Contents
- k-NN regression
1-1. Scatter plot
1-2. Train/Test split
1-3. Training KNeighborsRegressor
1. k-NN regression
While k-NN classification distinguishes various types of classes, for example, 0 (negative) and 1 (positive), regression model predicts a certain value of a feature.
지난 글에서 다룬 k-NN classification 은 다양한 종류의 classes 를 구분할 수 있었다. 예로 들어, 두 가지 classes 가 있다면 0 을 negative 로, 1 을 positive 로 두는 방식이다. 하지만 regression 에서는 그와 같은 class membership 이 아닌 "어떤 feature 의 값" 을 예측한다. 따라서, 모델을 학습시킬 때 우리는 target value 를 제공할 필요가 없다.
1-1. Scatter plot
이번 글에서는 Numpy array 로 변형한 브로콜리의 길이와 무게를 사용해 볼 것이다. 우선 scatter plot 을 이용해 샘플들의 분포를 보게되면, 우리는 브로콜리의 길이가 늘어남에 따라 무게도 증가하는 positive correlation 을 알 수 있다. 따라서 해당 상관관계를 브로콜리의 무게 예측에 이용할 수 있을 것이다.
본래 길이 외에도 더 많은 특성을 참고해 무게를 예측할 수 있지만 임의의 값을 3차원 이상의 공간에서 어떠한 "축" 위에 표현하려면 어려움이 있다. 따라서 그래프로 표현 및 설명하기 위하여 하나의 특성만을 이용해 2차원으로 나타내보자.
from matplotlib.pyplot as plt
plt.scatter(broccoli_length, broccoli_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()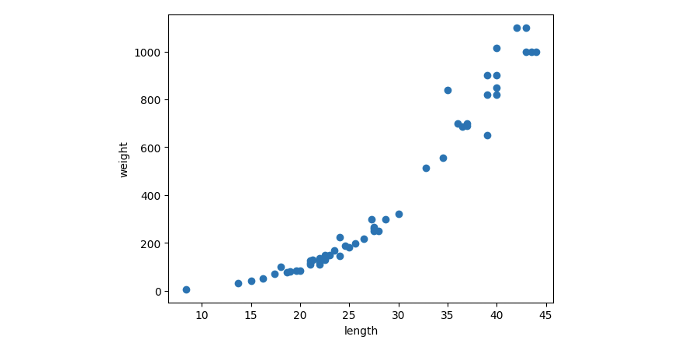
1-2. Train/Test split
sklearn 의 train_test_split 을 이용해 훈련세트와 테스트세트를 만들 때, 우리는 sklearn 이 2차원 배열을 요구한다는 것을 상기해야 한다. 따라서 우리는 1차원 배열로 구성된 train 과 test input 을 2차원으로 reshaping 해주어야 한다. 아래와 같이 적용 시 기존의 (42,) 와 (14,) 였던 train 과 test_input 이 (42,1) 과 (14,1) 이 되었음을 알 수 있다.

1-3. Training KNeighborsRegressor
마지막으로 우리의 KNeighborsRegressor 모델을 학습시킨 후 성능을 확인하기 위해 우리는 score 를 계산할 수 있다. 분류 시 score 는 "정확도" 를 나타내며, 회귀일 때에는 다양한 evaluation metrics 중 특히 score (결정계수) 를 출력한다. 이와 관련한 더 자세한 내용은 다음 글에서 다루도록 하자.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
print(knr.score(test_input, test_target)) # 0.9276430664575899