요즘 계속 speculative decoding을 MoE 모델에 적용 시킬 아이디어를 찾아보면서, draft 모델을 구하는데 꽤 고생을 좀 했었다. 비교적 신규 모델인 Qwen3 235B나, Phi-4 MoE의 경우, draft 모델이 생각보다 MoE의 분포를 따라오지 못하는 것 같아서 가속이 잘 안되는 경우가 많았다. 거기에 DeepSeek나 GPT-OSS는 아예 draft 모델로 사용할 만한 작은 모델이 없었다. 그래서 MoE 자체를 draft로 사용하려고 궁리를 해봤는데, 비슷한 아이디어의 논문을 오늘 소개를 받게 되었다. (역시 좋은건 누가 먼저 한다...)
Medusa와 EAGLE의 문제점
우선, speculative decoding에 대한 내용은 이전 리뷰를 참조하면 된다.
https://velog.io/@with1015/ICML23-Fast-Inference-from-Transformers-via-Speculative-Decoding
Medusa와 EAGLE은 vLLM V1에서 지원하고 있는 방식이지만, 늘 그렇듯 문제가 있다. 우선, Medusa는 논문을 보면 대부분 batch size가 1인 상태에서 효과를 보는 방식이다. 그리고 Medusa head는 target LLM의 마지막 hidden state를 기반으로 독립적으로 토큰을 예측 한 뒤, 이들을 결합 시키는 방식인데, 모든 head가 동일한 마지막 hidden state를 사용하기 때문에, 완벽한 decoupling이 이루어지지 않는다. 그렇기 때문에 각 head는 독립적이고 다양한 예측이 어렵다는 문제가 있다.
EAGLE의 경우, draft에서 이전 시점의 draft 토큰을 feature 수준에서 decoupling 시키는 방식이다. 그리고 이를 원래 LLM의 LM head를 이용하여 feature를 draft token으로 변환 시킨다. 이 방식은 feature sequence 내의 불확실성을 줄여서 좀 더 정확한 예측을 가능하게 하긴 한다. 하지만 draft가 만드는 token tree의 동일 layer에서 발생하는 top-K 토큰들이 서로 의존성이 발생하게 된다. 그래서 이 방식 역시 다양성이 제한이 되는 문제가 있다.
Jakiro
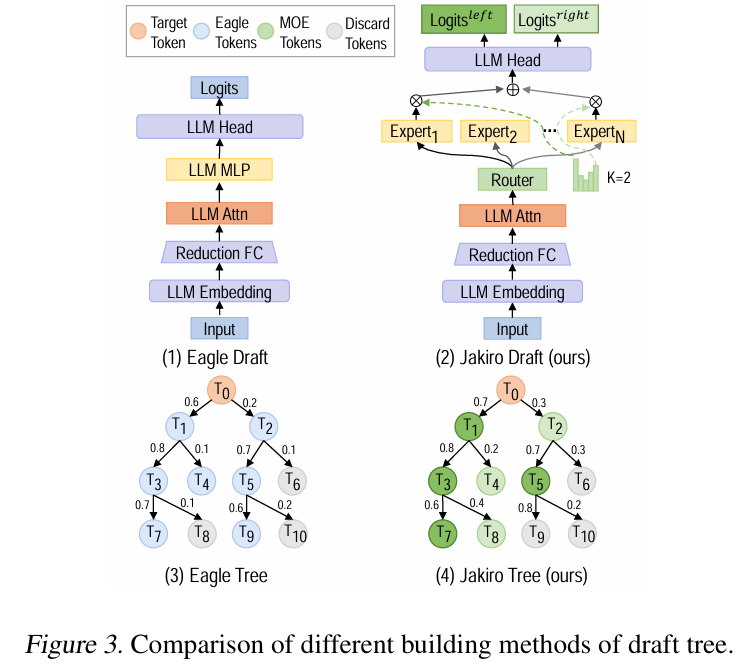
MoE head를 이용한 Dynamic Decoupling
Jakiro는 여러개의 MoE head를 이용하여 expert 모듈을 동적으로 할당하는 방식으로 토큰을 예측한다. 이 방식은 발생하는 draft 토큰 사이에 잠재되어 있는 차이를 반영 할 수 있고, 서로 다른 head 사이에 토큰 예측을 decoupling하여 예측 간의 간섭을 줄일 수 있다.
draft 모델의 구조는 EAGLE의 방식과 유사하다. 위 그림의 (2)번처럼, reduction layer가 dimension을 줄이고, attention layer와 경량 MLP로 만들어진 expert head가 병렬로 구성이 된다. 이처럼 EAGLE과 동일하게 단일 decoder layer로 구성이 된다. 반면 embedding과 head layer는 target 모델과 동일하게 유지되어야 하기 때문에 추가적인 파라미터를 도입하지 않았다.
MoE Tree 구성
Jakiro는 draft 토큰으로 EAGLE과 같은 tree를 구성하면서, intra-layer 의존성을 분리함과 동시에 inter-layer의 독립성을 유지하는 방향을 시도했다. 이 방식은 서로 다른 expert 레이어에서 생성 된 draft 토큰들이 독립적으로 생성 되는 것을 보장하고, target model의 예측 과정과 일관성을 유지하도록 한다.
즉, 이전 문맥을 기반으로 다음 문장을 이어가면서 (inter-layer) 같은 문맥에서도 여러 해석을 다양하게 시도(intra-layer)한다.
이와 동시에, intra-layer token들의 decoupling을 통해 non-greedy decoding에서 더 넓은 후보 sequence search space 확보가 가능하다. 그렇기 때문에 예측 할 수 있는 다양성은 증가하면서, 출력되는 분포는 일관성을 가지게 된다.
Jakiro는 LLM 내부의 MLP 레이어를 MoE expert로 대체하고 draft tree를 수정했다. 이를 예시를 들어서, expert 전체 수가 이고, 최종적으로 활성화 되는 expert의 수를 라고 가정해보자. MoE의 router와 LLM head layer는 expert들 사이에서 공유 된다.
각 단계에서, Jakiro는 2개의 후보 logits distribution을 생성한다. 이들은 MoE tree decoding 과정을 통해 처리가 되고, logits은 선택 된 expert에 의해 대응하는 점수인 를 기준으로 정렬이 된다. 그래서 결과적으로 점수가 큰 expert는 현재 layer의 왼쪽 노드로, 작은 쪽은 오른쪽 노드로 배치가 된다. 이러한 과정은 EAGLE의 top-K를 이용한 방식을 따르기 때문에, 각 토큰은 개 만큼의 expert를 활성화 시키고, 기본 값을 사용하는 sparse MoE 구조이기 때문에 computation efficiency가 보장이 된다.
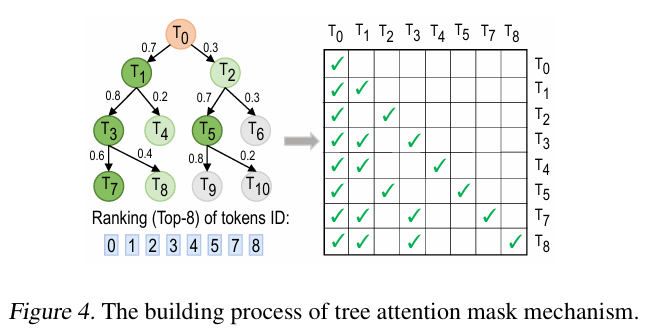
Attention mask의 경우, 위 그림처럼 참조 되지 않는 branch에 존재하는 토큰끼리는 attention tree에 masking이 되는 방식이다. (SpecInfer에 나오는거랑 똑같다.)
Contrastive Mechanism 통합
LLM의 문제점 중 하나인 hallucination은 draft 모델에서도 발생하기 때문에 top-1만 사용하는 greedy decoding에서 문제가 발생한다. 이건 물론 학습을 추가로 더 하면 어느정도 완화는 되지만, draft 모델은 일반적으로 작기 때문에 어느정도 성능 향상이 이루어지고 나면 더이상 성능이 좋아지지 않는다.
Jakiro는 contrastive decoding을 이용해 추가 학습 없이도 greedy decoding에서 품질 향상이 되는 것에 착안하였다. contrastive decoding은 원래 strong 모델 (크고 정확한 모델)과 weak 모델 (작고 빠르지만 부정확한 모델) 사이에서 가장 크게 차이가 발생하는 단어를 고르면 정확한 답변을 얻을 수 있는 방식이다.

Jakiro는 두 모델을 사용하는 것과 달리, 위 그림처럼 MoE의 expert 사이에서 top-1과 top-2 점수를 가지는 expert의 output hidden state에 contrastive 방식을 적용했다. 이는 전체 모델을 돌리는 것과 대비하여 두 expert의 출력만 비교하기 때문에 훨씬 계산도 적고 효율적이다. 해당 방식의 구체적인 수식을 통한 해석은 다음과 같다.
- 각 expert가 계산한 hidden state를 , 라고 했을 때, 두 expert의 출력을 확률 가중 평균한 값을 구한다.
- 두 expert의 output 차이를 계산한다. 완전히 같을 수록 이 차이 값은 작아진다.
- 1번과 2번 두 값을 사용해 최종 logits 값을 계산한다.
2번 수식에서 와 는 각각 top-2와 top-1 expert의 점수값에 해당하는 학습 가능한 파라미터이다. 두 expert 사이의 차이를 adaptive 방식으로 조정하여 contrastive learning의 효과를 높이는 역할을 한다.
Draft Model Training
EAGLE과 동일하게 학습 비용을 줄이기 위해서 Jakiro는 전처리가 완료 된 고정 된 데이터셋을 사용한다. 이에 따라 data augmentation을 위한 하이퍼파라미터는 EAGLE과 동일하게 사용 된다.
다음 단계의 feature를 regression으로 예측하기 위해 Smooth L1 loss를 사용하고, 발생하는 token sequence의 정확도 보장을 위해서 cross-entropy를 병행하여 사용한다. 하지만 draft 모델의 전체 과정은 autoregressive라서 계산 비용 자체가 원래 높기 때문에, 끝에서 2번제 단계에서 parallel decoding을 적용했다. parallel decoding이 이루어 질 때, 다음 토큰의 예측이 MoE의 두 expert head 사이에서 contrast를 통해 수행이 되기 때문에 Medusa처럼 additional loss가 추가가 된다.
결론적으로, optimization을 위한 최종 loss function은 다음과 같다.
그리고 각 항은 다음과 같이 계산이 된다.
위 두 식은 draft가 다음 단계의 feature를 얼마나 잘 예측했는지 평가하는 loss이다. 현재 단계가 인데, 재밌는 점은 아래 수식인 constrastive loss는 현재로부터 한 단계가 아니라 두 단계 뒤의 feature를 예측하려고 한다.
그리고 MoE와 constrast에서 발생한 다음 토큰 확률 분포를 정규화 시킨다.
정규화 된 확률 분포를 통해 각 branch에서 나온 예측값인 를 정답 확률 분포인 와 비교하여 loss를 계산한다. 이는 각각 MoE 모델이 다음 단어를 얼마나 정확하게 맞췄는가, 그리고 contrast가 얼마나 정확한가를 계산하게 됨을 의미한다.
두 loss를 합칠 때 사용 되는 두 가중치 값은 , 값을 일반적으로 사용하였다.
실험 결과
Jakiro의 실험에서는 Vicuna 7B, 13B, 33B와 LLaMA-2 chat 7B, 13B, 70B, 그리고 LLaMA-3 instruct 8B, 70B를 사용하였다. 대부분 Medusa나 EAGLE과 비교하기 위해서 batch size는 1을 사용했다. 그래서 평가지표도 throughput 대신 latency 감소와 acceptance length를 중점으로 평가하였다. GPU는 모델에 따라 1개에서 최대 4개를 사용하였다.
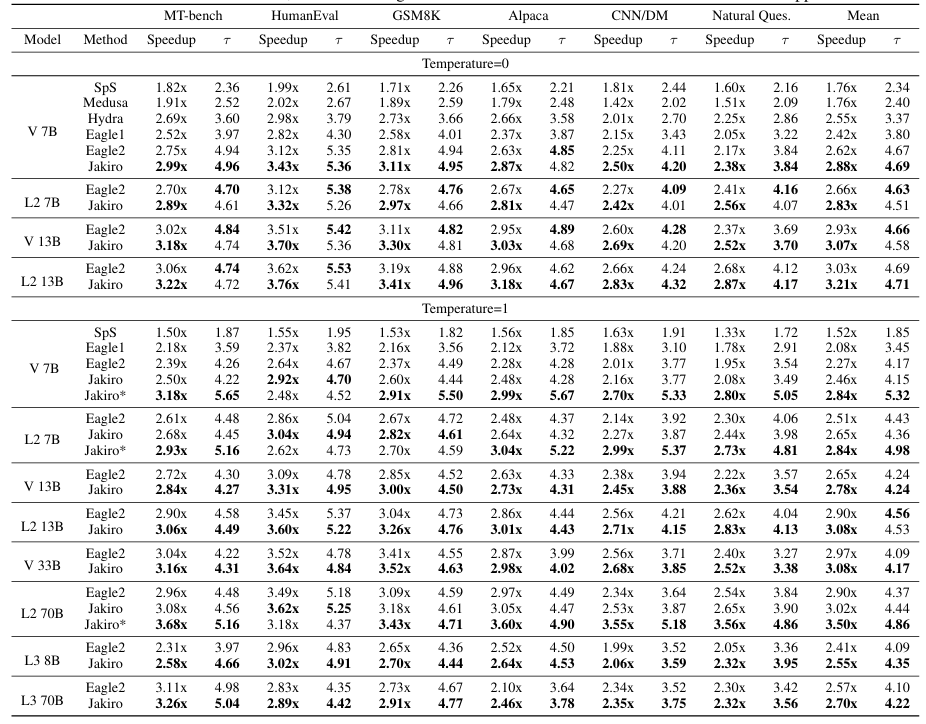
위 표는 다양한 데이터셋과 모델에서 Jakiro의 speed-up과 평균 acceptance length 향상을 보여준다. 거의 대부분의 데이터셋과 모델에서 성능 향상이 이루어졌다. EAGLE-2에 비하면 acceptance length의 개선이 미미한 수준인데, 이는 EAGLE-2에 비해 draft step이 하나 더 적기 때문이다. 그럼에도 speed-up은 Jakiro가 더 높은 값을 달성했다.
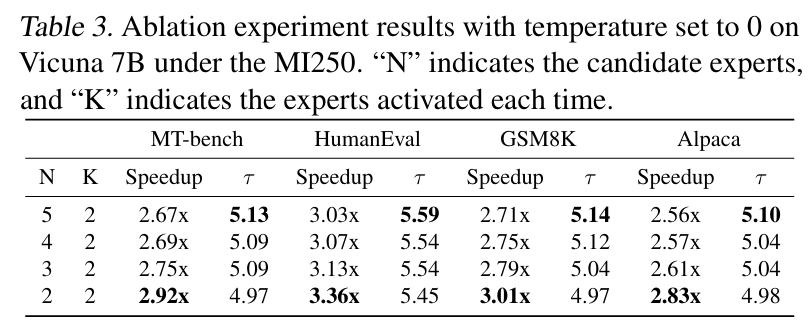
위 표는 MoE의 후보 expert 수와 활성화 되는 expert 수를 조정을 했을 때, speed-up 비율과 acceptance length의 변화를 보여준다. 후보가 되는 expert 수가 증가 할수록 acceptance length는 길어지지만 반대로 computational overhead는 증가하는 것을 확인 할 수 있다.
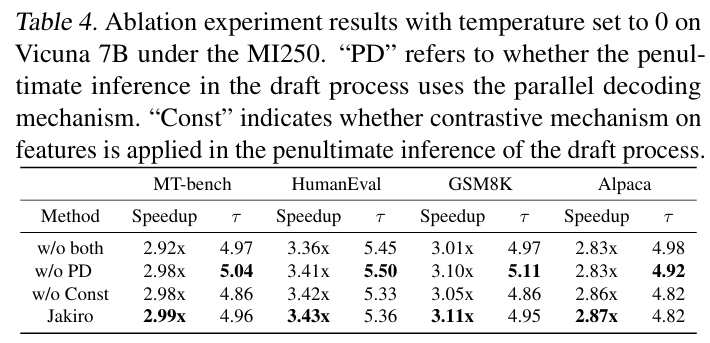
마지막으로 parallel decoding과 contrastive mechanism을 결합함으로써 얻을 수 있는 성능 증가를 설명한 표이다. 일단 constrastive mechanism과 parallel decoding은 둘이 서로 orthogonal이다. constrastive mechanism는 다음 토큰을 더 정확하게 예측하는데 초점을 두지만, parallel decoding은 한 번의 단계에서 여러개의 토큰을 동시에 출력하는 것을 목표로 하기 때문이다.
결과적으로 parallel decoding이나 contrastive mechanism을 개별적으로 사용해도 MoE를 단독으로 사용하는 것보다 성능 향상은 발생하긴 한다. 하지만 동시에 사용을 하는 경우에 speed-up 비율이 제일 극대화 되었고, 평균 acceptance length도 유지가 되기 때문에 둘 다 사용하는 것을 권장한다고 한다.
결론 및 고찰
이 논문을 읽으면서, head를 MoE expert로 바꿔놓고, 거의 대부분은 EAGLE과 Medusa의 구조를 가져다가 사용했다는 느낌이 많이 들었다. 실험의 결과 상으로는 speed-up이 꽤 이루어졌는데, 팀에 인턴 분이 Jakiro의 오픈소스를 돌렸을 때는 생성 퀄리티가 그닥 좋지는 않았다고 알려줬었다. 그 분이 뭔가 설정을 잘못 했을 수도 있다고는 했지만, MoE 자체가 학습이 워낙 까다롭기도 해서 나도 따로 돌려서 교차 검증을 해봐야겠다는 생각이 들었다. 그리고 batch size를 1로 두고 실험을 한 것도 보면 batch size가 커지는 경우에는 성능이 생각보다 좋지 않을 것으로 보인다. 아마 MoE를 head로 쓰기 때문이 아닐까 싶은데, 이것도 확인해봐야 할 것 같다.
