KPMG Future Academy AI 활용 데이터 분석가 3기 32일차 수업을 2025년 1월 2일에 참석했다. 지난 수업에 이어 판다스 수업이 시작되었다.
- 판다스
1.1. 판다스
1.2. 데이터프레임 탐색
1.3. 데이터프레임 조회
1. 판다스
1.1. 판다스
판다스(Pandas)란?
빠르고 유연한 데이터 구조를 제공하는 파이썬 라이브러리이다.
행과 열로 이루어진 2차원 데이터를 효율적으로 가공할 수 있다.
Pandas 데이터 구조
-
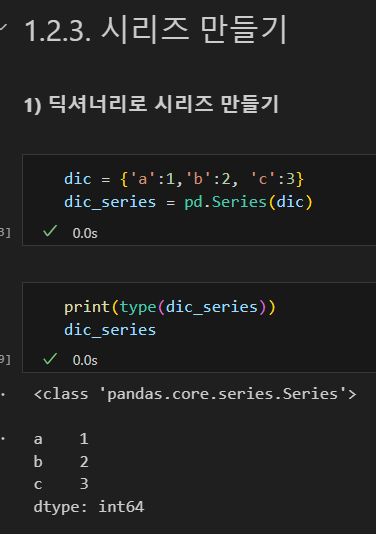
시리즈(Series)
1차원 배열로, 데이터와 인덱스를 가지며 리스트와 유사
각 데이터는 고유한 인덱스를 가지고 있어 접근 및 조작이 쉬움 -
데이터프레임(DataFrame)
2차원 배열로, 행과 열로 구성된 테이블 형태의 데이터 구조
각 열은 Series 객체로 구성되며, 다양한 데이터 타입을 가질 수 있음
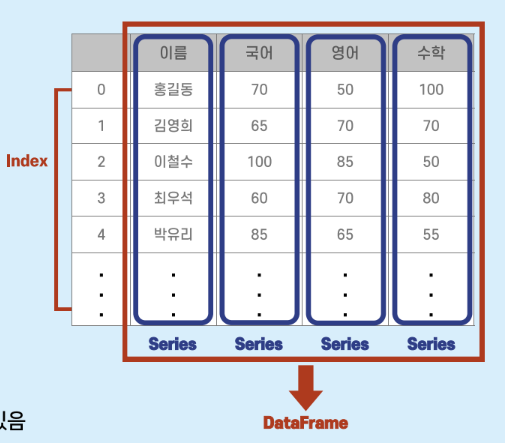
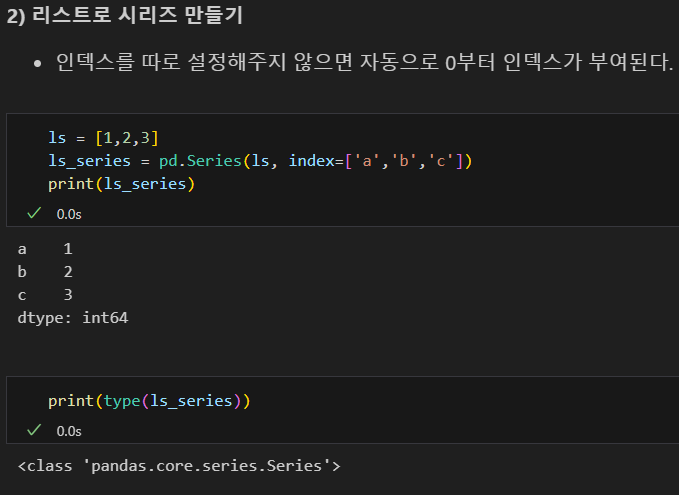
인덱스 기본은 0
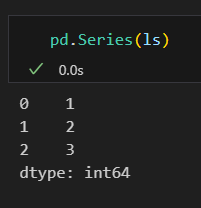
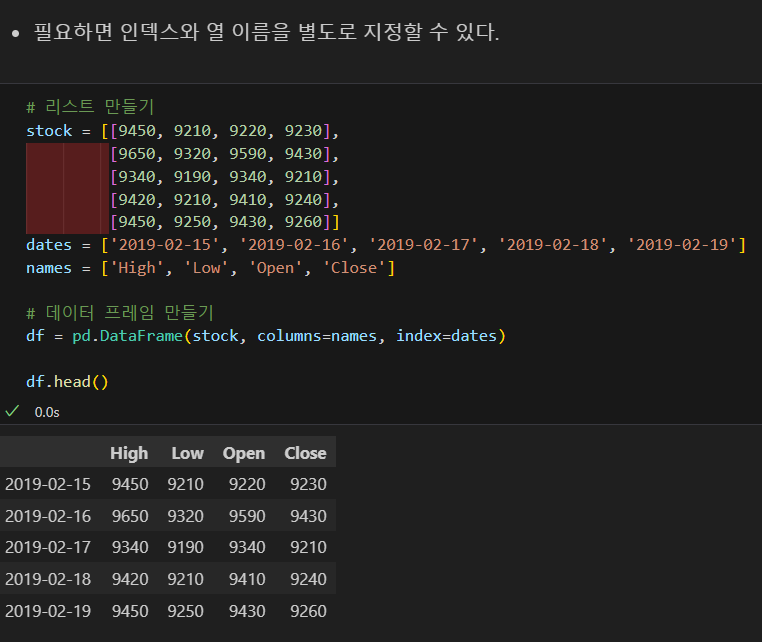
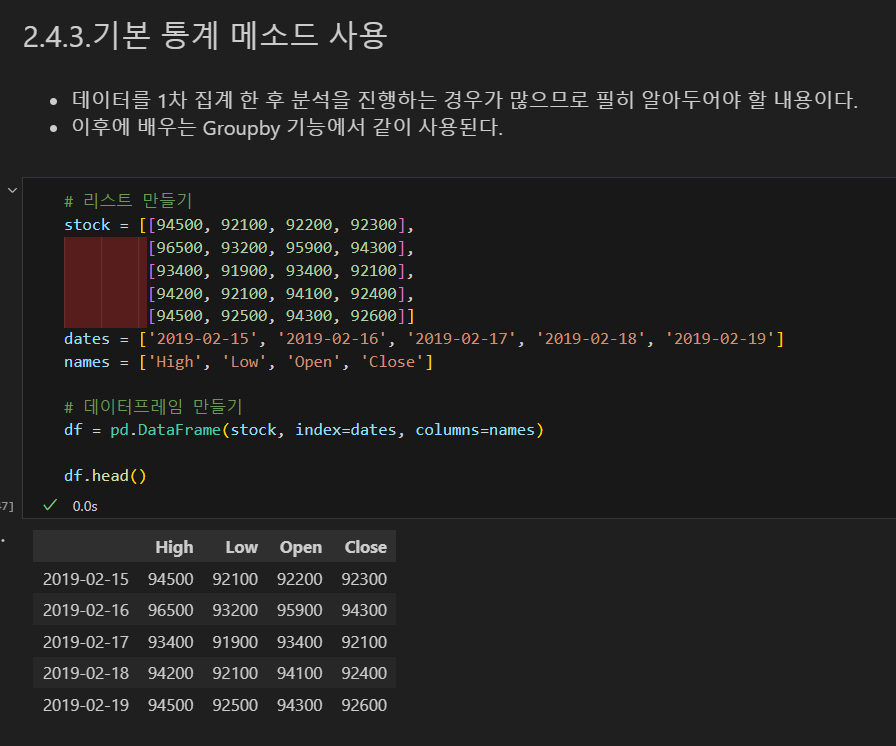
데이터프레임
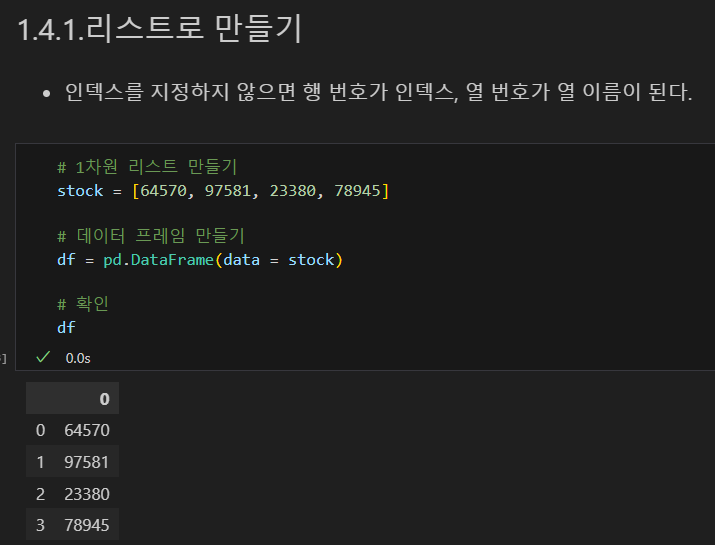
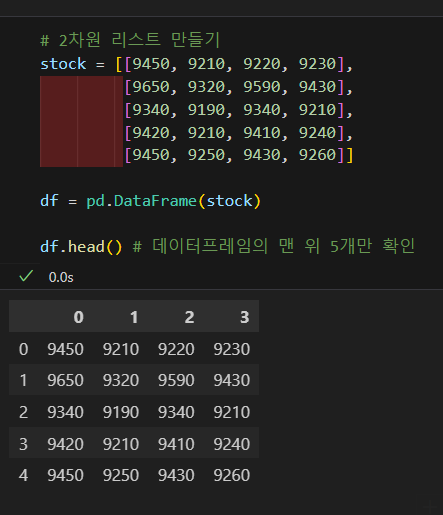
리스트로 만들기
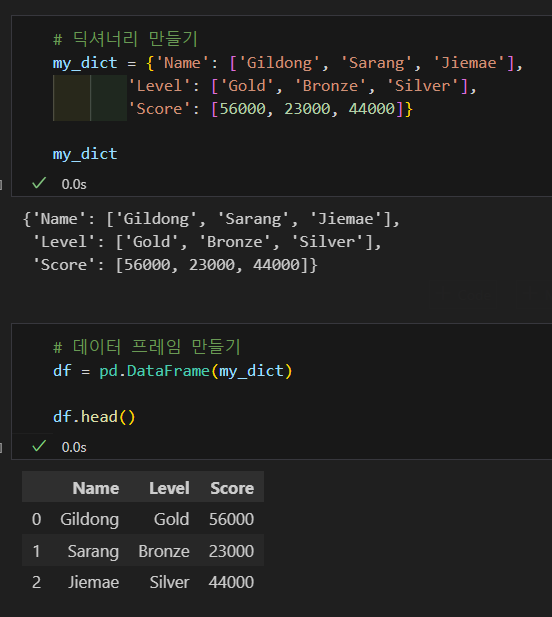
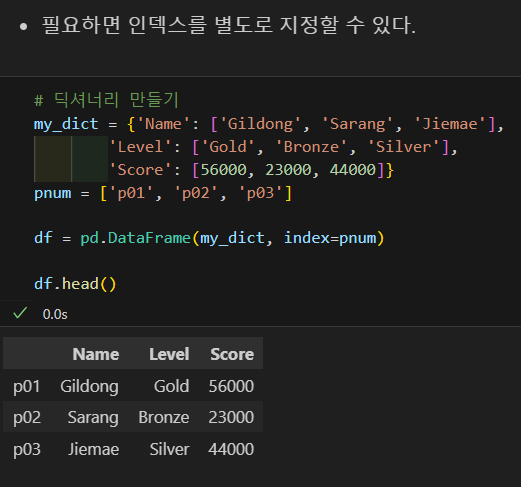
딕셔너리로 만들기
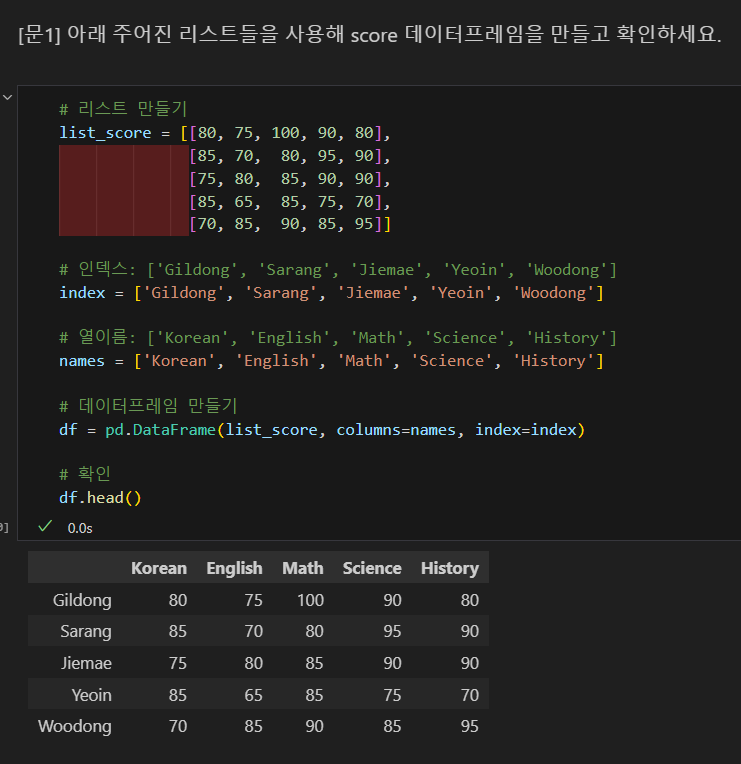
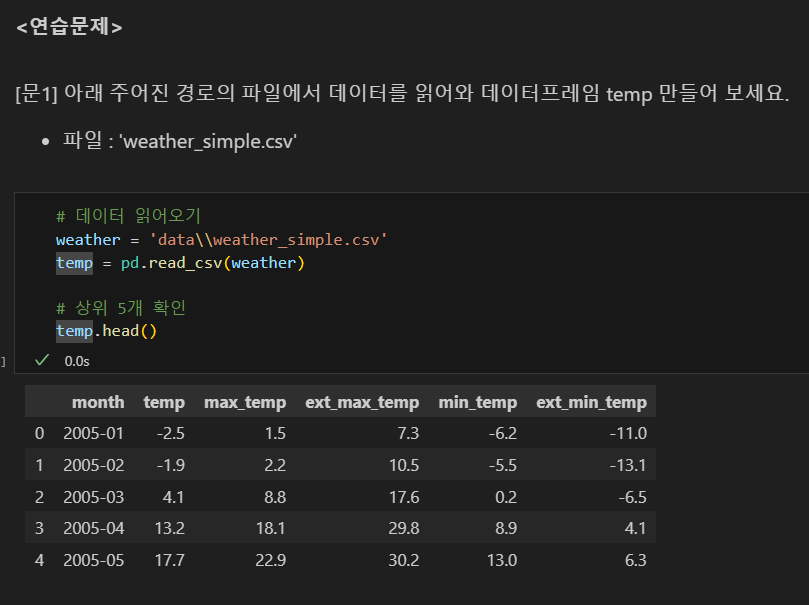
문제
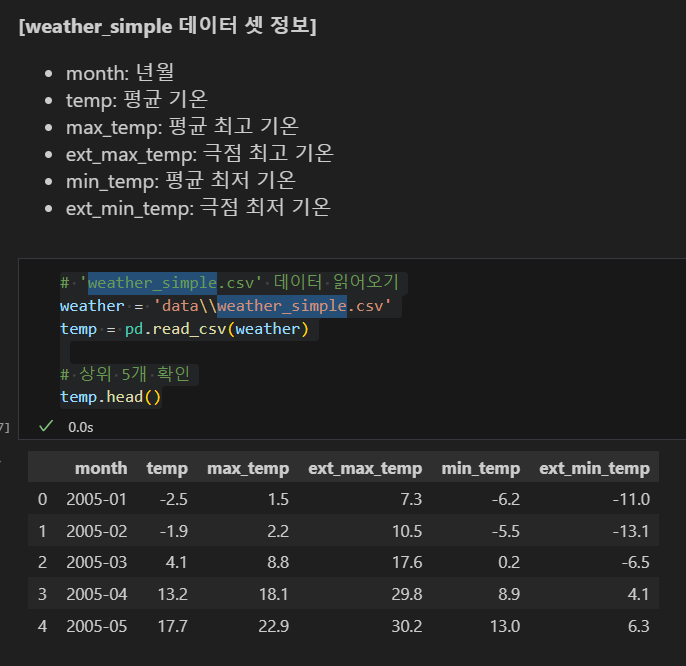
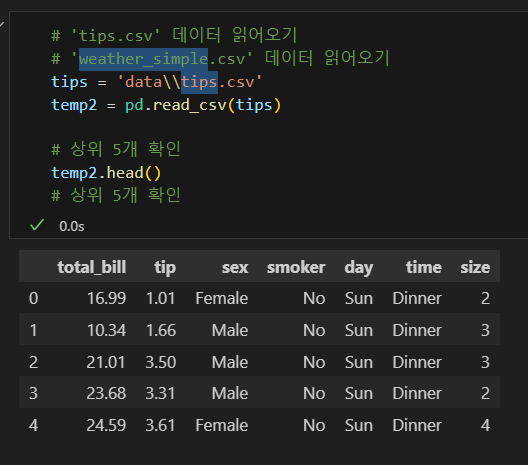
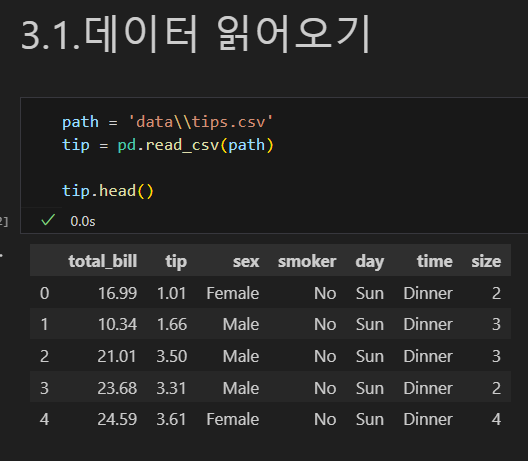
csv(Comma-Seperated Values) 파일 읽어오기
[주요옵션]
- sep: 구분자 지정(기본값 = 콤마)
- header: 헤더가 될 행 번호 지정(기본값 = 0)
- index_col: 인덱스 열 지정(기본값 = False)
- names: 열 이름으로 사용할 문자열 리스트
- encoding: 인코딩 방식을 지정
※ 참고
한글이 포함된 파일을 읽을 때 다음과 같은 encoding 오류가 발생하면 encoding='CP949' 로 지정
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte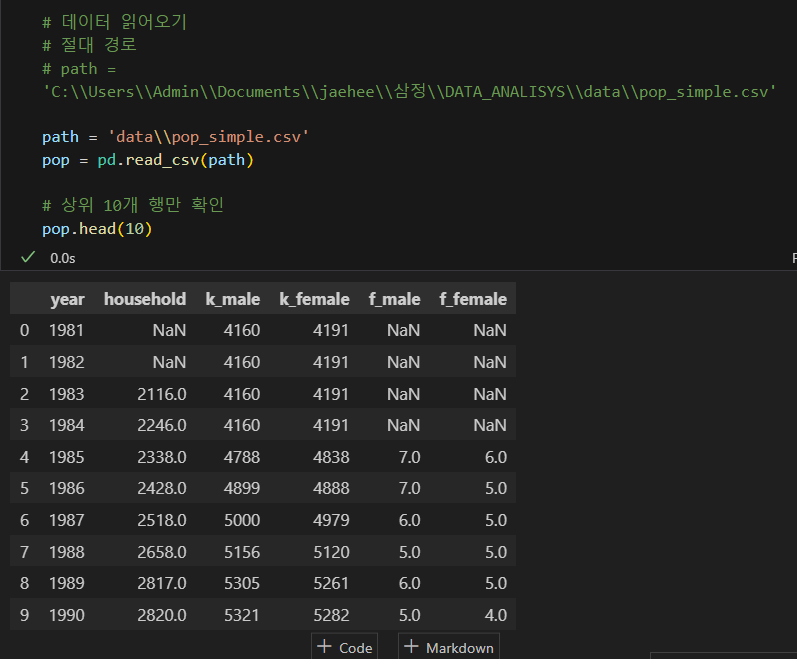
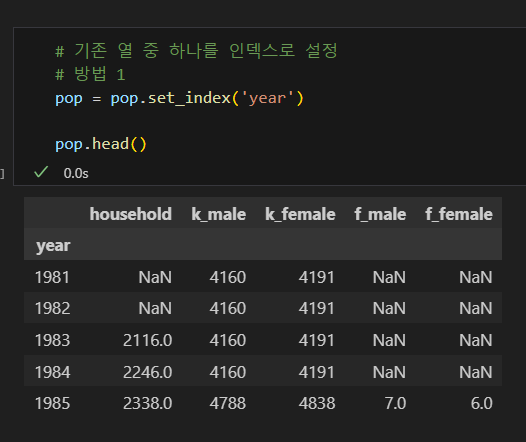
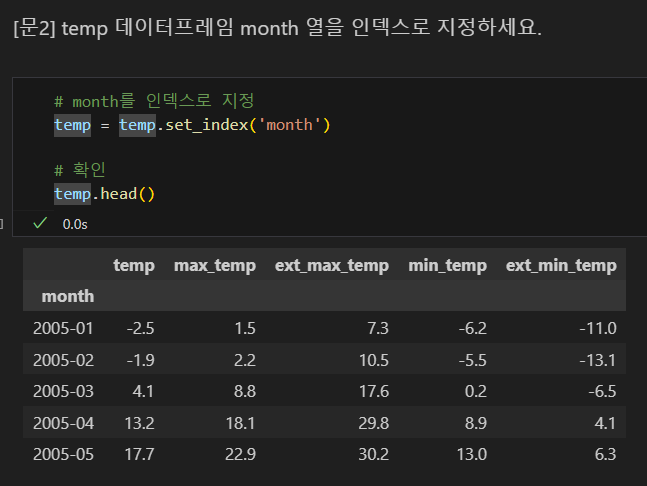
인덱스 설정
방법1
방법2
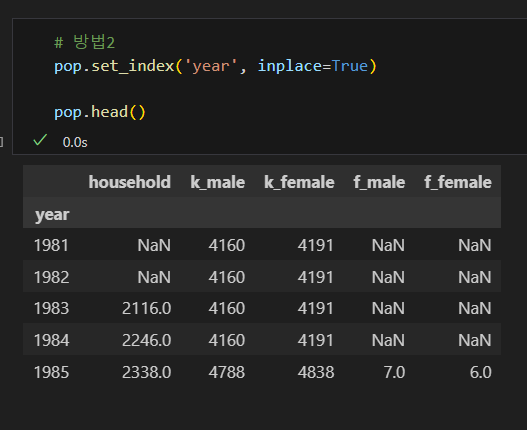
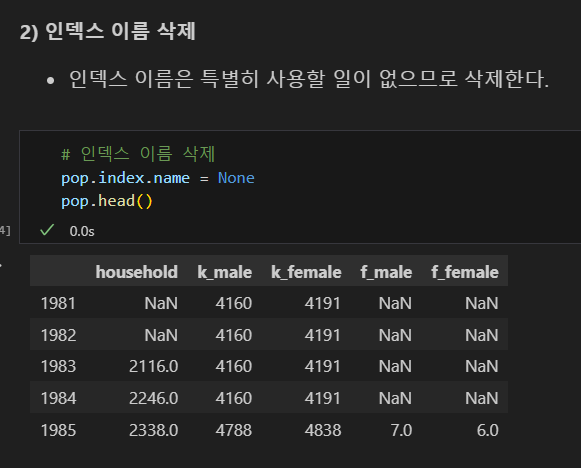
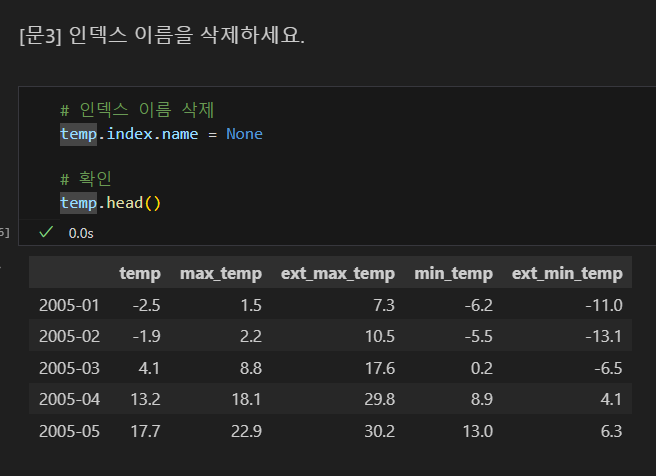
인덱스 열 이름 삭제
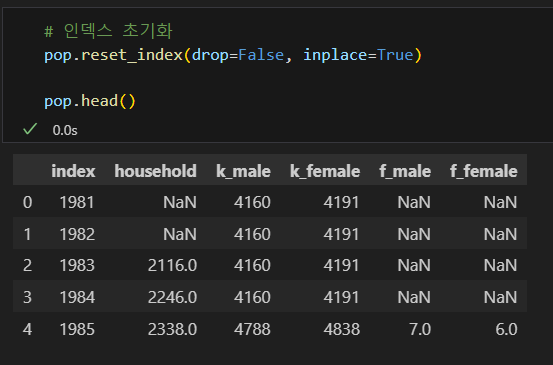
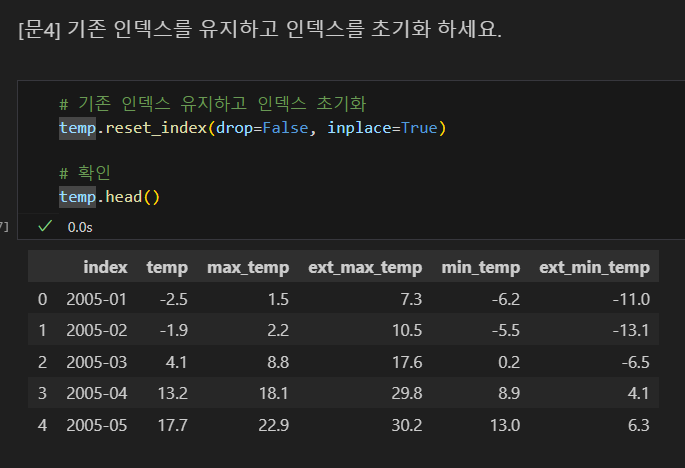
인덱스 초기화
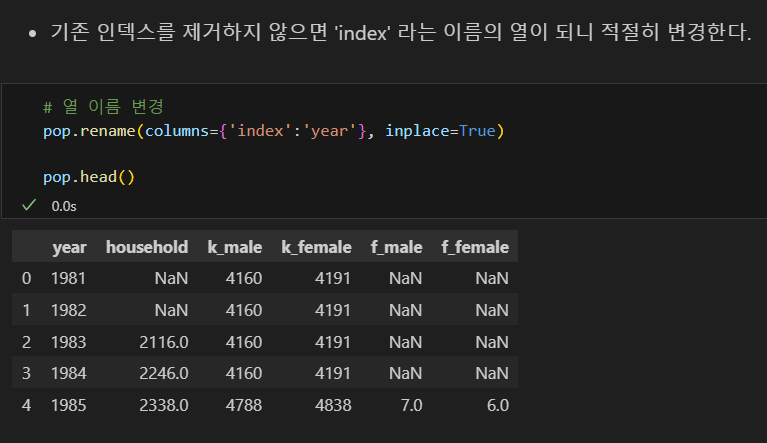
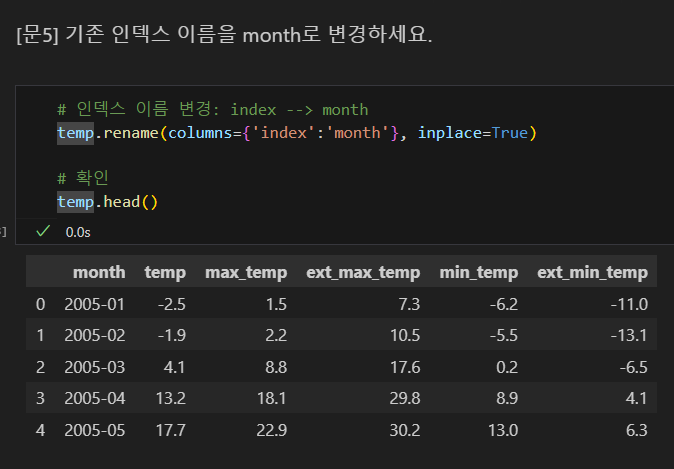
기존 인덱스명을 제거
연습 문제
1.2. 데이터프레임 탐색
- 데이터프레임 탐색은 데이터프레임의 키와 몸무게를 재는 것이라 할 수 있다.
- 파일에서 불러온 데이터의 크기, 내용, 분포, 누락된 값 등을 확인할 수 있어야 한다.
- 확인된 내용을 통해 데이터 전처리 필요 여부를 결정한다.
- 데이터를 알아야 데이터를 분석할 수 있다.
데이터 내용 확인하기
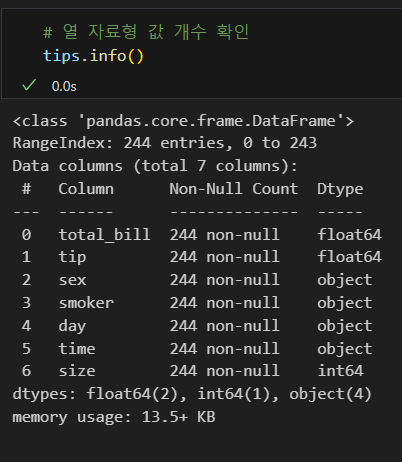
head(): 상위 데이터 확인tail(): 하위 데이터 확인shape: 데이터프레임(행, 열) 크기 확인index: 인덱스 정보 확인values: 값 정보 확인columns: 열 이름 확인dtypes: 열 자료형 확인info(): 데이터프레임의 열에 대한 요약 정보 확인describe(): 기초통계정보 확인

상위 데이터 확인

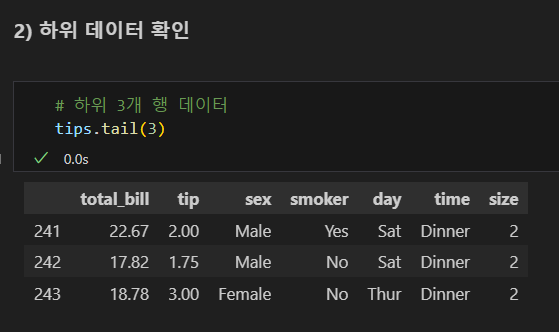
하위 데이터 확인
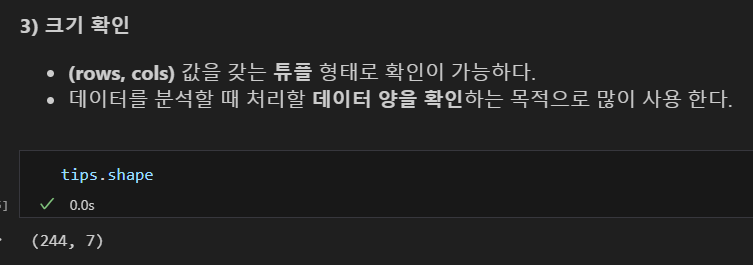
데이터 크기 확인
행과 열 확인
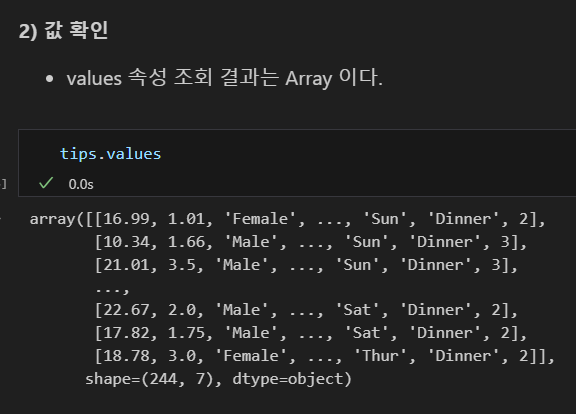
값 조회시 배열로 조회됨
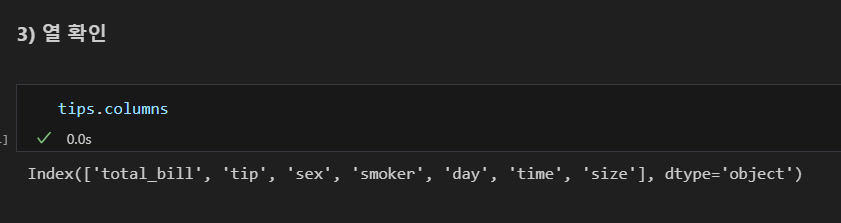
데이터 형식 확인
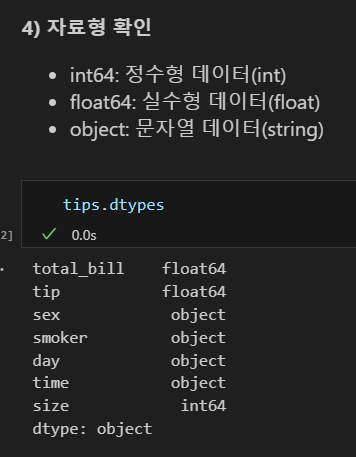
열 값 개수 확인
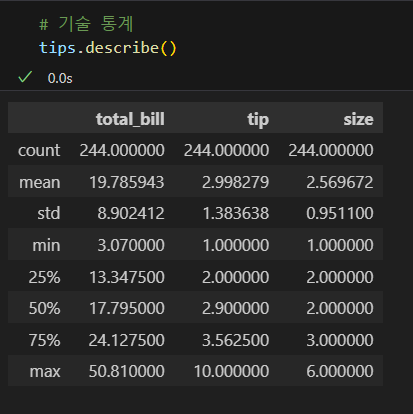
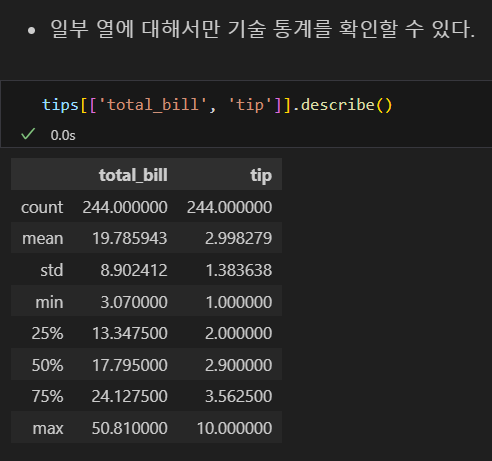
기술 통계 확인
- 기술 통계(Descriptive Statistics)는 데이터의 정리, 요약, 해석, 표현 등을 통해 데이터가 갖는 특성을 나타내는 정보이다.
- describe() 메소드는 데이터에 대한 많은 정보를 제공하는 매우 중요한 메소드이다.
- 개수(count), 평균(mean), 표준편차(std), 최솟값(min), 사분위값(25%, 50%, 75%), 최댓값(max)을 표시한다.
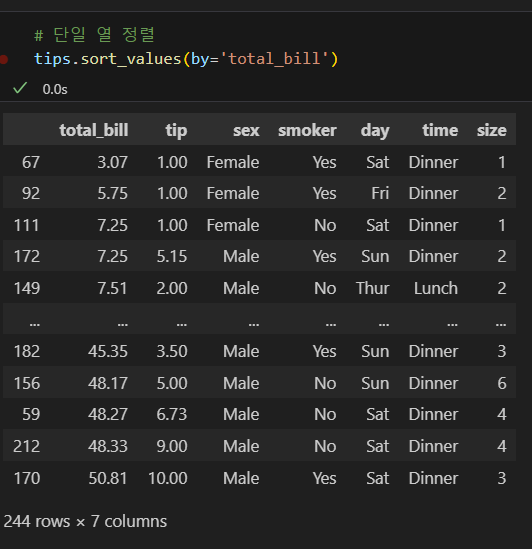
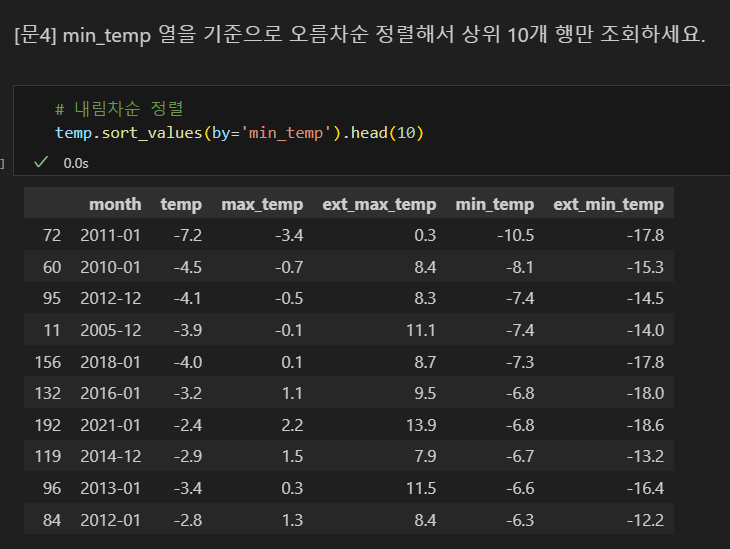
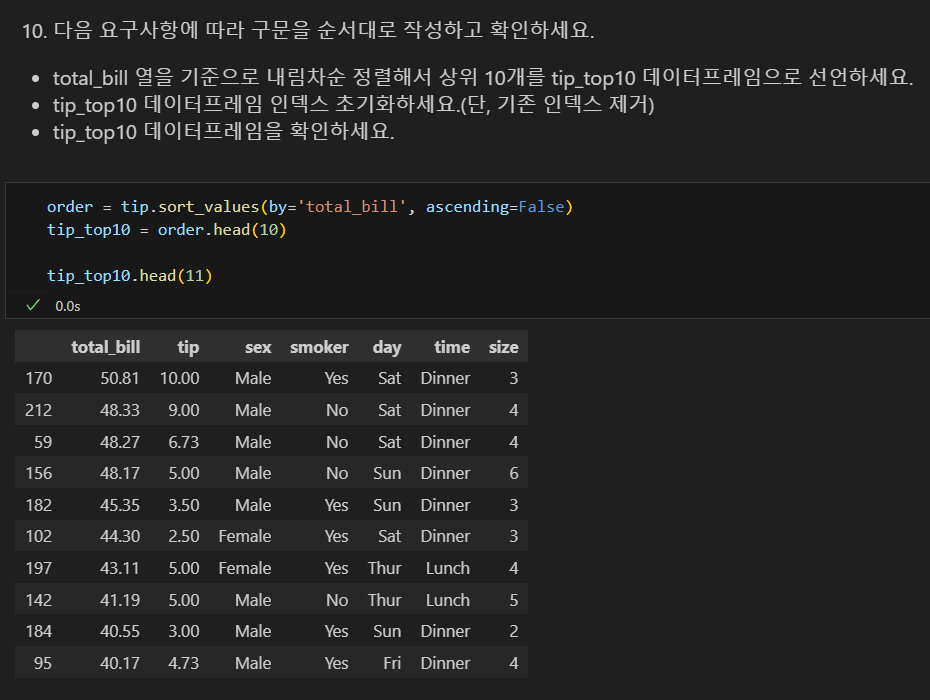
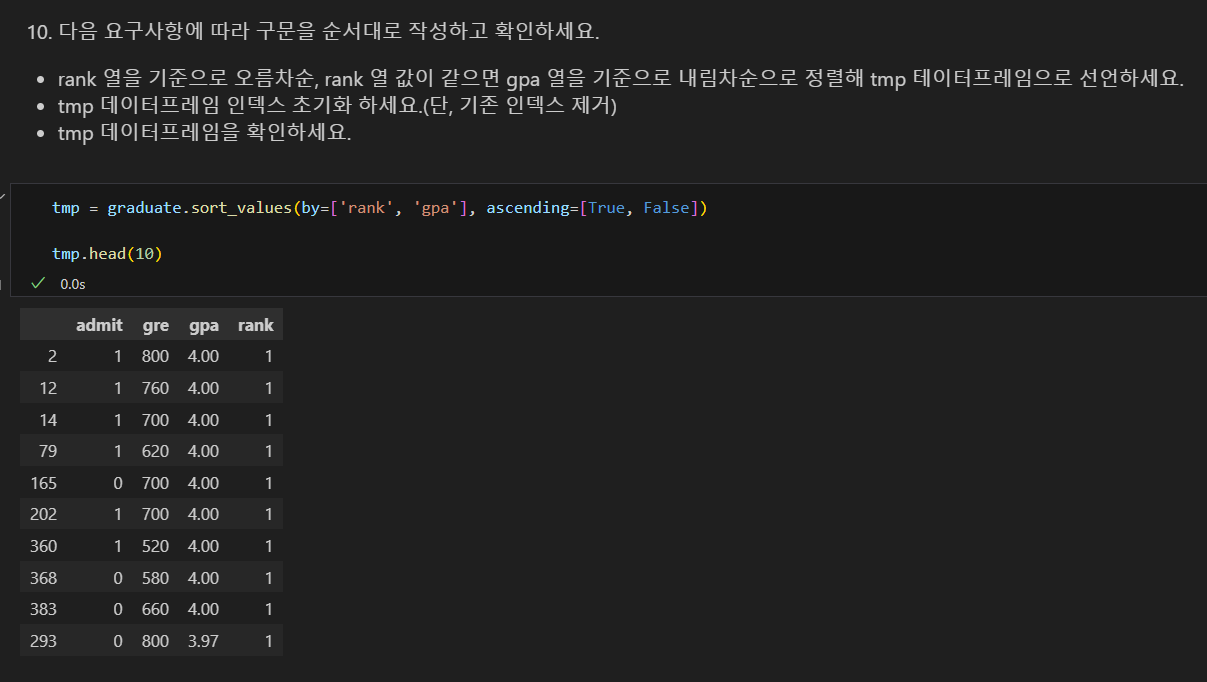
데이터 정렬해서 보기
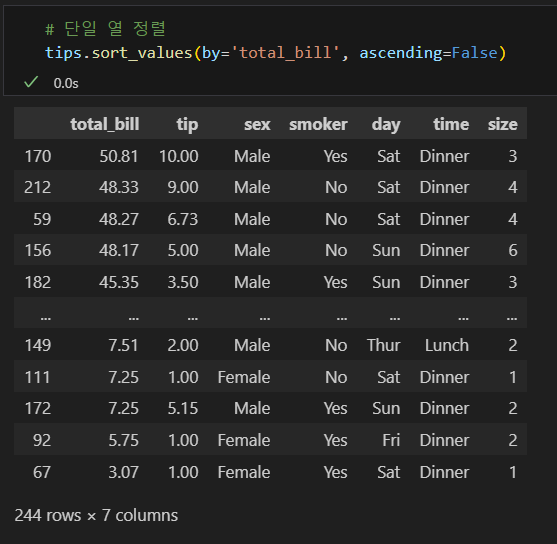
- 인덱스를 기준으로 정렬하는 방법과 특정 열을 기준으로 정렬하는 방법이 있다.
- sort_values() 메소드로 특정 열을 기준으로 정렬한다.
- ascending 옵션을 설정해 오름차순, 내림차순을 설정할 수 있다.
- ascending=True: 오름차순 정렬(기본값)
- ascending=False: 내림차순 정렬
단일 열 정렬
내림차순
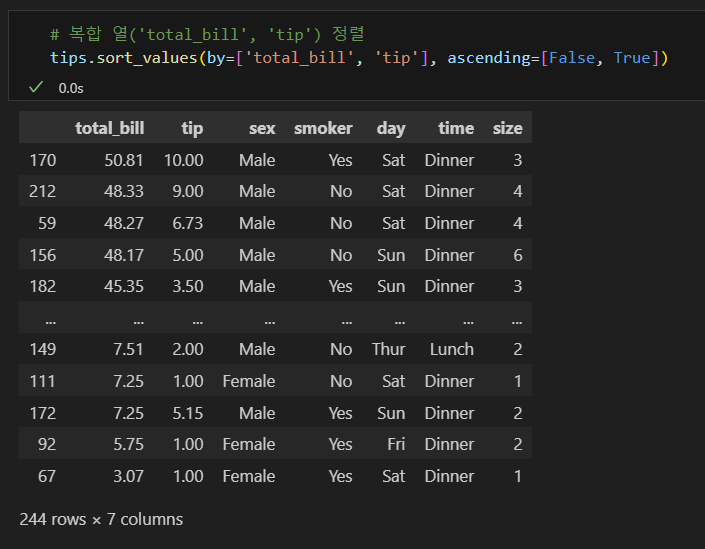
복합 열 정렬
체인 방식으로 조회
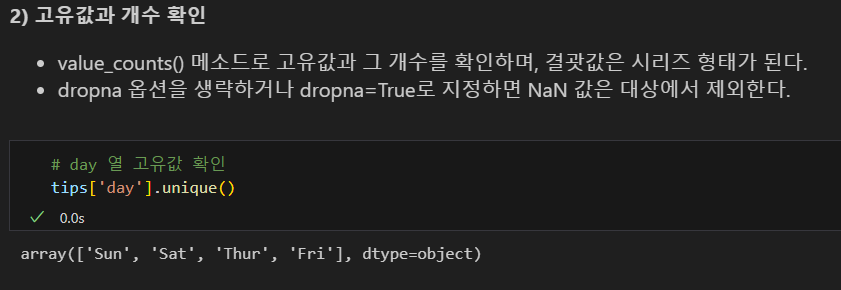
고유값 확인
- 범주형 열(열이 가진 값이 일정한 값인 경우, 성별, 등급 등)인지 확인할 때 사용한다.
- unique() 메소드로 고유값을 확인하며, 결괏값은 배열 형태가 된다.
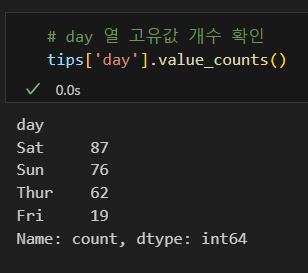
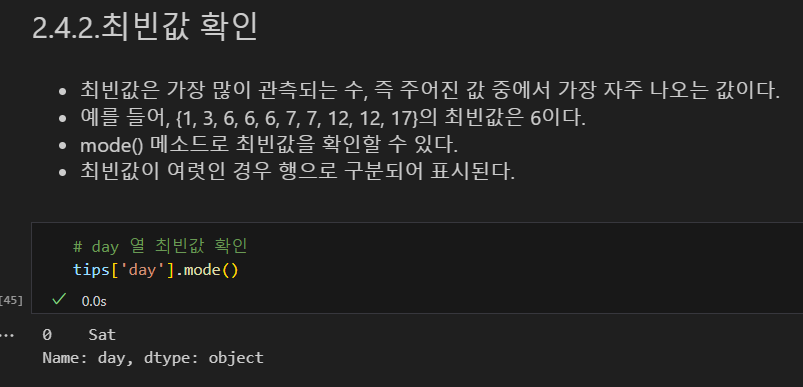
최빈값 (가장 자주 나오는 값) : mode() 메소드로 확인
통계 메소드
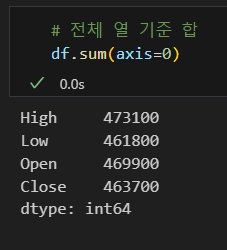
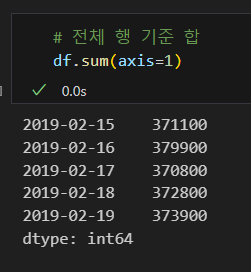
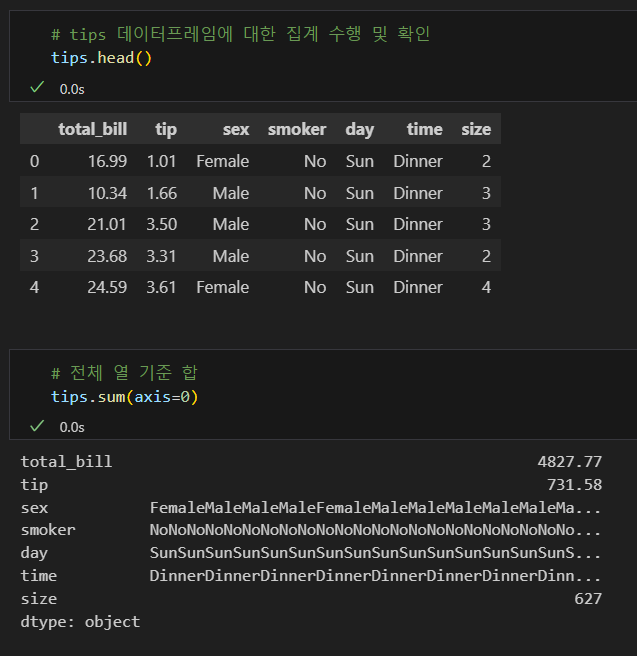
열 합계 조회
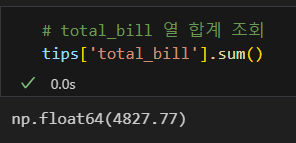
최대값 조회
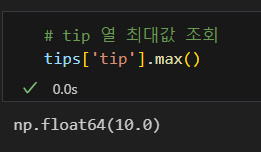
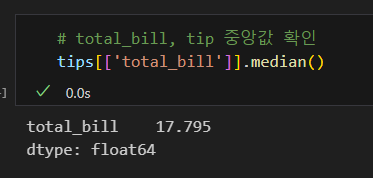
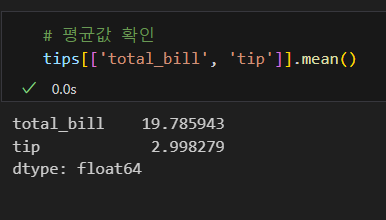
중앙값 조회
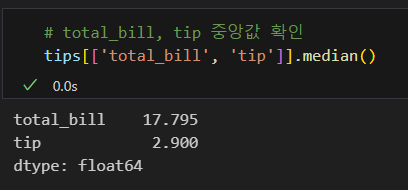
표준편차
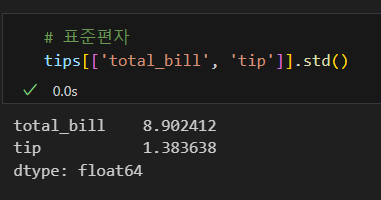
평균값
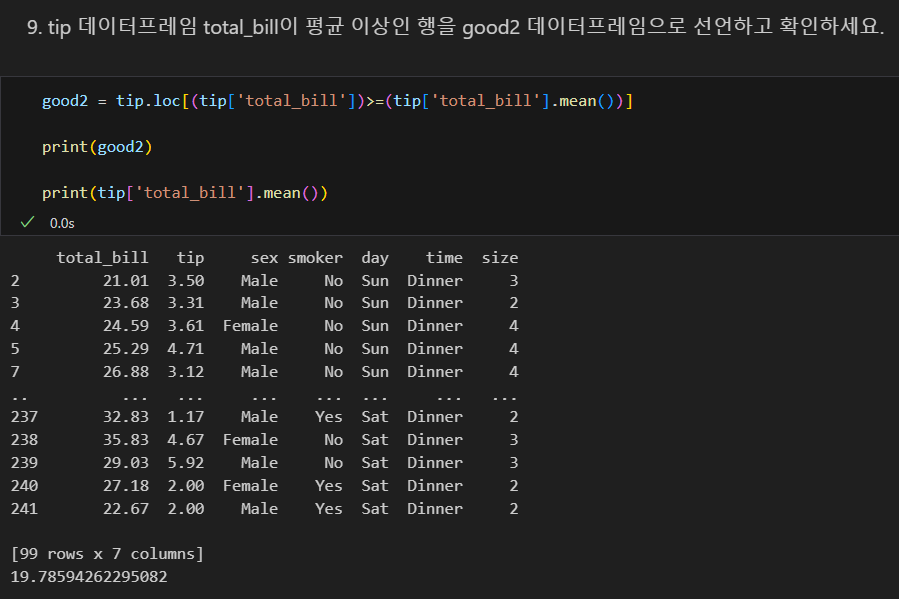
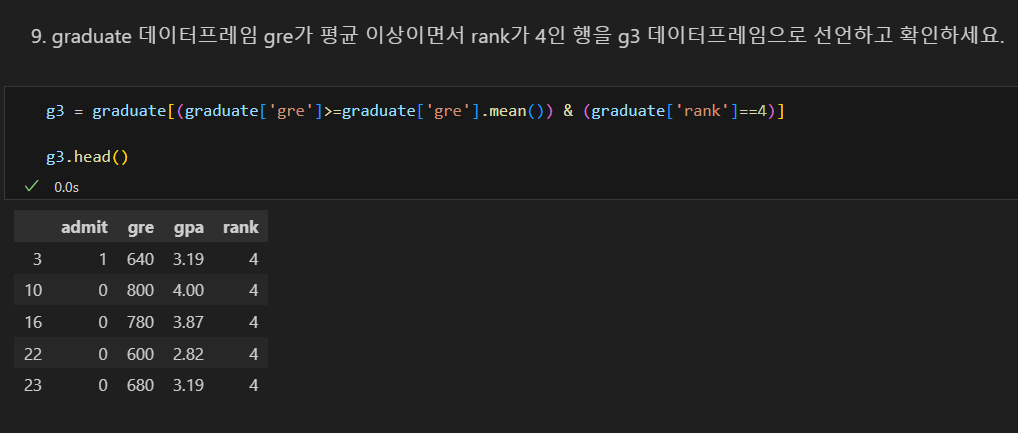
문제 풀기
데이터 탐색 문제 풀기
범주형 시각화
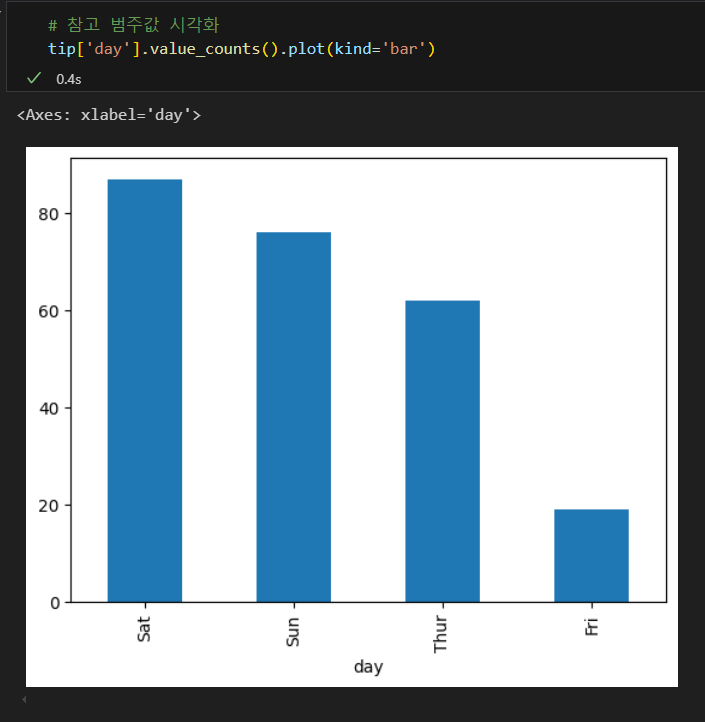
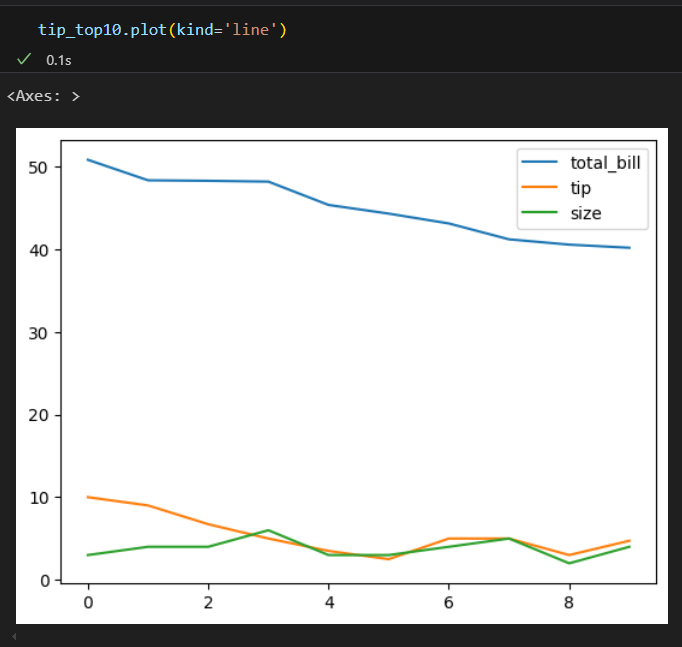
1.3. 데이터프레임 조회
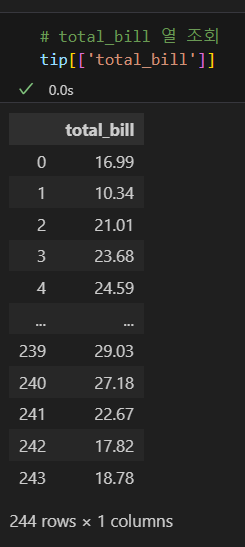
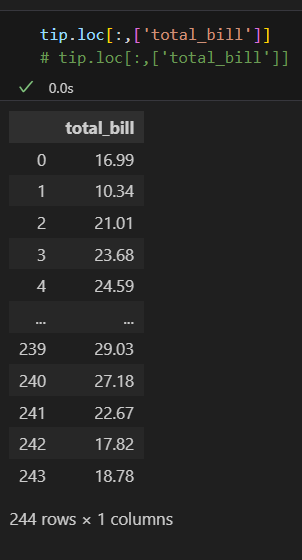
특정 열 조회
- df.loc[ : , [열 이름1, 열 이름2,...]] 형태로 조회할 열 이름을 리스트로 지정한다.
- 조회할 열이 하나면 리스트 형태가 아니어도 된다.
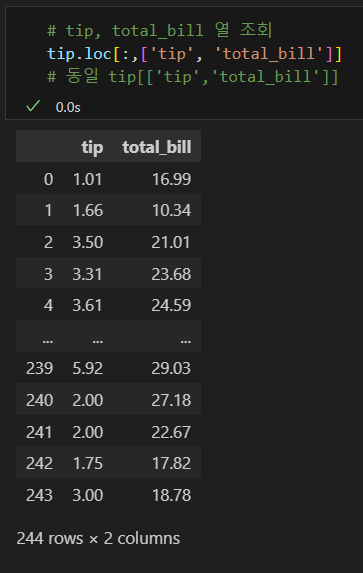
- 열 부분은 생략할 수 있었지만, 행 부분을 생략할 수는 없다.
- 하지만 df[[열 이름1, 열 이름2,...]] 형태로 인덱서를 생략함이 일반적이다.
아래 형태에서 생략한 것.
열 범위 조회
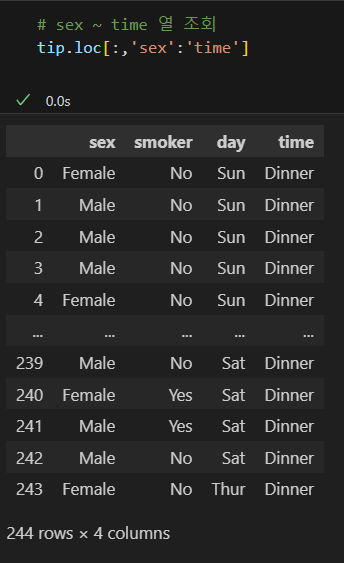
- 범위 조회는 df.loc[:, 열 이름1:열 이름2] 형태로 조회한다.
- 범위는 하나만 지정할 수 있어 리스트가 될 수 없으니 대괄호를 사용하지 않는다.
- 범위 마지막 열도 조회 대상에 포함된다.
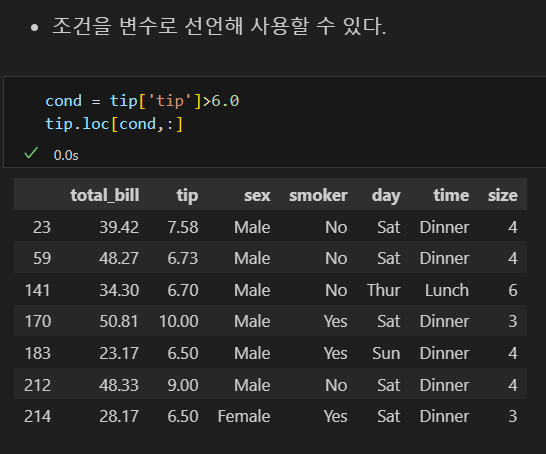
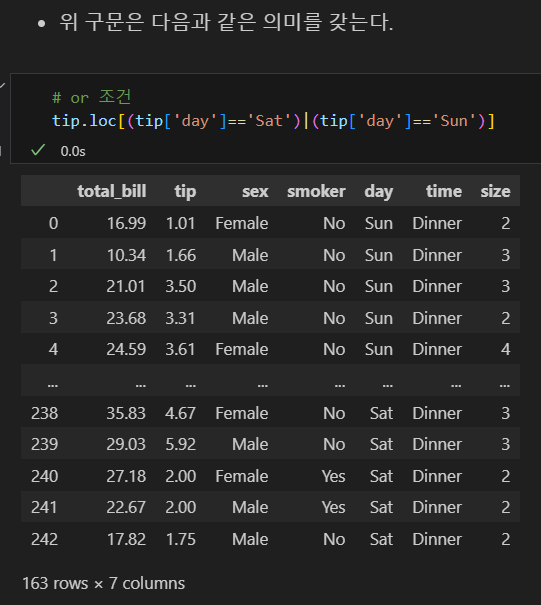
& 연산자
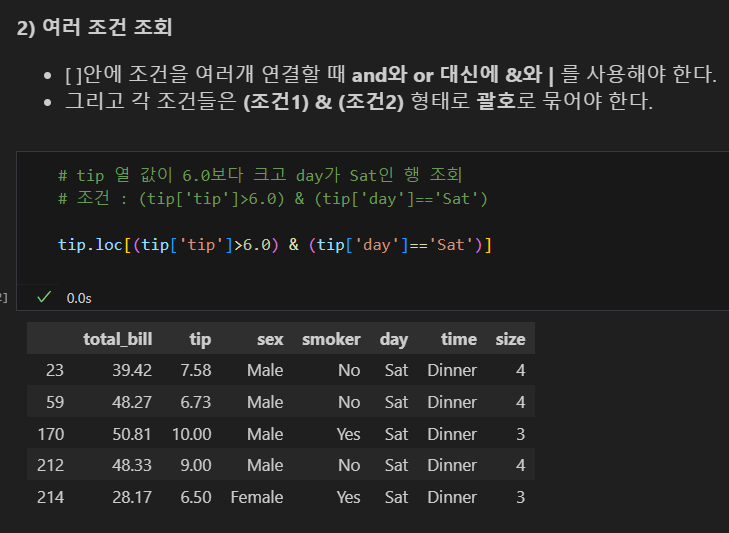
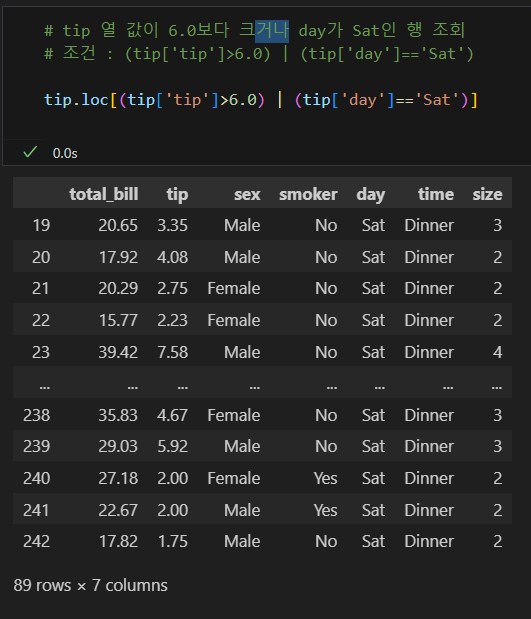
| 연산자
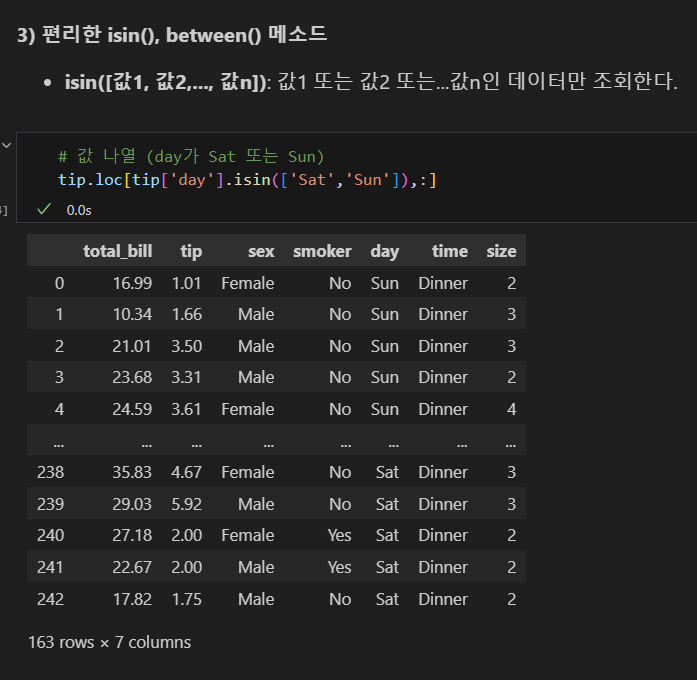
isin() 메소드
아래와 같은 의미
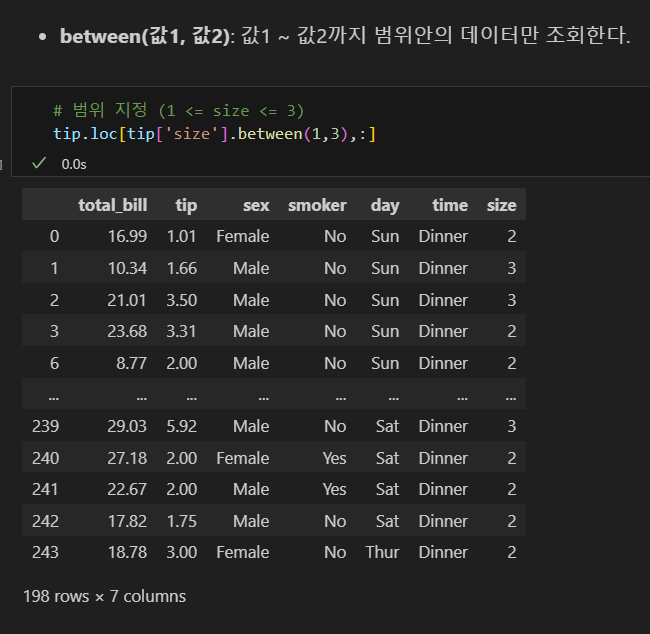
between 메소드
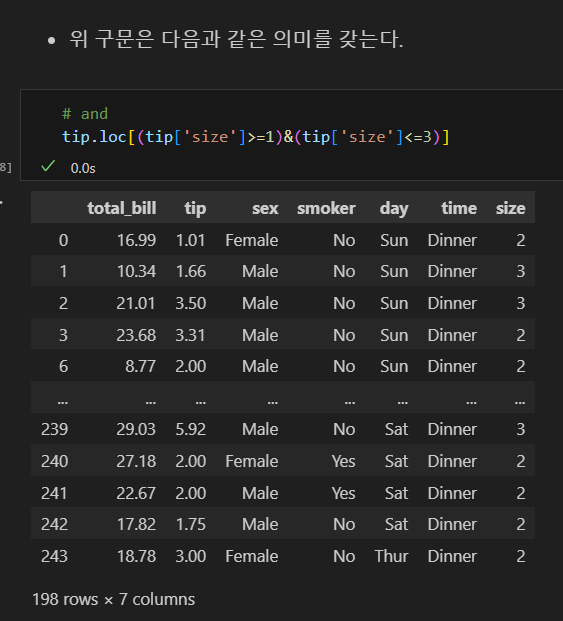
아래와 같은 의미
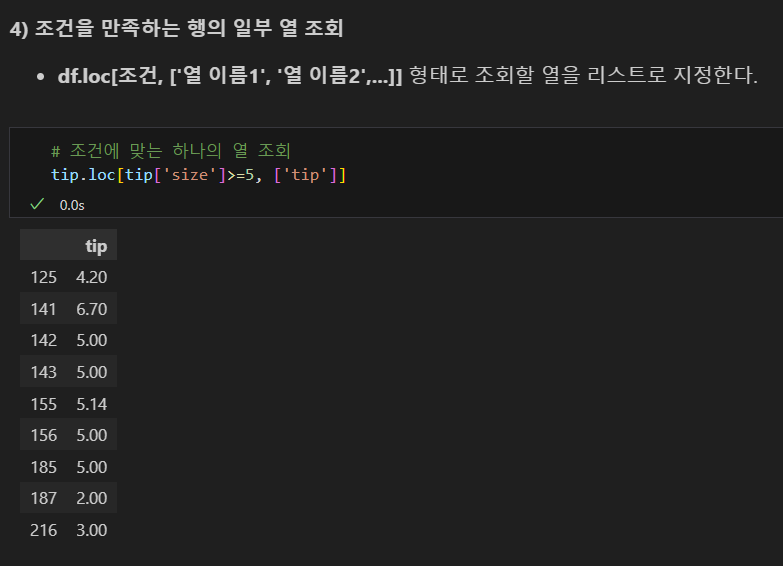
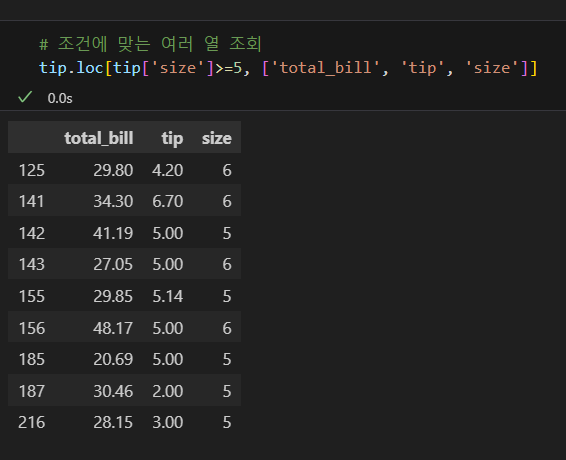
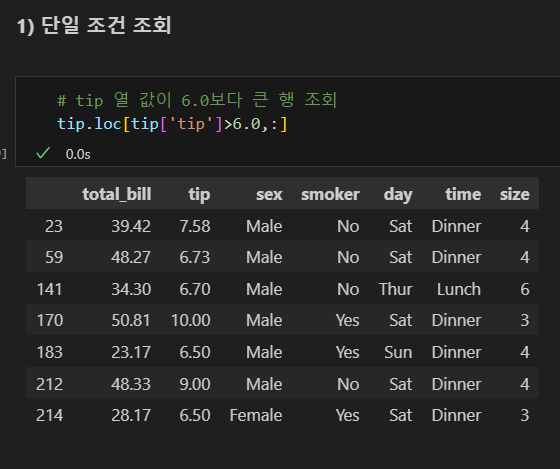
loc 조회

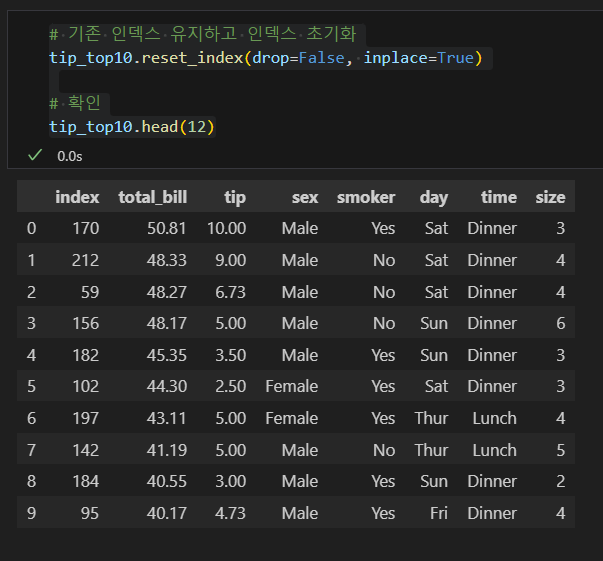
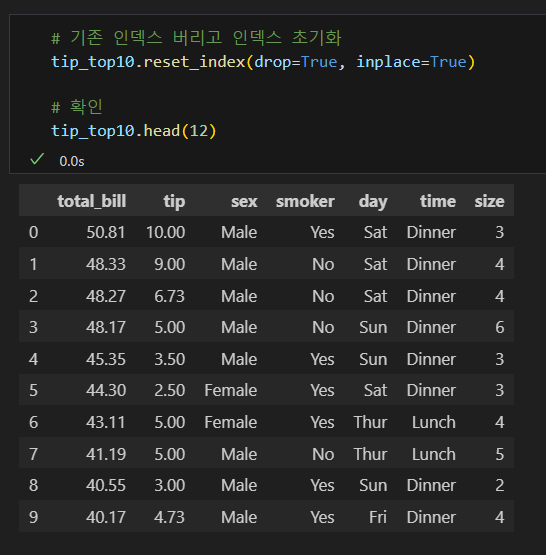
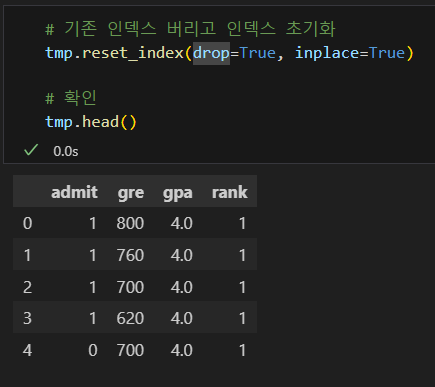
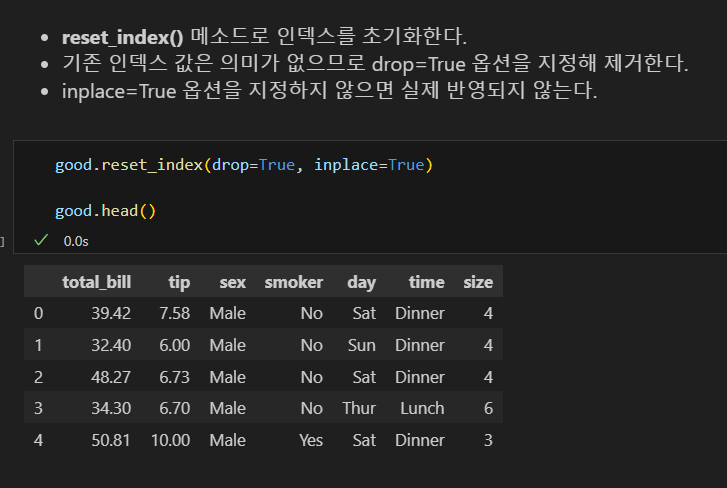
인덱스 초기화
- 다음과 같은 경우 인덱스 초기화가 필요하다.
- 기존 데이터프레임에서 일부 행을 가져와 새로 만든 데이터프레임
- 일부 행이 지워진 데이터프레임
- 특히 0부터 시작하는 정수형 인덱스의 경우 초기화를 하는 것이 좋다.
- 깔끔한 데이터가 사용하기 좋은 데이터이다.
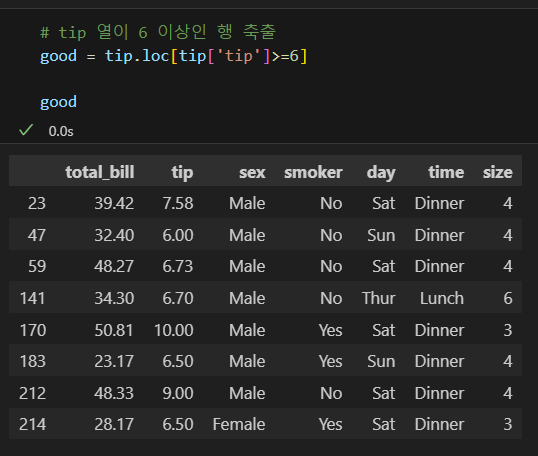
인덱스 초기화
iloc[ ]로 필터링하기
- iloc는 정수 위치(integer location)의 줄임말로 정수값으로 필터링할 때 사용
- loc[ ]와 비슷하지만 필터링할 때 대상을 정수로 짚어내야 하는 점이 다르다.
범위 선택시 마지막 값은 제외됨.
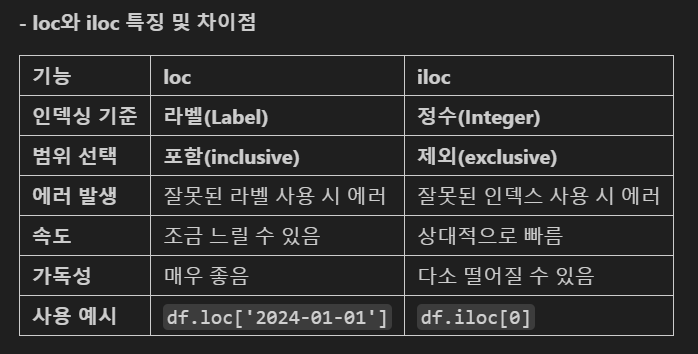
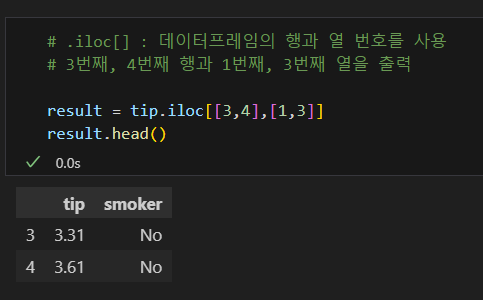
데이터프레임 조회 실습