시퀀스
시퀀스는 일련의 연속적인 사건들 또는 사건의 행동 등의 순서라는 뜻을 가지고 있다.
예를 들어 밥을 한다고 치면 쌀을 씻어야 하고 씻은 후 적정량의 물과 함께 압력밥솥에 넣은 후 취사 버튼을 누르면 된다.
만약 알고리즘에 취사버튼을 누르라는 말이 없다면 식사할 때 밥이 아닌 물에 불린 쌀을 먹게될 것이다.
밥하는 순서처럼 알고리즘은 어떠한 작업을 완료하기 위해 수행되는 일련의 과정 또는 일련의 규칙 이라는 뜻이다. 이런 알고리즘의 작업을 처리하는 과정이 시퀀스이다.
순환신경망
문장을 생각해보자
- 나는 밥을
[ ] - I
[ ] - He
[ ]
빈칸에 들어올 말은 무엇일까??
첫 번째는 먹는다, 먹었다 등 다양한 말이 올 수 있다. 두 번째는 am, 세 번째는 is일 것이다. 그 외에도 다양한 말들이 올 수 있지만 대체로는 먹는다, am, is를 생각할 것이다.
인공지능이 글을 이해하는 방식도 위와 같은 방식을 사용한다. 문법적인 원리가 아닌 수많은 글들을 일게 함으로 통계적으로 I 다음에 am, He 다음에 is가 오는 것을 배우게 한다.
따라서 분류하는 문제와 같이 데이터가 많을 수록 좋은 결과를 보여줄 것이다.
이러한 방식을 처리하는 인공지능 중 하나가 순환신경망(RNN)이다.
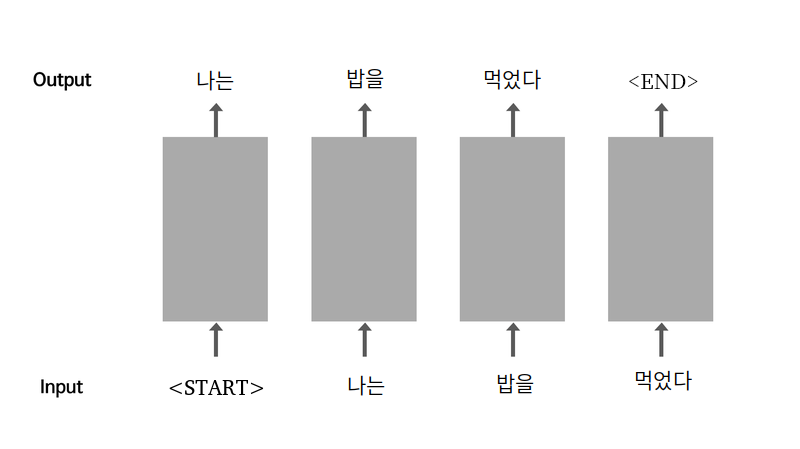
위 사진은 순환신경망의 작동을 간단하게 표현한 그림이다.
START 토큰으로 시작해주고 나는이 출력된다. 출력된 나는은 다시 입력으로 사용되고 이러한 반복을 통해 먹었다까지 글을 생성하게 된다. 이러한 순환구조를 가지기 때문에 순환신경망이라고 한다. 글을 완성한 이후에는 END라는 토큰을 생성한다.
위 과정에 대한 예시
sentence = " 나는 밥을 먹었다 "
source_sentence = "<start>" + sentence
target_sentence = sentence + "<end>"
print("Source 문장:", source_sentence)
print("Target 문장:", target_sentence)언어 모델
언어 모델은 단어 시퀀스에 확률을 할당하는 일을 하는 모델이다. 쉽게 말하면 언어 모델은 가장 자연스러운 단어의 시퀀스를 찾아내는 모델, 나는이 주어졌을 때 밥을을 예측하는 것 처럼 이전 단어들이 주어질 때 다음 단어를 예측하는 것이다.
언어 모델을 만드는 방법은 통계를 이용한 방법과 인공 신경망을 이용한 방법 두 가지로 구분할 수 있다. 최근에는 인공 신경망을 이용한 방법의 성능이 더 좋다.
언어모델에 대해 더 자세한 사항 [참고 : 위키독스 언어모델]
실습하기
데이터 준비
shakespeare.txt 파일을 사용할 계획이다 (velog에 파일 올리는 법을 몰라 다음에 수정)
import re
import numpy as np
import tensorflow as tf
# 파일을 읽기모드로 열고 라인 단위로 끊어서 list 형태로 읽어옵니다.
file_path = 'shakespeare.txt'
with open(file_path, "r") as f:
raw_corpus = f.read().splitlines()
print(raw_corpus[:9])출력값
'First Citizen:', 'Before we proceed any further, hear me speak.', '', 'All:', 'Speak, speak.', '', 'First Citizen:', 'You are all resolved rather to die than to famish?', ''출력값을 보면 :로 끝나는 문장은 말하는 이(화자)이다. 지금 필요한 데이터는 공백과 화자의 말을 제외한 문장들이다
필요한 문장들만 다시 정리를 해보자
for idx, sentence in enumerate(raw_corpus):
if len(sentence) == 0:
continue
if sentence[-1] == ":":
continue
if idx > 9:
break
print(sentence)데이터 토큰화
텍스트 생성 모델을 만들기 위해서 토큰화(Tokenize)가 필요하다. 토큰화는 문장을 일정한 기준으로 쪼개서 단어에 숫자를 매칭 시키는 것이다.
예를 들어 I = 0, You = 1, He = 2와 같이 단어와 숫자를 묶어준다
하지만 토큰화에 문제점이 있는데
- 대소문자 :
Sound body sound mindSound와 sound는 다른 단어로 인식 - 특수문자 :
I am ten-years-oldten-years-old를 한 단어로 인식 - 문장부호 :
Hi, long time no seeHi,로 인식
문제를 해결하기 위해 전부 소문자로 바꾸고, 특수문자를 제거하고, 문장부호 양쪽에 공백을 추가한다.
def change_sentence(sentence):
sentence = sentence.lower().strip() # 소문자로 변경, 양쪽 공백 삭제
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence) # 특수문자 양쪽 공백 삽입
sentence = re.sub(r'[" "]+', " ", sentence) # 여러개의 공백 하나로
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence) # a-zA-Z?.!,¿가 아닌 문자를 하나의 공백으로 변경
sentence = sentence.strip() # 양쪽 공백 삭제
sentence = '<start> ' + sentence + ' <end>' # 문장 시작에 <start>, 끝에 <end>를 추가한다.
return sentence
print(change_sentence("This @_is ;;;sample sentence."))자연어 처리에서 입력이 되는 문장을 소스 문장(Source Sentence), 출력 문장을 타겟 문장(Target Sentence)라고 한다. 분류 할때 자주 사용하는 X_train, y_train과 같다.
위에서 만든 글을 정리해주는 함수를 통해 데이터를 정리하자
corpus = []
for sentence in raw_corpus:
if len(sentence) == 0:
continue
if sentence[-1] == ":":
continue
changed_sentence = change_sentence(sentence)
corpus.append(changed_sentence)
corpus[:10]공백과 :로 끝나는 문장들을 지운뒤 sentence에 담고 sentence는 change_sentence 함수를 사용해 정리했다 이후 corpus 리스트 안에 정리한 문장들을 담아준다.
인공지능이 이해할 수 있게 데이터를 숫자로 변환해주어야 한다.
텐서플로우의 tf.keras.preprocessing.text.Tokenizer패키지를 사용한다. 정제된 데이터를 토큰화해서 단어사전을 만들고, 데이터를 숫자로 변환까지 해준다.
이 과정을 벡터화(vectorize)라 하고, 숫자로 변환된 데이터를 텐서(tensor)라고 칭한다.
텐서플로우로 만든 모델의 입출력 데이터는 텐서로 변환돼 처리되는 것이다. [인공지능 개념] Tensor란 무엇인가?
def tokenize(corpus):
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=7000, filters='', oov_token="<unk>")
tokenizer.fit_on_texts(corpus)
tensor = tokenizer.texts_to_sequences(corpus)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
print(tensor, tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)코드 설명
- tokenizer
- num_words = 7000단어를 기억한다
- filters = 문장 정리, 이미 change_sentence 함수로 정리했으므로 패스한다.
- oov_token = 7000단어를 넘어가면
<unk>로 변경한다 tokenizer.fit_on_texts(corpus)문자 데이터(단어)를 입력받아 리스트의 형태로 변환tokenizer.texts_to_sequences(corpus)텍스트 안의 단어들을 숫자(정수) 시퀀스 형태로 변환
- tensor
- 입력 데이터 시퀀스 길이를 일정하게 맞춰준다
- padding = 시퀀스가 짧다면 문장 뒤에 패딩을 붙여 길이를 맞춰줌(앞에는 'pre'를 사용한다)
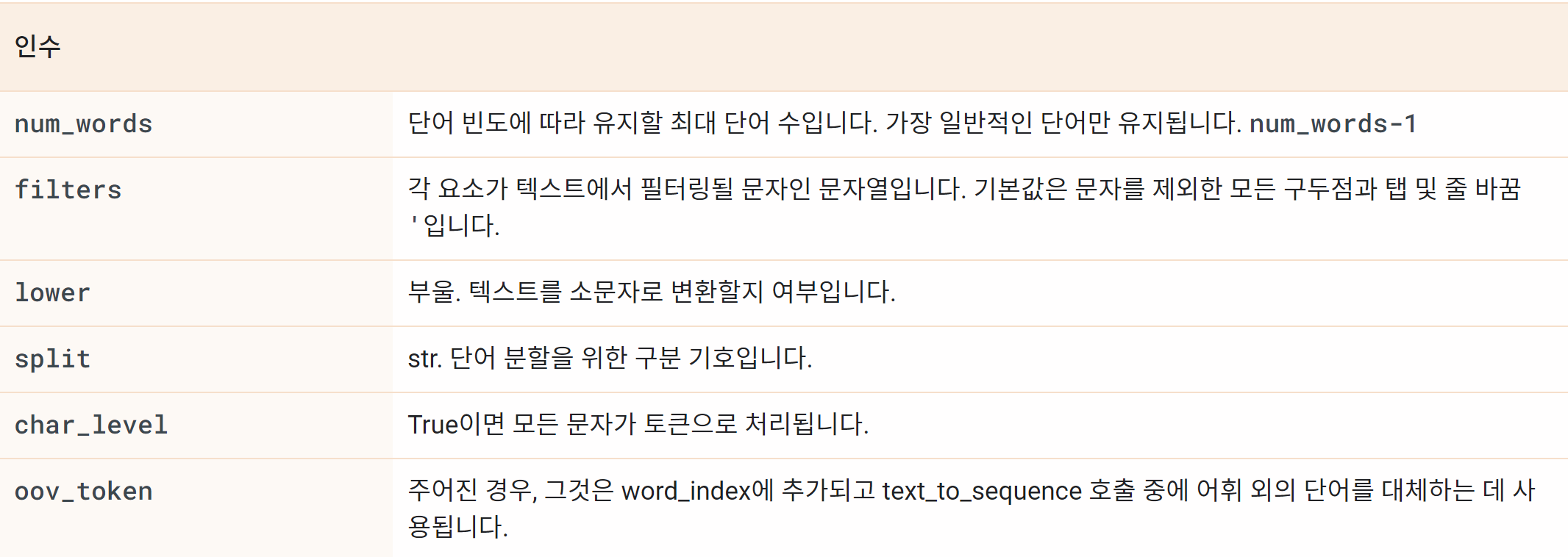
tf.keras.preprocessing.text.Tokenizer
tf.keras.preprocessing.text.Tokenizer( num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False, oov_token=None, document_count=0, **kwargs )
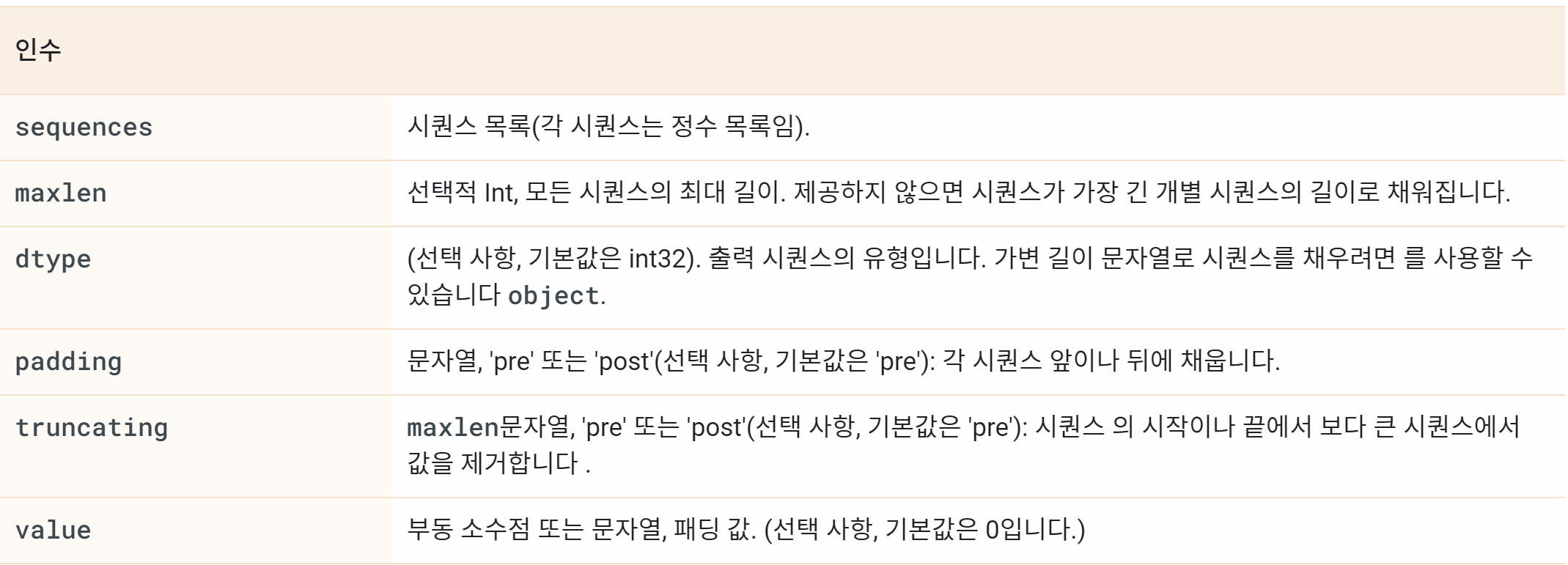
tf.keras.preprocessing.sequence.pad_sequences
tf.keras.preprocessing.sequence.pad_sequences( sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0 )
토큰화된 데이터 확인
생성된 텐서 데이터를 확인해보자
3개의 행, 10개의 열만 출력해본다
print(tensor[:3, :10])
출력
[[ 2 143 40 933 140 591 4 124 24 110]
[ 2 110 4 110 5 3 0 0 0 0]
[ 2 11 50 43 1201 316 9 201 74 9]]데이터는 모두 정수로 이루어져 있고, 이는 tokenizer에 구축된 단어 사전의 인덱스들이다.
단어 사전이 구축된 것을 확인해 보자
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx >= 10:
break
출력
1 : <unk>
2 : <start>
3 : <end>
4 : ,
5 : .
6 : the
7 : and
8 : i
9 : to
10 : of위의 텐서 데이터의 행의 시작이 2인 이유는 <start>가 2이기 때문이고 0 0 0 으로 이어지는 부분은 문장이 짧아 0으로 패딩을 채워넣었기 때문이다
이제 텐서플로우가 제공하는 모듈을 사용해 생성된 텐서를 source와 target으로 분리하여 모델을 학습시켜보자
source_input = tensor[:, :-1]
target_input = tensor[:, 1:]
print(source_input[0])
print(target_input[0])소스 문장은 맨 마지막 토큰을 잘라서 생성하고 타겟 문장은 맨 처음 <start>를 잘라서 생성했다.
첫 번째 문장을 확인해 보면
소스 문장은 2(<start>)로 시작해 3(<end>)로 끝난 후 0(padding)으로 채워져 있고, 타겟 문장은 2가 아닌 그 다음 열부터 시작하고 있다.
데이터셋 객체 생성하기
텐서플로우에서는 텐서로 생성한 데이터셋을 tf.data.Dataset객체로 만들 예정이다. tf.data.Dataset객체를 만들기 위해 tf.data.Dataset.from_tensor_slices()메서드를 사용한다.
BUFFER_SIZE = len(source_input)
BATCH_SIZE = 256
steps_per_epoch = len(source_input) // BATCH_SIZE
VOCAB_SIZE = tokenizer.num_words + 1
dataset = tf.data.Dataset.from_tensor_slices((source_input, target_input))
dataset = dataset.shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
datasetVOCAB_SIZE에 +1을 하는 이유는 단어사전 7000개에 padding(0)을 포함해줘야 한다
dataset은 데이터 소스로 부터 데이터셋을 만든다. 디테일은 Tensorflow Dataset 공식 문서에서 확인해 주십사
데이터셋 생성 정리
지금까지 한 일련의 과정이 데이터셋을 생성하기 위한 과정이고, 텐서플로우의 데이터 전처리라고 한다.
데이터셋을 생성하는 과정
- 정규표현식을 이용한 corpus 생성
tf.keras.preprocessing.texxt.Tokenizer를 이용해 corpus를 Tensor로 변환tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를tf.data.Dataset객체로 변환
모델 학습
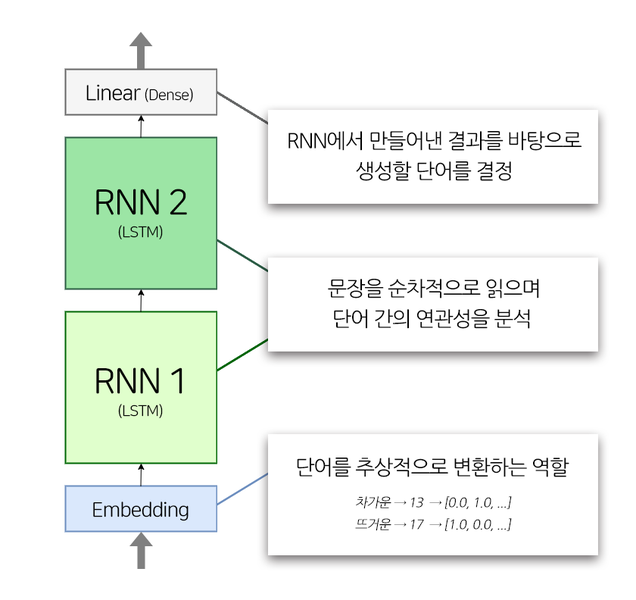
위 사진은 이제부터 만들려고 하는 모델의 구조도이다. 모델은 tf.keras.Model을 Subclassing하는 방식으로 만들 예정이다.
Subclassing은 어떤 객체의 일부 기능을 원하는 다른 기능으로 바꾸어주는 기법을 의미한다. 설명하자면 A라는 기능을 실행하도록 요청이 들어오면, 이를 B라는 기능으로 실행시키도록 객체를 바꿔주는 것이다
모델의 layer는 4개로 Embedding layer 1개, LSTM layer 2개, Dense layer 1개로 구성된다.
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.kears.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256
hidden_size = 1024
model = TextGenerator(tokenizer.num_words + 1, embedding_size, hidden_size)자연어 처리에서 사람의 언어를 기계가 이해하도록 숫자형태인 벡터로 바꿔주는 과정을 거친다 이를 Embedding이라고 한다.
입력 텐서(source_input)는 단어 사전의 인덱스를 포함한다. Embedding layer는 이 인덱스 값을 해당 인덱스 위치의 언어벡터(Word2Vec)로 바꿔준다. 자세한 설명은 [임베딩이란?] 블로그를 참고하자
embedding_size는 단어를 벡터로 표현할 차원의 수(단어가 표현되는 크기)이다.
값이 커질 수록 차원이 많아져 단어의 추상적인 특징들을 더 많이 찾을 수 있지만, 데이터 수가 모자라면 오히려 혼란을 야기할 수도 있다
hidden_size는 hidden state의 차원 수이다. hidden state는 RNN에서 기억을 담당하는데 지금까지 입력한 데이터를 요약한 정보라고 볼 수 있다. 따라서 hidden_size는 기억할 차원이 몇 개인가 정도로 생각하자.
model을 아직 빌드하지 않았다. 지금 이 모델을 빌드한다면 시간이 너무 오래걸리기 때문에 빌드하는 동안 미리 model 내부 데이터들을 확인하기 위해 다음 과정을 먼저 수행해보자
데이터를 아주 조금만 model에 태워서 build를 확인하는 방법이다
for source_sample, target_sample in dataset.take(1):
break
model(source_sample)model.summary()아래 코드를 실행하는데 시간이 많이 걸리기 때문에 위 코드를 먼저 실행하고 아래 코드를 실행한 후에 설명을 보면 시간을 아낄 수 있다.
먼저 모델의 최종 출력 텐서의 shape을 보면 shape=(256, 20, 7001)을 확인할 수 있다.
- 7001은 Dense layer의 출력 차원수로 7001개의 단어 중 어느 단어의 확률이 가장 높은지를 모델링 한다.
- 256은 배치 사이즈로 이전에
embedding_size로 지정해준 값이다. - 20은 LSTM이 입력된 시퀀스의 길이만큼 동일한 길이의 시퀀스를 출력한다는 말이다. 이는 아래에서 좀 더 자세히 설명하자
tf.keras.layers.LSTM(hidden_size, return_sequences=True)로 호출한 LSTM layer에서 return_sequences=True를 지정했기 때문에 동일한 시퀀스를 출력했다. 만약 False값을 입력했다면 1개의 벡터만 출력한다.
하지만 모델을 만들때 입력 데이터의 시퀀스 길이를 지정해주지 않았는데 어떻게 20이란 값이 나왔냐면 데이터셋의 max_len이 20으로 맞춰져 있었기 때문이다
모델 학습하기
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
model.compile(loss=loss, optimizer=optimizer)
model.fit(dataset, epochs=30)optimizer와 loss에 관한 자세한 자료는 공식문서를 참고하자
모델 평가
이제 모델 학습을 완료 했으니 평가를 해볼 차례이다.
하지만 작문의 경우 분류, 회귀 문제와 다르게 알고리즘이 평가하는 것은 많은 어려움이 있다. 이 모델을 가장 확실하게 평가하는 방법은 모델이 한 작문을 직접 평가해 보는 것이다.
generate_text 메서드는 모델에게 시작문장을 전달하면 모델이 시작 문장을 바탕으로 작문을 진행한다.
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
while True:
predict = model(test_tensor)
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1]
test_tensor = tf.concat([test_tensor, tf.expand_dims(predict_word, axis=0)], axis=-1)
if predict_word.numpy()[0] == end_token:
break
if test_tensor.shape[1] >= max_len:
break
generated = ""
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generatedtokenizer.texts_to_sequences, tf.convert_to_tensor, tokenizer.word_index = 테스트를 위해 입력한 init_sentence를 텐서로 변환한다.
while 문
- predict = 입력받은 문장의 텐서 입력
- predict_word = 예측된 값 중 갖장 높은 확률인 word index를 출력한다.
- 앞에서 예측한 word index를 문장 뒤에 붙인다.
- model이
<end>를 예측하거나, max_len에 도달하면 문장 생성을 마친다.
for 문
- tokenizer를 이용해 word index를 단어로 하나씩 변환한다.
그럼 이제 문장을 만들어보자. 함수를 실행한다
generate_text(model, tokenizer, init_sentence="<start> he")he를 대신해 다른 단어를 넣어보면서 여러가지 출력결과를 확인하자
start를 빼먹으면 안된다
