🔴 목 표
사전학습된 모델(VGG16, ResNet, MobileNet)을 활용해 강아지, 고양이 분류하고 파인튜닝을 통해 모델 학습 성능을 개선시키기
※ Google Colab에서 T4 사용
데이터셋 로드
train_data = image_dataset_from_directory(
directory='./data/cat_dog/cats_and_dogs_filtered/train',
labels='inferred', # 폴더명을 기준으로 라벨링 실시
label_mode='binary', # 이진분류용 정답 형태로 변환
color_mode='rgb', # rgb 색상체계로 데이터 로딩
image_size=(224, 224), # 이미지 크기 리사이징
batch_size=64
)
test_data = image_dataset_from_directory(
directory='./data/cat_dog/cats_and_dogs_filtered/test',
labels='inferred',
label_mode='binary',
color_mode='rgb',
image_size=(224, 224),
batch_size=64
)1. VGG
VGG (Visual Geometry Group)
- CNN 아키텍처로 획기적인 객체 인식 모델 기초로 ImageNet과 같은 대규모 데이터셋에서 높은 정확도를 보임
- ILSVRC-2014에서 준우승한 모델로 가장 인기 있는 모델 중 하나였음
- 단순하고 규칙적인 네트워크 구조를 가진 모델로, 주로
3×3컨볼루션 필터를 반복적으로 사용하여 딥 네트워크를 형성함 - 각 레이어가 이전 레이어의 출력을 연속적으로 받아서 학습하는 순차적인 구조를 갖고 있음
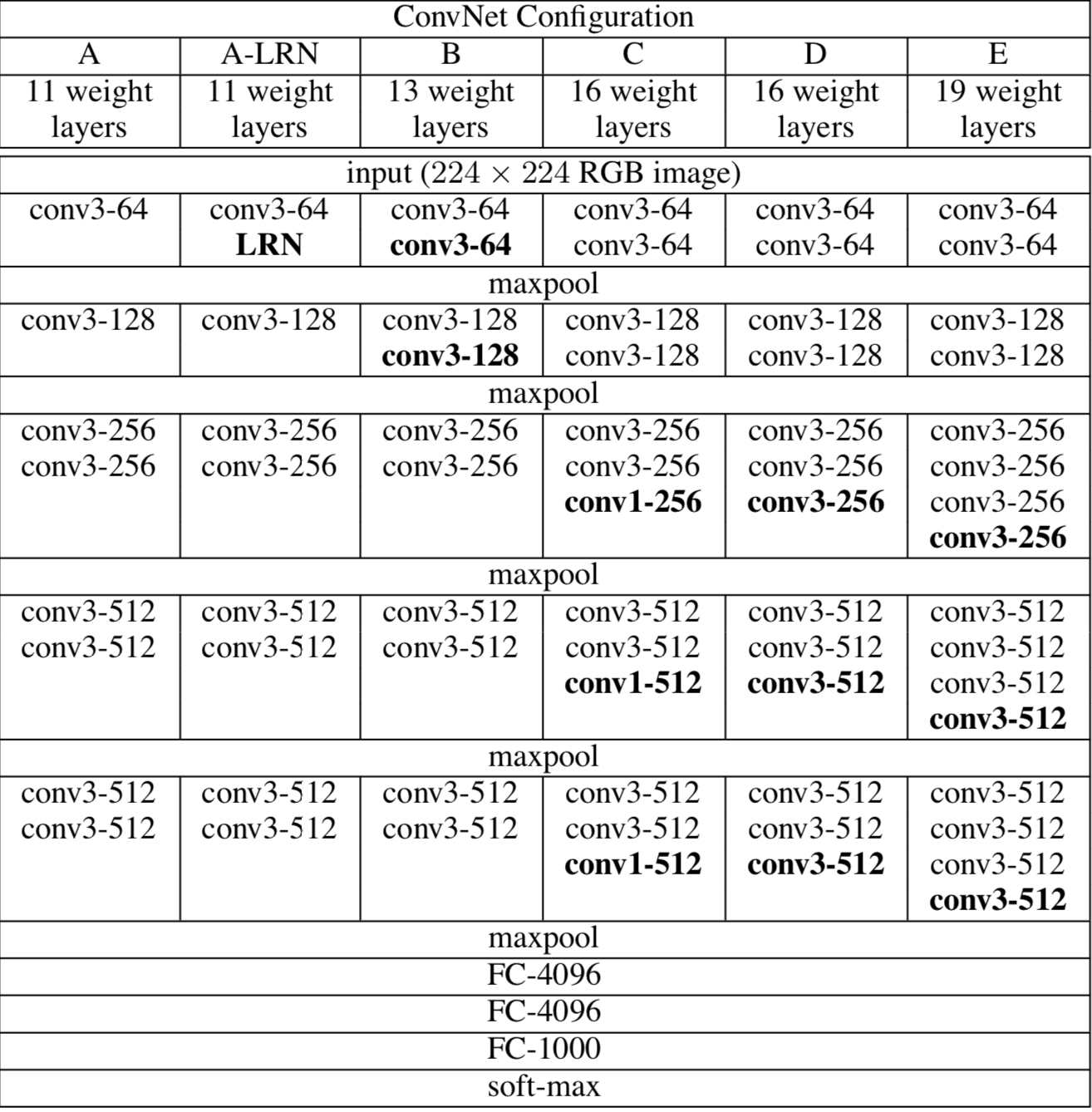
- VGG는 깊이(가중치 레이어)에 따라 VGG-11, VGG-16, VGG-19 등 여러 버전이 있음
- VGG-16, VGG-19 이상으로 깊어지면 기울기 소실 문제가 발생할 수 있음
Architecture
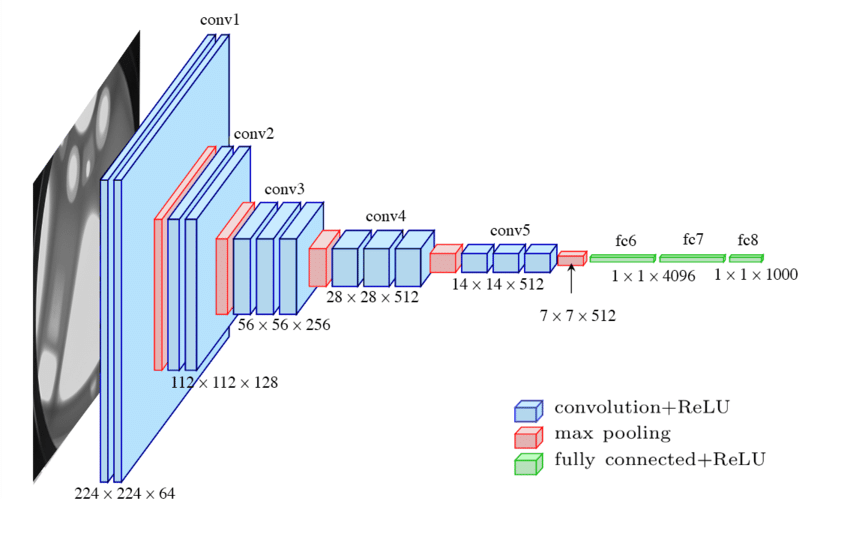
3개의 Convolution Layer와 3개의 FCL로 구성
모든 Convolution Layer의 커널 사이즈는 (3×3)이며, 활성화 함수는 ReLU 사용
VGG 구성 D (VGG-16)
VGG-16에서 16은 가중치 레이어 개수를 의미함
VGG-16은 13개의 컨볼루션 레이어와 3개의 완전 연결층(FCL)으로 구성됨
이 모델은 5개의 블록으로 나눌 수 있으며, 각 블록에는 여러 개의 컨볼루션 레이어(Conv2D)와 맥스 풀링 레이어(MaxPooling2D)가 포함되어 있음
| Layer | Role |
|---|---|
| Input | (244×244) RGB 이미지가 모델의 입력으로 사용됨 |
| Block 1 | - conv3-64 → 3×3 컨볼루션 필터를 사용한 2개의 컨볼루션 레이어가 있으며, 출력 채널 수는 64임 - 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (224×224) → (112×112) |
| Block 2 | - conv3-128 → 3×3 컨볼루션 필터를 사용한 2개의 컨볼루션 레이어가 있으며, 출력 채널 수는 128임- 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (112×112) → (56×56) |
| Block 3 | - conv3-256 → 3×3 컨볼루션 필터를 사용한 3개의 컨볼루션 레이어가 있으며, 출력 채널 수는 256임- 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (56×56) → (28×28) |
| Block 4 | - conv3-512 → 3×3 컨볼루션 필터를 사용한 3개의 컨볼루션 레이어가 있으며, 출력 채널 수는 512임 - 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (28×28) → (14×14) |
| Block 5 | - conv3-512 → 3×3 컨볼루션 필터를 사용한 3개의 컨볼루션 레이어가 있으며, 출력 채널 수는 512임- 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (14×14) → (7×7) |
| Output | - Flatten : 마지막 맥스 풀링 레이어 이후, 7×7×512 크기의 3D 피처맵을 1차원 벡터로 펼침- FC-4096 : 4096개 뉴런을 가진 완전 연결층(Dense Layer)이 2개 존재함. 이 레이어는 모델이 이미지의 복잡한 패턴을 학습하고 분류 결정을 내리는 데 사용됨.- FC-1000 : 1000개의 뉴런을 가진 완전 연결층. ImageNet 데이터셋에서 1000개의 클래스로 분류하기 위해 사용됨.- Softmax : 출력층에서 소프트맥스 활성화 함수를 사용해 1000개의 클래스 중 하나의 확률을 출력함 (다중분류) |
사전학습된 VGG16 모델의 특징 추출 부분(Feature Extractor)를 가져오기
- 분류기층(MLP)을 제외하고 특징 추출부만 로드하기
- 컨볼루션 레이어와 풀링 레이어로 이루어진 특징 추출부만 남겨두고, 분류기(FCL) 부분은 제거하기
vgg16_conv_base는 이미지에서 유용한 특징을 추출하기 위한 베이스 모델로 사용됨 → Transfer Learning
# 사전학습된 VGG16 모델의 Feature Extrator 가져오기
vgg16_conv_base = VGG16(
include_top=False, # 분류기층(MLP층)를 제외하고 다운로드 (VGG16의 분류기 층 제외하고 특징 추출기 부분만 사용))
weights='imagenet', # 이미지넷 데이터로 학습된 가중치 로딩
input_shape=(224,224,3)
)
vgg16_conv_base.summary()
>>> Model: "vgg16"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ input_layer_2 (InputLayer) │ (None, 224, 224, 3) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_conv1 (Conv2D) │ (None, 224, 224, 64) │ 1,792 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_conv2 (Conv2D) │ (None, 224, 224, 64) │ 36,928 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_pool (MaxPooling2D) │ (None, 112, 112, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_conv1 (Conv2D) │ (None, 112, 112, 128) │ 73,856 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_conv2 (Conv2D) │ (None, 112, 112, 128) │ 147,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_pool (MaxPooling2D) │ (None, 56, 56, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv1 (Conv2D) │ (None, 56, 56, 256) │ 295,168 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv2 (Conv2D) │ (None, 56, 56, 256) │ 590,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv3 (Conv2D) │ (None, 56, 56, 256) │ 590,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_pool (MaxPooling2D) │ (None, 28, 28, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv1 (Conv2D) │ (None, 28, 28, 512) │ 1,180,160 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv2 (Conv2D) │ (None, 28, 28, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv3 (Conv2D) │ (None, 28, 28, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_pool (MaxPooling2D) │ (None, 14, 14, 512) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv1 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv2 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv3 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_pool (MaxPooling2D) │ (None, 7, 7, 512) │ 0 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 14,714,688 (56.13 MB)
Trainable params: 14,714,688 (56.13 MB)
Non-trainable params: 0 (0.00 B)※ 파라미터 수 = (필터너비 × 필터높이 × 입력채널수 + 1) × 출력채널수
※ 1 : 바이어스 파라미터
전체 모델 만들기
사전학습된 모델(Feature Extractor)을 포함해, 새로운 데이터에 맞춰 학습할 분류기층 추가한 전체 모델 만들기
# 뼈대 생성
vgg16_model = Sequential()
# 입력층
vgg16_model.add(InputLayer(input_shape=(224,224,3)))
# 중간층
# 특성추출부 (사전학습된 모델)
vgg16_model.add(vgg16_conv_base)
# 분류기 (추출된 특징을 이용해 새로운 분류를 수행하기 위한 FCL 추가)
vgg16_model.add(Flatten()) # 피처맵을 1차원으로 변경
vgg16_model.add(Dense(128, activation='relu')) # 비선형성 도입
# 출력층
vgg16_model.add(Dense(units=1, activation='sigmoid')) # 해결해야 하는 문제는 이진분류 문제이므로, 활성화 함수를 시그모이드로 변경
# units=1이므로 출력 뉴런이 하나 = 출력 텐서의 크기도 1 = 출력값이 하나 = 배열의 길이가 1
vgg16_model.summary()
Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ vgg16 (Functional) │ (None, 7, 7, 512) │ 14,714,688 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ flatten_1 (Flatten) │ (None, 25088) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_2 (Dense) │ (None, 128) │ 3,211,392 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_3 (Dense) │ (None, 1) │ 129 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 17,926,209 (68.38 MB)
Trainable params: 17,926,209 (68.38 MB)
Non-trainable params: 0 (0.00 B)학습, 평가방법 설정 및 학습
vgg16_model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.001),
metrics=['accuracy'])
f_early = EarlyStopping(monitor='val_accuracy', patience=10)
# 모델 학습
vgg16_h = vgg16_model.fit(train_data,
validation_data=test_data,
epochs=100,
callbacks=[f_early]) # early stopping특정 레이어만 학습되는 코드로 변경 (동결)
데이터셋의 규모가 작기 때문에, 입력층에 가까운 컨볼루션 레이어(일반적인 정보 추출)는 동결하고, 출력층에 가까운 레이어(도메인 특성 추출)만 업데이트하기
vgg16_conv_base = VGG16(
include_top=False,
weights='imagenet',
input_shape=(224,224,3)
)
# 모델 설계
vgg16_model = Sequential()
# 입력층
vgg16_model.add(InputLayer(input_shape=(224,224,3)))
# 중간층
# 특성추출부
# ------------------------ 동결코드 추가 ------------------------
for layer in vgg16_conv_base.layers: # 각 층을 하나씩 꺼냄
if layer.name == 'block5_conv3': # 출력층에 가까운 마지막 컨볼루션 레이어
layer.trainable=True # 사전학습된 가중치를 활용하면서도 모델 출력층에 가까운 부분에서 새로운 데이터에 맞추어 파인 튜닝
else:
layer.trainable=False # 가중치가 업데이트되지 않도록 설정
# ---------------------------------------------------------------
vgg16_model.add(vgg16_conv_base)
# 분류기
vgg16_model.add(Flatten())
vgg16_model.add(Dense(128, activation='relu')) #
# 출력층
vgg16_model.add(Dense(units=1, activation='sigmoid'))
vgg16_model.summary()
Model: "vgg16"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ input_layer_4 (InputLayer) │ (None, 224, 224, 3) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_conv1 (Conv2D) │ (None, 224, 224, 64) │ 1,792 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_conv2 (Conv2D) │ (None, 224, 224, 64) │ 36,928 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block1_pool (MaxPooling2D) │ (None, 112, 112, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_conv1 (Conv2D) │ (None, 112, 112, 128) │ 73,856 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_conv2 (Conv2D) │ (None, 112, 112, 128) │ 147,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block2_pool (MaxPooling2D) │ (None, 56, 56, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv1 (Conv2D) │ (None, 56, 56, 256) │ 295,168 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv2 (Conv2D) │ (None, 56, 56, 256) │ 590,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_conv3 (Conv2D) │ (None, 56, 56, 256) │ 590,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block3_pool (MaxPooling2D) │ (None, 28, 28, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv1 (Conv2D) │ (None, 28, 28, 512) │ 1,180,160 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv2 (Conv2D) │ (None, 28, 28, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_conv3 (Conv2D) │ (None, 28, 28, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block4_pool (MaxPooling2D) │ (None, 14, 14, 512) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv1 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv2 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_conv3 (Conv2D) │ (None, 14, 14, 512) │ 2,359,808 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ block5_pool (MaxPooling2D) │ (None, 7, 7, 512) │ 0 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 14,714,688 (56.13 MB)
Trainable params: 14,714,688 (56.13 MB)
Non-trainable params: 0 (0.00 B)
vgg16_model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.001),
metrics=['accuracy'])
vgg16_h = vgg16_model.fit(train_data,
validation_data=test_data,
epochs=100,
callbacks=[f_early])
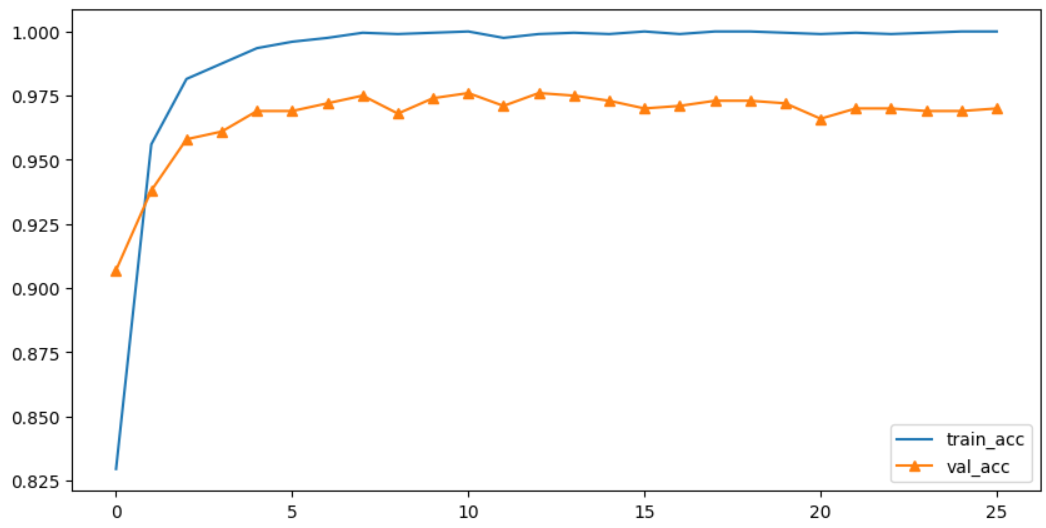
# 결과 시각화
plt.figure(figsize=(10,5))
plt.plot(vgg16_h.history['accuracy'], label='train_acc')
plt.plot(vgg16_h.history['val_accuracy'], label='val_acc', marker='^')
plt.legend()
plt.show()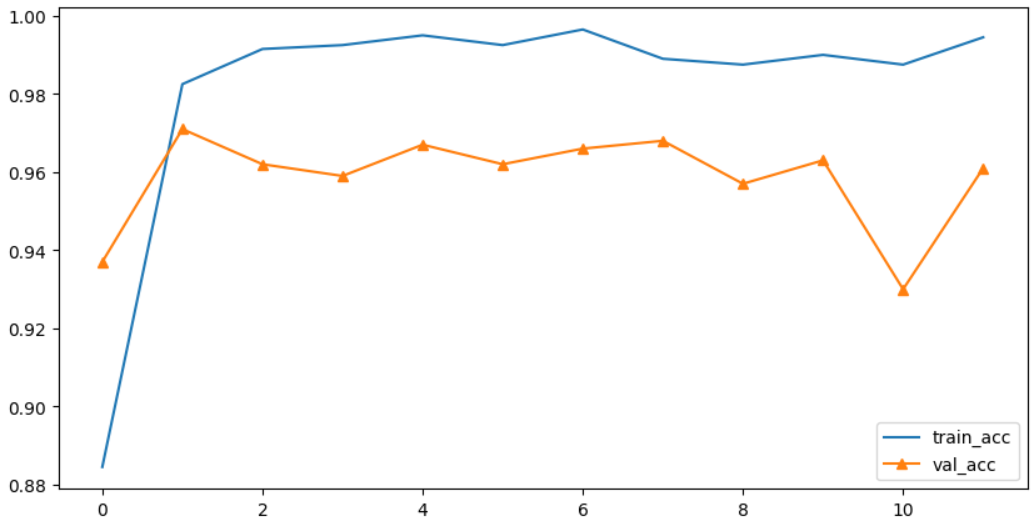
2. ResNet
ResNet(Residual Neural Network)
- ILSVRC-2015에서 우승한 CNN 네트워크로 마이크로소프트에서 개발한 알고리즘
잔차 연결(Residual Connection)을 도입해 훨씬 깊은 네트워크를 안정적으로 학습할 수 있도록 설계됨- 네트워크가 깊어지면 기울기 소실 문제가 발생해 성능이 감소되는 경향이 있음
- 따라서 Residual Connection 및 Skip Connection을 도입!
- Residual Connection은 입력을 레이어의 출력과 직접 연결하는 스킵 연결(Skip Connection)을 사용하여 입력 정보가 후속 레이어로 쉽게 전달되도록 함
Residual Block을 통해 입력을 출력에 직접 더해주는 구조- 즉, 네트워크는 각 블록에서 학습하는 것이 아니라, 잔차(Residual)만 학습하면 되어서 학습이 훨씬 쉬워짐 (불필요한 계산 감소, 중요 특성에 집중)
- 스킵 연결을 도입해 더 깊은 네트워크를 사용하지만, 파라미터 수는 효율적으로 유지됨
- 깊이(가중치 레이어)에 따라 RestNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152 등이 있음
Architecture
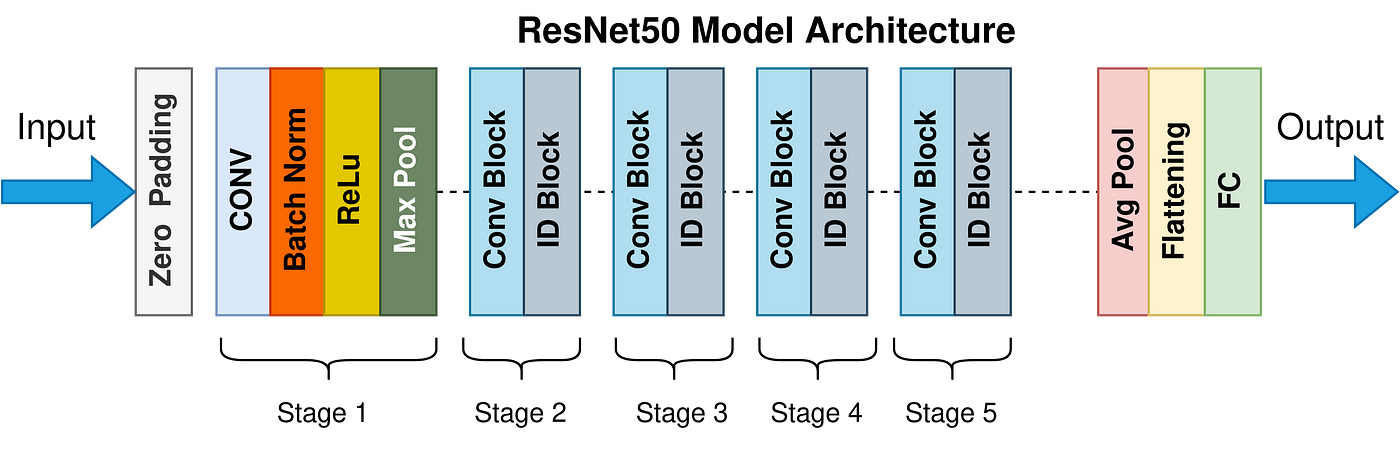
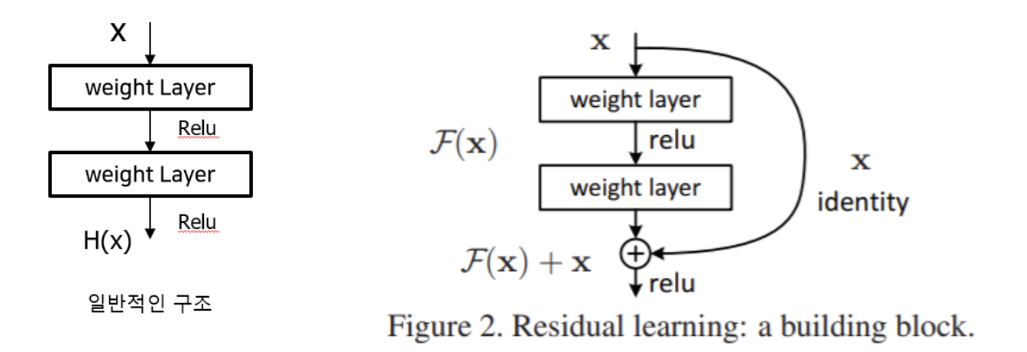
Residual block: 컨볼루션 레이어를 하나의 블록으로 묶은 계층들. 이 블록을 여러 개 쌓은 것이 ResNetResidual Mapping: 컨볼루션 레이어를 통과한F(x)와 컨볼루션 레이어를 통과하지 않은x를 더하는 과정Skipping Connection: 이전 레이어 정보를 직접적으로 이용하기 위해 이전 레이어의 입력을 연결- : 입력값
- : 해당 레이어에서 원래 출력하고자 하는 값
- : = 잔차
- 잔차를 최소화 하여 가 되는 것이 목표: 즉, 잔차를 학습하는 것
| Layer | Role |
|---|---|
| Input | (224×224) RGB 이미지가 모델의 입력으로 사용됨 |
| Zero Padding | 입력 이미지의 가장자리 픽셀에 0을 추가하여 크기를 유지함 |
| Stage 1 (CONV) | - conv1-64 : (초기 컨볼루션 레이어) 7×7 컨볼루션 필터를 사용해 64개의 출력 채널을 생성- stride 2 : 컨볼루션 필터가 두 칸씩 이동하며 특징을 추출함 (출력 크기가 (224×224)에서 (112×112) 로 감소- 맥스 풀링을 통해 특징 맵의 크기를 절반으로 줄임 (112×112) → (56×56) - Batch Normalization과 ReLU 사용 |
| Stage 2 (Conv Block) | - conv Block → 3×3 컨볼루션 필터와 스킵 연결을 사용해 256개의 출력 채널을 생성 (입력 크기와 출력 크기는 동일하게 유지됨)- ID Block(Identity Block) → 잔차 연결 을 포함해 입력과 출력 크기를 그대로 유지 (56×56) |
| Stage 3 (Conv Block) | - conv Block → 3×3 컨볼루션 필터와 스킵 연결을 사용해 512개의 출력 채널을 생성하고, 크기는 (56×56) 에서 (28×28)로 감소- ID Block → 잔차 연결을 포함해 입력과 출력 크기를 그대로 유지 (56×56) |
| Stage 4 (Conv Block) | - Conv Block → 3×3 컨볼루션 필터를 사용하여 출력 채널 수를 1024개로 증가시키고, 크기는 (28×28)에서 (14×14)로 감소- ID Block → 입력과 출력의 크기 (14×14) 을 그대로 유지하고, 채널 수는 동일 |
| Stage 5 (Conv Block) | - Conv Block → 3×3 컨볼루션 필터를 사용하여 출력 채널 수를 2048개로 증가시키고, 크기는 (14×14)에서 (7×7)로 감소- ID Block → 입력과 출력의 크기 (7×7)을 그대로 유지하고, 채널 수는 동일. |
| Output | - Global Average Pooling → 특징 맵 전체의 평균을 계산하여 (1, 1, 2048)로 축소, 특징을 효과적으로 요약함- Flatten → 1차원 벡터(2048)로 펼쳐서 완전 연결층에 연결- FC-1000 → 1000개의 뉴런을 가진 완전 연결층. ImageNet 데이터셋에서 1000개의 클래스로 분류하기 위해 사용됨- Softmax → 출력층에서 소프트맥스 활성화 함수를 사용하여 1000개의 클래스 중 하나의 확률을 출력 |
사전학습된 ResNet-152 모델의 특징 추출 부분를 가져오기 + 전체 모델 생성
# 사전학습된 ResNet-152 모델의 Feature Extrator 가져오기
res152_model = ResNet152V2(
include_top=False,
weights='imagenet',
input_shape=(224,224,3)
)
# 모델 요약 생략
# 특성 추출기 형태로만 활용
res152_model.trainable=False # 가중치가 학습 안 되도록 설정
# 모델의 뒷부분에 있는 특정 레이어들만 학습가능하게 설정하고 나머지는 동결
layer_names = ['conv5_block3_3_conv', 'conv5_block3_2_conv', 'conv5_block3_1_conv']
# 사전학습된 가중치를 유지하면서, 새로운 데이터에 대해 고수준 특징만 조정해 파인튜닝
# 동결된 레이어는 작동하지만 가중치가 학습되지 않으며, 학습 가능하게 설정된 레이어만 새로운 데이터에 대해 업데이트함
# 모델 설계
transfer_res_model = Sequential()
# 입력층
transfer_res_model.add(InputLayer(shape=(224,224,3)))
# 특성추출부(동결)
# ------------------------ 동결코드 추가 ------------------------
for layer in res152_model.layers:
if layer.name in layer_names:
layer.trainable=True
else:
layer.trainable=False
# ---------------------------------------------------------------
transfer_res_model.add(res152_model)
# 분류기
transfer_res_model.add(GlobalAveragePooling2D())
# Flatten 대신 이거 사용 (GlobalAveragePooling2D는 다차원 피처맵을 평균내며 1차원 벡터로 변환하기 때문에 - 즉 알아서 flatten하기 때문)
# <공간정보 축소를 통한 모델 경량화>
# (7, 7, 512) -> flatten -> (25088,)
# -> GlobalAveragePooling2D -> (512,)
transfer_res_model.add(Dense(256, activation='relu'))
transfer_res_model.add(Dense(128, activation='relu'))
# 출력층
transfer_res_model.add(Dense(units=1, activation='sigmoid')) # 이진분류
transfer_res_model.summary()
Model: "sequential_7"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ resnet152v2 (Functional) │ (None, 7, 7, 2048) │ 58,331,648 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ flatten_6 (Flatten) │ (None, 100352) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_25 (Dense) │ (None, 512) │ 51,380,736 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_26 (Dense) │ (None, 256) │ 131,328 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_27 (Dense) │ (None, 128) │ 32,896 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_28 (Dense) │ (None, 128) │ 16,512 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_29 (Dense) │ (None, 1) │ 129 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 109,893,249 (419.21 MB)
Trainable params: 63,644,801 (242.79 MB)
Non-trainable params: 46,248,448 (176.42 MB)
transfer_res_model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
res152_h = transfer_res_model.fit(train_data,
validation_data=test_data,
epochs=100,
callbacks=[f_early])
# 결과 시각화
plt.figure(figsize=(10,5))
plt.plot(res152_h.history['accuracy'], label='train_acc')
plt.plot(res152_h.history['val_accuracy'], label='val_acc', marker='^')
plt.legend()
plt.show()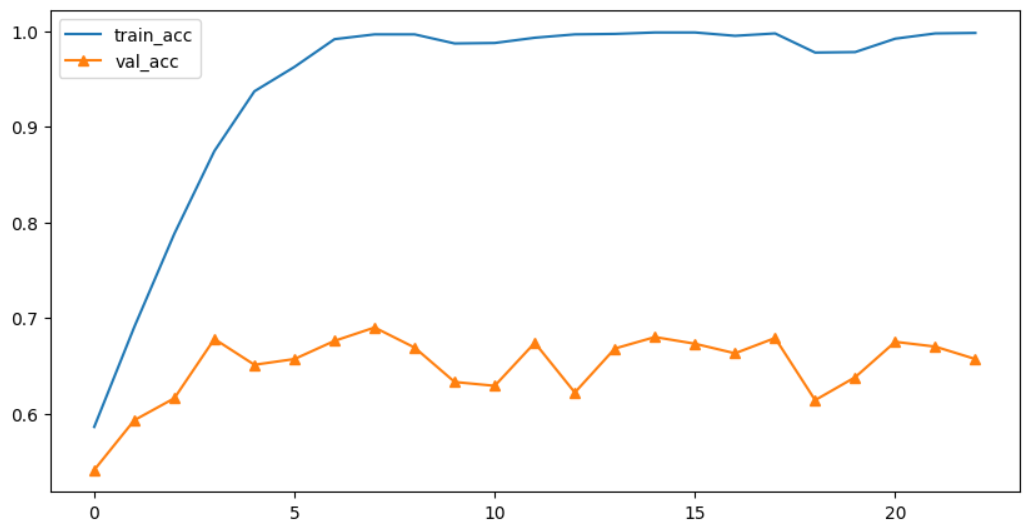
데이터 변형, 증식 기법 추가
# data augmentation layer 생성
augmentation_layer = Sequential(
[
RandomFlip('horizontal'), # 좌우반전
RandomRotation(0.1), # 회전
RandomZoom(0.1) # 확대
]
)
res152_model = ResNet152V2(
include_top=False,
weights='imagenet',
input_shape=(224,224,3)
)
# 1. 모델 설계
transfer_res_model3 = Sequential()
# 입력층
transfer_res_model3.add(InputLayer(shape=(224,224,3)))
transfer_res_model3.add(augmentation_layer) # data augmentation layer 추가
# 특성추출부(동결)
# ------------------------ 동결코드 추가 ------------------------
for layer in res152_model.layers:
if layer.name in layer_names:
layer.trainable=True
else:
layer.trainable=False
# ---------------------------------------------------------------
transfer_res_model3.add(res152_model)
# 분류기
transfer_res_model3.add(GlobalAveragePooling2D())
transfer_res_model3.add(Dense(256, activation='relu'))
transfer_res_model3.add(Dense(128, activation='relu'))
# 출력층
transfer_res_model3.add(Dense(units=1, activation='sigmoid')) # 이진분류
transfer_res_model3.summary()
Model: "sequential_10"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ sequential_9 (Sequential) │ (None, 224, 224, 3) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ resnet152v2 (Functional) │ (None, 7, 7, 2048) │ 58,331,648 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ global_average_pooling2d_1 │ (None, 2048) │ 0 │
│ (GlobalAveragePooling2D) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_33 (Dense) │ (None, 256) │ 524,544 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_34 (Dense) │ (None, 128) │ 32,896 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_35 (Dense) │ (None, 1) │ 129 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 58,889,217 (224.64 MB)
Trainable params: 5,016,065 (19.13 MB)
Non-trainable params: 53,873,152 (205.51 MB)
transfer_res_model3.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
res152_h = transfer_res_model3.fit(train_data,
validation_data=test_data,
epochs=100,
callbacks=[f_early])
# 결과 시각화
plt.figure(figsize=(10,5))
plt.plot(res152_h.history['accuracy'], label='train_acc')
plt.plot(res152_h.history['val_accuracy'], label='val_acc', marker='^')
plt.legend()
plt.show()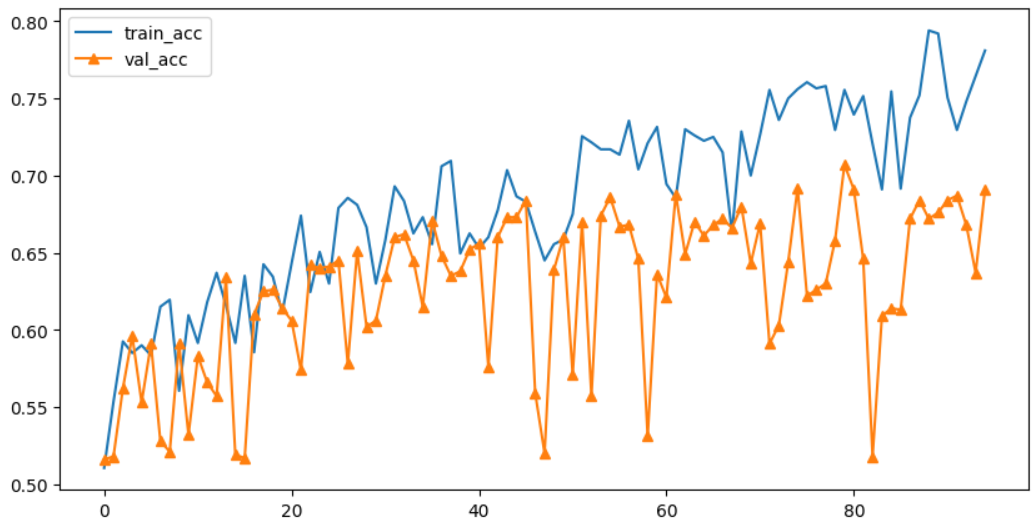
3. MobileNet
- AlexNet 이후 네트워크는 성능 향상을 위해 깊고 복잡한 구조로 발전했으나, 모바일 환경에서의 효율성은 고려되지 않았음
- 2017년 Google에서 개발한 경량화된 CNN인 MobileNet은 모바일 기기나 임베디드 시스템처럼 제한된 자원을 가진 환경에서도 딥러닝 모델을 실행할 수 있도록 설계되었음
- SqueezeNet 등 다른 경량화 모델들은 주로 모델 크기를 줄이는 데 집중했지만, MobileNet은 계산량(동작시간) 과 모델 크기(파라미터 수) 모두 줄이는 것을 목표로 함
- Depthwise Separable Convolution (Xception에서 도입)을 활용해 연산 효율을 극대화함
- 일반적인 컨볼루션을 두 단계(Depthwise, Pointwise Convolution)로 나누어 연산량과 파라미터 수를 줄임
- 하드웨어 특성에 맞춰 모델 크기를 조절할 수 있는 하이퍼파라미터를 도입함
※ 기본적인 컨볼루션 레이어는 2차원 공간(너비, 높이)과 1차원 채널로 이루어진 3차원 구조의 필터임. 그러므로 컨볼루션 레이어를 학습할 땐 공간 사이 상관분석과 채널 사이 상관분석이 동시에 이뤄짐. 그런데 Inception 모듈은 채널 정보가 4개로 나뉘어 각각의 컨볼루션 레이어에서 공간 사이 상관분석이 이뤄진 후 마지막으로 채널 정보가 합쳐지는 구조임.
※ Inception 모듈과 MobileNet은 모두 공간적 특징과 채널 간 정보를 다루지만, Inception은 다양한 필터 크기로 공간적 특징을 동시에 추출하고 합치는 반면, MobileNet은 공간과 채널의 연산을 분리하여 각각의 연산을 간소화하는 방식으로 차이가 있음 <- 참고링크
Architecture
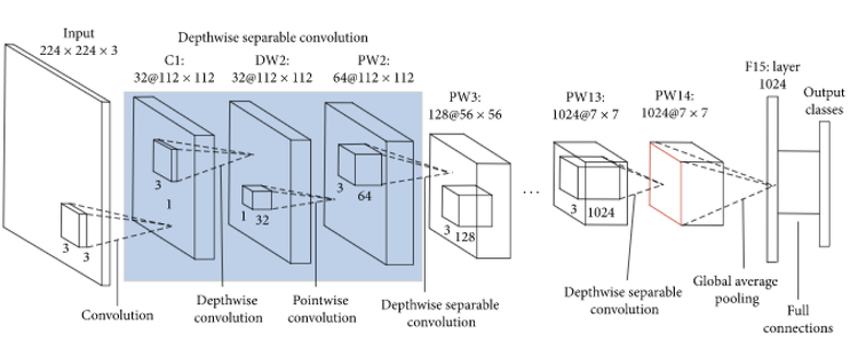
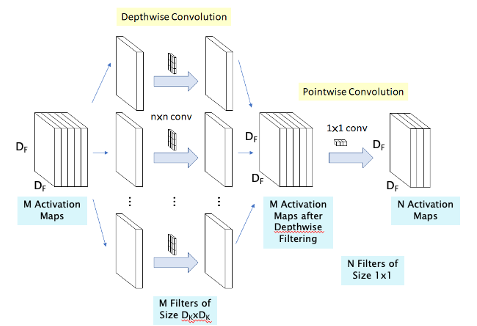
Width Multiplier (α): 네트워크의 너비(채널 수)를 조정해 모델 크기를 효율정으로 조절Resolution Multiplier (ρ): 입력 해상도를 줄여 연산량과 파라미터 수 감소시킴
- Depthwise Convolution
- 채널 방향 컨볼루션 없이, 공간 방향으로만 컨볼루션 수행
- 각 채널별로 독립적으로 필터를 적용해 공간적 특징 추출
Width Multiplier (α)와Resolution Multiplier (ρ)사용
- Pointwise Convolution
- 공간 방향의 컨볼루션 없이, 채널 방향으로만 컨볼루션 수행
- 모든 채널을 결합하기 위해
1×1컨볼루션을 사용- 각 채널에서 추출된 특징을 결합해 유의미한 표현을 생성하고, 필요시 출력 채널 수를 줄여 정보 압축 (→ 연산 속도 향상)
Width Multiplier (α)만 사용
- Depthwise Separable Convolution
- Depthwise Convolution과 Pointwise Convolution을 순차적으로 수행해 컨볼루션 연산을 분리
- Depthwise Convolution으로 공간적 특징을 추출한 후, Pointwise Convolution으로 각 채널을 결합해 결과물 간소화함
- 이러한 구조는 연산량과 파라미터 수를 크게 줄이는 데 도움이 됨
사전학습된 MobileNetV3 Small 모델의 특징 추출 부분(Feature Extractor)을 가져오기
mobile_model = MobileNetV3Small(
include_top=False,
weights='imagenet',
input_shape=(224,224,3),
pooling='avg' # flatten 대신 활용
)
mobile_model.summary() # 아웃풋 생략전체 모델 만들기
# 1. 모델 설계
mobile_small_model = Sequential()
# 입력층
mobile_small_model.add(InputLayer(shape=(224,224,3)))
# 특성추출부
mobile_small_model.add(mobile_model) # 사전학습 모델 추가
# 분류기
mobile_small_model.add(Dense(128, activation='relu'))
# 출력층
mobile_small_model.add(Dense(1, activation='sigmoid'))
mobile_small_model.summary()
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ MobileNetV3Small (Functional) │ (None, 576) │ 939,120 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 128) │ 73,856 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_1 (Dense) │ (None, 1) │ 129 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 1,013,105 (3.86 MB)
Trainable params: 1,000,993 (3.82 MB)
Non-trainable params: 12,112 (47.31 KB)
# 2. 학습방법 및 평가방법 설정
mobile_small_model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
# 3. 모델 학습
mobile_small_h = mobile_small_model.fit(train_data,
validation_data=test_data,
epochs=100,
callbacks=[f_early])
# 4.결과 시각화
plt.figure(figsize=(10,5))
plt.plot(mobile_small_h.history['accuracy'], label='train_acc')
plt.plot(mobile_small_h.history['val_accuracy'], label='val_acc', marker='^')
plt.legend()
plt.show()