
어제 조별활동 피드백에서 크게 느낀 바가 몇 가지 있어서, 다음 조별과제는 좀 더 철저하게 준비하기 위해 차원축소 스터디를 진행하였습니다.
프로젝트의 프로세스에 맞춰 문서 구성도 반영해 볼 예정입니다. 바로 시작하겠습니다.
(비장...)
1. 프로젝트의 의의(4W frame)
Who – 누구를 위한 프로젝트인가?
아이폰 건강 앱의 의료정보 수집 및 비상연락 기능이 2019년 iOS 13과 함께 공개되었습니다.
저는 3gs 시절부터 앱등이였던지라, 공개된 날 해당 기능을 바로 설정하였습니다. 언제 어디서 무슨 일이 나에게 일어날 지 감히 예상할 수 없는 세상이기 때문입니다. 이 프로젝트는 저를 포함하여 '일상적 움직임의 변화가 건강·안전과 직결되는 모든 사람을 위한' 프로젝트입니다.
Why – 왜 이 프로젝트를 해야 하는가?
건강 앱의 이 기능을 쉽게 설명하면, 내 폰이나 워치가 나에게 일어난 갑작스러운 상황을 감지하고 위험 상황임을 확인하면 지정된 연락처나 의료기관 등으로 긴급연락을 취하는 기능입니다. 그렇다면 나에게 '무슨 일'이 생긴건지 얘네들은 어떻게 감지하게 될 수 있었을까요?
스마트폰과 스마트워치에는 Gyro센서, 중력 센서 등 다양한 센서가 존재합니다. 이런 센서값들을 통해 사용자의 자세나 상황을 인지하고, 계단에서 굴러 떨어졌거나 갑작스럽게 쓰러지는 등, 사용자의 움직임이 평소와 다른 패턴일 경우 이를 '이상상황'이라고 판단합니다.
하지만 무조건 크거나 갑작스러운 움직임이라고 모두 위험한 상황은 아니기 때문에, 어떤 행동을 하는지 정밀하게 판단하는 기술이 필요합니다. 개개인을 위해 24시간 CCTV를 촬영하며 관제할 수 없기 때문에 평상시에는 각자의 리소스를 통해 안전을 확보해야 할 것입니다. 이 프로젝트는 '센서 데이터만으로 사람이 지금 어떤 행동을 하고 있는지 정확히 인식'해야 하는 문제를 해결하기 위한 프로젝트입니다.
What – 이 프로젝트는 무엇을 해결하는가?
스마트폰이나 웨어러블 디바이스에 내장된 센서의 종류는 매우 다양하며, 하나의 센서에서 나오는 데이터는 적을지라도 이 다양한 센서에서 동시에 많은 숫자의 값이 기록되고, 이를 계산하기 위한 항목들이 추가되다 보면 데이터셋의 길이, 넓이가 엄청나게 증가합니다. 이 프로젝트 데이터셋인 UCI-HAR Dataset 만 해도 열(column), 즉 Feature가 561개나 되는 561차원 데이터입니다.
기계가 사람의 '비정상' 행동을 판단하려면 '정상'패턴을 먼저 알고 있어야 하고, 그러기 위해서는 앉기/서기/걷기/계단 오르내리기 등의 기본 활동부터 정확히 분류해야 합니다. 이를 위해 다양한 AI 모델 학습이 필요한데, 561차원 데이터를 그대로 학습시키는 과정은 매우 복잡하고 많은 자원이 소요됩니다.
그렇기 때문에 데이터의 복잡성을 줄이고, 계산 효율성을 높이며, 중요한 특징에 집중하고, 고차원 데이터를 시각화하기 위해 '차원축소'라는 개념이 필요합니다. 이 프로젝트는 모델 성능을 유지하면서도 불필요한 차원을 제거하고, 실제 제품에서 사용할 수 있을 만큼 가벼우면서도 정확한 행동 인식 모델을 만들기 위해, ‘얼마나 차원을 줄여도 성능이 유지되는가?’를 탐구하는 것을 목표로 합니다.
이는 배터리 용량이 제한된 웨어러블이나 실시간 처리가 필요한 모바일 환경에서 특히 중요합니다. 모델이 가벼워질수록 더 많은 사용자에게 안정적으로 적용될 수 있기 때문입니다.
Where – 이 모델은 어디에서 활용될 수 있는가?
프로젝트 결과물의 활용처는 굉장히 다양한 도메인에 활용될 수 있습니다. 가장 직접적 연관 분야로는 센서를 탑재한 웨어러블 디바이스나 스마트폰 등 디바이스 분야를 들 수 있으며, 데이터를 주로 활용할 것으로 예상되는 의료·실버케어·스마트홈 분야에서 환자나 노약자 모니터링, 이상패턴 감지, 낙상위험 감지, 사용자 행위 기반 가전제품 자동 제어 등 다양한 현장에 폭넓게 적용 가능합니다.
즉, 이 모델은 단순한 기술 실험을 넘어, 실제 사람들의 안전과 삶의 질을 높이는 여러 서비스의 핵심 엔진으로 활용될 수 있습니다.
(여기까지는 프로젝트 대비를 위해 엄근진 컨셉입니다.)
2. 데이터셋 탐색
UCI-HAR Dataset이 대체 무엇인가?
본격적인 데이터 세팅에 앞서, 해당 데이터셋을 세팅하기 위한 raw 데이터패키지 구조와 정보를 짚고 넘어가야 합니다. 왜냐, 이 데이터 패키지는 모두 'txt 파일'로 이루어져 있기 때문입니다.
네. 맞습니다. 메모장 그 파일이요.
Kaggle의 데이터 페이지(https://www.kaggle.com/datasets/drsaeedmohsen/ucihar-dataset)의 Data Explorer를 보면 패키지는 대략 아래와 같은 구조입니다.
UCI-HAR Dataset/
├── test/
│ ├── Inertial Signals/ ← 원시(sensor signal) 128개 raw시그널
│ ├── X_test.txt ← 561-feature matrix
│ ├── y_test.txt ← 라벨(1~6)
│ ├── subject_test.txt ← 사람이 누구인지(ID)
│
├── train/
│ ├── Inertial Signals/ ← 원시(sensor signal), 128개 raw시그널
│ ├── X_train.txt ← 전처리 완료된 특징(feature)
│ ├── y_train.txt
│ ├── subject_train.txt ← 참여자 ID
│
├── README.txt ← 설명서
├── activity_labels.txt ← 활동명(클래스) 매핑
├── features.txt ← X 컬럼명 561개
├── features_info.txt ← feature 의미 및 수학적 계산 설명아무것도 모르고 보면 굉장히 잘 정리되어 있어 보이기에, 여기서 feature부터 확인해야지~ 하고 features.txt 를 열면,
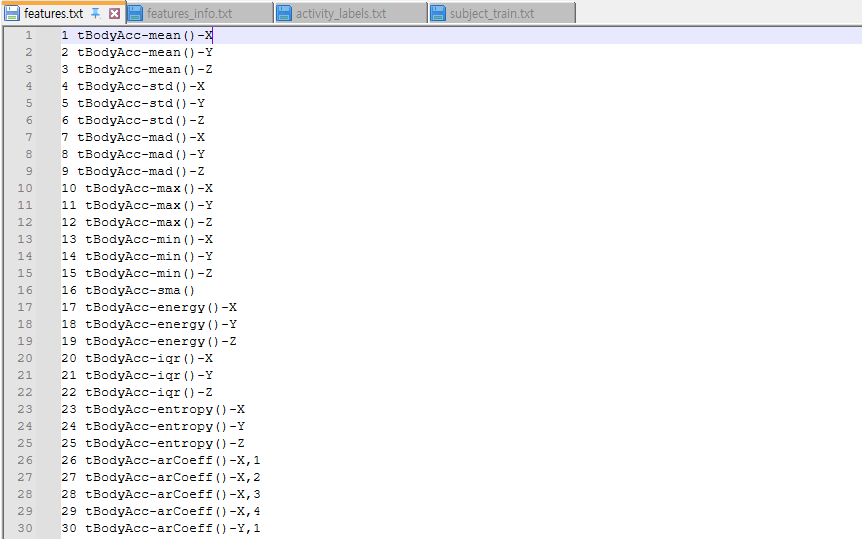 이런 데이터가 나를 기다립니다.
이런 데이터가 나를 기다립니다.

잠시 숨을 가다듬고 과연 이게 무슨 의미일까...? 하고 features_info.txt를 열면,
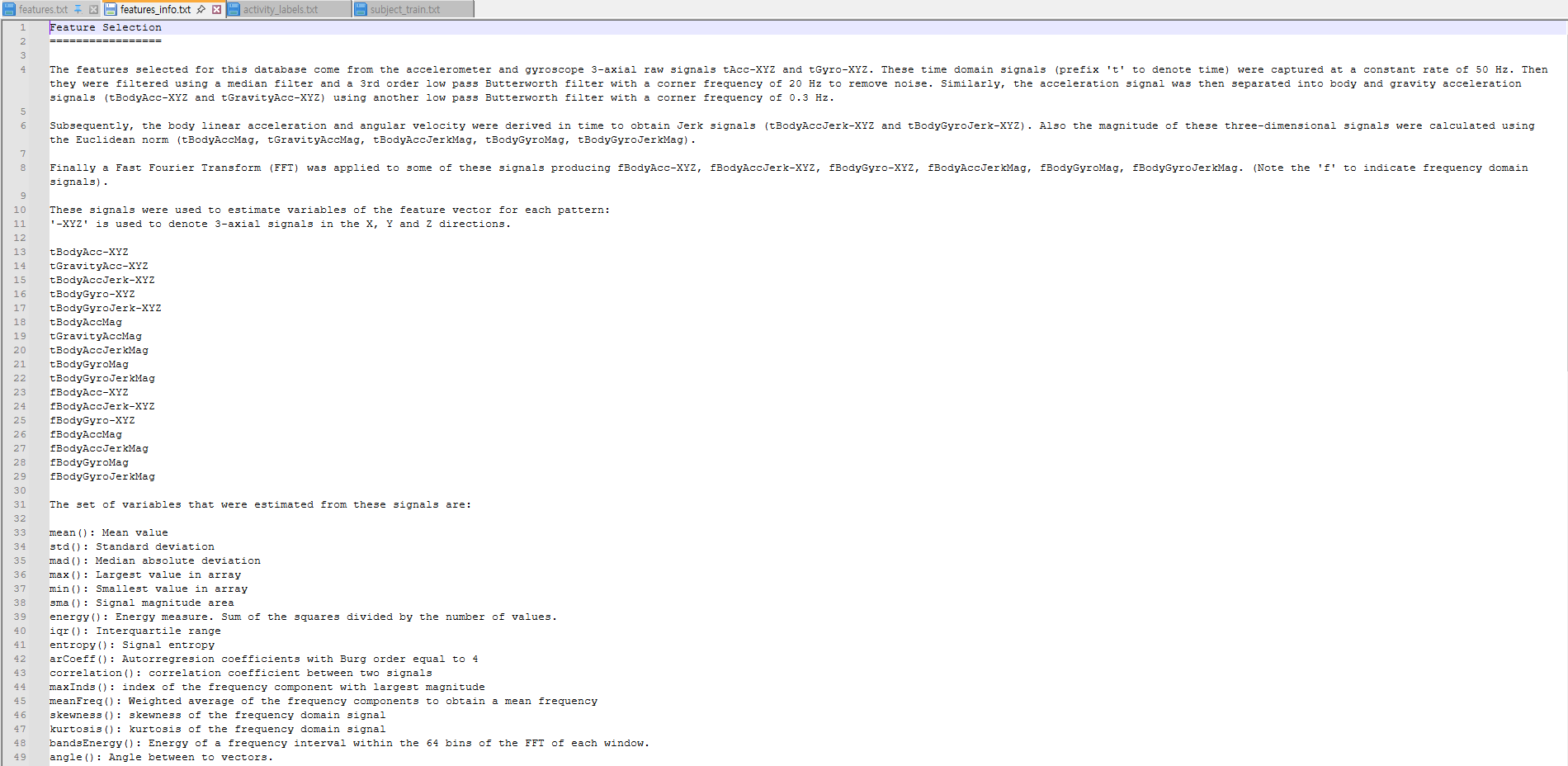 그냥 안 보는게 더 도움이 될 것 같습니다.
그냥 안 보는게 더 도움이 될 것 같습니다.

그렇다면 학습용 데이터는 어떻게 생겼을까~? 어이쿠 용량도 크네~?
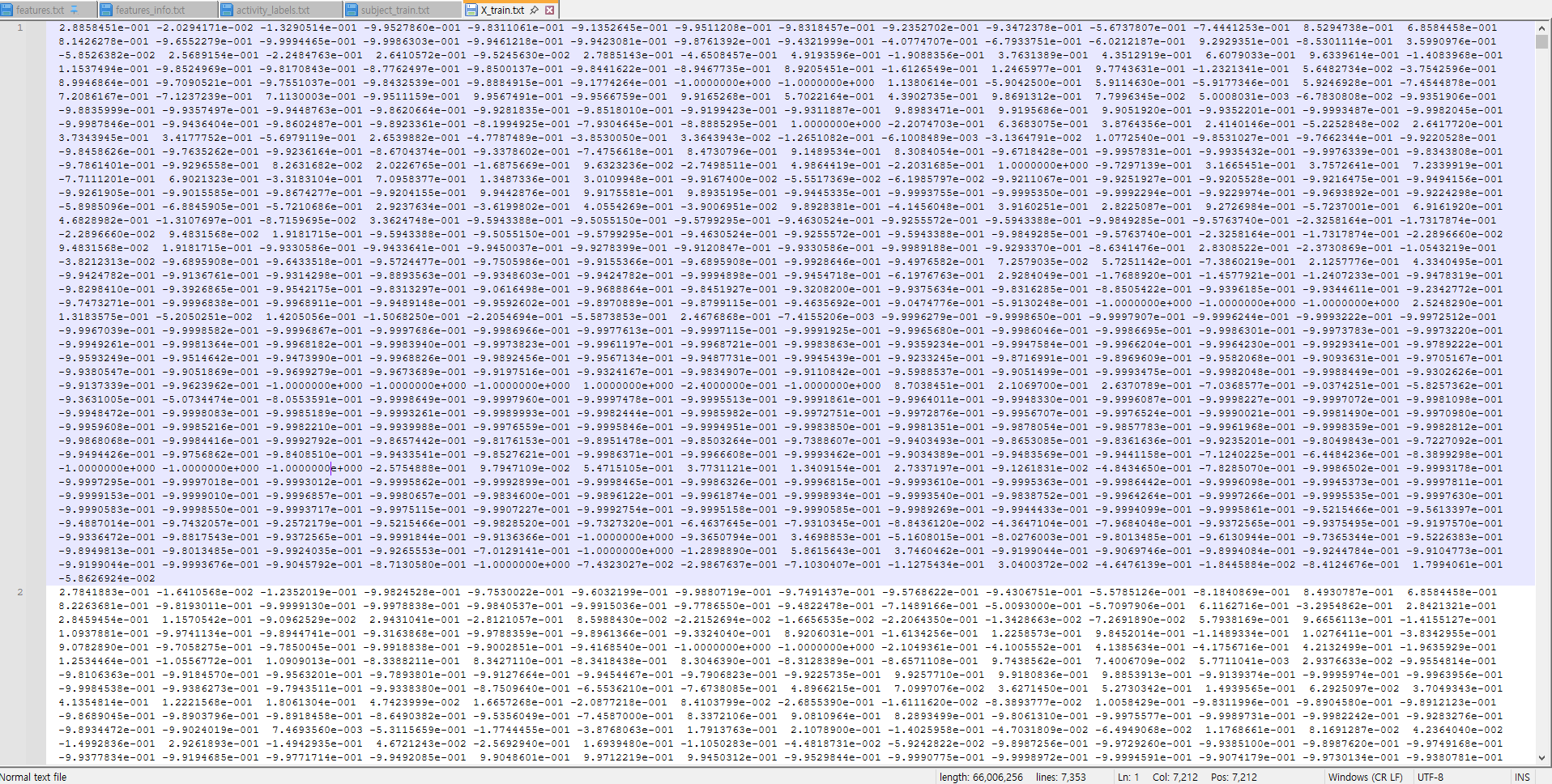
어... 음... 네.........

어떻게든 되겠죠.
그래서 UCI-HAR Dataset이 대체 무엇이냐고?
무튼, 이전 팀 프로젝트 때 데이터셋에 대한 정보 없이 본론부터 들어갔다가 데이터 해석이 안되서 고생했던 경험을 교훈삼아, 이번 프로젝트는 데이터셋의 정보부터 파헤쳐보기로 결심했습니다.
그런 의미에서 README 파일부터 번역하였습니다. 아래는 요약내용입니다.
-
이 데이터셋은 스마트폰 센서로 사람의 활동을 자동으로 인식(HAR, Human Activity Recognition) 하기 위해 만들어졌으며, 사람이 다음 6가지 행동을 할 때 스마트폰이 감지한 가속도 + 자이로스코프 신호를 분석하여 “지금 어떤 활동인가?”를 분류하는 데 사용됨
-
6가지 활동(class, Activity 라고도 함) : 걷기 (WALKING), 계단 오르기 (WALKING_UPSTAIRS), 계단 내려가기 (WALKING_DOWNSTAIRS), 앉기 (SITTING), 서 있기 (STANDING), 누워 있기 (LAYING)
-
실험방법 : 19~48세 사이 성인 30명 대상, 허리 벨트에 갤럭시S2 고정하여 데이터 수집
-
수집데이터 : 가속도(accelerometer) – 3축 (X, Y, Z), 자이로스코프(gyro) – 3축 (X, Y, Z), 샘플링 속도: 50Hz (초당 50회 측정)
-
라벨링: 실험 장면을 영상 촬영, 사람이 수작업으로 활동 레이블 부여 (사람이 한땀..한땀..)
-
원시 센서(raw signal)은 그대로 쓰는가? → No. 데이터 전처리가 이미 완료됨
-
전처리 과정 : 노이즈 필터 적용 → 데이터를 2.56초 길이의 슬라이딩 윈도우로 자름 → 각 윈도우는 128개의 연속 측정값 포함 → 50% overlap (앞 샘플과 절반 겹침) → 가속도에서 중력(gravity)와 신체 움직임(body motion)을 분리 → 각 윈도우에서 561개의 통계적 특징(feature) 을 추출 → 시간 도메인(time domain) 특징, 주파수 도메인(frequency domain) 특징 등
-
따라서 X_train.txt 파일에는 561개의 가공된 피처가 이미 만들어짐 (생김새는 위의 그림 참고)
-
샘플(record, 한 행 샘플) 포함 정보 : 정규화된 561개의 센서 기반 feature, 해당 샘플의 활동(Activity) 레이블 (1~6), 샘플을 수집한 참여자의 ID → 즉, 한 사람(Subject)이 특정 시간구간(Window) 동안 한 행동(Activity)을 561개의 수치(feature)로 표현한 데이터
-
데이터 추가 설명 : 가속도는 중력 가속도 g(9.80665 m/s²) 기준, gyro 센서 단위는 rad/sec, 561개 feature는 모두 [-1, 1] 범위로 정규화 완료
음.. 이런 정보를 알고 나면 좀 친해질 수 있을까요? 아직은 잘 모르겠네요.. 하하..
일단 이 txt파일들로 어떻게 데이터셋을 만들지부터 고민을 좀 해봐야겠습니다.
이제부터 지옥의 데이터 세팅 대장정이 펼쳐집니다.
어딘가에서 설명을 봤는데 다행히(?) 데이터들이 쉼표(,)로 구분되어 있어서 csv파일 취급하면 된다고 합니다.
# features.txt를 로딩함 → 561개의 Feature 이름을 불러오기 위함
# X_train을 DataFrame으로 읽을 때, 컬럼명이 필요하며
# features.txt 안에 중복된 이름이 존재하므로 미리 처리해야 함
features = pd.read_csv(
"UCI-HAR Dataset/features.txt",
sep="\s+", # 구분자(separator)로 하나 이상의 공백(whitespace)을 사용
header=None, # 헤더가 없기도 하지만 일단 없는 채로 로딩
names=["index", "feature"] # 두 컬럼을 가진 파일: index, feature_name
)
# 중복 feature명 처리
# HAR dataset에는 동일한 feature명이 여러 번 등장하는 경우가 있음
# Pandas에서는 DataFrame 컬럼명이 중복되면 에러 또는 예기치 않은 동작이 발생하므로
# 동일 이름이 있을 경우 뒤에 _1, _2 같은 suffix를 붙여 고유한 컬럼명으로 변환함
feature_names = []
counter = {}
for f in features["feature"]:
if f in counter:
counter[f] += 1
new_name = f"{f}_{counter[f]}"
feature_names.append(new_name) # 중복 시 feature명 뒤에 +'_번호' 처리
else:
counter[f] = 0
feature_names.append(f)
# feature_names는 최종적으로 X_train/X_test에서 사용할 561개 feature 컬럼명 리스트가 됨
len(feature_names), feature_names[:10]이쯤에서 왜 features.txt에 중복이 발생할 것을 대비해야 하는지 확인해보니, HAR Dataset의 feature 생성 과정에서 tBodyAcc-XYZ, fBodyGyroJerk-XYZ 같은 feature들이 FFT 변환·통계량 생성 과정에서 자동 생성되는데, 특정 파이프라인 때문에 동일한 이름이 중복 생성되는 버그가 존재한다고 합니다. 그렇다보니 features.txt 파일에는
fBodyBodyGyroMag-mean()
fBodyBodyGyroMag-mean()이런 동일한 feture명이 종종 나온다고 하네요.
그래서 그대로 불러오면 데이터프레임에 같은 컬럼명이 두번 들어가며 충돌하기 때문에 강제로 넘버링하여 고유 컬럼명을 만드는 과정이 필요합니다. 코드를 실행시키고 데이터프레임 길이와 feature명들을 좀 보겠습니다.
(561,
['tBodyAcc-mean()-X',
'tBodyAcc-mean()-Y',
'tBodyAcc-mean()-Z',
'tBodyAcc-std()-X',
'tBodyAcc-std()-Y',
'tBodyAcc-std()-Z',
'tBodyAcc-mad()-X',
'tBodyAcc-mad()-Y',
'tBodyAcc-mad()-Z',
'tBodyAcc-max()-X'])근데, 이쯤되니 갑자기 궁금해집니다. 제가 배운 상식으로는 'feature' = '컬럼명' 인데, 쟤넨 왜 데이터로 들어가있고 난리죠? 어떻게 저 데이터들을 컬럼명으로 만들어야 하죠?
일단 진정하고 데이터프레임을 확인해보겠습니다.
# Index 별 feature명 확인
features실행하면,
| index | feature | |
|---|---|---|
| 0 | 1 | tBodyAcc-mean()-X |
| 1 | 2 | tBodyAcc-mean()-Y |
| 2 | 3 | tBodyAcc-mean()-Z |
| 3 | 4 | tBodyAcc-std()-X |
| 4 | 5 | tBodyAcc-std()-Y |
| ... | ... | ... |
| 556 | 557 | angle(tBodyGyroMean,gravityMean) |
| 557 | 558 | angle(tBodyGyroJerkMean,gravityMean) |
| 558 | 559 | angle(X,gravityMean) |
| 559 | 560 | angle(Y,gravityMean) |
| 560 | 561 | angle(Z,gravityMean) |
561 rows × 2 columns
이렇게 되어있습니다.
첫 코드에서 for 문이 실행되면 feature 컬럼 데이터를 feature_names 리스트 안에 인덱스 순서대로 차곡차곡 넣고 & 중복이 있으면 중복처리와 동시에 결과물을 순서대로 리스트에 넣는 과정(헥헥..) 을 수행하여 총 561개의 1차원 컬럼명 리스트가 완성됩니다.
# X_train.txt 로딩, 561차원의 센서 feature
X_train = pd.read_csv(
"UCI-HAR Dataset/train/X_train.txt",
sep="\s+",
header=None,
names=feature_names
)
X_train.shape이제 학습용 데이터 X_train을 불러오면서, header=None 처리를 하고, 헤더명 리스트를 feature_names 로 지정해주면, 자동으로 찹찹찹 feature명이자 컬럼명이 생성되고 데이터가 쌓입니다. 생긴것을 확인해보겠습니다.
 네, 아주 잘생겼네요(?).
네, 아주 잘생겼네요(?).
이제 y_train과 subject_train도 불러오겠습니다.
# y_train 로딩, subject ID 매핑
y_train = pd.read_csv(
"UCI-HAR Dataset/train/y_train.txt",
sep="\s+",
header=None,
names=["Activity"] # Activity 차후 class가 될 것
)
subject_train = pd.read_csv(
"UCI-HAR Dataset/train/subject_train.txt",
sep="\s+",
header=None,
names=["Subject"]
)y_train 데이터셋의 컬럼명은 분류 class가 되는 'Activity' 즉 '활동'이며, 데이터셋 설명서에서 언급한 6가지 활동이 숫자형 데이터 존재합니다.
subject_train 데이터셋은 'Subject'로 실험대상 30명의 ID이며, ID가 숫자형 데이터로 존재합니다.
이제 학습용 데이터셋을 완성하기 위해 각각의 데이터셋들을 모아서 묶어보겠습니다.
# train set 하나로 묶기
train_df = pd.concat([subject_train, y_train, X_train], axis=1)
train_df.head()참고로 데이터프레임을 합치는 pandas 메써드는 concat인데, 명령어 외우기에 취약하지만 이건 외우기 편했던 이유가, 엑셀에서 지정한 두 셀을 합치는 함수 concatenate를 많이 쓴 덕분인지 바로 외워지더라고요.
잘 됐나 한번 보겠습니다.
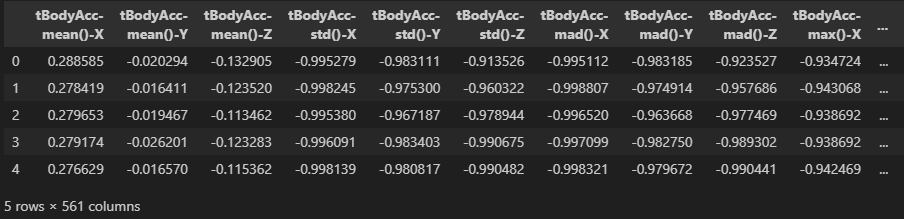 잘 됐군요. 다행입니다(?).
잘 됐군요. 다행입니다(?).
이제 test 세트도 동일하게 적용하겠습니다.
# test set도 동일하게 적용
X_test = pd.read_csv(
"UCI-HAR Dataset/test/X_test.txt",
sep="\s+",
header=None,
names=feature_names
)
y_test = pd.read_csv(
"UCI-HAR Dataset/test/y_test.txt",
sep="\s+",
header=None,
names=["Activity"]
)
subject_test = pd.read_csv(
"UCI-HAR Dataset/test/subject_test.txt",
sep="\s+",
header=None,
names=["Subject"]
)
test_df = pd.concat([subject_test, y_test, X_test], axis=1)
# train & test 합치기
full_df = pd.concat([train_df, test_df], axis=0).reset_index(drop=True)
full_df.shapetest셋 불러오기 따로 full 데이터셋 합치기 따로 코드 작성했는데 블로그엔 귀찮아서 이어 올렸습니다. 장장 3시간 동안 글을 썼더니 슬슬 지치거든요.. shape 보겠습니다.
(10299, 563)561차원이라면서 왜 563차원이냐 라고 하면 안되는거 아시죠?
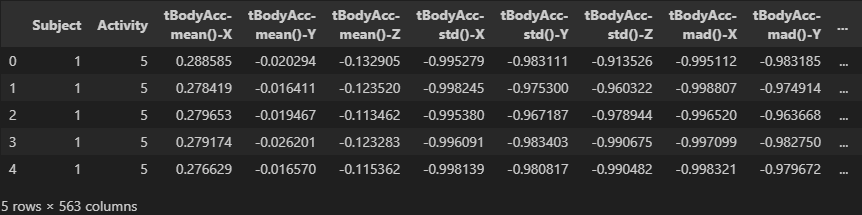 여기서 563차원이 된 이유는
여기서 563차원이 된 이유는 Subject와 Activity가 붙었기 때문입니다.
여기까지가 데이터셋 세팅 과정입니다.
지금 당장 글을 끊고 싶지만 큰제목이 '2. 데이터 탐색'인 만큼 학습 전 단계까지는 탐색해보고 끝내겠습니다.🤦♂️
왜 차원축소를 해야 하는지 분석 안 해보고도 아는 방법
# 데이터 구조 확인
print(full_df.shape)
full_df.info()
# 결측치 확인
full_df.isnull().sum()
# target 분포 확인
full_df['Activity'].value_counts()데이터 구조, 결측치, target 분포를 한번에 확인하겠습니다.
(10299, 563)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10299 entries, 0 to 10298
Columns: 563 entries, Subject to angle(Z,gravityMean)
dtypes: float64(561), int64(2)
memory usage: 44.2 MB
Activity
6 1944
5 1906
4 1777
1 1722
2 1544
3 1406
Name: count, dtype: int64사실 결측치 실행 결과 안나왔는데 그 이유는 뒤에 .sum()을 한번 더 붙여서였고...... 코드 수정하고 다시 run all 하기 귀찮아서 생략한 것은 안 비밀입니다...... 그리고 데이터 만드신 분들께서 전처리를 워낙 잘 해놔서 결측치는 없다고 하셨어요. 믿고가야죠.
describe()도 봤는데 생각해보니 이 데이터프레임 친구는 563차원입니다. 심지어 subject와 Activity는 명목척도입니다. 의미가 없어요. 그래서 샘플링을 시도하였습니다.
# 그래서 기초통계 EDA 샘플링
sample_cols = [col for col in full_df.columns if 'mean' in col][:5]
full_df[sample_cols].describe()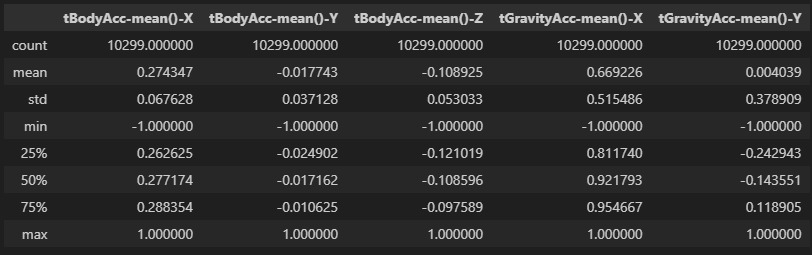
다른건 모르겠고 표준편차가 아주 버라이어티하다는건 알겠습니다...... 앞으로가 걱정이 됩니다....
# 아니면 박스플롯
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
sns.boxplot(data=full_df[sample_cols])
plt.xticks(rotation=90)
plt.show()이상치가 있을까 싶어서 배운거 다 써먹어볼 겸 boxplot도 그려봅니다.
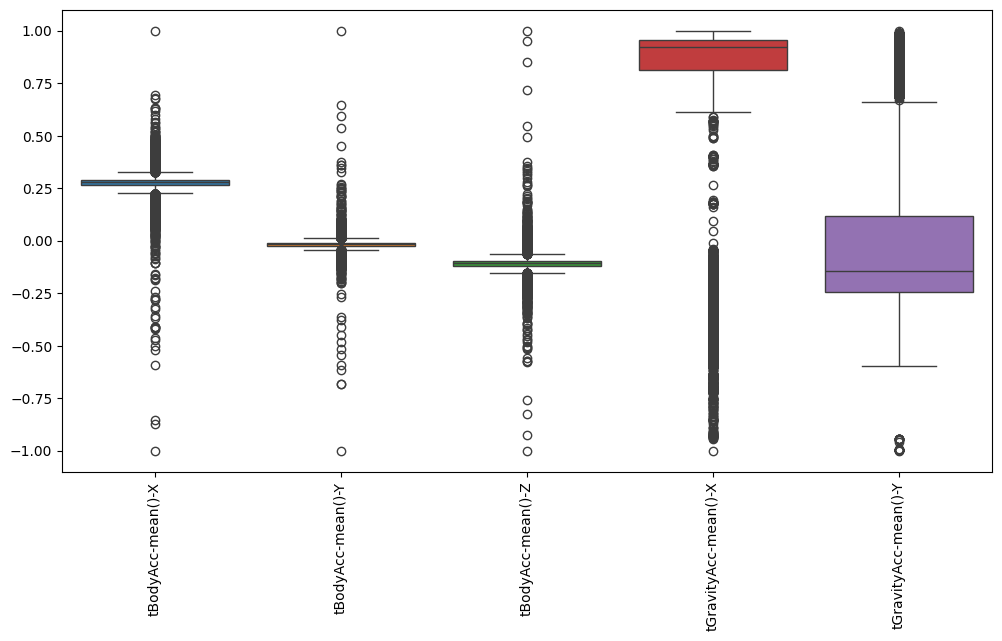 ... 제가 이 결과 보고 노트북 markdown에 이렇게 썼거든요.
... 제가 이 결과 보고 노트북 markdown에 이렇게 썼거든요.

분명 설명서에 정규화 하셨다고 했는데... 그 분의 정규화와 내가 아는 정규화는 다른 것인가... 정규화를 했음에도 저렇다는 것은...... 아니지 정규화를 해서 그나마 저정도인가... 하.....😱
일단 제가 너무 지쳐서 + 데이터 탐색을 마쳤으니 다음 화에는 본격적으로 차원접었다폈다와 분석 수행 과정을 이어가겠습니다.
🔗Dataset source
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra and Jorge L. Reyes-Ortiz. A Public Domain Dataset for Human Activity Recognition Using Smartphones. 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013. Bruges, Belgium 24-26 April 2013.
