KPMG Future Academy AI 활용 데이터 분석가 3기 33일차 수업을 2025년 1월 3일에 참석했다.
- 판다스
1.1. 데이터프레임 집계
1.2. 데이터프레임 변경
1.3. 데이터프레임 결측치 처리
1. 판다스
1.1. 데이터프레임 집계
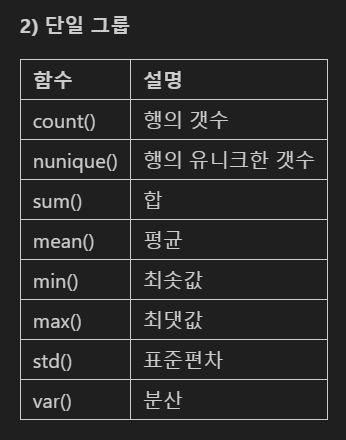
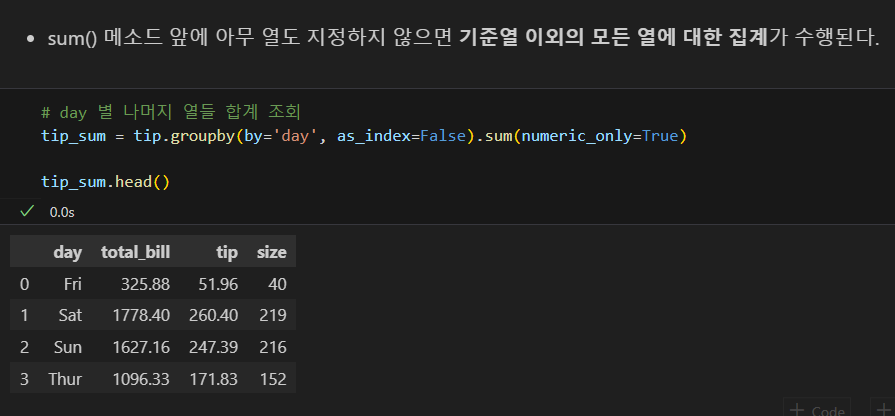
sum(), mean(), max(), min(), count() 메소드
sum()합계. array로 나옴
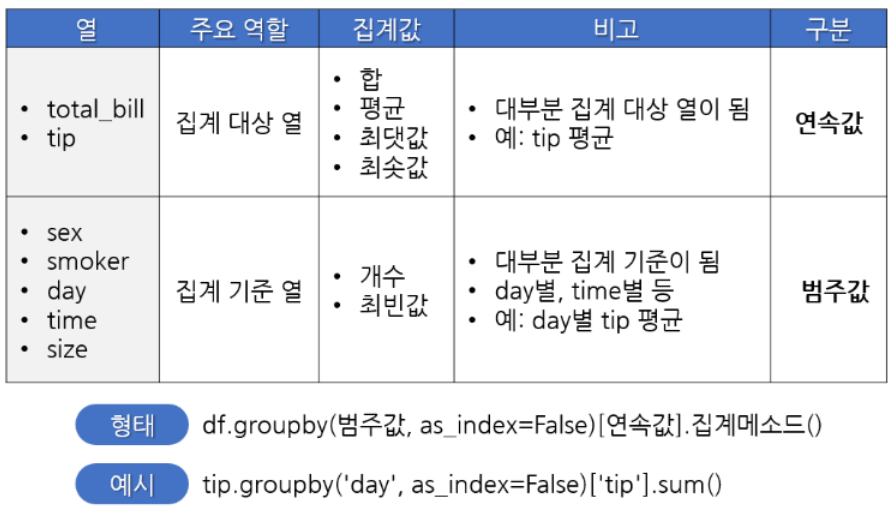
그룹별 집계하기; groupby()함수
- 같은 값을 한 그룹으로 묶어서 여러 가지 연산 및 통계를 구할 수 있다.
- dataframe.groupby(by=grouping_columns)[columns_names].function()
- dataframe : 대상 데이터프레임을 의미
- by : 그룹화할 열을 지정하는 매개변수
- grouping_columns : 그룹화할 열 이름 또는 열 이름의 리스트
- columns_names : 집계 결과에서 표시할 열 이름 또는 열 이름의 리스트
- function() : 적용할 집계 함수를 지정하는 함수
타이타닉 생존자 데이터
불러오기
승객ID를 문자형으로 바꾸기
클래스별 탑승객수
값의 유니크한 갯수 확인
합계
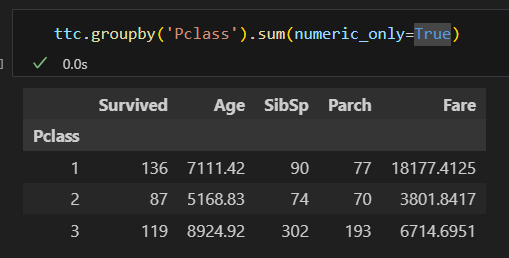
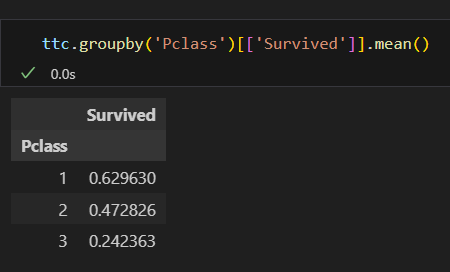
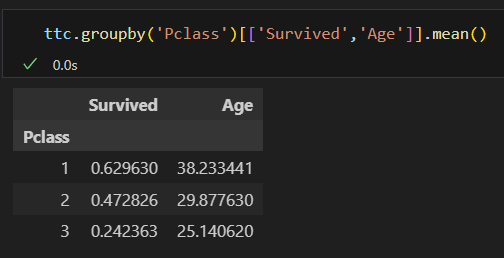
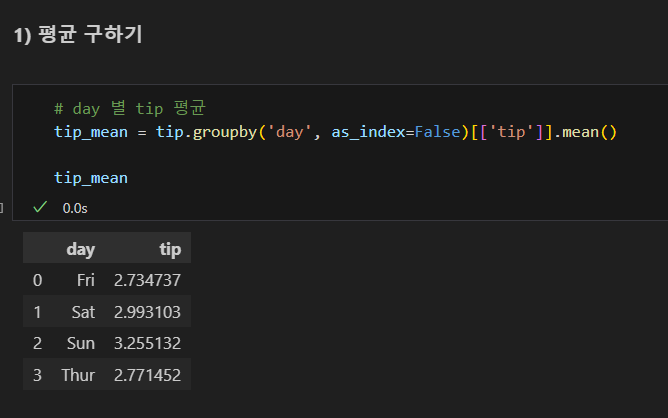
평균
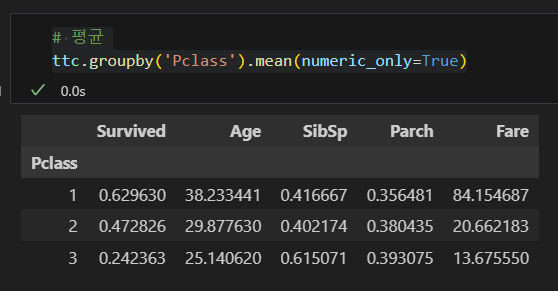
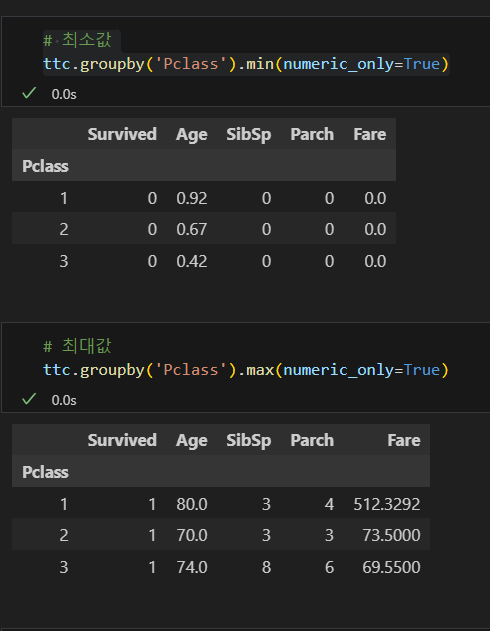
최대, 최소값
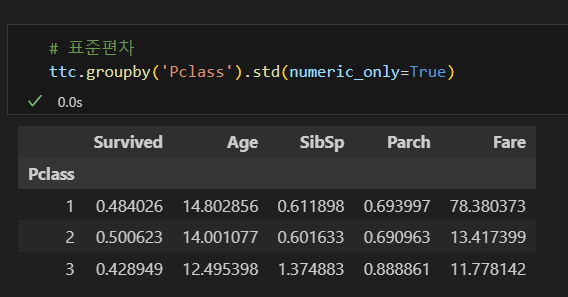
표준편차
분산
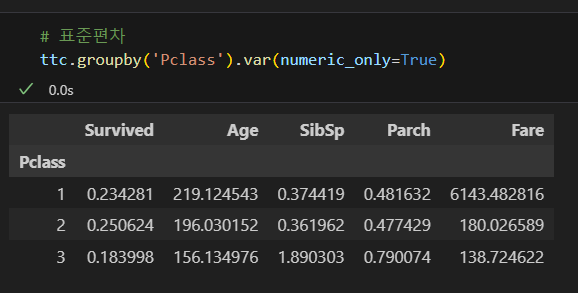
특정 열만 집계
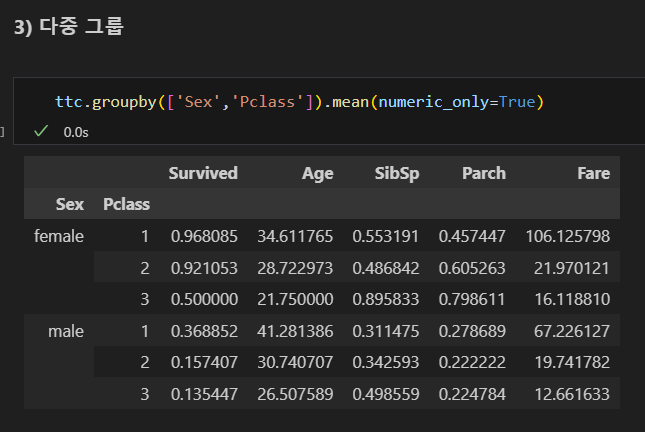
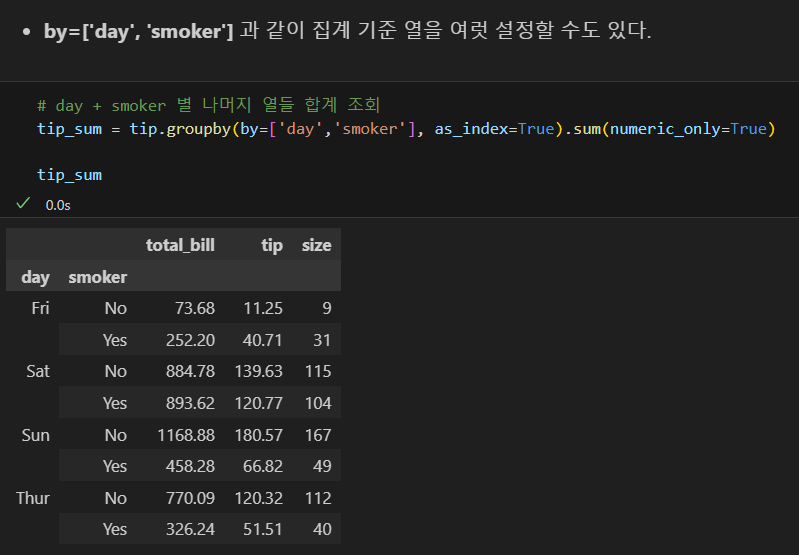
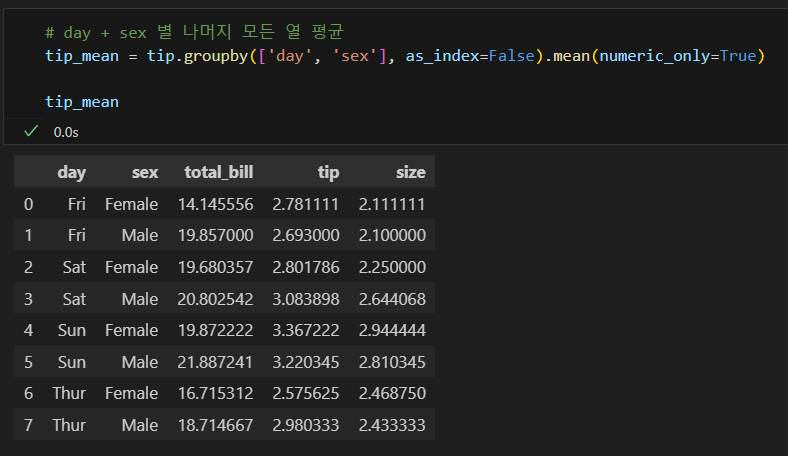
다중 그룹
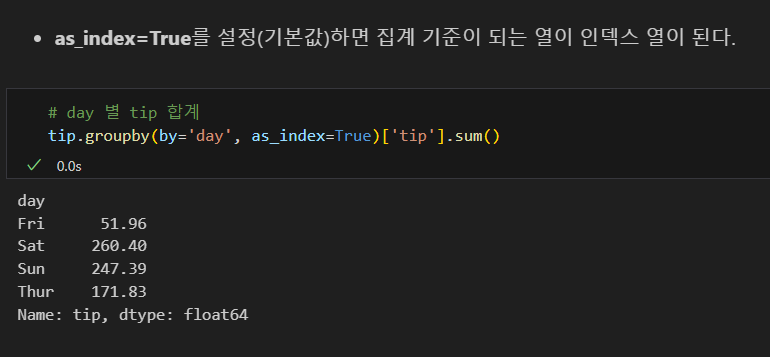
데이터프레임으로 출력
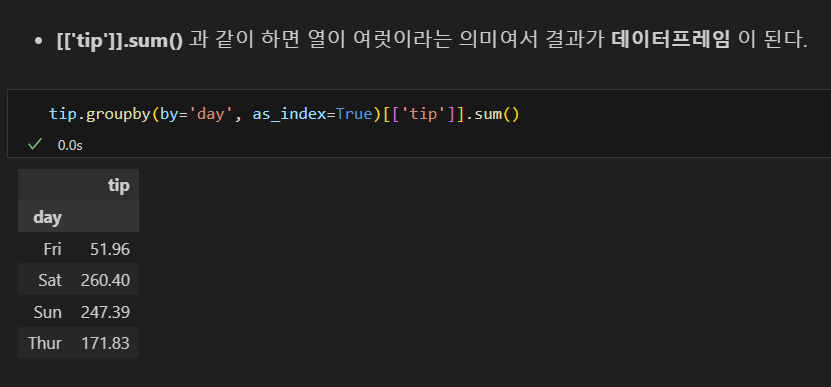
as_index=False인 경우
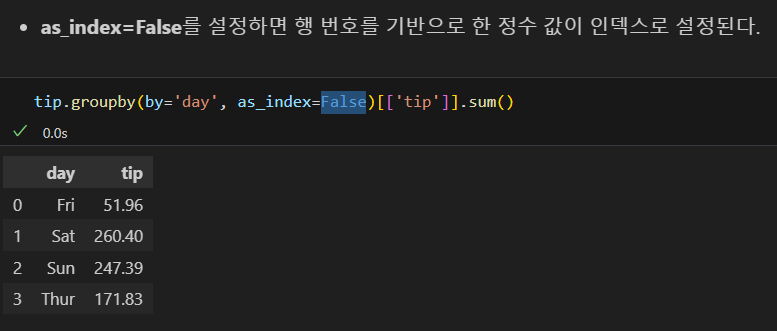
집계 결과를 새로운 데이터프레임으로 선언하는 것이 편의상 좋음.
matplotlib
Jupyter Notebook에서 그래프를 더 선명하게 표시하기 위한 설정
%config InlineBackend.figure_format = 'retina'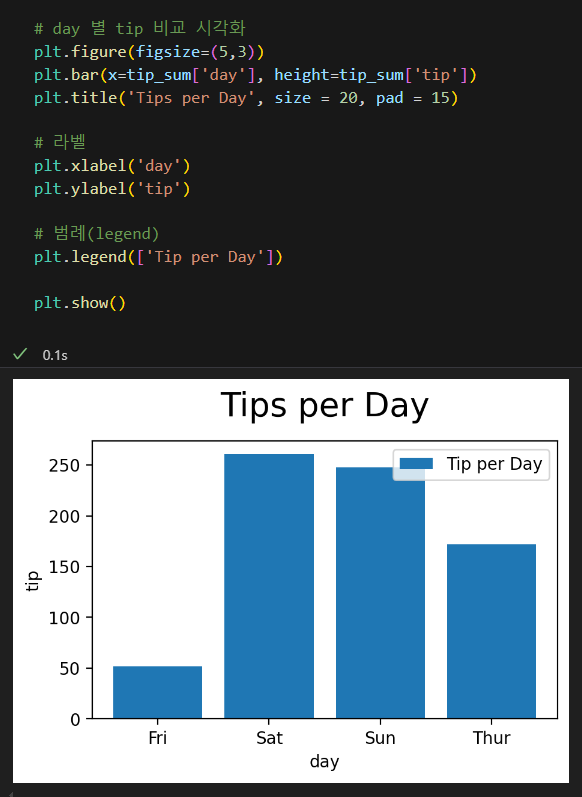
선 그래프
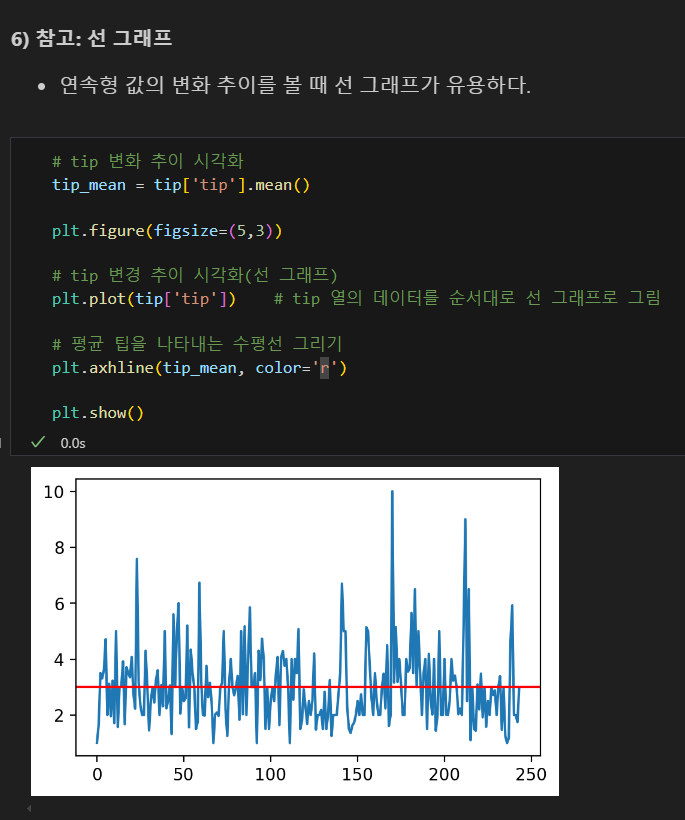
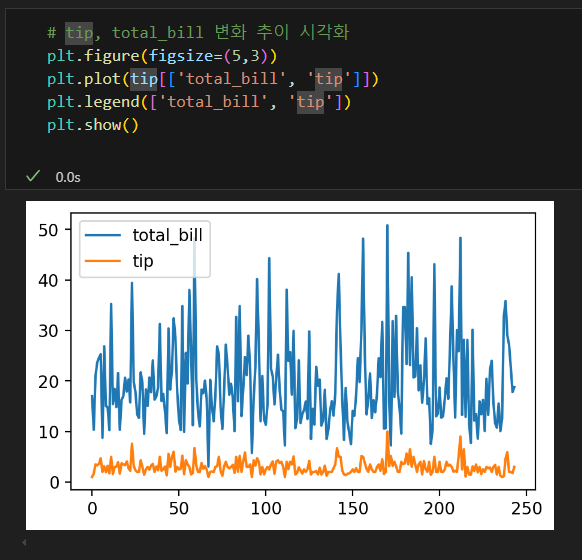
히스토그램
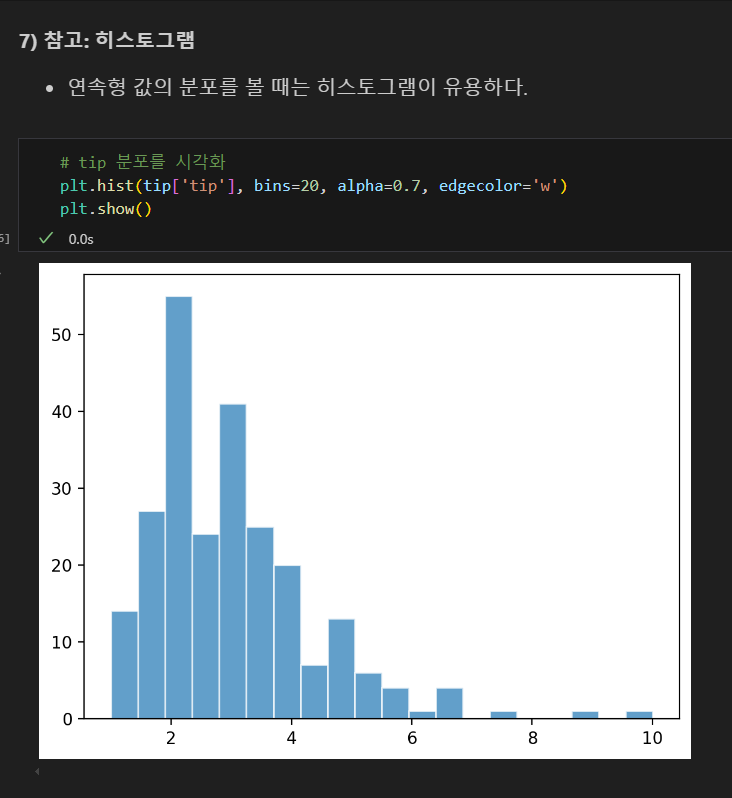
bins = 데이터 구간을 n개로 나눔
alpha = 막대의 투명도
edgecolor = 막대의 아웃라인
여러 열 집계
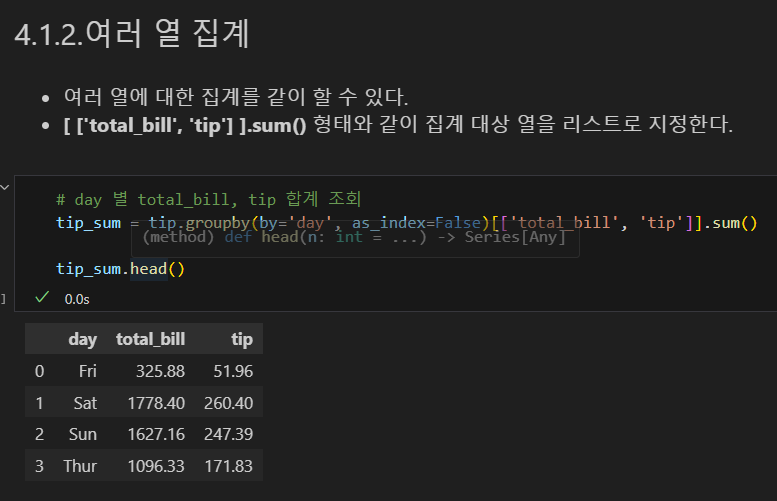
평균 집계
최대값 집계
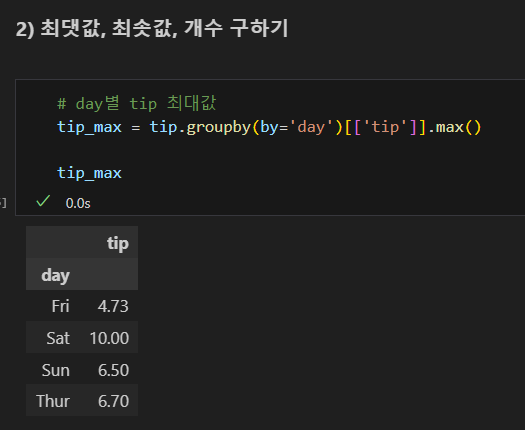
최소값 집계
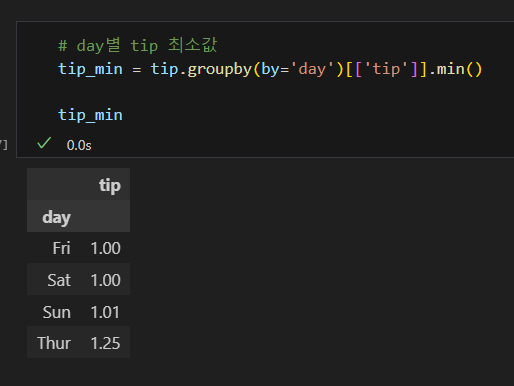
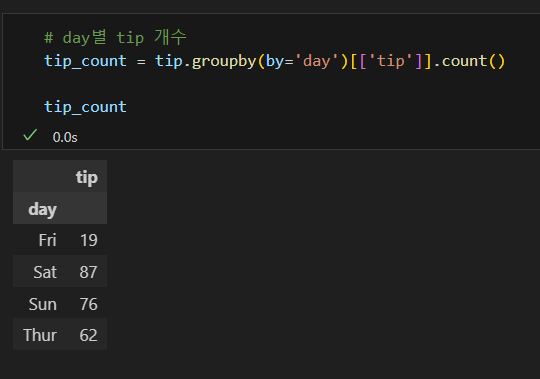
개수 집계
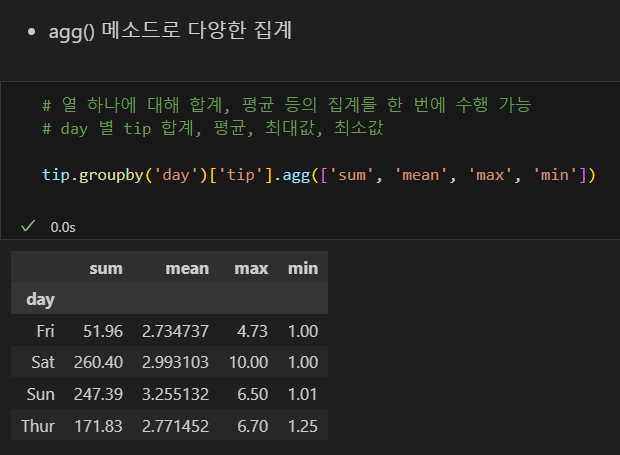
agg 메소드로 열 하나에 대한 집계 한번에 수행
여러 열에 대해 여러 집계 한번에 수행
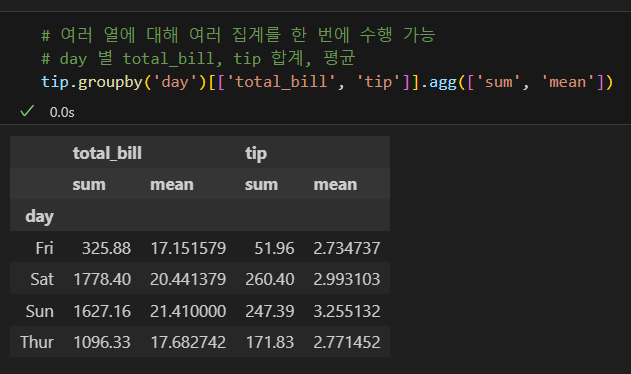
여러 열에 대해 각 열마다 다른 집계를 수행
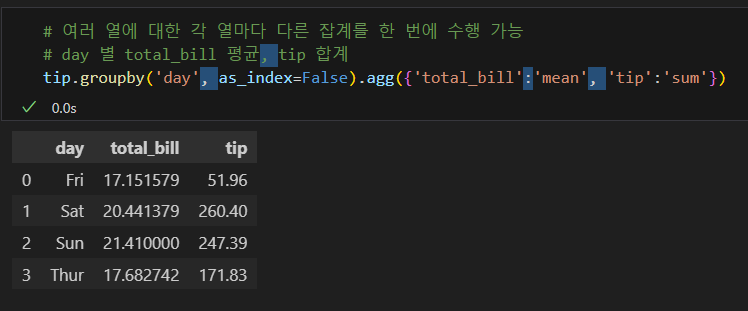
실습
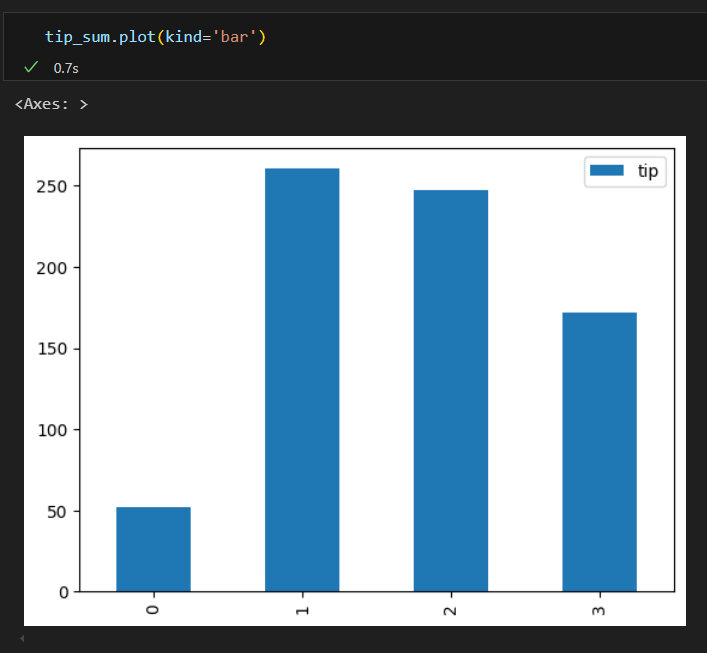
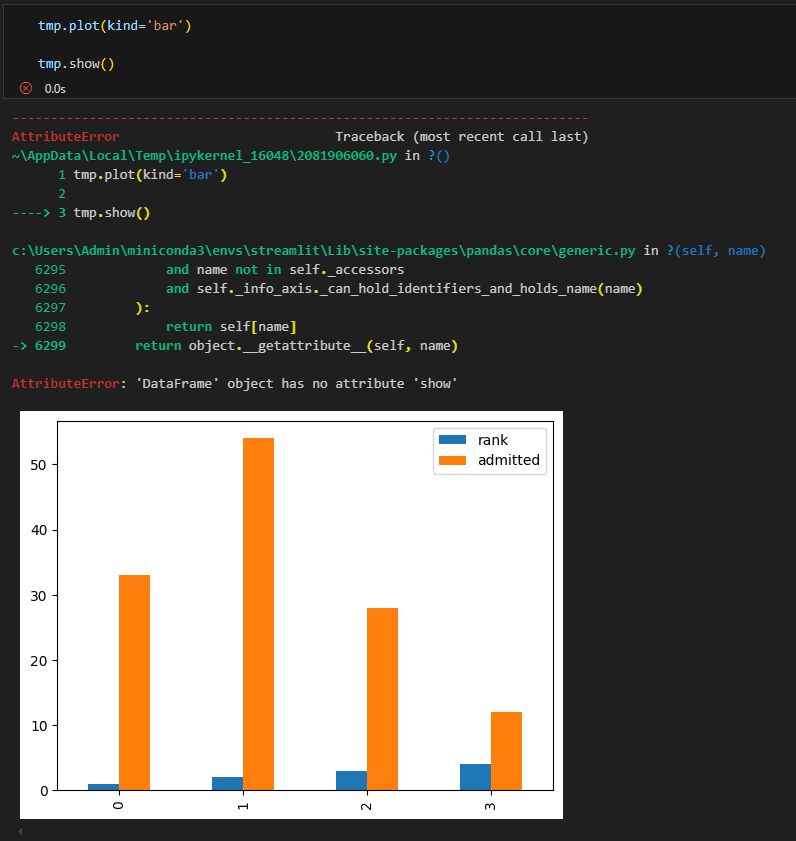
pandas 라이브러리에서 Axes 객체를 활용하지 않고 plot 메소드를 통해 간단한 차트를 그린 사례
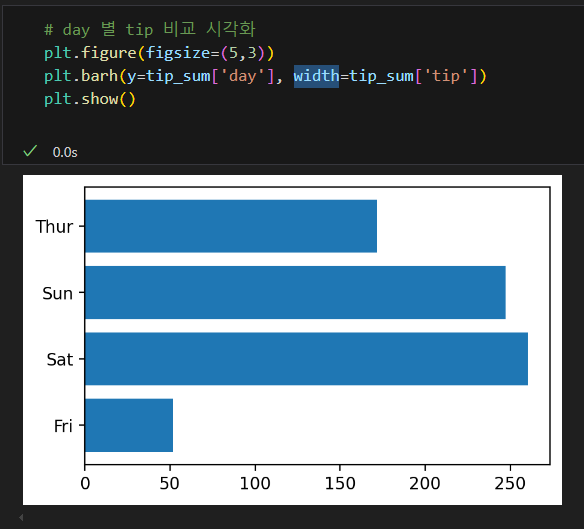
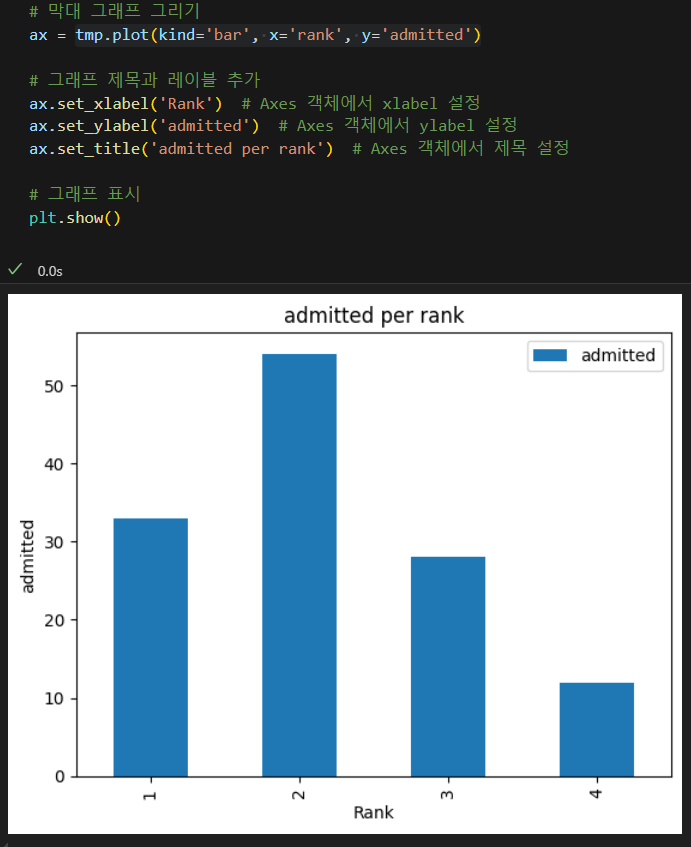
matplotlib 라이브러리를 호출한 후 Axes 객체의 show 메소드를 사용하여 차트를 상세히 그린 사례
자주 쓰이는 라이브러리는 공식 홈페이지에서 메소드 및 객체 구조를 확인해두는 것이 좋을 것 같다.
전체 학생수 대비 합격 학생수를 구한 뒤 합격율을 구하여 이를 rank별로 표시.
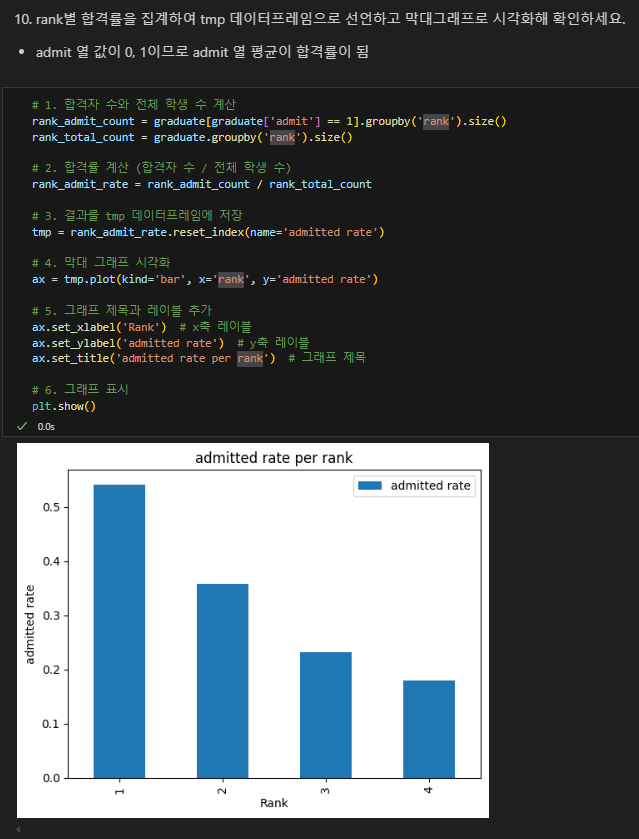
pandas의 plot 메소드는 기본적으로 x축 값이 숫자일 경우, 그 값을 그대로 사용함
1.2. 데이터프레임 변경
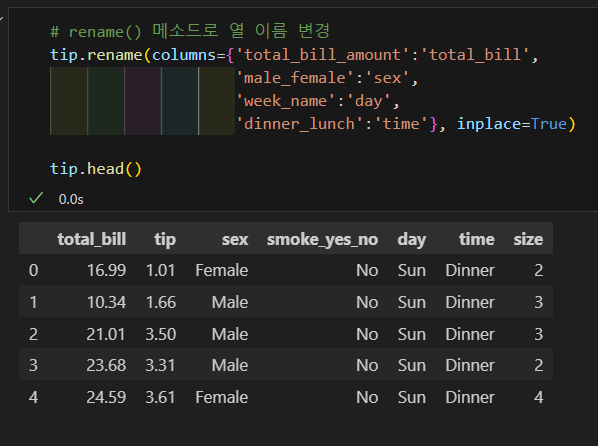
일부 열 이름 변경
- rename() 메소드를 사용해 변경 전후의 열 이름을 딕셔너리 형태로 나열하는 방법으로 변경한다.
- inplace=True 옵션을 설정해야 변경 사항이 실제 반영이 된다.
- 다음과 같이 열 이름을 변경한다.
- total_bill_amount → total_bill
- male_female → sex
- smoke_yes_no → smoker
- week_name → day
- dinner_lunch → time
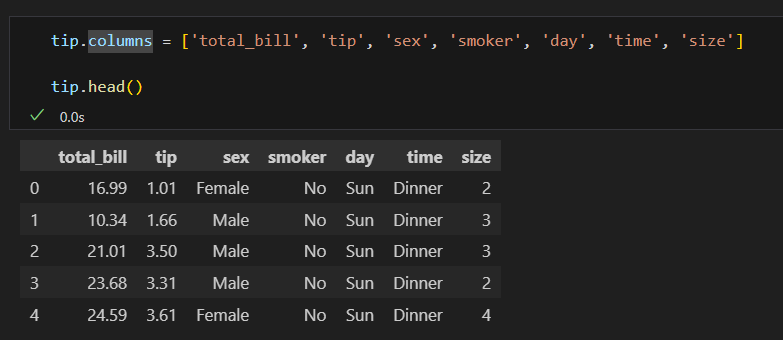
모든 열 이름 변경
- 모든 열 이름을 변경할 때는 columns 속성을 변경한다.
- 변경이 필요없는 열은 기존 이름을 부여해 변경한다.
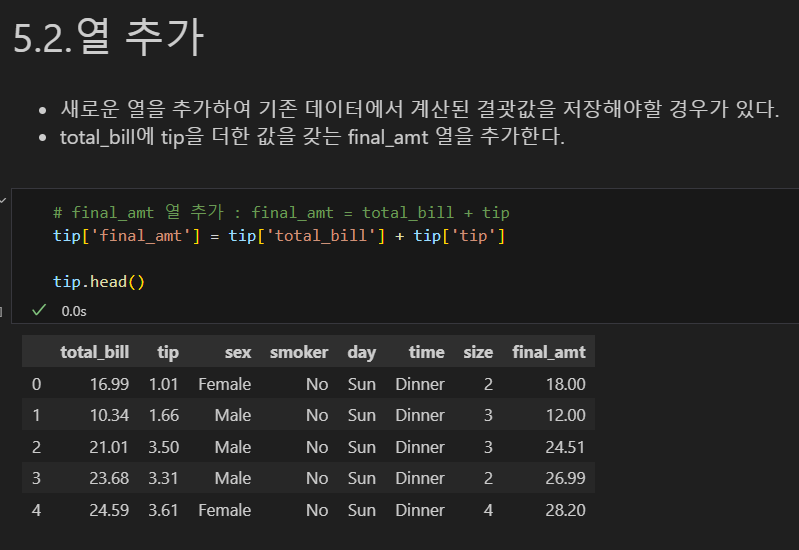
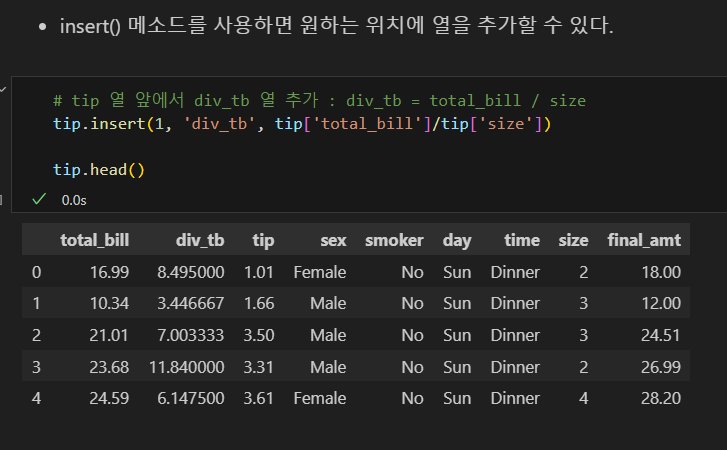
열 추가
- 새로운 열을 추가하여 기존 데이터에서 계산된 결괏값을 저장해야할 경우가 있다.
- total_bill에 tip을 더한 값을 갖는 final_amt 열을 추가한다.
insert()로 열 추가
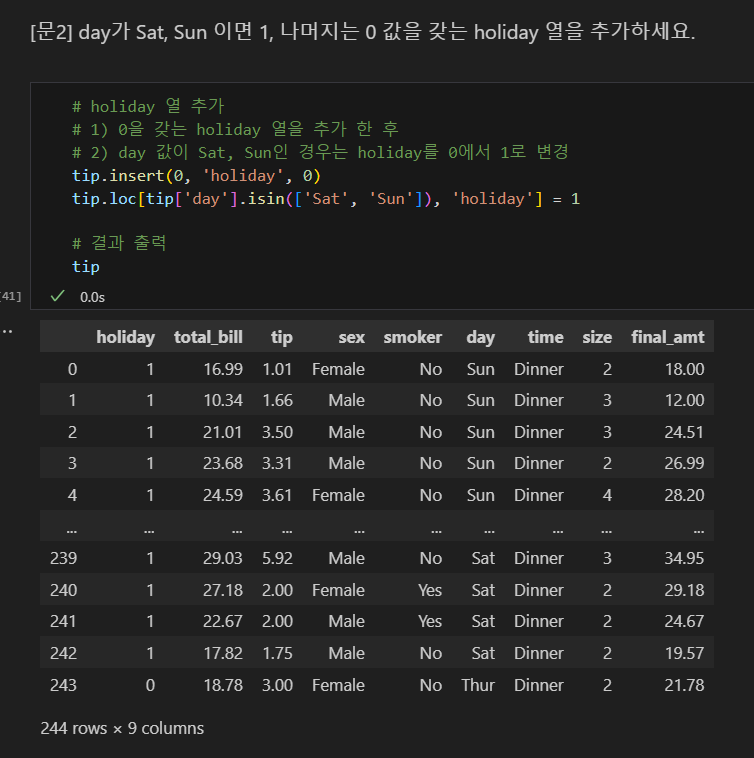
isin 조건 메소드로 값 변경
열 삭제
삭제는 조심히 할 것.
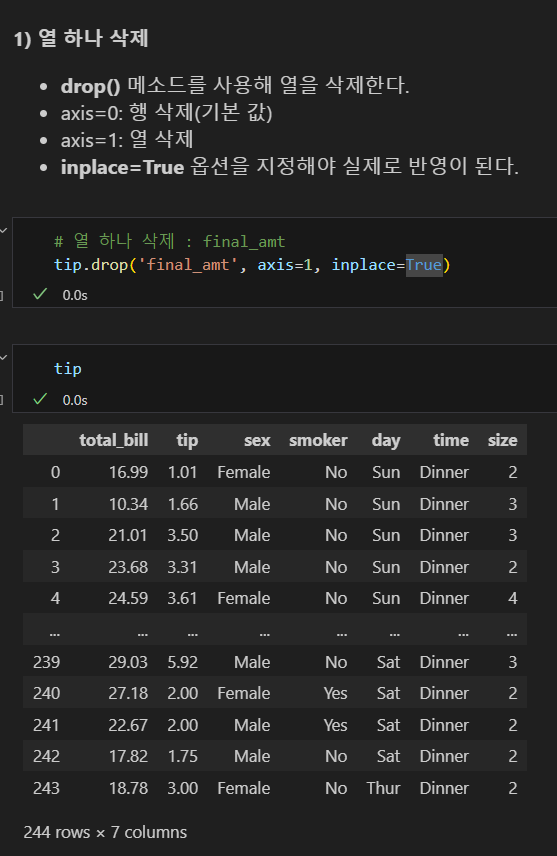
열 하나 삭제
- drop() 메소드를 사용해 열을 삭제한다.
- axis=0: 행 삭제(기본 값)
- axis=1: 열 삭제
- inplace=True 옵션을 지정해야 실제로 반영이 된다.
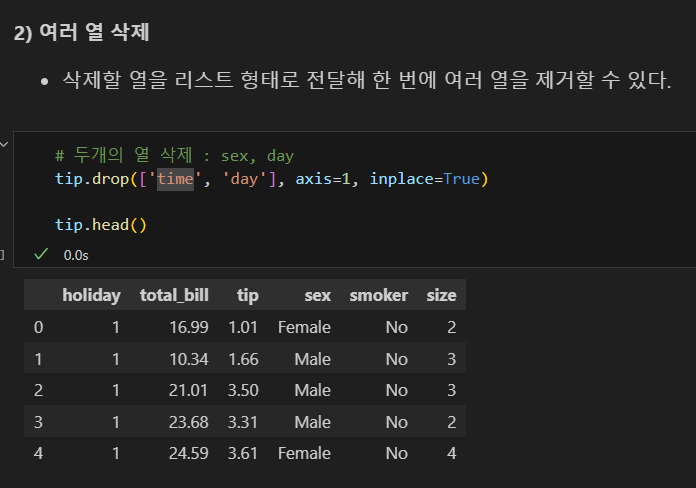
여러 열 삭제
map 메소드로 값 바꾸기

값 변경
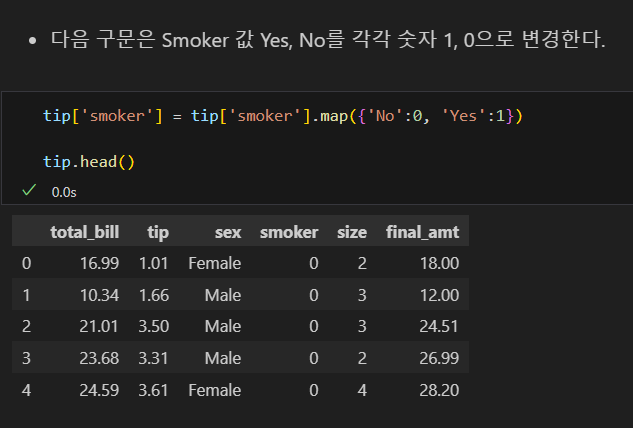
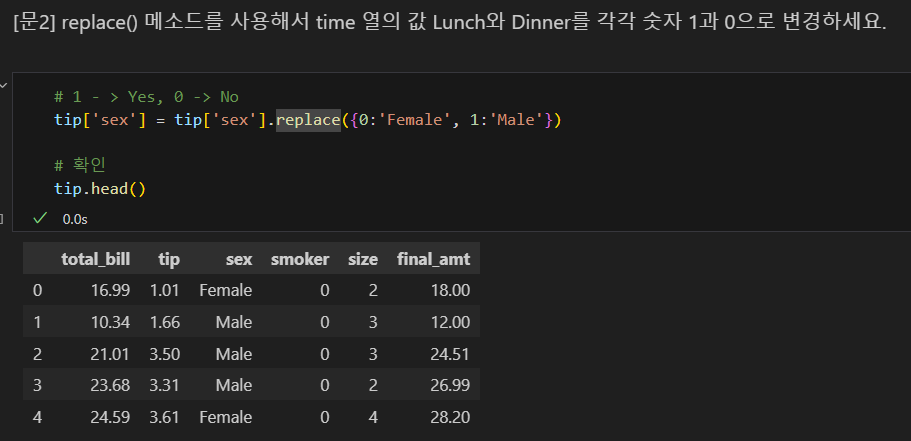
replace 메소드는 맵핑이 안 되면 데이터를 그대로 둠. map은 맵핑이 안 되면 결측치가 됨.

범주값 만들기
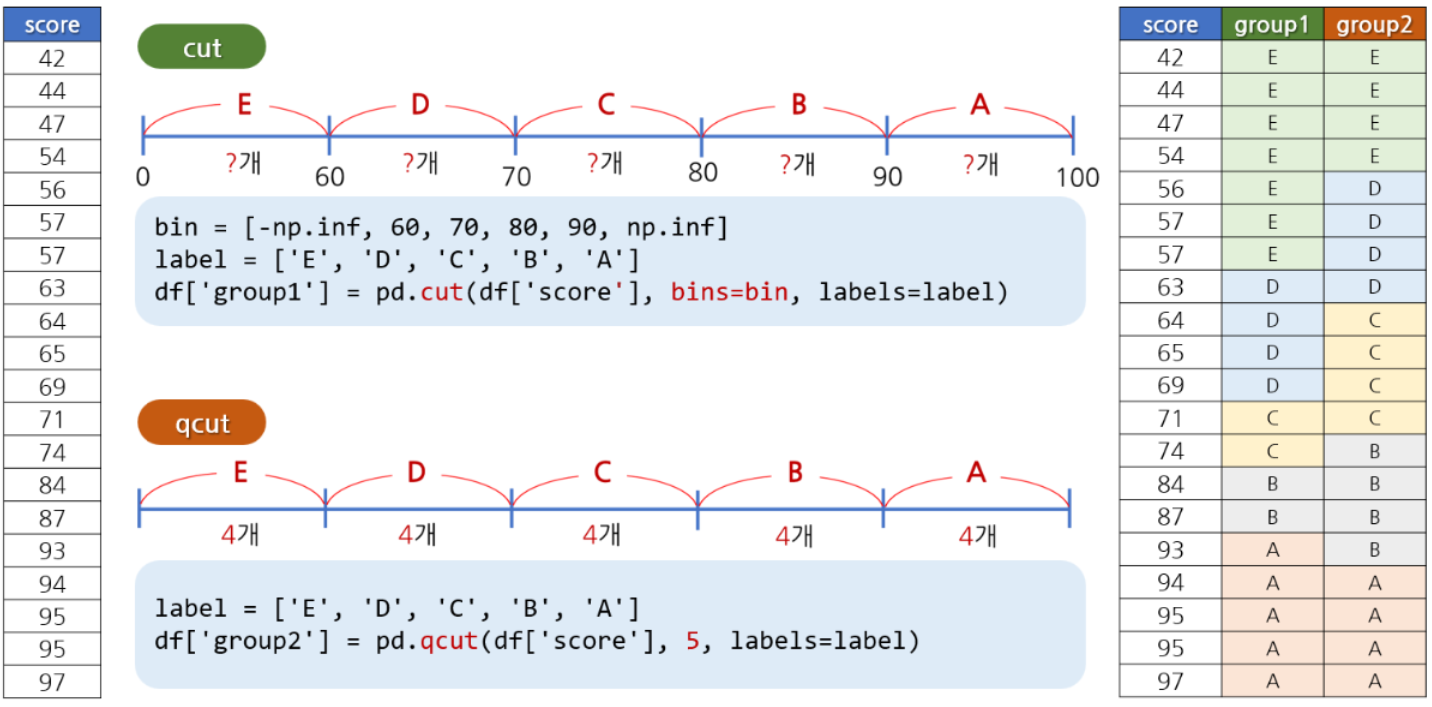
- 연속값을 구간을 나누어 범주값으로 표현하는 과정을 이산화(Discretization) 라고 한다.
- cut(), qcut() 함수를 사용하여 쉽게 이산화 과정을 수행할 수 있다.
- 연속값을 이산화 함으로써 더 심도있는 데이터 분석이 가능해진다.
- 예를 들어 점수를 일정 구간으로 구분하면 점수 구간별 분석이 가능해진다.
- 또한 데이터가 단순해져 머신러닝 학습 과정과, 모델 성능이 향상될 수 있다.
cut 함수
- 크기를 기준으로 구간을 나누고 싶을 때 cut() 함수를 사용한다.
- 범위 개수를 지정하면 자동으로 크기를 기준으로 나눈다.
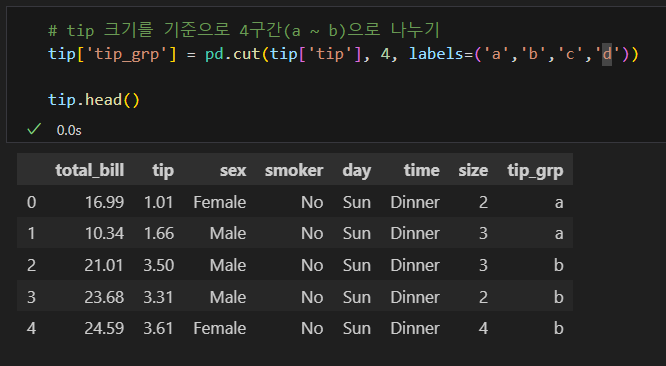
my_bin과 my_label의 범위 개수가 같아야한다.
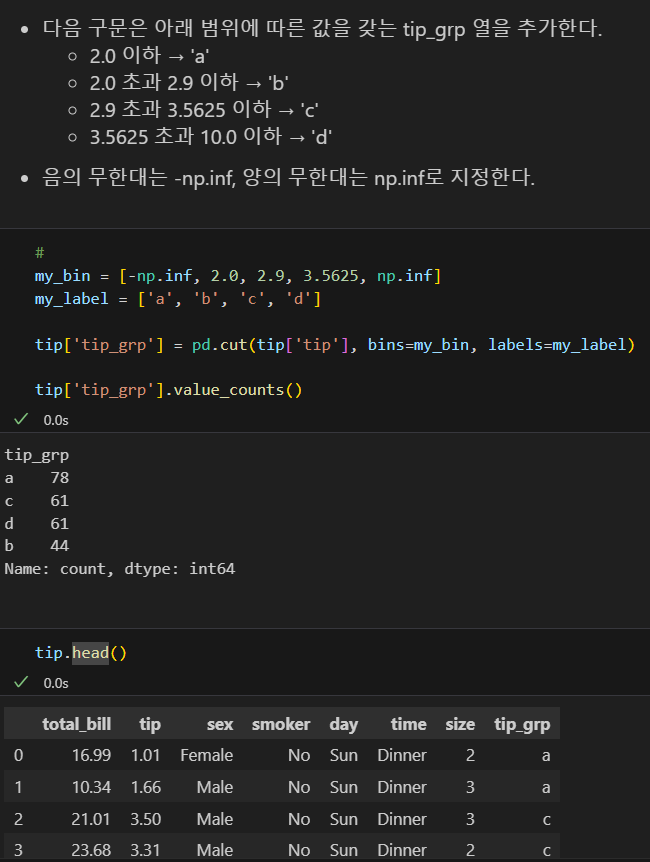
문제 1
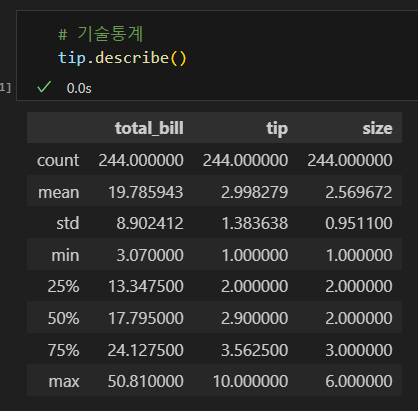
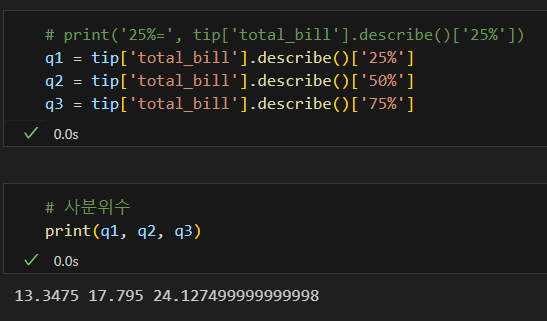
문제 2
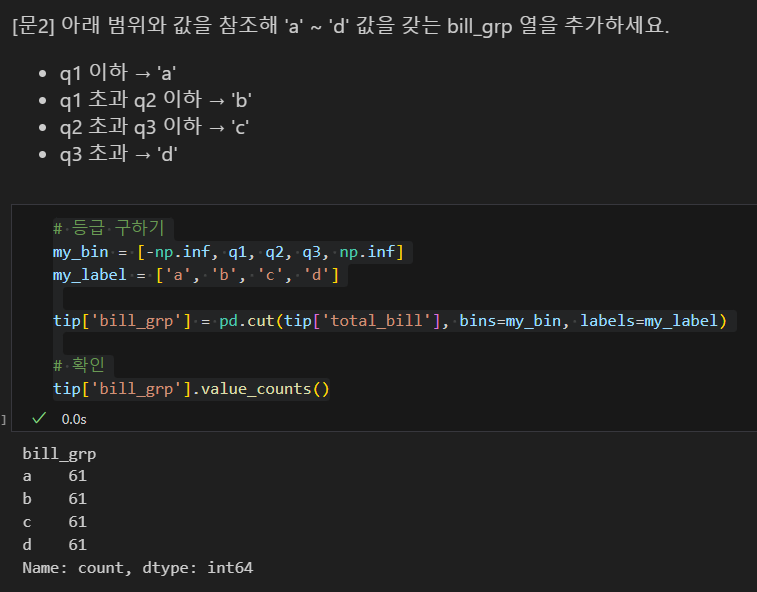
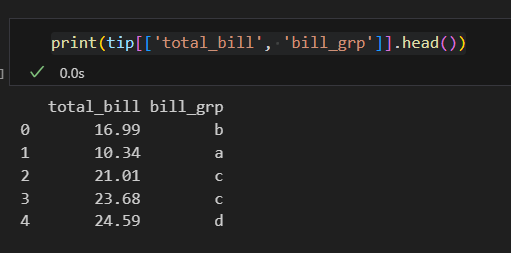
처음에 아래와 같이 코드를 짜서 틀렸다.
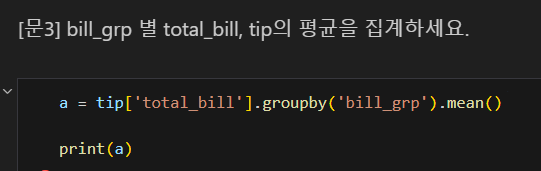
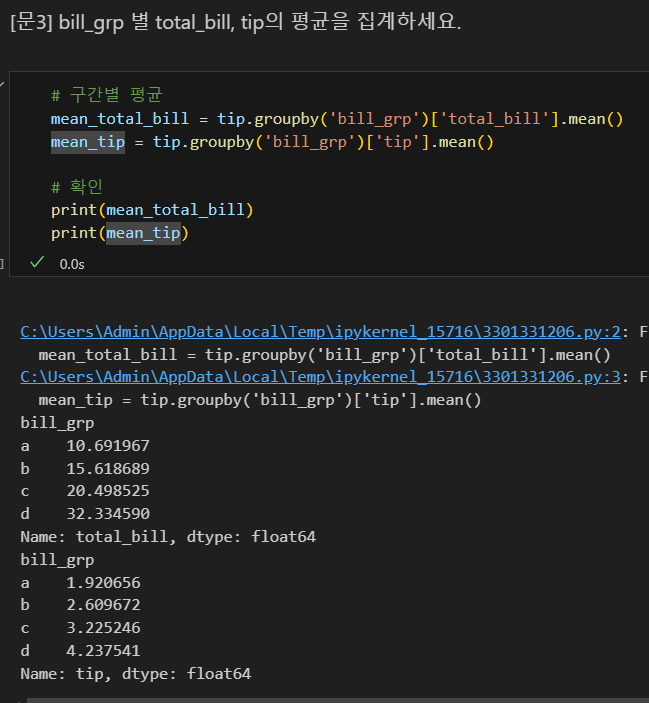
먼저 범위를 특정 열로 한정한 뒤에 groupby로 조건화를 했기 때문에 옳은 답을 얻을 수 없다.
나는 tip['total_bill'] 코드란: 불러올 값을 그 열로 한정한다는 의미가 아니라, 그 열이기도 하고, groupby의 조건과 겹치기도 하는 값을 구할 수 있을 줄 알고 그렇게 썼으나, 파이썬에게는 해당되지 않는다. 즉, 파이썬에서는 객체화하지 않고 동시에 명령할 수 없다.
이 부분이 나에게는 다소 stubborn하게 느껴진다. 데이터의 임의 범주를 굳이 객체화할 필요없이 가정하여 명령하는 것이 더 유연할 것이다.
객체 지향형 말고 절차적 또는 함수형 패러다임을 따르는 언어로는 C, C++, Go, JavaScript, Rust 등이 있다.
동시성 측면에서는 Go, Erlang, Rust, JavaScript(Node.js), C 등의 언어들이 효율적이며 객체 지향 개념을 사용하지 않고 동시 작업을 다룰 수 있다.
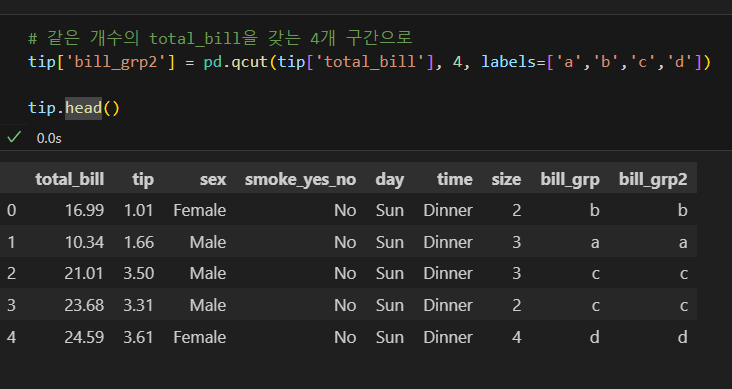
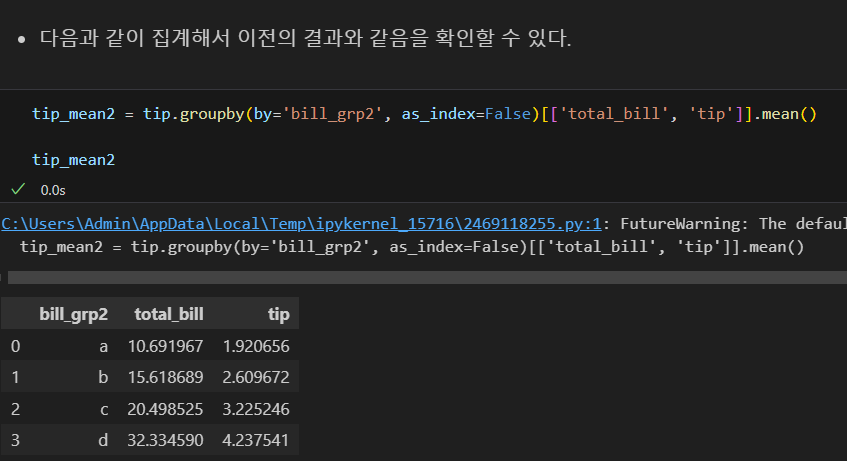
qcut 함수
- 개수를 기준으로 구간을 나누고 싶을 때 qcut() 함수를 사용한다.
- 구간 개수를 지정하면 자동으로 동일한 개수를 갖는 구간이 만들어진다.
- 위 연습문제는 total_bill 열의 사분위 값을 기준으로 cut() 함수를 사용해 범위를 나누었다.
- 사분위는 값 개수를 기준으로 4분의 1씩 데이터를 갖는 4개 구간을 만든 것이다.
- 그러므로 qcut() 함수를 사용해 4개 구간으로 나누면 같은 결과를 얻게 된다.
실습
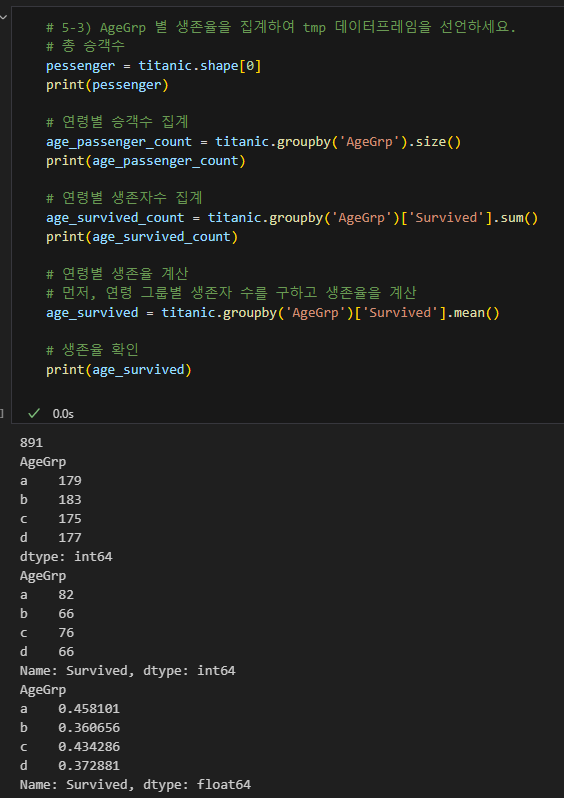
titanic 연령 그룹별 생존율 구하기
1.3. 데이터프레임 결측치 처리
-
결측치란?
- 데이터에 값이 없거나 부적절한 경우 결측치로 표시
- NA : Not Available(유효하지 않은)
- NaN : Not a Number(숫자가 아닌)
- Null : 아무것도 존재하지 않음
-
즉 결측치는 정확한 분석을 방해한다.
-
결측치를 만나면 오류가 발생하는 함수도 있다.
-
결측치 처리가 중요한 이유는?
- 분석 결과가 왜곡
- 데이터의 완전성 저하
- 결측치가 있는 데이터는 예측 모델의 성능을 저하
- 신뢰성 저하
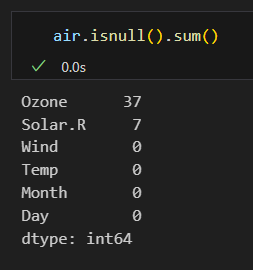
결측치 확인
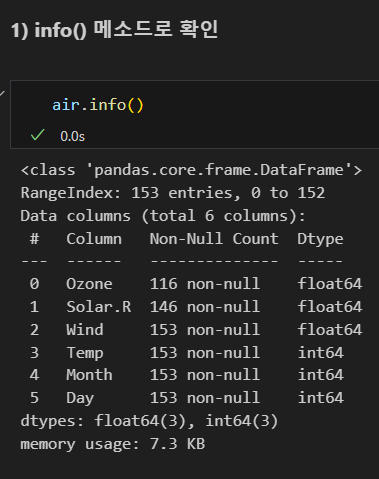
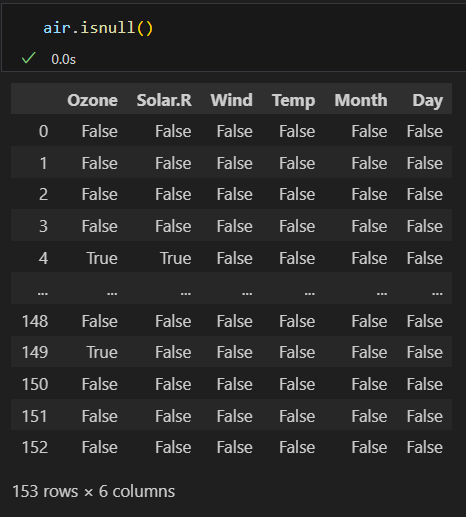
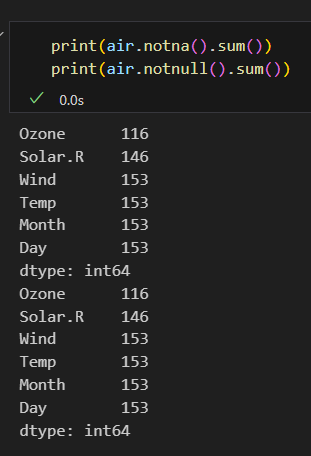
isnull(), notnull() 메소드 사용
- isnull() 메소드는 결측치면 True, 유효한 값이면 False를 반환한다.
- notnull() 메소드는 결측치면 False, 유효한 값이면 True를 반환한다.
- isnull() 대신 isna(), notnull() 대신 notna() 메소드를 사용해도 된다.
isnull()
notna(), notnull()
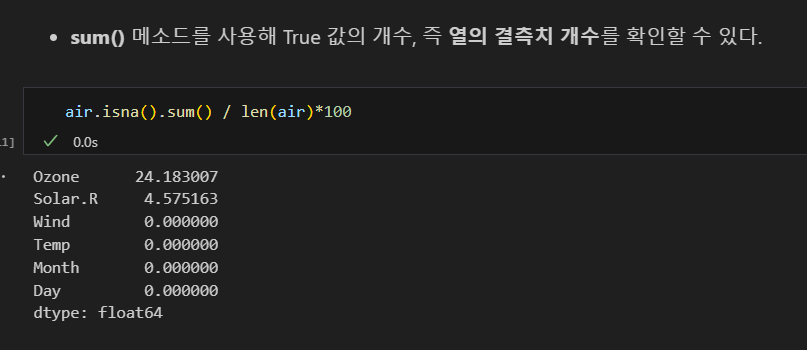
결측치 비율
결측치 제거
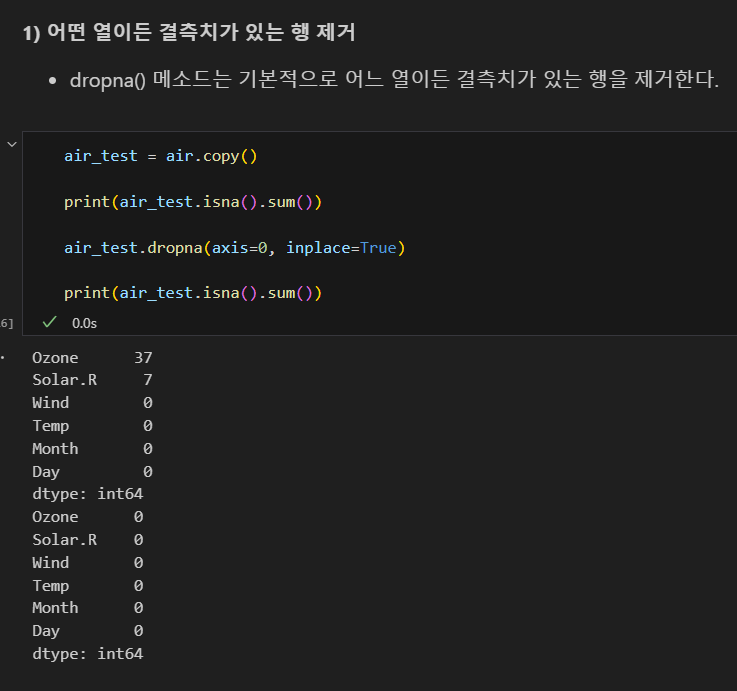
- dropna() 메소드로 결측치가 있는 열이나 행을 제거할 수 있다.
- inplace=True 옵션을 지정해야 해당 데이터프레임에 실제로 반영된다.
- axis 옵션으로 행을 제거할지 열을 제거할지 지정한다.
- axis=0: 행 제거(기본값)
- axis=1: 열 제거
결측치 있는 행 제거
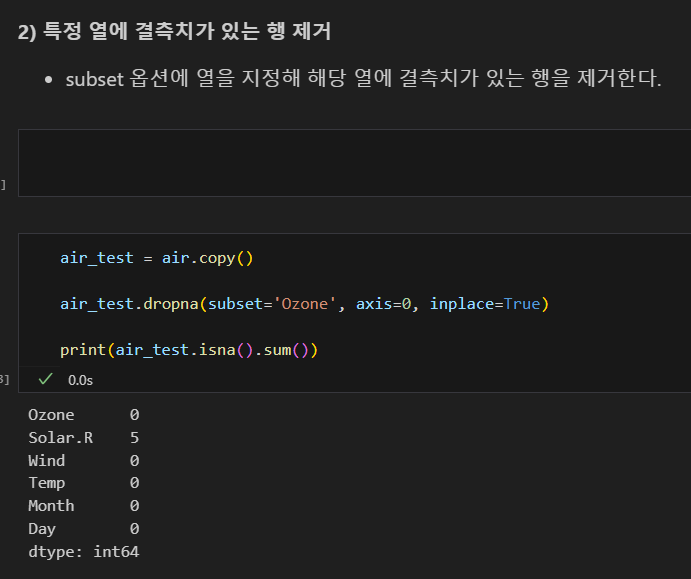
subset으로 특정 열에서 결측치 있는 행 제거
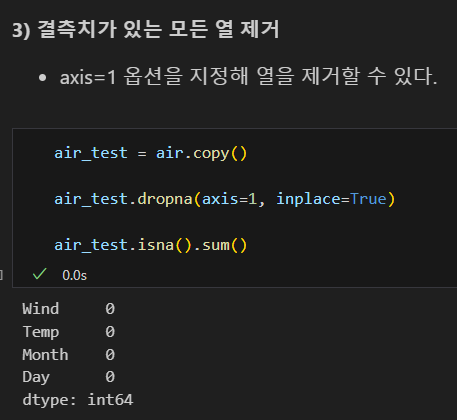
결측치 있는 열 제거
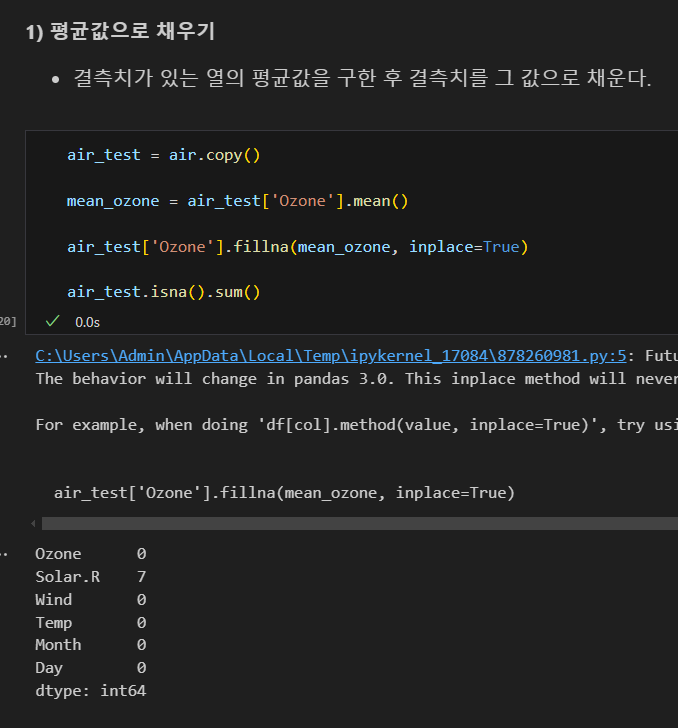
결측치 채우기
해당 열의 평균값으로 채우기
특정값으로 채우기
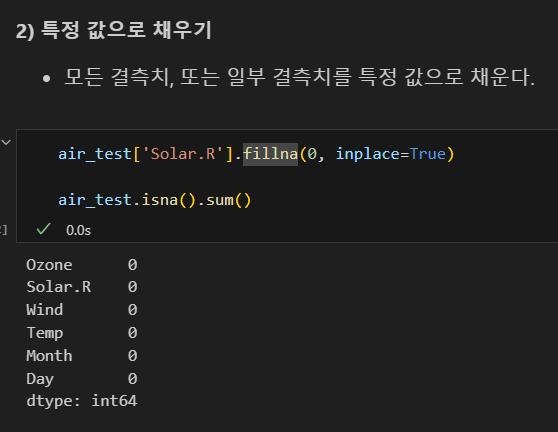
직전 행의 값 또는 바로 다음 행의 값으로 채우기
- 결측치를 바로 앞의 값이나 바로 다음에 나오는 값으로 채운다.
- 날짜 또는 시간의 흐름에 따른 값을 갖는 시계열 데이터 처리시 유용하다.
- method='ffill': 바로 앞의 값으로 변경(Fowared Fill)
- method='bfill': 바로 다음 값으로 변경(Backwared Fill)
바로 앞이나 바로 뒤의 값이 결측치면 결측치가 채워짐
값이 맨앞이거나 맨뒤인 경우 채워지지 않음
라이브러리 업데이트 경고 등 무시하기
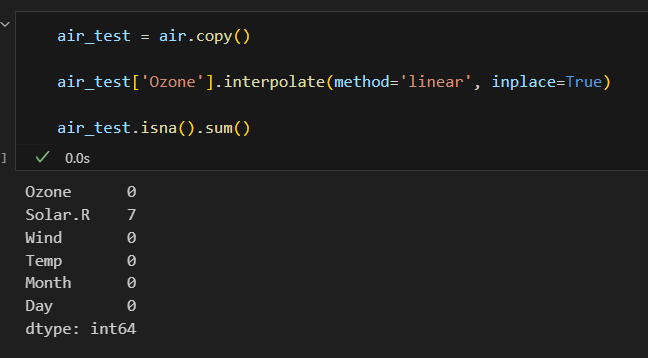
선형보간법으로 채우기
가변수(Dummy Variable) 만들기
- 가변수는 일정하게 정해진 범위의 값을 갖는 데이터(범주형 데이터)를 독립된 열로 변환한 것이다.
- 특히 범주형 문자열 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 한다.
- 가변수를 만드는 과정을 One-Hot-Encoding 이라고 부르기도 한다.
- get_dummies() 함수를 사용해서 가변수를 쉽게 만들 수 있다.
