데이터 분석의 두 가지 접근 방법이 있다.
확증적 데이터 분석(CDA, Donfimatory Data Analysis) 가설을 설정한 후, 수집한 데이터로 가설을 평가하고 추정하는 전통적인 분석이다. 관측 형태나 효과의 재현성 평가, 유의성 검증, 신뢰구간 추정 등 통계적 추론을 하는 분석 방법으로 설문조사나 논문에 관한 내용을 입증하는데 사용된다.
CDA의 데이터 분석 과정은 가설 설정 - 데이터 수집 - 통계적 분석 - 가설 검증순서로 이루어진다
탐색적 데이터 분석(EDA, Exploratory Data Analysis) 가공되지 않은 데이터(raw data)를 가지고 유연하게 데이터를 탐색, 데이터의 특징과 구조로부터 얻은 정보를 바탕을 통계모형을 만드는 분석 방법이다. 빅데이터 분석에 사용된다.
EDA의 데이터 분석 과정은 데이터 수집 - 시각화 탐색 - 패턴 파악 - 인사이트 도출순으로 이루어진다
CDA는 추론 통계, EDA는 기술 통계로 나눠서 볼 수 있다.
오늘은 데이터 분석 실습을 통해 EDA를 연습해본다
데이터 구하기
포켓몬 데이터 셋을 구해야 한다. 데이터셋은 캐글(kaggle)이라는 데이터 분석 경진대회 사이트에서 빌려 쓸 예정이다.(캐글은 다양한 데이터셋을 구할 수 있는 사이트기 때문에 북마크해두는 것이 좋다.)
위 사이트를 확인하면 포켓몬 게임에 대한 설명이 적혀있고 11개의 feature(특성)이 있는 것을 알 수 있다.
목표는 일반 포켓몬과 전설 포켓몬을 분류하는 것이다
데이터 불러오기
데이터 불러오기에 앞서 사용할 라이브러리들을 import하자
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'seaborn은 matplotlib의 상위버전이다.
pokemon_csv = 'data/Pokemon.csv'
original_data = pd.read_csv(pokemon_csv)
pokemon = original_data.copy()
print(pokemon.shape)
pokemon.head()csv 파일을 pandas로 읽어온 후 원본 데이터는 그대로 두고 pokemon이라는 변수에 새로 복사해서 저장
위 같이 원본을 따로 두는 이유는 원본 데이터를 훼손하지 않기 위해서이다.
shape을 통해 총 800마리의 포켓몬과 13개의 특성(feature)이 있는 것을 확인할 수 있다.
이제 이 데이터를 통해 간지나는 전설의 포켓몬을 구별해보자
Legendary의 값이 True인 포켓몬은 legendary 변수에 담고, False인 값은 ordinary 변수에 담는다
legendary = pokemon[pokemon["Legendary"] == True].reset_index(drop=True)
ordinary = pokemon[pokemon["Legendary"] == False].reset_index(drop=True)
print(legendary.shape)
print(ordinary.shape)
legendary.head()
ordinary.head()전설의 포켓몬은 총 800마리 중 65마리 밖에 되지 않는 것을 확인할 수 있다.
데이터 확인
데이터셋을 이제 하나씩 확인해 보는 작업을 해보자
전설의 포켓몬을 구별하기 위해서는 데이터 자체를 잘 이해하는 것이 중요하다
결측치 확인
데이터를 다루기 전 가장 우선으로 해야할 것은 결측치(비어있는 데이터)를 확인하는 것이다.
pokemon.isnull().sum()Type 2 컬럼에만 꽤나 많은 결측치가 있다 총 386개로 Type 1이 있는 것으로 유추해보면 한 가지 속성만 가진 포켓몬들이 386마리가 있다고 생각해볼 수 있다.
결측치는 데이터셋의 성격에 따라 다루는 방법이 달라진다. 데이터를 조금 더 살펴보고 어떻게 해결할지 생각해보자
전체 컬럼 이해
데이터셋의 컬럼을 출력해보자
print(len(pokemon.columns))
pokemon.columns각 컬럼의 설명은 캐글 사이트에서 확인할 수 있었다.
#: 각 포켓몬의 아이디(번호)- Name : 각 포켓몬의 이름
- Type 1 : 첫 번째 속성
- Type 2 : 두 번째 속성, 위에서 확인했듯이 속성이 하나면 Type 2는 결측치가 된다
- Total : 아래의 6개의 스텟의 합계
- HP : 체력
- Attack : 공격력
- Defense : 방어력
- SP Atk : 특수 공격 skill
- SP Def : 특수 공격에 대한 방어력
- Speed : 공격 속도 높은 포켓몬이 먼저 공격한다
- Generation : 포켓몬 세대, 1세대, 2세대로 구분. 총 6세대까지
- Legendary : 전설의 포켓몬 여부
하나씩 살펴보자
중복을 확인하기 위해서
python의 set(집합 자료형)을 사용해 중복이 없는 데이터를 만들고 길이를 확인해 본다
# : ID Number
len(set(pokemon["#"]))id가 총 721개가 나온다. 총 데이터 수는 800인데 왜 721개 밖에 나오지 않을까??
이는 id를 중복으로 가지는 컬럼들이 있다는 것을 알 수 있다.
pokemon[pokemon["#"] == 6]샘플로 id가 6번인 포켓몬을 보면 Charizard, CharizardMega Charizard X, CharizardMega Charizard Y
Charizard은 리자몽이다. 리자몽, 리자몽의 진화인 메가리자몽이 있다. X,Y는 성별이다.
Name
len(set(pokemon["Name"]))이름은 800으로 중복된 데이터가 없는 것을 알 수 있다.
Type 1, 2
pandas의 loc[]을 사용해 행 두개를 가져온다(loc[]은 행,열 조회함수 pandas loc[]
pokemon.loc[[6, 10]]6번 Charizard(리자몽)은 Fire, Flying 두 개의 속성을 가지고, 10번 Wartortle(어니부기)은 Water 한 개의 속성만 가진다. 속성이 한 개면 Type 2 는 NaN 값이 들어간 것을 확인 할 수 있다.
그럼 각 속성의 종류가 총 몇 가지인지 확인해보자
len(list(set(pokemon["Type 1"]))), len(list(set(pokemon["Type 2"])))Type 1 = 18가지, Type 2 = 19가지 속성이 들어있는데 Type 2가 한 개 더 많다
한 개 더 많은 속성이 무엇인지 알아보자
set함수를 통해 집합으로 만들고 차집합을 확인해보자
set(pokemon["Type 2"]) - set(pokemon["Type 1"])Type 2의 한개 더 많던 속성은 NaN 값임을 확인해 볼 수 있다. 나머지 18개는 1, 2 모두 같은 것도 확인할 수 있다.
포켓몬 모든 Type을 types 변수에 저장 (속성 1, 2 모두 같아 한개만 저장함)
types = list(set(pokemon["Type 1"]))
print(len(types))
print(types)Type이 하나인 포켓몬이 몇 마리인지 구해보자. Type이 하나면 Type 2는 NaN의 값을 가지고 있을테니 Type 2가 NaN인 포켓몬의 수를 구하면 된다.
NaN 값의 개수는 Pandas의 isna()함수를 사용하면 쉽게 구할 수 있다
pokemon["Type 2"].isna().sum()총 386 마리의 포켓몬이 하나의 속성만을 가지고 있다.
Type 1 데이터 분포
이번엔 일반 포켓몬과 전설 포켓몬의 각 속성 분포도를 확인해보려고 한다
전설의 포켓몬은 100마리가 채 안되니 따로 시각화 해주자
plt.subplot으로 두 개의 그래프를 그리고, 그래프는 sns(seaborn).countplot로 표시한다.
countplot은 이름대로 개수를 표시한다
plt.figure(figsize=(14, 7))
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 1", order=types).set_xlabel('')
plt.title("[Ordinary Pokemon]")
plt.subplot(212)
sns.countplot(data=legendary, x="Type 1", order=types).set_xlabel('')
plt.title("[Legendary Pokemon]")
plt.show()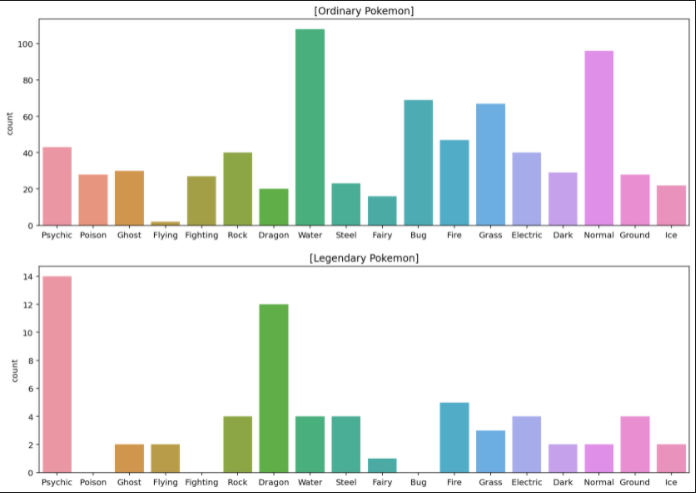
일반 포켓몬과 전설 포켓몬이 따로따로 그래프로 나타났고 속성에 대한 비율도 다른 것을 볼 수 있다. (전설 포켓몬이 dragon, psychic 같이 간지나는게 비중이 높다)
이번엔 pivot table로 각 속성에 전설 포켓몬이 몇 퍼센트를 차지하는지 확인해보자
sort_value를 활용해 내림차순으로 정렬한다
pd.pivot_table(pokemon, index="Type 1", values="Legendary").sort_value(by=["Legendary"], ascending=False)Type 2 데이터 분포
Type 2에 대한 전설 포켓몬의 비율도 확인해 보자
위와 똑같은 방법을 통해 확인 할 수 있다. (Countplot은 결측값을 자동으로 제외해준다)
plt.figure(figsize=(14, 7))
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 2", order=types).set_xlabel('')
plt.title("[Ordinary Pokemon]")
plt.subplot(212)
sns.countplot(data=legendary, x="Type 2", order=types).set_xlabel('')
plt.title("[Legendary Pokemon]")
plt.show()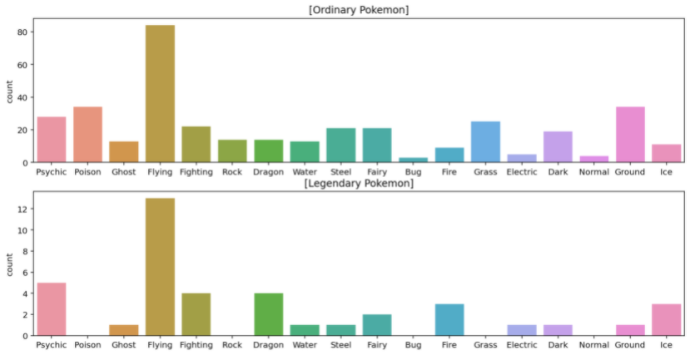
여전히 간지안나는 속성들은 전설포켓몬에 많이 없는 것을 볼 수 있다.
pivot table
pd.pivot_table(pokemon, index="Type 2", values="Legendary").sort_values(by=["Legendary"], ascending=False)Total
아래에 나올 총 6가지 스텟의 총합이다
각각 6개 스텟의 총합이 제공된 Total 데이터와 일치하는지 확인하기 위해 우선 stats이라는 변수에 모든 스텟을 담는다.
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
stats이제 각 스텟과 Total데이터를 확인해보자
print("0번째 포켓몬 : ", pokemon.loc[0, "Name"])
print("Total : ", int(pokemon.loc[0, "Total"]))
print("stats : ", list(pokemon.loc[0, stats]))
print("stats 총 합 : ", sum(list(pokemon.loc[0, stats])))Total과 stats의 총합이 318로 일치한다
이제 전체 데이터에 대한 Total과 stats 총합을 확인해보자
sum(pokemon['Total'].values == pokemon[stats].values.sum(axis=1))axis=1은 포켓몬 한 마리당 가로로 계산을 더해야 되기 때문에 지정해 준 값이다
.values는 DataFrame의 값만 반환해준다
Total에 대한 plot을 확인해보자
fig, ax = plt.subplots()
fit.set_size_inches(14,10)
sns.scatterplot(data=pokemon, x="Type 1", y="Total", hue="Legendary")
plt.show()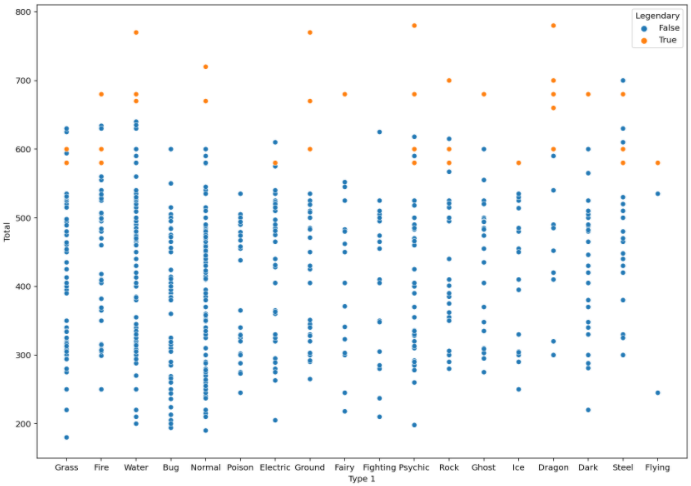
hue="Legendary"를 통해 전설 포켓몬은 따로 표시하도록 해줬다
결과 값을 보면 대체적으로 전설 포켓몬의 Total 스텟 값이 높은 것을 확인할 수 있다.
Stats
이제 남은 세부 스텟들을 확인해보자
각각의 스텟을 한번에 확인하기 위해 subplot을 사용한다
figure, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2)
figure.set_size_inches(14, 18)
sns.scatterplot(data=pokemon, y="Total", x="HP", hue="Legendary", ax=ax1)
sns.scatterplot(data=pokemon, y="Total", x="Attack", hue="Legendary", ax=ax2)
sns.scatterplot(data=pokemon, y="Total", x="Defense", hue="Legendary", ax=ax3)
sns.scatterplot(data=pokemon, y="Total", x="Sp. Atk", hue="Legendary", ax=ax4)
sns.scatterplot(data=pokemon, y="Total", x="Sp. Def", hue="Legendary", ax=ax5)
sns.scatterplot(data=pokemon, y="Total", x="Speed", hue="Legendary", ax=ax6)
plt.show()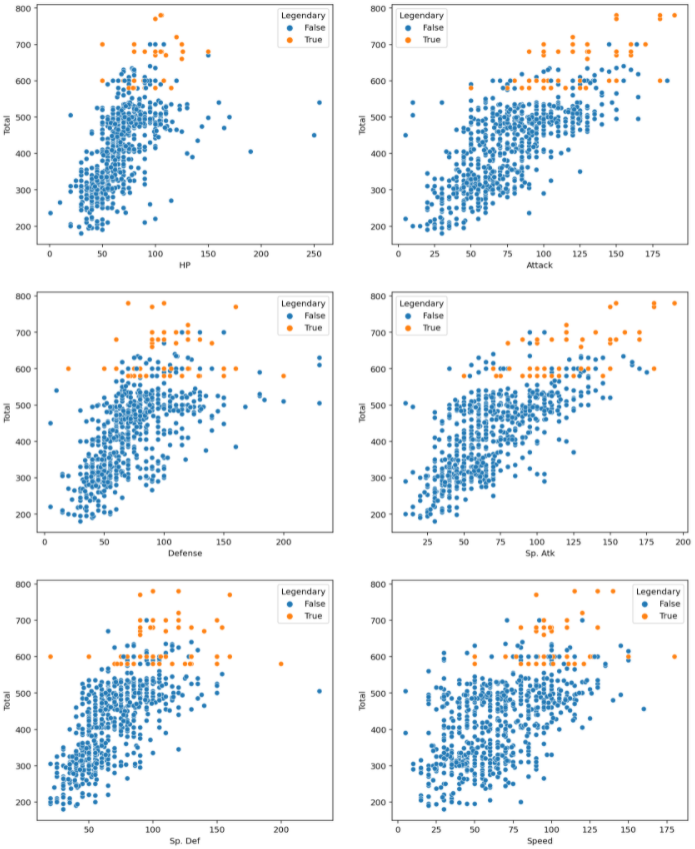
위 결과 표를 보면서 하나씩 살펴보자
전체적으로 보면 대부분 Total 값은 전설의 포켓몬들이 높은 수치를 보이고 있지만
세부적으로 HP, Defense, Sp. Def 수치만 봤을때는 전설의 포켓몬 보다 높은 값을 가지고 있는 포켓몬이 있다. 하지만 Total 값은 낮으므로 그 스텟에 특화된 포켓몬으로 보인다.
그 외에는 전설의 포켓몬이 압도적으로 우위를 점하고 있다
Generation
이번엔 포켓몬 세대로 각 세대에 대한 포켓몬 수를 확인해 보자
plt.figure(figsize=(14, 10))
plt.subplot(211)
sns.countplot(data=ordinary, x="Generation").set_xlabel('')
plt.title("[All Pokemons]")
plt.subplot(212)
sns.countplot(data=legendary, x="Generation").set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show()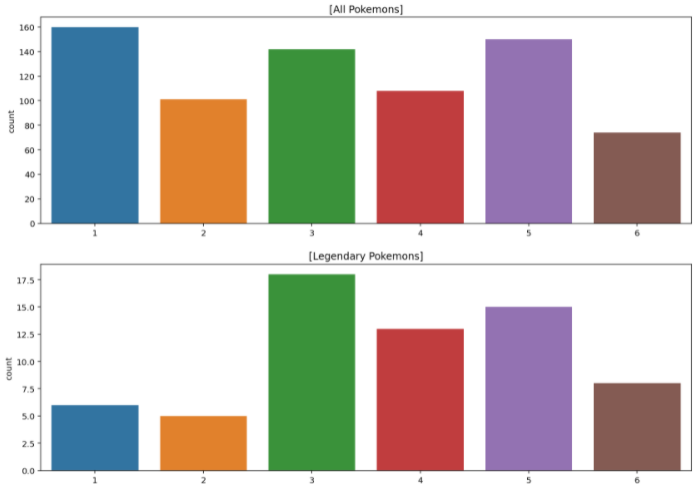
초창기에는 전설이 진짜 전설이였다가 점점 전설이 많아 진 것을 볼 수 있다.
분석하기
이제 다시 원래의 목표대로 일반 포켓몬과 전설 포켓몬을 분류하는 것이니 각각의 특징들을 세분화해서 확인해보자
전설의 Total
전설 포켓몬의 속성에 대한 Total값을 확인해보자
fig, ax = plt.subplots()
fig.set_size_inches(8,4)
sns.scatterplot(data=legendary, y="Type 1", x="Total")
plt.show()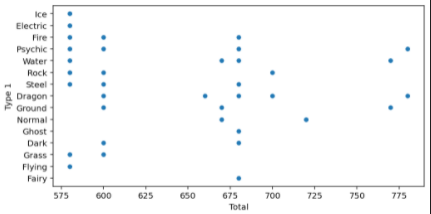
x축은 Total의 값들인데 같은 Total값을 가지는 전설 포켓몬들이 많다.
전설의 포켓몬들의 Total값의 집합을 확인해보자
print(sorted(list(set(legendary["Total"]))))Total 값은 총 9가지 밖에 안된다. 같은 Total 값을 가지는 포켓몬의 수를 확인해보자
fig, ax = plt.subplots()
fig.set_size_inches(14, 10)
sns.countplot(data=legendary, x="Total")
plt.show()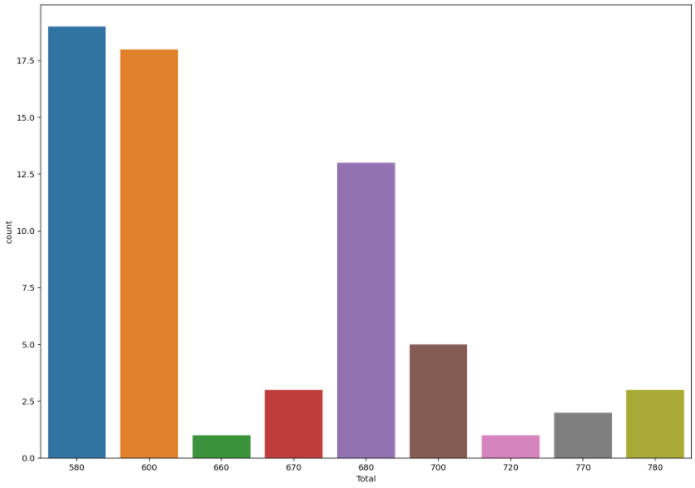
그럼 일반 포켓몬의 Total값은 어떻게 분포되어 있는지 확인해보자
print(sorted(list(set(ordinary["Total"]))))
print(len(sorted(list(set(ordinary["Total"])))))일반 포켓몬의 Total값은 다양하게 분포되어 약 195가지의 값이 나온다
그럼 각각의 비율을 생각해보면 전설은 65마리, 일반은 735마리 임으로
- 전설 : , 약 7.22 마리는 같은 Total 값을 가진다.
- 일반 : , 약 3.77 마리만 같은 Total 값을 가진다.
위 과정을 통해 두 가지를 알 수 있다
- 일반 포켓몬은 Total 값이 다양하고, 전설 포켓몬은 Total 값이 다양하지 않다
- 포켓몬의 Total값이 전설 포켓몬 Total 값의 집합에 포함되는지를 통해 전설 포켓몬을 유추할 수 있다
- 전설 포켓몬의 Total 값은 일반 포켓몬은 가지지 못하는 Total 값이 존재한다
- Total 값을 통해 전설인지 아닌지를 판단하는데 영향을 줄 수 있다.
- 결론적으로 Total 값은 전설을 분류하는데 유의미한 컬럼이다
전설의 이름
포켓몬들은 이름이 유사하거나 특정단어가 들어가 있는 경우가 있다
- 예를 들어
- 이상해씨(Bulbasaur), 이상해풀(Ivysaur), 이상해꽃(Venusaur)처럼 한국식으로는
이상해지만 영어로는saur이 공통되는 것을 볼 수 있다 - 파이리(Charmander), 리자몽(Charmeleon), 리자몽(Charizrd)은 한국이름엔
리가 공통되고 영어로는Char이 공통되는 것을 확인 할 수 있다
- 이상해씨(Bulbasaur), 이상해풀(Ivysaur), 이상해꽃(Venusaur)처럼 한국식으로는
전설 포켓몬도 위 예시처럼 비슷한 이름을 가지는지 확인해보자
n1, n2, n3, n4, n5 = legendary[3:6], legendary[14:24], legendary[25:29], legendary[46:50], legendary[52:57]
names = pd.concat([n1,n2,n3,n4,n5]).reset_index(drop=True)
names각각 이름이 비슷한 전설 포켓몬들을 슬라이싱 해서 에 넣어준다 그리고 pd.concat으로 합쳐준다
출력값을 확인하면 이름들이 거의다 비슷비슷하다.
앞에서 name 컬럼을 확인했을 때는 전부 다른 값을 가진 것을 확인했었다. 위를 보면 이름은 다르지만 유사한 형태를 가지고 있는 것을 알 수 있다.
각각 비슷한 것끼리 같은 이름을 공유하고 있다 ex) Mewtwo, Latias, Kyogre...등
그리고 위 표를 보면 마지막 이름에 forme가 들어가는 전설의 포켓몬이 다수 있다
formes = names[13:23]
formes그리고 전설의 이름 특징 중 하나는 딱봐도 길이가 길어보이는 점도 있다.
데이터셋에 이름 길이 컬럼을 생성해서 비교해 보자
legendary, ordinary 모두에게 name_len 이름의 길이를 나타내는 컬럼을 만들어준다.
lambda를 사용해 행마다 길이를 구하고 name_len 컬럼에 넣어준다.
legendary["name_len"] = legendary["Name"].apply(lambda i: len(i))
ordinary["name_len"] = ordinary["Name"].apply(labmda i: len(i))
print(legendary.head())
print(ordinary.head())name_len 컬럼의 특징을 확인해보자
plt.figure(figsize=(14,10))
plt.subplot(211)
sns.countplot(data=legendary, x="name_len").set_xlabel('')
plt.title("Legendary")
plt.subplot(212)
sns.countplot(data=ordinary, x="name_len").set_xlabel('')
plt.title("Ordinary")
plt.show()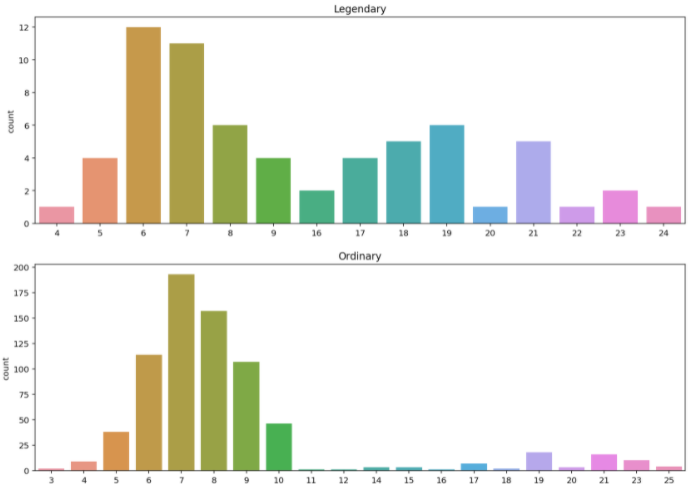
출력된 그래프를 보면 전설 포켓몬은 len가 16이상인 포켓몬이 많지만, 일반 포켓몬은 len가 11 이상인 포켓몬이 적다
전설 포켓몬, 일반 포켓몬 이름이 10 이상인 비율을 확인해보자
print(round(len(legendary[legendary["name_len"] > 9]) / len(legendary) * 100, 2), "%")
print(round(len(ordinary[ordinary["name_len"] > 9]) / len(ordinary) * 100, 2), "%")전설 포켓몬의 len이 10 이상인 비율은 약 41%를 정도이고, 일반 포켓몬은 len이 10 이상인 비율은 약 16% 정도이다
이름 분석을 통해 세 가지 특징을 알 수 있다
- 만약 "Latios"가 전설 포켓몬이면 "~~~Latios"도 전설 포켓몬이다
- 전설 포켓몬은 높은 빈도를 보이는 이름들의 모임이 존재한다
- 전설 포켓몬은 긴 이름을 가졌을 확률이 높다
데이터 전처리
항상 데이터 분석을 할때는 데이터를 모델에 입력할 수 있는 형태로 변환하는 것이 매우 중요하다.
머신러닝 모델은 문자열 데이터를 처리할 수 없어 숫자 데이터 또는 부울 데이터 등으로 전처리 해줘야 한다.
이름 컬럼을 모델이 연산할 수 있는 형태로 처리해보려고 한다
- 이름의 길이 :
name_len컬럼 생성 후 길이가 10을 넘는지 아닌지에 대한 categorical 컬럼을 생성한다 - 토큰 추출 : 전설 포켓몬에서 많이 등장하는 토큰을 추려내고 토큰 포함 여부를 원-핫 인코딩으로 처리한다
이름의 길이
아까와 같이 name_len 컬럼을 생성하지만 이번엔 전체 데이터가 있는 pokemon 데이터 프레임에 생성한다. 또 name_len이 10 이상은 True, 미만은 False를 가지는 long_name컬럼도 생성한다.
pokemon["name_len"] = pokemon["Name"].apply(lambda i: len(i))
print(pokemon.head())
print("----------------------------------------------------")
pokemon["long_name"] = pokemon["name_len"] >= 10
print(pokemon.head())포켓몬 분류에 있어 이름의 길이 값인 name_len과 불 값을 가진 long_name 둘 중 어떤 것이 더 좋은 결과를 보여줄지는 모른다
이름 토큰
이번엔 포켓몬 이름에 많이 쓰이는 토큰을 찾아보고 이에 대해 새로운 컬럼을 만든다.
포켓몬 이름은 총 네 가지 유형이 있다
- 한 단어일 경우 : Diancie
- 두 단어일 경우 : DiancieMega Diancie (앞 단어 두 개의 대문자, 대문자를 기준으로 나뉜다)
- 두 단어에 성별 표시 : CharizardMega Charizard X(또는 Y)
- 알파벳이 아닌 문자를 포함하는 경우 : Zygarde50% Forme
알파벳이 아닌 문자
우선 알파벳이 아닌 문자를 포함할때 전처리한다.
pandas의 isalpha() 함수를 사용하면 손쉽게 구해낼 수 있다.
isalpha()는 띄어쓰기도 문자를 포함하고 있다고 처리된다(False)
따라서 먼저 띄어쓰기가 없는 컬럼을 따로 만들어주고 띄어쓰기를 빈칸으로 처리한다
pokemon["Name_nospace"] = pokemon["Name"].apply(lambda i: i.replace(" ", ""))
pokemon.tail()isalpha() 함수를 사용해 이름이 알파벳으로만 이루어져있는지 확인해보자
pokemon["name_isalpha"] = pokemon["Name_nospace"].apply(lambda i : i.isalpha())
pokemon.head()알파벳이 아닌 다른 문자가 이름에 포함된 것들 확인하기
print(pokemon[pokemon["name_isalpha"] == False].shape)
pokemon[pokemon["name_isalpha"] == False]9마리 정도가 알파벳이 아닌 문자를 포함하고 있다
이 처럼 소규모일때는 직접 이름을 바꿔도 무리가 없다
문자열을 다른 문자열로 바꿀 때는 pandas의 replace 함수를 사용한다
pokemon = pokemon.replace(to_replace="Nidoran♀", value="Nidoran X")
pokemon = pokemon.replace(to_replace="Nidoran♂", value="Nidoran Y")
pokemon = pokemon.replace(to_replace="Farfetch'd", value="Farfetchd")
pokemon = pokemon.replace(to_replace="Mr. Mime", value="Mr Mime")
pokemon = pokemon.replace(to_replace="Porygon2", value="Porygon")
pokemon = pokemon.replace(to_replace="Ho-oh", value="Ho Oh")
pokemon = pokemon.replace(to_replace="Mime Jr.", value="Mime Jr")
pokemon = pokemon.replace(to_replace="Porygon-Z", value="Porygon Z")
pokemon = pokemon.replace(to_replace="Zygarde50% Forme", value="Zygarde Forme")
pokemon.loc[[34, 37, 90, 131, 252, 270, 487, 525, 794]]다시 isalpha를 사용하여 빠진 것이 있는지 확인해보자
위 Name을 Name_nospace로 만들고 alpha로 확인하는 과정을 다시 한번한다
pokemon["Name_nospace"] = pokemon["Name"].apply(lambda i : i.replace(" ", ""))
pokemon["name_isalpha"] = pokemon["Name_nospce"].apply(lambda i : i.replace())
pokemon[pokemon["name_isalpha"] == False]name_isalpha 컬럼이 False인 컬럼이 없어졌다. 이제 모든 포켓몬의 이름이 알파벳으로만 이루어 진 것을 알 수 있다.
이름 토큰화하기
이제 이름을 세 가지 타입으로 토큰화할 수 있다
문자열을 처리할때는 정규표현식(RegEx: Regular Expression)이라는 것이 사용된다.
정규표현식은 문자열을 처리하는 방법 중 하나로 특정 조건의 문자를 '검색 또는 치환하는 과정을 매우 간편하게 처리할 수 있도록 도와준다
정규표현식에 대해 정확히 알고 싶다면 위키독스 정규 표현식, 생활코딩 정규표현식을 참고하자
정규표현식은 re 모듈을 import 해준다
이제 이름을 쪼개서 리스트를 만들어 주려고 한다.
이해를 돕기 위해 간단한 예제를 먼저 실행해보자
import re
name = "CharizardMega Charizard X"우선 공백을 기준으로 나눠보자 split()은 문자열을 공백을 기준으로 나눠 리스트를 만든다.
name_split = name.split()
name_split이 다음은 CharizardMega를 나눠 줘야한다. 대문자를 기준으로 분리를 해보자
temp = name_split[0]
temp우선 CharizardMega를 temp에 넣어주고 findall를 사용해 대문자로 시작해서 소문자로 끝나는 패턴을 찾아 나눠준다
tokens = re.findall('[A-Z][a-z]*', temp)
tokens위의 [A-Z][a-z]*이 정규표현식이다
- [A-Z] : A-Z 대문자 중 한 가지로 시작
- [a-z] : 대문자 뒤로 a-z 소문자 중 하나가 붙는다
*: 앞의 소문자가 반복(*는 정규표현식에서 반복을 뜻 한다)
위 과정을 tokens 리스트에 담아보자
tokens = []
for part_name in name_split:
a = re.findall('[A-Z][a-z]*', part_name)
tokens.extend(a)
tokens위 코드는 한 개의 이름만 토큰화하는 코드다. 전체 데이터셋에 적용할 수 있도록 한다.
def tokenize(name):
name_split = name.split(" ")
tokens = []
for part_name in name_split:
a = re.findall('[A-Z][a-z]*', part_name)
tokens.extend(a)
return np.array(tokens)
all_tokens = list(legendary["Name"].apply(tokenize).values)
token_set = []
for token in all_tokens:
token_set.extend(token)
print(len(set(token_set)))
print(len(token_set))
print(token_set)총 120개의 토큰이 있고, set을 통해 중복을 제외하면 65개의 토큰이 있다.
가장 많이 사용된 토큰을 추출해보자
list, set 자료형에서 각 요소의 개수를 다룰때는 collections라는 패키지를 사용한다
collections는 데이터 전처리나 효율적 자료 구조 설정에서 많이 활용되기 때문에 잘 알아두는 것이 좋다. 코딩하는 금융인 : 파이썬 collections 컨테이너형 자료 모듈], 파이썬 공식문서 collections
collections의 Counter를 사용해볼 예정이다
간단한 예시를 확인해보자
import collections
scores = ['A', 'B', 'B', 'C', 'C', 'D', 'A']
counter = collections.Counter(scores)
print(counter)scores에 리스트로 담겨 있는 값들을 collections의 Counter를 사용하게 되면
Counter({'A': 2, 'B': 2, 'C': 2, 'D': 1})와 같이 딕셔너리 형태의 Counter 객체를 가진다.
더 나아가 most_common을 사용하면 가장 많이 있는 요소와 개수를 보여준다
counter = collections.Counter(scores).most_common()
print(counter)출력 : [('A', 2), ('B', 2), ('C', 2), ('D', 1)]
이제 token_set에 사용해본다. (most_common을 통해 10개만)
from collections import Counter
most_common = Counter(token_set).most_common(10)
most_common마지막으로 전설의 포켓몬 이름에 해당하는 토큰이 포켓몬의 이름에 있는지 확인하는 컬럼을 만든다.
특정 구문이 포함되어 있는지 확인할 때는 pandas의 str.contains함수를 사용한다
for token, _ in most_common:
pokemon[f"{token}"] = pokemon["Name"].str.contains(token)
pokemon.head(10)지금까지 문자열들을 전처리를 통해 부울 데이터로 변환시켰다.
범주형 데이터 전처리
이제 범주형 데이터인 Type 컬럼을 처리하려고 한다.
두 가지 규칙으로 범주형 데이터를 전처리한다.
- 18가지 모든 Type을 원-핫 인코딩(One-Hot Encoding)한다.
- 원-핫 인코딩이란 주어진 카테고리중 하나만 1(True) 나머지는 모두 0(False)으로 표현하는 인코딩 방식이다
- 두 가지 속성을 가진 포켓몬은 두 가지 Type에 해당하는 자리에서 1의 값을 가지게 한다.
원-핫 인코딩에 대해서 더 자세한 설명 wikidocs 원-핫 인코딩
범주형 데이터 전처리에 대한 자세한 설명 머신러닝3. 범주형 데이터 전처리 (Label Encoding, One-Hot Encoding)
우선 앞에서 만든 Type의 리스트인 types를 확인해보자
print(types)이제 원-핫 인코딩을 해준다
for t in types:
pokemon[t] = (pokemon["Type 1"] == t) | (pokemon["Type 2"] == t)
pokemon[[["Type 1", "Type 2"] + types][0]].head()확인해 보면 Type에 해당하는 컬럼에만 True가 있는 것을 확인할 수 있다.
모델 만들기
데이터 전처리까지 마무리 했으니 이제는 모델을 준비할 차례이다.
베이스라인
베이스라인은 가장 기초적인 방법으로 만든 모델로 지금까지 생성했던 컬럼들이 아닌 처음 데이터를 불러왔을 때 있던 컬럼들만 사용해서 만드는 모델이다
베이스라인을 만드는 이유는 성능 하한선을 통해 새롭게 만든 모델들이 제대로 동작하는지 확인할 수 있게 도와준다. 기본적으로 베이스라인보다는 성능이 좋게 나와야 한다.
베이스라인은 우리가 따로 저장해둔 original_data를 사용한다.
print(original_data.shape)
original_data.head()컬럼 확인
original_data.columns위 컬럼 중에서 #와 문자열 데이터인 Name, Type 1, Type 2 데이터는 제외하고 사용하고 Legendary는 target 데이터에 넣어준다.
features = ['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation']
target = 'Legendary'이제 모델에 넣어주기 위해서 X에 features 데이터를 y에 target 데이터를 담아준다.
X = original_data[features]
y = original_data[target]
print(X.shape)
print(y.shape)
print(X.head())
print("-------------")
print(y.head())다음은 모델 학습을 위해 훈련 데이터와 학습 데이터로 분리한다
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=15)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)이제 학습을 위해 데이터 분리까지 모두 끝났다
분류 모델로 의사 결정 트리(Decision Tree)를 사용한다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=25)
model모델을 불러왔으니 학습시키고, 예측까지 한다.
model.fit(X_train, y_train)
y_pred = model.predict(X_test)이제 정답인 y_test와 비교해본다. Confusion Matrix(오차행렬)을 통해 확인한다.
Confusion Matrix(오차행렬)이란?
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)4가지 값이 나온다 이는 아래 그림과 같다.
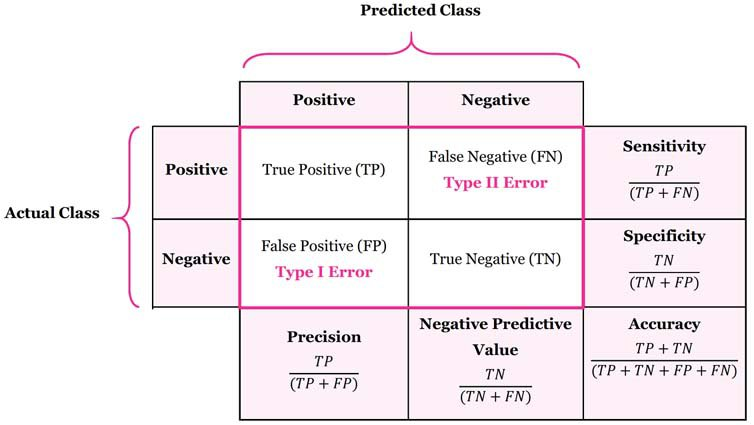
위 그림을 기반으로 Positive는 전설의 포켓몬, Negative는 일반 포켓몬이라고 생각하면 된다.
각각의 값은 아래와 같다
- TP(True Positive) : 전설을 전설로 옳게 판단 - 144
- FN(False Negative) : 전설을 일반으로 잘 못 판단 - 3
- FP(False positive) : 일반을 전설로 잘 못 판단 - 5
- TN(True Negative) : 일반을 일반으로 옳게 판단 - 8
더 자세한 설명은 앞서 데이터 분류에 대해 정리해놓은 부분에서 맨 아래 정답과 오답의 종류를 참고
정확도
일반적으로 모델을 평가할 때 정확도(accuracy)를 많이 사용하는데
정확도는 데이터가 불균형할 때는 별로 좋지 않다.
지금 포켓몬 데이터의 경우는 전설은 총 65마리로 735마리에 비하면 매우 불균형하다고 볼 수 있다. 따라서 정확도가 아닌 다른 값들을 사용해서 성능을 평가하는 것이 좋다.
정확도 대신 다른 척도들을 사용하기 위해 classification_report를 활용한다
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))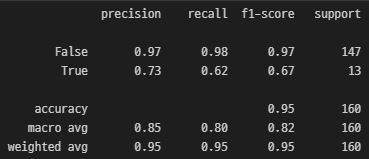
지금 포켓몬 데이터와 같이 데이터가 불균형할때는 적은 양을 가진 Positive 데이터(전설 포켓몬)를 잘 잡아내는 것이 중요하다. 따라서 FN값이 낮을 수록 좋고 FN값을 계산에 사용하는 Recall 값이 높을 수록 좋다
Feature Engineering
이제 베이스라인이 아닌 우리가 특성들을 만들어주고 전처리한 데이터를 사용해보자
앞서 우리가 특성을 추가하고 수정하고 전처리한 과정을 Feature Engineering이라고 한다.
우선 컬럼을 확인해보자
print(len(pokemon.columns))
print(pokemon.columns)원본은 13개의 컬럼밖에 없었지만 지금은 45개로 늘어났다
이 컬럼들을 우선 정리해보자
#, Name, Type 1, Type 2, Name_nospace, Name_isalpha 이 6가지는 문자열로 모델에 사용할 수 없어서 제외해준다 Legendary는 target이므로 빼준다
features = ['Total', 'HP', 'Attack', 'Defense','Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'name_count','long_name', 'Forme', 'Mega', 'Mewtwo','Kyurem', 'Deoxys', 'Hoopa', 'Latias', 'Latios', 'Kyogre','Groudon','Ice', 'Fighting', 'Dark', 'Ground', 'Grass', 'Ghost', 'Dragon','Steel', 'Flying', 'Fairy', 'Water', 'Bug', 'Electric', 'Rock','Normal', 'Psychic', 'Fire', 'Poison']
len(features)7개를 빼고 총 38개만 남았다
나머지는 위에서 베이스라인을 할때와 같은 과정을 거친다
target = "Legendary"
X = pokemon[features]
y = pokemon[target]
print(X.shape)
print(y.shape)
print(X.head())
print("------------------")
print(y.head())X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=15)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)model = DecisionTreeClassifer(random_state = 25)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
confusion_matrix(y_test, y_pred)
print(classification_report(y_test, y_pred))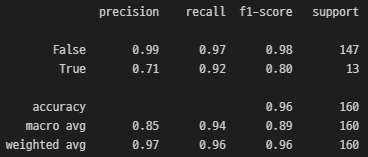
위 베이스라인에서 0.62 밖에 나오지 않던 True에 대한 recall 값이 0.92로 높은 상승률을 보인다.
