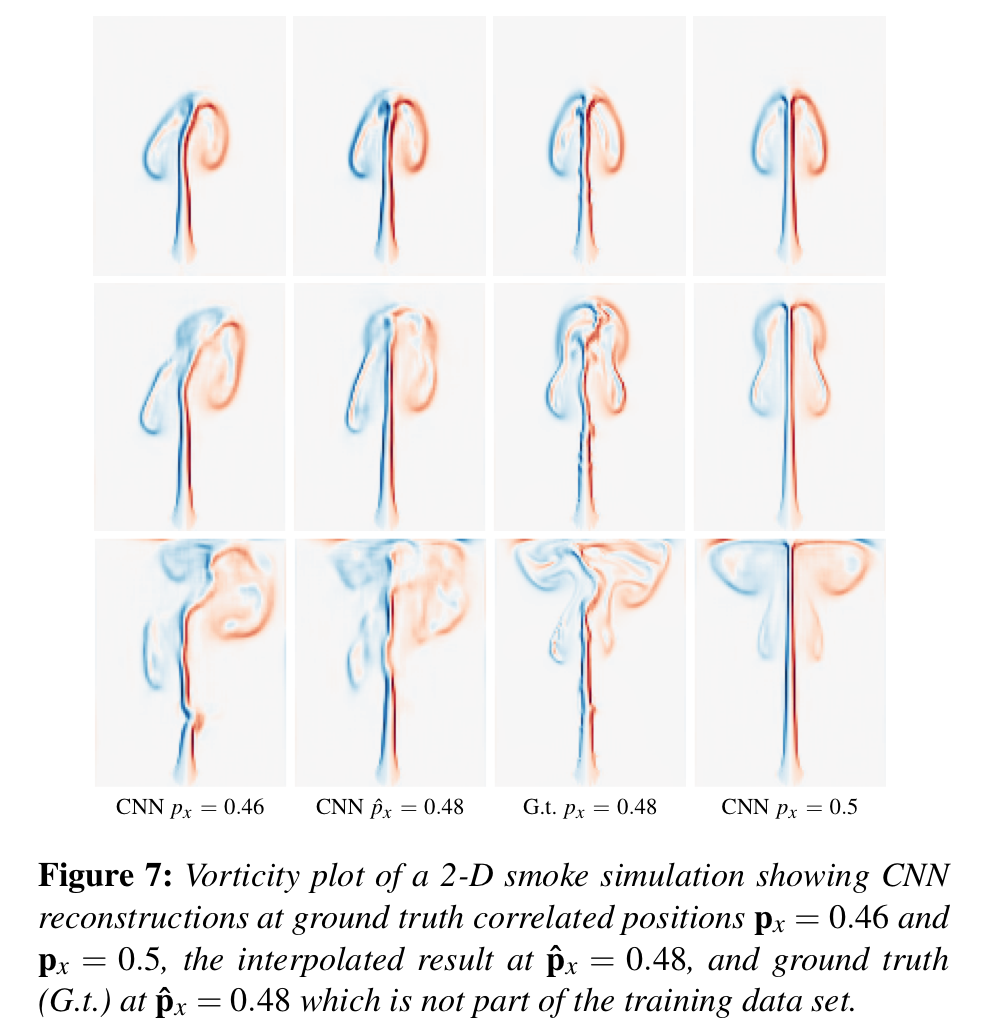
위의 그림에서 의 hat(^) 기호는 training dataset 내 ground truth의 parameter와 직접적으로 일치하지 않는 parameter(with no direct correspondence), 즉 학습한 적 없는 파라미터를 뜻합니다.
예를 들어 위 그림처럼 학습 데이터에는 smoke source의 -position이 , 만 존재한다고 가정합시다. 이 때 을 갖는 샘플은 학습 데이터에 존재하지 않았음에도 (딥러닝 모델은 애초에 모든 연속적인 파라미터를 input으로 넣어줄 수 있기 때문에) 의 조건 하에 생성된 velocity field도 생성할 수 있게 됩니다.
다만 딥러닝 모델이 training dataset에 내재된 유체의 representation 매커니즘을 제대로 학습하지 못했다면 생성 결과가 좋지는 못하겠죠. 이와 같이 모델의 실질적인 효용을 증명하기 위해 test set의 Ground truth와의 결과를 비교한 것이 Fig. 7의 그림입니다.
아무튼, original data에 없는 source position에 대해서도 test data에 있는 ground truth sample과 꽤나 가까운 새로운 모션을 생성해내는 것을 볼 수 있습니다.
3-D Smoke Examples
Smoke & Sphere Obstacle
Dataset
- Parameter : 구의 중심 위치() 10가지
- 각 샘플 당 프레임 : 660 frame
- 총 velocity sample : 6600
- 샘플 당 사이즈 :

해당 데이터셋은 구의 중심 위치 에 따라 10개의 샘플을 가집니다.
위의 그림 Fig. 8에서 볼 수 있다시피 (학습한 parameter들인) (1번째 열), (4번째 열)는 현상이 꽤나 다름에도 불구하고, 그 사이에 있는 (학습한 적 없는 parameter인) (2번째 열)을 사용한 생성 결과가 Ground Truth(3번째 열)과 꽤나 유사합니다.
데이터 자체가 10개로 굉장히 sparse함에도 불구하고 모델이 해당 시뮬레이션의 semantic representation을 잘 학습했다고 볼 수 있습니다.
나머지 3D-Smoke 시뮬레이션들과 3D-Liquid 시뮬레이션들도 같은 방식으로 기술되어 있습니다.
본 글에서는 단순히 그림만 첨부하고, 참고할 만한 특이사항이 있을 때만 글로 기술하도록 하겠습니다.
Smoke Inflow and Buoyancy

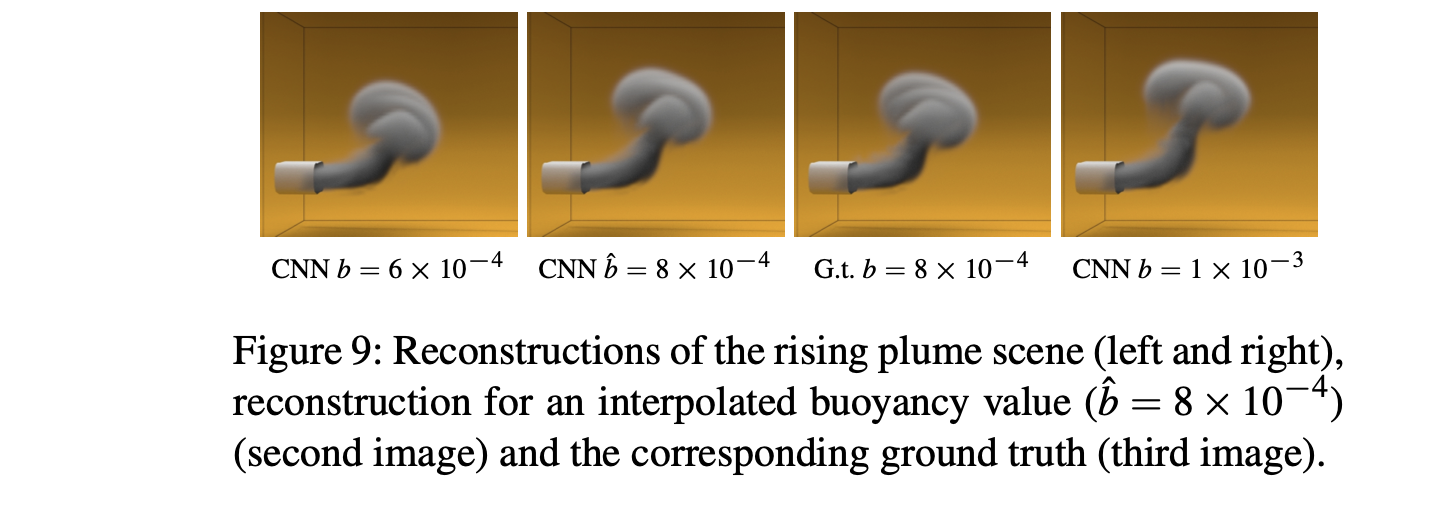
Rotating Smoke

- (smoke source가 100frame을 주기로 회전하는) 500 frame data만을 활용해 학습
- interpolation이 아닌 extrapolation을 진행해 기존 데이터보다 2배 더 긴 시뮬레이션을 수행할 수 있었음.
- 기존의 500frame 이후에도 100 frame마다 회전하는 연기 기둥을 잘 표현함(+20% : 600frame, +60% : 800frame, +100% : 1000frame)
Moving Smoke
- smoke source가 Perlin noise를 따라 랜덤하게 을 이동.
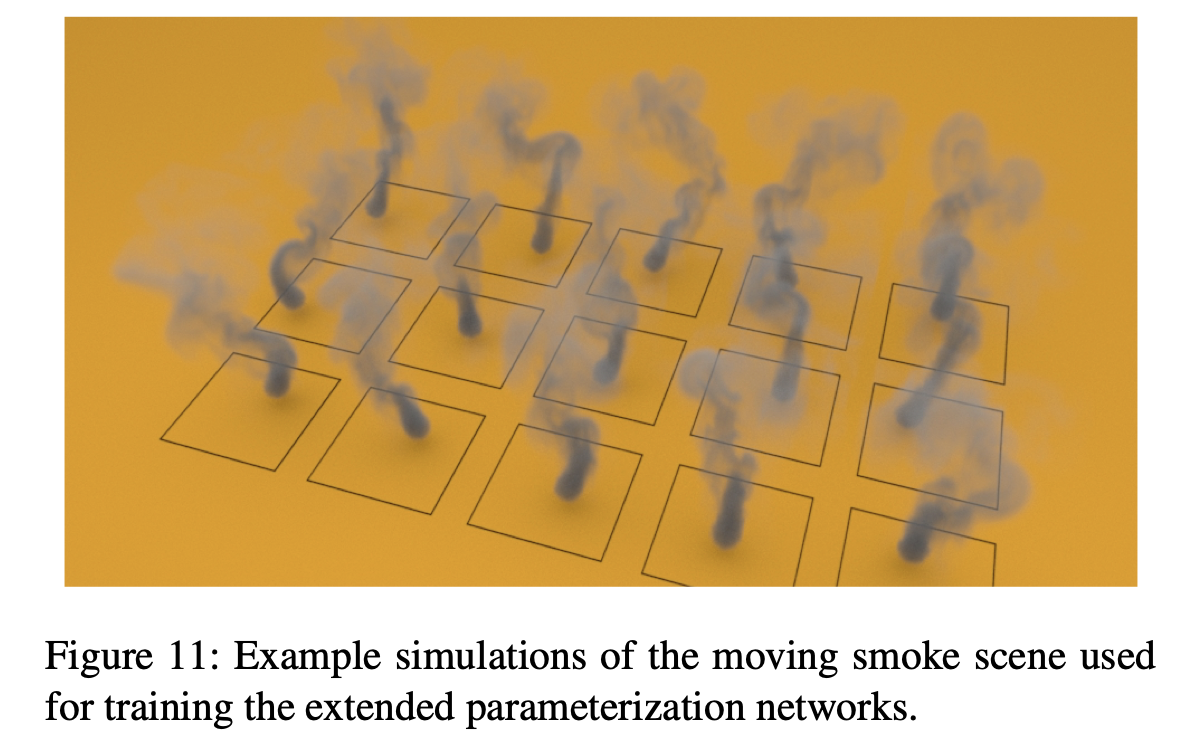
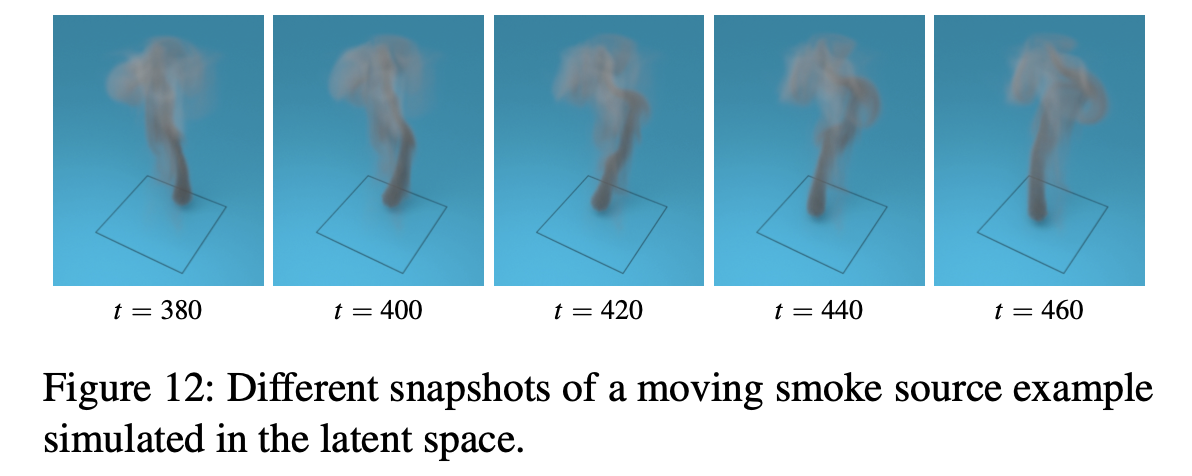
- 마찬가지로 모델이 학습하지 않은 움직임(path)에 대한 시뮬레이션도 기존의 400frame보다 2배가량 긴 800frame동안 부드럽게 잘 구현할 수 있었음.
3-D Liquid Examples
Spheres Dropping on a Basin
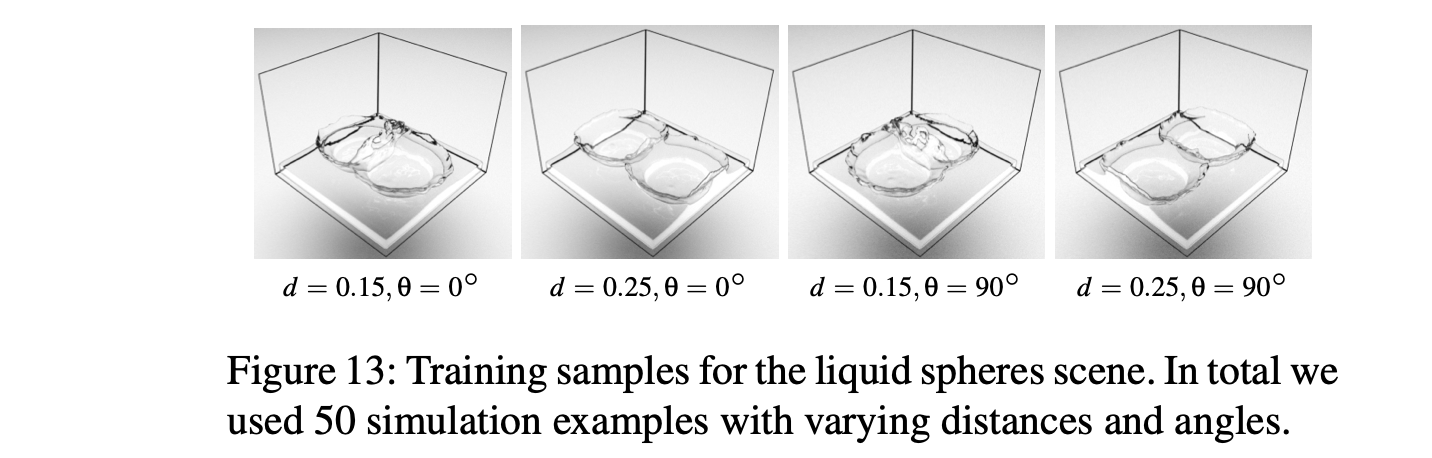
- 2개의 구 사이의 거리와 평면에 대한 각도에 따른 4개의 예시

- 두 Input 사이의 Interpolation
- 액체 역학에서의 양(bulk)은 잘 보존되지만, high-frequency structure나 splash같은 디테일 구현에는 꽤나 취약한 모습을 보인다.
Viscous(점성이 있는) Dam Break

-
점성이 있는 액체에 대한 시뮬레이션도 잘 구현되는 모습
-
green : 학습한 parameter (reconstruction), red : 학습하지 않은 parameter (interpolation)
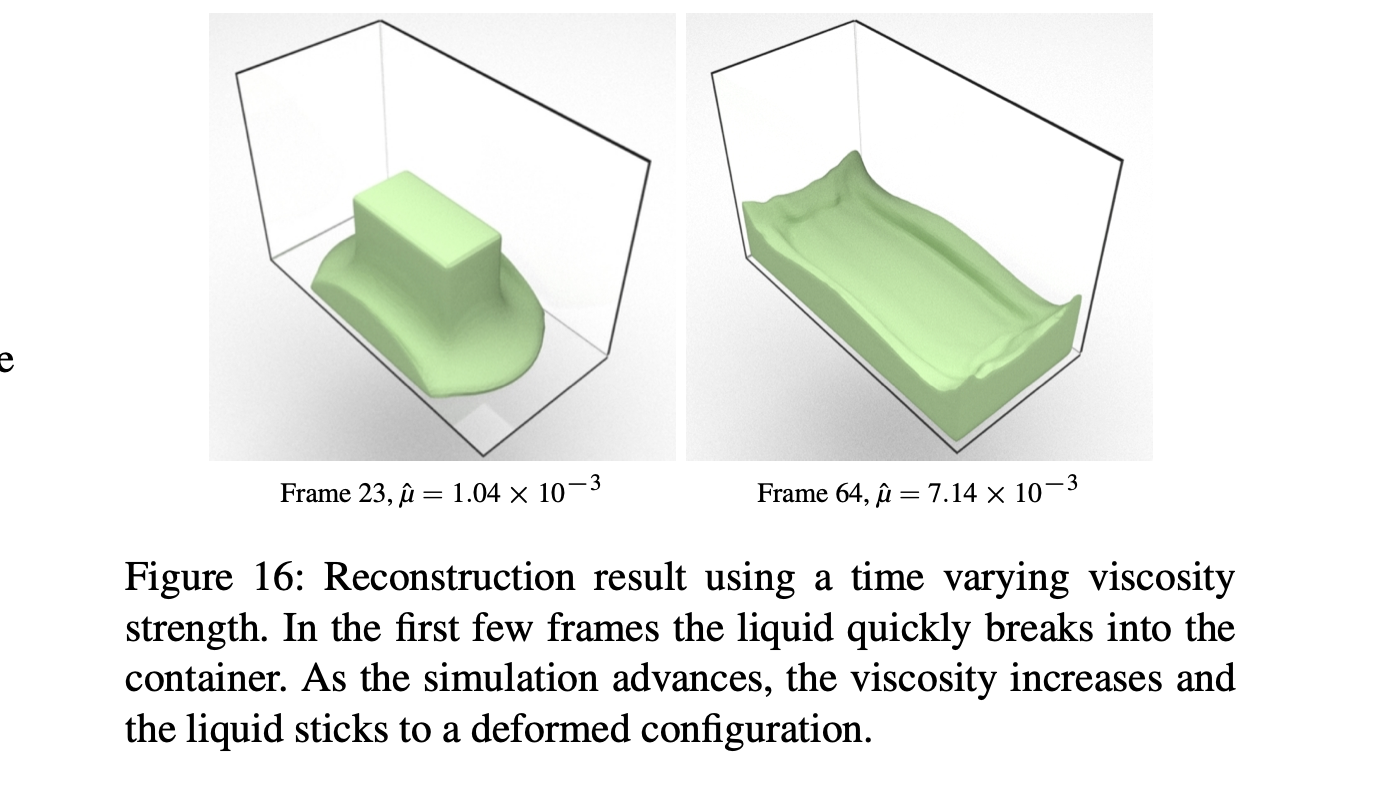
- 심지어, 학습 데이터에는 있지도 않은 parameterization(구체적으로, 시간에 따라 점성이 변하는 파라미터)도 잘 구현하는 모습.
- (데이터 샘플도 존재하지 않음)
Slow Motion Fluids

Capture in Youtube
- 위에 첨부한 비디오에 liquid drop과 dam break 예시에 대한 슬로우 모션 태스크가 첨부되어 있음.
- 저자들이 제안한 생성모델은 interpolation을 극단적으로 사용함으로써 일종의 슬로우 모션 시뮬레이션도 구현할 수 있는 높은 활용력을 보임
6. Evaluation and Discussion
본 단락에서는 실험 환경 및 테크닉, 정성평가, 학습 추이 등의 내용을 담고 있습니다.
Training
-
maximum absolute value를 나누는 식으로 정규화된 의 데이터를 사용
-
모두 안정적으로 잘 학습됨.
-
학습 시간은 task마다 다르지만, 3-D liquid 같은 task의 경우 고 퀄리티의 surface를 얻기 위해 학습을 약간 더 많이 했어어야 했음(smoke에 비해)
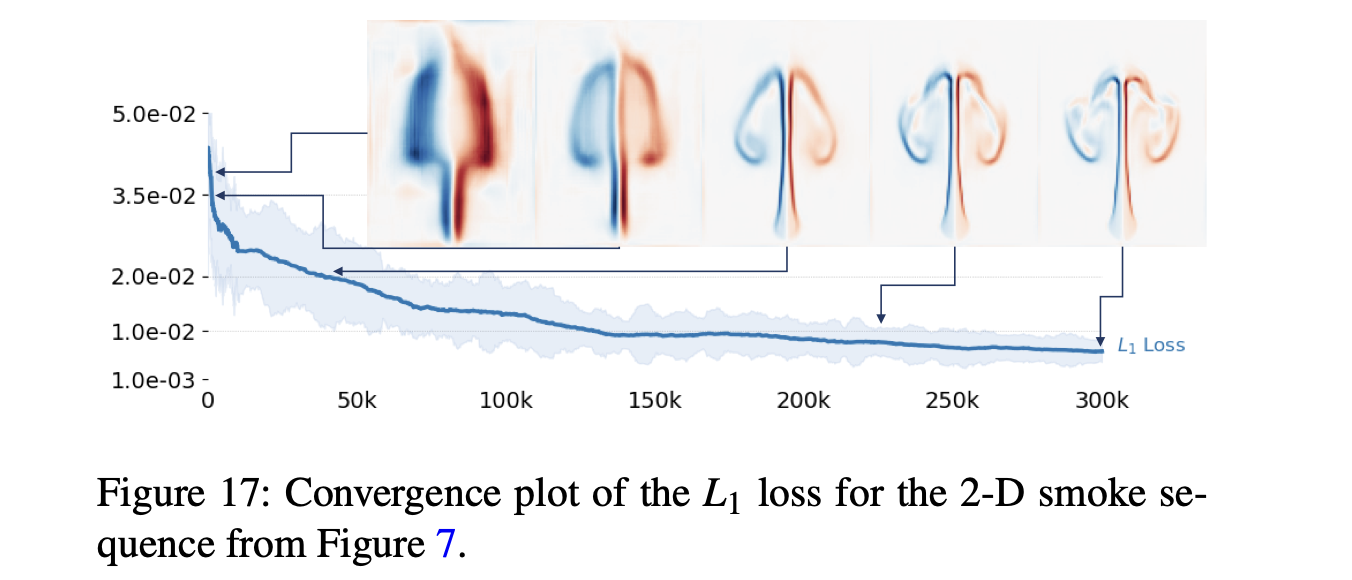
- 위의 그림(Fig. 17)은 학습 추이에 따른 2-D smoke example의 생성 결과를 보여줌.
- 3시간 가량의 학습에 해당되는 180k iteration부터 연기 기둥을 잘 reconstruct하는 모습을 보임.
- 학습 시간은 해상도에 비례(while keeping the mae at a constant level(?)).
Performance Analysis
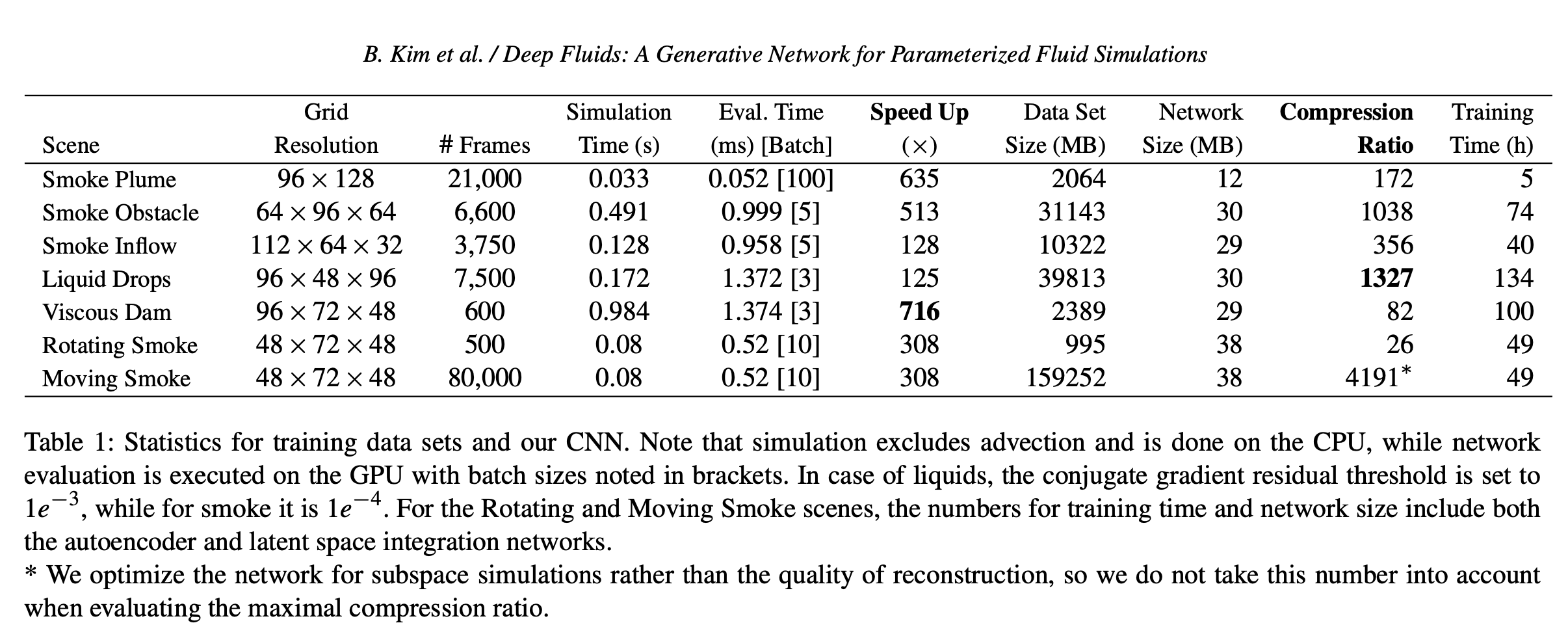
- 기존의 CPU solver보다 최대 700배 가량 빠르게 velocity field를 생성
- 물론 애초에 GPU를 사용했기 때문에 단순하게 성능을 비교할 수는 없음
- 단, 유체 시뮬레이션은 일반적으로 memory bandwidth-limited*됐다고 알려져 있음.
- CPU와 GPU의 bandwidth(대역폭)차이를 보수적으로 고려했을 때에도, 여전히 저자들이 제안하는 핵심 알고리즘은 58배 가량 빠른 모습을 보임
* Memory bandwidth limit
메모리의 단순 지연 시간(latency) 때문에 실행 속도가 느린 게 아니라, 메모리의 대역폭(bandwidth)의 한계 때문에 실행 속도가 느려지는 경우.
참고 : Main memory bandwidth
Traditionaln solver와의 비교
-
1. GPU batch를 활용해 한 번에 여러 개의 CNN queries 를 사용할 수 있다(즉, 한 번에 multiple frames을 생성할 수 있다).
- Table 1의 Eval. Time column 내에 있는 [Batch]
- 당연히 각 태스크마다 다르며, 네트워크의 사이즈와 GPU 메모리 등에 따라 결정됨.
- 다만, 하나의 파라미터(하나의 시뮬레이션)에 대한 생성을 동시에 할 수 있다는 것은 아닐듯(batch size가 5라고 1-5frame을 동시에 생성할 수는 없음)
- Time integration network가 존재하므로.
- 그리고 (아마 학습 시에는 다르겠지만) Evaluation 단계에서는 실행 시간이 네트워크의 사이즈나 배치 사이즈와는 독립적이기 때문에 배치 사이즈가 커져도 상관은 없음.
-
2. 학습 자체가 iteative한 방식으로 진행되기 때문에 활용하기 용이함.
- 가령, 전통적인 SVD 기반 subspace 알고리즘을 사용할 경우 20~30시간이 걸리는데, 컴퓨터가 중간에 멈춘다면 싹 다 날라갈 수도 있음.
- 딥러닝과 다르게 최적의 singular vector를 찾는 방식으로 연산이 진행됨.
- 가령, 전통적인 SVD 기반 subspace 알고리즘을 사용할 경우 20~30시간이 걸리는데, 컴퓨터가 중간에 멈춘다면 싹 다 날라갈 수도 있음.
-
3. input data를 1300배 가량 압축할 수 있음.
- 기존의 subspace 방식은 14배 가량의 압축률을 보이기 때문에 거의 two orders of magnitude 가량의 성능 향상을 보일 정도로 SoTA.
- 저자들의 방식은 30MB만을 소모함(data는 40GB 정도).
- 아키텍처 실행에 필요로 하는 메모리는 별개로 생각.
Quality of Reconstruction and Interpolation
Training Data
딥러닝 기반 방식인만큼 학습에 사용되는 데이터에 따라 최종적인 성능이 결정됩니다. 가령, input의 sampling density(주사율)가 낮거나, parameter에 따라서 output이 급격하게 변화할 경우 interpolation의 성능이 떨어지게 됩니다.
즉, detail한 flow structure를 구현하는데 문제가 생기거나, 장애물 근처에 artifact(인공물)이 생기거나, 특히 아래와 같이 ghosting effect를 보일 수 있습니다.
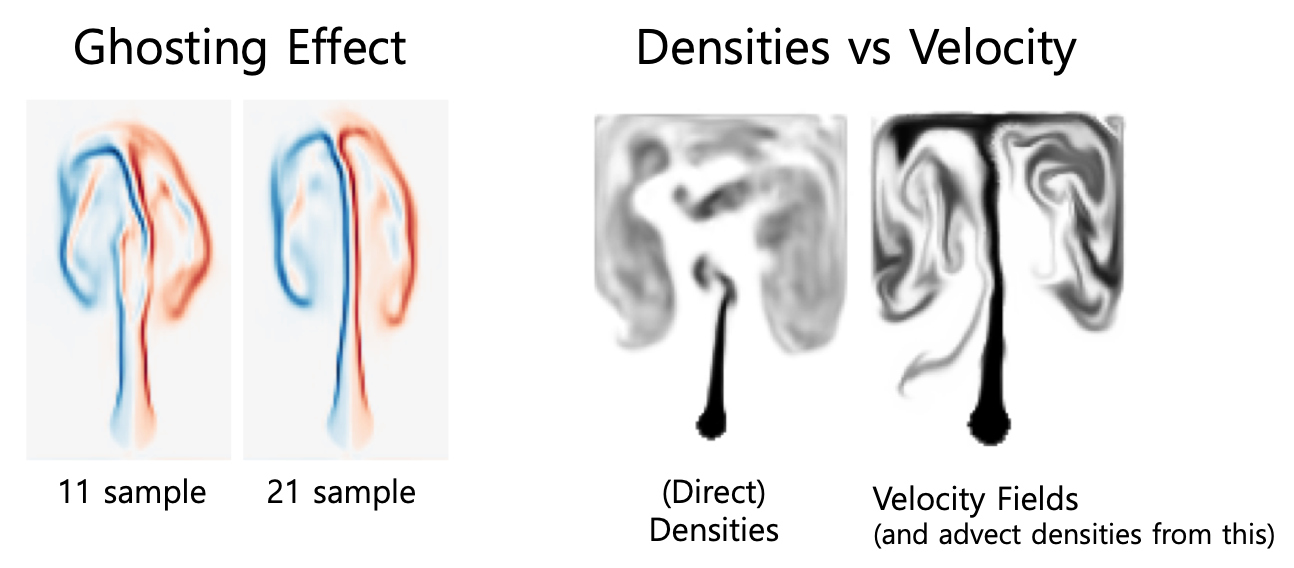
왼쪽이 11개의 training sample, 오른쪽이 21개의 training sample을 사용한 경우, 왼쪽 사진에만 ghosting effect가 발생했다고 합니다.. 만은, 정확히 무슨 현상인지는 모르겠어요..
Target Quantities
또한 위 사진의 우측은 학습을 할 때 직접적으로 밀도(Densities)를 추정한 경우와 (저자들의 방식처럼), velocity fields를 추정하고 이를 이용해Advecting density를 수행하는 것과 비교한 모습을 보여줍니다.
Velocity field(위치 + 속도)가 담은 정보가 Direct dencity(위치 + 값)이 담은 정보보다 많아서 질량 보존 법칙의 non-linear 특성을 잘 담을 수 있었던 것으로 보이는데, 자세한 내용은 Supplemental material에 있다고 합니다.
Velocity Loss
저자들은 Incompressible flow(conservation of mass)를 가정할 때와 Compressible flow를 가정할 때 각각 loss를 할당했었는데, 이에 대한 비교를 진행했습니다.

즉, conservation of mass를 만족하는 incompressible loss를 활용했을 때 어느 정도 성능의 향상이 있었다.
Boundary Conditions
저자들이 제안하는 모델은 별도의 수정 없이 boundary condition(유체에 대한 경계 조건)을 고려하거나 immersed obstacles(장애물)을 고려할 수 있습니다(3-D Smoke에서 다뤘던 것처럼).
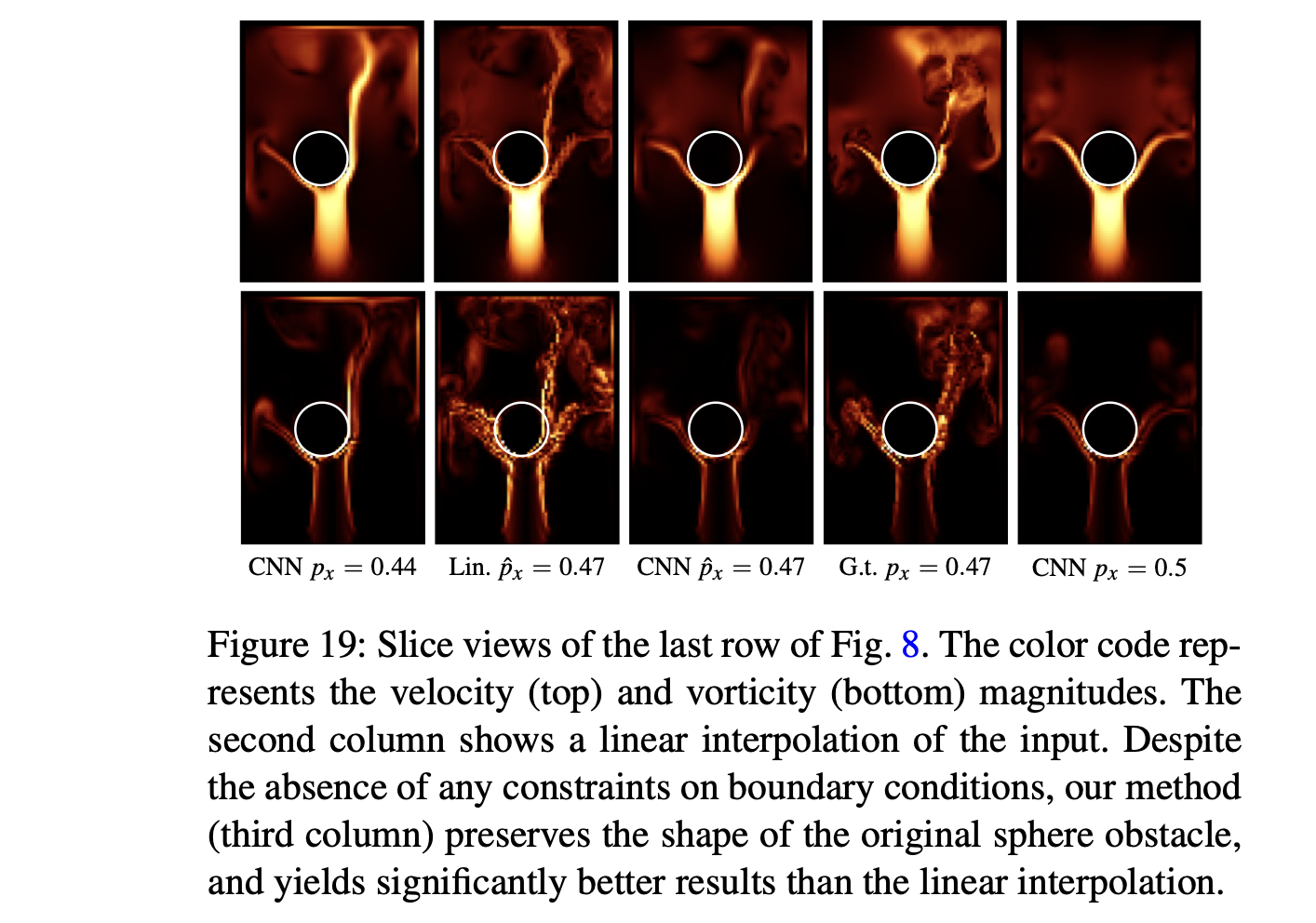
위의 그림은 기존의 Linear basis 기반 방법을 사용한 모습(column 2)와 저자의 CNN 기반 방법을 사용한 모습(column 3)을 비교한 그림으로, Linear 기반 방법은 구체 안에 유체의 velocity가 겹쳐서 나타나는 ghosting effect가 생기는 것을 볼 수 있습니다. 반면에 저자들의 방법은 이런 문제가 없는 것을 볼 수 있습니다.
다만, 해당 모델링 과정에서 구체의 모양에 대한 명시적인 제약(constraint)조건이 없었기 때문에, 위와 같은 penetration(침투) 현상이 아예 발생하지 않는 것은 아닙니다.
다만 어느 정도는 성공적으로 non-penetration boundary condition을 처리한 것으로 보입니다.
Liquid-air Interface
저자들의 CNN 모델은 따지고 보면 velocity field만 예측할 뿐, FLIP simulation을 구현하기 위해서는 별도의 advection 연산을 수행해야 합니다. 단, 이 과정에서 (유체 현상은 워낙 민감하기 때문에) 약간의 velocity field 차이가 유체의 표면까지 advect(이류)시킬 수 있습니다(surface hang in mid-air).
이런 문제는 특정 threshold(역치)보다 낮은 velocity를 갖는 경우를 아예 제거해서, particle artifact를 어느 정도 제거할 수 있었다고 합니다.
Extrapolation and Limitations
Extrapolation wiht Generative Model
학습한 Deep Fluids 모델은 기존의 학습 데이터에 존재하는 parameter의 범위() 밖의 값도 input parameter로 넣어줄 수 있습니다. 다만 학습하지 않은 만큼 과도하게 차이나면 (애초에 모델은 본 적 없는 현상이므로) 생성 성능이 좋지는 않겠죠. 저자들은 기존의 parameter range를 10% 가량 벗어날 때까지는 비교적 plausible한 결과를 보였다고 합니다.
아래의 그림은 (수직 순서대로) source의 위치(position), inflow 속도, 그리고 시간(time)를 기존의 범위보다 늘린 경우(즉 extrapolation) 생성 결과를 보여줍니다.
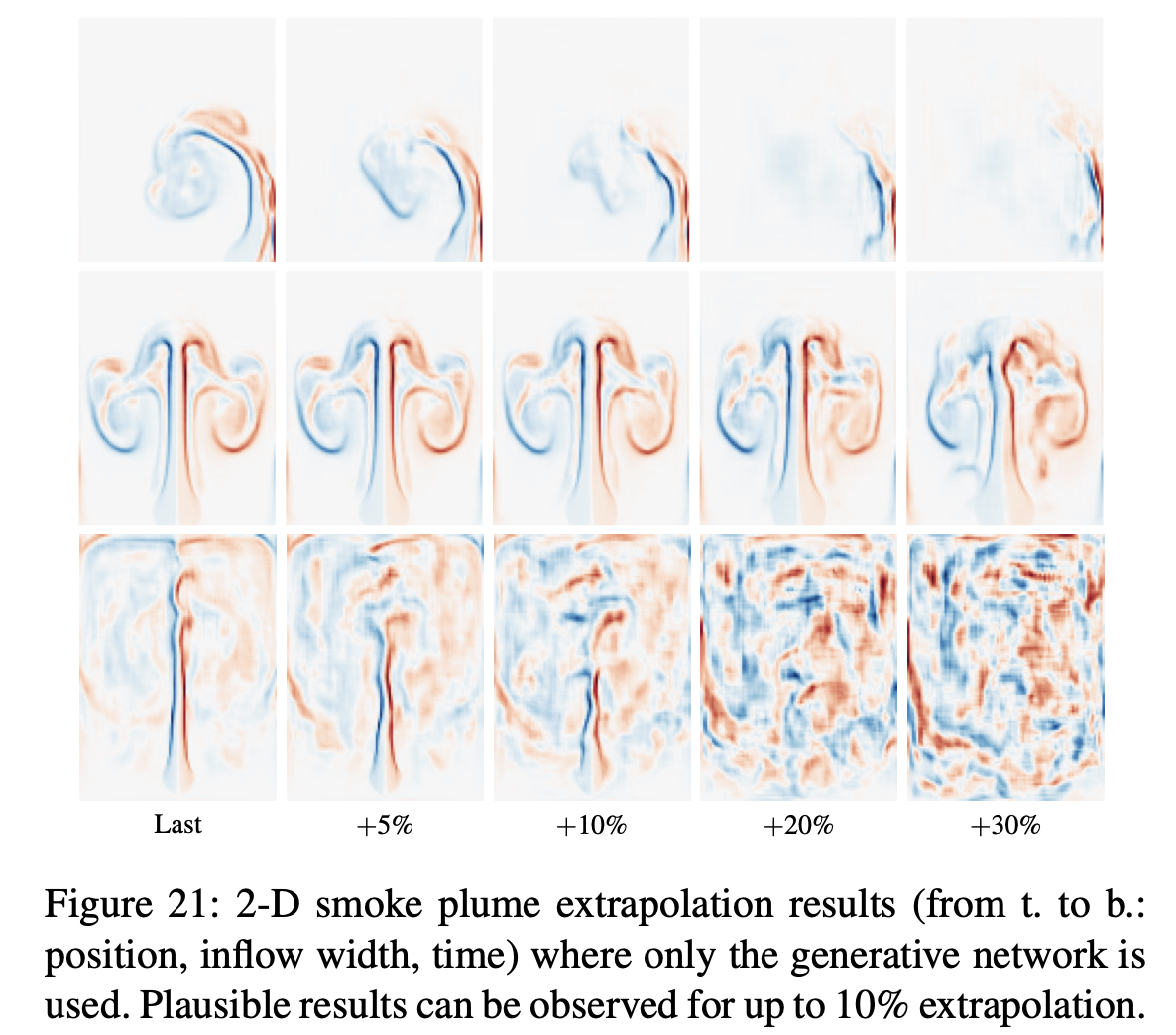
10%까지는 괜찮은데, 20%부터는 성능이 저하되는 모습.
Limitations
모델의 한계 또한 위의 단락들에서 볼 수 있는데요, 간단히 정리하면 아래와 같습니다.
- 굉장히 다양한 상황들에 대한 (임의의)velocity field를 reconstruction하는 데에 한계가 있다.
- 특정 boundary condition에 대한 physical constraints가 존재하지 않는다.
- 즉, 학습한 데이터와 유사한 상황에서만 interpolation, reconstruction 등이 잘 수행될 수 있다.
- 뿐만 아니라 학습과 reconstruction 결과에 있어서 latent space 가 큰 영향을 끼치지만, (방정식 5에 나타나듯) gradient loss가 존재하지 않기 때문에 일시적인 학습 불안정(jitering) 현상을 겪을 수 있다.
역시 추가적인 내용은 Supplementary materials을 참고하세요.
