
- 전체보기(20)
- hadoop(9)
- chess(6)
- data(4)
- python(4)
- chess opening(3)
- spark(3)
- hive(3)
- lichess(2)
- chess.com(2)
- MapReduce(2)
- data engineering(1)
- rdd(1)
- pyspark(1)
- Hadoop echo(1)
- Database(1)
- django(1)
- 데이터 엔지니어(1)
- lichess database(1)
- chess anlayze(1)
- HDFS(1)
- &&(1)
- Pig(1)
- Preprocessing(1)
- mysql(1)
PySpark RDD basic
Spark는 RDD를 사용하여 데이터를 처리합니다. RDD는 분산된 데이터 세트이며, Spark는 RDD를 사용하여 병렬로 작업을 수행할 수 있습니다.
Resilient Distributed Dataset (RDD)
Spark의 핵심은 Resilient Distributed Dataset (RDD) -> 복구 가능한 분산 데이터 셋다양한 데이터 세트를 추상화 한 것.RDD는 분산되고 변형하는 성질을 갖고 있어 여러 클러스터에 나눌 수 있고 개인 컴퓨터에서도 작동 가능. 클러스터의
Pig
Pig를 사용하면 더 쉽게 데이터를 처리할 수 있다.Hadoop과 MapReduce 위에 구축되었기 때문에 이를 통해 매퍼와 리듀서를 작성하지 않고 MapReduce 작업을 할 수 있다.Apache Pig-> 매퍼나 리듀서를 작성하지 않고 데이터를 빠르게 분석할 수 있
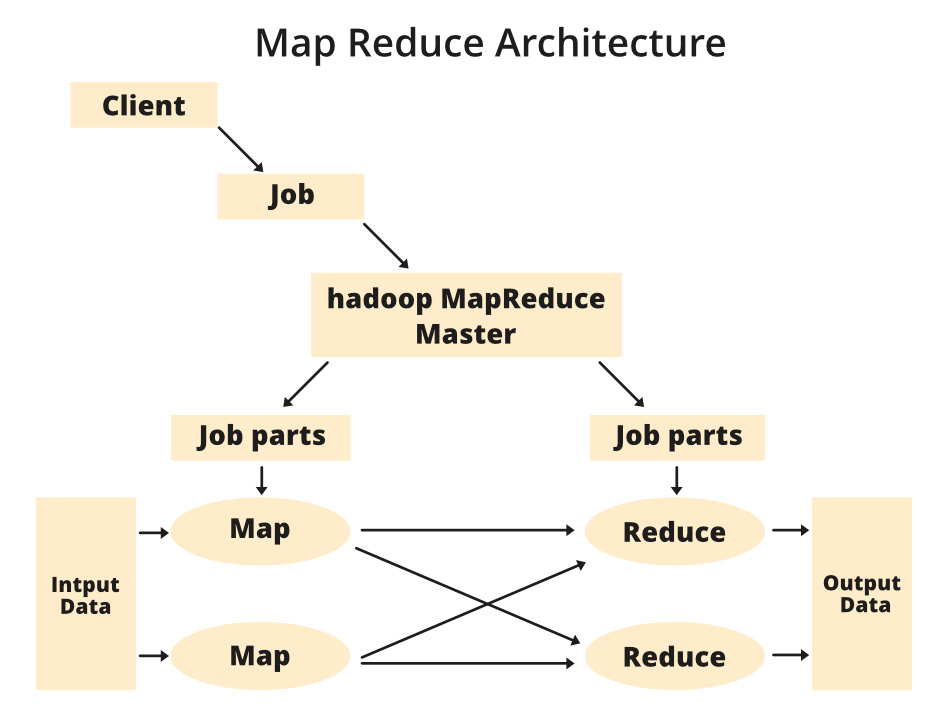
MapReduce 분산 처리 방법
매퍼가 키-값 쌍을 추출셔플과 정렬은 각 고유 키와 연관된 값을 구조화리듀서는 구조화된 정보를 전달받아 최종 출력물을 생산정말 큰 데이터 세트를 가진 클러스터를 운영하고 있다고 가정하면, 처리 과정을 여러 컴퓨터에 배분하거나 적어도 여러 작업(task)에 걸쳐 진행해야
MapReduce 정의 및 작동방식
MapReduce는 HDFS, YARN과 함께 제공되는 Hadoop의 핵심 기술.Hadoop에 내재된 기능이며 클러스터에 데이터의 처리를 분배.MapReduce는 데이터를 파티션으로 나눠서 클러스터에 걸쳐 병렬 처리되도록 한다매핑은 기본적으로 데이터를 변형시킨다즉 데이
django annotate에 filter 적용하기
lichess 분석 기능 따라잡기이전에 포스팅했던 새로운 방식으로 코드를 변경했다.orm이 기존에비해 많이 길어지긴 했지만, 속도측면이나 데이터베이스 용량측면에서 보다 나아졌다고 확신한다.django annotate를 사용할때 조건을 적용할 수 있다.
체스 프로젝트 구축 요구사항
나만의 체스 분석, 연습 프로젝트프로젝트를 진행하면서 생각나는대로 즉흥적으로 api설계를 하고 모델들을 정의하다보니 전반적으로 진행이 매끄럽지 않은듯한 느낌이 들었다.이미 진행했던 프로젝트를 리팩토링 하는 겸 요구사항을 명확하게 정의하여 보다 깔끔한 코드를 작성하기 위
django orm으로 lichess 분석 따라잡기
lichess database에서 추출한 74만개의 체스 기보 데이터를 가지고 lichess나 chess.com에서 제공하는 analze기능을 따라잡아보자체스는 전략과 계획이 필요한 대표적인 보드 게임. 체스에서 성공하기 위해서는 다양한 기술과 전략을 학습하고 연습해야
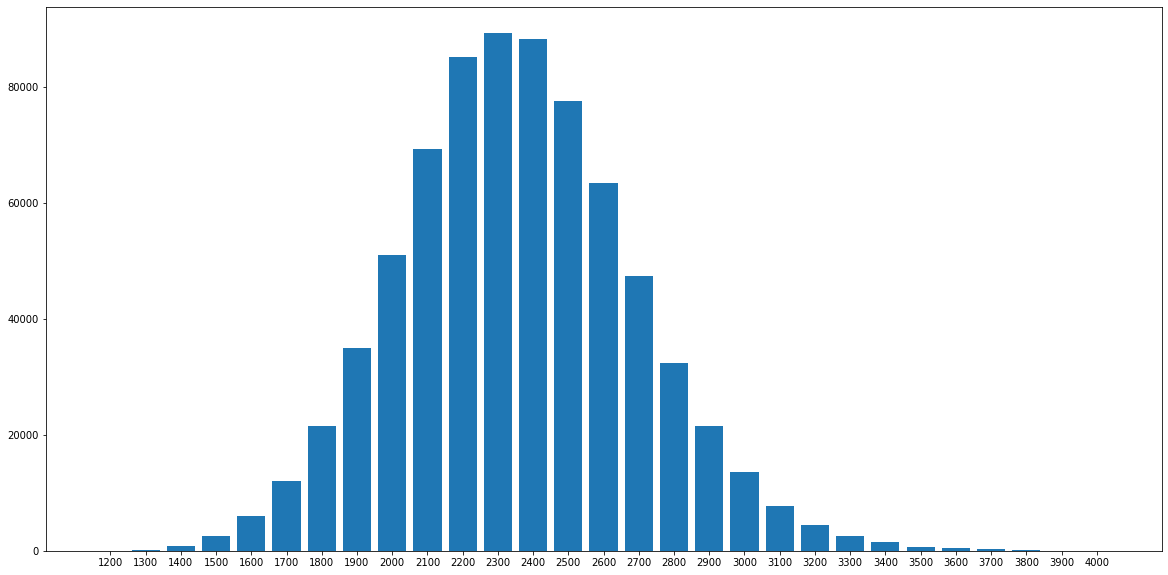
체스 레이팅 별 가장 높은 승률 오프닝
lichess database를 활용해서 각 레이팅별 가장 높은 승률의 오프닝, 가장 승률이 낮은 오프닝을 알아보자.lichess database 기준 대략 74만개의 게임을 분석.하위 레이팅 1200 ~ 1800, 중위 레이팅 1900 ~ 2400, 상위 레이팅 25
Chess Opening database Preprocessing
이전 포스팅에서는 lichess에서 제공한 체스 오프닝 데이터를 간단하게 전처리 했다. 이번엔 본격적으로 우리가 데이터베이스에 저장할 포맷으로 전처리를 진행한다.
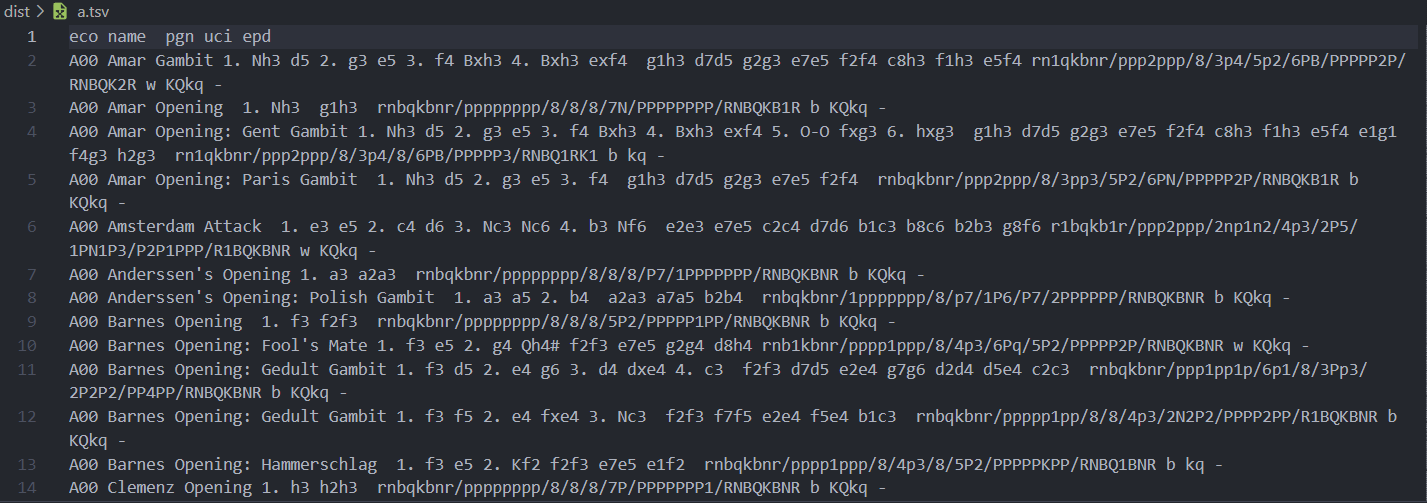
Chess Opening database 구축
이번 프로젝트의 구성은 Stockfish를 활용하여 Chess engine과의 대결을 할 수 있는 사이트와, chess 기보를 읽어들이는 data pipeline, 그 데이터를 저장하는 data warehouse를 구성하는 것이 목표.평소 체스와 바둑 장기 등 여러 보
HDFS 작동방식
빅데이터를 전체 클러스터에 분산해 안정적으로 저장하여 애플리케이션이 그 데이터를 신속하게 액세스해 분석할 수 있게함.HDFS는 대용량 파일들을 다루기 위해 만들어짐.대용량 파일들을 작은 조각으로 나누어 클러스터 전체에 걸쳐 분산시키는데 최적화되어있다. \- 대용량 파
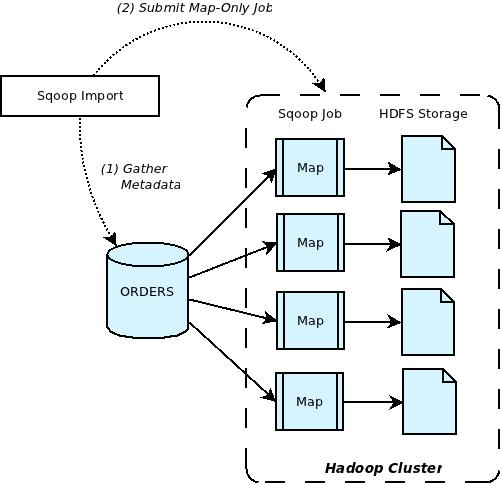
MYSQL Hadoop 통합하기
Hive는 Hadoop 클러스터를 관계형 데이터베이스처럼 사용하지만 실제로 데이터베이스를 갖는 것은 아니었다. 그러나 만약 MySQL과 같은 진짜 관계형 데이터베이스를 갖고 있고 Hadoop 클러스터에 데이터를 불러오거나 내보내고 싶을 수도 있을 때 Sqoop을 활용하

HIVE 작동방식
관계형 데이터베이스에서는 Schema on Write 개념을 사용한다. \- 데이터베이스에 데이터를 입력하기전에 스키마를 정의.데이터를 디스크에 저장할 때 이 스키마대로 시행.Hive는 구조화되지 않은 데이터를 가져와서 읽는 순간에 스키마를 적용한다. \- ex)

Hive
Hive 기술을 통해 hadoop 클러스터를 관계형 데이터베이스처럼 사용할 수 있다.SQL을 사용해 Hadoop 클러스터에 걸쳐있는 데이터를 쿼리하는 간단하고 강력한 도구.(구조화된 쿼리 언어)HDFS 클러스터 전체에 걸쳐 저장된 데이터에 표준 SQL 쿼리를 실행. \
Hadoop 주요 구성 요소(3)
Zookeeper는 클러스터의 모든 것을 조직화하는 기술.어떤 노드가 살아있는지 추적할 수 있고 여러 애플리케이션이 사용하는 클러스터의 공유 상태를 안정적으로 확인할 수 있다.많은 애플리케이션이 Zookeeper에 의존. \- 그래서 어떤 노드가 다운되더라도 일관성
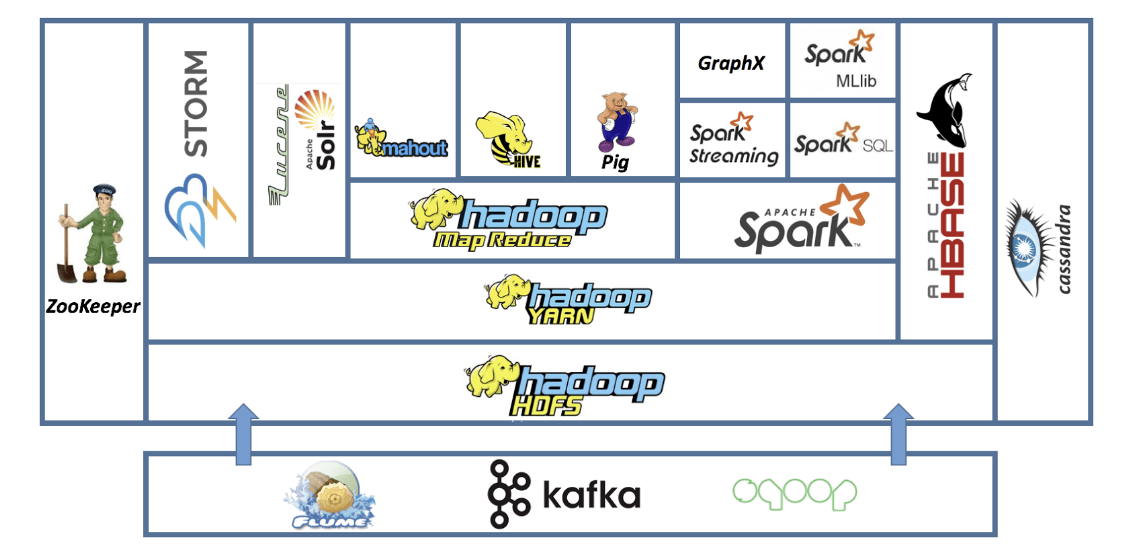
Hadoop 주요 구성 요소(2)
클러스터의 리소스를 관리하는 또 하나의 방법.YARN과 협업이 가능하다.Hadoop 생태계에서 가장 흥미로운 기술.Spark는 YARN이나 Mesos중 어느 쪽을 기반으로 하든 데이터에 쿼리를 실행할 수 있음.Pyhon, Java, Scala를 사용해 스크립트를 작성.
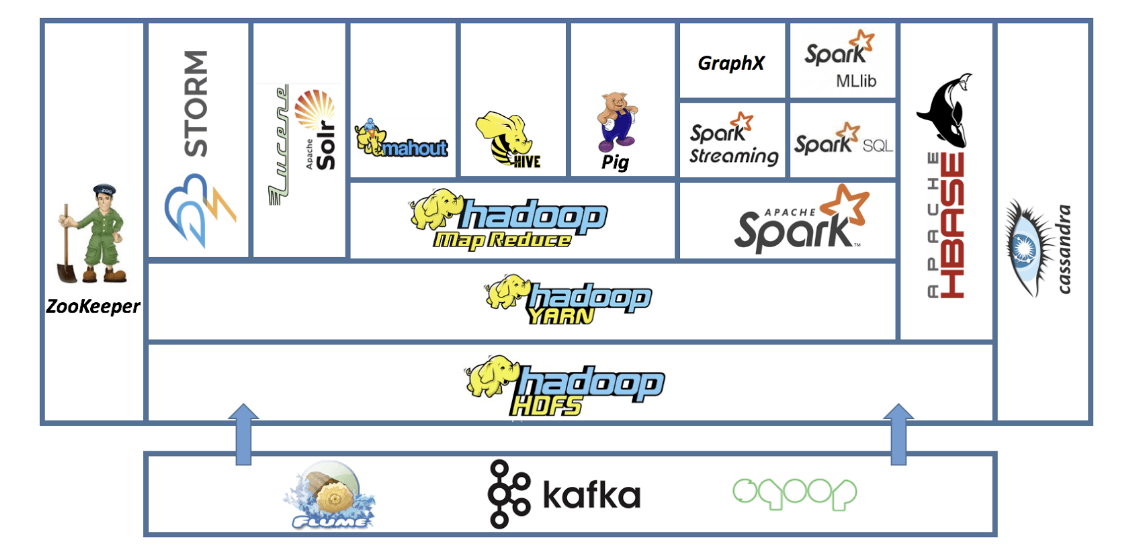
Hadoop 주요 구성 요소
https://www.softwaretestingclass.com/introduction-to-hadoop-architecture-and-components/Hadoop 분산 파일 시스템빅데이터를 클러스터의 컴퓨터들에 분산 저장하는 시스템.데이터의 여분 복사본
Hadoop 생태계 이해하기
Hadoop 플랫폼의 주요 벤더인 Hortonworks는 하둡을 이렇게 정의.범용 하드웨어로 구축된 컴퓨터 클러스터의 아주 방대한 데이터 세트틀 분산해 저장하고 처리하는 오픈 소스 소프트웨어 플랫폼오픈 소스 한대의 PC가 아닌 컴퓨터 클러스터에서 작동하는 소프트웨어 묶