Database
1.Interleaving 인터리빙

문제DB 인터리빙(Interleaving)에 대해 설명하시오.답변0\. 질문에 대한 답변DB 인터리빙(Interleaving)이란 다중 트랜잭션 환경에서 동시에 여러 트랜잭션의 연산들이 일정한 규칙에 따라 교차되어 실행되는 방식으로, 데이터베이스의 일관성(Consist
2.Transaction
문제트랜잭션(Transaction)에 대해 설명하시오.답변 0\. 질문에 대한 답변트랜잭션(Transaction)은 데이터베이스에서 하나의 논리적인 작업 단위를 의미하며, 데이터의 무결성과 일관성을 보장하기 위해 ACID 특성을 만족해야 한다.1\. 개념 & 핵심
3.동시성 제어 Concurrency control
문제동시성 제어 기법(Concurrency Control Technique)에 대해 설명하시오.답변 0\. 질문에 대한 답변동시성 제어 기법은 여러 트랜잭션이 동시에 데이터베이스를 조작할 때 발생할 수 있는 충돌을 방지하고, 데이터의 일관성과 무결성을 보장하기 위한
4.DB Locking
DB Locking은 데이터베이스에서 동시성 제어를 위해 사용하는 메커니즘이다.여러 트랜잭션이 동시에 같은 데이터에 접근할 때 데이터 무결성과 일관성을 보장한다.트랜잭션이 데이터에 접근할 때 Lock을 획득한다.트랜잭션이 완료(COMMIT)되거나 롤백(ROLLBACK)
5.db lock expand shrink
락(Lock) 경합 상황을 다루는 방법 중 하나야.DBMS가 락을 "얻는 과정"과 "풀어주는 과정"을 순서대로 안전하게 관리하려고 나눈 단계야.중요 포인트: 확장할 때는 락을 추가만 하고 해제는 안 함. 축소할 때는 락을 해제만 하고 추가는 안 함.즉, 락을 잡을
6.투 페이즈 커밋(Two-Phase Commit, 2PC)
투 페이즈 커밋(2PC)은 분산 환경에서 원자성(Atomicity)을 보장하기 위해 사용되는 분산 트랜잭션 프로토콜입니다. 여러 데이터베이스 노드(또는 자원 관리자)가 하나의 트랜잭션에 참여할 경우, 모든 노드가 정합성 있는 상태로 Commit 혹은 Rollback할
7.비동기 보상 트랜잭션(Asynchronous Compensation Transaction)
비동기 보상 트랜잭션(Asynchronous Compensation Transaction)은 하나의 트랜잭션을 여러 단계로 나누어 실행하고, 실패 시에는 각 단계를 되돌리는 보상 작업(Undo가 아닌 Compensation Action)을 수행하여 전체적인 정합성을 유
8.SAGA 패턴
SAGA 패턴은 분산 시스템에서 원자성을 보장하기 위한 트랜잭션 관리 방식입니다. 전통적인 2PC(투 페이즈 커밋)은 동기적이며 중앙 집중적인 방식인데 반해, SAGA는 트랜잭션을 작은 여러 개의 로컬 트랜잭션(local transaction)으로 분할하고, 실패 시
9.DB 설계 및 모델링
1\. 개요정보시스템 구축 시 데이터의 정합성과 일관성 유지, 효율적인 데이터 처리를 위해 체계적인 데이터베이스 설계 및 데이터 모델링은 필수적인 과정이다. 데이터 모델링은 요구사항 분석을 바탕으로 현실 세계의 데이터를 구조화하여 표현하는 작업이며, 데이터베이스 설계는
10.data modeling
문제 데이터 모델링의 종류와 단계별 작업에 대하여 설명하시오.답서론정보시스템의 품질은 데이터의 구조적 안정성과 무결성에 크게 의존하며, 이는 곧 효과적인 데이터 모델링에 의해 좌우된다. 데이터 모델링은 사용자의 요구사항을 기반으로 데이터 구조를 체계화하고, 이를 통해
11.NoSQL, 공간 데이터베이스, 비정형 데이터베이스, 벡터 데이터베이스
현대 데이터 환경은 정형 데이터를 넘어서 반정형, 비정형, 고차원 데이터로 확장되고 있다. 이러한 데이터는 기존 관계형 DBMS로는 저장·검색·분석에 한계가 있으며, 이를 해결하기 위해 등장한 기술이 NoSQL, 공간 데이터베이스, 비정형 DB, 벡터 DB이다. 본 문
12.BOM, Arc, Recursive relationship
BOM(Bill of Materials, 자재명세서)은 최종 제품이 어떤 부품들로 구성되어 있는지를 계층적으로 표현하는 구조입니다. BOM 관계는 이런 구성 요소 간의 관계를 계층적 Parent-Child 형태로 모델링합니다.Parent (상위 항목): 제품 또는 조립
13.개념 데이터 모델링 Conceptual Data Modeling
\*\*개념 데이터 모델링(Conceptual Data Modeling)\*\*이란,“사용자의 비즈니스 요구사항을 바탕으로 데이터의 주요 개체(엔터티), 속성, 관계를 추상적으로 정의하여 정보의 구조를 표현하는 활동”입니다.이는 데이터베이스 설계의 가장 초기 단계로,
14.논리 데이터 모델링(Logical Data Modeling)
논리 데이터 모델링(Logical Data Modeling)은 데이터베이스 설계의 핵심 단계 중 하나로, 업무의 요구사항을 바탕으로 데이터 간의 관계, 구조, 제약조건 등을 논리적으로 정의하는 과정입니다. 이는 물리적인 저장 구조와는 분리되어 있으며, 비즈니스 관점에서
15.기출 개념적 논리적 ERD 로 요구사항을 구조화 하시노
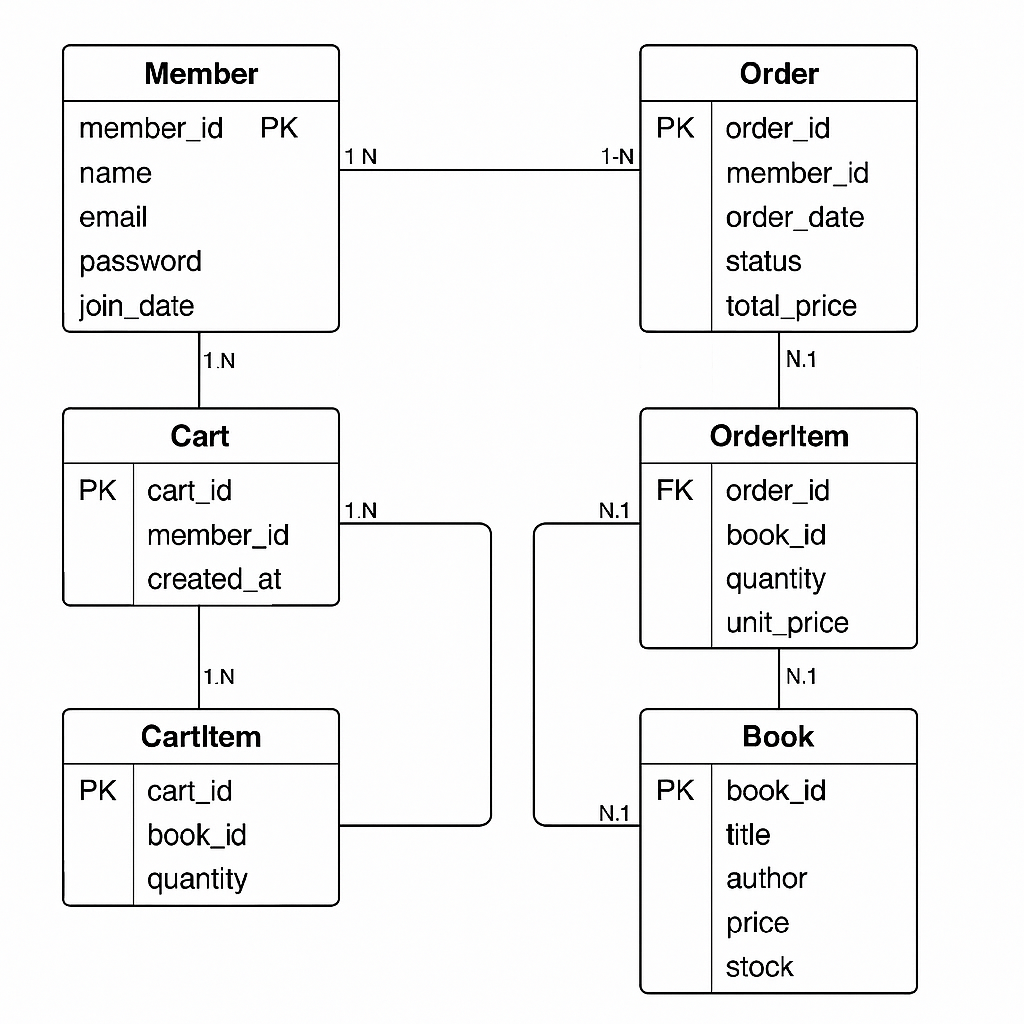
사용자는 웹사이트를 통해 도서를 검색, 장바구니에 담고 구매판매자는 도서를 등록하고 재고를 관리관리자는 회원과 주문 내역을 관리목적: 비즈니스 요구사항을 반영한 고수준 모델특징: 주체(Entity), 관계(Relationship), 속성(Attribute) 위주로 표현
16.정규화 1~3 Normalization
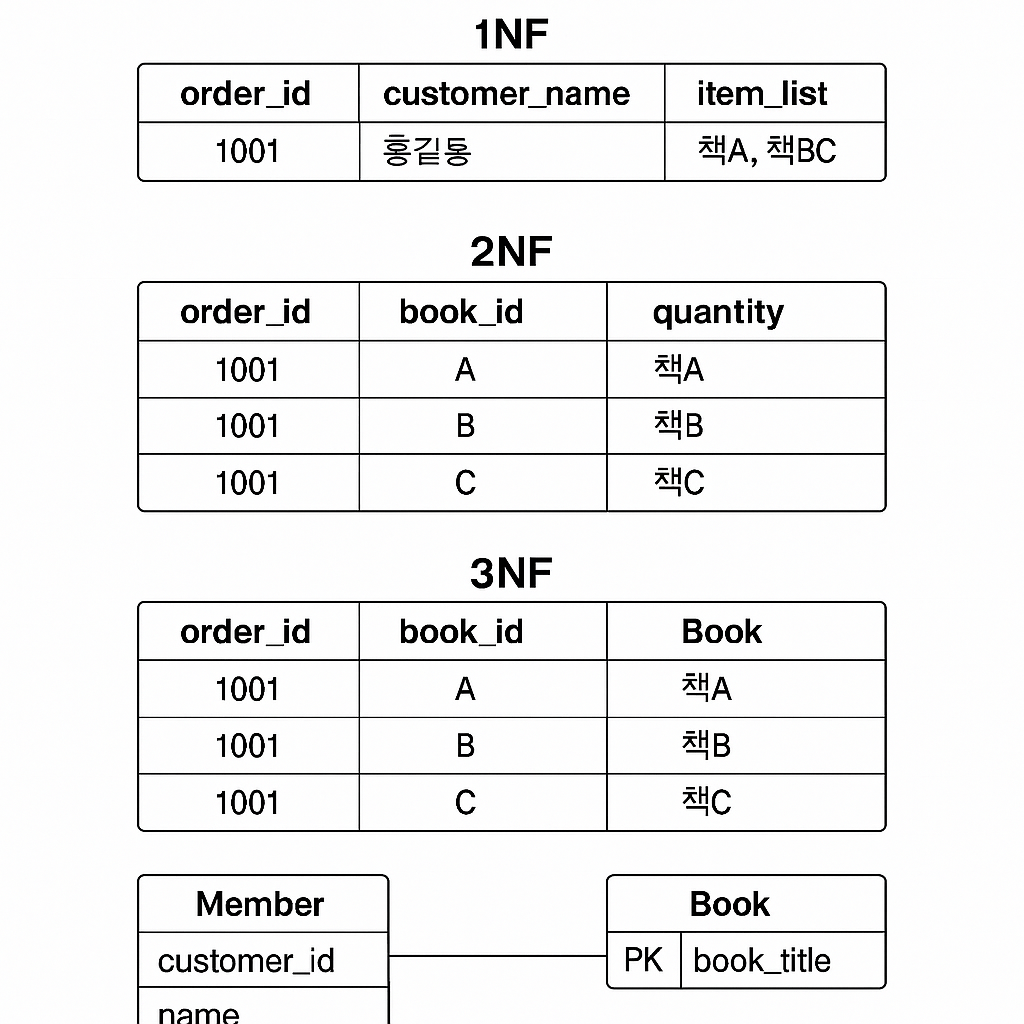
2정규형(2NF)과 3정규형(3NF)은 릴레이션 모델에서 데이터 중복 제거와 데이터 무결성 유지를 위한 핵심 정규화 단계입니다. 기술사 관점에서는 정의, 적용 조건, 예시, 효과까지 구조적으로 정리해야 합니다.속성의 원자성(Atomicity) 만족:하나의 필드는 하나의
17.물리 데이터 모델링 Physical data modeling
물리 데이터 모델링(Physical Data Modeling)은 논리 데이터 모델을 바탕으로 DBMS에 실제 구현 가능한 구조로 변환하는 과정입니다.기술사 수준에서는 성능, 저장 효율, 인덱싱, 파티셔닝, 보안 등을 고려한 현실적이고 최적화된 구조 설계가 핵심입니다.논
18.ARC 관계 Alternative Relationship Constraint
DB의 ARC 관계는 주로 개체(Entity) 간의 관계(Relationship) 를 설명할 때 사용되는 개념 중 하나로, 데이터베이스 설계(특히 E-R 다이어그램)에서 다음과 같은 맥락으로 사용됩니다. ARC는 “Alternative Relationship Const
19.업무규칙, 제약조건
조직의 업무 처리 방식, 규정, 정책을 정보 시스템에서 구현 가능하도록 정형화한 비즈니스 로직입니다.비즈니스 측면에서의 규칙으로, 데이터의 생성, 처리, 흐름, 변경 조건 등을 정의합니다.주로 요구사항 분석 단계에서 도출되며, 시스템의 행위를 제어합니다.예: 고객은 한
20.db index
인덱스(Index) 는 데이터베이스 테이블에서 데이터 검색 속도를 향상시키기 위한 보조적인 데이터 구조입니다.일반적으로 책의 목차나 색인처럼, 원하는 정보를 빠르게 찾기 위해 사용됩니다.목적: 빠른 검색, 정렬, JOIN 성능 향상단점: 저장 공간 증가, 쓰기(INSE
21.기출 foreign key
\*\*외래키(Foreign Key)\*\*는 한 테이블에서 다른 테이블의 기본키(Primary Key)를 참조하는 컬럼입니다. 외래키는 데이터베이스에서 테이블 간의 관계를 설정하는 중요한 요소로, 데이터의 무결성을 유지하는 데 사용됩니다.외래키의 주요 목적은 관계형
22.ER Model 유도, 복합 속성
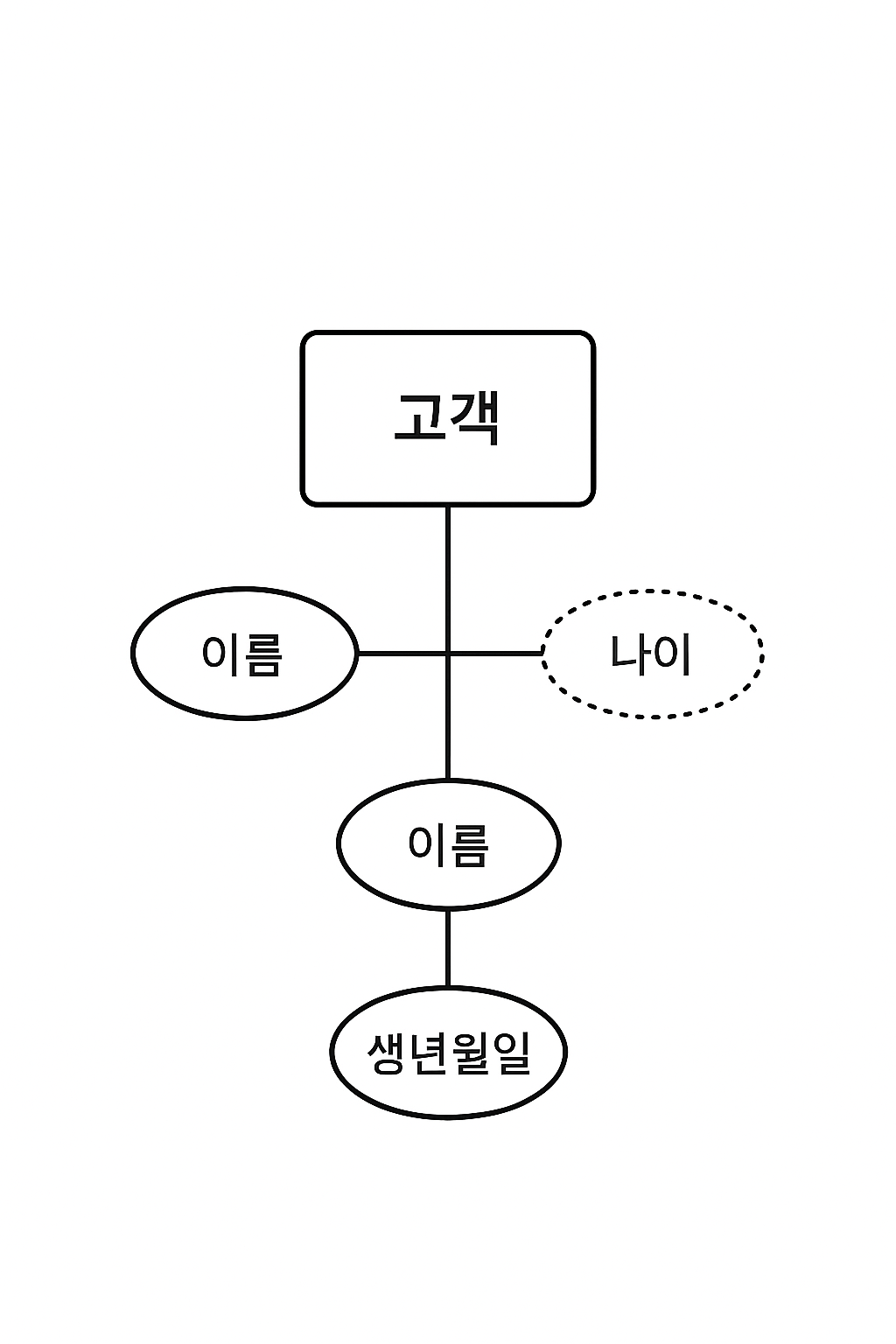
ER 모델(Entity-Relationship Model)에서 \*\*유도 속성(Derived Attribute)\*\*과 \*\*복합 속성(Composite Attribute)\*\*은 속성(Attribute)의 세부 분류에 해당합니다. 개체(Entity)나 관계(R
23.카디널리티(Cardinality)
\*\*카디널리티(Cardinality)\*\*는 상황에 따라 약간 다른 의미로 사용되지만, 공통적으로 "어떤 대상의 개수" 또는 \*\*"몇 번 연결되거나 발생하는가"\*\*를 나타내는 개념입니다.ER(Entity-Relationship) 모델에서 카디널리티는 \*\
24.ER Model Unary, Binary, Ternary 관계
ER 모델에서 \*\*관계(Relationship)\*\*는 개체(Entity)들 간의 연관성을 표현합니다. 이 관계는 참여하는 개체의 수에 따라 단항(Unary), 이항(Binary), 삼항(Ternary) 관계로 나뉩니다. 각 관계 유형은 데이터 모델링에서 구조와
25.기출 ERD 첸표기법
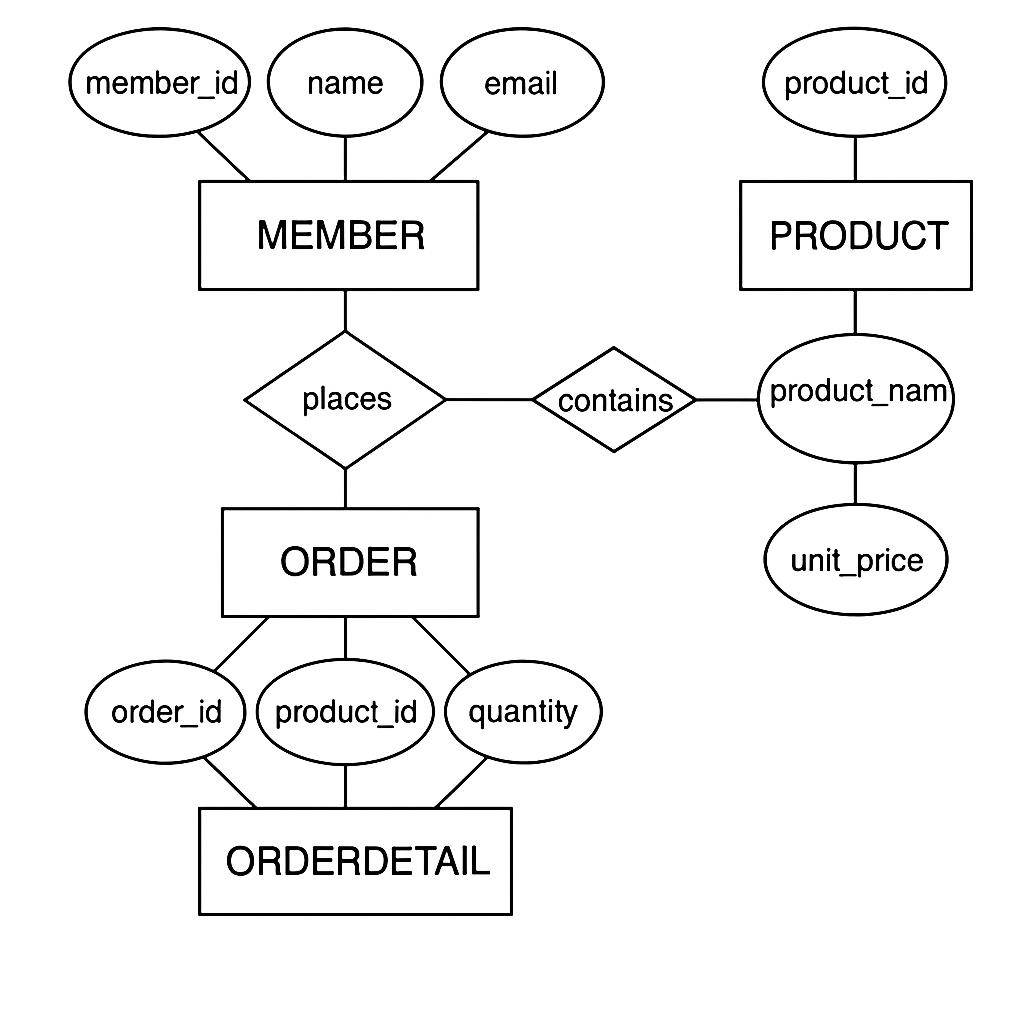
개념적 ERD는 업무 개념 중심의 단순한 구조로, 엔터티 간 관계를 식별하는 수준입니다.회원(Member): 회원ID, 이름, 이메일 등주문(Order): 주문ID, 주문일, 총금액제품(Product): 제품ID, 제품명, 단가회원은 주문을 한다 (1\\:N)→ 한 명
26.기출 반정규화 Denormalization
반정규화(Denormalization)는 정규화된 데이터 모델에서 성능 향상을 목적으로 의도적으로 중복을 허용하거나 정규화 수준을 낮추는 과정입니다. 즉, 정규화로 인해 생긴 성능 저하 문제를 해결하기 위해 데이터 구조를 다시 조정하는 것입니다.반정규화는 데이터 무결성
27.조인 join operation
조인
28.옵티마이저(Optimizer), 실행 계획(Execution Plan)
옵티마이저는 SQL 질의를 가장 빠르고 효율적으로 실행하기 위한 최적의 실행 계획을 선택하는 DBMS의 핵심 컴포넌트입니다.사용자가 작성한 SQL은 논리적 질의일 뿐이며,DBMS는 이를 실제 물리적 연산으로 변환해 실행해야 합니다.이 과정에서 여러 가능한 실행 계획 중
29.ORM
ORM은 객체지향 언어의 객체와 관계형 데이터베이스(RDBMS)의 테이블을 자동으로 매핑해주는 기술입니다.즉, 개발자가 SQL을 직접 작성하지 않고도 객체 조작만으로 DB 연동이 가능하게 해줍니다.단위: 클래스와 객체구성: 속성(필드) + 메서드(행위)관계: 참조 기반
30.기출 ORM 필요성과 원리
ORM(Object-Relational Mapping)이란,객체지향 프로그래밍의 객체와 관계형 데이터베이스(RDBMS)의 테이블 간의 구조적/행위적 차이를 자동으로 연결(Mapping)해주는 기술이다.TypeScript에서는 클래스 또는 모델을 통해 객체를 정의하고,R
31.JDBC
JDBC(Java Database Connectivity)는 Java 언어 기반의 데이터베이스 연동을 위한 표준 인터페이스 API로, Java 프로그램이 다양한 관계형 데이터베이스(RDBMS)와 독립적으로 통신할 수 있도록 중간 계층 역할을 수행한다. JDBC는 ANS
32.ODBC
ODBC는 Microsoft 주도로 개발된 범용 데이터베이스 접속 API 표준으로, C 기반의 API 집합을 제공하여 애플리케이션이 다양한 관계형 데이터베이스(RDBMS)와 독립적으로 통신할 수 있도록 한다. ODBC는 데이터 소스의 물리적 구조나 벤더의 특수성으로부터
33.CDP(Continuous Data Protection)
CDP(Continuous Data Protection)는 기존의 백업 개념을 넘어선 지속적이고 실시간에 가까운 데이터 보호 기술로, 시스템 장애 및 사이버 위협에 대응하기 위한 핵심 전략 중 하나입니다. 기술사 수준에서는 CDP의 원리, 복구 절차와 아키텍처, 타 백
34.DB DR
데이터베이스 복구는 시스템 장애, 트랜잭션 오류, 저장소 손상 등으로부터 데이터의 일관성과 무결성을 회복하는 절차를 의미합니다.정상적인 상태로 복원하여 서비스 연속성을 확보하는 것이 궁극적 목적입니다.트랜잭션은 모두 완료되거나 전혀 실행되지 않아야 함실패한 트랜잭션은
35.기출 하드웨어 가상화 파티셔닝 및 VTL
1. 하드웨어 가상화 파티셔닝 (Hardware Virtualized Partitioning) 1.1. 정의 > (기존 내용과 동일) 1.2. 구현 방식 > (기존 내용과 동일) 1.3. 주요 효과 및 장점 > (기존 내용과 동일) 1.4. 제약 및 단점
36.기출 DB deduplication
\*\*데이터 중복(duplication)\*\*은 데이터베이스 내에 동일하거나 유사한 데이터가 반복 저장되어 저장 공간 낭비, 데이터 정합성 저하, 성능 저하 등을 유발하는 문제입니다.De-duplication은 이러한 중복 데이터를 식별하고 제거하거나 통합하여 데이
37.데이터 정합성 (무결성) Integrity
데이터 정합성은 저장된 데이터가 예상된 규칙, 형식, 관계를 일관되게 따르며, 원래의 의미와 목적을 정확히 유지하고 있는 상태입니다.이는 데이터의 정확성, 일관성, 유효성, 신뢰성을 포함합니다.PK, FK, UNIQUE, NOT NULL, CHECKDBMS 수준에서 강
38.데이터 백업 변천사
초기에는 주로 \*\*물리 테이프 장치(DLT, LTO)\*\*를 사용.데이터베이스(DB) 서버에서 직접 백업 수행 → 오프라인 작업 필수백업 윈도우(업무 외 시간에 백업) 필요전체 백업(Full Backup) 위주복구 속도 느림 (복구 시 전체 테이프 순차 탐색)보관
39.db join
외부 테이블의 각 튜플마다 내부 테이블을 스캔하여 조건에 맞는 튜플을 찾는 방식.두 테이블 간의 이중 루프 구조로 작동:가장 단순하고 범용적인 조인 방식.인덱스가 있을 경우 효율적 (특히 소규모 + 인덱스 기반 접근).테이블 간의 조인 조건이 복잡하거나 인덱스를 사용할
40.데이터베이스 성능 개선 프로세스
서비스 수준 목표(SLO/SLI) 설정: 트랜잭션 응답시간, TPS, 동시 접속자 수 등.업무 특성 기반 관리 기준 수립: OLTP/OLAP/Hybrid 등 업무 성격에 따라 성능 기준을 차별화.정책 기반 성능 관리 체계 수립: 예방 중심 관리(Predictive Mo
41.db hash collision
해시 테이블에서 해시 함수로 계산된 값을 저장하는 저장소 단위입니다.각 버킷은 하나의 키-값 쌍을 저장할 수도 있고, \*\*여러 개의 데이터를 저장하는 공간(리스트, 포인터 등)\*\*이 될 수도 있습니다.예를 들어, 해시(key) % N = 3이면 3번 버킷에 저장
42.db hash
해시는 \*\*키(key)를 해시 함수(Hash Function)에 통과시켜 계산된 주소(버킷)\*\*에 데이터를 저장하는 방식.해시 기반 저장 구조는 일반적으로 \*\*빠른 단일 레코드 접근(=Point Access)\*\*에 최적화됨.주로 Heap, B-Tree 등
43.db b-tree b+tree
B-Tree는 균형 이진트리를 일반화한 \*\*다진 균형 검색 트리(M-ary Balanced Search Tree)\*\*이다.모든 리프 노드는 동일한 깊이를 가지며, 트리의 높이를 최소화하여 디스크 접근 횟수를 줄인다.노드 하나에 여러 개의 키와 자식 포인터를 저장
44.t-tree, r-tree, index
In-memory DBMS에서 주로 사용되는 트리 구조.AVL 트리와 B-트리의 장점을 절충하여 만든 자료구조.메모리 기반 환경에서 성능 최적화를 위해 고안됨.노드는 정렬된 key들의 배열을 포함.노드마다 최소/최대 key, 자식 포인터, 부모 포인터 존재.균형 이진
45.db ETL
ETL은 데이터베이스(DB)나 데이터 웨어하우스에서 자주 사용하는 데이터 처리 작업으로, 다음 세 가지 단계로 구성E (Extract, 추출)여러 출처(예: 다른 DB, API, 엑셀 파일 등)에서 데이터를 가져오는 단계예요.T (Transform, 변환)추출한 데이터
46.데이터 품질관리 DQM
디지털 전환 가속화에 따라 데이터 기반 의사결정의 중요성이 증가데이터 오류, 불일치, 중복 등의 문제로 업무 비효율 및 신뢰성 저하 발생정확성, 완전성, 일관성, 유효성, 중복성, 적시성 확보를 통해 데이터 품질을 체계적으로 관리하고자 함주요 데이터 도메인(고객, 상품
47.데이터 품질관리 프레임워크
데이터 품질관리 프레임워크(Data Quality Management Framework)는 조직이 데이터를 체계적으로 관리하고, 신뢰할 수 있는 고품질 데이터를 확보하여 비즈니스 의사결정에 활용할 수 있도록 설계된 구조와 절차를 말합니다. 이 프레임워크는 일반적으로 다
48.data architecture
데이터 아키텍처(Data Architecture)는 정보 시스템에서 데이터를 효과적으로 수집, 저장, 관리, 사용하기 위한 원칙, 표준, 모델, 정책, 기술적 구조를 정의하고 설계하는 체계적인 접근 방법입니다. 기술사 수준에서는 단순한 정의를 넘어 데이터 아키텍처의 구
49.data profiling, cleansing
데이터 프로파일링은 데이터 집합에 대한 통계적, 구조적, 내용적 분석을 통해 데이터의 특성, 품질 상태, 이상값 등을 파악하는 과정입니다.데이터 품질 평가데이터 정제 전 사전 분석통합 및 마이그레이션 설계 기반 마련컬럼 프로파일링: NULL 값, 유일값, 최소/최대/평
50.기출 BI 에서 data mining, text mining 비교
BI에서 Data Mining과 Text Mining을 비교 설명하시오.BI(Business Intelligence, 비즈니스 인텔리전스)는 조직의 의사결정을 지원하기 위해 내부 및 외부 데이터를 수집·통합·분석하여 인사이트를 제공하는 기술 및 시스템을 의미한다.최근
51.기출 web mining
Web Mining에 대하여 설명하시오.인터넷의 발전과 함께 기업 및 기관은 웹을 통해 방대한 양의 데이터를 생성·축적하고 있다.웹 페이지, 로그 데이터, 사용자 행동 정보, 소셜 미디어 등에서 파생되는 이러한 데이터는 정형, 반정형, 비정형의 복합 형태를 띠며,이로부
52.OLTP ACID
OLTP 시스템에서 데이터 일관성과 무결성을 보장하기 위해 ACID 특성이 필요한 이유와 그 개념을 설명하라.OLTP 시스템에서의 트랜잭션은 \*\*ACID 특성 (Atomicity, Consistency, Isolation, Durability)\*\*을 만족해야 데
53.기출 distributed system transparancy
분산 시스템에서는 사용자가 시스템이 분산되어 있다는 사실을 인식하지 못하도록 해야 한다. 이를 위해 여러 형태의 \*\*“투명성 (Transparency)”\*\*이 필요하다. 각 투명성의 개념과 역할을 설명하라.분산 시스템은 여러 대의 컴퓨터가 하나처럼 동작하게 해야
54.기출 전국단위 금융 분산시스템 레퍼런스 구조 자문
\*\*전국 단위 금융 분산 시스템을 구축하려는 은행이 분산 데이터베이스(Distributed Database)의 참조 구조(Reference Architecture 또는 Reference Model)\*\*에 대해 자문을 요청한 상황입니다
55.기출 DBMS 변천과정
문제: 63회 응용DBMS의 변천과정과 RDBMS, ORDBMS 및 OODBMS를 비교 설명하시오.개념: 응용 프로그램이 직접 파일을 제어함구조: 데이터와 프로그램이 밀접하게 연결되어 있음 (Tightly Coupled)문제점: 데이터 중복, 일관성 부족, 보안 취약,
56.분산 데이터베이스
분산데이터베이스(Distributed Database)의 개념과 특징, 구조 및 핵심 기술에 대하여 설명하시오.분산데이터베이스(Distributed Database, DDB)는 지리적으로 분산된 여러 컴퓨터 시스템에 저장되고 관리되는 데이터베이스로, 네트워크를 통해 연
57.기출 disk DB vs MMDB
문제: 메인 메모리 데이터베이스 관리 시스템(Main Memory Database Management System, MMDBMS)을 디스크 기반 DBMS와 비교하여 설명하시오. (25점)정의: 데이터를 디스크가 아닌 \*\*주기억장치(Main Memory, RAM)\*
58.기출 임베디드 데이터베이스(Embedded Database)와 실시간 데이터베이스(Real-time Database)
문제 임베디드 데이터베이스(Embedded Database)와 실시간 데이터베이스(Real-time Database)의 개념 및 특징을 비교하고, 각각의 적용 사례에 대해 설명하시오. (25점) 1. 개념(Concept) 1) 임베디드 데이터베이스 (Embedded Database) 정의: 애플리케이션에 내장(Embedded) 되어 동작하는 경량 ...
59.CAP 이론
CAP 이론에 대해 설명하시오.\*\*CAP 이론(CAP Theorem)\*\*은 \*\*분산 컴퓨터 시스템(Distributed Computing System)\*\*에서 동시에는 일관성(Consistency), 가용성(Availability), 파티션 허용성(Par
60.mobile DB, SQLite
모바일 데이터베이스와 SQLite에 대해 설명하시오.모바일 데이터베이스는 모바일 디바이스(스마트폰, 태블릿 등) 상에서 동작하는 \*\*경량화된 데이터베이스 시스템(DBMS: Database Management System)\*\*으로, 무선 네트워크 환경에서도 데이터
61.SQLite
SQLite에 대하여 설명하시오.SQLite는 경량 관계형 데이터베이스 관리 시스템 (RDBMS, Relational Database Management System) 으로, 서버 없이 파일 기반으로 데이터베이스를 관리할 수 있는 임베디드(Embedded) DBMS이다
62.기출 모바일 환경 데이터 동기화 기법
모바일 환경에서 데이터 동기화 기법에 대하여 설명하시오. (10점)\*\*데이터 동기화(Data Synchronization)\*\*란, 서로 다른 저장 위치(예: 모바일 단말 ↔ 서버)의 데이터 상태를 일관성 있게 유지하는 기술을 의미한다.모바일 환경에서는 네트워크
63.PouchDB, CouchDB, RealmDB
PouchDB, CouchDB, Realm DB에 대해 각각 설명하고, 모바일 환경에서의 적용 및 비교를 수행하시오.Client-Side NoSQL DBHTML5 LocalStorage 대체를 위해 만들어진 오프라인 퍼스트(Offline First) 설계자바스크립트 기
64.기출 embedded DB
임베디드 DB(Embedded Database)에 대해 설명하시오.임베디드 데이터베이스(Embedded DB) 란,\*\*애플리케이션 내에 직접 통합(내장)되어 실행되는 경량형 데이터베이스 관리 시스템(DBMS)\*\*으로,별도의 DB 서버 없이도 프로그램 자체에서 데
65.기출 Realtime DB, Embedded DB
Real-time DB, Embedded DB 에 대해 설명하시오.Real-time Transaction Manager: 시간 제약 조건 확인 및 처리Scheduler: Deadline 기반 스케줄링 (예: EDF, RM)Temporal Data Manager: 시계열
66.기출 최근 모바일 기기 등과 같은 내장형(Embedded) DBMS에 대한 관심과 수요가 증가하고 있다. 기존의 DBMS와 비교하여 내장형 DBMS가 가져야 할 중요한 특징 세 가지를 설명하시오.
최근 모바일 기기 등과 같은 내장형(Embedded) DBMS에 대한 관심과 수요가 증가하고 있다. 기존의 DBMS와 비교하여 내장형 DBMS가 가져야 할 중요한 특징 세 가지를 설명하시오. \*\*Embedded DBMS (내장형 데이터베이스관리시스템)\*\*는 애플
67.XML DB
XML DB에 대하여 설명하시오.\*\*XML DB(XML Database)\*\*는 XML(eXtensible Markup Language) 형식의 데이터를 저장, 검색, 관리하기 위한 데이터베이스이다.기존 관계형 데이터베이스(RDBMS)가 정형 데이터를 관리하는 반
68.XML DB
XML DB에 대하여 설명하고, RDBMS(Relational Database Management System)와의 차이점 및 적용 분야에 대해 기술하시오.\*\*XML DB (XML Database)\*\*란 XML(eXtensible Markup Language)
69.RSS
\*\*신디케이션(Syndication)\*\*은콘텐츠를 한 곳에서 만들고, 여러 곳에서 자동으로 배포·공유하는 방식입니다.즉,“A 사이트에서 만든 글, 영상, 뉴스를B, C, D 여러 사이트에서 자동으로 볼 수 있게 배포하는 기술”입니다.신디케이션(Syndicatio
70.SOAP
\*\*SOAP(Simple Object Access Protocol)\*\*는\*\*분산 환경(distributed environment)\*\*에서 이기종 시스템 간에 구조화된 메시지를 교환하기 위해 설계된 XML 기반의 메시징 프로토콜입니다.웹 서비스(Web Se
71.WSDL
SOAP 기반의 웹 서비스를 설명할 때 반드시 등장하는 핵심 개념이며,SOAP = 통신 프로토콜, WSDL = 계약서, UDDI = 주소록이라고 외우면 쉽게 기억됩니다.\*\*WSDL(Web Services Description Language)\*\*는웹 서비스가 제
72.기출 XML DB, RDB, NATIVE (Embedded)DB 비교
XML DB, 관계형 DB, Native XML DB 방식의 특징 및 장단점을 비교하시오.XML DB: 이기종 시스템 간 데이터 교환, 웹서비스, B2B 연동에서 XML 데이터를 그대로 처리하기 위한 DB 방식RDB: 범용적인 구조화된 데이터 저장과 빠른 검색, 정형화
73.기출 멀티미디어 데이터베이스 시스템은 이미지 데이터의 인덱스 등을 구성한다. 이를 구축 시 피해야 할 사항을 제시하시오
멀티미디어 데이터베이스 시스템(Multimedia Database System, MMDBS)은 이미지, 오디오, 비디오 등 비정형(Non-structured) 데이터를 저장, 검색, 관리하는 데이터베이스 시스템입니다. 특히 이미지 데이터의 인덱스를 구성할 때는 일반 텍
74.온톨로지 Ontology
좋은 질문입니다.\*\*"온톨로지(Ontology)"와 "시멘틱 웹(Semantic Web)"\*\*은 정보 표현과 이해를 위한 중요한 개념으로, 지능형 웹, 지식 표현, AI와 밀접하게 관련되어 있습니다.기술사 시험 스타일로 구성한 상세하고 체계적인 설명을 드리겠습니
75.POSTGRESQL MVCC
PostgreSQL은 데이터베이스에서 어떤 방식으로 동시성을 제어하는가?\*\*MVCC (Multi-Version Concurrency Control)\*\*는트랜잭션 간 \*\*동시성(Concurrency)\*\*을 보장하면서도, \*\*락(Lock)\*\*으로 인한
76.벡터 데이터베이스(Vector Database)
벡터 데이터베이스는 고차원 벡터 공간 상에서 데이터를 저장하고, \*\*벡터 간의 유사도 기반 검색(예: 근접 이웃 검색)\*\*을 빠르게 수행하기 위한 특화된 데이터베이스입니다.특히 \*\*비정형 데이터(이미지, 텍스트, 음성 등)\*\*를 \*\*정형화된 벡터 표현