앞서 설명한 질병 A.각막궤양을 ResNet 18-Layer를 통해 학습, 모델을 작성하고, 해당 정확도를 분석
ResNet -18Layer
ResNet -18Layer는 18개 층을 이루는 ResNet으로 기존의 VGGNet이 밝힌 Layer가 깊어질수록 성능이 좋아진다는 사실을 부정하고 심층적으로 연구한 결과 Layer의 깊이가 깊어질수록 미분이 늘어나 weight의 영향이 작아져 성능이 떨어지는 결과를 가져온다고 분석함.
Input image
- size: (224,224)
- 구조
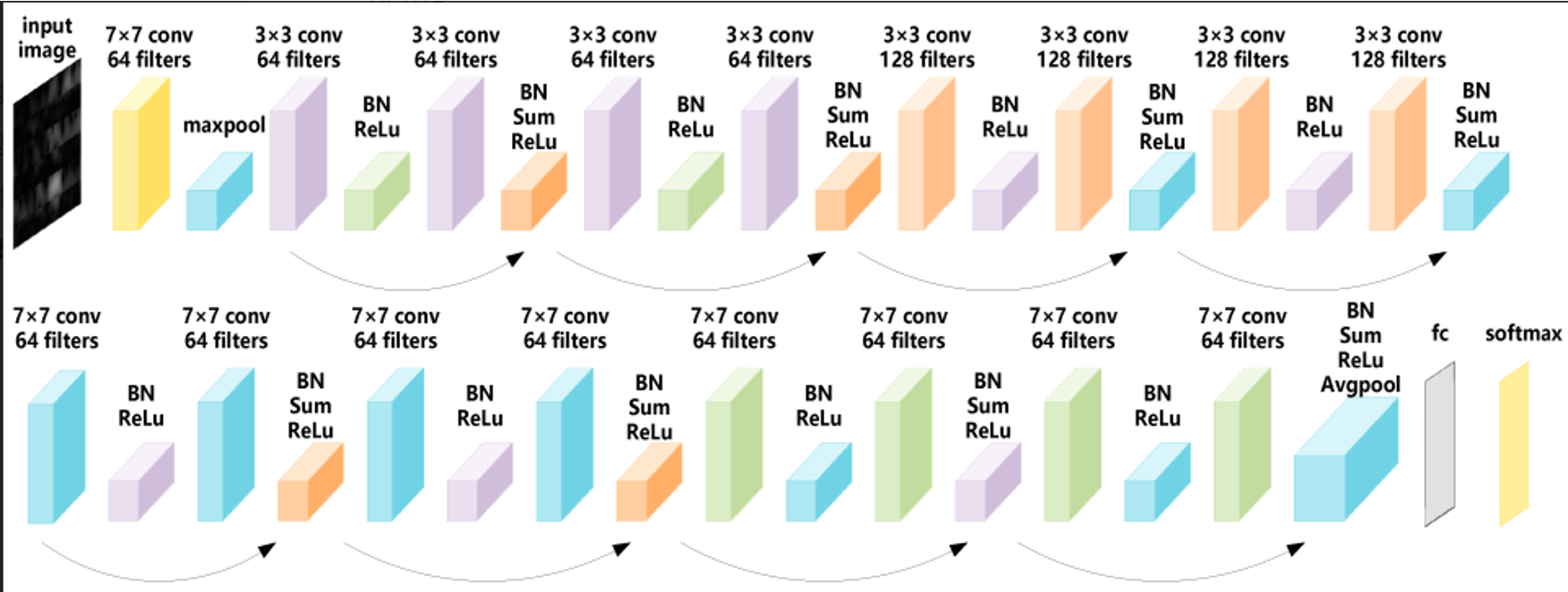
ResNet은 Identity Block과 Convolution Block을 적용한 네트워크의 Layer가 깊어질수록 성능이 좋아지는지 확인하기 위해 많은 Layer단계(18,34,50,101,152Layer)를 구분하여 적용 - 18Layer만 서술할 예정Identity Block
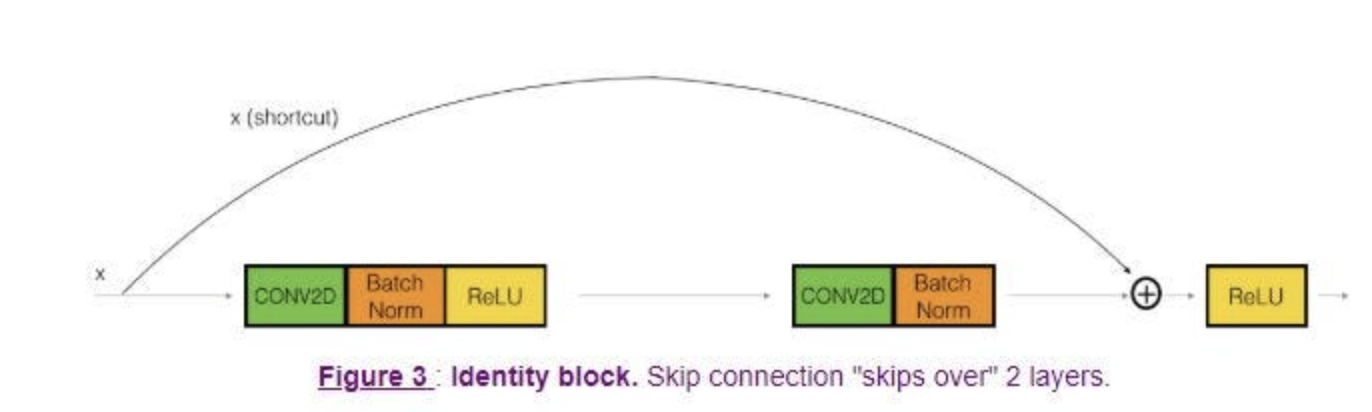
ResNet의 Identity Block으로 입력값 는 weight layer를 통과하여 나오는 와 해당 출력값과 최소 Gradient로 1은 갖도록 하기 위해 입력값 를 더하는 구조를 가지고 있다. 이 입력값에 를 더해주기 위해 생겨난 추가적인 길을 지름길(Shortcut)을 추가하고, 최종 Residual Block 결과값 형태로 Residual Block을 형성한다.
Convolution Block
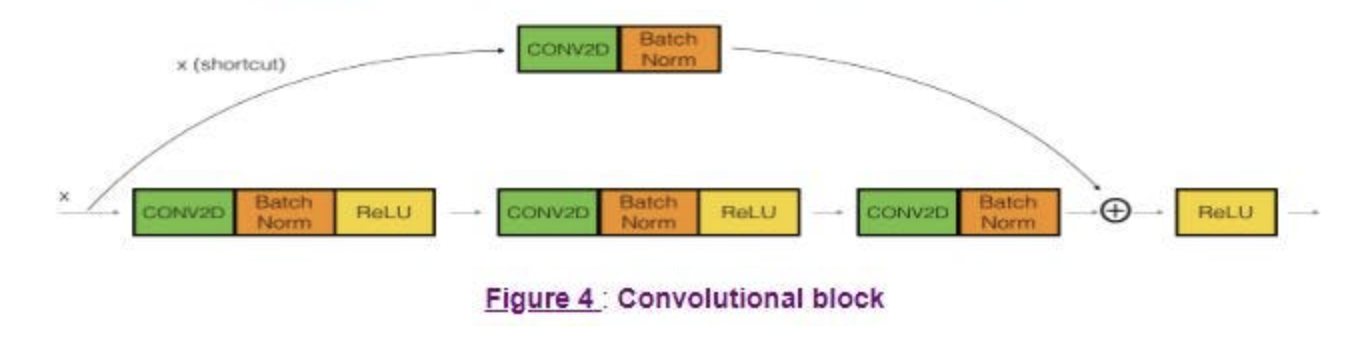
ResNet의 Convolution Block은 Input값이
Convolution -> BatchNomalization-> Activation -> Convolution -> BatchNormalization -> Add -> Activation 순으로 진행될 때 이미지의 크기나, 필터의 개수가 일치하지 않아 발생하는 문제를 해결하기 위해 등장한 블록으로, 현재의 shortcut을 하게 되면 필터를 통과하지 않은 input Feature map의 channel은 64이지만, 필터를 통과한 이후는 128의 channel을 가지는 경우가 있다.
즉, 입력값 는 필터를 통과한 와 차원 개수가 다르게되는데 이를 해결하기위해 두가지 방법이 있다.
1. 1x1크기의 필터를 두고, x를 Convolution Layer에 통과시킨다.
2. Padding을 수행한다.
여기서 1번방식에 초점을 두고 있는데,
해당 사진은 ResNet 50 Layer의 Convolution Layer를 가져온 사진으로, 18Layer모델과 달리 세 가지 필터를 통과하지만, 여기서 주목할 것은 shortcut 즉 다른 채널을 갖는 input값과 output값을 더하기 위해, Convolution을 진행하고, BatchNomalization을 시행하는 것까지 수행한 뒤에 합하는 형태를 가지고 있다.
구현
1. 라이브러리
from tensorflow.keras.models import Model from tensorflow.keras.layers import Input,GlobalAveragePooling2D, Conv2D, BatchNormalization, Activation, Add, MaxPooling2D, AveragePooling2D, Flatten, Dense, ZeroPadding2D import matplotlib.pyplot as plt import numpy as np import pandas as pd import os import cv2 import time import math from tensorflow.keras.optimizers import Adam,SGD from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from sklearn.model_selection import train_test_split import tensorflow as tf import tensorflow.keras.backend as K from tensorflow.keras import layers import random from keras.preprocessing.image import ImageDataGenerator사용 툴은 Tensorflow,Keras이다.
그 이외에, tensorflow는 numpy와 연계되는 점에서 라이브러리를 호출하고, 그래프를 그리기 위한 matplotlib, 이미지 연산을 위한 cv2 등을 호출한다.2. 시드 고정
os.environ['PYTHONHASHSEED']='1' os.environ['TF_DETERMINISTIC_OPS']='1' np.random.seed(5148) random.seed(5148) tf.random.set_seed(5148)환경은 Google Colab에서 시행하기 때문에, numpy나 random, tensorflow의 랜덤 변수 이외에도 environ환경에 변수를 지정해 줄 필요가 있다.
3. GPU사용
#%% GPU 할당 # GPU를 사용할 수 있는지 확인 gpus = tf.config.list_physical_devices('GPU') if gpus: try: tf.config.set_logical_device_configuration( gpus[0], [tf.config.LogicalDeviceConfiguration(memory_limit=8*1024)]) except RuntimeError as e: # 프로그램 시작시에 가상 장치가 설정되어야만 합니다 print(e)학습에 GPU를 사용하기 위해 장치의 메모리를 확인하고, 메모리의 한계를 지정하고 학습을 시작한다.
4. 구글 Colab환경 드라이브 Mount
# 구글 Colab에서 Drive 마운트 (파일을 가져오기 위함) from google.colab import drive # google drive mount drive.mount('/content/drive')드라이브를 마운트시켜 Notebook환경에서 Drive 파일에 접속할 수 있도록 함.
5. ResNet 구조 설계
해당 표를 참고하여 ResNet 18 Layer모델을 설계해 보자
def resnet_block(inputs,kernel,filters,strides=1,activation='relu'): x=Conv2D(filters,kernel_size=(kernel,kernel),strides=strides, padding='same')(inputs) x=BatchNormalization()(x) x=Activation(activation)(x) x=Conv2D(filters,kernel_size=(kernel,kernel),padding='same')(x) x=BatchNormalization()(x) if strides != 1 or inputs.shape[3] != filters: inputs = Conv2D(filters, kernel_size=(1, 1), strides=strides, padding='same')(inputs) inputs = BatchNormalization()(inputs) x=Add()([inputs,x]) x=Activation(activation)(x) return x해당 코드는 ResNet의 Identity Block과 Convolution Block을 설계한 것이다.
먼저 Convolution -> BatchNormalization-> Activation -> Convolution -> BatchNormalization -> Add -> Activation
순서로 적용되어있는 것을 확인해 볼 수 있으며,
앞서설명했듯이, input image와 output image의 크기가 다른 경우를 대비하여, Convolution을 통해 필터의 개수를 맞추어 통과시킨 모양이다.def resnet_18(input_shape,num_classes): inputs=Input(shape=input_shape) x=Conv2D(64,kernel_size=(7,7),strides=(2,2),padding='same')(inputs) x=BatchNormalization()(x) x = Activation('relu')(x) x=MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x) x=resnet_block(x,3,64) x=resnet_block(x,3,64) x=resnet_block(x,3,128,strides=2) x=resnet_block(x,3,128) x=resnet_block(x,3,256,strides=2) x=resnet_block(x,3,256) x=resnet_block(x,3,512,strides=2) x=resnet_block(x,3,512) x=AveragePooling2D(pool_size=(7, 7), strides=(1, 1))(x) x=Flatten()(x) x=Dense(num_classes,activation='softmax')(x) model=Model(inputs=inputs,outputs=x) return model이것은 ResNet의 전체 구조에서 표를 참고하여 제작한 형태이다.
먼저 7x7 크기의 Convolution을 진행한다. stride는 2형태로 주어 (224,224)크기의 입력 이미지를 (112,112)로 제작한다.
이후 MaxPooling, strides=2로 설정하여, (56,56)으로 이미지를 변화시킨다. 이후 conv2구간에서는 (56,56)이미지를 가지고 필터 64개 3x3크기의 커널에 2번 통과시키고, conv3구간에서는 (28,28)이미지를 만들기위해, stride를 2로 주어 크기를 반으로 줄이고, 필터개수 128개 3x3크기의 커널에 통과 시킨다.
conv4구간에서는 256, conv5구간에서는 512로, 각각 (14,14),(7,7)의 Feature map을 생성하고, 이를 AveragePooling, Fully Connected를 하면 모델의 설계가 끝이난다.#%% Parameter input_shape=(224,224,3) #이미지의 크기 num_classes=2 #클래스의 숫자 #disease=["a","b","c","d","e"] ## resnet50 모델 5개를 각각 5개의질병에 적용 (a,b,c,d,e) model_a=resnet_18(input_shape,num_classes) #%% 모델 요약 model_a.summary()
model.summary()확인까지 실행을 해보고, 넘어가도록 하자.
이때 질병의 "유"와 "무"만을 판단하기 때문에, num_classes=2로 설정해 두었다.# 이미지 경로 지정 image_path="/content/drive/MyDrive/L_TL2/cat/eye/normal" #categories 는 유/무 구별 categories=["Y","N"] #0이 Y 1이 N으로 0이 질병의 유, 1이 질병의 무 로 표현하도록 설계하고,
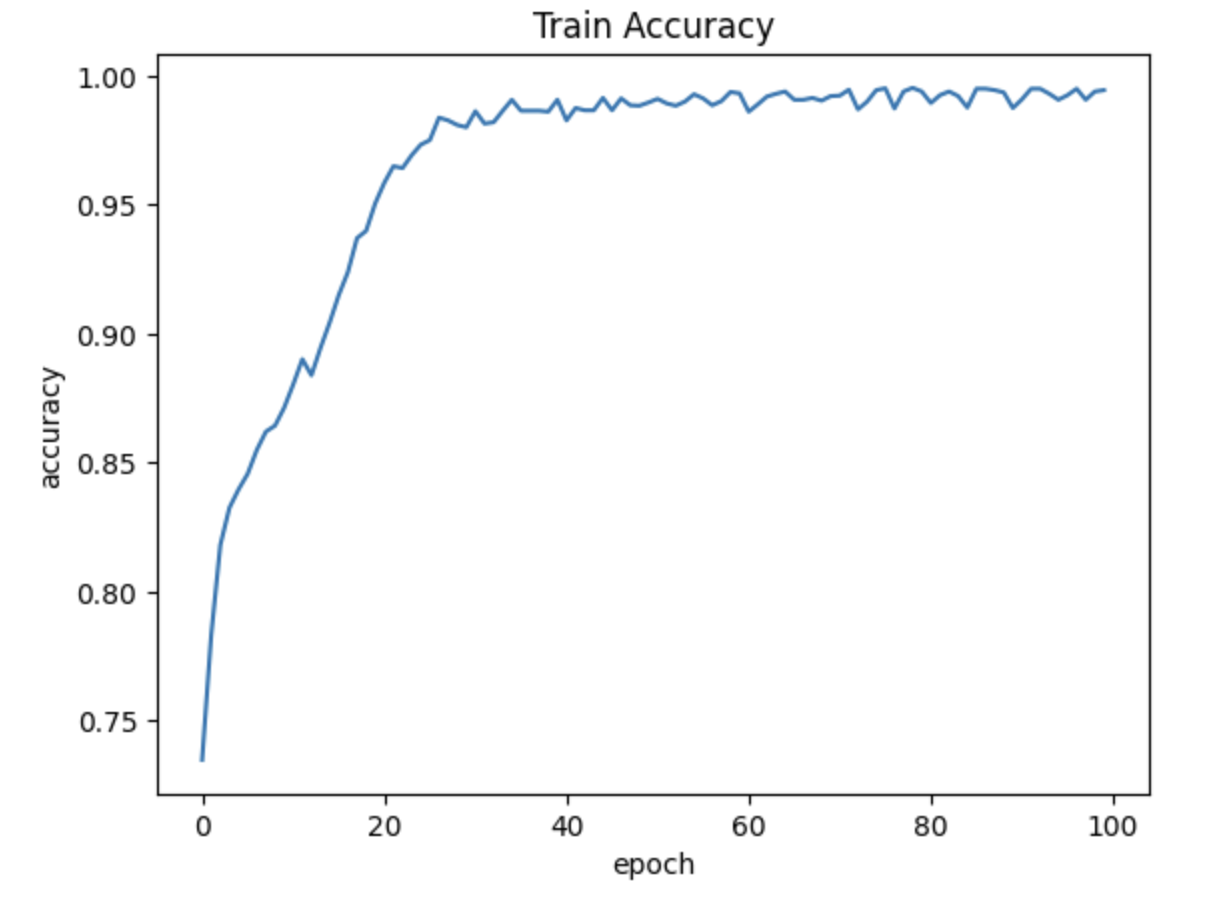
#%% A모델 학습 각막궤양 X=[] Y=[] for idx, cate in enumerate(categories): label = [0 for _ in range(num_classes)] label[idx] = 1 # Y는 정답라벨링, 0은 병이 있는 경우(유), 1은 병이 없는 경우(무) image_dir = image_path + '/a/'+cate+'/' for top, dir, files in os.walk(image_dir): i = 0 for filename in files: if filename[-4:] != 'json': i += 1 img = cv2.imread(image_dir + filename, 1) # 이미지를 BGR형식으로 호출 img = cv2.resize(img, (200, 200)) #(400,400)이미지를 (200,200)이미지로 resize -> 크기의 배수로만 resize하여 화질이 뭉개지는 현상 방지 # 이미지의 크기가 모델 ResNet 18 Layer모델에 입력 이미지 크기 (224,224)와 매치 되지 않아, zeropadding을 진행 # 화질의 해상도를 최대한 유지 시키면서, 이미지의 크기를 키움. img = cv2.copyMakeBorder(img, 12, 12, 12, 12, cv2.BORDER_CONSTANT, value=0) X.append(img) Y.append(label) # NUMPY형식으로 변환하고, X=np.array(X) X=X.astype(np.float32)/255.0 # 정규화 0~1의 값을 가질 수 있도록 만듦 Y=np.array(Y) # 각각 라벨링 된 데이터에서, 10%를 제외한 나머지 90%를 학습 데이터에 활용 (데이터의 개수가 많지 않은 관계로 최대한 많은 데이터를 학습에 확보하기 위함.) x_train, x_test, y_train, y_test = train_test_split(X, Y,test_size=0.1) # 학습 테이터, 테스트 데이터 개수 확인 print(x_train.shape) print(y_train.shape) print(x_test.shape) print(y_test.shape) # 모델의 Learning rate, optimizer와 loss계산 규정 model_a.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy']) # GPU를 통해 학습 진행 with tf.device('/GPU:0'): history=model_a.fit(x_train,y_train,epochs=100,batch_size=16) # 테스트 데이터를 모델에 넣고, 이를 통해서, test accuracy,loss 반환 test_loss,test_acc=model_a.evaluate(x_test,y_test) print("test accuracy:",test_acc) # 데이터의 정확도를 기준으로한 그래프 작성 plt.plot(history.history['accuracy']) plt.title('Train Accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.show() # 데이터의 loss를 기준으로 그래프 작성 plt.plot(history.history['loss']) plt.title('TrainLoss') plt.ylabel('loss') plt.xlabel('epoch') plt.show()이와 같은 형태로 모델을 설계하고 학습을 시작했다.
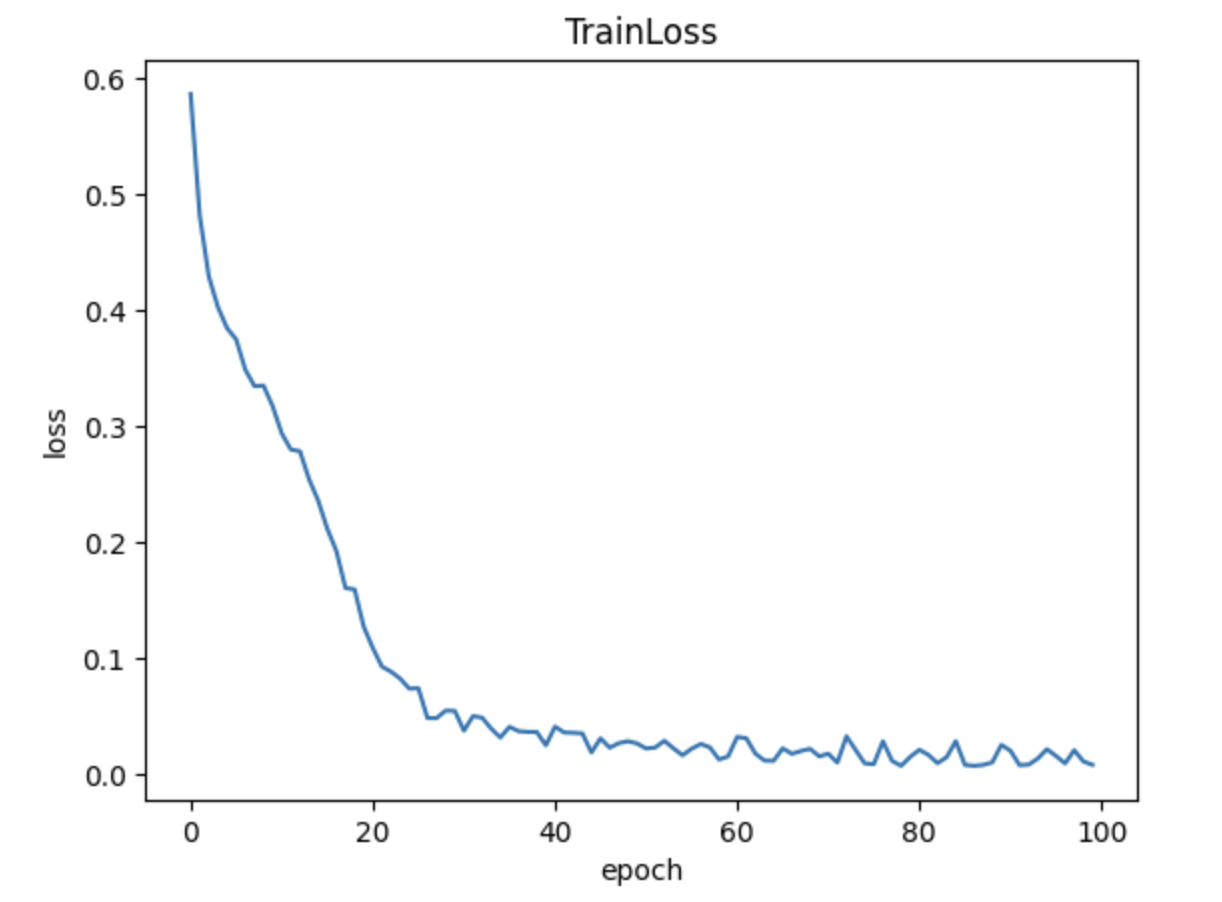
Loss, Accuracy 측면에서 증가하는 모습을 볼 수 있다.
또한 질병에 따라서 달라지지만
이 Test Data에 대해 Accuracy가 88.96%정도도 나오므로, 낮은 정확률으로 보기는 어렵지만 높은 정확률이라고 하기에는 한계가 있음을 겪고, 다른 네트워크도 사용해보기로 마음먹게되었다.

개선할 점
현재 학습은 Train Data와 Test Data로 나뉘어 학습이 진행이 되었습니다.
하지만 여기서 데이터 셋을 하나 더 나누어 교차검증 즉, Validation Set을 만들어 학습에 투자하였다면, 좀 더 좋은 결과를 내비칠 수 있을 것이라 예상합니다.x_train, x_test, y_train, y_test = train_test_split(X, Y,test_size=0.2) x_test, x_val, y_test, y_val = train_test_split(x_test, y_test,test_size=0.5)를 시행함으로 써 Train:(Test+Validation)=0.8:0.2로 나누고, 후자를 5:5로다시 나누어, 0.8:0.1:0.1로 분리하는 방법을 사용할 수 있고,
model.fit(x_train, y_train, epochs=100, batch_size=16, validation_data=(x_val, y_val))를 통해 Validation Set도 이용하여 검증하는 작업까지 진행할 수 있을 것으로 예상하지만.. 이후 여러 네트워크들도 제작 및 실행시켜보면서 환경에서의 컴퓨터 단위 부족, 시간부족 등의 조건으로 인해 제출할 당시의 코드는 적용을 시키지 못하였다.
GIT: https://github.com/Yeon1A/KWHackathon/blob/main/ResNet18_disease_a.ipynb
