
Depth First Search
DFS(Depth First Search)는 말 그대로 깊이 우선 탐색이다.바로 예시를 보자.위와 같은 순서로 노드를 탐색한다.구현 방식은 다음과 같다.어떤 문제에서 DFS를 사용하면 좋을지 백준에 나와 있는 문제를 보자.백준 2606번 링크정답 1번 컴퓨터가 바이러스
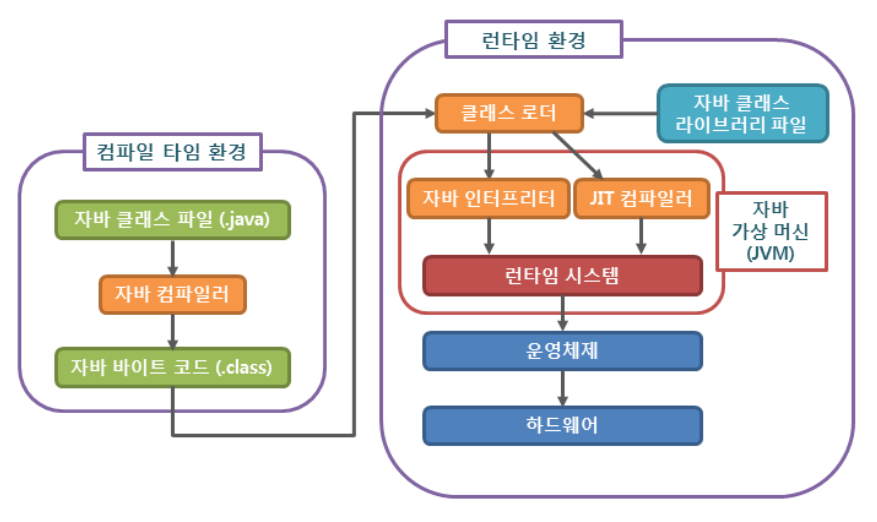
JVM 이란?
JVM이란 자바를 실행하기 위한 가상 기계라고 할 수 있다. OS에 종속받지 않고 Java를 실행시킬 수 있다는 특징이 있다. 이 글에서는 JVM의 구조와 java의 실행과정이 어떻게 이루어지는지 알아보겠다. JVM의 구조 Class Loader JVM내로 클래스 파
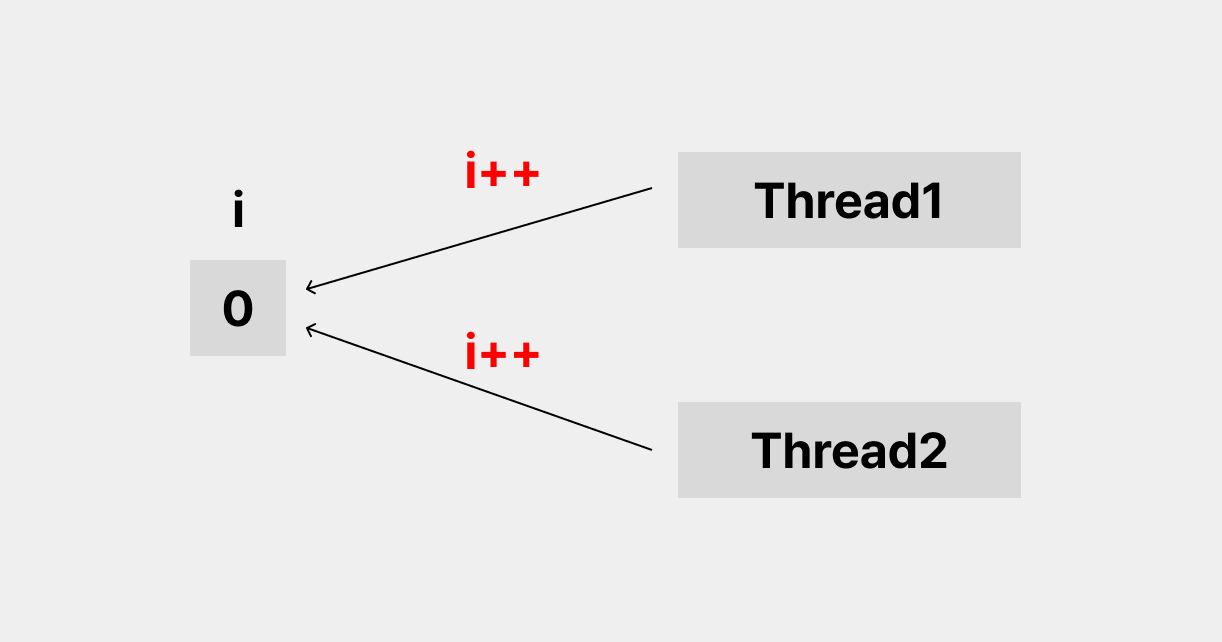
실시간 재고 처리 (동시성 문제)
앞으로 이야기할 주제는 예약 주문 결제 프로젝트를 진행하던 중 만난 동시성 문제에 관한 이야기이다.먼저, 동시성 문제란 한 자원에 여러 쓰레드가 동시에 접근 했을 때, 내가 예상했던 값이 결과로 나타나지 않는 것을 말한다.예를 들어보면,위의 그림처럼 i라는 자원에 대해
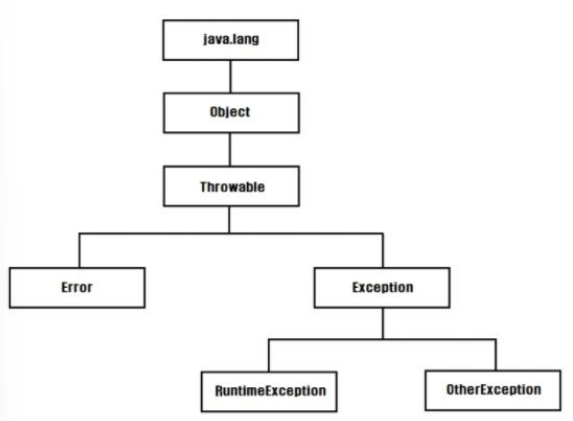
Exception 제대로 파보기
RuntimeException을 상속하는 자식 클래스를 생성해 주었다.먼저, 예외에 대해서 살펴보자.Java에서 예외는 Error,RuntimeException,OtherException으로 나눌 수 있다.Error: JVM, 하드웨어 등 시스템에 문제가 발생했을때 나
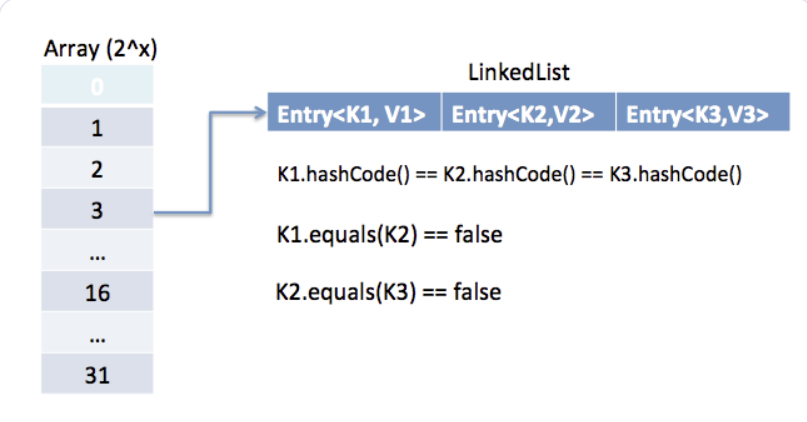
자바의 hashMap 구조
자바에서 HashMap은 배열로 이루어져 있다.HashMap의 index를 어떻게 관리하는지 보면, hashcode() % M 으로 index를 결정 하게 되는데, 이러한 단순한 방식으로는 해시 충돌이 일어나게 된다.해시 충돌을 방지하기 위해 open addressin
ArrayList VS LinkedList
ArrayList는 주소 공간이 쭉 나열되어 있는배열과 같은 형태이지만, 크기를 동적으로 할당 할 수 있다는 장점이 있다.원하는 데이터에 무작위로 접근할 수 있어서 조회 성능이 좋다.시간 복잡도: O(1)맨뒤가 아닌 곳에 추가 하기 위해서는 추가 하고나서 추가한곳보다
엔티티의 identity 전략
Test를 하다보니 이상한 점이 생겼다.Member entity의 id가 1,2,3,4,5가 나오고Team entity의 id가 6,7,8,9,10이 나왔다.왜 다른 엔티티인데 각자 1,2,3,4,5를 갖는게 아니지?? 하고 검색해 보았다.문제는 identity 전략이
[JPA]join 과 fetch join , @ToOne에서N+1 문제 해결
결론부터 말하면, join : 연관된 객체를 select하지 않고 주체만 select한다.fetch join: 연관된 객체까지 select 한다.따라서, 검색 조건에만 필요하고 데이터가 필요 없다면 join데이터까지 필요하다면 fetch join을 쓰면 된다!자세하게
[JPA]단건 vs List 조회시 null
위에서 findListByUsername()은 List로 반환하고, findMemberByUsername은 Member 객체 하나를 반환한다.만약 두 반환값 모두에서 조회되는 값이 없다면 어떻게 될까??결론을 먼저 말하자면List로 받는다면 null 값이 아니라 빈
[JPA]OSIV
jpa에서 OSIV는 API가 끝날때까지 즉, view에 반환할때까지 DB Connection을 가지고 있는것을 말한다. OSIV가 켜져 있으면, Transaction이 끝나도 영속성 컨텍스트가 DB Connection을 붙들고 있기 때문에 lazy loading같은
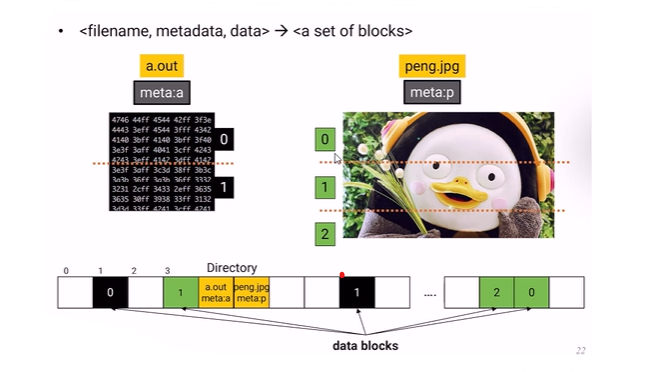
[운영체제] File System
OS 입장에서는 file은 사용자가 만들어놓은 data에다가 이름을 붙여놓은 것이다. data들은 쪼개서 storage 장치에 저장한다. file에 들어가는 정보(meta data) name indentifier : 사람이 file을 맵핑하는것은 name이 될 것이고
[운영체제]Storage Dvices
자석을 이용해서 데이터를 저장한다.자석이 붙어있는 원판이 돌아가면서 헤더가 자석의 방향을 관측하고 0과 1을 쓴다.Seek time: 데이터를 찾기 위해 헤드가 디스크 표면에서 이동하는 데 걸리는 시간이다. 이동 거리가 짧을수록 seek time은 짧아진다. 하드 디스
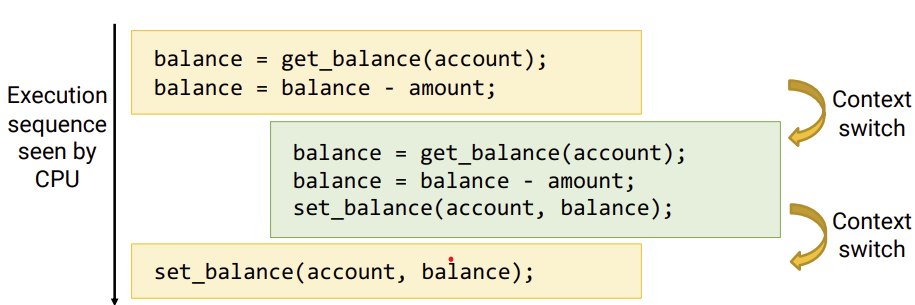
[운영체제]Synchronization
김씨가 ATM기에서 돈을 인출하려고 한다.인출할 수 있는 ATM에 프로그래밍 되어 있는 코드는 다음과 같다.김씨가 20만원이 있었는데 5만원을 뺐다.위에 코드대로라면, 잔액을 조회하고, 잔액에서 인출할 금액을 빼서 잔액을 다시 업데이트 해준다.문제는 ATM기가 하나만
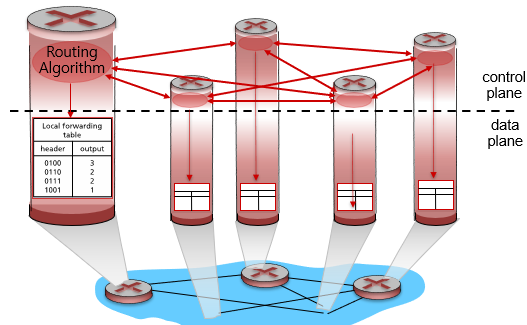
[네트워크]Network Layer(Control)
Pre-Router Control Plane은 네트워크에서 데이터 패킷을 전송하기 전에 라우터에서 수행되는 제어 작업을 의미합니다. 이러한 제어 작업은 라우터가 제대로 동작하고 네트워크에서 데이터 패킷이 올바르게 전송되도록 보장합니다.각각의 모든 라우터의 개별 라우팅

[운영체제] 쓰레드
single and multithreaded processes thread들은 address space를 모두 공유한다. 즉, 한쪽 쓰레드에서 데이터값을 바꾸면 다른쪽 쓰레드도 바뀐값을 알 수 있다.
[운영체제] Page Replacement
demand paging(memory를 캐시로 사용)을 효율적으로 하기 위해선 page fault를 줄이는게 가장 중요하다.왜냐하면 page fault가 일어났을때 disk로 접근하는 시간이 memory 접근 시간보다 훨씬 커서 속도에 큰 영향을 미치기 때문이다.예를들
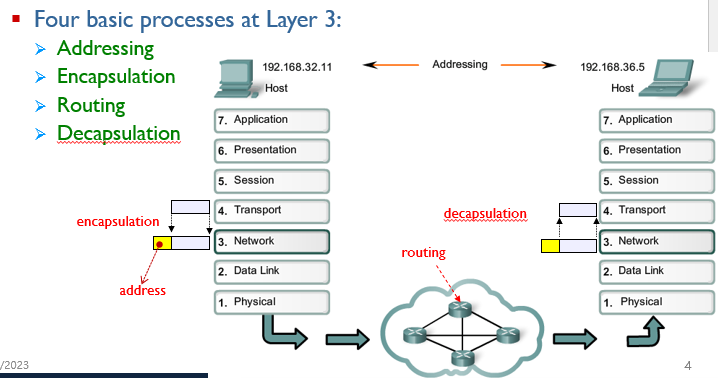
[네트워크] Network Layer(Data)
network layer는 encapsulation을 통해서 address를 datagram header에 추가하고 그 address 주소에 맞는 다른 end system의 network layer까지 올라간다.다른 end system을 찾아갈때는 routing과정이
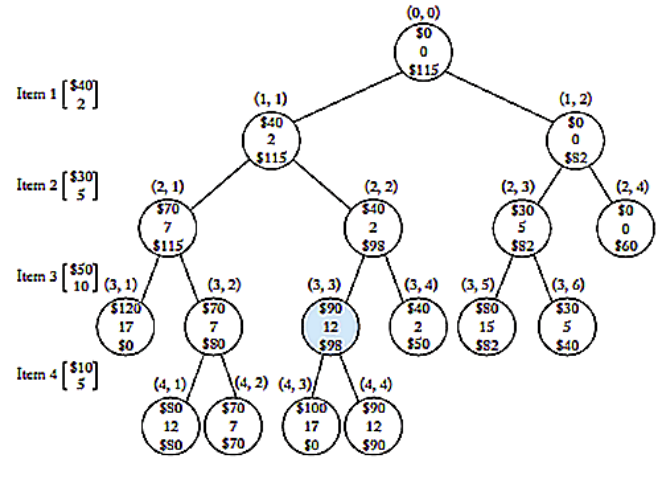
[알고리즘]branch and bound
W=16인 이 트리구조가 어떻게 나온건지 알아보자.먼저 value값은 실제적으로 넣은 값을 넣어준다. 반면 bound 값은 현재 노드 상황에서 Item들을 쪼갤 수는 없지만 무게에 맞춰 쪼개서까지 가방에 넣을수 있다고 했을때의 최대 가치 값이다. 이걸 기억하면서 접근

H2 db 설치하고 실행하기
h2는 java기반으로 실행되기 때문에 java는 깔려있어야 한다.http://www.h2database.com/html/download.html여기서 다운받는다.압축을 풀어주고나서 H2/bin 파일을 찾아간다.윈도우라면 h2.bat 맥이라면 h2.sh를 실행
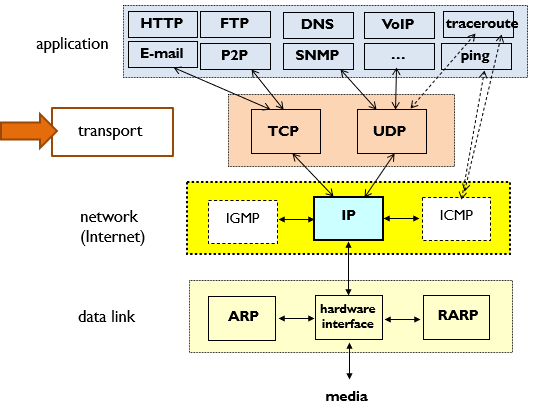
[네트워크]Transport Layer - UDP
계층구조를 보면 TCP와 UDP는 transport Layer에 있다.다른 host에서 실행되는 app process 사이에서 logical한 communication을 한다.(end system)✍️send side: app message를 segment로 쪼개서 n