[논문리뷰] Explainable Artificial Intelligence (XAI): An Engineering Perspective
XAI / Object Detection
※ 실제 논문과 단락 순서는 다를 수 있습니다.
0. Abstract
여전히, DL(Deep Learning) 분야에서 설명력과 투명성을 제공하는 것은 법률 규제자, 소비자, 서비스 제공자 등에게 중요한 상황이다.
본 논문에서는, XAI의 컨셉을 다루기 위해 ‘engineering’ apporach를 취할 예정이다. XAI 분야에서 이해관계자들에 대해 얘기하고, 엔지니어링적 관점에서 XAI의 수학적인 윤곽을 보일 것이다. 그 후, 자율주행 차량을 실생활 케이스로 여겨 object detection, perception, control, action decision 등의 다양한 요소를 위한 XAI의 적용을 다룰 것이다.
1. XAI Systems And Techniques
본 글에서는 다양한 머신러닝 모델에 대한 설명을 제공한다. 하지만, 단지 “예측이 어떻게 이루어지는가?”에 대한 설명은 결과를 정당화하기 위해 충분하진 않다. 이런 white box 모델은 수많은 모델의 복잡성 때문에 실용적이지 않으며, 정량적이기에 자연 세계에서 직관적이지도 못하다. 따라서, 전문가가 아닌 단순한 사용자(user)는 이해하기 힘들 수 있다. 따라서 이해가능한 설명 또한 제공될 필요가 있다.
A. Transparent Models
이 모델들은 주로 interpretable model로 알려져 있으며, 설계에 의해 설명 가능하다.
- 특정 모델의 투명성에 관한 첫번째 단계는 ‘algorithmic transparency’이다. 선형모델은 이해하기 쉬우며, 비선형 모델은 조금 더 정교한 모델이 필요하다.
- 두번째 단계는, 모델의 분해가능성(decomposability)에 관한 단계이다. 이는, 모델 내 각 부분의 설명이 얼마나 intelligent한가다.
(Furthermore, Concolusion 생략)
B. Prediction Interpretation and Justification Models
블랙박스 모델은 계획 상 설명가능하지 않기에, post-hoc 설명을 필요로 한다(혹은 gray, white box model을 구축하든지). 이는 text를 통해서, visual을 통해서, simplification을 통해서, example을 통해서, 그리고 feature relevance를 통해서 이루어질 수 있다.
넓게 말하자면, 그런 post-hoc 설명은 저자에 의해 채택된 테크닉에, 그리고 그 테크닉들이 실제로 적용되고 사용되는 data의 type에 의존한다. 즉, 단순 image를 사용하는 태스크인지, multiple object에 대해 annotations(text, bounding box, etc.)이 달려 있는 image를 사용하는 태스크인지, 자연어 처리에 관한 태스크인지 등에 따라서 설명이 달라질 수 있다.
예를 들면, 저자(해석자)는 image에 대해 simplification을 통한 설명을 사용하고, 민감성 분석을 수행할 수 있다. 특정 연구(본문 내 출처 있음)에서, 저자는 블랙박스 모델의 다양한 타입들을 다루고, user에 의해 유도된 transparency를 근간으로 넓은 경계를 제안한다. 저자는 시스템을 아래의 세가지 타입으로 나눈다.
- Opaque
- Interpretable
- Comprehensible
Opaque 시스템에서는, input과 output의 매핑은 user에게 보이지 않으며, 반면에 Interpretable 시스템에서는, input과 output의 매핑을 인지하고, 수학적으로 분석할 수 있게 된다. 마지막으로, comprehensible 시스템에서는 input과 output의 매핑을 이해할 수 있을 뿐만 아니라, 그 뒤에 잇는 특정한 규칙 또한 이해할 수 있다. 요약하면, comprehensible system은 user에 의해 완전히 이해할 수 있는 방법으로, AI 시스템의 특정한 output을 반환하는데 따르는 규칙의 전반적인 이해를 제공한다.
이 post-hoc 설명 기법들은 어떠한 black box model이든간에 해석가능한 모델을 추론하는데 적용될 수 있다. 또한 어떠한 black box model이든지 이로부터 설명가능한 모델을 추론하는 테크닉은 model induction으로 알려져 있기도 하다.
하지만, comprehensive explanation으로 전체 모델을 해석하는 것은 굉장히 어렵고, 모델의 완전한 description이 선행돼야 가능하다. 또한, local과 global한 개념 또한 중요한데, local fidelity에서의 설명은 global fidelity 관점에서는 true일 수가 없기 때문이다(가령, LIME과 같이).
2. Stakeholders in XAI and Explainability Requirements
※ A 생략
B. Role-Based Explainability Requirements
AI 모델의 설명을 위해서 이해관계자(stakeholder)들이 누구인지 식별하는 것은 굉장히 중요하다 할 수 있다.
설명은 누구를 위한 것인가? 수학 전문가? 엔지니어? 회사원? 소비자?
AI 모델을 잘 결부 짓고, 쉽게 해석할 수 있게끔 만들기 위해 “Explainer” 역할들의 완벽한 정의가 필요할 것 같다.
또한, 설명을 수반하기 위해 “무엇이” 필요할 지에 대한 논의도 행해져야 한다. 이는 설명의 대상에 대해 이해하고, 그 대상이 모델인지, 아니면 데이터 그 자체인지 알아내는 것은 굉장히 중요하다.
역시 예를 들어보자.
도로 위의 다양한 차들을 ‘식별’하는 시스템을 고려해보자.
source로부터 얻어지는 data에 대한 설명은 아래와 같을 수 있다.
- 이 이미지는 차의 이미지인데, 모양(shape)과 차원(dimension) 상 다른 차의 이미지와 비슷하기 때문이다(KNN 활용).
- 4가지 바퀴, 모양, 전면 및 후면등 등과 같은 다양한 특징을 고려함으로써 위와 같은 결정을 내릴 수 있다(feature selection).
즉, comprehensibility(이해가능성)과 explainability(설명 가능성)은 ‘특정 사례’나 ‘이해관계자’의 관점에서 논의되어야 한다.
이 논의를 가져오기 위해 Section V에 있는 자율주행 차의 실사례를 가져와보자.
아래 그림에서, 다양한 이해 관계자들과 그에 대응하는 질문들이 나타나있다.
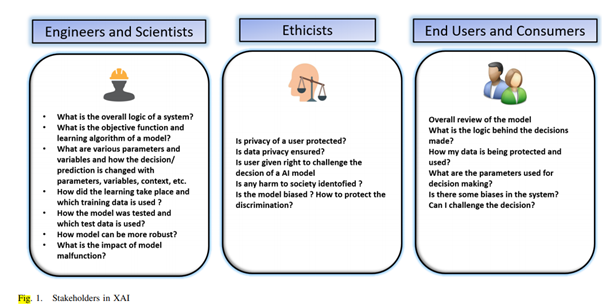
C. Explainability in the Contedxt of Engineers and Scentists
어떠한 ML 모델이든 수학적 설명에 관해서라면 아래와 같은 논의가 이루어져야 한다.
- Objective : -
- Scope : -
- Model Framework : -
- Modelling and mathematical equations : -
단, 내가 관심 있는 것은 user 관점의 설명성이기 때문에 생략.
D. Explainability of Currently Used ML Models
본 단락에서는 결정 트리(Decision Tree), KNN(K-Nearest Neighbors) 등의 머신러닝 모델과, transparent algorithm으로 여겨지는 Bayesian model 모델에 대해 얘기해보도록 하자(DT, KNN 생략).
베이지안 모델은 확률적 모델로서, 조건부 의존성을 통해 다양한 변수들 사이에 LINK들이 연결되는 것처럼, directed acyclic graphical model(유향 비순환 그래프)의 형태로 구성된다.
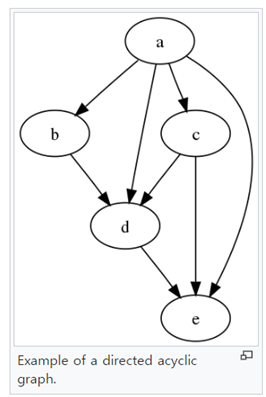
베이지안 모델에서는 feature와 target(변수들을 서로 엮는 연결) 간의 관계가 꽤나 명확하다.
예를 들어, 베이지안 네트워크가 질병 진단을 위해 쓰인다면, ‘질병’과 ‘증상’ 사이의 ‘확률적 관계’는 직관적으로 명확할 것이고, 증상을 조사함으로써 특정 질병의 ‘존재 확률’ 또한 쉽게 결정될 수 있다.
하지만, 매우매우 복잡하고, 거추장스러운 변수들 하에서 통계적인 관련성은 쉽게 해석될 수 없고, 수학적 툴을 이용해야만 분석될 수 있다.
DT, KNN 등에 대한 이야기는 안했지만, 베이지안 모델과 마찬가지로 직관적으로 이해하기 쉽기 때문에, 모두 다 Transparent model로 여겨진다. 또한, 다양한 변수들이 쉽게 분해되고, 분석될 수 있기 때문에 decomposable 하다고 볼 수도 있다.
하지만, 변수의 유사성 측정 방법은 매우 높은 차원을 가지며, 분해하기 복잡하기 때문에 설명을 위해 수학적 틀이 쓰여야 되는 점은 꼭 참고하도록 하자.
3. Related Work
본 단락에서는 IoT를 포함해 다양한 XAI에 대해 간략히 다뤄보도록 하자.
논문 “A Grounded Interaction Protocol for Explainable Artificial Intelligence”(논문) 에서는 기반이 되는 AI 모델을 증강하는 ‘explainable causal model’을 제안한다. 저자들은 6개의 다른 대화들을 통해 398개의 설명 대화들을 분석함으로써 그들의 모델을 도출했다. 제안 모델은 정확히 structure와 설명 대화의 sequence를 정의하며, 기존의 모델들로부터 얻어진 설명과 비교하여 인간 청충들 사이의 ‘natural interaction’을 지지하는 것으로 보인다.
비슷한 맥락으로, 논문 ”do you trust me?: Increasing user-trust by integrating virtual agents in explainable ai interaction design”(논문)의 저자들은 자동 시스템의 ‘신뢰성’에 대한 XAI에서의 가상 agent의 영향력 조사를 수행했다(user study). 간단한 speech 인식 task에 기반한 연구는 XAI 분야에서 가상 에이전트들의 융합이 자동 지능 시스템에 큰 신뢰를 제공한다는 것을 보여주었다.
해석가능한 CNN
논문 "Interpretable CNNs for Object Classification”에서 저자는 해석가능한 CNN의 구성에 쓰이는 해석가능한 convolutional filter를 학습하는 ‘generic interpretable model’을 제안한다. 이 필터들은 CNN에 투입된 모든 이미지를 통틀어 same object portion(part라 보는게 적절할듯)을 표현하는 방법을 배우며, 어떠한 추가적인 object annotation이나 texture를 필요로 하지 않는다.
학습 과정에서, 해석가능한 필터는 자동적으로 각 convolutional layer에 할당된다. 이 필터들은 CNN의 각 convolutional layer에 존재하는 여러 parameter의 explicit한 지식을 표현한다. 예를 들어, CNN의 encoded logic, input image로부터 어떤 패턴이 추출되는지, 그리고 예측이 어떻게 만들어지는지 등에 관한 정보를 학습한다.
4. USE-CASE: AUTONOMOUS CAR
본 단락에서는 AI를 극도로 활용한 (익명의) 차를 예시로 들어, XAI의 쓰임새와 이것이 인간의 삶에 어떻게 영향을 미치는 지를 살펴볼 것이다. Perception, object detection, actuation 등 주요 구성 요소를 고려하여 XAI를 현실화하는 데 있어서 필요사항들, 역할, 테크닉 등을 의논해보자.
A. General Objective, and Transparency and Explainability Requirement for the XAI Model
자율주행 자동차를 사용하면서 생길 수 있는 예기치 못한 문제는 아래와 같다.
- 잘못된 방향
- 잘못된 회전
- 급정거
- 물체 인식 문제
- 브레이크 실패 등으로 인한 충돌..
위와 같은 일들이 왜 일어나는 지 이해하는 것은 아래와 같은 이유로 하여금 필수불가결하게 된다.
1. 문제를 고치고, 사용자 경험을 증진시키며, 자율주행 기술에 대한 신뢰를 제고한다.
2. 법적인 관점에서, 사고의 이유에 대해 파악하는 것은 너무너무 중요하다.
위와 같은 개선은 분명 AI 모델이 투명하고, 설명가능해야만 가능할 것이다. 이런 관점에서, XAI는 improvement, transparency, explanability, optimization 등에 관한 것이라 볼 수 있다.
B. Mathematical Perspective of the XAI Model in Autonomous Cars
이번엔 수학적인 관점에서 자율주행 내 XAI에 대해 살펴보자.
이는 자동차, 도로, 보행자, 자동차의 위치 및 제어 등 굉장히 많은 상호작용 개체들로 이루어진 복잡계 시스템이라 볼 수 있다. 이들간의 상호작용은 미분 방정식 등으로 모델링될 수 있으며, 해당 방정식들은 특정 자율주헹 모델의 행동을 이해하는 데 쓰일 수 있다.
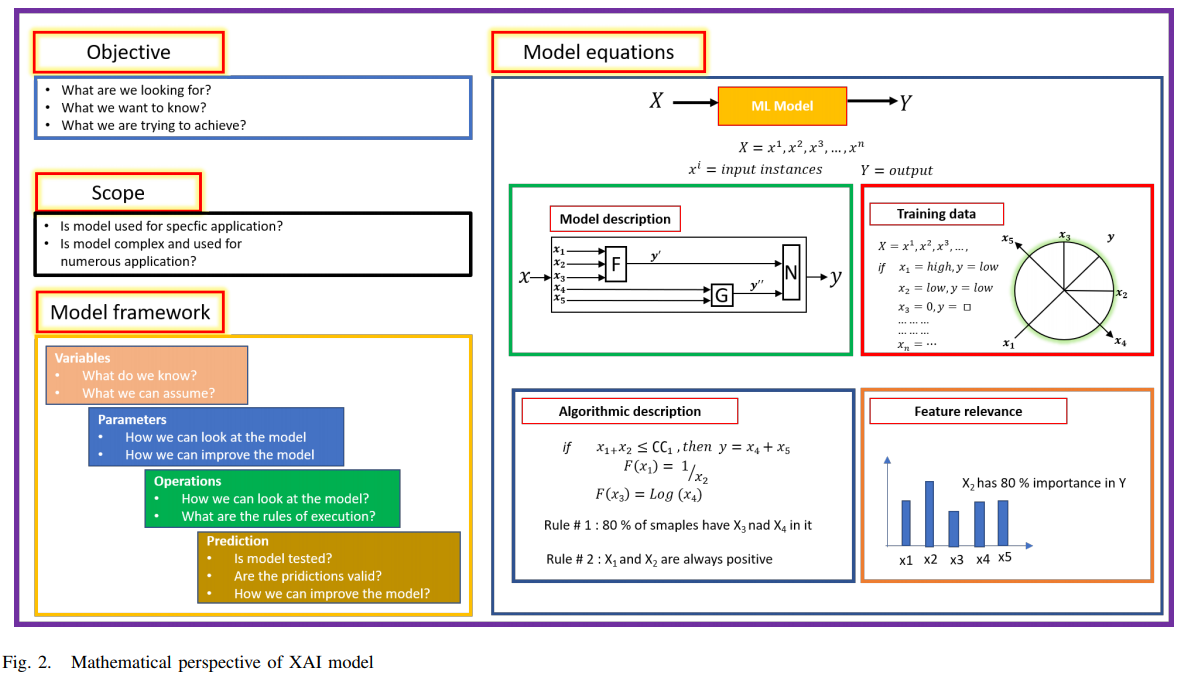
위와 같은 그림을 토대로 나타낸 (수학적인 관점의) XAI model framework는 아래 그림과 같다.
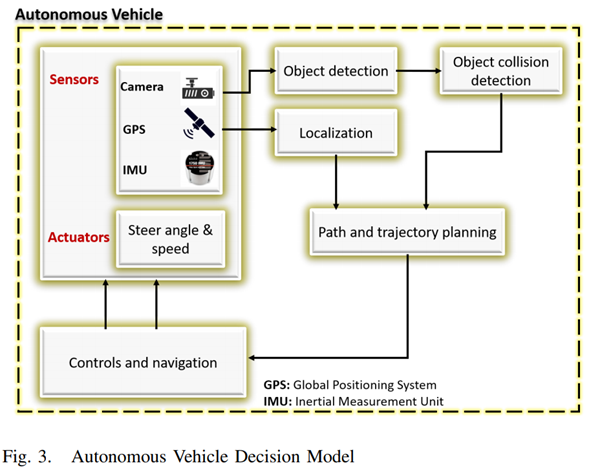
이제 자율주행 자동차의 다양한 기능적 요소에 필요한 설명의 type과 level을 살펴보자.
1. Object detection and classification
우서적으로, image classification에 쓰이는 패턴 인식 알고리즘에 대해 구체적으로 다룰 필요가 있을 것이다. 많은 종류의 이미지 데이터들이 Advanced Driver ASsistance Systems(ADAS) data를 통해 얻어지기 때문에, 관련 없는 이미지를 걸러내기 위해 reduction algorithm이 필요하다.
data reduction algorithm을 구체적으로 살펴보면, Principle Component Analysis(PCA), Histogram of Oriented Gradients(HOG), Support Vector Machine(SVM) 등을 예로 들 수 있을 것 같다.
이미지 분류 후에, object detection이 수행되어야 한다. 그 후에는 아래와 같은 질문이 촉발된다.
어떤 회귀 알고리즘이 object detection을 위해 쓰일까?
회귀 알고리즘에는 어떤 변수가 독립적이고, 어떤 변수가 종속적일까?
object detection에 쓰이는 end-to-end 학습과 inference model을 해석하는데 쓰이는 기저 구조를 언급하는 것도 도움이 될 것 같다.
논문 Towards interpretable object detection by unfolding latent structures 에서 저자는 image 내 region을 기반으로 하는 two-stage convolutional network를 제안하며, 설명의 역할을 하는 의미있는 정보를 생성한다. 또한 저자는 top-down grammar model을 bottom-up convolutional network와 결합하기도 했다. 해석가능한 object detection을 위해 RoI를 풍부하게하기도 했으며, 널리 쓰이는 flat structure 대신 RoI의 계층적 표현(hierarchical representation)을 사용하기도 했다.
유사하게, 논문 Explainable density-based approach for self-driving actions classification 에서는 0-order fuzzy rule을 사용함으로써 자율주행 차량의 다양한 결정(가속, 레인 변경 등)과 관련된 "인간이 해석가능한 'IF-THEN' 표현"을 제공한다. 이들이 제공하는 분류기는 분류 성능을 높힐 뿐만 아니라, 대규모 병렬 0-order fuzzy rule을 활용함으로써, 결정에 기여하는 feature들의 density에 초점을 두기도 했다.
Object localization, perception, and movement prediction
motion prediction을 위해서, 그리고 감지된 object의 현재와 미래 위치에 관한 통계적으로 합리적인 모델을 생성하기 위해서, 회귀 알고리즘이 쓰인다. 이 때, 회귀 알고리즘에는 결정 트리, neural network regression, 베이지안 회귀 등이 쓰일 수 있다. 또한, 장기적인 예측에 쓰이는,혹은 단기적인 예층에 쓰이는 알고리즘 등도 따져볼 수 있다.
하지만, 우리가 아는 한, object localization과 (자율주행 차량의) movement predict에 쓰이는 설명은 아직 도입되지 않은 걸로 보인다. 하지만 여전히 자율주행 차량의 perception에 대한 해석은 계속해서 발전하고 있다.
※ 여기서 perception이란, 도로의 상황을 인지하는 end-to-end 모델의 인지 능력이라고 봐도 무방할 듯 하다.
논문 Interpretable learning for self-driving cars by
visualizing causal attention 에서는 visual attention 구조를 사용해 자율주행 차량에 의한 perception에 관한 설명을 제공한다. 여기서 interpretable learning을 위해 Visual attention network가 중요한 역할을 하는데, 학습 과정에서 network(?)에 의해 영향을 받는 이미지 내 area와 underlying network에 의해 주목받는 area에 대한 visual attention을 제공한다. 운전 중에는 사실상 real-time image가 포착되어야 하므로, 근본적으로 자율주행 자동차의 실 사용에 적절하다할 수 있다.
또한, 해당 논문에서 Kim et al은 visual attention network의 output(특히, images 위의)서 나온 이미지에 대해 후처리를 적용했으며, 네트워크의 end-to-end output에 있는 attention area에 대한 영향력을 결정했다.
그 후, end-to-end 네트워크 학습에서 causal effect(인과적 효과)를 갖는 이미지의 영역이 식별되어 유저에게 제공된다. 다시 말하면, 저자는 이미지 내 visual saliency를 제공했다고 볼 수 있다. 게다가 visual attention heat map을 제공할 뿐더러 object detection과 perception 단계에서 성능을 감소시키지도 않았다. output을 도출하는 데 도움이 되지 않는 필요 없는 feature를 지움으로써 causal filtering은 설명력을 강화하는 데 도움이 됐다고도 말한다.
이처럼 visual intelligence는 자율주행 자동차에서 큰 역할을 할 수 있는데, 다른 논문에서는 real-world 상황에서 기존의 visual perception 방법들은 내재적인 단점이 존재한다고 주장하기도 한다. 논문 Building explainable ai evaluation for autonomous perception 에서 저자는 극단적인 날씨, 저조도 등의 상황에서 학습 데이터의 불균형 등에 의해 AI 모델이 좋지 못한 판단을 내릴 수 있다고 지적한다. 딥러닝 네트워크에 의해 학습된 Representation의 해석력은 앞에서 언급한 문제를 부분적으로 다룰 수 있긴 하긴 하지만, 여전히 Test data와 관련된 external factor는 아주 중요하다.
해당 논문의 저자는 해당 논문에서 다양한 변수에 대한 'human domain knowledge'를 포함하는 설명가능한 AI evaluation을 제안함으로써, 의미 있는 개념(semantic concepts)과 시각적인 인식에 쓰이는 기저 알고리즘의 출력을 강화하려고 하였다. 결정적인 관계를 찾기 위해 Ridge Regression을 사용했으며, 특정 알고리즘의 output들을 테스트 하였다.
유사하게 perception 단계에서 visual region과 그 의미 또한 너무나 중요하다. 따라서, 자율주행 간에 perception을 수행하면서, visual scene 내 특정한 region에 집중하는 것도 아주 중요하다.
특정연구는 driving scenario를 이해하기 위한 end-to-end 학습에 쓰이는 CNN의 역할을 해석하기 위한 FRAMEWORK를 제안하기도 한다. 즉, perception에 큰 기여를 한 region을 결정하는 것이다.
※ Motion planning은 perception과 prediction의 다음 단계이니, 여기선 크게 다루지 않겠다.
5. Conclusion And Open Challenge
본 글에서는 XAI의 필요성, XAI와 관련된 이해 관계자들, 다양한 이해 관계자의 존재로 인한 다양한 관점들을 다루었다. 특히, 엔지니어링적 관점에서 어떻게 XAI를 바라보아야 할 지를 자율주행 차량을 예시로 들어 기술했다. 여러 기법들과 다양한 구성 요소들을 살펴보았지만, 여전히 문제점들은 남아 있다. 이는 아래와 같다.
1) Generalization of XAI
본 글에서도 자율주행 차량을 예시로 다룬 만큼, XAI는 극도로 환경과 도메인에 의존한다고 볼 수 있다. 그렇기에 XAI의 일반화 문제는 아주 오래 걸릴 것으로 예상한다. 하지만 XAI의 중요성에 대해서 역설하는 것은 의미가 없을 정도로, 일반화 XAI에 대한 도입은 '왜?'가 아닌 '언제?'의 문제라 할 수 있다. 다양한 이해 관계자들이 얽혀 있는 만큼 이를 한 번에 실현하기는 힘들지만, 도메인 관점에서 locally하게 접근함으로써 스타트를 끊을 수 있다고 생각한다.
2) Adaptation of XAI
XAI 분야에서는 다양한 도메인 간 차이를 줄이기 위해 선행된 가치 있는 노력들이 많지만, 여전히 XAI의 채택에 대해서는 어려움이 있다. 이에는 다양한 이유들이 있겠지만, 주된 문제는 다양한 이해관계자들에게 필요한, 설명의 level과 다양성이다. 예를 들면, 자율주행 차량에서는 같은 AI 모델이 end-user, developer, designer 등에게 각기 다른 설명의 레벨을 제공해야 할 필요가 있을 것이다. 그렇기에, 이 또한 미래 연구에서 해결해야 할 큰 문제라 할 수 있다. 'Domain adaptation', 즉 '특정 domain을 대상으로 채택하는 것'이 역시 좋은 시작점이 될 수 있다.
3) Security of XAI
Adversarial learning은 입지를 다지고 있으나, XAI에 대한 영향력은 아직 탐구되지 않았다. Adversarial machine learning의 영향은 자명하게도 연구의 중요한 과제인데, ML과 DL의 attack을 다룰 뿐더러 적대적 환경에서 ML, DL의 사용까지 다룬다(본 논문 내 존재). XAI에서 Adversarial ML(DL)은 여전히 흥미로운 주제이다. 학습 모델의 input data에 대한 간섭, 편향, 공평성 등은 AI 모델의 안전성을 위해 아주 중요한 요소이기도 하다. 이 feature들은 XAI에서 너무나도 중요하므로, 반드시 탐구되어야 한다.
4) XAI and Responsible AI
설명성, 해석가능성, 투명성 등의 특징을 갖는 Responsible AI(RAI)는 XAI 분야 내에 존재한다. 하지만, 이 또한 실 세계(real-world)에 적용될 수 있을지는 충분히 조사되어야 한다. XAI가 AI model의 사용에 끼치는 영향은 더욱 조사 되어야 한다. 예를 들면, 연구자 커뮤니티에서는 여전히 XAI의 근거는 논란의 여지가 있다. 테크니컬한 관점을 벗어 나더라도, 사회적, 법적인 차원에서의 논의 또한 XAI를 실세계에 실현하는 데 중요한 요소이다. 반대로 말하면, 이러한 방향으로의 연구 기회 또한 굉장히 많다고 할 수 있다.
5) Performance of XAI
XAI가 기저 AI model에 중요한 요소를 부여하는 것은 맞지만, 여전히 기반이 되는 AI model의 성능 또한 중요하다. 즉, 새로운 특징(설명)이 overhead(간접비용)를 초래해 accuracy에 영향을 미칠 것인지에 대한 논의가 급선무이다. 오늘 날에도 XAI의 performance에 대해 다룬 몇 가지 연구가 있긴 하다([7], [41], [42]). 이런 '성능'의 방향으로도 연구가 필요한 실정이다. 또한, 좋든 나쁘든 간에 Original model에 XAI가 끼치는 영향은 새로운 연구 방향을 열기 위해 심층 조사가 필요하다.
6. Let me say something
내 연구를 위해 본 논문의 어떤 관점을 취할 수 있을까? 주목할 만한 대목은 굵은 글씨로 나타내긴 했으나, 아래에서 대략적으로 정리해보자.
- Object detction 등은 real time의 속도를 갖는 것도 아주 중요하다.
- 그렇기에, 이에 적용될 XAI 또한 inference time에 대한 논의가 필요할 수 있다(엔지니어, 유저 등이 post investigation를 목적으로 XAI를 사용하지 않는 이상).
- 특정 domain에 대해서 적용가능한 모델을 연구할 것인지, 전체 domain에 대해 적용가능한 모델을 연구할 것인지 따져보아야 한다.
- 특정 이해 관계자에 대한 설명을 제공할 것인지, 전체 이해 관계자에 대한 설명을 제공할 것인지도 따져보아야 한다.
- AI의 안정성을 위해 adversarial deep learning을 도입하는 것이 의미가 있을까?
- base AI 모델의 성능을 꽤나 큰 폭으로 감소시키는 설명 모델(가령, adversarial explanation(논문))이 의의를 가질 수 있을지, 혹은 해당 설명 모델이 base AI 모델 성능에 끼치는 악영향을 개선하는 것에 시간을 투자하는 게 비효율적이진 않을지도 생각해봐야 할 듯.
- 본 글에서 제안한 예시 논문들이 XAI을 도입함으로써 생길 수 밖에 없는 문제(본 모델 성능 저하, inference time) 혹은 extreme environment 문제(저조도, 빛 공해, 극한의 날씨 등) 을 어떤 방식으로 해결했는지 참고할 만 할 듯
- 이는 papers to read 태그 게시물에 적어놓았음.
※ Reference는 본문에서 모두 링크로 표기하였음.
