Code : https://github.com/NVlabs/SPADE
Paper : https://arxiv.org/pdf/1903.07291.pdf
해당 글에서 다룰 Generator 아키텍처는 아래 구조 중 두번 째 구조인 VAE Architecture(2. Semantic manipulation and guided image synthesis) 입니다.
1. Multi-modal synthesis

같은 segmentation mask에 대해 다른 noise inputs를 샘플링함으로써 다양한 output을 생성할 수 있었습니다.
Generator의 first layer는 input으로 noise vector를 받고, intermediate layers는 segmentation mask를 받아 를 얻게 됩니다.
input으로서 Generator의 first layer에 주어지는 벡터와, (사실상 input이긴 하지만) Intermediate layers에 information으로서 주어지는 segmentation map은 구분할 필요가 있습니다.
2. Semantic manipulation and guided image synthesis(VAE Architecture)
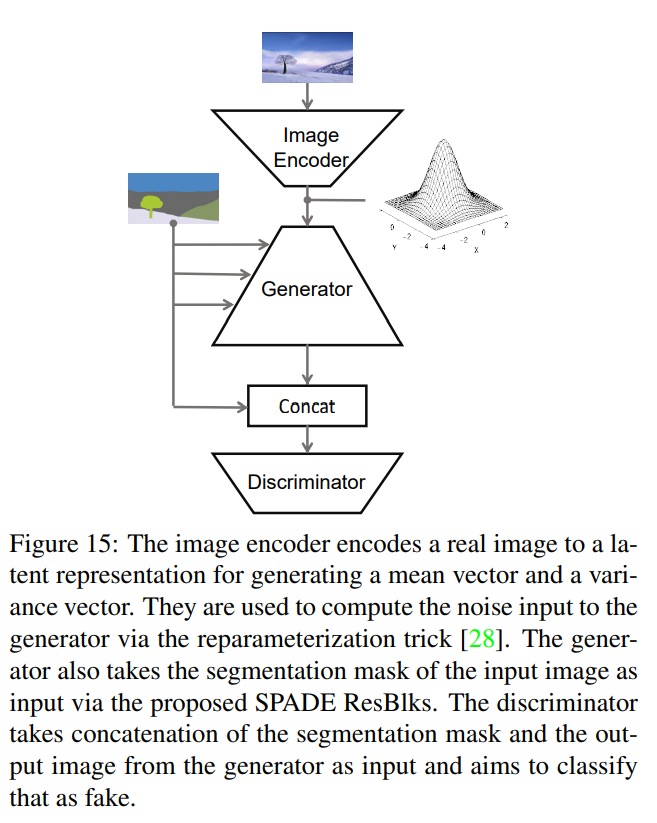

1.의 모델과 다르게 일반 사용자가 직접 segmentation mask를 그릴 수도 있고, 최종적인 output을 결정하기 위해 style image를 인코더로 직접 임베딩해 노이즈 벡터로 제공해줄 수 있습니다.
(즉, encoded style vector + segmentation map)
(1.의 모델은 그냥 noise input + segmentation map)
VAE Architecture in SPADE
1. How to Train?
in train.py
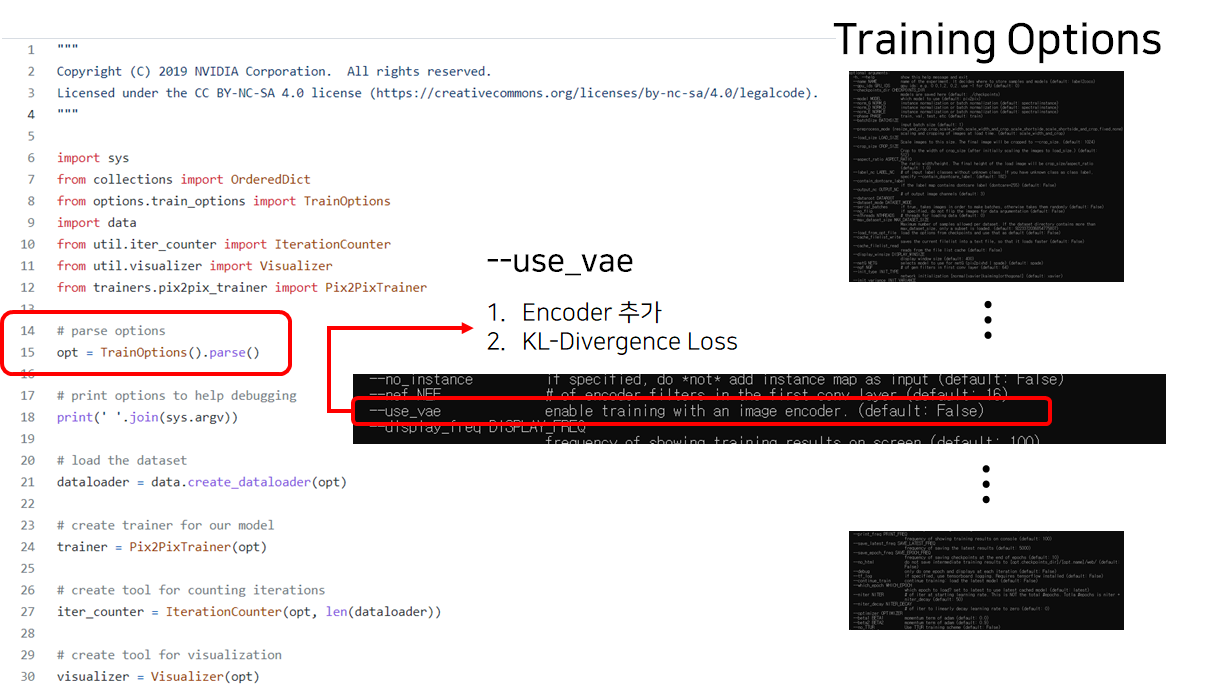
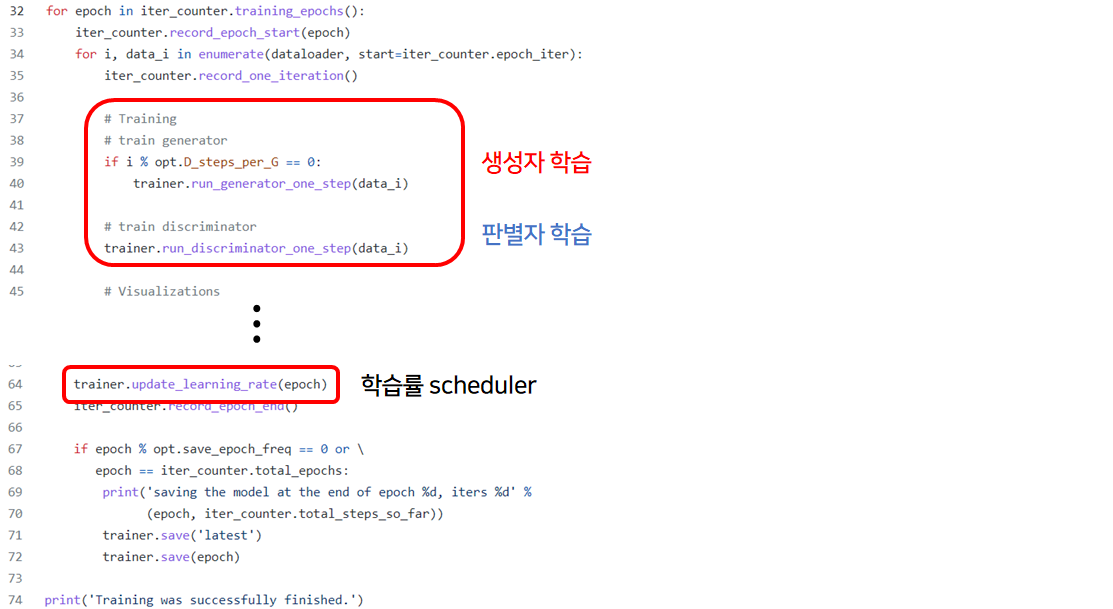
Code : python train.py ... '--use_vae' ...
2. VAE in pix2pix model
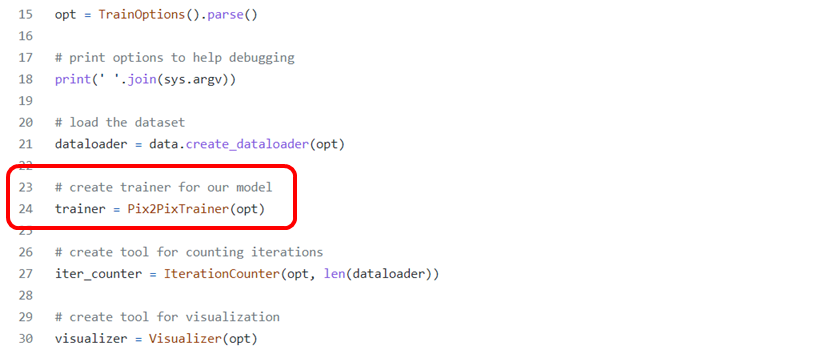
in pix2pix_trainer.py ,
self.pix2pix_model_on_one_gpu = self.pix2pix_modelrun_generator_one_steprun_discriminator_one_stepget_latest_lossesupdate_learning_rateget_latest_generated- e.t.c. ...
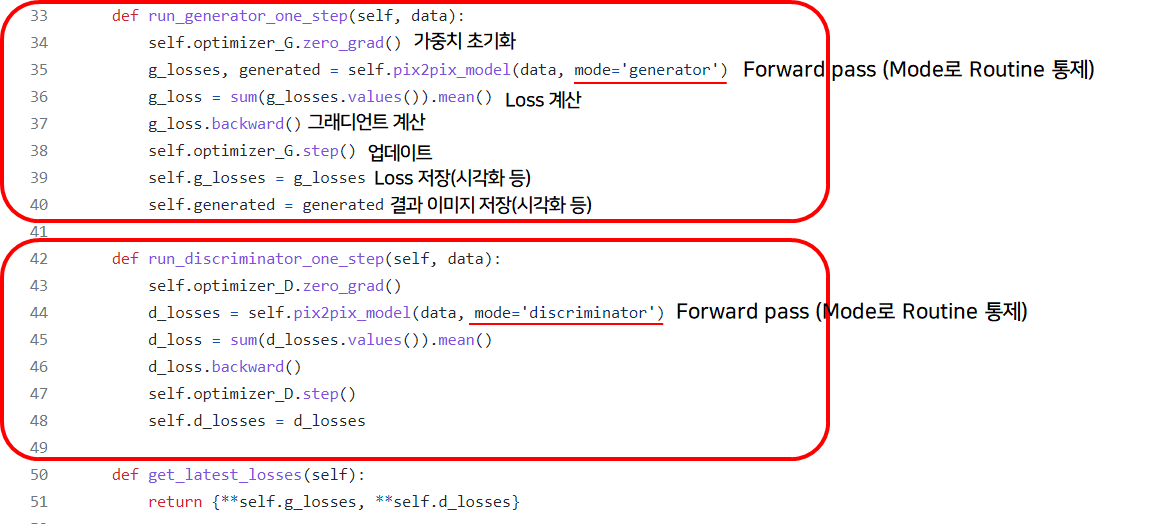
학습을 위한 전반적인 과정이 담긴 파일.
이 중 pix2pix_model을 살펴보자.
in pix2pix_model.py
def forwarddef create_optimizersdef initialize_networksdef preprocess_inputdef compute_generator_lossdef compute_discriminator_lossdef generate_fakedef discriminatedef encode_z
in def __init__(self,opt)
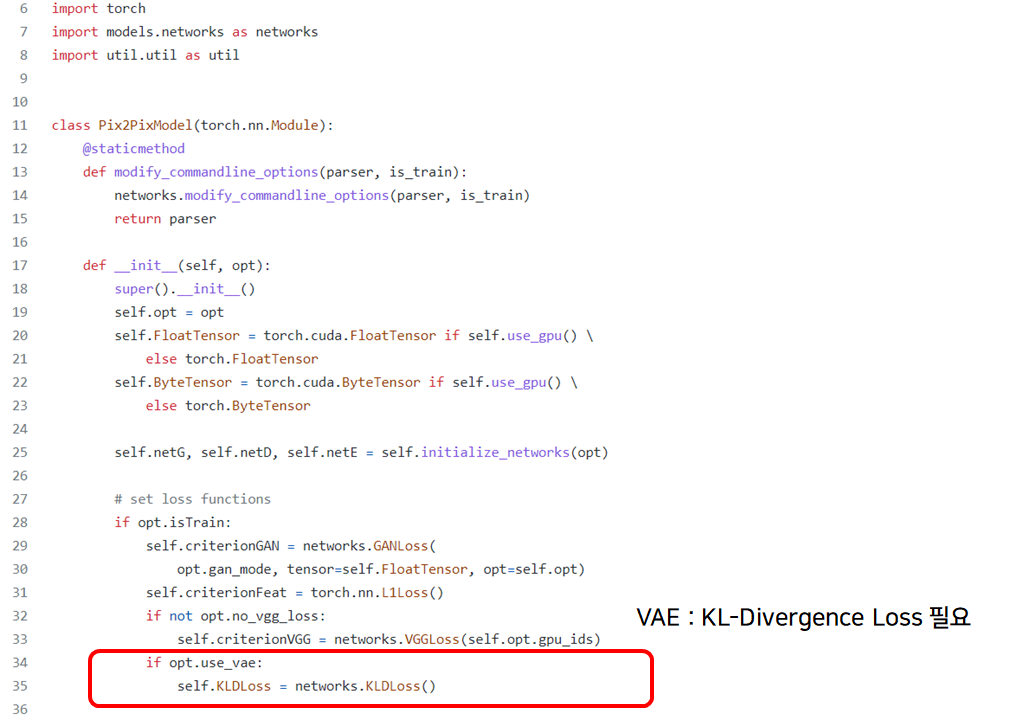
in def forward(data, mode)

vae 버전과 관련된 code(아키텍처, loss 등)는 아래와 같습니다.
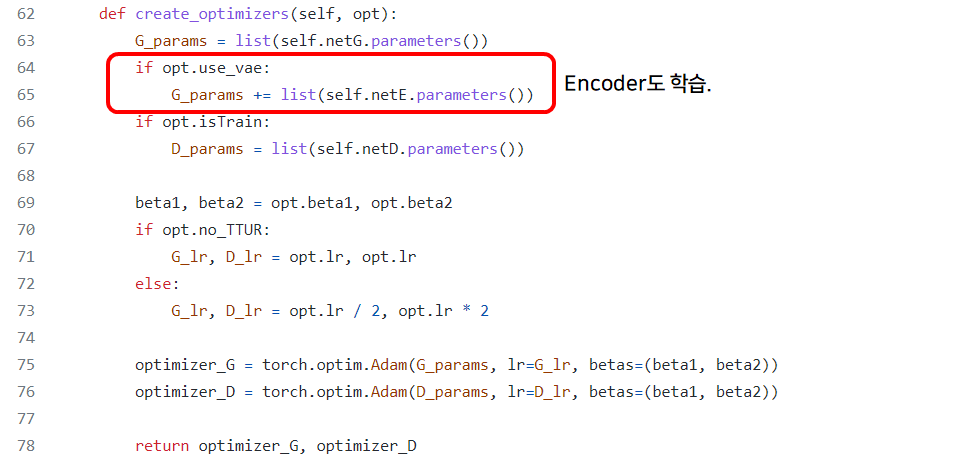
in def create_optimizers(self, opt)
in def save(self, epoch)

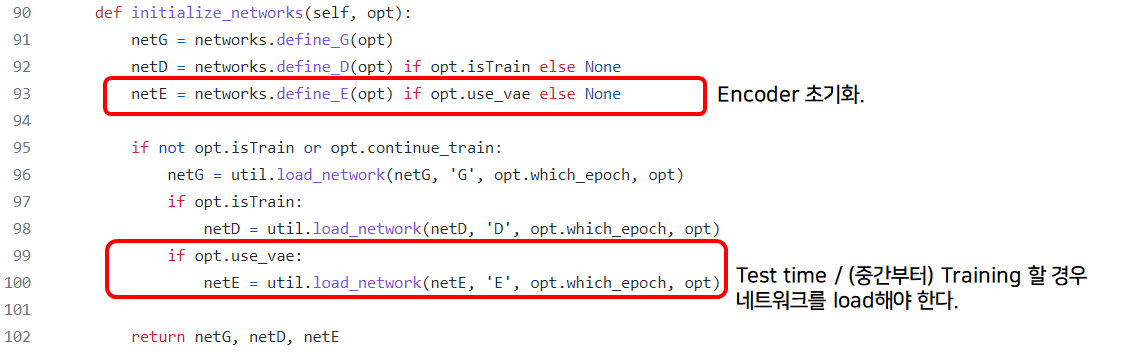
in def initialize_network(self, opt)
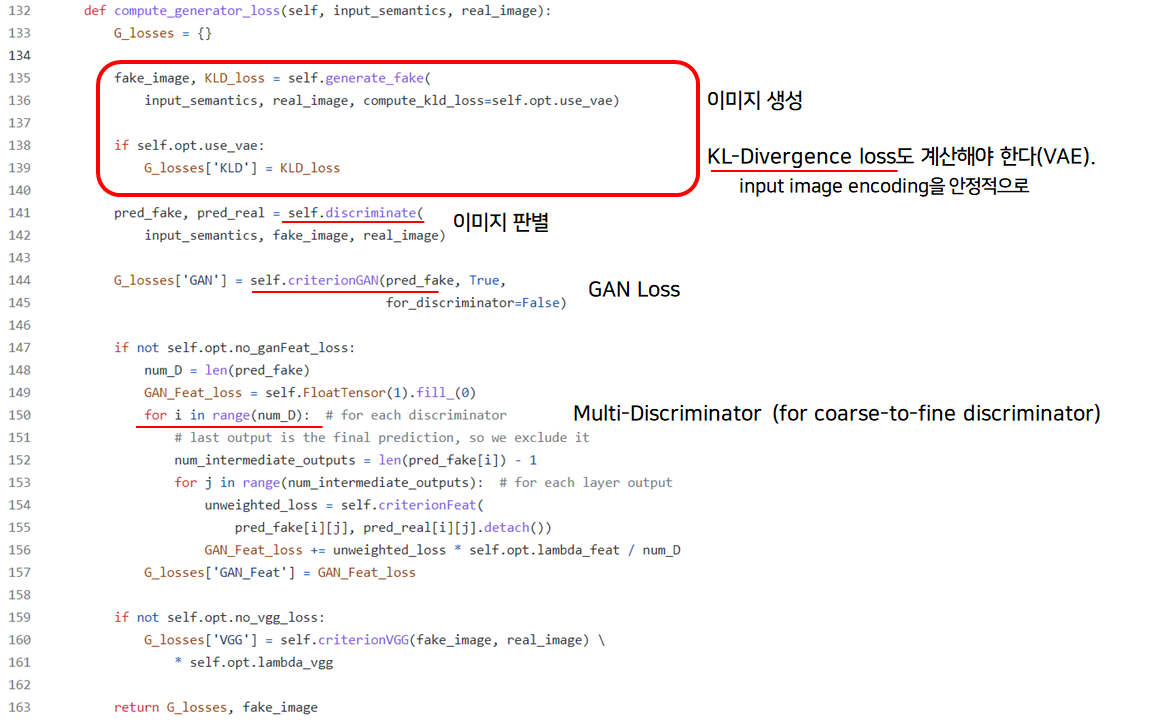
in def compute_generator_loss(self, input_semantics, real_image)
in def generate_fake(self, input_semantics, real_image, compute_kld_loss=fake)
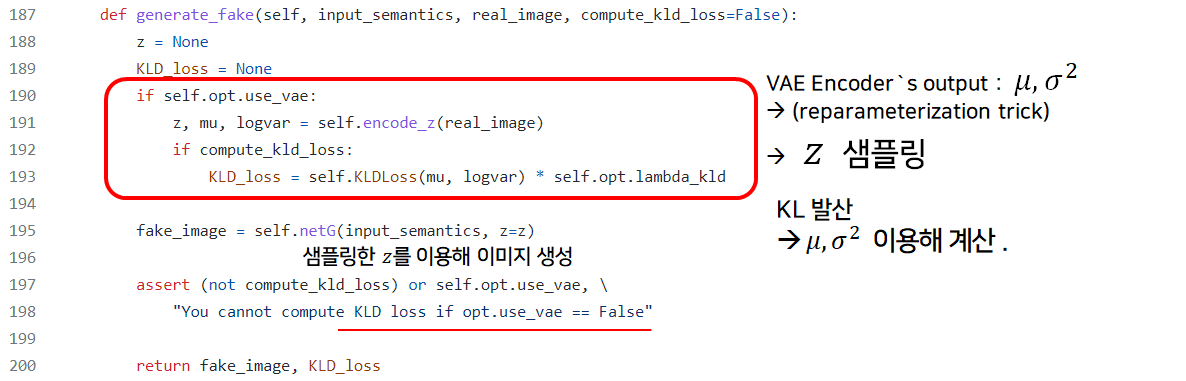
참고(VAE)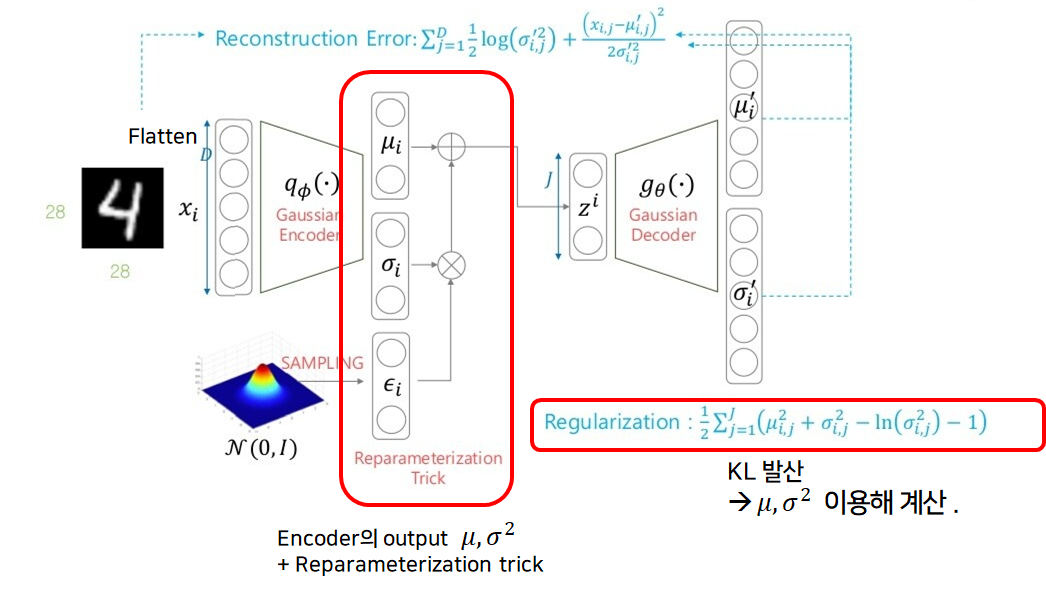
즉, 우리가 원하는 style을 갖는 이미지를 input으로 투입, 인코딩해 얻는 는 input image의 분포를 잘 묘사하는 평균과 분산이 됩니다.
Architecture of SPADE Encoder

Code https://github.com/NVlabs/SPADE/blob/master/trainers/pix2pix_trainer.py
https://github.com/NVlabs/SPADE/blob/master/models/pix2pix_model.py
https://github.com/NVlabs/SPADE/blob/master/models/networks/encoder.py
VAE
https://velog.io/@sjinu/VAE2
3. SPADE Generator(common to all Architecture)
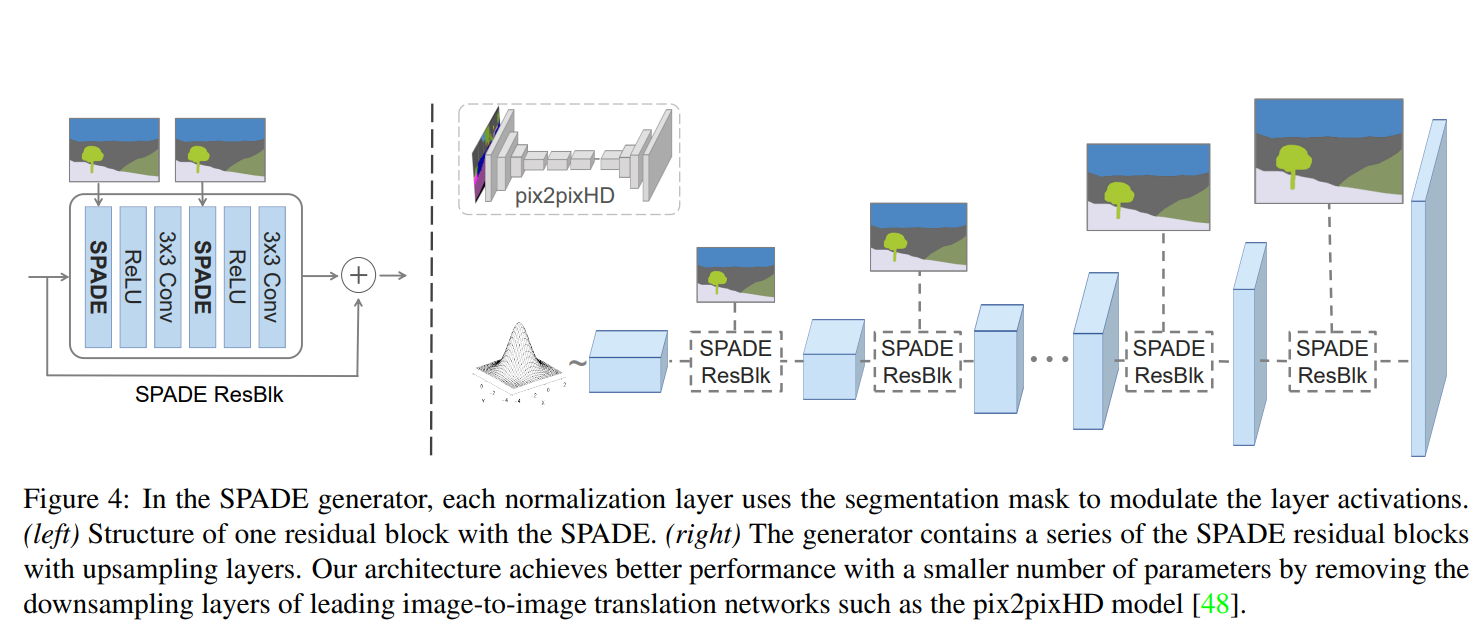
만약 Image의 Style을 활용하지 않는다면 (생성자)와 (판별자)만 사용하게 됩니다.
Encoder를 통해 Image의 style(혹은 Text, Sound의 style)을 활용하게 된다면 , 에 추가적으로 (Encoder)를 사용하게 됩니다.
여기서는, (생성자)에 대해서 살펴보도록 하겠습니다.
저자들은 모델을 불러올 때 '이름'을 이용해 불러옵니다.
in models/networks/__init__.py

in models/networks/generator.py
.. in class SPADEGenrator()
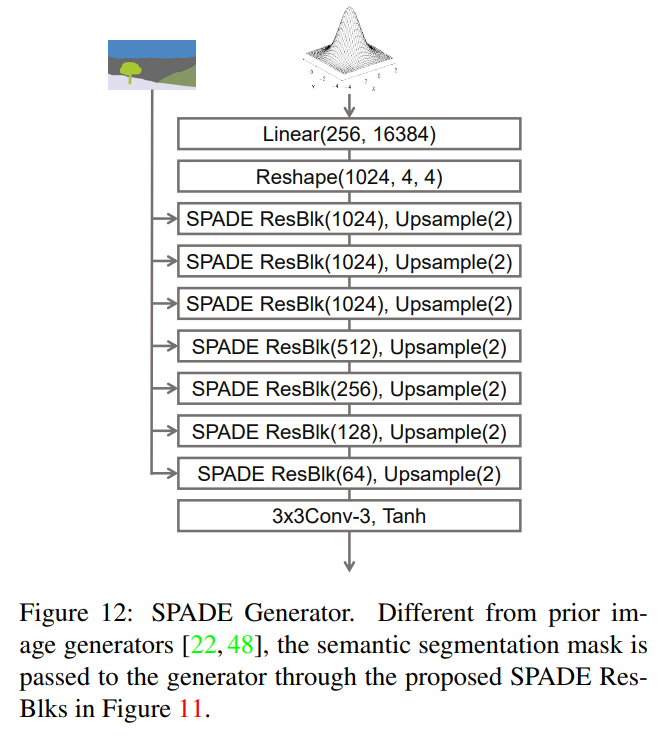
우선, VAE mode Generator의 전반적인 구조는 아래와 같습니다.
Encoder를 통해 256-length vector 를 얻었다면, 이를 Linear 모델에 통과시켜 16384차원으로 키운 뒤 4번의 (SPADE) Upsampling 과정을 거쳐 최종적인 Image를 생성합니다.
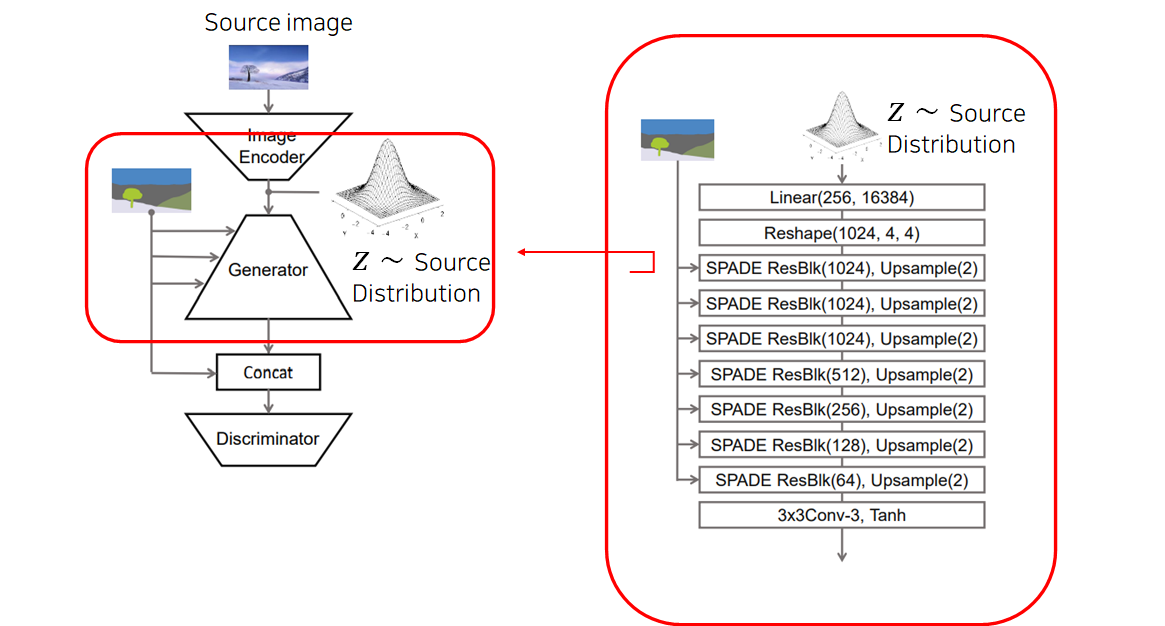
코드로 보면, 아래와 같이 VAE mode를 사용할 경우 style image를 인코딩해 얻은 잠재벡터 를 사용하게 됩니다.

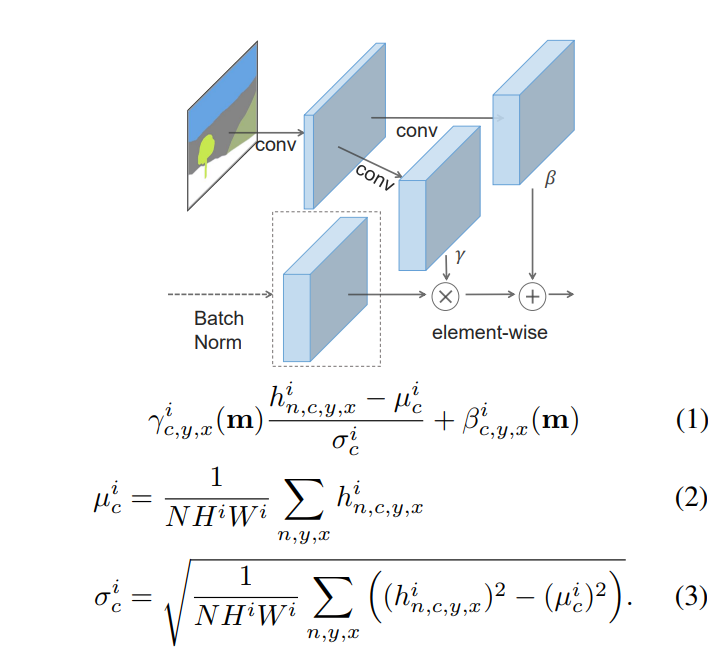
또한, SPADE의 핵심인 SPADE-Residual block은 아래와 같이 나타나 있습니다(세부 구조 생략, 그림 참고).

참고로, SPADE Residual block 안에 있는 SPADE는 아래의 레이어를 통해 연산됩니다.
즉, 해당 과정을 통해 를 얻고 이를 이용해 Denormalization을 진행해주는 것을 SPADE라 칭합니다.
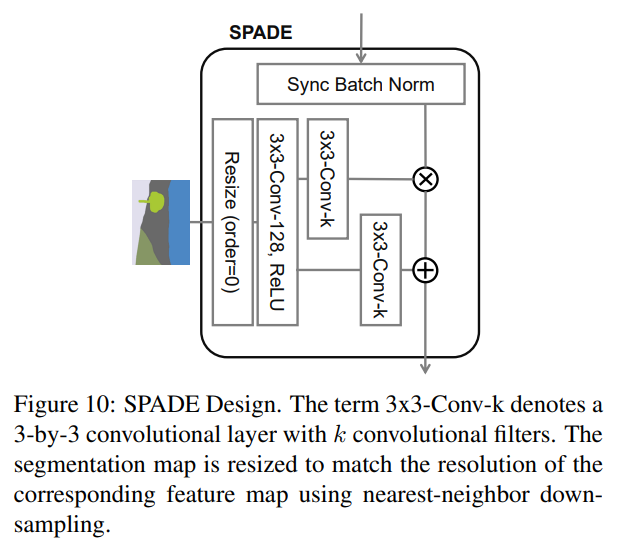
in def forward(self, input, z=None):

이후 Conv-upsampling을 진행합니다.

4. Discriminator

대충 이렇게 생겼습니다.
다만, Multi-Discriminator를 차용하기 때문에 판별자가 여러 개 존재하며, 특히 각자 다른 image scale에 대해 판별해 loss -> Gradient feedback을 제공합니다.
