
0. (차원 축소 전) 모델 학습 및 Feature Importance 확인
일단 차원축소를 어느 정도까지 해도 학습에 지장이 없는지 확인하기 전에, 데이터셋이 잘 만들어졌는지, 학습이 잘 되는지를 확인하기 위해 학습에 맞는 전처리와 모델 fitting을 수행해보겠습니다.
현재 작업한 full_df은 train & test가 나눠지지 않은 일체형이기 때문에 모델 학습을 위한 일부 split이 필요합니다.
from sklearn.model_selection import train_test_split
X = full_df.drop(columns=['Activity'])
y = full_df['Activity']
X_train2, X_test2, y_train2, y_test2 = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)x는 답을 알 필요가 없기 때문에 Activity를 drop하고, y를 Activity로 놓겠습니다. 왜 각 train, test셋을 2로 설정했는지는 기억 안나는데 아마 1은 PCA용으로 남기고 싶어서 그랬던 것 같습니다.
# 기본 학습을 위한 앙상블 모델 (RF 혹은 로지스틱회귀)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=200,
max_depth=None,
random_state=42,
n_jobs=-1
)
rf.fit(X_train2, y_train2)일단 562차원에서 선형 관계가 나올 것이라는 기대를 하지는 않기 때문에 Random Forest로 기본 학습을 시키고 예측까지 수행해보겠습니다.
RF 분류기 세부 설정의 경우 결정트리의 개수(n_estimators)는 200개로 설정하고, 결정 트리의 최대 깊이를 제한하지 않는 상태(max_depth=None)에서 재현 가능성 확보(random_state=42)에 의미를 두고 CPU 코어를 병렬(n_jobs=-1)로 사용하겠다고 선언하였습니다.
학습을 잘 시켰으니 예측 정확도를 보겠습니다.
# 예측 정확도 확인
from sklearn.metrics import accuracy_score
pred = rf.predict(X_test2)
accuracy_score(y_test2, pred)정확도 점수는 '0.9810679611650486' 가 나왔습니다. 98.1% 정도군요.
Random Forest는 대표적인 Classification 모델이고, 이 말인 즉 현재는 센서 feature를 사용해서 사람이 어떤 행동(자세)을 하고 있는지 매우 정확하게 분류하고 있다는 것입니다. 결과를 예측하는 모델링, 본 데이터 정제도가 높아서 기본 머신러닝으로도 높은 정확도가 나옴을 검증한 것이죠.
이제 Feature Importance 확인을 위한 SHAP 분석을 수행해봅니다. SHAP 분석은 '모델의 예측 결과를 각 특성이 얼마나 기여했는지로 분해해 설명하는 방법'입니다.
게임이론의 Shapley value 개념을 기반으로, 개별 예측값이 기준값(base value)에서 얼마나 증가하거나 감소했는지를 각 특성(feature)의 기여도로 정량화하는 설명 기법이라고 합니다.
# feature Importance 확인을 위한 SHAP
import shap
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X_train2.sample(100))
shap.summary_plot(shap_values, X_train2.sample(100), plot_type="bar")RF 같은 트리 모델의 경우 분류 성능 자체는 좋지만 '왜 이렇게 예측했는지?' 를 직관적으로 설명하기 어려운 블랙박스형 모델입니다. 그래서 모델 성능을 넘어 '해석 가능성'을 확보하기 위해 SHAP 분석을 추가적으로 수행하는 경우가 많습니다.
이제 결과를 보겠습니다.
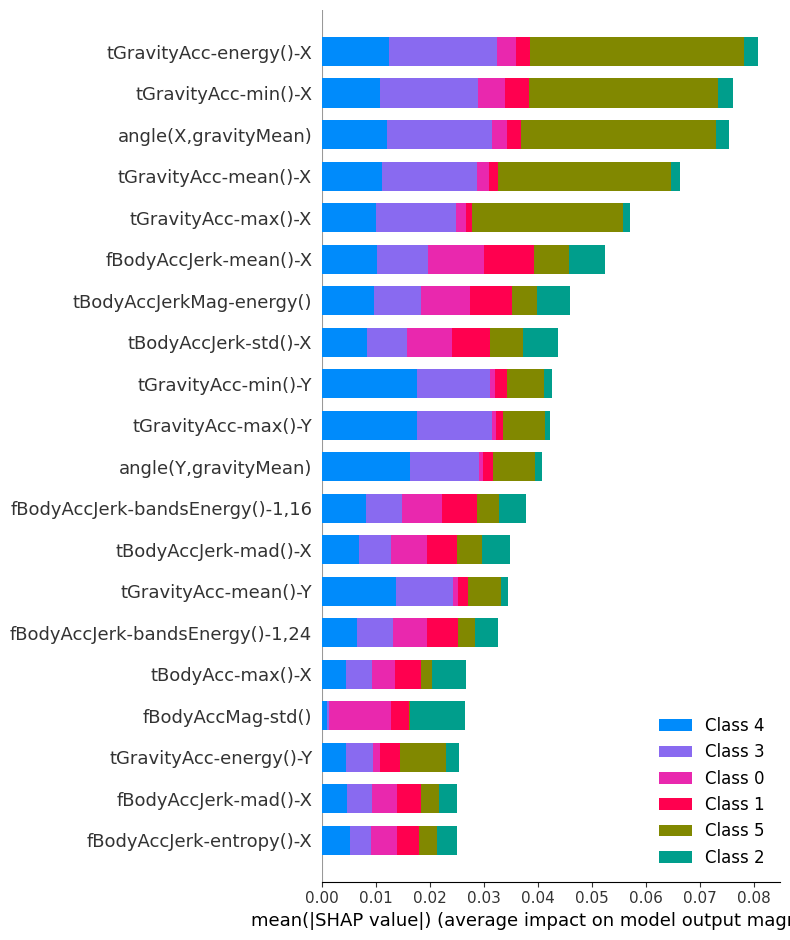
일단 시각화 결과가 예쁘긴 한데 저 센서들이 뭔지 모르겠어요.
그래서 센서 하나하나를 밝히는데 의미를 두기보다 어떤 센서이고 어떤 class(활동) 분류의 성능이 좋은지에 초점을 맞춰 해석하기 위해 노력했습니다.
참고로 Class lable의 정의는 이렇습니다.
| Class | 실제 Activity 이름 | 의미 |
|---|---|---|
| 0 | WALKING | 보통 속도로 걷기 |
| 1 | WALKING_UPSTAIRS | 계단 오르기 |
| 2 | WALKING_DOWNSTAIRS | 계단 내려가기 |
| 3 | SITTING | 앉아있기 |
| 4 | STANDING | 서있기 |
| 5 | LAYING | 누워있기 |
일단 가장 상위 Feature인 tGravityAcc-energy()-X는 '중력 기반 가속도(gravity acceleration) X축에서 energy의 통계 값'으로, 서 있는지/누워있는지/걷는지 등의 구분에 매우 큰 영향을 미치며, 특히 Standing / Laying 구분 시 중요도가 매우 높습니다.
해당 센서가 클래스 별 미치는 영향력을 보면
- Class 0(WALKING): 약간 영향
- Class 1(UPSTAIRS): 약간 영향
- Class 2(DOWNSTAIRS): 약간 영향
- Class 3(SITTING): 4 대비 큰 영향
- Class 4(STANDING): 0,1,2 대비 비교적 큰 영향
- Class 5(LAYING): 아주 큰 영향
인 것을 볼 수 있습니다. 즉, 일반적으로 우리가 스마트폰을 주머니에 넣고 있거나 팔에 웨어러블 기기를 착용했다고 가정했을때 X축 방향으로 이동을 하고 있는지, 중력 센서 기반으로 측정한다는 겁니다. 그래서 내가 걷는지 계단을 오르내리는지 여부를 판단하는 것보다 앉거나, 서거나, 눕는걸 더 잘 판단합니다.
그런 의미에서 정말 제가 누워서 끌려가면 저 센서 친구가 가장 잘 판단하겠네요. 아무래도 '중력 가속도' 다 보니까 땅에 붙어서 움직이는지(?) 일어나서 움직이는지 알 수 있겠죠.

(예를 들자면 말입니다 예를 들자면..)
사족이 길었는데 아무튼 위에 출력한 SHAP 분석 시각화 결과는 각 Class 별로 해당 feat이 어느 정도 영향을 미치는지 상위 features 별로 확인하는 것이라 생각하면 되겠습니다.
1. PCA 차원 축소
제가 1편에 작성한 UCI 데이터의 개요를 보면 저 센서들이 무엇인지 왜 저런 흉측한 이름들이 붙었는지 알 수 있는데, 차원축소의 당위성을 설명하기 위해 여기서 한번 더 짚고 넘어가보겠습니다.
한 센서와 쌍을 이루는 데이터는 2.56초 단위로 하나의 'window'로 슬라이싱되어 128개 연속 측정값을 포함합니다. 그렇다면 왜 '128개 연속 측정값'일까요?
스마트폰 센서 주파수는 50Hz(초당 50회)이며, 사람이 어떤 '행위'를 수행하는 2.56초에 50Hz를 곱하면 총 128개의 연속 측정값이 발생합니다. 이를 하나의 window로 슬라이싱 할 경우 센서축(X,Y,Z)과 주파수 도메인, 파생신호 들의 특징 등을 합쳐 총 '561개의 센서 기반 특징'이 발생합니다.
하지만 561차원 전체를 그냥 분석하면 리소스도 많이 들고 연산 시간도 오래 걸립니다. 그것은 마치 561명을 데리고 이구동성 게임을 하는 것과 같습니다. 아무리 계속 외쳐도 답이 안 나오겠죠.
그렇기 때문에 해당 데이터를 가지고 각 행동 클래스에 대한 확률(가중치)을 계산하여 이 사람이 어떤 행동을 하고 있는지 판단하기 위해 그룹별 PCA(주성분 분석)를 통한 차원축소가 필요합니다.
주성분 분석? 차원축소? 차원축소는 도대체 뭔데?
제가 이 그림을 또 써먹을 줄은 몰랐는데, 차원축소는 쉽게 말하면 복잡한 구조로 된 데이터의 '특성'만 가지고 그 데이터를 분류하기 위해 '특성 데이터'로써 단순화하는 과정입니다.

(제가 쓴겁니다. 물론 전적으로 제가 그린건 맨 오른쪽이고요.)
복잡한 고화질의 고양이 사진(왼쪽)을 '이게 일반적인 고양이임' 하고 일러스트 형식으로 단순화(중간)했을때, 고양이의 일반적 특징을 설명할 수 있는 부분만 남겨서 데이터화 한 것(오른쪽) = 차원축소 입니다.
차원축소가 뭔지 감이 잡혔다면 이제 본격적으로 차원축소 실험을 해보겠습니다. 먼저 PCA 객체를 생성하고 2차원으로 줄여봅니다.
# PCA 객체 생성 & 2차원 PCA 준비
from sklearn.decomposition import PCA
pca_2d = PCA(n_components=2)
X_pca_2 = pca_2d.fit_transform(X_scaled)2차원으로 축소시킨 결과를 가지고 시각화를 해보겠습니다.
pca_2d = PCA(n_components=2)
X_pca_2 = pca_2d.fit_transform(X_scaled)
pca_df = pd.DataFrame({
"PC1": X_pca_2[:, 0],
"PC2": X_pca_2[:, 1],
"Activity": y.values # y_train 아님!
})
palette = sns.color_palette("tab10", 6)
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="PC1",
y="PC2",
hue="Activity",
palette=palette,
data=pca_df,
s=40,
alpha=0.7
)
plt.title("HAR Dataset PCA (2D)")
plt.legend(title="Activity", loc="best")
plt.show()일단 PCA로 2차원 축소를 한 X_scaled 데이터를 설명 분산이 가장 큰 두개의 주성분(PC1, PC2)f로 축소하여, PCA 결과와 실제 레이블을 결합하고 시각화 하였습니다. 훈련/테스트 분리 및 모델 학습과는 무관하며 오로지 전체 데이터의 분포를 보기 위한 차원축소입니다.
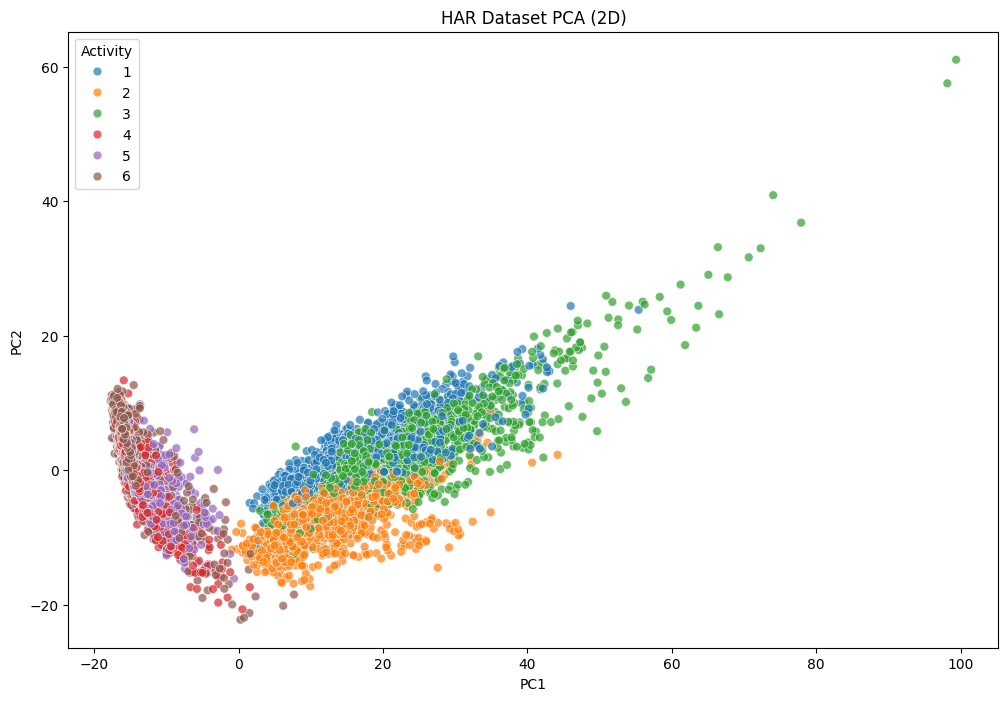
3차원의 내 얼굴을 2차원에 우겨넣으면 뭔가 내 얼굴이 아닌 것 같죠? 얘네도 마찬가집니다. 561차원 데이터를 2차원에 우겨넣었더니 클래스별로 구분도 잘 안되고 이게 무슨 동향을 말해주고 있는건지 잘 모르겠습니다.
데이터 생긴걸 보면 알 수 있을까요?
pca_df.head()| PC1 | PC2 | Activity | |
|---|---|---|---|
| 0 | -16.380980 | 1.995083 | 5 |
| 1 | -15.582173 | 1.182594 | 5 |
| 2 | -15.423989 | 2.243166 | 5 |
| 3 | -15.647807 | 3.762882 | 5 |
| 4 | -15.842320 | 4.438897 | 5 |
모르겠습니다. (당당)
아마 클래스를 구분하는 가장 크리티컬한 특성만 가져온 것 같은데 어떤 특성인지 설명하기가 어렵네요.
그렇다면 2D를 기준으로 전체 대비 어느 정도의 정보만 반영된건지 봅시다.
# 2D 기준으로 얼마만큼의 정보만 반영된 상태인지 ratio 확인
pca_2d.explained_variance_ratio_array([0.50738221, 0.06239186])array 앞에서부터 PC1, PC2 인데요, PC1의 경우 전체 데이터 분산의 약 50.7%를 설명하고 있고, PC2의 경우 전체 데이터 분산의 약 6.2%를 설명하고 있습니다.
그래서 두 개를 합쳐보면 이 2차원 PCA는 전체 분산정보의 약 56.9%만 반영하고 있음을 알 수 있죠. 어디까지나 '시각화' 목적으로 차원축소를 했다는 것을 염두에 둡시다.
그렇다면 몇 차원까지 축소해야 본래 성능이 나오는가?
보시다시피 2차원 만으로는 우리가 알고싶은 걸 알 수가 없습니다. 그렇다면 과연 561차원에서 몇차원까지 줄여야 리소스 낭비나 연산 과다 없이 최적 성능을 발휘할 수 있을까요?
이를 알기 위해 차원축소 누적 기여도를 한번 그려보겠습니다. 이는 가장 적은 차원의 성능부터 Full 차원에서의 성능을 누적그래프로 보여주는 것입니다.
# 전체 PC 누적기여도_ 몇차원까지 줄여야 원래 성능으로 유지하는지 확인
pca_full = PCA().fit(X_scaled)
plt.plot(np.cumsum(pca_full.explained_variance_ratio_))
plt.xlabel("Number of Components")
plt.ylabel("Cumulative Explained Variance")
plt.grid()
plt.show()중간에 plot을 보기 위해 입력한 명령어(pca_full.explained_variance_ratio_)가 아까 2차원의 누적기여도를 보기 위한 명령어와 확연히 다르네요.
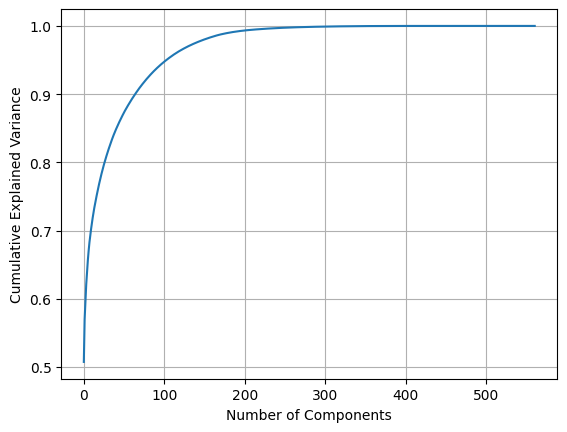
대애애애애충 봤을때 한... 150차원만 되도 95% 이상은 될 것 같습니다. 더 긍정적으로 보았을때는 100만 넘어도 90% 이상은 설명 가능할 것 같습니다.
그럼 정확하게 몇차원 정도를 가지고 모델을 돌려보고 시각화를 할지 테스트를 해보죠.
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import pandas as pd
# 성능을 저장할 리스트
results = []
# 실험할 PCA 차원 목록
dims = [2, 5, 10, 20, 30, 40, 50, 75, 100, 120, 150, 200, 300, 561] # 561=원본 그대로
# Train/Test split
X_train_split, X_test_split, y_train_split, y_test_split = train_test_split(
X_scaled, y_train["Activity"], test_size=0.2, random_state=42
)
for d in dims:
print(f"\n=== PCA {d}차원으로 실험 중 ===")
# PCA 적용
pca = PCA(n_components=d)
X_train_pca = pca.fit_transform(X_train_split)
X_test_pca = pca.transform(X_test_split)
# 랜덤포레스트 학습
rf = RandomForestClassifier(n_estimators=200, random_state=42)
rf.fit(X_train_pca, y_train_split)
# 예측 및 정확도 계산
y_pred = rf.predict(X_test_pca)
acc = accuracy_score(y_test_split, y_pred)
results.append({
"PCA_Dim": d,
"Accuracy": acc
})
# 결과 DataFrame 정리
results_df = pd.DataFrame(results)
results_df지금보니 아까 제가 RF를 위해 각 split 세트를 2로 지정한게 임시 테스트를 위해서인게 맞는 것 같습니다.
저기서 dims 리스트는 실험할 PCA 차원 목록이고 안에 데이터는 차원 수입니다. 차원 숫자대로 줄여서 RF를 돌려보고 예측 후 정확도 계산을 하겠다는 코드입니다.
결과를 보겠습니다.
| PCA_Dim | Accuracy | |
|---|---|---|
| 0 | 2 | 0.533651 |
| 1 | 5 | 0.838205 |
| 2 | 10 | 0.889191 |
| 3 | 20 | 0.907546 |
| 4 | 30 | 0.926581 |
| 5 | 40 | 0.923861 |
| 6 | 50 | 0.932699 |
| 7 | 75 | 0.925901 |
| 8 | 100 | 0.938137 |
| 9 | 120 | 0.944256 |
| 10 | 150 | 0.933379 |
| 11 | 200 | 0.942896 |
| 12 | 300 | 0.932019 |
| 13 | 561 | 0.913664 |
얼추 예상한대로, 아니 한 20차원만 되도 90% 이상은 발휘하는 것을 알 수 있습니다. 아마 데이터 정제가 잘 되서 인 것 같네요.
근데 의외로 이렇게 보니 100~120회차 쯤부터 Accracy가 흔들리기 시작합니다. 진짜 그런가 한번 볼까요?
plt.figure(figsize=(10, 5))
sns.lineplot(data=results_df, x="PCA_Dim", y="Accuracy", marker="o")
plt.title("HAR Dataset: Accuracy changes according to the number of PCA dimensions")
plt.show()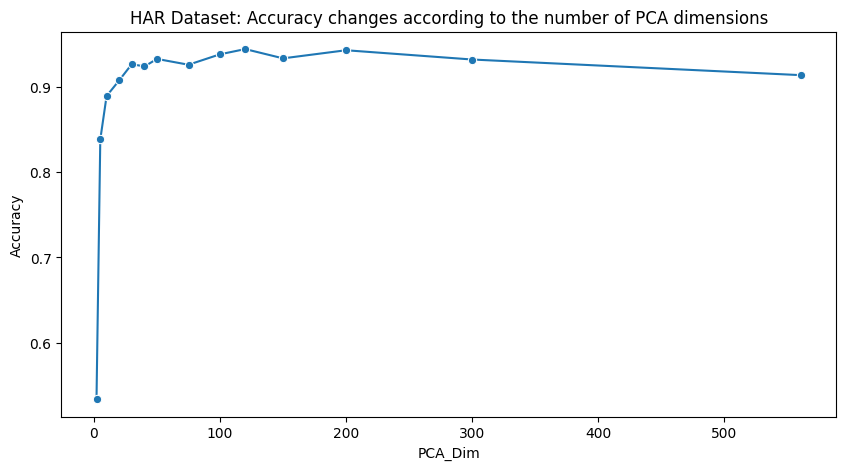
그래프로 보니 확실하게 알 수 있는 것이, 제 예상에서는 100~120회차쯤에 Accuracy가 원래 데이터셋만큼 올라갈 것이라 생각했는데 그 전에 거의 복구하고, 심지어 100 넘는 순간부터 Accuracy가 흔들리기 시작하여 561차원에는 아예 떨어지는 것을 확인하였습니다.
아니 근데 그러면, 처음 RF를 돌려서 나온 98%의 정확도는 무엇이었을까요?
모델의 문제일까요? 데이터는 아주 깨끗하다고 했는데?
저는 아직 베테랑 Data Scientist가 아니므로, 정확한 원인 분석을 위해 저의 동반자 ChatGPT에게 물어봤고 결론은 다음과 같습니다.
→ 학습 환경과 테스트 환경이 유사한 원본 HAR 데이터의 train:test(7:3) 를 사용해서 거기에 적합성을 띔
→ 현재 차원별 RF는 임의로 train/test를 split 하면서 subject가 섞이고, 패턴이 사람별로 달라지면서 그에 따라 난이도가 높아짐 & RF는 고차원일수록 overfitting & variance 증가로 일반화 성능 떨어진다고 함
∴ 처음 만든 데이터로 한 건 일종의 학원 모의고사, 현재 다시 차원별로 테스트해본 것은 6모 모의고사 같은 것
그래서 저는 여기서 하지 않아도 될 짓(?)을 해봅니다. 머신러닝 모델을 모두 불러와서 성능검증을 해본거죠. 집 데스크톱 터지는 줄 알았습니다. 코드는 모두 생략하고 시각화 한 결과만 보겠습니다.
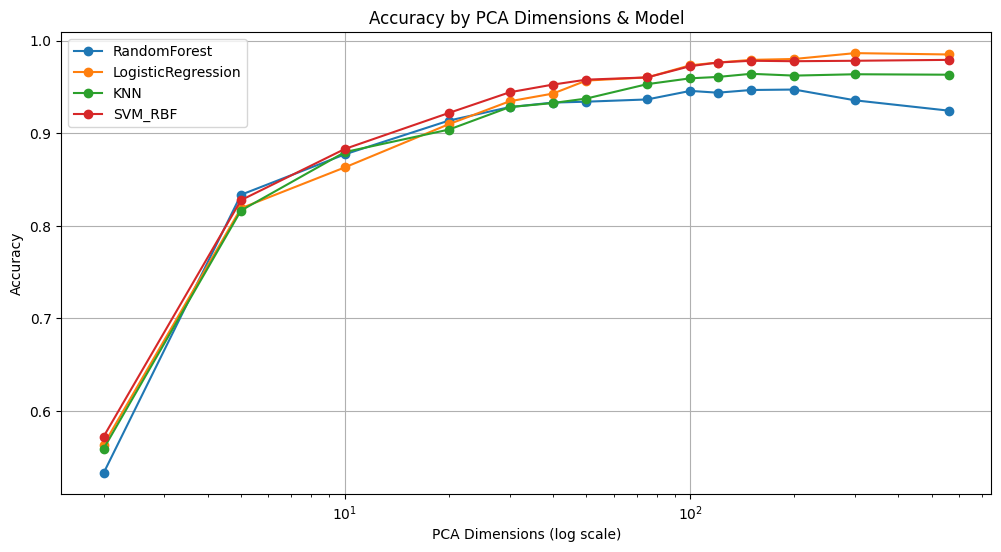
KNN, 로지스틱회귀, Random Forest, SVM 결과는 위와 같습니다. 전반적으로, 특히 Random Forest가 차원이 높아지면서 아까 봤던 현상이 나타납니다. 그래서 트리 모델들의 특징인가 하여 트리 부스터 계열 모델들을 추가로 불러와 해봅니다.
UCI 데이터셋 실험을 시작한게 오후 8시인가 그랬는데 저 지랄(?)을 끝내고 나니 새벽 1시 반이었습니다.
| PCA_Dim | RandomForest | LogisticRegression | KNN | SVM_RBF | XGBoost | LightGBM | CatBoost |
|---|---|---|---|---|---|---|---|
| 2 | 0.544175 | 0.562136 | 0.553398 | 0.572816 | 0.530583 | 0.536408 | 0.578641 |
| 5 | 0.831553 | 0.816505 | 0.811650 | 0.828155 | 0.826699 | 0.823786 | 0.832524 |
| 10 | 0.883495 | 0.863107 | 0.878641 | 0.884466 | 0.883010 | 0.884951 | 0.876699 |
| 20 | 0.908738 | 0.910680 | 0.907767 | 0.921359 | 0.917476 | 0.919417 | 0.907282 |
| 30 | 0.923301 | 0.935437 | 0.931553 | 0.944175 | 0.941262 | 0.937864 | 0.928641 |
| 40 | 0.936408 | 0.942233 | 0.931068 | 0.952427 | 0.950971 | 0.950971 | 0.934951 |
| 50 | 0.933010 | 0.952913 | 0.935437 | 0.957282 | 0.950000 | 0.954369 | 0.933010 |
| 75 | 0.939806 | 0.958252 | 0.952427 | 0.960194 | 0.954854 | 0.958252 | 0.940291 |
| 100 | 0.944175 | 0.972330 | 0.960194 | 0.973301 | 0.966990 | 0.964078 | 0.945146 |
| 120 | 0.948544 | 0.976699 | 0.958252 | 0.977184 | 0.966990 | 0.964078 | 0.945146 |
| 150 | 0.948058 | 0.979126 | 0.958738 | 0.978155 | 0.966505 | 0.966505 | 0.944660 |
| 200 | 0.946117 | 0.980097 | 0.958738 | 0.976699 | 0.971845 | 0.967476 | 0.949515 |
| 300 | 0.938350 | 0.985437 | 0.962136 | 0.977670 | 0.972816 | 0.971845 | 0.946602 |
| 561 | 0.922330 | 0.984466 | 0.962621 | 0.978641 | 0.971359 | 0.971845 | 0.947573 |
결론적으로, 데이터 구조 자체가 PCA를 통해 선형적으로 정리되었을 때 가장 효율적으로 패턴을 잡는 모델은 Logistic Regression임을 확인할 수 있었습니다. 물론 로지스틱 회귀가 가장 HAR 원본 데이터에서 최적 모델이라는 것은 아니며, 원래의 561차원 데이터 기준으로 보았을때는 부스트 계열이나 SVM이 가장 성능이 좋은 것을 알 수 있었습니다.
2. UMAP & t-SNE 시각화
PCA 차원축소를 통해 전체 데이터 생김새를 봤으니, 이제 UMAP / t-SNE 시각화를 통해 클래스 내부에서 어떻게 나뉘는지를 보도록 하겠습니다.
UMAP과 t-SNE는 PCA와 달리 비선형 차원 축소 기법으로, 데이터 포인트 간 국소적인 거리 관계를 중점적으로 보존하여 클래스 내부 구조와 군집 형태를 보다 선명하게 시각화할 수 있습니다.
(출처 : https://medium.com/swlh/everything-about-t-sne-dde964f0a8c1)
반면 전체적인 거리 관계는 일부 왜곡될 수 있는데, 이는 지구본을 평면 세계지도에 펼쳐 표현할 때 지역 간 형태는 유지되지만 대륙 간 실제 거리가 달라 보이는 것과 유사하다고 볼 수 있습니다.
그럼 원활한 시각화를 위해 처음부터 UMAP, t-SNE를 할 수도 있지 않냐? 라는 의문이 들 수도 있습니다.
이론적으로는 원본 데이터에 바로 UMAP이나 t-SNE를 적용할 수 있습니다. 다만 고차원 데이터에서는 노이즈와 중복 특성이 많아 비선형 차원 축소 결과가 불안정해질 수 있기 때문에,일반적으로 PCA로 주요 분산 성분을 먼저 추출한 뒤 UMAP이나 t-SNE를 적용하여 시각화를 수행합니다.
그럼 처음부터 UMAP/t-SNE를 적용하는 경우는 없나?
지금 UCI 데이터처럼 데이터 차원이 높지 않고 비교적 낮거나 탐색적으로 군집 구조만 빠르게 확인하려는 경우에는 PCA 없이 UMAP이나 t-SNE를 적용하기도 합니다.
일단 제가 너무 지쳤으므로 UMAP & t-SNE 시각화부터 빠르게 가보겠습니다.
# UMAP 시각화
# 데이터 준비
X = full_df.drop(columns=["Subject", "Activity"])
y = full_df["Activity"]
# UMAP 2D 세팅, 모델 피팅
import umap.umap_ as umap
import matplotlib.pyplot as plt
import seaborn as sns
# UMAP 2D
umap_2d = umap.UMAP(
n_neighbors=15,
min_dist=0.3,
spread=1.5,
n_components=2,
metric='euclidean',
random_state=42
)
X_umap_2d = umap_2d.fit_transform(X)
# 시각화
plt.figure(figsize=(10, 8))
sns.scatterplot(
x=X_umap_2d[:, 0],
y=X_umap_2d[:, 1],
hue=y,
palette="tab10",
s=20
)
plt.title("UMAP Projection (2D) – HAR Dataset")
plt.legend(title="Activity", bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()결과를 보겠습니다.
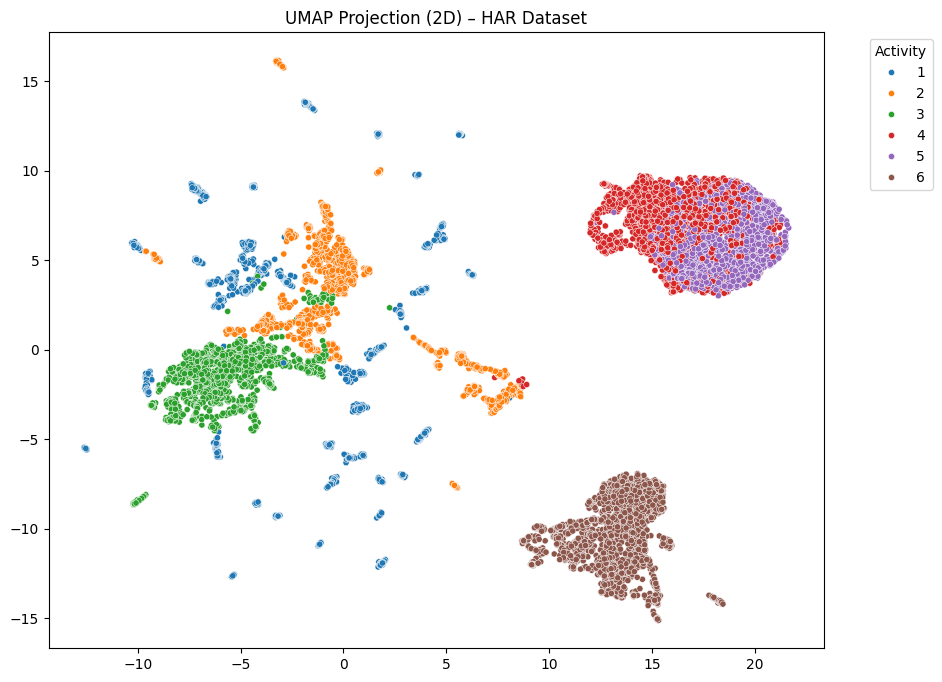
자세한 해석은 UMAP/t-SNE 차이를 들면서 이따 설명하기 위해 빠르게 t-SNE 코드부터 가봅니다.
# t-SNE 차원축소
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
# t-SNE 전처리: PCA로 100차원 축소
pca_100 = PCA(n_components=100)
X_pca_100 = pca_100.fit_transform(X)
# t-SNE 2D
tsne_2d = TSNE(
n_components=2,
perplexity=30,
learning_rate=200,
max_iter=1000,
metric="euclidean",
random_state=42,
verbose=1
)
X_tsne_2d = tsne_2d.fit_transform(X_pca_100)
# 시각화
plt.figure(figsize=(10, 8))
sns.scatterplot(
x=X_tsne_2d[:, 0],
y=X_tsne_2d[:, 1],
hue=y,
palette="tab10",
s=20
)
plt.title("t-SNE Projection (2D) – HAR Dataset (PCA 100 → t-SNE)")
plt.legend(title="Activity", bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()결과를 봅니다.
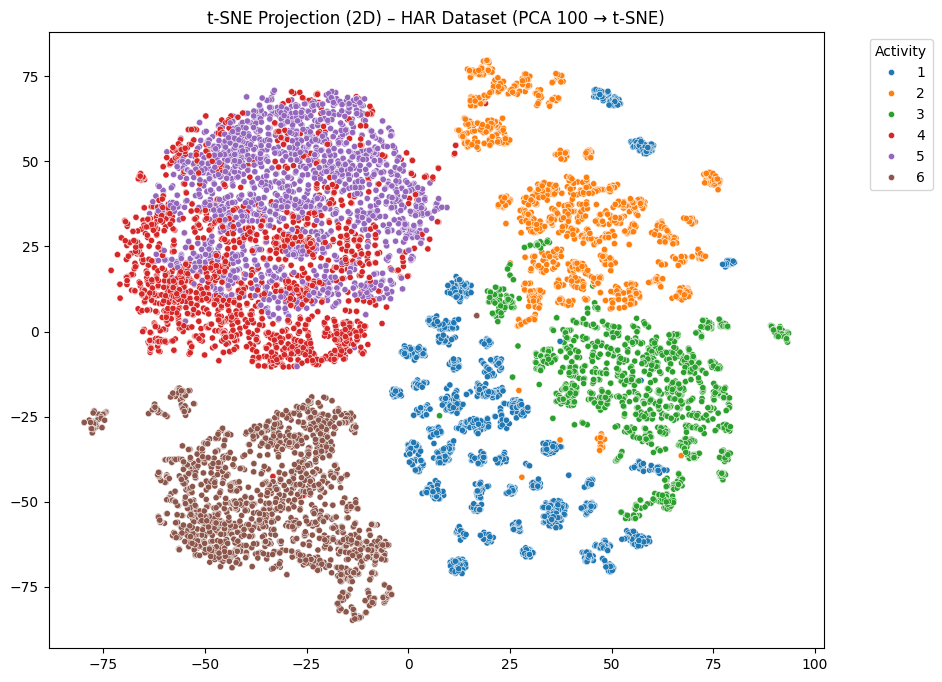
뭔가 상대적으로 t-SNE가 더 예쁘게(?) 표현하였음을 알 수 있습니다.
UMAP의 경우 구조적으로 보았을때 3~4개의 큰 덩어리로 묶여있는데, 상대적으로 4, 5(앉기, 서기)는 뭉쳐있고 6(눕기)는 아예 따로 떨어져있으며 걷기, 계단오르기, 내리기는 몰려있는 것을 볼 수 있습니다. 이는 전역 구조(Global Structure)를 보존하려는 UMAP의 성향 때문인데요, 이 때문에 전체 데이터의 '큰 지형도'를 유지하려 하기 때문에 비슷한 활동들이 가깝게 모이는 경향이 보입니다.
앉기, 서기는 그 자리에서 서거나/앉거나 한 상태, 즉 사실상 움직임이 없는 상태에서 중력 센서 Y축 차이이기 때문에 뭉쳐있고 눕기는 중력 센서 Y축이 땅에 붙어있는 것이나 다름없어 따로 떨어져 있는 것입니다. 걷기, 계단 오르내리기는 일단 이동을 한다는 측면에서 한 덩어리처럼 몰려있습니다.

정적 활동 – 앉기 (SITTING)

정적 활동 – 서기 (STANDING)

정적 활동 – 눕기 (LAYING)

동적 활동 – 걷기 (WALKING)
동적 활동 – 계단 오르기 (WALKING_UPSTAIRS)
동적 활동 – 계단 내려가기 (WALKING_DOWNSTAIRS)
t-SNE의 경우 UMAP과 비슷하게 앉기, 서기와 계단 오르내리기 등이 겹치는 현상을 보이지만, 비교적 6개 클래스가 완전히, 안정적으로, 또렷하게 분리되어 있음을 볼 수 있으며, 걷기/계단 오르기/계단 내려오기가 완전 다른 방향으로 산재되어 있음을 알 수 있습니다. 이는 국소 구조(Local Structure)를 보존하려는 t-SNE의 목표에 따른 것인데, 비슷한 포인트끼리는 붙이고 다른 것은 아주 멀리 밀어버린다는 데에서 그 특징이 뚜렷하게 나타난다고 볼 수 있습니다.
그럼 차원축소 후 어떤 센서(요소)가 데이터 변동성에 가장 큰 영향을 미칠까?
그렇다면 차원축소 후 데이터 변동성에 가장 큰 영향을 미치는 센서는 어떤 것들이 있을까요?
# PCA Component Loadings 분석(동적 vs 정적 활동 구분 축 파악)
from sklearn.decomposition import PCA
pca = PCA(n_components=10) # 상위 10개만 분석
X_pca = pca.fit_transform(X)
# PCA Loadings (component weight)
loadings = pd.DataFrame(
pca.components_.T,
columns=[f"PC{i+1}" for i in range(10)],
index=X.columns
)
# PC1 ~ PC3 까지만 보기
for i in range(3):
print(f"\n===== Top loadings for PC{i+1} =====")
display(loadings.iloc[:, i].abs().sort_values(ascending=False).head(15))===== Top loadings for PC1 =====
fBodyAccJerk-entropy()-X 0.126754
fBodyAccJerk-entropy()-Y 0.124041
tBodyAccJerkMag-entropy() 0.121878
fBodyAcc-entropy()-X 0.121675
fBodyAccMag-entropy() 0.114412
fBodyBodyAccJerkMag-entropy() 0.113277
tBodyGyroJerkMag-entropy() 0.112373
fBodyAcc-entropy()-Y 0.111808
tGravityAccMag-entropy() 0.108504
tBodyAccMag-entropy() 0.108504
fBodyAccJerk-entropy()-Z 0.107748
tBodyAccJerk-entropy()-X 0.107593
fBodyBodyGyroJerkMag-entropy() 0.104784
tBodyAccJerk-entropy()-Y 0.104646
fBodyAcc-entropy()-Z 0.102721
Name: PC1, dtype: float64
===== Top loadings for PC2 =====
tGravityAcc-energy()-X 0.161948
tBodyGyroMag-entropy() 0.151491
fBodyAcc-skewness()-Z 0.149908
fBodyAcc-kurtosis()-Z 0.138779
tBodyGyroMag-arCoeff()1 0.130883
tGravityAcc-arCoeff()-Y,2 0.128974
fBodyAcc-meanFreq()-Z 0.127125
tGravityAcc-arCoeff()-Y,1 0.125599
tGravityAcc-arCoeff()-Y,3 0.123955
tGravityAcc-arCoeff()-Z,1 0.122269
tGravityAcc-max()-X 0.121896
tGravityAcc-mean()-X 0.119618
tGravityAcc-arCoeff()-Z,2 0.117093
tGravityAcc-arCoeff()-Y,4 0.115533
angle(X,gravityMean) 0.114278
Name: PC2, dtype: float64
===== Top loadings for PC3 =====
tGravityAcc-energy()-X 0.369417
angle(X,gravityMean) 0.271175
tGravityAcc-mean()-X 0.269532
tGravityAcc-min()-X 0.268996
tGravityAcc-max()-X 0.260520
tGravityAcc-correlation()-Y,Z 0.217780
tGravityAcc-energy()-Z 0.197200
fBodyAcc-kurtosis()-X 0.186169
tGravityAcc-energy()-Y 0.184530
fBodyAcc-skewness()-X 0.173143
tGravityAcc-mean()-Y 0.138524
tGravityAcc-max()-Y 0.138397
tGravityAcc-min()-Y 0.132563
tGravityAcc-correlation()-X,Z 0.125908
tGravityAcc-max()-Z 0.122909
Name: PC3, dtype: float64PC1, PC2, PC3 별로 다르게 나옴을 확인할 수 있습니다.
PC1은 정적 ↔ 동적 활동을 가르는 가장 큰 축으로, 상위 로딩 항목이 entropy(불규칙성) 관련 지표임을 알 수 있습니다. 이는 PC1이 움직임의 복잡도/활동 강도의 축으로써 센서 신호 변동이 클 경우, 한마디로 움직임이 많은 활동은 entropy가 높고, 서기/앉기/눕기 등은 신호 변화가 작아 entropy가 낮음을 나타내기 때문입니다.
PC2는 활동 강도보다 자세 및 방향성 차이를 설명하는데, 그래서 상위 로딩 항목이 중력, Gyro 분포형 통계임을 알 수 있습니다. 그래서 특히 앉기 vs 서기, 서기 vs 눕기 등 정적 활동의 내부 차이가 이 축에서 드러납니다.
PC3은 중력 벡터 기준의 신체방향을 설명하는 축으로, 상위 로딩 항목이 중력, 앵글 등을 나타냅니다. 이에 따라 몸이 어떻게 놓여(orientation) 있는가를 강하게 반영합니다. 그래서 눕기의 경우 중력 벡터가 X축으로 크게 이동한다던지, 서기/앉기의 경우 중력이 주로 Z축으로 나타나는 것을 볼 수 있습니다. 그래서 눕기 클래스가 PC3에서 강하게 분리되는 경향이 존재합니다.

원래 Notebook에는 더 많은 분석내용이 존재하는데, 일단 현재 듣는 강좌에서 차원축소 캡스톤은 PCA 분석까지만이라고 하셔서 이쯤에서 마무리하고자 합니다. 다음 데이터는 아마 다음 캡스톤 주제를 예상해서 수행하거나, 최대한 정제되지 않은 날것 그대로의 데이터를 탐색하여 의미있는 결과를 도출을 위해 시도하거나 둘중 하나가 될 것 같습니다.
긴 헛소리 봐주셔서 감사합니다.
