Contents
- Wine: Red or white
- Decision tree
2-1. Gini impurity - Pruning
- Unscaled features & feature importances
1. Wine: Red or white
이번 글에서는 alcohol, sugar, 그리고 pH 정도에 따라 레드인지 화이트 와인인지를 구분하는 연습을 해 볼 것이다. 이를 위해 pandas 에서 wine csv 파일을 읽어 온 후 info() 또는 describe() methods 를 이용하면 유용한 정보를 얻을 수 있다.
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.head()
wine.info()
wine.describe()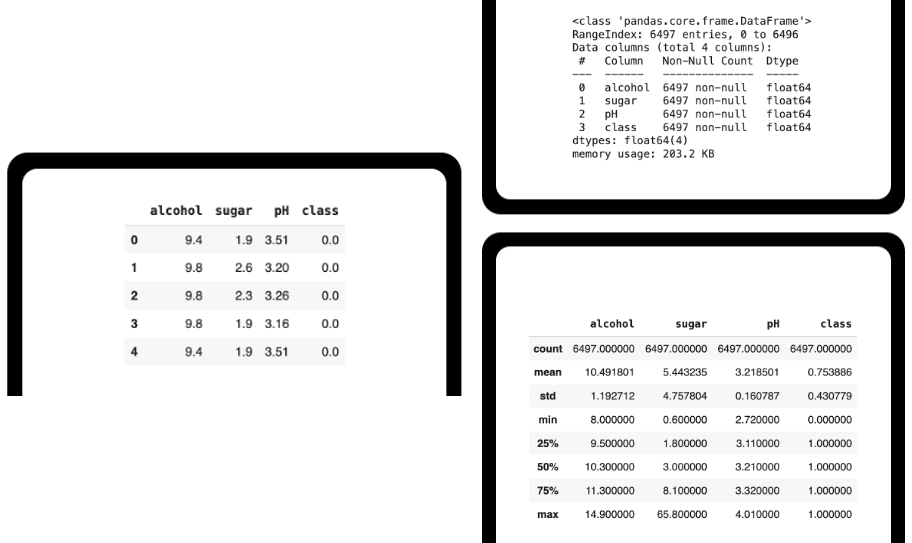
특히 info() 로 데이터의 종류나 누락된 (null) 정보의 유무를, describe() 로 간단한 통계 파악이 가능하다.
Model 1: Logistic regression
이전처럼 로지스틱 회귀를 이용해 와인의 종류를 예측해보자.
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target)) # 0.7766830870279147
print(lr.score(test_scaled, test_target)) # 0.7938461538461539
print(lr.coef_, lr.intercept_) # [[ 0.52895532 1.67830922 -0.68250775]] [1.76634167]결과적으로 train 과 test 의 점수도 낮을 뿐더러 다항 특성 생성 시 모델이 학습한 계수의 의미 또는 significance 를 설명하기에 어려움이 있다.
2. Decision tree
결정트리는 질문을 통해 데이터를 점점 분할하며 답을 찾는다. 분류와 회귀 모두에 적용할 수 있는데, root node 에서 시작해 branches 를 통해 internal nodes 로 쪼개어지고 결국 leaf nodes 에 도달하는 hierarchical 방식이다.
Model 2: Decision tree
이번에는 결정트리를 이용해 와인의 종류를 예측해보자.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 0.9971264367816092
print(dt.score(test_scaled, test_target)) # 0.8738461538461538Model 1 에 비하면 전체적인 score 는 증가했으나 둘의 차이가 크다. Overfitted 되었다고 볼 수 있다. 그렇다면 결정트리는 어떤 기준으로 노드를 나누는 것일까?
2-1. Gini impurity
우리가 사용한 DecisionTreeClassifier 의 매개변수 중에는 criterion 이 있다. 이는 결정트리가 노드를 어떻게 분할할지에 영향을 미치는데, 여러 기준들 간에 성능 차이가 크게 없으므로 default 인 'gini' 를 주로 이용한다.

Gini impurity 는 전체 비율 1 에서 음성클래스 비율의 제곱과 양성클래스 비율의 제곱을 뺀 값이고, 결정트리는 따라서 부모와 자식 노드의 gini impurity 의 차이가 가장 크게 나오는 방향으로 노드를 분할한다. 직접 결정트리를 figure 로 나타내어 보자.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()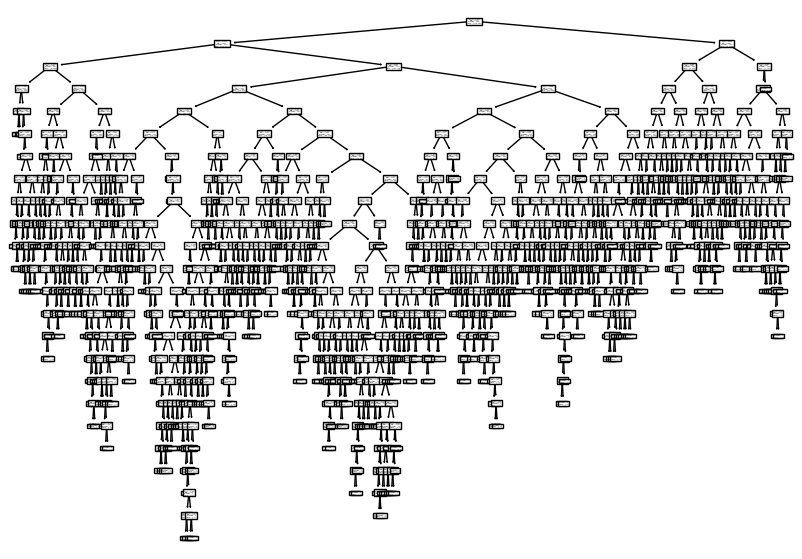
최종적으로 순수한 leaf nodes 까지 간다면 이렇게 복잡한 트리가 만들어진다. 하지만 정확도로 확인했듯이 훈련세트에만 너무 잘 맞는 과대적합이 발생하므로 우리는 이를 제한해 줄 필요가 있다.
3. Pruning
앞선 overfitting 문제를 해결하기 위해 decision tree 의 max_depth 를 직접 지정하는 '가지치기' (pruning) 를 해주도록 하자.
dt = DecisionTreeClassifier(max_depth=3)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 0.8450328407224958
print(dt.score(test_scaled, test_target)) # 0.8406153846153847덕분에 train score 가 상당히 떨어지긴 했지만 test score 와의 차이가 별로 나지 않게 되었다.

이를 시각화해보면 위와 같다. 파란색일수록 양성에 가까우므로 화이트 와인으로 분류된다. 처음과 두번째 depth 모두 'sugar' 라는 특성을 바탕으로 샘플들이 구분되었다. 하지만 당도가 음수보다 작거나 클 때가 기준이 되는 것이 직관적으로 맞지 않는 듯 하다. 따라서 스케일을 조정하지 않은 input data 를 그대로 학습한 후 점수를 확인해보자.
4. Unscaled features & feature importances
정확도를 비교해보면 train_scaled 를 이용했을 때와 정확히 일치한다. 이를 통해 우리는 사실 결정트리가 다른 모델들과 다르게 데이터 전처리를 필요로 하지 않음을 알 수 있다.
print(dt.score(train_input, train_target)) # 0.8450328407224958
print(dt.score(test_input, test_target)) # 0.8406153846153847그와 동시에 아래의 figure 에 제시된 당도의 기준이 조금 더 이치에 맞다.
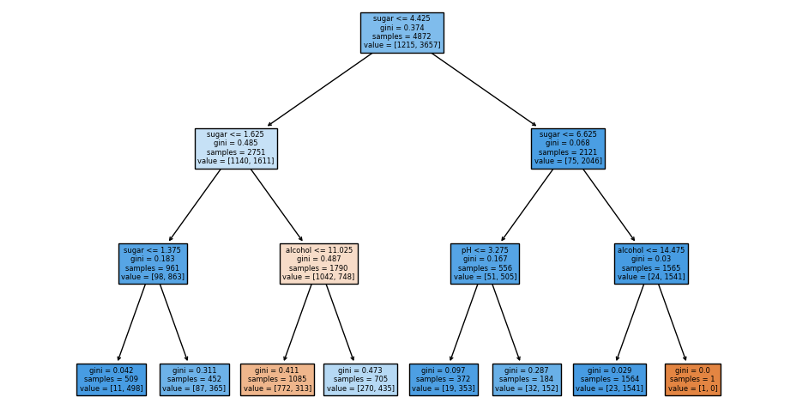
마지막으로 결정트리의 또 다른 특징으로는 특성 중요도가 있다. 이는 결정트리 모델이 학습한 값으로, 어떠한 특성들이 주요하게 사용되었는지를 반영한다.
print(dt.feature_importances_) # [0.12574003 0.86930049 0.00495948]따라서 sugar > alcohol > pH 의 중요도로 트리가 생성된 것은 우리가 확인한 바와 상응한다.
