시작하며
오늘은 MNIST 이미지 처리와 퍼셉트론에 대해 배웠다. 복잡한 코드를 많이 배우니 따라가기도 벅찬 하루였다. 그래도 이전에 한 번 배웠던 내용이라 괜찮을 줄 알았는데 이전에 맛보기로 배웠던 내용들을 본격적으로 배우려니 생각보다 어려웠던 것 같다.
흑백 이미지 전처리 : MNIST
이미지 데이터의 특징
- 이미지 분류 문제를 다루기 위해 수치 텐서로 변환 → 모델 구조에 따라 벡터 형태로 재구성하는 전처리 과정이 반드시 필요
- 흑백 이미지 : 채널 축을 포함하여 (1, H, W) 형태로 표현
- 컬러 이미지 : 채널 축을 포함하여 (3, H, W) 형태로 표현
- 다층 퍼셉트론은 입력값을 1차원 벡터로 받기 때문에 텐서를 적절히 변형하는 과정이 필수
MNIST 데이터 TensorFlow vs PyTorch
| 구분 | TensorFlow | PyTorch |
|---|---|---|
| 데이터 로드 API | tf.keras.datasets.mnist.load_data() | torchvision.datasets.MNIST |
| 데이터 로딩 방식 | NumPy 배열 기반 | Dataset + DataLoader |
| 반환 자료형 | numpy.ndarray | torch.Tensor |
| 이미지 형태 | (H, W) | (C, H, W) |
| 이미지 크기 | ||
| 색상 채널 차원 | 기본적으로 없음 | 기본적으로 포함 () |
| CNN 입력용 형태 | (28, 28, 1)로 직접 차원을 추가해야 함 | (1, 28, 28) |
| 픽셀 값 범위 | 0 ~ 255 (uint8) | 0 ~ 255 (uint8) |
| 정규화 | 사용자가 직접 255로 나눠서 정규화 | transforms.ToTensor()에서 자동 수행 |
모듈 임포트 및 디바이스 설정
import torch
from torchvision.datasets import MNIST
from torchvision import transforms- CPU, CUDA 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)MNIST 훈련셋 준비
- 다운로드 시 별도의 변환 객체를 지정하지 않으면 이미지 데이터를 PIL.Image 파일로 불러옴
train_mnist = MNIST(
root=DIR_PATH,
train=True,
transform=None,
download=True
)- 원본 데이터 확인
type(train_mnist)
# torchvision.datasets.mnist.MNIST
len(train_mnist)
# 60000
train_mnist[0]
# (<PIL.Image.Image image mode=L size=28x28>, 5)train_mnist.data
type(train_mnist)
# torchvision.datasets.mnist.MNIST
train_mnist.data.shape
# torch.Size([60000, 28, 28])
train_mnist.data.dtype
# torch.uint8img = train_mnist.data[0]
type(img)
# torch.Tensor
img.shape
# torch.Size([28, 28])MNIST 훈련셋 타겟 확인
train_mnist.targets
# tensor([5, 0, 4, ..., 5, 6, 8])
train_mnist.targets[0]
# tensor(5)
train_mnist.classes
# ['0 - zero',
# '1 - one',
# '2 - two',
# '3 - three',
# '4 - four',
# '5 - five',
# '6 - six',
# '7 - seven',
# '8 - eight',
# '9 - nine']
train_mnist.class_to_idx
# {'0 - zero': 0,
# '1 - one': 1,
# '2 - two': 2,
# '3 - three': 3,
# '4 - four': 4,
# '5 - five': 5,
# '6 - six': 6,
# '7 - seven': 7,
# '8 - eight': 8,
# '9 - nine': 9}MNIST 훈련셋 이미지 렌더링
import matplotlib.pyplot as plt
for i in range(9):
plt.subplot(3, 3, i + 1)
img = train_mnist.data[i]
plt.imshow(X=img, cmap='gray')
plt.title(label=f'label : {train_mnist.targets[i]}')
plt.axis('off')
MNIST 훈련셋 데이터의 전체 평균과 표준편차 계산
- 훈련셋 데이터를 실수형으로 변환하고 0~1 범위로 스케일링
pixels = train_mnist.data.float() / 255- 형태 확인
pixels.shape
# torch.Size([60000, 28, 28])- 평균 및 표준편차 확인
pixels.mean() # tensor(0.1307)
pixels.std() # tensor(0.3081)MNIST 이미지 변환 객체 생성
- 평균과 표준편차 생성
mnist_avg = round(pixels.mean().item(), 3)
mnist_std = round(pixels.std().item(), 3)- 정규화 포함한 이미지 변환 객체 생성
transform = transforms.Compose(
transforms=[
transforms.ToTensor(),
transforms.Normalize(mean=mnist_avg, std=mnist_std)
]
)MNIST 훈련셋 - 변환 객체 추가
- 다운로드 시 정규화 및 표준화 변환 객체를 추가하면 이미지 데이터를 실수형 텐서로 불러옴
train_mnist = MNIST(
root=DIR_PATH,
train=True,
transform=transform
)MNIST 훈련셋 첫 번째 이미지 확인
img, label = train_mnist[0]type(img)
# torch.Tensor
img.shape
# torch.Size([1, 28, 28])plt.imshow(X=img.squeeze(dim=0), cmap='gray')
plt.axis('off');
MNIST 시험셋 준비
- 훈련셋과 동일한 transform 적용
- 표준화 까지는 동일하게 적용
- 증강은 훈련셋에만 적용
test_mnist = MNIST(
root=DIR_PATH,
train=False,
transform=transform
)Perceptron
딥러닝의 출발점 : 퍼셉트론
- 퍼셉트론은 매우 단순한 모델
- 여러 개의 입력을 받아 하나의 출력을 만들어내는 계산 단위
- 신경망 모델의 가장 기본적인 형태
- 하나의 층으로 구성되어 있어 단층 퍼셉트론이라고도 함
- 퍼셉트론의 동작
- 입력값을 가중치와 곱함
- 그 결과를 모두 더하고 편향을 더함
- 활성화 함수를 적용하여 출력 계산
활성화 함수의 필요성
- 퍼셉트론이 단순 선형 결합만 수행한다면 여러 층을 쌓아도 여전히 하나의 선형 모델에 불과
- 활성화 함수는 이 구조에 비선형성을 추가해 주는 역할
- 비 선형성 덕분에 신경망은 복잡한 패턴 표현 가능
- 대표적인 활성화 함수는 Sigmoid, Hanh, ReLU 등이 있음
소프트맥스 함수의 역할과 의미
- 출력층에서 계산된 출력값을 확률로 변환하는 함수
- 출력층에서 계산된 각 클래스의 선형 결합값에 지수 함수를 적용
- 전체 클래스의 지수 함수값 합계로 나누어 모든 출력값의 합이 1이 되도록 정규화
- 소프트맥스 함수를 통한 출력은 각 클래스에 속할 확률로 해석 가능
- 출력 결과를 확률 분포로 해석하고 의사 결정 및 평가 지표에 활용 가능
소프트맥스와 손실 함수의 연결
- 소프트맥스 함수는 일반적으로 크로스 엔트로피 손실 함수와 함께 사용
- 이 조합은 확률 분포 간 차이를 측정하는 데 매우 적합
- 정답 클래스의 확률을 최대화하는 방향으로 모델 학습
- 기울기 계산이 단순해지는 장점 → 기울기 기반 학습 효율적으로 수행
- 사실상 하나의 세트처럼 사용
소프트맥스와 크로스 엔트로피 결합
- 소프트맥스 함수는 출력층의 로짓을 확률 분포로 변환
- 크로스 엔트로피 손실 함수는 확률 분포와 실제 정답 분포 간의 차이를 측정
- 소프트맥스와 크로스 엔트로피를 결합한 손실을 출력층 로짓 에 대해 미분
- 가 1(정답)이면 예측 확률 가 1에 가까울수록 기울기는 0에 가까워짐
- 가 0(오답)이면 예측 확률 가 클수록 더 큰 기울기를 갖게 됨
출력층 활성화 함수 선택 기준
| 구분 | 활성화 함수 | 이진 분류 문제 | 다중 분류 문제 |
|---|---|---|---|
| 활성화 함수 | 항등 함수 | 시그모이드 함수 | 소프트맥스 함수 |
순전파와 역전파 : 단층 퍼셉트론
- 단층 퍼셉트론의 학습 과정은 순전파와 역전파로 구성
- 순전파는 입력값에 가중치를 적용하여 출력값을 계산 → 실제값과 비교하여 손실값을 계산
- 역전파는 손실값을 기준으로 가중치에 대한 기울기를 계산하고 이 기울기를 이용해 가중치를 업데이트
경사하강법과 최적화 알고리즘
- 경사하강법은 손실 함수가 감소하는 방향으로 가중치를 조금씩 이동시키는 방법
- 손실이 증가하는 방향의 반대 방향으로 학습률만큼 이동
- 최적화 알고리즘은 기울기를 이용해 가중치를 어떻게 업데이트할지 결정하는 규칙
경사하강법 기반 최적화 알고리즘 비교
| 구분 | 상세 내용 |
|---|---|
| SGD | • Stochastic Gradient Descent의 줄임말 • 가장 기본적인 최적화 알고리즘으로, 현재 기울기만을 사용하여 가중치를 갱신 • 구조가 단순하여 이해하기 쉽지만, 수렴 속도가 느리고 학습이 불안정할 수 있음 |
| SGD with Momentum | • 이전 기울기의 방향성을 함께 고려하여 가중치를 갱신하는 방식 • 진동을 줄이고 수렴 속도를 개선할 수 있어, 기본 SGD보다 안정적인 학습이 가능 |
| Adam | • Adaptive Moment Estimation의 줄임말 • Momentum과 적응성 학습률 조정을 결합한 최적화 알고리즘 • 학습률 튜닝이 비교적 쉽고 빠르게 수렴하는 특징이 있어, 전이학습에서 널리 사용 |
| AdamW | • Adam에서 가중치 감소(Weight Decay)를 분리하여 적용한 방식 • 일반화 성능이 개선되는 경우가 많아, 최근 실무에서 자주 사용 |
Adam 최적화 기법의 직관적 이해
- 확률적 경사하강법은 모든 파라미터에 동일한 학습률을 적용하여 갱신
- Adam 최적화 알고리즘
- 이전 기울기의 방향을 기억하는 모멘텀 개념을 사용
- 파라미터마다 서로 다른 학습률을 자동으로 조정
- Adam은 복잡한 신경망에서도 비교적 안정적이고 빠르게 수렴
이미지 텐서 결합
- 처음 두 개의 이미지 텐서를 각각 생성
img1 = train_mnist[0][0]
img2 = train_mnist[1][0]
print(img1.shape)
print(img2.shape)
# torch.Size([1, 28, 28])
# torch.Size([1, 28, 28])- 두 개의 이미지를 첫 번째 축 방향으로 결합
stacked_images = torch.stack(tensors=[img1, img2], dim=0)- 결합 후 형태 확인
stacked_images.shape
# torch.Size([2, 1, 28, 28])이미지 평탄화
- 다층 퍼셉트론은 입력값으로 1차원 벡터를 사용
flattened_image = img1.flatten()
flattened_image.shape
# torch.Size([784])MNIST 훈련셋을 이미지와 라벨로 분리
train_images = torch.stack(tensors=[img for img, _ in train_mnist], dim=0)
train_labels = torch.tensor(data=[label for _, label in train_mnist])- 형태 확인
train_images.shape
# torch.Size([60000, 1, 28, 28])
train_labels.shape
# torch.Size([60000])- 평탄화 후 재할당
train_images = train_images.reshape(train_images.shape[0], -1)
train_images.shape
# torch.Size([60000, 784])MNIST 시험셋을 이미지와 라벨로 분리
test_images = torch.stack(tensors=[img for img, _ in test_mnist])
test_labels = torch.tensor(data=[label for _, label in test_mnist])- 평탄화 후 재할당
test_images = test_images.reshape(test_images.shape[0], -1)
test_images.shape
# torch.Size([10000, 784])시드 고정의 필요성
- 실험 환경 차이 최소화(원인 분석)
- 모델 간 차이, 학습률 차이, 드롭아웃 유무, 배치 크기 변화 등을 확인하기 좋음
- 학습 초기의 가중치 차이로 인한 편차를 줄임
시드 고정
- CPU 연산
import random
def set_seed(seed=0):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)- GPU 연산
deterministicTrue 지정 시 일부 연산이 느려질 수 있고, 에러 발생 가능- 재현성 100% 보장 불가능
import random
def set_seed_gpu(seed=0, deterministic=False):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
if deterministic:
torch.backends.cudnn.deterministic=True
torch.backends.cudnn.benchmark=False
torch.use_deterministic_algorithms(True)단층 퍼셉트론 모델 생성
import torch.nn as nn- 모델 생성
model = nn.Linear(in_features=784, out_features=10).to(device)- 가중치 형태 확인
model.weight.shape
# torch.Size([10, 784])손실 함수와 최적화 알고리즘 생성
- 크로스 엔트로피 손실 함수 생성
- 크로스 엔트로피는 내부적으로 소프트맥스 연산을 포함
criterion = nn.CrossEntropyLoss()- 최적화 알고리즘 생성
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)단층 퍼셉트론 모델 1회 학습
- 모델을 학습 모드로 전환
model.train()- 각 클래스에 대한 예측 점수(로짓) 계산(순전파)
- 신경망 모델과 최적화 객체는 새로운 모델을 학습할 때마다 새로 생성해야됨
logits = model(train_images)- 크로스 엔트로피 손실값 계산
loss = criterion(logits, train_labels)- 이전 계산된 기울기를 0으로 초기화
optimizer.zero_grad()- 손실 함수를 가중치로 미분하여 기울기 계산(역전파)
loss.backward()- 기울기를 이용하여 가중치 업데이트(경사하강법)
optimizer.step()모델 정확도 확인
- 모델을 평가 모드로 전환
model.eval()- 평가 단계에서는 가중치를 업데이트 하지 않기 때문에
with torch.no_grad()설정
with torch.no_grad():
logits = model(test_images) # 클래스별 예측 점수 계산
y_prob = torch.softmax(input=logits, dim=1) # 클래스별 예측 확률 계산
y_pred = y_prob.argmax(dim=1) # 가장 큰 예측 확률을 갖는 클래스를 예측값으로 선택
acc = (test_labels == y_pred).float().mean().item() # 실제값과 예측값의 일치 정도 계산
print(acc)모델 정확도 평가 함수 생성
@torch.no_grad()- 데코레이터 사용으로 함수 사용 시 자동으로 기울기 계산 X
- 로짓을 예측 확률로 변환하지 않아도 예측값 계산 가능
- 지수함수는 단조증가
@torch.no_grad()
def accuracy(model, x, y):
model.eval()
logits = model(x)
y_prob = torch.softmax(input=logits, dim=1) # 생략 가능
y_pred = y_prob.argmax(dim=1)
acc = (y == y_pred).float().mean().item()
return acc모델 학습 함수 생성
def train(model, x, y):
logits = model(x)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backwar()
optimizer.step()
return loss.item()단층 퍼셉트론 모델 반복 학습
train_losses = []
train_accs = []
test_accs = []
for epoch in range(20):
model.train()
loss = train(model, train_images, train_labels)
train_losses.append(loss)
train_acc = accuracy(model, train_images, train_labels)
test_acc = accuracy(model, test_images, test_labels)
train_accs.append(train_acc)
test_accs.append(test_acc)
print(f'[Epoch : {epoch + 1:02d}] Loss : {loss:.4f} ',
f'Train_Acc = {train_acc:.4f}, Test_ACC = {test_acc:.4f}')학습 곡선 시각화
- 손실 함수 학습 곡선 시각화
plt.plot(train_losses, label='훈련셋 손실값')
plt.title('훈련셋 손실값 변화')
plt.xlabel('에포크')
plt.ylabel('손실값')
plt.legend()
plt.show()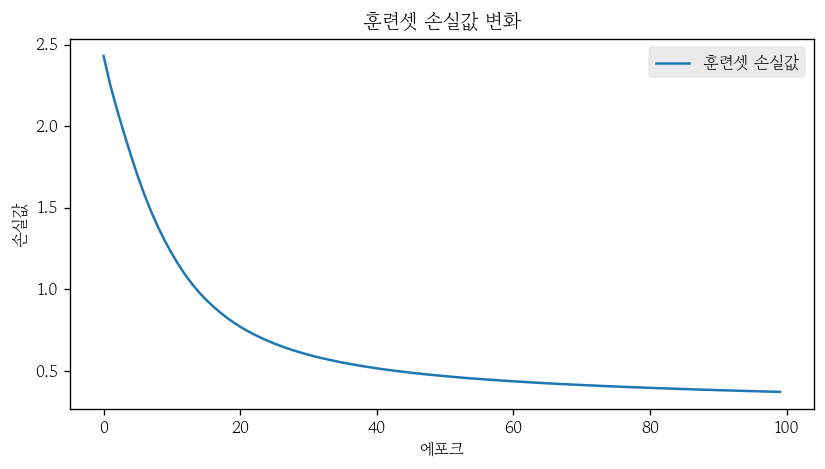
- 정확도 학습 곡선 시각화
plt.plot(train_accs, label='훈련셋 정확도')
plt.plot(test_accs, label='시험셋 정확도')
plt.title('정확도 변화')
plt.xlabel('에포크')
plt.ylabel('정확도')
plt.legend()
plt.show()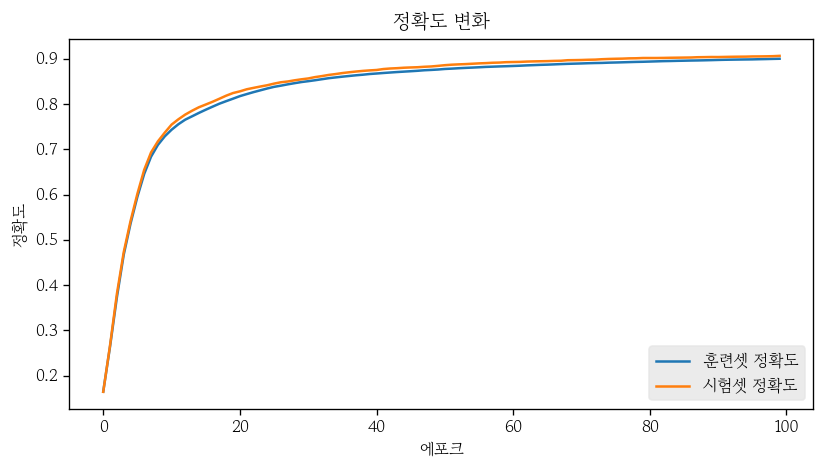
optimizer.zero_grad()가 필요한 이유
- PyTorch에서
loss.backward()를 호출할 때 기울기를 자동으로 누적하는 방식으로 동작- 이전 배치에서 계산된 기울기가 다음 배치의 기울기에 더해지는 구조
- 배치마다
optimizer.zero_grad()를 호출하지 않으면 의도하지 않은 파라미터 업데이트가 발생 optimizer.zero_grad()는 이전에 계산된 기울기를 모두 초기화- 현재 배치의 손실값만을 기준으로 파라미터를 갱신
- 에포크 단위가 아니라 배치 단위로 반복 수행
모델 파라미터 저장 및 불러오기
- 모델 파라미터 저장
torch.save(obj=model.state_dict(), f=SAVE_PATH)- 새로운 모델 생성
model_loaded = nn.Linear(in_features=784, out_features=10)- 기존 저장해둔 모델 파라미터를 불러옴
model_params = torch.load(f=SAVE_PATH, map_location=device)- 기존 파라미터 적용
model_loaded.load_state_dict(model_params)모델 예측 확률 및 예측값 생성
- 모델을 평가 모드로 전환
model.eval()- 시험셋 이미지에 대한 로짓, 예측 확률 및 예측값 계산
with torch.no_grad():
test_logits = model(test_images)
test_probs = torch.softmax(input=test_logits, dim=1)
test_preds = test_probs.argmax(dim=1)혼동 행렬 생성
- 시험셋 예측값 및 라벨 시리즈로 변환
y_pred = pd.Series(data=test_preds, name='y_pred')
y_true = pd.Series(data=test_labels, name='y_true')- 실제값과 예측값으로 혼동 행렬 생성 후 행 열이름 타겟 범주로 변경
cfmx = pd.crosstab(index=y_true, columns=y_pred)
cfmx.index = train_mnist.classes
cfmx.columns = train_mnist.classes혼동 행렬 시각화
plt.figure(figsize=(8, 6), dpi=120)
sns.heatmap(data=cfmx, cmap='viridis_r', annot=True, annot_kws={'size': 8})
plt.show()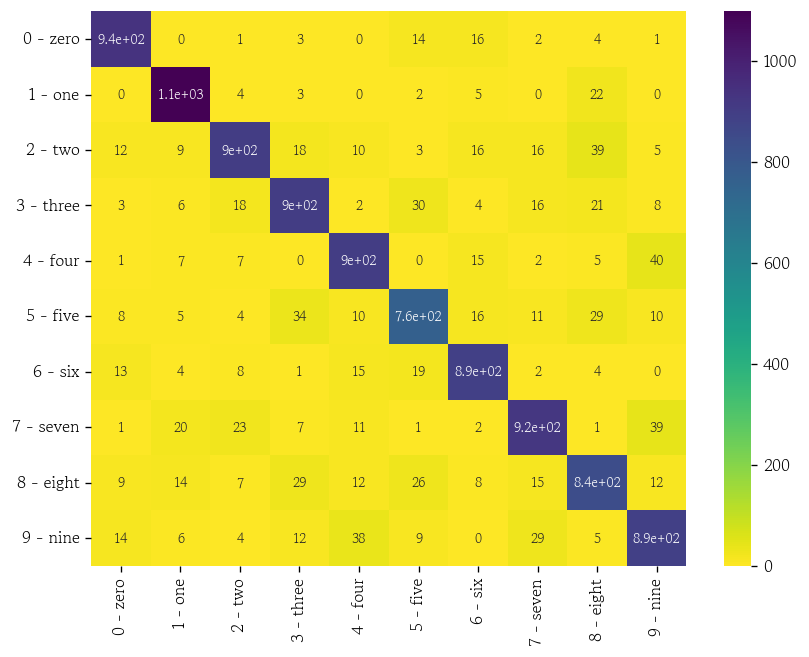
오분류 이미지 시각화
n = 10- 오분류 케이스 n개 인덱스 할당
mis_index = np.where(y_true.ne(y_pred))[0][:n]fig, axes = plt.subplots(2, 5, figsize=(8, 4), dpi=120)
for ax, i in zip(axes.flatten(), mis_index):
ax.imshow(X=test_images[i].reshape(28, 28), cmap='gray')
ax.set_title(label=f'[{i.item()}] True : {y_true[i]} Pred : {y_pred[i]}', size=8)
ax.axis('off')- 2를 8로 착각한 경우의 이미지 확인
cond = y_true.eq(2) & y_pred.eq(8)
mis_index = np.where(cond)[0]
fig, axes = plt.subplots(2, 5, figsize=(8, 4), dpi=120)
for ax, i in zip(axes.flatten(), mis_index):
ax.imshow(X=test_images[i].reshape(28, 28), cmap='gray')
ax.set_title(label=f'[{i.item()}] True : {y_true[i]} Pred : {y_pred[i]}', size=8)
ax.axis('off')손글씨 이미지 생성
from PIL import Image- 읽기 모드로 파일열고 할당
test_img = Image.open(fp='mnist_test.png', mode='r')MNIST 크기로 변경
- 크기 확인
test_img.size- MNIST와 동일한 크기로 변경
test_img = test_img.resize((28, 28))
test_img.size
# (28, 28)흑백 이미지로 변환
- 색상 모드 확인
test_img.mode
# 'RGBA'- 흑백 이미지로 변환
test_img = test_img.convert(mode='L')이미지 색상 반전
- NumPy 배열로 변환
test_img = np.array(test_img)- 픽셀 값 반전하여 색 변환
test_img = np.invert(test_img)배경 잡음 제거
import cv2- Otsu 방법으로 배경과 글씨를 구분하는 자동 임계값 설정
threshold, _ = cv2.threshold(src=test_img, thresh=0, maxval=255, type=cv2.THRESH_BINARY + cv2.THRESH_OTSU)- 임계값보다 작은 픽셀 0으로 설정
test_img = np.where(test_img < threshold, 0, test_img)텐서로 변환
test_img = torch.tensor(test_img, dtype=torch.float32)- 배치 차원 추가
test_img = test_img.unsqueeze(dim=0)- 평탄화
test_img = test_img.flatten(1, -1)- 형태 확인
test_img.shape
# torch.Size([1, 784])모델로 예측
model.eval()
logits = model(test_img)
y_prob = torch.softmax(input=logits, dim=1)
y_pred = y_prob.argmax(dim=1)
print(y_pred)함수로 생성
def guess_digit(file):
img = Image.open(fp=file, mode='r')
img = img.resize((28, 28)).convert(mode='L')
img = np.invert(np.array(img))
thresh, _ = cv2.threshold(src=img, thresh=0, maxval=255, type=cv2.THRESH_BINARY + cv2.THRESH_OTSU)
img = np.where(img < thresh, 0, img)
img = torch.tensor(img, dtype=torch.float32)
img = img.unsqueeze(dim=0).flatten(1, -1)
logits = model(img)
y_pred = logits.argmax(dim=1)
return y_pred마치며
이번 주말에는 일정이 있지만 시간 남을 때 도메인을 하나 정해서 개인 프로젝트를 해볼 예정이다. 최근 공고를 봤을 때 자주 보이던 A/B 테스트 분석을 먼저 시작해볼까 싶은데 어떤 프로젝트인지와 어떤 데이터가 필요한지를 찾아봐야겠다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis