자료구조/ 알고리즘
1.[자료구조/ 알고리즘] 시간복잡도
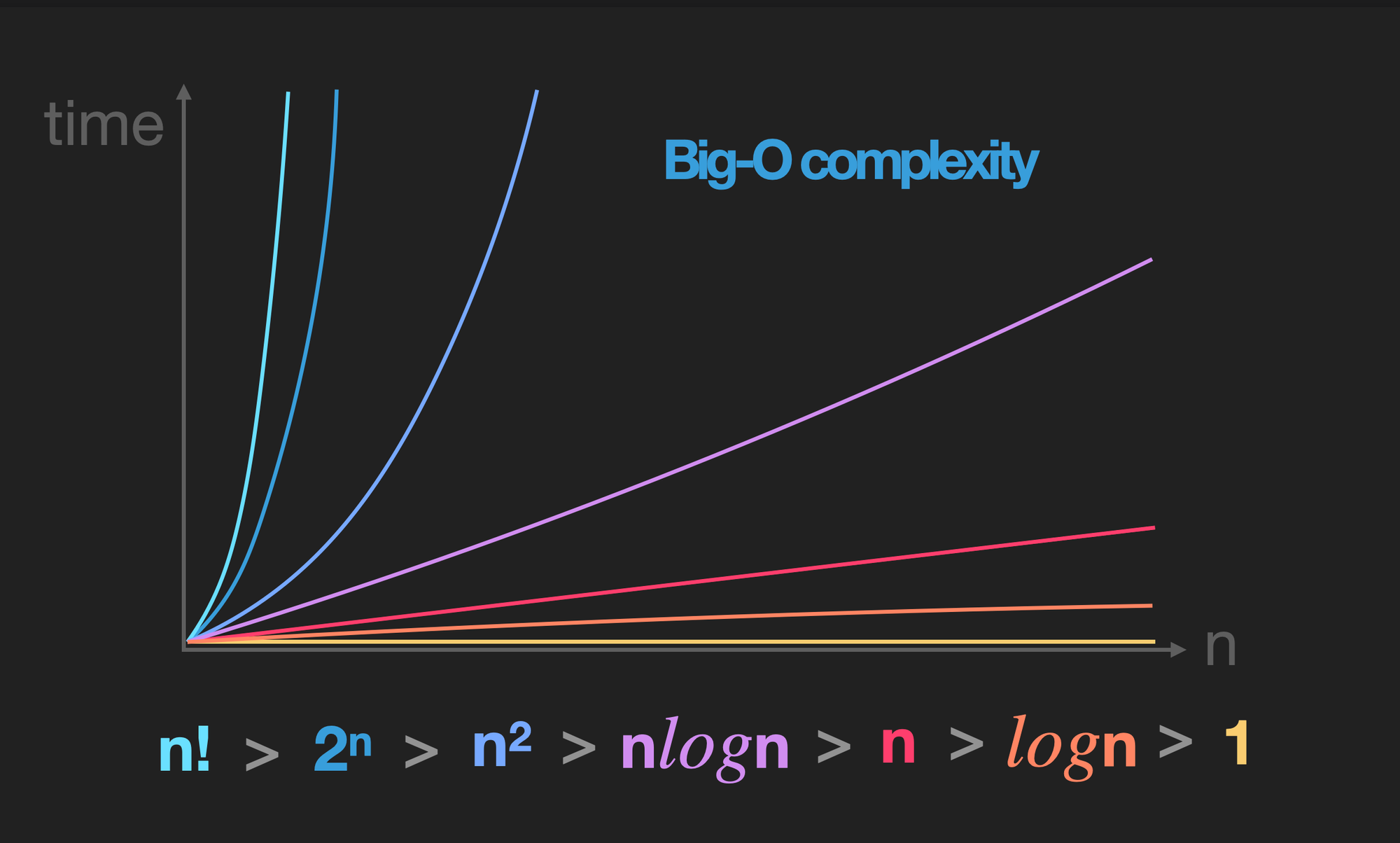
어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법: 문제를 해결하는 방법한 문제를 해결하는 방법은 한 가지만 있는게 아니라 무수히 많을 수 있다.자주 쓰이는 문제 해결 방법은 패턴화: BFS, DFS, DP, 다익스트라 등등각 상황에 적합한 알고리즘을 선택할 수
2.[자료구조/ 알고리즘] 리스트(List)

리스트(List)는 순서를 가지고 원소를 저장하는 자료구조이다. sequence라고도 불린다.구현방법으로는 ArrayList로 구현할 수 있고, LinkedList로 구현할 수 있다.배열을 기반으로 구성된 List 자료구조이다. Static Array로 구현할 수 있고
3.[자료구조/ 알고리즘] 큐 & 스택(Queue & Stack)
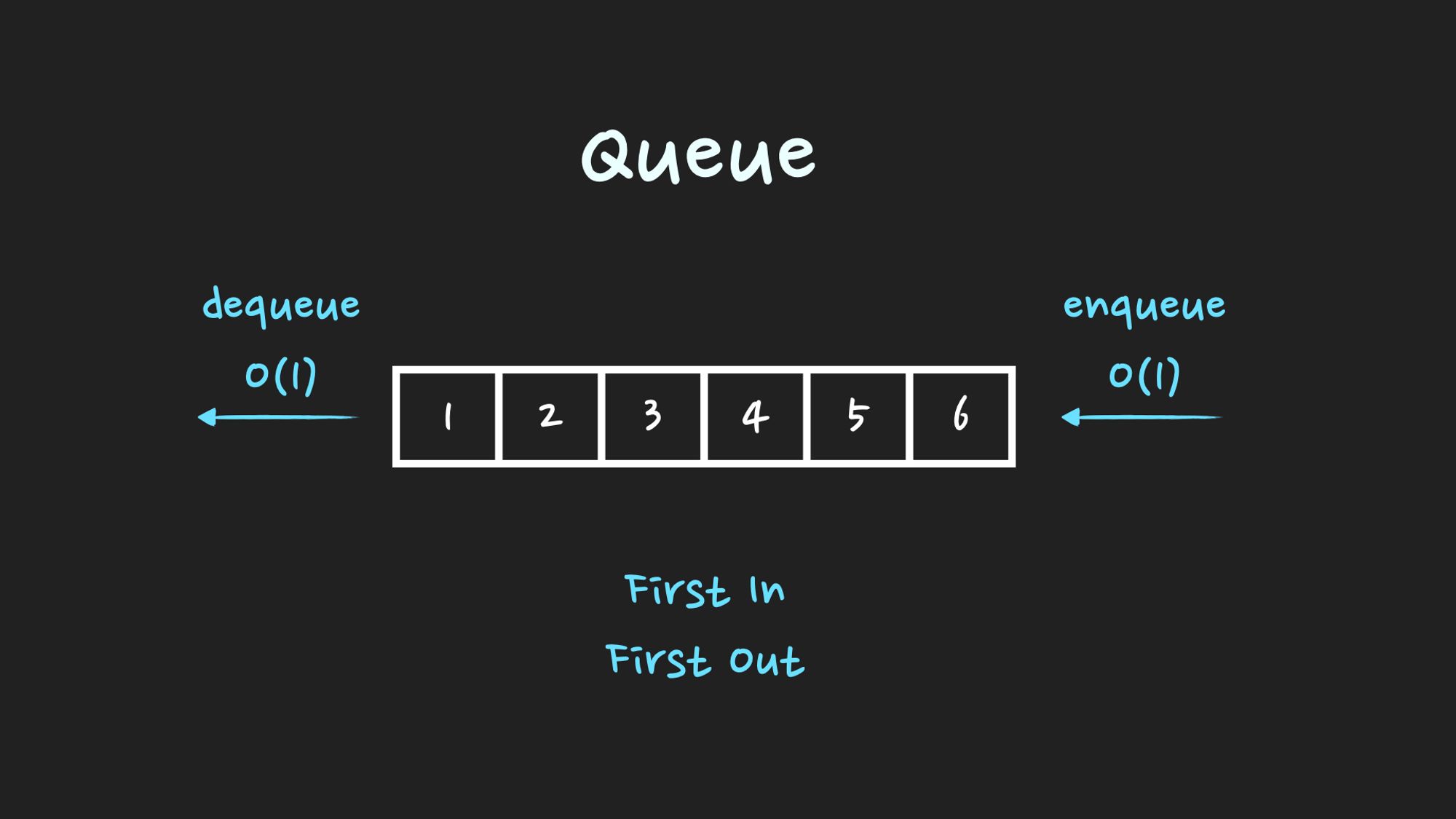
먼저 저장한 데이터가 먼저 출력되는 선입선출 FIFO(First In First Out)형식으로 데이터를 저장하는 자료구조이다.enqueue: Queue의 rear(뒤)에 데이터를 추가하는 것dequeue: Queue의 front(앞)에서 데이터를 꺼내는 것시간 순서상
4.[자료구조/ 알고리즘] 해시테이블(Hash Table)
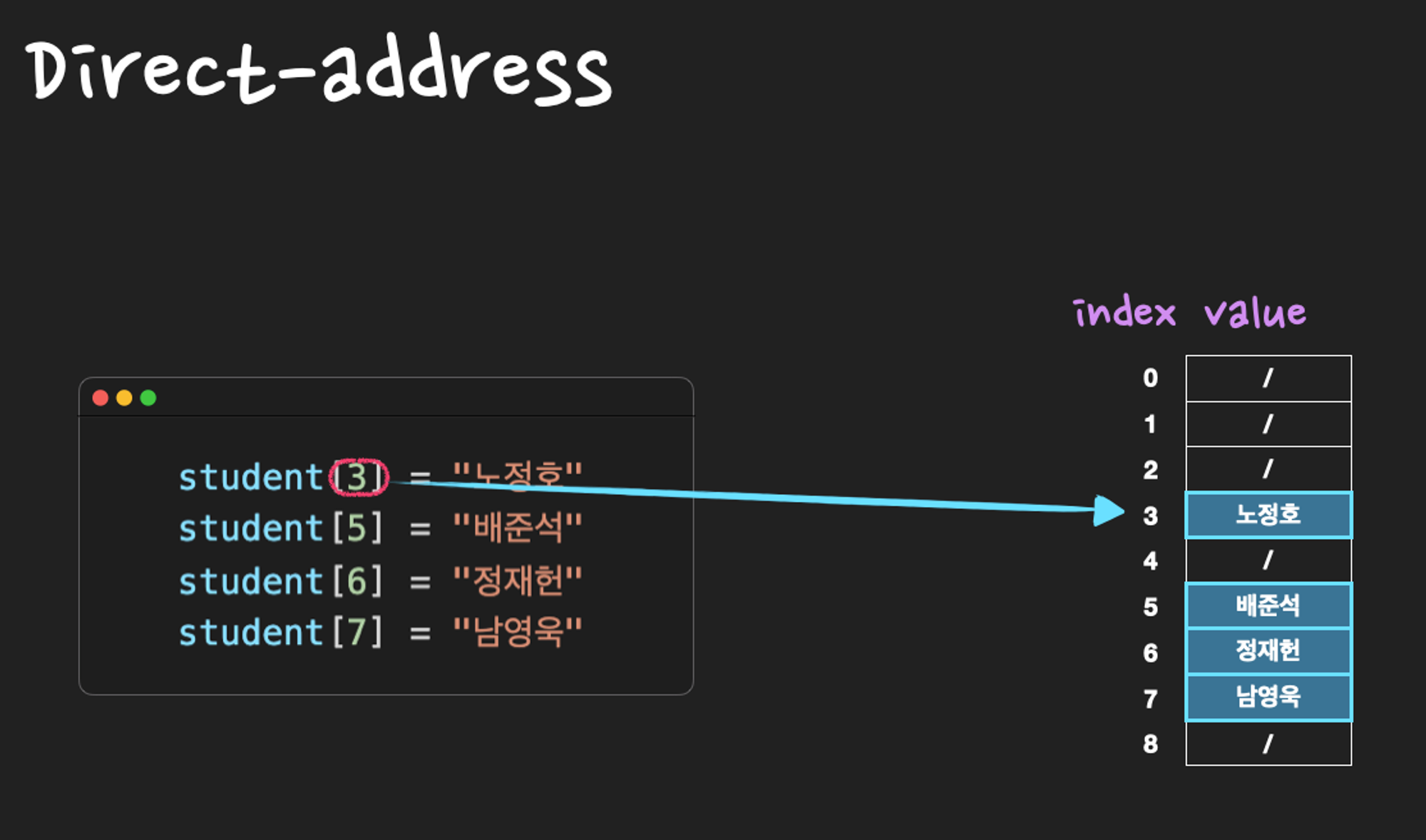
효율적인 탐색(빠른 탐색)을 위한 자료구조로, key-value쌍의 데이터를 입력받는다.hash function h에 key값을 입력으로 넣어 얻은 해시값 h를 위치로 지정하여 key-value 데이터 쌍을 저장한다.저장, 삭제, 검색의 시간복잡도는 모두 O(1)입니다
5.[자료구조/ 알고리즘] 재귀(Recursion)

참고사항💡 재귀는 추후 그래프 탐색, 트리, dp 등 주요 자료구조와 알고리즘에 접목되기에 중요하다!자신을 정의할 때, 자기 자신을 재참조하는 것대표적은 재귀로는 팩토리얼과 피보나치가 있다. 자기 자신을 재참조하는 것이 어떤 의미인지 아래 코드를 통해 확인해보자.함수
6.[자료구조/ 알고리즘] 트리(Tree)
서로 연결된 Node의 계층형 자료구조로써, root와 부모-자식 관계의 subtree로 구성되어 있다.root에서 시작하여 여러 개의 tree가 중첩되는 형태로 만들어진다. 하나의 tree안에 여러 개의 subtree가 존재한다.정점(Vertex): A, B, C와
7.[자료구조/ 알고리즘] 그래프(Graph)
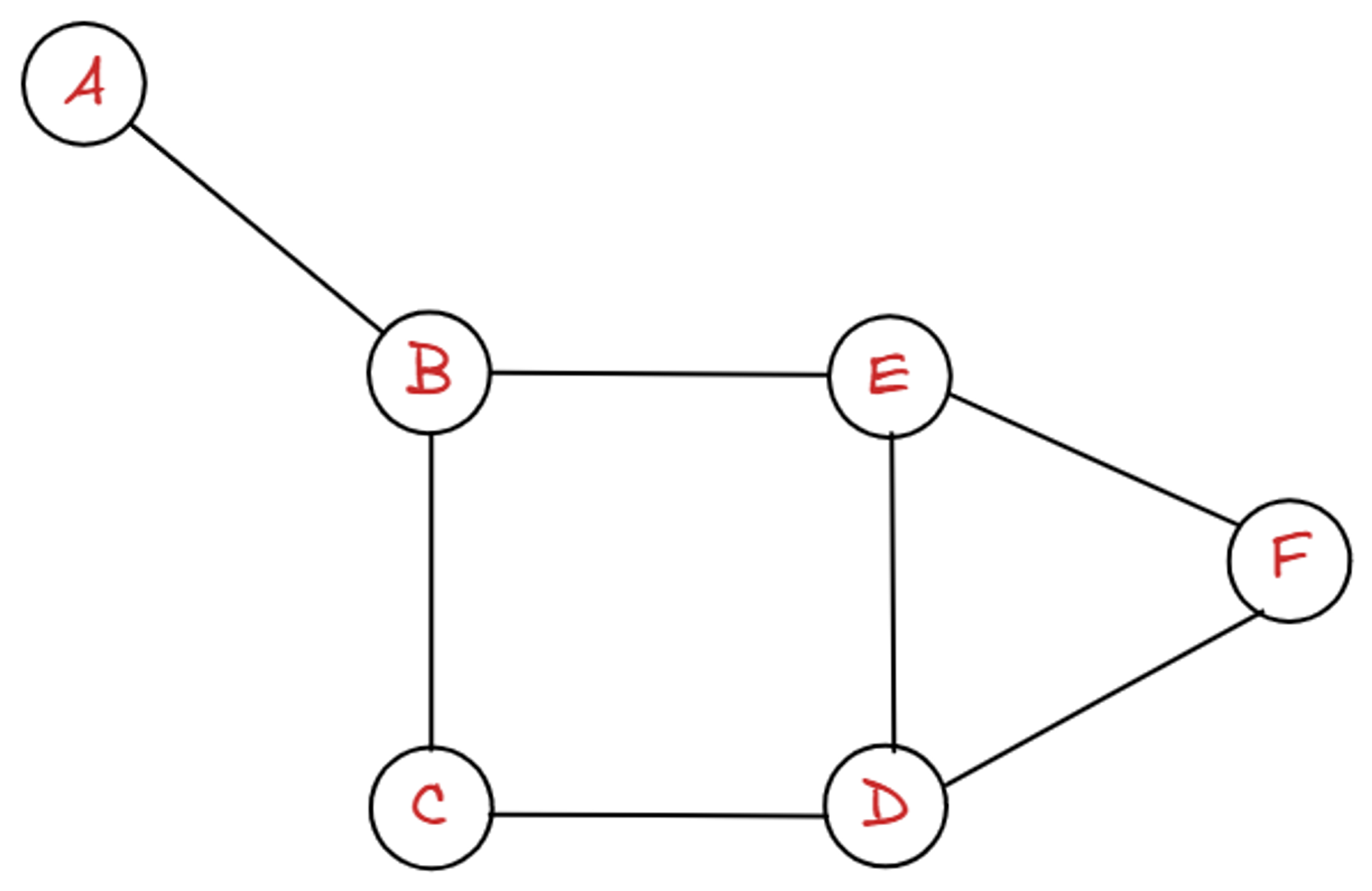
그래프(G)는 정점(vertex)들의 집합 V와 이들을 연결하는 간선(edge)들의 집합 E로 구성된 자료 구조이다.정점들의 집합 V = {A,B,C,D,E,F}, 서로 연결해주는 간선들의 집합 E = {(A,B),(B,C),(B,E),(C,D),(E,D),(E,F)
8.[자료구조/ 알고리즘] 동적 계획법(DP, Dynamic Programming)
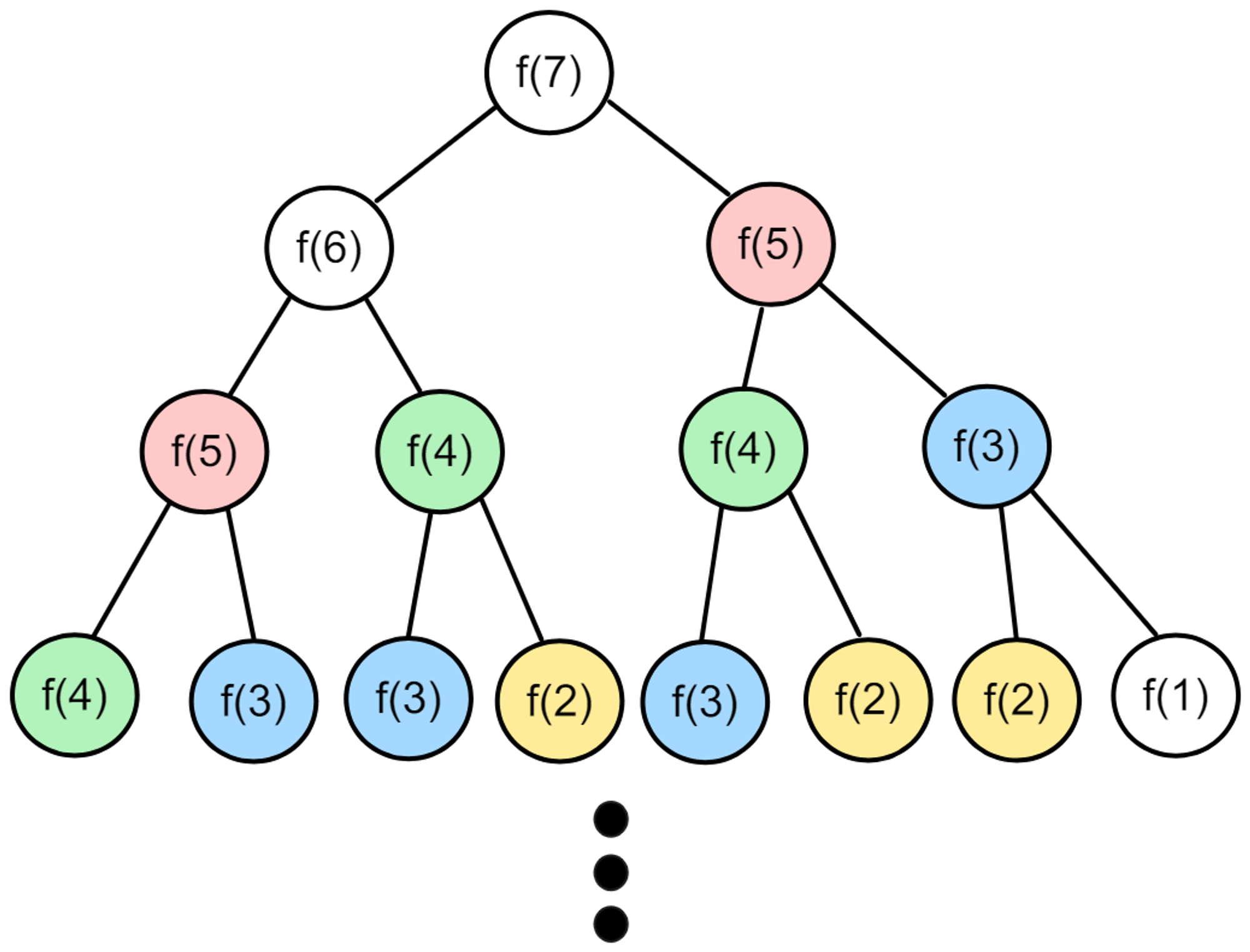
문제에 대한 정답이 될 가능성이 있는 모든 해결책을 체계적이고 효율적으로 탐색하는 풀이법이다모든 해결책을 다 탐색해보는 완전 탐색은 기본적으로 높은 시간 복잡도를 가진다. 이를 체계적이고 효율적으로 탐색하기 위해서는 몇 가지 조건이 있어야 한다.Overlapping S
9.[자료구조/ 알고리즘] 힙 (Heap - priority queue)

아래와 같은 queue가 있을 때, shift()를 하면 5 ➔ 3 ➔ 9 ㆍㆍㆍ ➔ 6 순으로 요소들이 나올 것 이다. 이 때 들어온 순서에 상관없이, 일정한 기준에 따라 요소들이 나오도록 할 수 있는데, 이것을 priority queue라고 한다.O(n)의 시간 복
10.[자료구조/ 알고리즘] 다익스트라(Dijkstra)
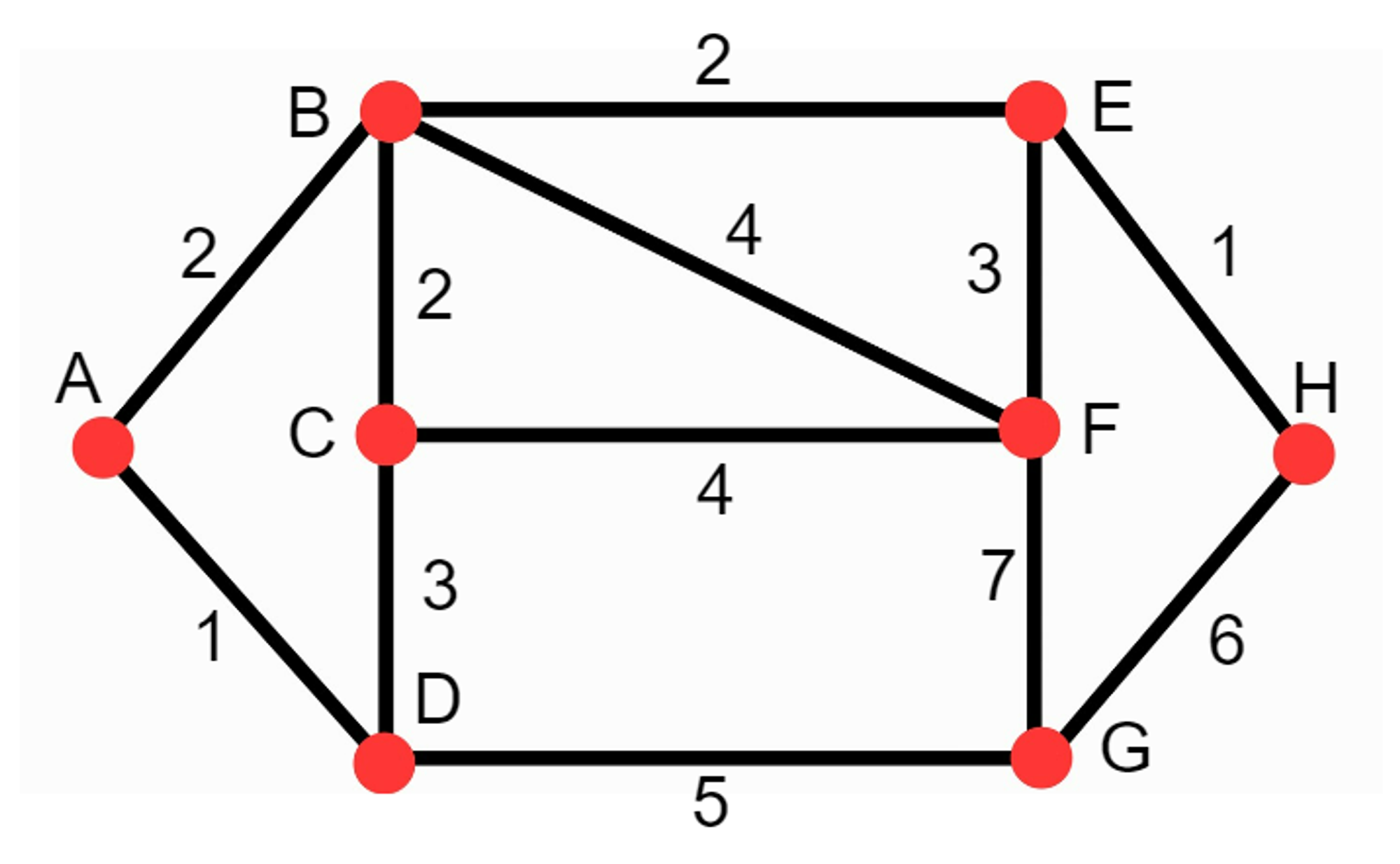
가중치 그래프에서 시작점과 도착점이 주어졌을 때, 최소 비용을 return하는 알고리즘이다.위 사진과 같은 가중치 그래프가 주어지고 시작점은 A, 도착점은 H라고 가정한다.1\. 각각의 점에 라벨을 매겨준다. 시작점의 라벨은 0으로 초기화하고 나머지 점들은 ∞로 초기화