0. Abstraction
- 트랜스포머 레이어의 특성상 정보가 레이어에 따라 계속 혼합됨.
- 그렇기 때문에 ATTENTION WEIGHT는 믿을만 하지 못함.
- 그래서 저자들은 정보의 흐름을 정량화할 수 있는 방법을 제안.
3. Attentio Rollout and Attention Flow
Attention rollout은 트랜스포머 모델의 각 레이어마다 재귀적으로 embedding attention을 input으로 받아 token attention을 연산합니다.
rollout과 flow의 차이는 정보를 순전파시킬 때 attention weight가 어떻게 영향을 끼치는 지, 그리고 token들 간에 독립적으로 여기는 지에 따라 차이가 생깁니다.
input layer에서 high layers의 embedding에 정보가 어떻게 전파되는 지 연산하기 위해서 attention weights외에도 residual connections도 염두에 두어야 합니다.
(attention과 feed-forward network가 residual에 쌓여있음)
본 논문에서는 이런 residual connection+attention을 고려하기 위해서 선형 결합을 가정하고 아래와 같이 추가적인 weight를 부여합니다.
원래는 비선형입니다. 왜냐면 그냥 Attention layer 자체에 softmax가 포함되기 때문입니다, Because .

3.1. Attention rollout
Attention rollout은 input layer에서 higher-layer의 임베딩으로 전파되는 information을 추적할 수 있는 직관적인 방법입니다.
layers의 트랜스포머가 주어졌다고 가정해봅시다.
이 때 우리는 실질적으로 layer 내 모든 position에서 layer 의 모든 position에 대한 attention을 계산하고 싶습니다.
더욱 구체적으로, layer 에서 번째 위치에 있는 node를 , layer 에서 번째 위치에 있는 node를 라고 해봅시다.
그러면, attention graph 관점에서 와 사이의 path는 두 node를 연결하는 일련의 edge들입니다.
이 때 edge에 해당하는 weight를 정보의 비율로 바라본다면, 우리는 특정 path를 따를 때 에서 얼마나 많은 정보가 로 전파되는 지 알 수 있습니다.
정확히는, 특정 path 내 모든 edge의 weight를 곱함으로써 해당 path를 통해 전파량을 계산할 수 있습니다.
attention graph에서 두 노드 간 path는 하나보단 많을 것이기 때문에 에서 로 흐르는 정보의 총량을 계싼하기 위해 두 노드 간에 성립할 수 있는 모든 path를 더해야 합니다.
실행 측면에서 본다면 와 사이의 어텐션을 연산하기 위해 모든 하위 레이어들의attention weights matrices를 재귀적으로 곱해 나갑니다.
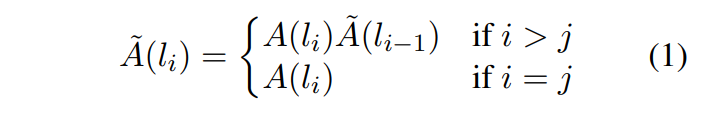
위 식에서 가 attention rollout이고, 는 raw-attention입니다.
일 때 input attention.
A.1. Single Head Analysis
본 논문에서는 Attention 과정에서 heads를 평균냅니다. 다만, 개별적인 head 또한 분석할 수 있다고 합니다.
사실 각 head의 역할이 다르긴 하지만, 결국 final output을 반환할 때에는 모든 heads의 정보를 concat해서 사용하기 때문에 개별적으로 고려하는 것이 좋지는 못하다는 얘기도 존재합니다.

