
우주와 인생의 Inductive Bias
Inductive Bias (차트/운명): 우주와 인간에게는 고유한 '흐름'과 '경향성'이 있다. 이것은 모델이 정답을 향해 빠르게 수렴하도록 돕는 강력한 가이드라인이다.Brute-force (의지와 노력): 때로는 트랜스포머처럼 엄청난 양의 데이터를 들이부어(고통과

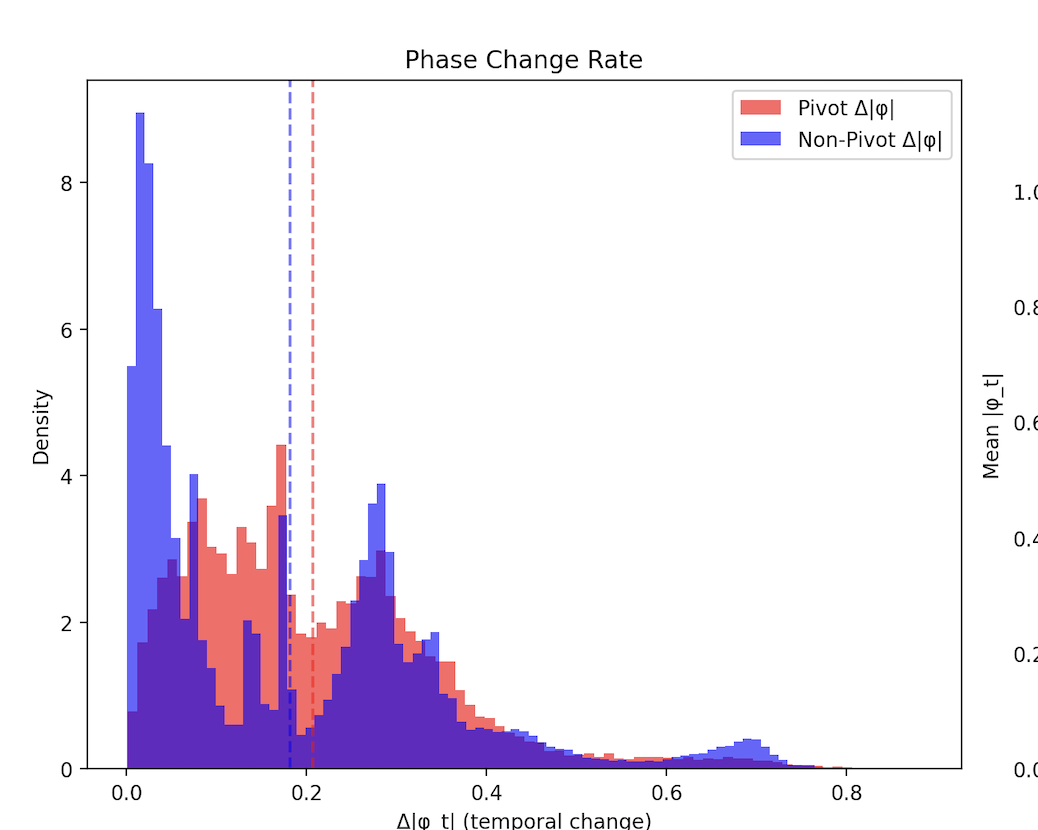
mamba pivot testv3


매번 까먹는 트랜스포머 로직
“나는 사과를 먹었다”토큰1: 나는토큰2: 사과를토큰3: 먹었다Q(Query): 나는 지금 무엇을 찾고 있지?K(Key): 나는 어떤 특징을 가지고 있지?V(Value): 내가 실제로 전달할 정보는 뭐지?“먹었다”의 Q: 먹은 대상이 뭔지 찾고 싶음“사과를”의 K: 먹
[논문] Mamba3
https://github.com/state-spaces/mambaexponential-Euler대규모 언어 모델(Large Language Models, LLMs)의 비약적인 발전 속에서 추론 단계의 계산 효율성은 모델의 실질적인 활용 가치를 결정짓는 핵심
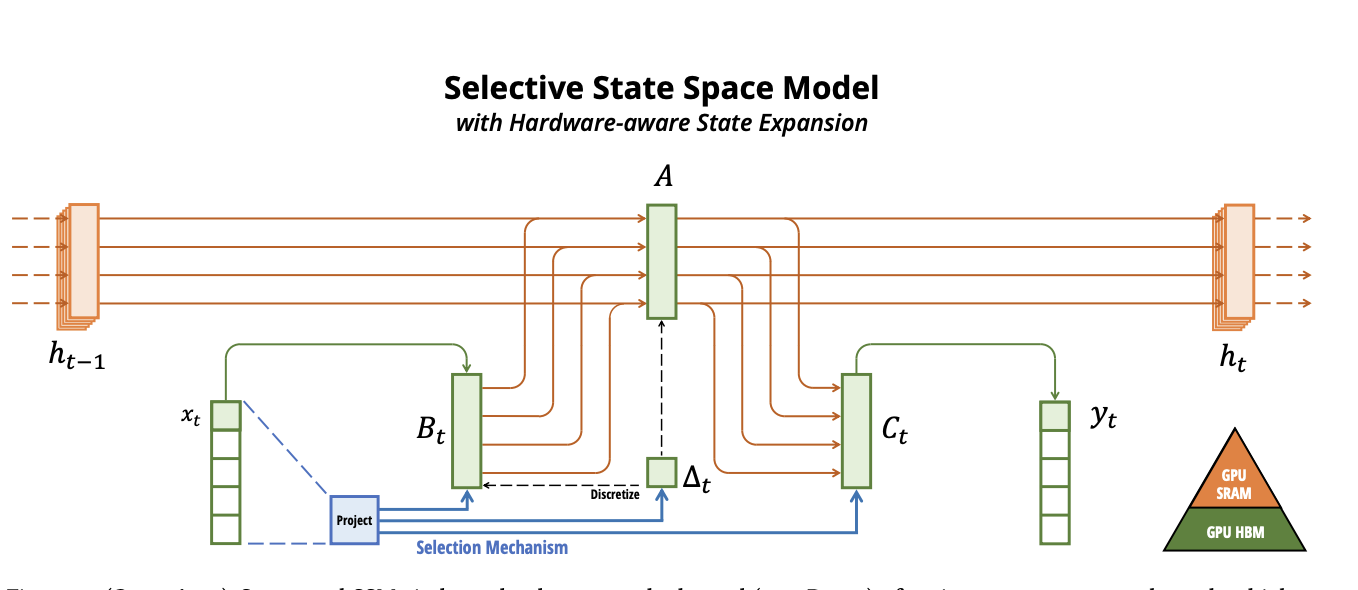
[논문]Mamba
transfomer의 시간복잡도O(N2)가 주는 비효율성이 큼 → 더 효율적으로 GPU 메모리를 쓸 수 있는 방법이 없을까? 특히 gpt계열은 모든 데이터를 인코딩하지 않고 그대로 kv-cache화해서 저장하는 만큼 메모리 비효율성 + 연산량 + 시간이 크다. 그래서
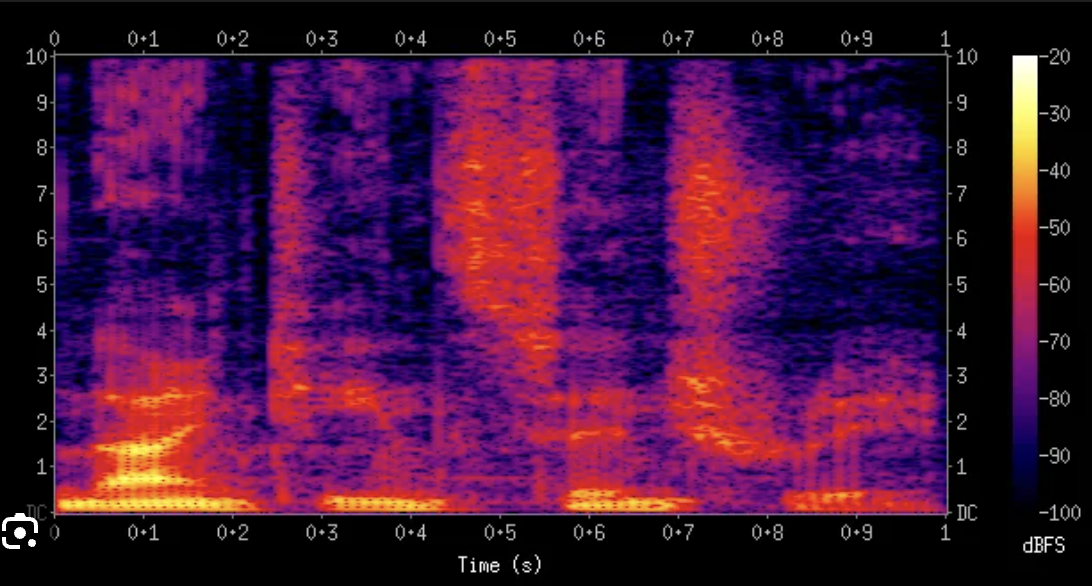
[논문] BIGVGAN
이미지를 생성하는 생성자 모델, ai가 만든 이미지와 진짜 이미지를 판별하는 판별자 모델을 만들어서둘을 경쟁시켜서 모델의 생성된 이미지의 결과를 높이는 모델오디오 신호 처리에서 AI가 소리를 이해하기 가장 좋게 가공한 '소리의 지도’Mel Scale: 인간의 청각 특성
[논문] CLIP & SigLIP 2
CLIP류 모델은 이미지와 텍스트를 동일한 의미 공간(embedding space)에 매핑하는 모델이다.즉, 이미지 하나와 문장 하나를 각각 벡터로 변환했을 때, 서로 의미적으로 일치하는 쌍은 가깝게, 일치하지 않는 쌍은 멀어지도록 학습한다.쉽게 말해, CLIP류 모델
[논문]You Only Cache Once
Classic Transformer (Encoder + Decoder): 번역기형구조: 입력(인코더)과 출력(디코더)이 분리됨.특징: 질문을 완전히 읽은 뒤 답변을 생성. 인코더-디코더 사이를 잇는 '가교(Cross-Attention)'가 필수적.GPT 시리즈 (Dec

[논문]pplx-embed
https://arxiv.org/abs/2602.11151웹 규모의 검색을 위한 다국어 임베딩 모델 패밀리웹 스케일 검색·RAG에서 고품질 텍스트 임베딩 제공.모델 종류pplx-embed-v1 - 0.6B 표준 검색용 pplx-embed-context-v1
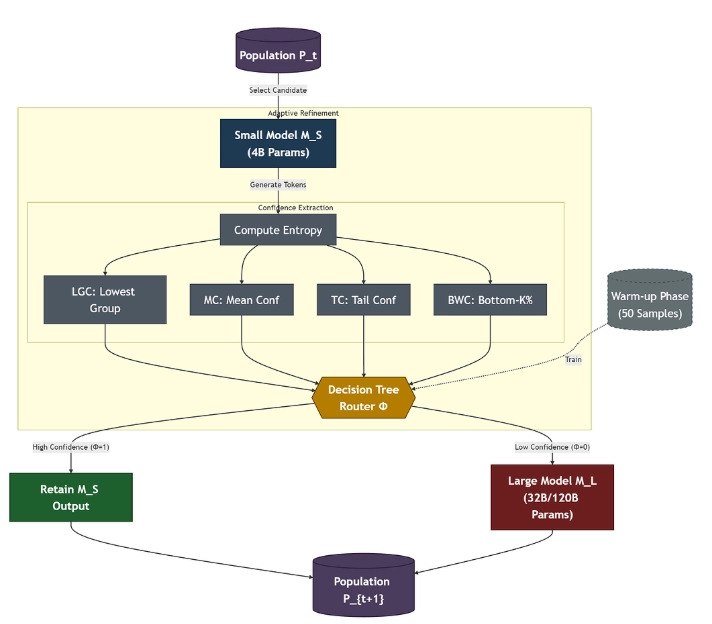
[논문]AdaptEvolve
https://github.com/raypretam/adaptive_llm_selectionhttps://arxiv.org/abs/2602.11931모델을 선택할때의 이슈는 토큰이 적은대신 정확도가 낮은 slm 을 사용할것인가, 아니면 토큰 사용량이
ㅇㄹㄴㅇㄹ
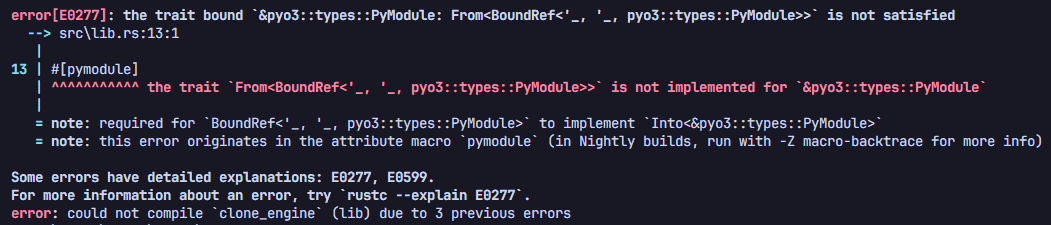
TIL | Rust
m의 타입을 &PyModulel 로 쓰고 잇었는데 버전 업 되면서 타입이 &Bound< PyModule>로 바뀌었다는 이야기. PyModule을 GIL에 묶어서 더 안전한 객체로 사용하겠다는것
Sementic Versioning
내 가장 큰 문제는 버릇이 나쁘다는것이다.버전 규칙 같은 버릇... 필요기본 개념버전 형식: MAJOR.MINOR.PATCH (예: 1.4.2)MAJOR(메이저): API가 호환 안 되게 깨질 때 올린다.MINOR(마이너): 기존과 호환되는 기능 추가나 개선이 있을 때
TIL| 개발일기는 꾸준히 쓰자!
꾸준하게 성실하지 못할수도 있다. 그렇다면 가끔이라도 성실하려고 노력해야지. [✅] 겹치는거 없게 하기 [✅] 번호매기기 [✅]] 옵션값 선택했을때 현재 선택된 값 테이블에 리액티브하게 반영되게 하기 [] 데이터가 약간 이상한거 같은데 그래프 이쁘게 나오는 데이터 있는지 찾아보기 [] 으아 [✅]] 코드 이쁘게 짜기.. [] 그 코드가 왜 나빴을까.......
[쿠버네티스] | 쿠버네티스 클러스터 구축 1시간
쿠버네티스 클러스터 구축 1시간 컷 실화 맞나요? 네 그렇습니다.https://kurl.sh/