Machine Learning / Deep Learning
1.[ML] Machine Learning 기본적인 용어와 개념
딥러닝에 대한 기초지식이 아예 없어서 입사 전에 공부하기아는 오빠가 홍콩과기대에서 강의하시는 sung kim 교수님의 강의를 추천해주셨다.강의는 유튜브에 나와있는 것을 토대로 정리하기위해 velog에 작성 일종의 SW 같은 것 Linitations of explicit
2.[ML] Linear Regression / Hypothesis / Cost
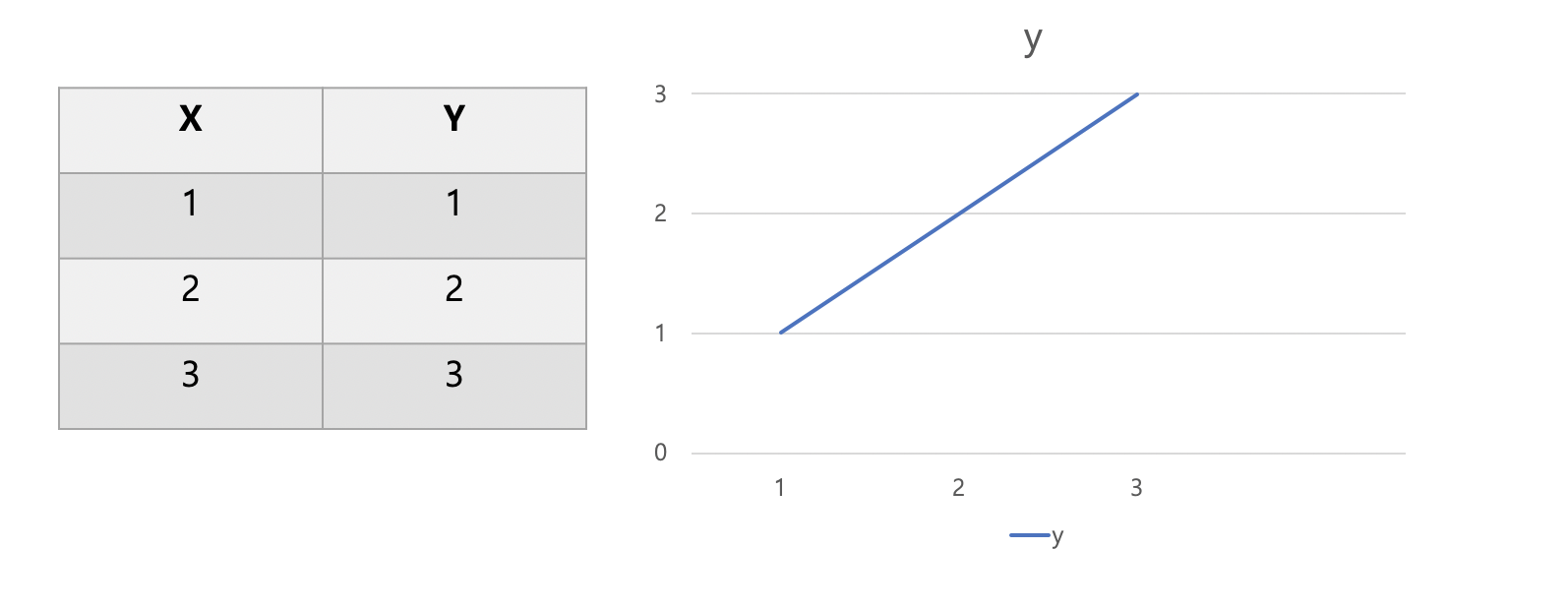
\-학생이 x시간만큼 공부했을 때 y만큼의 결과가 나올 것이다 라는 데이터 셋을 정의한 예이다.\-x: 예측을 하는데 필요한 데이터 \-Y: 예측을 해야하는 결과값\-왼쪽은 데이터셋, 오른쪽은 왼쪽 표를 바탕으로 x를 기준으로 y의 결과값을 그래프로 나타낸 것 \-학
3.[ML] minimize Cost Linear Regression 원리

(1)의 Hopothesis를 기반하여 실제 모델이 (2)의 실제 값과 얼마큼 차이가 있는가 원래 정의했던 Hypothesis에서 b의 값을 제외시켜 간단하게 hypothesis를 정의하여 Cost가 어떻게 될지 구해볼 것이다. W = 2일 때, Cost(W)의 값은
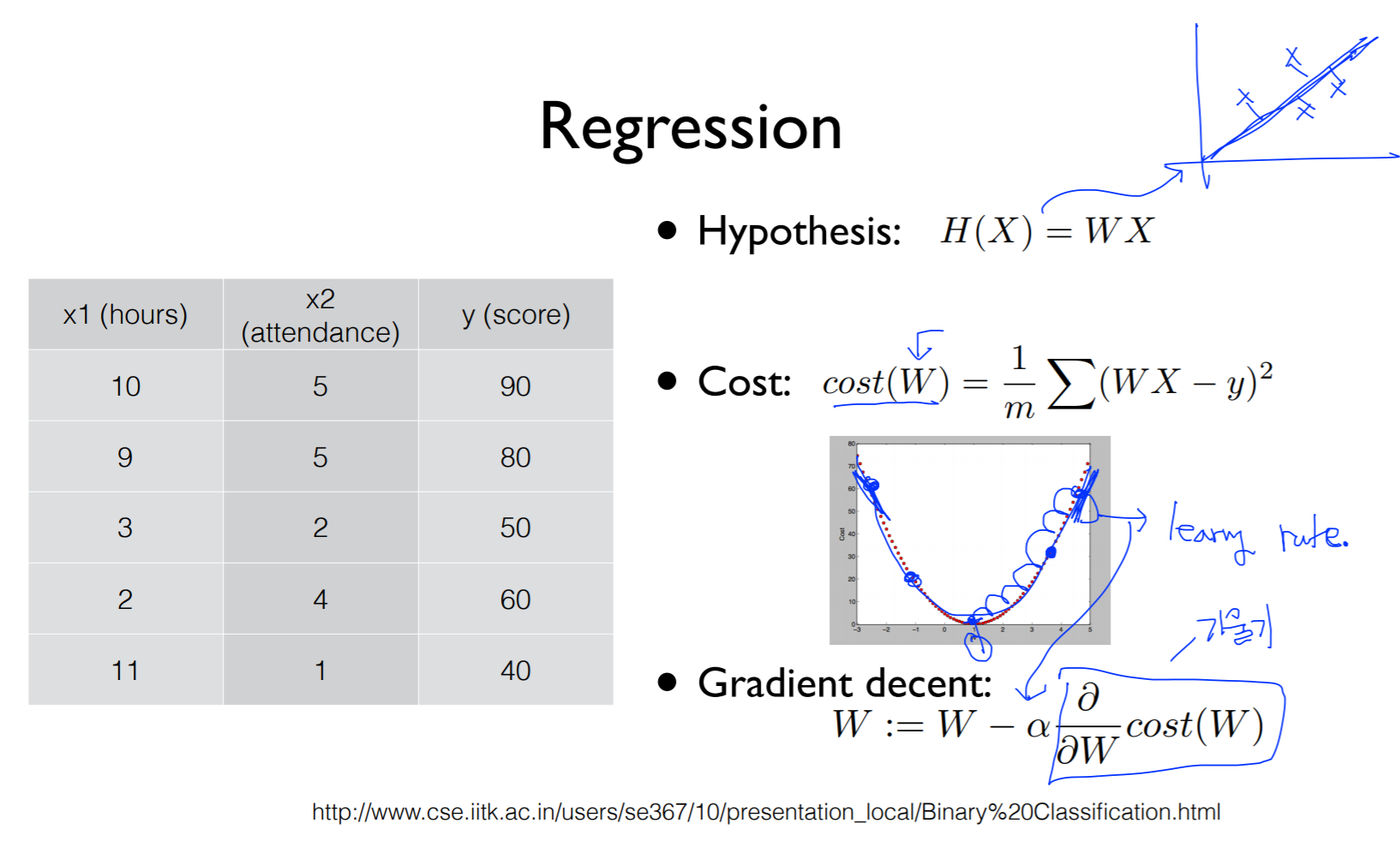
4.[ML] Multi-variable linear regression
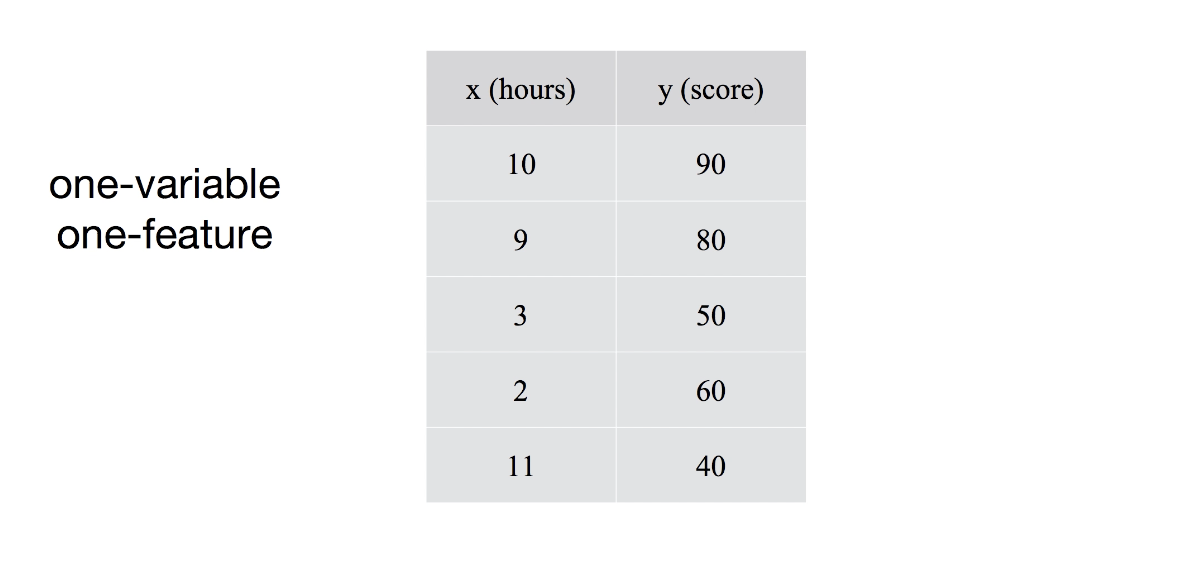
input이 1인 경우에는 data가 위의 그림처럼 나오게되고, 하나의 x와 하나의 y로 결과값이 나오게 된다. 여러 개의 input인 경우, 즉 x1, x2, x3와 같이 three inputs 인 경우에 위 그림과 같이 quiz 1과 quiz 2, mid 1 점수를
5.[ML] Logistic (regression) Classification
linear 하게 나타나있음 (식)가설로 세운 linear가 얼마나 가깝고 먼가의 값이 cost학습을 한다는 것은 우리가 가지고 있는 데이터에서 cost가 최소화되는 weight를 찾아야함cost 함수를 미분한 값이 기울기 한번에 얼마나 움직일까가 알파 (step si
6.[ML] Logistic (regression) classification: Cost function & gradient decent
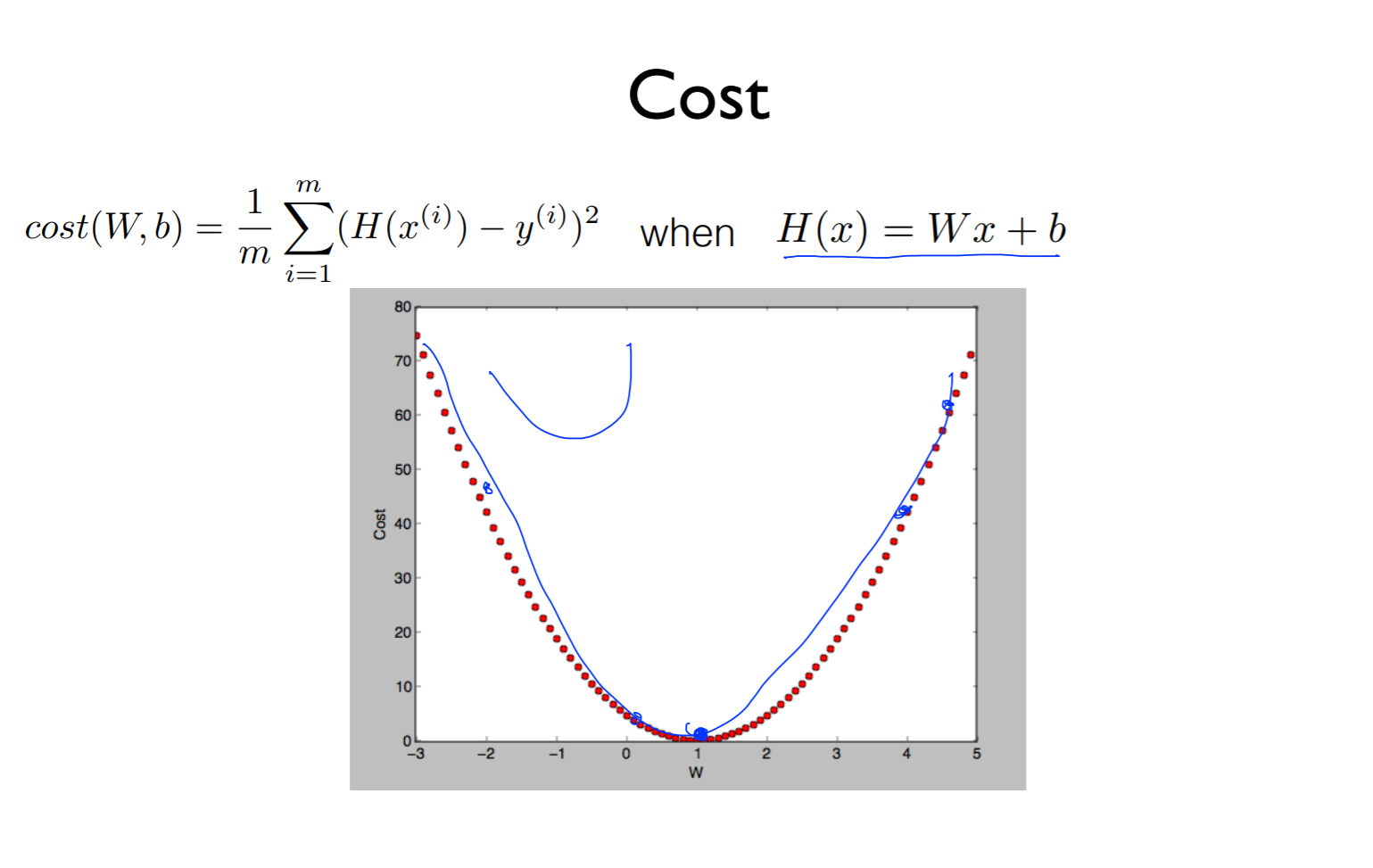
Cost function의 식은 위의 식으로 나타냄이것을 linear로 hypothsis를 주면 위의 그래프로 그려낼 수 있음가설이 0-1의 값으로 바뀌어 H(X)의 식이 오른쪽 식으로 변경됨H(x)의 경우 제곱으로 인해 구부러진 그래프가 되고 어느점에서 시작하든 최소
7.[ML] Softmax regression
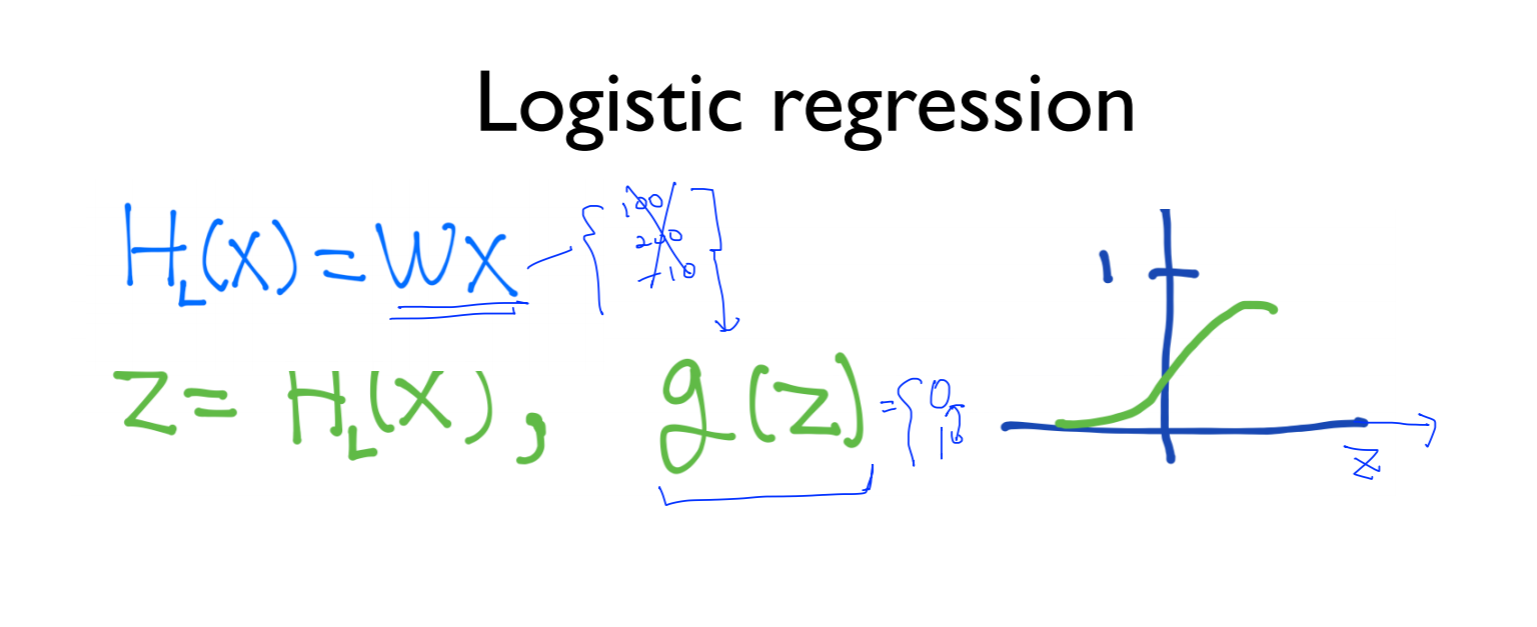
H(x)의 함수는 100, 200, -10 과 같이 큰 값의 결과를 얻어내기 때문에 z라는 압축된 수로 나타내길 원함따라서 아무리 큰 값이더라도 0-1사이의 값으로 나타낼 수 있음g(z)의 식은 다음과 같이 나타낼 수 있으며, 이 식을 sigmoid 또는 logisti
8.[ML] Learning rate / Overfitting / Regularization
그래프의 learning rate를 조절하는 알파값을 임의로 정해줌minimize할 때 learning rate를 지정하여 값을 정해줌rate의 값을 크게 줬을 때는 어떤 점에서 시작하게 되면 경사면의 step이 굉장히 크게되는데 이러한 경우 값의 범위를 넘어버리는 경
9.[ML] Training / Testing data set
Last lecture 지난 시간동안 데이터를 통해 학습을 시킴 이 모델이 얼마나 훌륭한지 / 성공적으로 예측 할 수 있는지를 평가하는 방법이 무엇일까? Evaluation 이러한 데이터가 있을 때 (training set) 모델을 학습을 시키고 다시 이 trai